大数据电商流量分析项目实战:Hadoop初认识+ HA环境搭建(二)


✨博客主页: https://blog.csdn.net/m0_63815035?type=blog
💗《博客内容》:大数据、Java、测试开发、Python、Android、Go、Node、Android前端小程序等相关领域知识
📢博客专栏: https://blog.csdn.net/m0_63815035/category_11954877.html
📢欢迎点赞 👍 收藏 ⭐留言 📝
📢本文为学习笔记资料,如有侵权,请联系我删除,疏漏之处还请指正🙉
📢大厦之成,非一木之材也;大海之阔,非一流之归也✨

前言&课程重点(day02)
大家好,我是程序员小羊!接下来一周,咱们将用 “实战拆解 + 技术落地” 的方式,带大家吃透一个完整的大数据电商项目 ——不管你是想靠项目经验敲开大厂就业门,还是要做毕业设计、提升技术深度,这门课都能帮你 “从懂概念到能落地”。
毕竟大数据领域不缺 “会背理论” 的人,缺的是 “能把项目跑通、能跟业务结合” 的实战型选手。咱们这一周的内容,不搞虚的,全程围绕 “电商业务痛点→数据解决方案→技术栈落地” 展开,每天聚焦 1 个核心模块,最后还能输出可放进简历的项目成果。
进入正题:
本项目是一门实战导向的大数据课程,专为具备Java基础但对大数据生态系统不熟悉的同学量身打造。你将从零开始,逐步掌握大数据的基本概念、架构原理以及在电商流量分析中的实际应用,迅速融入当下热门的离线数据处理技术。
在这门课程中,你将学会如何搭建和优化Hadoop高可用环境,了解HDFS存储、YARN资源调度的核心原理,为数据处理打下坚实的基础。同时,你将掌握Hive数据仓库的构建和数仓建模方法,了解如何将海量原始数据经过层次化处理,转化为高质量的数据资产。
课程还将引领你深入Spark SQL的世界,通过实际案例学习如何利用Spark高效计算PV、UV以及各类衍生指标,提升数据分析效率。此外,你还将学习Flume的安装与配置,实现Web日志的实时采集和ETL入仓,确保数据传输的稳定与高效。
为了贴近企业实际运作,本项目还包括定时任务的设置和自动化数据管道构建,教你如何编写Shell脚本并利用crontab定时调度Spark作业,让数据处理过程实现自动化与智能化。最后,通过可视化展示模块,你将学会用FineBI等工具将数据分析结果直观呈现
总之,这是一门集大数据基础、系统搭建、数据处理与智能分析于一体的全链路实战课程。无论你是初入大数据领域的新手,还是希望提升数据处理能力的开发者,都将在这里收获满满,掌握最前沿的大数据技术。
课程计划:
| 天数 | 主题 | 主要内容 |
|---|---|---|
| Day 1 | 大数据基础+项目分组 (ZK补充) | 大数据概念、数仓建模、组件介绍、分组;简单介绍项目。 |
| Day 2 | Hadoop初认识+ HA环境搭建 | 初认识Hadoop,了解HDFS 基本操作,YARN 资源调度,数据存储测试等,并且完成Hadoop高可用的环境搭建。 |
| Day 3 | Hive 数据仓库 | Hive SQL 基础、表设计、加载数据,搭建Hive环境并融入Hadoop实现高可用 |
| Day 4 | Spark SQL 基础 | 讲解Spark基础,DataFrame & SQL 查询,Hive 集成和环境的搭建 |
| Day 5 | Flume 数据采集及ETL入仓 | 安装Flume高可用,学习基础的Flume知识并且使用Flume 采集 Web 日志,存入 HDFS;数据格式解析,数据传输优化 |
| Day 6 | 数据入仓 & 指标计算 | 解析 PV、UV 计算逻辑,Hive 数据清洗、分层存储(ODS → DWD) |
| Day 7 | Spark 计算 & 指标优化 | 使用 Spark SQL 计算 PV、UV 及衍生指标(如跳出率、人均访问时长等) |
| Day 8 | 定时任务 & 数据管道 | 编写 Shell 脚本,使用 crontab 实现定时任务,调度 Spark SQL |
| Day 9 | 可视化 & 数据分析 | 搭建一个简单的项目使用 FineBI 进行数据展示,分析趋势。 |
| Day 10 | 项目答辩 | 小组演示分析结果,可以后台联系程序员小羊点评 |
今日学习重点:
大数据Hadoop的三大组件:HDFS 分布式文件存储,MapReduce 分布式计算引擎,YARN 分布式资源调度
文章将会展示:大数据的概述,Hadoop的概述,Hadoop安装部署,HDFS Shell,HDFS Block,HDFS 工作机制,HDFS API,HDFS 命令行操作,HDFS 高级操作,MR设计思想,MR入门案例,Hadoop序列化机制,MapReduce 运行流程,MapReduce Shuffle,YARN设置思想,YARN JOB提交,YARN队列和标签。
Hadoop安装
安装并配置可用的 Hadoop 集群环境时,可以选择不同的部署模式,包括 单机模式、伪分布式模式 和 完全分布式模式。然而,在生产环境中,为了确保 高可用性(HA),搭建 HA 集群是必不可少的。如果不配置 HA,Hadoop 的稳定性和容灾能力将受到限制,从而降低其实际应用价值。因此,我们接下来将开始 安装和配置 Hadoop 高可用集群。
目标环境:
| 节点 | NameNode01 | NameNode02 | DataNode | Zookeeper | ZKFC | JouralNode |
|---|---|---|---|---|---|---|
| node01 | ✅ | ✅ | ✅ | ✅ | ✅ | |
| node02 | ✅ | ✅ | ✅ | ✅ | ✅ | |
| node03 | ✅ | ✅ | ✅ |
首先,我们先下载Hadoop安装包
文件名:hadoop-3.3.4.tar.gz 下载地址:https://cloud.189.cn/web/share?code=NzuA3aiiYNFf(访问码:fad9)
- 进入 /opt/yjx/ 上传文件
[root@node01 ~]# cd /opt/yjx
【上传文件】
- 解压并删除安装包
[root@node01 ~]# tar -zxvf hadoop-3.3.4.tar.gz -C /opt/yjx/
[root@node01 ~]# rm hadoop-3.3.4.tar.gz -rf
- 修改配置文件
# 修改环境配置文件 hadoop-env.sh:[root@node01 ~]# cd /opt/yjx/hadoop-3.3.4/etc/hadoop/
[root@node01 hadoop]# vim hadoop-env.sh# 在文件末尾添加以下内容:
export JAVA_HOME=/usr/java/jdk1.8.0_351-amd64
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_ZKFC_USER=root
export HDFS_JOURNALNODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root# 修改核心配置文件 core-site.xml:
[root@node01 hadoop]# vim core-site.xml# 在configuration 节点中添加以下内容<!-- 设置 NameNode 节点的 URI (包括协议、主机名称、端口号),用于 NameNode 与 DataNode 之间的通讯 --><property><name>fs.defaultFS</name><value>hdfs://hdfs-yjx</value></property><!-- 设置 Hadoop 运行时临时文件的存放位置,比如 HDFS 的 NameNode 数据默认存放在该目录 --><property><name>hadoop.tmp.dir</name><value>/var/yjx/hadoop/ha</value></property><!-- 设置 Web 界面访问数据时使用的用户名 --><property><name>hadoop.http.staticuser.user</name><value>root</value></property><!-- 配置 HA (高可用),需要一组 Zookeeper 地址,以逗号分隔 --><!-- 该参数被 ZKFailoverController 用于自动故障转移(Failover) --><property><name>ha.zookeeper.quorum</name><value>node01:2181,node02:2181,node03:2181</value></property><!-- 该参数表示可以通过 httpfs 接口访问 HDFS 的 IP 地址限制 --><!-- 配置 root(超级用户)允许通过 httpfs 方式访问 HDFS 的主机名或域名 --><property><name>hadoop.proxyuser.root.hosts</name><value>*</value></property><!-- 通过 httpfs 接口访问的用户获得的群组身份 --><!-- 配置允许通过 httpfs 方式访问的客户端的用户组 --><property><name>hadoop.proxyuser.root.groups</name><value>*</value></property>
- 修改 HDFS 配置文件 hdfs-site.xml
[root@node01 hadoop]# vim hdfs-site.xml在configuration 节点中添加以下内容:<!-- 设置 NameService(HDFS 命名服务),支持多个 NameNode 的 HA 配置 --><property><name>dfs.nameservices</name><value>hdfs-yjx</value></property><!-- 设置 NameNode ID 列表,hdfs-yjx 对应 dfs.nameservices --><property><name>dfs.ha.namenodes.hdfs-yjx</name><value>nn1,nn2</value></property><!-- 设置 NameNode 的 RPC 地址和端口 --><property><name>dfs.namenode.rpc-address.hdfs-yjx.nn1</name><value>node01:8020</value></property><property><name>dfs.namenode.rpc-address.hdfs-yjx.nn2</name><value>node02:8020</value></property><!-- 设置 NameNode 的 Web 界面访问地址和端口 --><property><name>dfs.namenode.http-address.hdfs-yjx.nn1</name><value>node01:9870</value></property><property><name>dfs.namenode.http-address.hdfs-yjx.nn2</name><value>node02:9870</value></property><!-- 设置 JournalNode 共享存储,用于存放 HDFS EditLog --><property><name>dfs.namenode.shared.edits.dir</name><value>qjournal://node01:8485;node02:8485;node03:8485/hdfs-yjx</value></property><!-- 设置 JournalNode 日志存储路径 --><property><name>dfs.journalnode.edits.dir</name><value>/var/yjx/hadoop/ha/qjm</value></property><!-- 设置客户端连接 Active NameNode 的代理类 --><property><name>dfs.client.failover.proxy.provider.hdfs-yjx</name><value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value></property><!-- HDFS-HA 发生脑裂时的自动处理方法 --><property><name>dfs.ha.fencing.methods</name><value>sshfence</value><value>shell(true)</value></property><!-- 失效转移时使用的 SSH 私钥文件 --><property><name>dfs.ha.fencing.ssh.private-key-files</name><value>/root/.ssh/id_rsa</value></property><!-- 是否启用 HDFS 自动故障转移 --><property><name>dfs.ha.automatic-failover.enabled</name><value>true</value></property><!-- 设置 HDFS 默认的数据块副本数(可在文件创建时覆盖) --><property><name>dfs.replication</name><value>2</value></property>
- 修改 workers:
[root@node01 hadoop]# vim workers
node01
node02
node03
- 把node01 已配置好的 hadoop 拷贝至 node02 和 node03。
[root@node02 ~]# scp -r root@node01:/opt/yjx/hadoop-3.3.4 /opt/yjx/
[root@node03 ~]# scp -r root@node01:/opt/yjx/hadoop-3.3.4 /opt/yjx/
- 修改环境变量
三个节点修改环境变量 vim /etc/profile ,在文件末尾添加以下内容:
export HADOOP_HOME=/opt/yjx/hadoop-3.3.4
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
修改完成后 source /etc/profile 重新加载环境变量。
- 启动
# 首先启动 ZooKeeper(三台机器都需要执行)。[root@node01 hadoop]# zkServer.sh start
[root@node01 hadoop]# zkServer.sh status# 然后启动 JournalNode(三台机器都需要执行)。
[root@node01 hadoop]# hdfs --daemon start journalnode# 最后格式化 NameNode 等相关服务并启动集群
# 格式化 node01 的 namenode(第一次配置的情况下使用)
[root@node01 ~]# hdfs namenode -format# 启动 node01 的 namenode
[root@node01 ~]# hdfs --daemon start namenode# node02 节点同步镜像数据
[root@node02 ~]# hdfs namenode -bootstrapStandby# 格式化 zkfc(第一次配置的情况下使用)
[root@node01 ~]# hdfs zkfc -formatZK# 启动 HDFS
[root@node01 ~]# start-dfs.sh
后期只需要先启动 ZooKeeper 然后再启动 HDFS 即可。
浏览器访问:http://192.168.100.101:9870/ 和 http://192.168.100.102:9870/
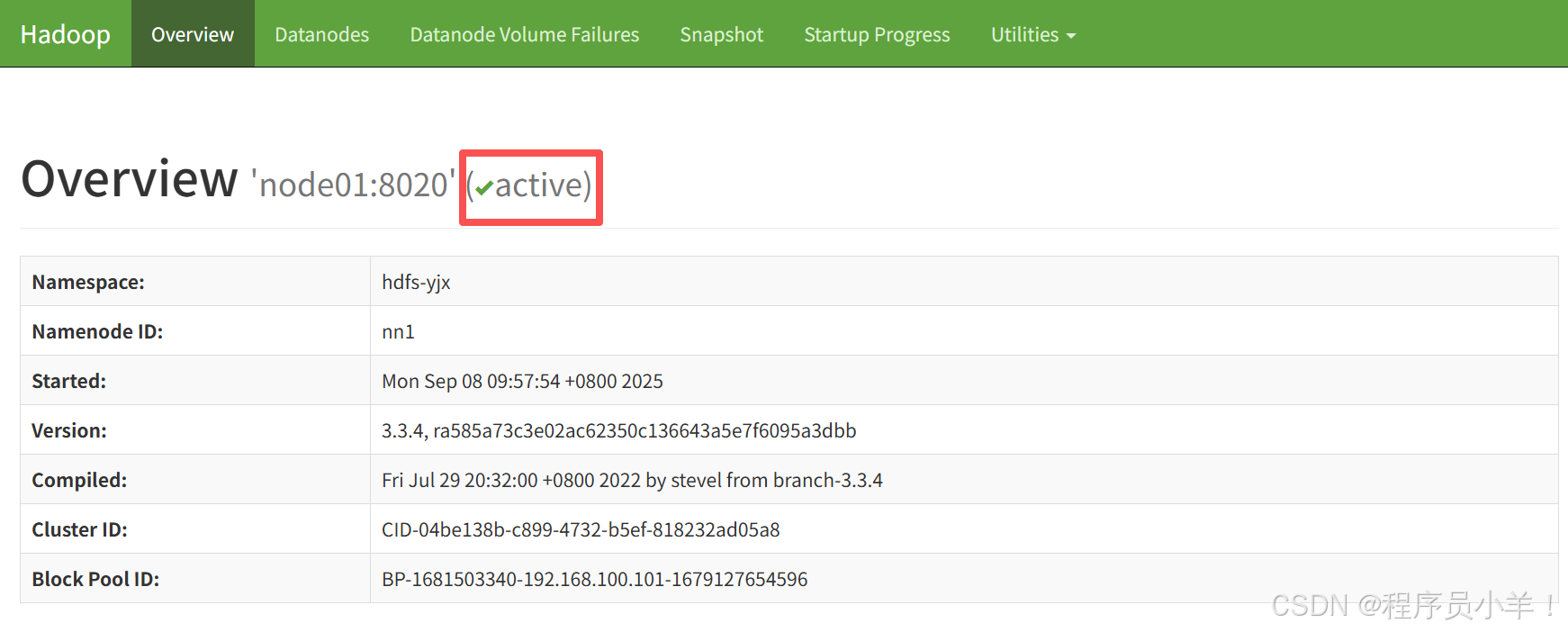
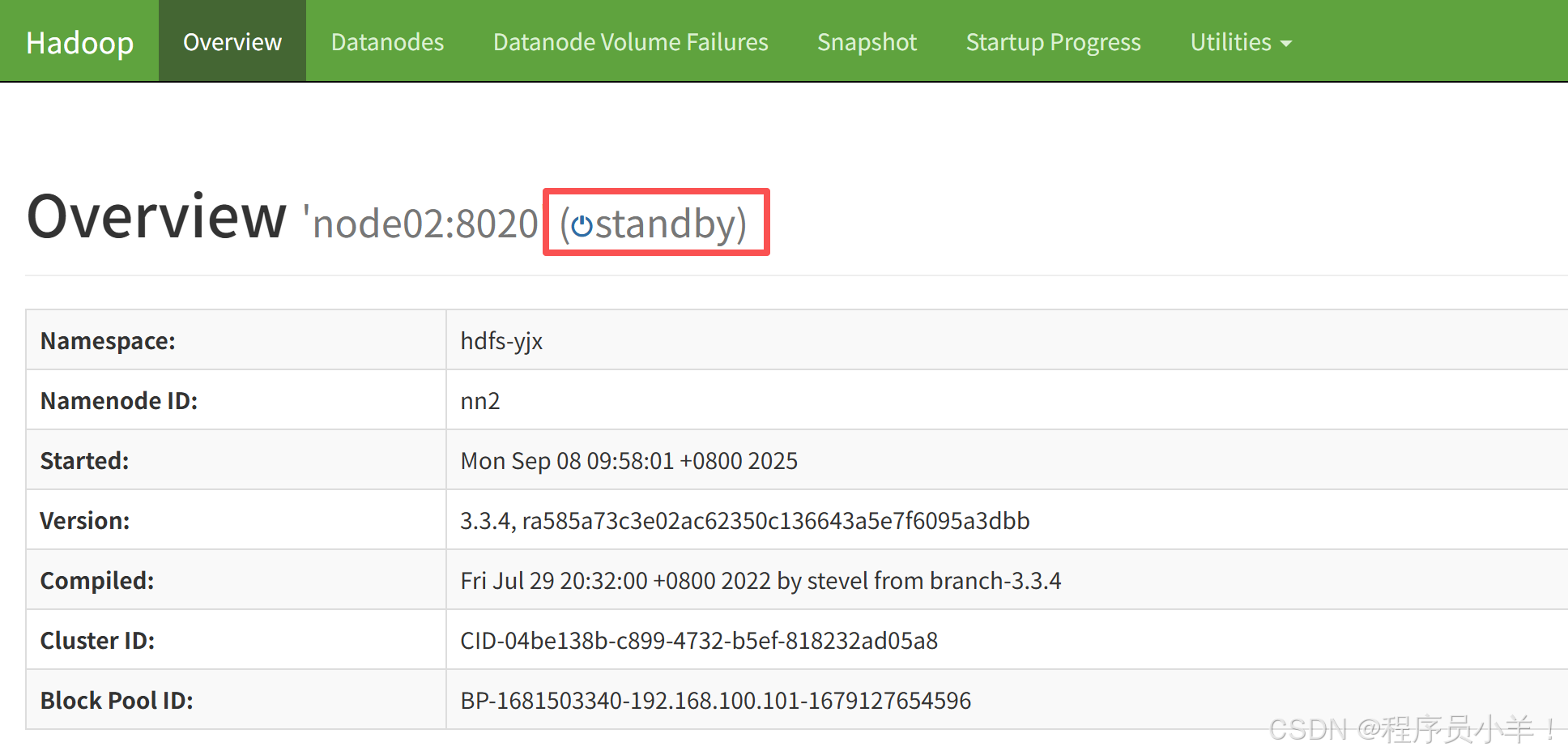
关闭hadoop
# 先关闭 HDFS。
[root@node01 ~]# stop-dfs.sh# 再关闭 ZooKeeper(三台机器都需要执行)。
[root@node01 ~]# zkServer.sh stop# 启动|关闭 所有节点和进程
[root@node01 ~]# start-all.sh
[root@node01 ~]# stop-all.sh[root@node01 ~]# mapred --daemon start historyserver
好,现在你搭建成功了,我们去拍一个快照准备者。
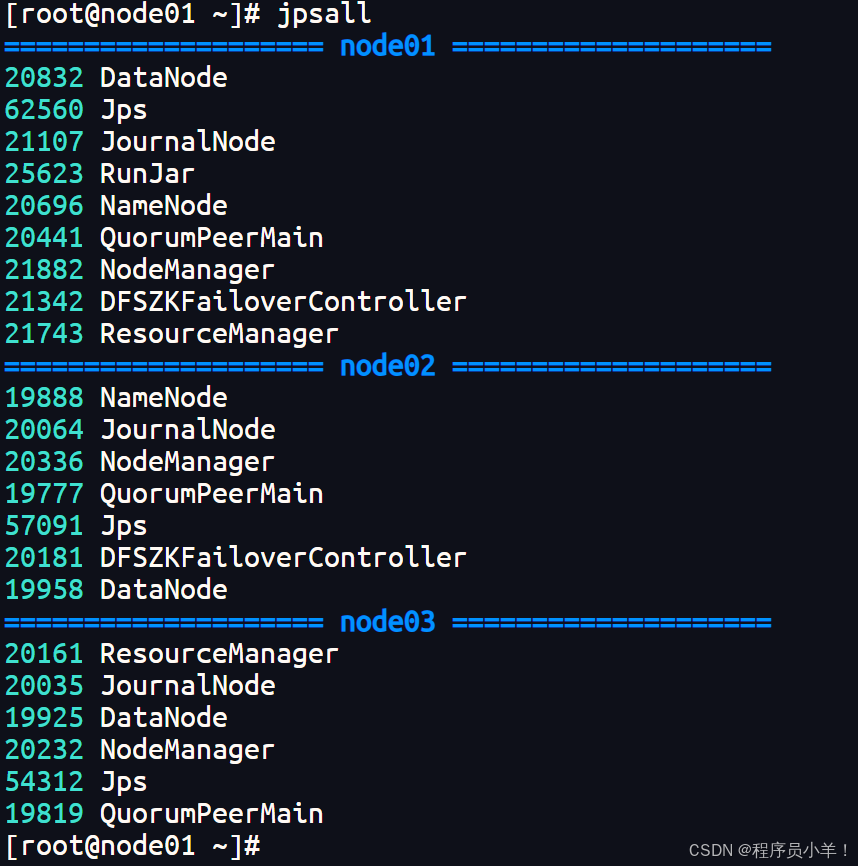
Hadoop介绍
Hadoop 是一个开源的分布式计算框架,主要用于存储和处理海量数据。它能够将大数据分散存储在普通硬件上,并通过并行计算高效处理数据。Hadoop 的核心价值在于实现了高容错、高扩展性和低成本的大数据处理能力。
狭义上来说,hadoop就是单独指代hadoop这个软件, 广义上来说,hadoop指代大数据的一个生态圈,包括很多其他的软件。
官网:https://hadoop.apache.org/
Hadoop的生态系统概述
Hadoop本身有三个核心组件,分别为 HDFS,MapReduce,Yarn 。
HDFS(Hadoop Distributed File System)
- 用于分布式存储数据,将数据切分成多个块(Block),存储在集群的各个节点上,并通过副本机制保证数据的可靠性和高可用性。
MapReduce
- 一种编程模型和计算框架,用于大规模数据处理。它将任务分为两步:Map 阶段(将输入数据拆分并并行处理)和 Reduce 阶段(对 Map 阶段的结果进行聚合)。
YARN(Yet Another Resource Negotiator)
- 资源管理层,负责调度和管理集群资源。YARN 将计算资源分配给各种应用程序,协调任务的执行,提升集群利用率和灵活性。
Hadoop 的设计思想主要受到谷歌两篇论文的启发:
《The Google File System (GFS)》
介绍了一种为大规模数据存储设计的分布式文件系统,强调数据冗余、容错和高吞吐量的思想。
《MapReduce: Simplified Data Processing on Large Clusters》
提出了 MapReduce 编程模型,用以简化大规模数据并行处理的复杂性,使开发者能够专注于数据处理逻辑,而不必关心底层的分布式并行执行细节。
当然Hadoop生态系统也不仅仅是Hadoop的一枝独秀,讲的是指的是围绕Hadoop核心组件(如HDFS、MapReduce和YARN)构建的一系列工具、框架和项目,这些组件共同协作来处理、管理、分析和利用大数据。它不仅包括分布式存储和批处理计算,还涵盖了数据仓库、实时流处理、数据导入导出、数据挖掘、机器学习等各个方面。
简单来说,Hadoop生态系统提供了一个完整的大数据解决方案,从数据采集、存储、处理到分析,都有专门的组件来支持,这些组件互相配合,共同构成了一个功能全面的大数据处理平台。常见的生态系统组件包括:
-
Hive:数据仓库,用SQL查询数据。
-
HBase:NoSQL数据库,用于实时随机读写。
-
Spark:快速内存计算框架,用于实时和批处理。
-
Flume、Sqoop:用于数据采集和数据迁移。
-
ZooKeeper:分布式协调服务,保证系统一致性和高可用性。
……
HDFS
在 HDFS 的主从架构中,主要的进程分为主节点(Master)和从节点(Slave),它们各自承担不同的职责。下面详细介绍各个关键进程及其作用:
NameNode(主节点)
作用:NameNode 是整个 HDFS 的核心,负责存储整个文件系统的元数据,包括目录结构、文件与数据块的映射、权限信息以及文件的状态。
职责:接收客户端的文件操作请求(如创建、删除、重命名等),协调 DataNode 读写数据,并管理编辑日志。
注意:在传统的 HDFS 架构中,NameNode 是单点故障(SPOF,Single Point of Failure),如果 NameNode 宕机,整个 HDFS 就无法使用。因此,为了保证 Hadoop 运行的高可用性,HDFS HA(High Availability,高可用)架构 通过 双 NameNode 机制 来消除单点故障,确保集群稳定运行。
两个namenode在开启的时候总是一个激活一个备用,如果当前主namenode死亡后,从namenode会立刻顶替。
Active NameNode(主 NameNode):负责处理客户端的所有请求,如文件的创建、删除、重命名、读取元数据等。维护整个 HDFS 的元数据(Metadata),如文件目录结构、文件到块的映射、DataNode 存储信息等。
Standby NameNode(备用 NameNode):作为 Active NameNode 的备机,不直接处理客户端请求。实时同步 Active NameNode 的元数据,以便在 Active 宕机时能立即接管。
DataNode(数据节点)
HDFS 的数据实际存储在 DataNode 上,每个 DataNode 负责存储数据块(Block)DataNode 既服务 Active NameNode,也服务 Standby NameNode,定期向两个 NameNode 汇报自己的存储信息(如哪些块在该节点上)。
JournalNode(日志节点)
用于 NameNode 之间的状态同步,解决 NameNode 之间的元数据一致性问题。他会记录 Active NameNode 的所有操作日志。
Standby NameNode 不断从 JournalNode 读取 EditLog,以保持和 Active NameNode 同步。当 Active NameNode 宕机,Standby NameNode 会重放 EditLog,确保切换后数据一致。
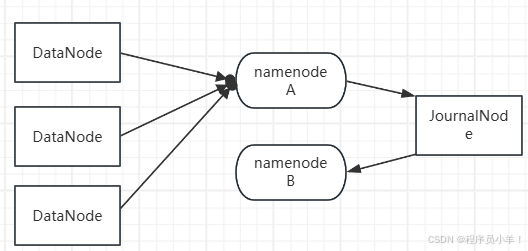
Block 块
块是HDFS中最小的存储单位,多个块存储在不同的dataNode上,dfs会保证一个块存在一个节点上。默认情况下的大小是128MB,这个大小是按照机械硬盘的平均读取速度/s制定的,可以按照实际需求更改,如果最后一个块不足128MB 这块不会占据整个块的大小。存储机制 三备份进一。
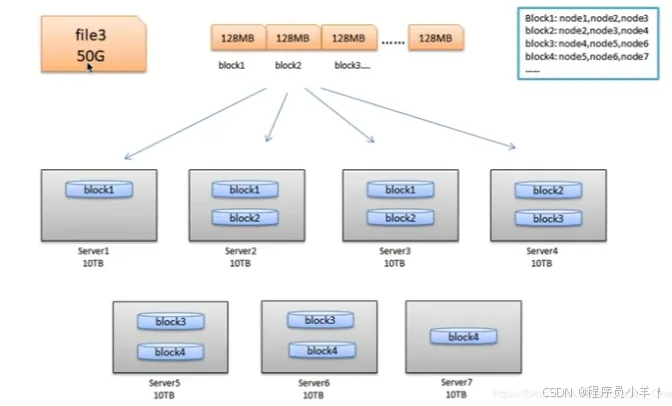
-
为什么要设置块大小为128MB?
在hadoop1.0时代设置默认块大小为64MB,在IO操作中最消耗时间的操作是寻址操作,将文件设置的大一些整体时间上会降低寻址的时间开销,数据块大找到第一个数据后就可以高效的顺序读取。
这个设计方法还可以高效地管理大规模数据。 如果数据量庞大,文件数量众多,每个文件一个块的做法会显著增加元数据的管理负担。大块的设计能够减少文件块的数量,从而减轻NameNode的负担。
加块大小来提升传输效率 : 这个数值是根据硬盘的读取速度来算的,机械硬盘的平均速度在128MB/s,可以充分的使用磁盘提高传输效率。
不适合存储小文件: HDFS块大小大,如果文件数量众多但文件较小,会占用较多的NameNode内存资源。例如,一个文件大小不足128MB,即使文件内容只有1MB,也会占用一个完整的块并持有相对的副本信息和块存储信息,导致内存浪费。
故事,128G磁盘理论每个块都存满128MB在这种情况下,磁盘的存储利用率最高128G/128MB150byte = 1024 块 约等于 0.14 MB。 每个块只存储1MB数据,加上150Byte的块信息 那么每个块大小就约等于 128G/1MB150byte = 131072 块 元数据占用达到了 18.75MB
设置块的大小: 在hdfs-default.xml中就有相关配置
<property>
<name>dfs.blocksize</name>
<value>134217728</value>
<description>默认块大小,以字节为单位。可以使用以下后缀(不区分大小写):k, m, g, t, p,e。例如指定大小(例如128k, 512m, 1g等)
</description>
</property><property>
<name>dfs.namenode.fs-limits.min-block-size</name>
<value>1048576</value>
<description>允许HDFS中的最小块大小,由NameNode在创建时强制执行的。 这可以防止意外创建非常小的块以降低性能。
</description>
</property><property>
<name>dfs.namenode.fs-limits.max-blocks-per-file</name>
<value>1048576</value>
<description>每个文件最多包含的块数,由HDFS的NameNode执行。这可以防止创建降低性能的超大文件。
</description>
</property><property>
<name>dfs.datanode.data.dir</name>
<value>file://${hadoop.tmp.dir}/dfs/data</value>
<description>DataNode 使用的目录用于存储 HDFS 数据块。这个路径指定了DataNode 在本地文件系统上存储数据块的位置。通常,这个目录应该位于具有足够存储空间的磁盘上,并且 DataNode 需要对其具有读写权限。
</description>
</property>
那么因为存在块这个概念hdfs的优缺点就很明显了,优点:高容错性、适合大数据量存储、高吞吐量、高可靠性。
缺点:不适合低延迟数据访问: HDFS设计目标是批处理数据,故不适合处理需要低延迟的交互式应用。不适合存储小文件: 小文件过多会导致NameNode存储元数据的开销较大,容易造成性能瓶颈。仅支持追加写入: HDFS上的文件只能追加写入,无法对文件进行随机写入或修改。
文件的合并和快照
在 HDFS 中,文件快照(snapshot)是一种保存文件系统某个时刻状态的机制。创建快照时,HDFS会记录下指定目录及其子目录当前的元数据状态,而不需要将所有数据复制一遍。
快照为系统提供了数据备份和版本管理的能力,可以在数据误删或错误修改时迅速恢复到先前状态,从而提高了整个集群的可靠性和管理的灵活性。
就比如说你做了一个修改操作,这个操作我会先记录下来。包括最后产生的元数据变化,等到最后例如 3600 秒后或者事务执行100万次自动 合并,拿最新的快照和日志记录(JournalNode 负责,日志叫做 EditLog)推算出最新的 FsImage 并且发送给 备用namenode。这个过程被称为 Checkpoint 检查点。
此过程不会阻塞 Namenode 的使用,因为交给JournalNode 了,是异步的操作。
Checkpoint 过程将分散的小日志文件合并成一个完整的镜像,使得后续的恢复和加载操作更加高效。另一方面,当面对大量小文件问题时,通常会通过应用层面进行合并,将多个小文件整合成一个大文件,这样不仅能降低 NameNode 的管理负担,也能提高数据读取的吞吐量。
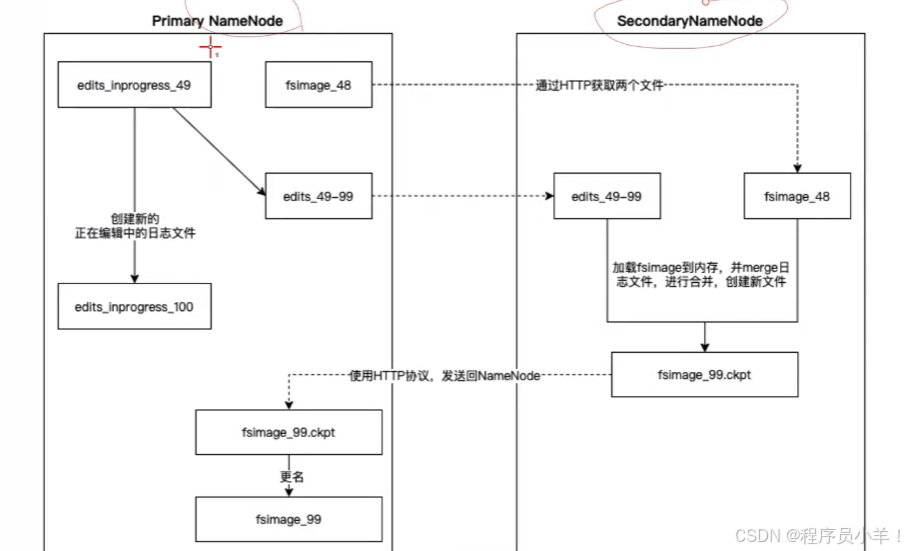
机制:注意,一般至少会留两个 Fsimage 确保不会因为最新的丢失推不出来最新的状态,当集群整个宕机之后重启数据不会毁坏,而是先进入安全模式,根据最新的 快照 和 日志数据推出最新的状态确保没问题后才会退出安全模式允许用户操作和访问。
文件读写流程
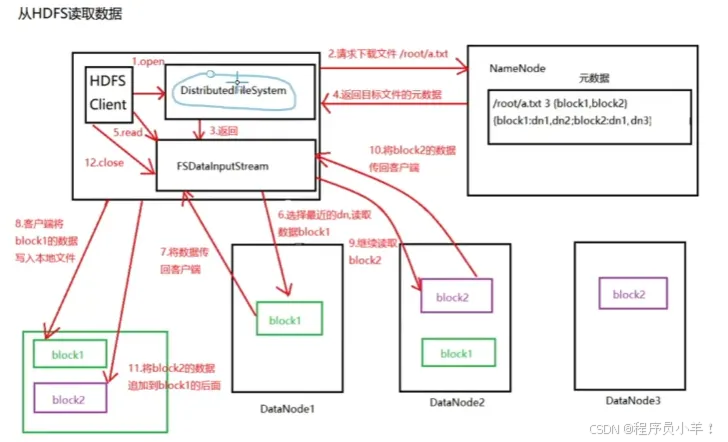
从hdfs中读取数据,见上图。
首先客户端先发送一个请求给Namenode,他来判断你有没有权限去访问,读取,返回排序好的针对数据的元数据等信息通过列表返回,通过实例化的FSDelalnputStram来读取信息,选择最近的机器拿文件返回此对象,然后操作写在本地文件中,然后继续读取块2通过此对象写入到刚刚的文件的后面就实现了完整的读取文件的操作。如果出现了读取块中途出现错误会根据块的元组信息顺序去读下一个节点标记此节点确保下次读取此文件不在这里读文件。
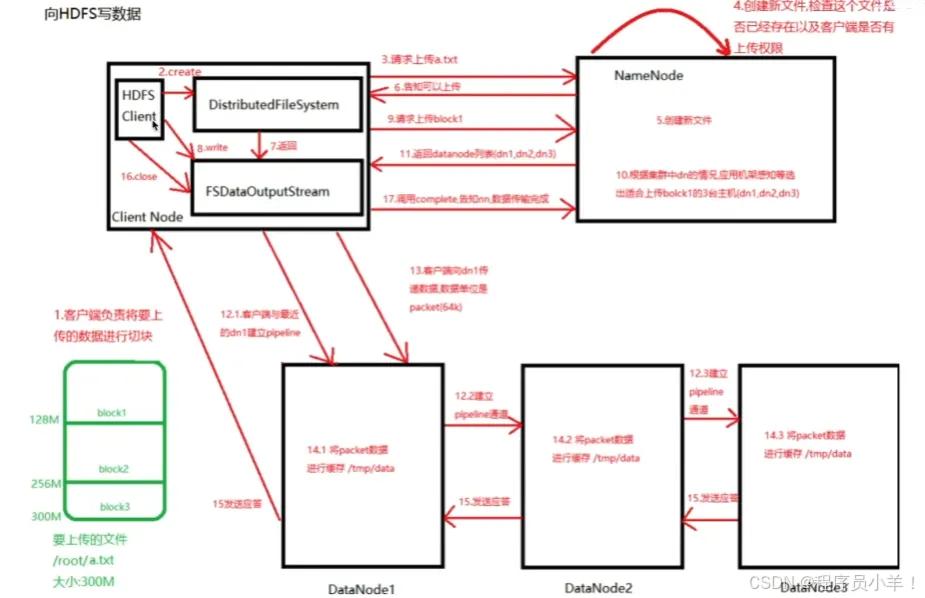
从hdfs中写入数据
客户端要先给文件进行切块,然后请求文件,构建对象和Namenode通信,创建新文件,检查当前位置文件名是否存在以及是否有权限上传,然后创建文件,返回可以上传的指示。沟通完毕后将获得的数据注入FSDelalnputStram对象让他来实现文件的写入,将文件给对象后向Namenode请求上传的块信息,namenode根据压力和机架感知策略来返回列表给写入对象,根据这个列表先和列表中的1建立连接,然后1和2通信,2和3通信,3给2汇报,2给1 不同的服务器和节点通信将数据进行缓存 tmp/data 结束后返回应答给客户端节点,指示关闭写入流,最后向Namenode汇报操作结束 完整流程结束。
如果写入断电就先关闭管道,确认队列中的所有数据包都添加回到数据队列的前端确保和之前没上传这个block时一样,然后根据下一个datenode写入并且保留一个标识就存两份,让Namenode发现这个坏掉节点重新工作后自动删除之前写一半的内容,Namenode发现副本数量不足会创建一个副本
安全模式和启动
HDFS 在启动过程中会进入一种叫做“安全模式”的状态。NameNode 在启动时会自动进入安全模式,在这个阶段,文件系统处于只读状态,不允许进行任何修改操作(如创建、删除文件),以保证系统在恢复过程中不会有数据不一致的问题。
当 NameNode 启动后,它首先会收集 DataNode 上各个块的报告(Block Reports),计算每个数据块的副本数量。NameNode 会检查整个文件系统中块副本的完整性,确保有足够多的块副本存在。只有当达到预设的阈值,比如大部分块副本都已经成功加载并报告给 NameNode 后,NameNode 才会退出安全模式,从而允许客户端进行写操作。
通常,管理员也可以通过命令手动退出安全模式,例如使用 hdfs dfsadmin -safemode leave。这种设计确保了在 NameNode 刚启动时,不会因部分数据副本缺失而出现数据损坏或不一致的问题,从而提高了 HDFS 的整体可靠性。默认阈值大概是98%接近100%
HDFS简单操作
hdfs的操作实际上和Linux很像,只是在前面添加了 hdfs dfs的前缀,例如:hdfs dfs mkdir /etc 【在dfs根目录下创建etc文件夹】 下面有是有关的基础Shell命令需要掌握:
创建新目录:!注意,操作路径都是绝对路径 不存在cd 相对路径
》hdfs dfs -mkdir (-p) /目录《
$ hdfs dfs -mkdir /test # 在根目录下传建一个test文件夹
$ hdfs dfs -mkdir -p /test/a/b/c # 多级创建,在一个文件夹下在创建子级文件夹多加-p上传命令:
》hdfs dfs -put /本地文件 /dfs路径《
$ hdfs dfs -put /sowfwares / # 上传/sowfwares到dfs的根目录上
$ hdfs dfs -put *.txt / # 上传当前目录下的txt文件到根目录上本地移动文件到dfs:
》hdfs dfs -moveFromLocal /本地文件 /dfs路径《
$ hdfs dfs -moveFromLocal hello.jpg / # 上传当前目录下的txt文件到根目录上查看hdfs文件:
》 hdfs dfs -ls (-hR) /dfs路径 《
$ hdfs dfs -ls / # 查看hdfs根目录文件
$ hdfs dfs -ls -h / # 带文件大小单位转换的展示
$ hdfs dfs -ls -R / # 递归查看hdfs根目录文件下所有文件(包括所有子文件)查看hdfs文件的内容:
》 hdfs dfs -cat /dfs路径 《
$ hdfs dfs -cat /file/txt01.txt # 查看hdfs下的/file/txt01.txt文件
$ hdfs dfs -cat /file/*.txt # 查看hdfs下的/file/*.txt,所有txt文件夹查看文件的头几行:
》 hdfs dfs -head /dfs路径 《
查看文件的后几行:
》 hdfs dfs -tail /dfs路径 《下载hdfs的文件到本地: []下的东西为非必写
》 hdfs dfs -copyToLocal /dfs路径 [本地路径] 《 # 不写本地路径会下载到当前位置
$ hdfs dfs -copyToLocal /file/txt01.txt # 下载hdfs下的/file/txt01.txt文件
》 hdfs dfs -get /dfs路径 《
$ hdfs dfs -get /file/txt01.txt # 下载hdfs下的/file/txt01.txt文件合并下载hdfs的文件到本地:
》 hdfs dfs -getmerge /dfs路径* 文件名(位置) 《
$ hdfs dfs -getmerge /input/file* file # 合并下载/input/file*的所有文件存在file文件中删除hdfs的文件:
》 hdfs dfs -rm (-r) /dfs路径 《 # 删除文件没提示信息,注意
$ hdfs dfs -rm /file/*.txt # 删除/file下的所有txt文件夹
$ hdfs dfs -rm -r /file # 删除整个/file文件夹拷贝文件
》 hdfs dfs -cp /dfs路径 /移动到的dfs路径 《
$ hdfs dfs -cp /file/file1.txt /file2_cp.txt # 拷贝hdfs的文件到其根目录下/file2_cp.txt的文件文件重命名和移动文件
》 hdfs dfs -mv /dfs路径文件 /dfs(同级目录下)新路径文件 《
$ hdfs dfs -mv /file/file1.txt /file/txt01.txt # 把/file/file1.txt文件重命名为/file/txt01.txt
》 hdfs dfs -mv /dfs路径文件 /dfs新路径文件 《
$ hdfs dfs -mv /file/file1.txt / # 把/file/file1.txt文件移动到根目录创建空文件
》 hdfs dfs -touchz /dfs文件夹名 《
$ hdfs dfs -touchz /file2 # 在dfs上创建了/file2文件夹向文件中追加内容
!HDFS中不支持你编辑文件,只能向后追加内容
》 hdfs dfs -appendToFile /本地文件 /dfs文件《
$ hdfs dfs -appendToFile /file1 /file # 向dfs文件/file上追加本地的文件/file1到文件末尾修改文件权限
》 hdfs dfs -chomd (-R) 权限符 /dfs位置 《
$ hdfs dfs -chomd 755 /file # 赋予dfs下/file文件权限为 755
$ hdfs dfs -chomd 755 /sofwares # 递归赋予dfs下/sofwares文件夹及其内部文件权限为 755修改文件所属用户、组
》 hdfs dfs -chown [所属用户][:所属用户组] /dfs位置 《
$ hdfs dfs -chown hadoop /file # dfs下的/file文件所属用户变为hadoop
$ hdfs dfs -chown root:superroot /file # dfs下的/file文件所属用户变为root,用户组为superroot修改文本副本数量
》 hdfs dfs -setrep 整数 /dfs位置 《
$ hdfs dfs setrep 3 /file # dfs下的/file文件副本数量为3
# 作用于文件夹下的时候下面所有文件都会被修改文件的测试
参考使用:hdfs dfs -test -d /sowfares && echo "0K" || echo "no"
# /sowfares 是不是一个文件夹(-d) 如果是输出OK,不是no
# -d 是否为文件夹 -e 是否存在 -z 是否为空查看文件夹和子文件夹数量
》 hdfs dfs -count /dfs位置 《
$ hdfs dfs -count / # 根目录下的子文件数量磁盘利用率统计:
》 hdfs dfs -df (-h) / 《
统计文件文件夹大小:
》 hdfs dfs -du (-hs) /dfs位置 《 # -s求总和文件状态查看:
》 hdfs dfs -stat [占位符] /dfs位置 《
# 占位符:%b 文件大小,%n 打印文件名,%o 打印block的size,%r 打印副本数量,%y 修改时间
$ hdfs dfs -stat %n-%b-%r-%o-%y /softwares/hadoop-3.3.1.tar.gz
# 查看dfs/softwares/hadoop-3.3.1.tar.gz 文件的名字,大小,副本数,修改时间和块大小
回收站
回收站:在dfs中是有回收站概念的,默认是不开启的,可以通过回收站找回被删除的文件,需要修改集群中的 core-site.xml 文件 。
回收站的基本原理: 当用户删除文件时,HDFS 并不会立即从磁盘中删除文件,而是将文件移动到一个称为回收站(Trash)的特定目录中,当保留时间设置为0代表不经过此文件夹立刻删除无法恢复。 检查点创建时间间隔 是防止存储出现意外设置的检查点将回收站的内容持久化一次。 这个值应该小于或等于 fs.trash.interval 的值。如果设置为 0,则会自动设置为与 fs.trash.interval 相同的值。
(对应配置文件名:hdfs-site.xml)
<!-- 回收站保留时间,单位是分钟。如果设置为0表示不启用回收站。 1440一天 -->
<property><name>fs.trash.interval</name><value>1440</value>
</property><!--这是检查点创建的时间间隔,单位是分钟。-->
<-- 这个值应该小于或等于fs.trash.interval,如果设置为0,则会将这个值设置为ts.trash.interval的值。-->
<property><name>fs.trash.checkpoint.interval</name><value>720/value>
</property>
回收站路径:hdfs://hdfs-yjx/user/root/.Trash/Current/……
文件找回: hdfs dfs -mv /user/root/.Trash/Current/xx / [将 /user/root/.Trash/Current/xx 文件移动到根目录下]
清空回收站: hdfs dfs -expunge
删除文件夹不通过回收站:hdsf -dsf -rm (-r) -skipTrash /xx
hadoop jar $HADOOP_HOME/share/hadoop/mapr educe/hadoop-mapreduce-examples-3.3.4.jar pi 1000 1000
YARN
YARN(Yet Another Resource Negotiator)是 Hadoop 2.x 引入的资源管理和任务调度框架,它将资源管理与应用程序调度、监控分离开来,使得集群可以同时运行多种不同的计算框架(如 MapReduce、Spark、Tez 等),从而极大地提高了 Hadoop 集群的利用率和灵活性。
YARN 的架构可以分为几个核心组件。首先是 ResourceManager,它作为集群的全局资源管理器,负责整个集群资源的分配和调度。ResourceManager 内部分为两个主要部分:
(Scheduler)和应用管理器(ApplicationManager)。调度器负责按照一定的调度算法(如 Capacity Scheduler 或 Fair Scheduler)分配容器资源,但它不负责任务的执行;应用管理器则负责接收用户的作业提交,并为每个应用启动对应的 ApplicationMaster。
其次,运行在集群每个节点上的 NodeManager 是局部资源管理器,它负责管理节点上的实际资源、监控容器的运行状态,并向 ResourceManager 定期汇报节点的资源使用情况。NodeManager 负责启动、监控和终止在本节点上运行的容器。
在 YARN 中,每个作业或应用程序都由一个专门的 ApplicationMaster 来管理。ApplicationMaster 负责与 ResourceManager 协商所需的资源(以容器的形式分配),并在各个节点上协调任务的执行。它相当于作业的总指挥,既要对作业进度进行监控,也要处理作业中的故障恢复和资源重新分配等问题。
容器(Container)是 YARN 中资源分配的最小单元,每个容器包含一定数量的 CPU、内存等资源。当 ResourceManager 将资源分配给 ApplicationMaster 后,ApplicationMaster 会进一步将这些资源划分给具体的任务,在 NodeManager 的协助下启动容器来执行任务。容器使得资源隔离与管理变得更加细粒度,也方便实现多租户环境下的资源保障。
YARN 的工作流程大致如下:
当用户提交一个作业时,ResourceManager 接收到作业请求,并启动一个 ApplicationMaster;ApplicationMaster 随后向 ResourceManager 请求资源(容器),ResourceManager 根据集群资源和调度策略分配容器;得到资源后,ApplicationMaster 联系对应节点的 NodeManager 启动容器,并将作业任务分派到这些容器上执行;在任务执行过程中,NodeManager 监控容器状态并将运行情况汇报给 ApplicationMaster;作业执行完成后,ApplicationMaster 通知 ResourceManager,最终释放资源。
通过这种架构,YARN 实现了资源的集中调度与分布式执行解耦,使得集群能够动态调配资源、运行多种计算框架,并提供更好的容错与扩展性。总的来说,YARN 是 Hadoop 集群高效、灵活、多任务共存的关键所在。
MapReduce(MR)
MapReduce 是一种用于大规模数据处理的编程模型和框架,它最初由谷歌提出,旨在帮助开发者在分布式集群上以简单的方式处理海量数据。MapReduce 把任务分为两个主要部分:Map(映射)和 Reduce(归约)。在 Map 阶段,每个节点独立地处理输入数据,生成一组中间的键值对;在 Reduce 阶段,相同键的中间结果被收集并进行合并或聚合,形成最终结果。
这种模型的设计理念在于将复杂的分布式计算抽象成两个简单的函数,使开发者无需关注底层的任务调度、数据传输和容错机制。MapReduce 内部通过自动将数据分割、分配任务、并行处理以及在节点发生故障时重新调度任务来保证计算的高效性和稳定性。它支持大规模并行计算,同时具备高度的容错能力,这使得 MapReduce 成为批量数据处理和数据分析的核心技术之一。
总的来说,MapReduce 为处理海量数据提供了一个清晰、易于理解的框架,简化了分布式并行计算的实现,而不需要开发者深入了解各个细节。
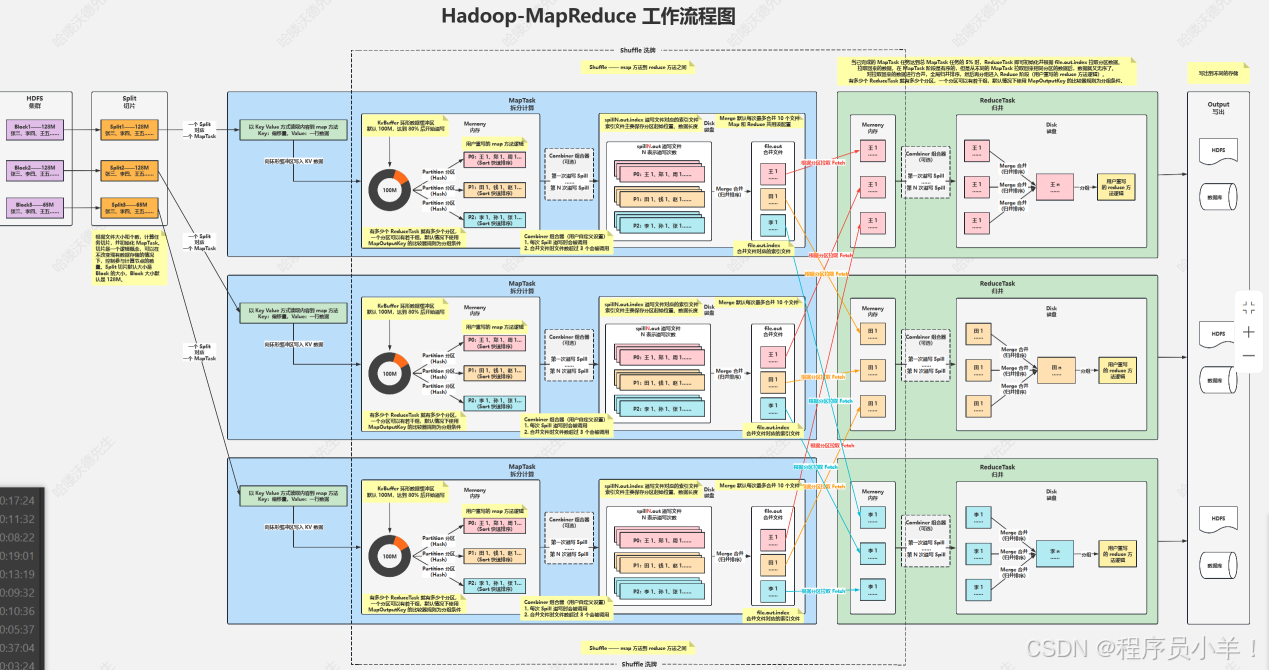
client: 客户端通常指的是用户或者就是我们程序员
Split:切片是一个逻辑概念,在不改变现在数据存储的情况下,可以控制参与计算的节点数目,在通过切片大小可以达到控制计算节点数量的目的,一般切片大小为Block的整数倍 1/2。切片小了可以调用更多的工作节点,节点少了切片大于块大小。(常见大小64,一个块分为两个逻辑块,默认情况下Split切片的大小等于Block的大小) 通常来说一个切片对应一个MapTask。
MapTask: Map任务从所属的切片(Split)中读取数据,每次读取一行 。它会对读取的数据进行处理,通常是将数据转换为键值对的形式 (Map<String,Integer>)临时数据。处理后的键值对会被写入内存缓冲区,等待进一步处理或传输到下一个阶段。
环形缓冲区:这是一个索引两边为零伪环形的数组,可以循环利用这块内存区域,数据循环写到硬盘,不用担心OOM(内存溢出)问题。在内存中构建一个环形数据缓冲区(kvBuffer),默认大小为100M,目的是为了减少数据溢写时map的停止时间,没有缓冲区就需要每次重新申请内存。设置缓冲区的阈值为80%,当缓冲区的数据达到80M开始向外溢写到硬盘。存储的时候块一边写block数据半边写元数据,
分区Partation: 根据Key直接计算出对应的Reduce,分区的数量和Reduce的数量是相等的(hash(key) % partation = num 默认分区的算法是Hash然后取余,Hash算法可以更改)当被溢写到磁盘之前会进行Sort快速排序。
排序Sort : 按照先Partation后Key的顺序排序–>相同分区在一起,相同Key的在一起。溢写Spill :将内存中的数据循环写到硬盘,每次会产生一个80M的文件,如果本次Map产生的数据较多,可能会溢写多个文件。 文件的通常命名为:spillN.out N表示溢写的次数
组合器combiner: 预处理的组件,减轻后面的计算负担,小Reduce。
当数据溢写到磁盘中后会进行Merge合并(归并排序),根据key来合并为file.out文件,此MapTask任务结束等待ReduceTask拉取。
Merge合并:Merge 是为了让传输的文件数量变少,但是网络传输数据量并没有改变,只是减少了网络 IO 次数。合并的是溢写出来的数据,将多个小文件合并成一个大文件,在拉取的过程中减少了IO
拉取Fetch: 将MapTask的临时结果拉取到Reduce节点,一个Reduce对应的多个MapTask。原则相同的Key必须拉取到同一个Reduce节点,一个Reduce节点可以有多个Key。
ReduceTask: 将文件中的数据读取到内存中,一次性将相同的key全部读取到内存中,他其实也有一个缓冲机制,缓冲量是当前内存的70%,当超过就会触发溢写写入到磁盘中,在写入的过程中会进行二级Merge合并将多个溢写的数据合并成为一个分区,最后的结果就是当前Reduce的结果,此时数据量已经合并小了很多,但是如果有多个Reduce任务最后就会有多个reduce计算结果,将这个结果再重复写入HDFS的零时节点转换为ReduceTask直到可以单个节点完成任务。
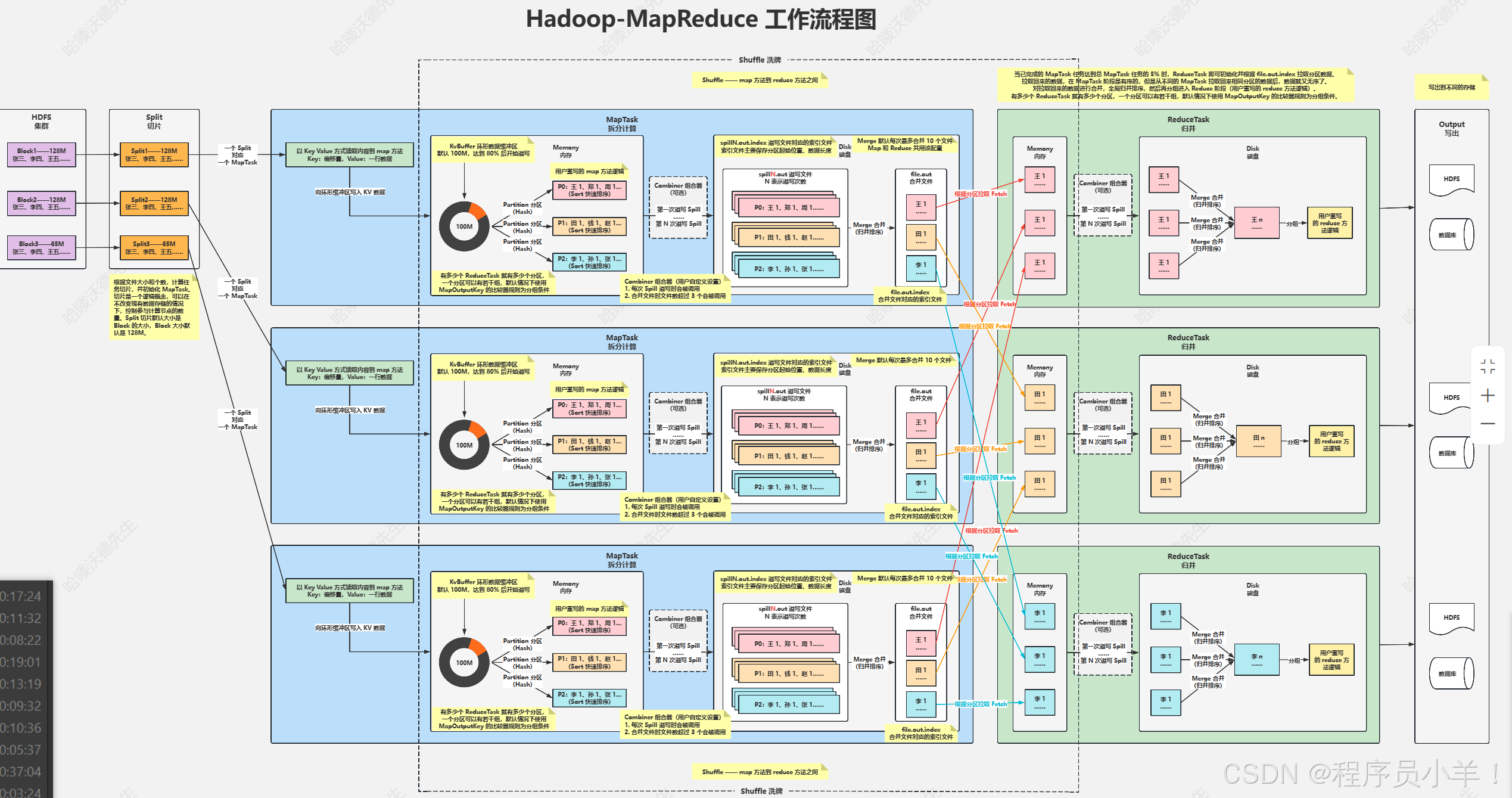
MR任务上传的流程
客户端发送分析的源文件和Jar包上传到hdfs中,首先任务开始的时候会将HDFS集群中的数据块拿出来,根据节点设置的切片大小先切片,不设置默认为128MB,每一个切片都会单独的被MapTask单独计算,先写到缓冲区中,缓冲区默认大小为100M。
切片存储的数据包含数据本体和元数据,通过环形缓冲区,当达到缓冲区大小的80%触发溢写合成一个分区,分区,此时会根据Key做第一次的数据排序,(排序完的数据在这里可以接入一个组合器为下一个在磁盘中的Merge做预处理准备)。溢写出来的数据会包含:分区起始位置,数据长度。溢写数据都准备好后会触发合并文件的操作也就是Merge合并,采用了归并排序,将根据相同的Key的数据合并成一个大文件,此时MapTask任务执行结束(在执行合并的时候的Map算法可以自己重写,也可以在里面加入Combiner组合器)。
开始执行归并操作ReduceTask,将之前在磁盘中的MapTask数据合并写在内存中,注意同一个Key只会在一个ReduceTask下,一个ReduceTask可以处理多个不同的Key数据,当数据达到当前节点内存容量的70%触发一次溢写操作,会将写入到磁盘中,(在此过程中可以插入组合器)在磁盘中合并进行计算,将结果写成一个文件。此时ReduceTask任务已经完成。
但是如图所示当我们有多个ReduceTask节点计算那就有多个计算结果,我们还需要把这个多个规约后的文件存在HDFS中进行临时存储做二次计算,逻辑切片然后转换为MapTask开始下一个周期,直到最后结果被算到可以一个ReduceTask节点可以处理完将数据输出出来,目的地可以是数据库或者HDFS中。
有关ReduceTask节点是什么时候出现的? 当MapTask处理的数据任务量达到5%就会开始生成ReduceTask。
有关为什么MapTask中排序合并后的数据为什么还要在Reduce中排序一次? 因为ReduceTask面对的节点数量是不止一台的所以多个拿过来数据不能保证又是顺序的,这次的操作只需要排序MapTask的文件就可以不是针对数据 KV的。
在合并的时候Merge无论是Map还是Reduce都是最多合并10个溢写出来的文件合并成一个。
Combiner组合器是用户自定义的功能,在每次spill滥用的时候会被调用,默认值是合并文件超过3个,也可以自己设置。
有关shuffle洗牌
在Hadoop MapReduce中,洗牌(Shuffle) 是一个关键步骤,主要用于在Map阶段和Reduce阶段之间传递数据。洗牌过程解决了如何有效地将Map任务的输出传递给相应的Reduce任务的问题。具体来说,它包括三个子过程:分区(Partitioning)、排序(Sorting)和合并(Merging)。
洗牌的作用 : (数据分配)将Map任务的输出数据按键分配给相应的Reduce任务,确保相同键的数据被同一个Reduce任务处理。 (排序) 保证Reduce任务接收到的数据是有序的,便于在Reduce任务中进行高效处理。 (合并) 减少数据传输量,提高数据处理效率,减少网络拥塞。
解决的主要问题:(数据分布和负载均衡) 通过分区函数,将数据均匀地分布到各个Reduce任务,避免单个Reduce任务负载过高。 (排序和合并) 通过排序和合并操作,减少网络传输的数据量,提高整体处理效率。(键的聚合) 确保相同键的数据被聚合到同一个Reduce任务中,便于进行进一步的聚合操作(如求和、平均值等)。
为什么说洗牌是分布式计算的敌人?
首先你要对洗牌是做什么有清楚的认知,他主要发生在Map阶段,磁盘中的逻辑分片数据写入到缓存区的时候开始到Reduce FetchMap写入到内存之后结束。1. 网络开销大: 洗牌阶段需要将大量的数据从一个节点传输到另一个节点,这会产生巨大的网络开销,特别是当数据量很大时,这种开销会显著影响整体性能。2. 磁盘I/O开销大:Map 阶段的输出数据通常会写到本地磁盘,然后再读取进行传输,这会产生大量的磁盘 I/O 操作,影响处理速度。3. 内存开销大: 在处理过程中,需要在内存中维护一定的数据结构来进行排序和合并操作,这对内存资源的消耗较大。4. 数据倾斜问题: 如果某些键的数据量特别大,导致某些 Reduce 任务的数据量明显超过其他任务,会导致负载不均衡,从而影响整个作业的执行时间。
为了解决这个问题我们可以优化我们的算法,避免 压缩中间数据 过多,例如Map阶段中的合并文件的数量可以写一个组合器在合并前根据Key做一次合并。 可以自己写分区函数,确保数据均匀的分布在各个Reduce任务重减少数据倾斜。 增加Reduce工作节点数量让数据分布均匀,最后调整缓冲区的大小改适当大一些。
通过以上优化措施,可以有效减少洗牌阶段的开销,提高 Hadoop MapReduce 作业的整体性能。
结尾:
本课程是一门以电商流量数据分析为核心的大数据实战课程,旨在帮助你全面掌握大数据技术栈的核心组件及其在实际项目中的应用。从零开始,你将深入了解并实践Hadoop、Hive、Spark和Flume等主流技术,为企业级电商流量项目构建一个高可用、稳定高效的数据处理系统。
在课程中,你将学习如何搭建并优化Hadoop高可用环境,熟悉HDFS分布式存储和YARN资源调度机制,为大规模数据存储与计算奠定坚实基础。随后,通过Hive数据仓库的构建与数仓建模,你将掌握如何将原始日志数据进行分层处理,实现数据清洗与结构化存储,从而为后续数据分析做好准备。
借助Spark SQL的强大功能,你将通过实战案例学会快速计算和分析关键指标,如页面浏览量(PV)、独立访客数(UV),以及通过数据比较获得的环比、等比等衍生指标。这些指标将帮助企业准确洞察用户行为和流量趋势,为优化营销策略提供科学依据。
同时,本课程还包含Flume数据采集与ETL入仓的实战模块,教你如何采集实时Web日志数据,并利用ETL流程将数据自动导入HDFS和Hive,确保数据传输和处理的高效稳定。
总体来说,这门课程面向希望提升大数据应用能力的技术人员和企业项目团队,紧密围绕公司电商流量项目的实际需求展开。通过系统的理论讲解与动手实践,你不仅能够构建从数据采集、存储、处理到可视化展示的完整数据管道,还能利用PV、UV、环比、等比等关键指标,全面掌握电商流量数据分析的核心技能。
今天这篇文章就到这里了,大厦之成,非一木之材也;大海之阔,非一流之归也。感谢大家观看本文
