学习triton-第1课 向量加法
跟着文档学习triton
以下是文档中的一个加法案例
import torch
import triton
import triton.language as tlfrom torch import deviceDEVICE = device(type='cuda', index=0)@triton.jit
def add_kernel(x_ptr, y_ptr, output_ptr, n_elements, BLOCK_SIZE: tl.constexpr):pid = tl.program_id(axis=0) # 获取当前程序(核函数实例)的ID,axis=0表示使用1D网格block_start = pid * BLOCK_SIZEoffsets = block_start + tl.arange(0, BLOCK_SIZE)mask = offsets < n_elements # 掩膜,超出范围的元素将不会被加载x = tl.load(x_ptr + offsets, mask=mask) # 加载并行化的数据y = tl.load(y_ptr + offsets, mask=mask)output = x + ytl.store(output_ptr + offsets, output, mask=mask) # 计算的结果储存回def add(x: torch.Tensor, y: torch.Tensor):output = torch.empty_like(x) # 创建一个和 x 一样的张量assert x.device == DEVICE and y.device == DEVICE and output.device == DEVICEn_elements = output.numel() # 获取张量的元素数量(数据长度)# 匿名函数,Triton 提供的向上取整除法函数,用于计算需要多少个块才能覆盖所有元素# 返回一个元组 (计算结果,),表示这是一个 1D 网格(元组中只有一个元素)grid = lambda meta: (triton.cdiv(n_elements, meta['BLOCK_SIZE']), )add_kernel[grid](x, y, output, n_elements, BLOCK_SIZE=1024)return outputif __name__ == '__main__':torch.manual_seed(0) # 初始化种子size = 98432 # 定义数据长度x = torch.rand(size, device=DEVICE)y = torch.rand(size, device=DEVICE)output_torch = x + y # 常规output_triton = add(x, y) # tritonprint(output_torch)print(output_triton)print(f'The maximum difference between torch and triton is 'f'{torch.max(torch.abs(output_torch - output_triton))}')
如果你有C语言的基础,不难发现,这段代码其实就是套了一层python外壳的C语言!
1. 首先我们定义了一个output空张量,用来放置输出结果的。
2. 在加法核函数,我们仍然需要传入一个向量长度n_elements,是不是和C语言很像?所以我们需要利用x或者output来获取长度。
3. 重点之一grid,它是一个匿名函数,用来计算每个计算需要多少个并行的内核实例(块)才能处理完所有数据。这里简单讲一下,GPU运算之所以快,就是因为,它可以多线程并行化处理数据,所以我们会将数据切分成多块,每块去执行相同的函数,最后再合并成完整的结果返回。
举个例子,我有个一维向量数据,长度2049,BLOCK_SIZE=1024,那么2049除以1024向上取整为3,所以我需要分配3个内核实例去处理这个数据,所以我们的匿名函数执行后的实际结果就是(3, ),但是我们不直接传结果,而是传匿名函数,扔给更底层去执行。
4. 注意传入核函数的变量,看上去像是把整个x, y, output传进去了,实际上是这个函数处理的时候都是取他们的第一个数据的地址,也就是指针!
add_kernel[grid](x, y, output, n_elements, BLOCK_SIZE=1024)没学过C语言的同学可以这样理解一个长度为2049的向量:就好比2049个人并排站立,每个人脚下都一一对应独立的一块砖,那这块砖的编号就是地址,而人就是每个数据本身。而传递变量的是时候,由于地砖编号都是连着的,我们只需要知道第一块地砖这个首地址就ok了。
所以也就不难理解为什么在核函数中的传参要写成*_ptr这样了:
def add_kernel(x_ptr, y_ptr, output_ptr, n_elements, BLOCK_SIZE: tl.constexpr)5. 在核函数内部,先获取一个核函数实例的pid,
具体来说:
- 假设通过
grid = lambda meta: (triton.cdiv(n_elements, meta['BLOCK_SIZE']), )计算出的网格大小为N(即需要N个内核实例并行处理) - 那么每个内核实例会得到一个唯一的
pid,取值范围是0, 1, 2, ..., N-1
那么按照上面的案例,我们获取的pid就是0, 1, 2
所以每个计算实例都从向量哪个索引开始呢:
block_start = pid * BLOCK_SIZE0 * BLOCK_SIZE = 0
1 * BLOCK_SIZE = 1024
2 * BLOCK_SIZE = 2048
有了block_start接着计算每个数据的索引:
offsets = block_start + tl.arange(0, BLOCK_SIZE)所以offsets是
[0, 1, ..., 1023]
[1024, 1, ..., 2047]
[2048, 2049, ..., 4095]
由于有数据长度限制,所以mask第三个块向量是[True, False, False, ....]
mask = offsets < n_elements6. 将数据加载到实例中计算时,会参考offsets对原数据的指针做偏移,如此一来,你可以理解为数据都被按照offsets合理的分配到了3个线程中做运算,
x = tl.load(x_ptr + offsets, mask=mask)下面的步骤,实际就是发生在3个独立的计算单元中。
output = x + y最后再将output结果按照output_ptr指针装回去
tl.store(output_ptr + offsets, output, mask=mask)以上就是加法算子的解释。
我们对其做基准测试
import torch
import triton
from torch import devicefrom val import addDEVICE = device(type='cuda', index=0)
@triton.testing.perf_report(triton.testing.Benchmark(x_names=['size'], # Argument names to use as an x-axis for the plot.x_vals=[2**i for i in range(12, 28, 1)], # Different possible values for `x_name`.x_log=True, # x axis is logarithmic.line_arg='provider', # Argument name whose value corresponds to a different line in the plot.line_vals=['triton', 'torch'], # Possible values for `line_arg`.line_names=['Triton', 'Torch'], # Label name for the lines.styles=[('blue', '-'), ('green', '-')], # Line styles.ylabel='GB/s', # Label name for the y-axis.plot_name='vector-add-performance', # Name for the plot. Used also as a file name for saving the plot.args={}, # Values for function arguments not in `x_names` and `y_name`.))def benchmark(size, provider):x = torch.rand(size, device=DEVICE, dtype=torch.float32)y = torch.rand(size, device=DEVICE, dtype=torch.float32)quantiles = [0.5, 0.2, 0.8]if provider == 'torch':ms, min_ms, max_ms = triton.testing.do_bench(lambda: x + y, quantiles=quantiles)if provider == 'triton':ms, min_ms, max_ms = triton.testing.do_bench(lambda: add(x, y), quantiles=quantiles)gbps = lambda ms: 3 * x.numel() * x.element_size() * 1e-9 / (ms * 1e-3)return gbps(ms), gbps(max_ms), gbps(min_ms)benchmark.run(print_data=True, show_plots=True)得到结果的对比,总体来说triton和torch原生的加法算子还是不分伯仲的。
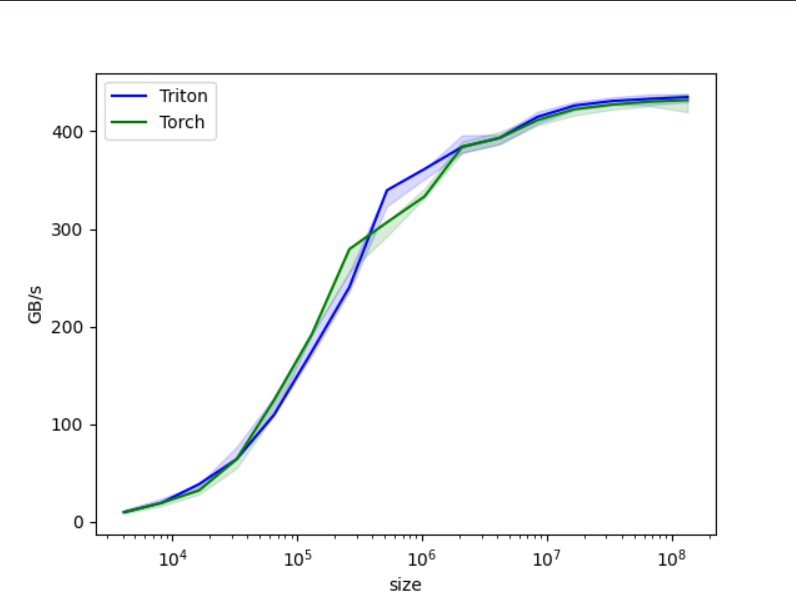
明天讲一个二维矩阵的加法。