NLP项目实战 | Word2Vec对比Glove进行词类比测试
Word2Vec 是一种 “用词语的‘朋友圈’(上下文)快速给词语生成‘语义身份证’(低维向量)” 的技术,让机器能通过向量距离 “感知” 词语的语义关联,是自然语言处理从 “机械匹配” 走向 “语义理解” 的关键一步,Word2Vec有两种主要架构: 连续词袋模型(Continuous Bag-of-Words) 和 skip-gram 模型(跳字模型)
GloVe 是 2014 年斯坦福大学提出的,因为当时学词向量的方法有两个 “短板”:
- Word2Vec(比如 Skip-gram):像 “看局部对话”—— 只关注句子里相邻的词(比如 “猫喜欢鱼” 中 “猫” 和 “鱼” 挨着),但忽略了 “全局规律”(比如整个语料中 “猫” 和 “动物” 其实经常一起出现)。
- LSA(潜在语义分析):像 “统计全局报表”—— 只算所有文本中词和词一起出现的总次数,但不懂 “具体关系”(比如算到 “猫” 和 “动物” 共现 100 次,却不知道 “猫属于动物”)。GloVe 的诞生就是为了 “结合两者优势”:既看局部句子里的搭配,又算全局的共现规律。
下面我们看一下代码实现
1、准备示例语料库
import gensim
from gensim.models import Word2Vec,FastText,KeyedVectorssentences = [["natural", "language", "processing", "is", "fascinating"],["word", "embeddings", "capture", "semantic", "meaning"],["king", "queen", "man", "woman", "royalty"],["similar", "words", "have", "close", "vectors"],["machine", "learning", "models", "learn", "patterns"]
]2、训练词向量模型
2.1、Word2Vec模型
word2vec_model = Word2Vec(sentences = sentences,vector_size = 100, #词向量维度window=5,#上下文窗口min_count=1, #最小词频workers=4, #并行线程epochs= 50 #训练轮次
)# 保存模型,后续方便直接加载使用,不用多次加载, 后续有使用
word2vec_model.save("word2vec_model.bin")2.2、FastText模型(支持子词)
fasttext_model = FastText(sentences = sentences,vector_size = 100, #词向量维度window=5,#上下文窗口min_count=1, #最小词频workers=4, #并行线程epochs= 50, #训练轮次min_n= 3,#子词最小长度max_n= 6 #子词最大长度
)2.3、打印模型相关信息
print(f"\nWord2Vec模型信息:词汇量:{len(word2vec_model.wv)}\n向量维度:{word2vec_model.vector_size}\n训练轮次:{word2vec_model.epochs}")
print(f"\nFastText模型信息:词汇量:{len(fasttext_model.wv)}\n向量维度:{fasttext_model.vector_size}\n训练轮次:{fasttext_model.epochs}")
Word2Vec模型信息:词汇量:25
向量维度:100
训练轮次:50FastText模型信息:词汇量:25
向量维度:100
训练轮次:503、词向量可视化函数
import numpy as np
from sklearn.decomposition import PCA
from sklearn.manifold import TSNEdef visualize_vectors(model, words, method='pca'):vector_model = model.wv if hasattr(model, 'wv') else model #通过hasattr检查模型是否包含wv属性,如果有则使用model.wv(完整模型),否则直接使用model(仅KeyedVectors对象)vectors = [vector_model[word] for word in words]vectors = np.array(vectors) #转换为numpy数组#降维到二维if method== 'pca':#pca降维(线性,保持全局结构)reducer = PCA(n_components = 2)title = 'PCA'else:#t-SNE降维(非线性,关注局部结构)reducer = TSNE(n_components = 2, perplexity = min(5, len(words)-1),learning_rate = 200, random_state = 42)title = 't-SNE'result = reducer.fit_transform(vectors)return result,title4、散点图可视化
import matplotlib.pyplot as plt
# 设置中文字体
plt.rcParams['font.sans-serif'] = ['SimHei'] # 使用黑体
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题def plot_vectors(result, words, title):#创建散点图plt.figure(figsize = (10,6))plt.scatter(result[:, 0], result[: , 1])#添加标签for i,word in enumerate(words):plt.annotate(word, xy = (result[i,0], result[i,1]))plt.title(title)plt.show()5、示例词合并可视化(PCA和t-SNE对比)
#测试数据集
test_words = ["king", "queen", "man", "woman", "royalty"]fig, (ax1,ax2) = plt.subplots(1,2,figsize =(16,6))
fig.suptitle('词向量可视化对比:PCA vs t-SNE', fontsize=16)#PCA降维
result_pca, _ = visualize_vectors(word2vec_model, test_words, method = 'pca')
ax1.set_title('PCA降维(保持全局结构)')
ax1.scatter(result_pca[:, 0], result_pca[: , 1])for i, word in enumerate(test_words):ax1.annotate(word, xy = (result_pca[i,0], result_pca[i,1]))#t_SNE降维
# 加载Word2Vec模型
loaded_w2v = Word2Vec.load("word2vec_model.bin")result_tsne, _ = visualize_vectors(loaded_w2v, test_words, method = 'tsne')
ax2.set_title('t-SNE降维(保持局部结构)')
ax2.scatter(result_tsne[:, 0], result_tsne[: , 1])for i, word in enumerate(test_words):ax2.annotate(word, xy = (result_tsne[i,0], result_tsne[i,1]))plt.tight_layout(rect=[0,0,1,0.95]) #调整布局
plt.show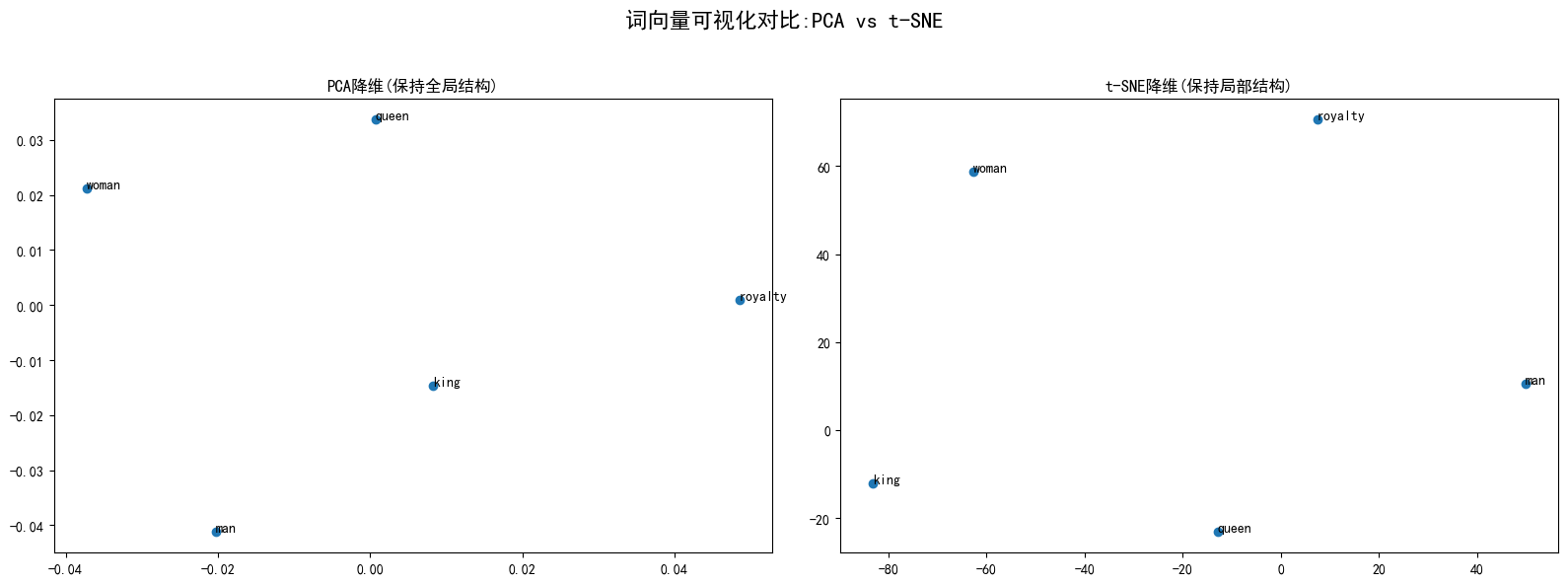
6、词类比测试
def word_analogy_test(model, a,b,c):try:vector_model = model.wv if hasattr(model, 'wv') else model#使用most_similar方法计算词向量,其中b和c作为正向词汇,a作为负向词汇#返回最相似的3个词作为类比结果result = vector_model.most_similar(positive=[b,c], negative=[a], topn=3) print(f"\n词类比测试:{a}:{b} :: {c}:? \n 结果:{result}")except KeyError as e:print(f"词类比测试失败,可能是词汇表中缺少某些词: {e}")word_analogy_test(word2vec_model, "man", "woman", "king") #效果差
词类比测试:man:woman :: king:? 结果:[('words', 0.22533772885799408), ('close', 0.15693038702011108), ('embeddings', 0.1550011932849884)]7、加载预训练Glove模型(若存在)
import os
from gensim.scripts.glove2word2vec import glove2word2vecdef load_glove_model(glove_file = 'glove.6B.100d.txt', convert = True):#script_dir= os.path.dirname(os.path.abspath(__file__)) #Pycharm写法script_dir= os.getcwd() #jupyter写法,不识别__file__print(f"script_dir:{script_dir}")glove_path = os.path.join(script_dir, glove_file)if not os.path.exists(glove_path):print(f"未找到Glove模型文件:{glove_path}")return None#转换为Word2Vec格式w2v_path = f"{glove_path}.w2v.txt"if convert and not os.path.exists(w2v_path):print(f"正在将Glove转换为Word2Vec格式:{w2v_path}")glove2word2vec(glove_path, w2v_path)#加载模型try:path_to_use = w2v_path if convert else glove_pathprint(f"正在加载Glove模型: {path_to_use}")model = KeyedVectors.load_word2vec_format(path_to_use, binary= False)return modelexcept Exception as e:print(f"加载Glove模型失败:{e}")return Noneglove_model = load_glove_model()
script_dir:/Users/thinkinspure/PycharmProjects/MyPython/ai/Week4
正在加载Glove模型: /Users/thinkinspure/PycharmProjects/MyPython/ai/Week4/glove.6B.100d.txt.w2v.txt8、Glove模型可视化词向量
if glove_model:glove_words= [w for w in test_words if w in glove_model]if len(glove_words) >= 3: #确保有足够的词进行可视化fig, (ax1,ax2) = plt.subplots(1,2,figsize =(16,6))fig.suptitle('Glove词向量可视化对比:PCA vs t-SNE', fontsize=16)#PCA降维result_pca, _ = visualize_vectors(glove_model, glove_words, method = 'pca')ax1.set_title('Glove - PCA降维(保持全局结构)')ax1.scatter(result_pca[:, 0], result_pca[: , 1])for i, word in enumerate(glove_words):ax1.annotate(word, xy = (result_pca[i,0], result_pca[i,1]))#t_SNE降维result_tsne, _ = visualize_vectors(glove_model, glove_words, method = 'tsne')ax2.set_title('Glove - t-SNE降维(保持局部结构)')ax2.scatter(result_tsne[:, 0], result_tsne[: , 1])for i, word in enumerate(glove_words):ax1.annotate(word, xy = (result_tsne[i,0], result_tsne[i,1]))plt.tight_layout(rect=[0,0,1,0.95]) #调整布局plt.show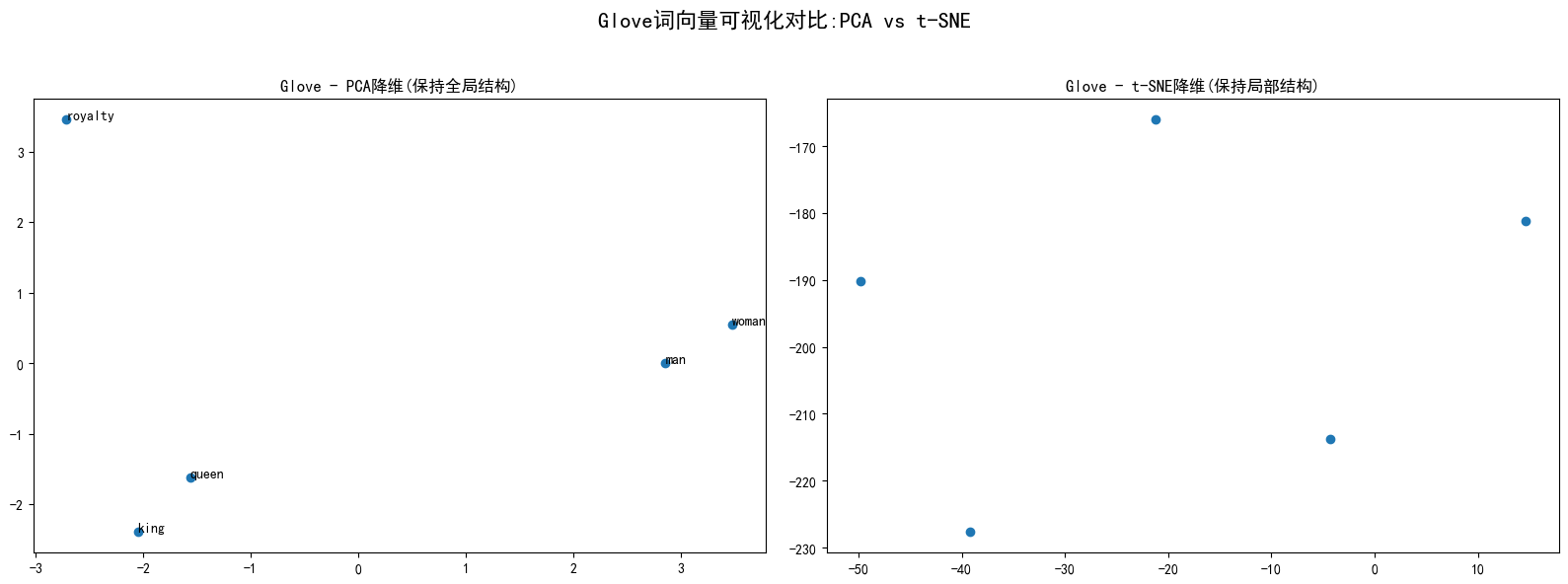
9、Glove模型词类比测试
word_analogy_test(glove_model, "man", "woman", "king")
词类比测试:man:woman :: king:? 结果:[('queen', 0.7698540687561035), ('monarch', 0.6843380928039551), ('throne', 0.6755736470222473)]