必知必会:词向量构建方法(Word2Vec、ELMo、BERT)、聚类性质的句子向量构建方法(SBERT、SimCSE )
词向量
词向量(Word Embedding)是将自然语言中的词汇映射到低维连续向量空间的技术,其核心目标是让向量的语义关系与词汇的实际语义关联(如同义、反义、上下位等)保持一致。构建词向量的方法经历了从基于统计到基于深度学习的演进,不同方法在语义表达能力、计算效率和适用场景上存在显著差异。
目前,比较流行的词向量表示方法有很多种,包括 word2vec、FastText、GloVe 等。相对于词袋模型,词向量的优点是能够捕捉到单词的语义信息,且有比较好的聚类表现。最简单的方案是将所有的词向量相加求平均,得到句子向量,进而通过计算距离的方法计算相似度。假设句子中第 iii 个词的向量为 EMBi\text{EMB}_iEMBi,那么句子 SSS 的表征为 S=∑i=0nEMBinS = \sum_{i=0}^{n} \frac{\text{EMB}_i}{n}S=∑i=0nnEMBi。
- 优点:词向量在大量语料中通过半监督学习学到了语义,并且不需要额外训练,方法简单、快速且高效
- 缺点:首先,未考虑到每个单词对应不同的重要性和语序问题;其次,长文本容易出现语义漂移的问题;最后,对分词和预处理语料要求比较高。
此外简单地修改每个词的权重使其不同,通过计算每个词的 TF-IDF 值来表达各单词的权重,然后在构建句子向量时,按词进行加权计算。假设句子中每个词的向量为 EMBiEMB_iEMBi,对应的权重为 tfidfi\text{tfidf}_itfidfi,那么句子 SSS 的表征为 S=∑i=0nEMBi×tfidfinS = \sum_{i=0}^{n} \frac{EMB_i \times \text{tfidf}_i}{n}S=∑i=0nnEMBi×tfidfi。这种方法考虑到了每个词的重要性权重,在相对较短的文本中表现较好。
以上两种方法都是先把词向量构建为句子向量,然后再通过计算距离的方法计算句子的相似度。这在长句子上会存在语义漂移的问题,尽管有加权的方式,但是与直接度量两个文本相比仍然会损失一定的信息量。下面将详细说说各类方法的优缺点。
一、词向量构建方法分类与详细介绍
根据技术原理,词向量构建方法可分为三大类:传统统计方法、浅层神经网络方法和预训练语言模型方法。以下逐一详解其核心思想、实现流程、优缺点及代表模型。
第一类:传统统计方法(基于共现与矩阵分解)
这类方法的核心逻辑是:“一个词的含义由其所处的上下文决定”(Distributional Hypothesis,分布假说)。通过统计词汇在文本中的共现频率,构建共现矩阵,再通过矩阵分解降低维度,得到词向量。
1. 代表方法:共现矩阵(Co-occurrence Matrix)
-
核心思想:
- 定义“上下文窗口”(如窗口大小为2,即某个词的左右各2个词为其上下文);
- 统计语料中所有词汇对(目标词-上下文词)的共现次数,构建
V×V的共现矩阵(V为词汇表大小); - 由于共现矩阵维度极高(如
V=10万时,矩阵维度为10万×10万),需通过奇异值分解(SVD) 对矩阵降维,取分解后维度较低的矩阵作为词向量。
-
示例:
假设语料为“猫喜欢吃鱼,狗喜欢吃肉”,窗口大小为1:- 共现矩阵(简化版)中,“喜欢”与“猫”“鱼”“狗”“肉”的共现次数均为1;
- 对该矩阵做SVD降维后,“猫”“狗”的向量会更接近(均为动物),“鱼”“肉”的向量会更接近(均为食物)。
-
优缺点:
优点 缺点 原理直观,可解释性强(共现次数直接反映语义关联) 计算复杂度极高(SVD对 V×V矩阵的时间复杂度为O(V³))能捕捉基础语义关联(如类别相似性) 维度灾难(词汇表增大时,矩阵存储和计算成本急剧上升) 无训练过程,直接通过统计和矩阵分解生成 无法处理低频词(低频词共现次数少,向量语义不准确)
第二类:浅层神经网络方法(基于预测的端到端训练)
为解决传统统计方法的“维度灾难”和“计算复杂”问题,研究者提出基于预测的浅层神经网络模型——核心是通过“预测上下文”或“预测目标词”的任务,端到端训练出低维词向量。这类方法是词向量技术的“里程碑”,代表模型为Word2Vec、GloVe。
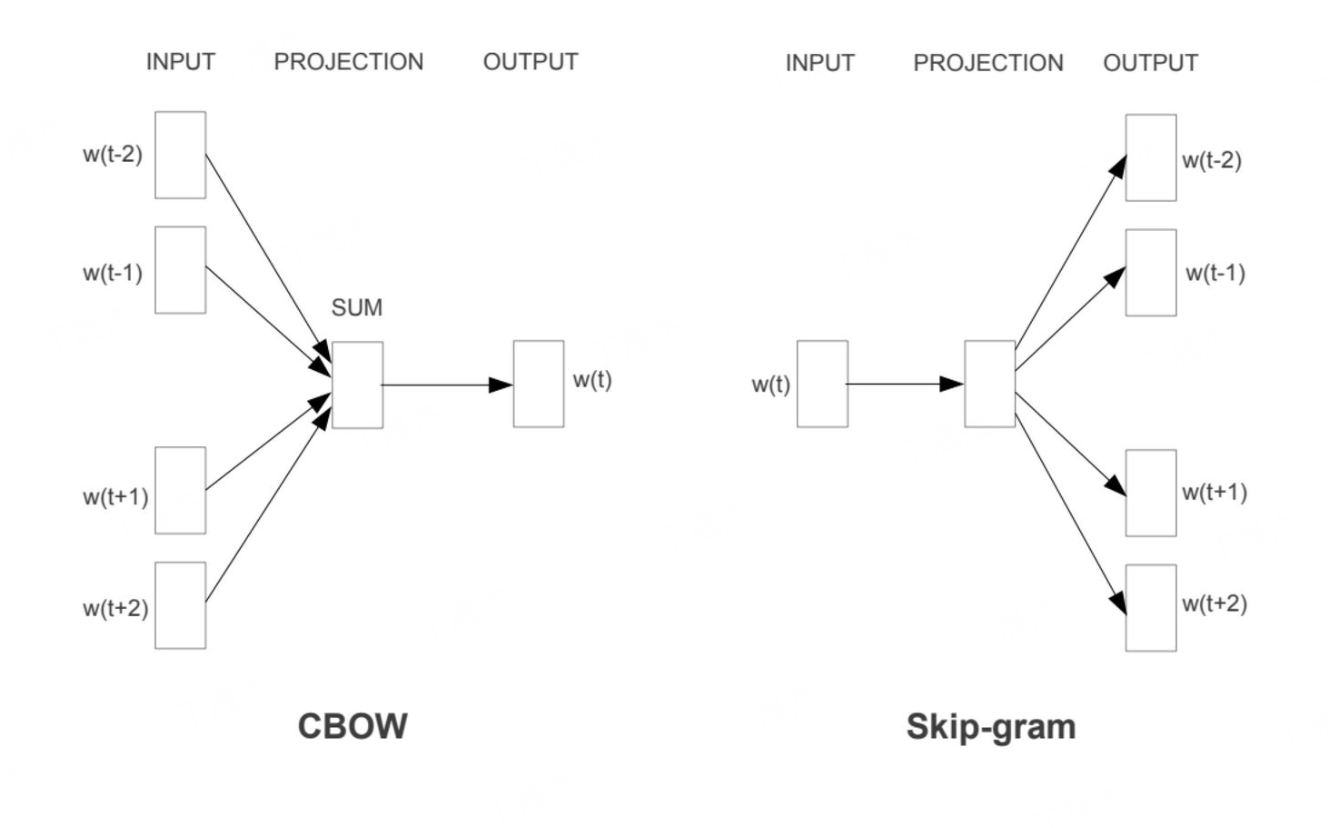
1. Word2Vec(2013年,Google)
Word2Vec包含两种核心模型:CBOW(Continuous Bag-of-Words,连续词袋模型) 和Skip-gram(连续Skip-gram模型),二者均通过“输入层-隐藏层-输出层”的浅层神经网络训练。
-
(1)CBOW模型:通过上下文预测目标词
- 流程:
- 输入:上下文词的one-hot向量(如窗口大小为2,输入2个上下文词的one-hot向量);
- 隐藏层:将所有上下文词的向量(从输入层权重矩阵
W中提取)取平均,得到隐藏层向量(无激活函数); - 输出层:通过softmax函数计算“每个词汇作为目标词”的概率,目标是让真实目标词的概率最大;
- 训练:通过反向传播优化权重矩阵
W,最终W的每一行即为对应词汇的词向量(维度=隐藏层节点数,通常为50-300维)。
- 特点:对高频词更友好(上下文词出现次数多,平均向量更稳定),训练速度快。
- 流程:
-
(2)Skip-gram模型:通过目标词预测上下文词
- 流程:
- 输入:目标词的one-hot向量;
- 隐藏层:从输入层权重矩阵
W中提取目标词的向量(无激活函数,直接传递到隐藏层); - 输出层:通过softmax函数计算“每个词汇作为上下文词”的概率,目标是让真实上下文词的概率最大;
- 训练:同样优化权重矩阵
W,W的行向量即为词向量。
- 特点:对低频词和罕见词更友好(目标词即使低频,也能通过预测上下文学习到有效向量),语义表达更精准,但训练速度比CBOW慢。
- 流程:
-
优化技巧:
- 为解决softmax输出层计算量大(
O(V))的问题,Word2Vec引入负采样(Negative Sampling) 和层次softmax(Hierarchical Softmax):- 负采样:每次训练仅更新真实目标词(正样本)和少量随机选取的负样本(非目标词)的权重,将计算量从
O(V)降至O(k)(k通常为5-20); - 层次softmax:将词汇表构建为霍夫曼树,输出层概率计算转化为“从根节点到叶子节点的路径概率乘积”,计算量降至
O(logV)。
- 负采样:每次训练仅更新真实目标词(正样本)和少量随机选取的负样本(非目标词)的权重,将计算量从
- 为解决softmax输出层计算量大(
-
优缺点:
优点 缺点 计算效率高(浅层网络+负采样/层次softmax,支持大规模语料) 静态词向量(一个词仅对应一个向量,无法处理多义词,如“苹果”既指水果也指公司) 语义表达能力强(能捕捉复杂语义关系,如“国王-男人+女人=女王”) 依赖局部上下文(仅考虑窗口内的词,忽略长距离语义关联) 维度低(50-300维,便于后续任务使用) 对语序不敏感(CBOW和Skip-gram均不考虑上下文词的顺序)
2. GloVe(Global Vectors for Word Representation,2014年,斯坦福)
GloVe是“统计方法”与“神经网络方法”的融合——既利用共现矩阵的全局统计信息,又通过神经网络的端到端训练优化词向量,解决了Word2Vec仅依赖局部上下文的问题。
-
核心思想:
- 构建“词-词共现计数矩阵
X”,其中X_ij表示词i作为词j上下文的共现次数; - 定义“词
i对词j的条件概率P_ij = X_ij / X_i”(X_i是词i的总共现次数),语义相似的词,其P_ij分布应相似; - 设计损失函数:最小化
(w_i + w_j + b_i + b_j - logX_ij)^2 * f(X_ij),其中w_i是词i的向量,b_i是偏置,f(X_ij)是权重函数(降低低频共现的影响); - 训练后,词向量可取
w_i或w_i + w_j(对称设计,词i作为目标词和上下文词的向量一致)。
- 构建“词-词共现计数矩阵
-
优缺点:
优点 缺点 融合全局统计信息,语义准确性优于Word2Vec(尤其在类比任务中) 仍为静态词向量,无法处理多义词 训练稳定(基于全局统计,避免局部上下文的随机性) 训练前需构建共现矩阵,对超大规模语料的存储压力较大
第三类:预训练语言模型方法(基于深层Transformer的动态词向量)
2017年后,随着Transformer架构的提出,词向量技术进入动态词向量时代——词向量不再固定,而是根据其在句子中的上下文语境动态生成(即“上下文相关的词向量,Contextualized Word Embedding”),能完美解决多义词和长距离语义关联问题。代表模型为ELMo、BERT、GPT。
1. ELMo(Embeddings from Language Models,2018年,Allen Institute)
ELMo是首个大规模应用的上下文相关词向量模型,基于双向LSTM(Bi-LSTM) 构建。
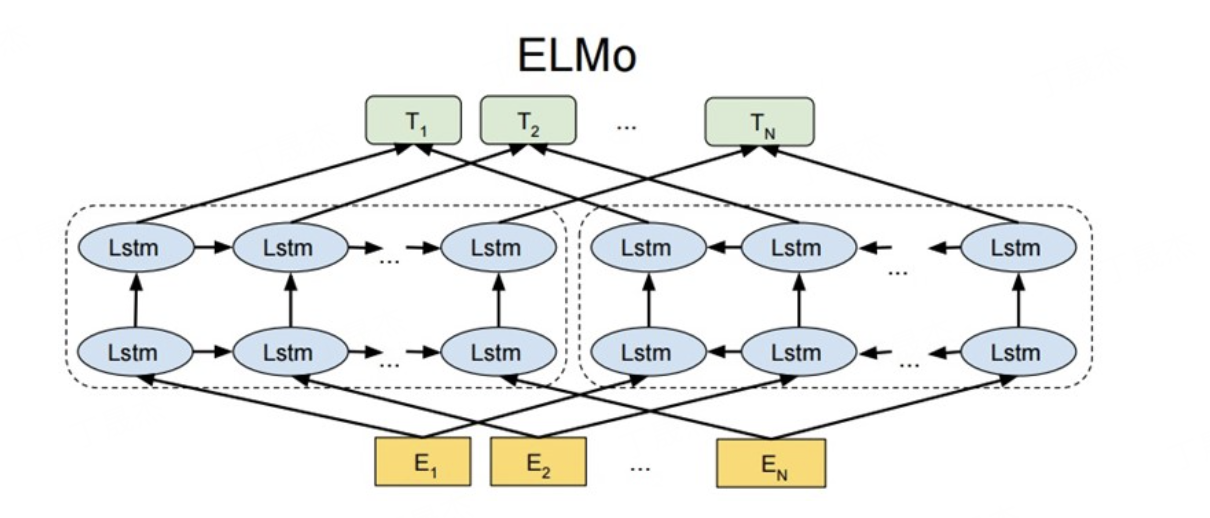
-
核心思想:
- 预训练阶段:训练一个双向LSTM语言模型(前向LSTM预测下一个词,后向LSTM预测上一个词);
- 词向量生成:对于句子中的每个词,取LSTM各层输出的加权和作为其动态词向量(底层捕捉语法信息,高层捕捉语义信息);
- 微调阶段:将预训练的ELMo向量作为下游任务(如文本分类、问答)的输入特征,联合微调模型参数。
-
示例:
- 句子1:“我吃了一个苹果(水果)”——ELMo为“苹果”生成与“食物”相关的向量;
- 句子2:“我用苹果(公司)手机”——ELMo为“苹果”生成与“科技产品”相关的向量。
-
优缺点:
优点 缺点 动态词向量,解决多义词问题 基于LSTM,并行计算能力弱(无法处理超长篇文本,训练速度慢) 捕捉双向上下文信息(前向+后向) 语义建模能力有限(LSTM对长距离依赖的捕捉不如Transformer)
2. BERT(Bidirectional Encoder Representations from Transformers,2018年,Google)
BERT是基于Transformer Encoder的双向预训练模型,彻底改变了词向量的语义表达能力,至今仍是自然语言处理(NLP)的基础模型之一。
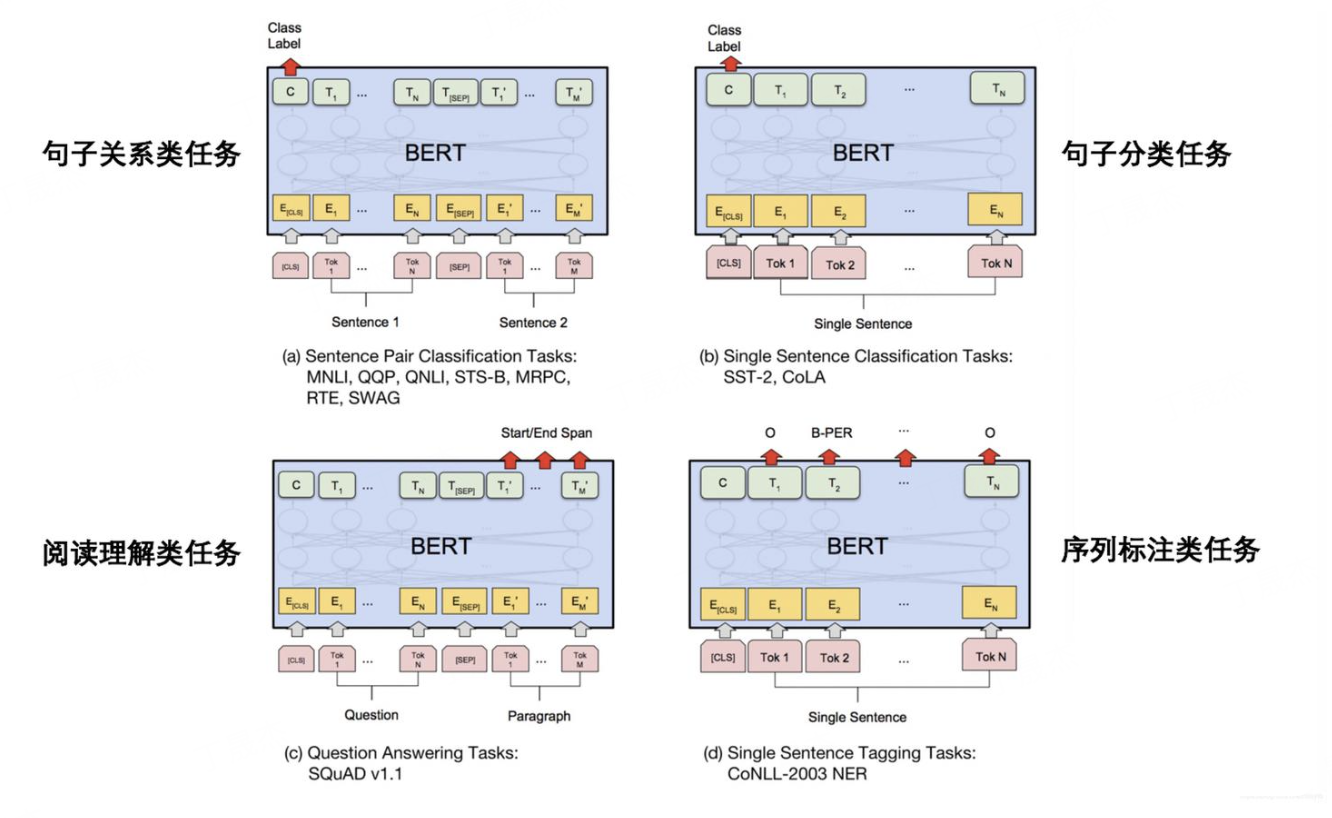
-
核心思想:
- 架构:采用多层Transformer Encoder(无Decoder,仅用于编码上下文),利用自注意力机制(Self-Attention)捕捉词与词之间的长距离语义关联;
- 预训练任务:
- Masked Language Model(MLM,掩码语言模型):随机掩盖句子中15%的词(如将“我喜欢吃苹果”改为“我喜欢吃[MASK]”),让模型预测被掩盖的词,强制模型学习双向上下文;
- Next Sentence Prediction(NSP,下一句预测):输入两个句子,让模型判断第二个句子是否是第一个句子的真实下一句,学习句子级别的语义关联;
- 词向量生成:
- 输入层:每个词的向量由“词嵌入(Token Embedding)+ 位置嵌入(Position Embedding,捕捉语序)+ 句子嵌入(Segment Embedding,区分不同句子)”组成;
- 输出层:取Transformer Encoder顶层的向量作为词的动态向量,能同时捕捉词法、句法和语义信息。
-
优缺点:
优点 缺点 双向语义建模,语义表达能力远超Word2Vec/GloVe 模型参数量大(基础版110M,大型版340M),训练成本高 自注意力机制,高效捕捉长距离语义关联 推理速度较慢(相比浅层模型) 通用性强,通过微调可适配几乎所有NLP任务(分类、问答、翻译等) 对小样本数据敏感(需足够数据微调)
3. GPT(Generative Pre-trained Transformer,2018年,OpenAI)
GPT是基于Transformer Decoder的单向预训练模型,核心用于生成式任务(如文本生成),但其词向量也具备较强的上下文相关性。
-
核心思想:
- 架构:采用多层Transformer Decoder(带掩码自注意力,仅关注当前词之前的上下文);
- 预训练任务:因果语言模型(Causal Language Model,CLM)——给定前
k个词,预测第k+1个词,强制模型学习单向语义依赖; - 词向量生成:通过Decoder的自注意力层,生成基于前文的动态词向量,更适合生成式场景(如续写句子)。
-
与BERT的对比:
维度 BERT GPT 架构 Transformer Encoder(双向) Transformer Decoder(单向) 预训练任务 MLM + NSP(双向预测) CLM(单向预测) 适用场景 理解类任务(分类、问答、命名实体识别) 生成类任务(文本生成、对话、摘要) 语义表达 双向上下文,语义更全面 单向上下文,生成连贯性更强
二、哪种方法能更好地表达句子的语义信息?
判断“更好的句子语义表达”,核心标准是:能否捕捉词的多义性、长距离语义关联、语序信息和句子级语义逻辑。综合来看,基于深层Transformer的预训练语言模型(尤其是BERT及其变体) 是目前最优选择,具体原因如下:
1. 从“词向量”到“句子向量”的本质差异
传统方法(Word2Vec/GloVe)生成的是静态词向量,句子语义需通过“词向量平均/拼接”等简单方式组合——这种方式存在致命缺陷:
- 忽略语序(如“猫抓狗”和“狗抓猫”的词向量平均结果相同,但语义完全相反);
- 无法处理多义词(一个词仅一个向量,无法区分不同语境下的含义);
- 丢失长距离关联(如“小明昨天买的那本书,他很喜欢”中,“他”与“小明”的关联无法通过词向量平均捕捉)。
而预训练语言模型(BERT/ELMo)生成的是动态词向量,句子语义通过“多层Transformer的自注意力机制”直接建模:
- 自注意力机制可计算句子中任意两个词的关联权重(如“他”的注意力会重点指向“小明”);
- 位置嵌入(Position Embedding)明确捕捉语序信息;
- 动态向量为多义词生成不同向量,精准匹配语境。
2. BERT及其变体(如RoBERTa、ALBERT)是当前“句子语义表达”的最优解
BERT相比其他方法,在句子语义表达上的核心优势的:
- 双向语义建模:MLM任务强制模型同时关注词的左、右上下文,句子语义理解更全面(如“我在银行(金融机构)取钱”和“我在银行(河边)钓鱼”,BERT能精准区分“银行”的含义);
- 长距离语义捕捉:Transformer的自注意力机制可跨越句子中的任意距离,高效建模“主谓宾”“修饰语-中心词”等长距离关系(如“在拥挤的地铁上,那个穿红色外套的女孩捡到了我丢失的钱包”,BERT能明确“捡到”的主语是“女孩”,宾语是“钱包”);
- 句子级语义关联:NSP任务(或后续RoBERTa的Sentence Order Prediction任务)让模型学习句子之间的逻辑关系(如因果、转折),更适合处理段落级语义。
三、总结
词向量构建方法的演进本质是“从静态到动态、从局部到全局、从浅层到深层”的升级:
- 传统统计方法(共现矩阵+SVD):仅适用于小规模语料,语义表达能力弱;
- 浅层神经网络方法(Word2Vec/GloVe):适合中大规模语料,能捕捉基础语义,但无法处理多义和长距离关联;
- 预训练语言模型(BERT/ELMo/GPT):基于深层Transformer,生成动态词向量,能精准捕捉多义性、语序和长距离语义,是当前句子语义表达的最优方案,其中BERT及其变体(RoBERTa、ALBERT)在理解类任务中表现最佳,GPT系列在生成类任务中更具优势。
2.如何使用 BERT 构建有聚类性质的句子向量?
有聚类性质的句子向量蕴含着整个句子(文档)的信息,有助于进行基于语义相似性的召回检索。实践中我们使用类似编码器的模型来创建有聚类性质的句子向量。
要分析句子向量表征的效果,通常可以使用对齐性(alignment)和均匀性(uniformity)作为评估指标。
对齐性:语义相近的句子的表征应该尽量接近。均匀性:语义不相近的句子的表征在超空间中分布均匀。
满足这两种聚类特点的句子向量表征就是良好的语义表征。
原始 BERT 存在的问题
BERT 本身是为 token 级任务设计的(如分词、命名实体识别),输出的是每个 token 的向量,在进行掩码语言模型(Masked Language Model,MLM)的预训练任务以及下一个句子预测(Next Sentence Prediction,NSP)任务时,原始 BERT 考虑的主要是如何让模型掌握与语言相关的知识。这些任务的损失设计也是取 [CLS] 单个词元的隐藏状态来进行分类任务。这些训练任务会导致 BERT 产生的句子向量在向量空间中仅占据比较狭窄的部分,不具备良好的分散性,从而无法有效建模重要的语义信息。
为了解决原始 BERT 产生的句子向量在向量空间中的各向异性问题,引入了对比学习(contrastive learning)的相关方法来增强 BERT 的语义感知能力。一些常见的模型在sentence_transformers 中已有成熟的实现,可以直接使用。它们的共同特点是设计损失函数来拉近正例(句意相近的句子)之间的距离,同时拉远负例之间的距离,使得不同语义的句子向量在向量空间中的分布较为均匀。下面以两个经典的模型为例,介绍构建有聚类性质的句子向量的基本思想。
SBERT
- Sentence-BERT (SBERT):SBERT 在原始 BERT 的基础上进行了微调,通过加入表征向量之差来表示两个句子向量之间的距离,后面接一层分类器来预测这两个向量是否有相近的句意。下图展示了 SBERT 在训练阶段和推理阶段的计算方式,左右两个模型共享同样的参数。
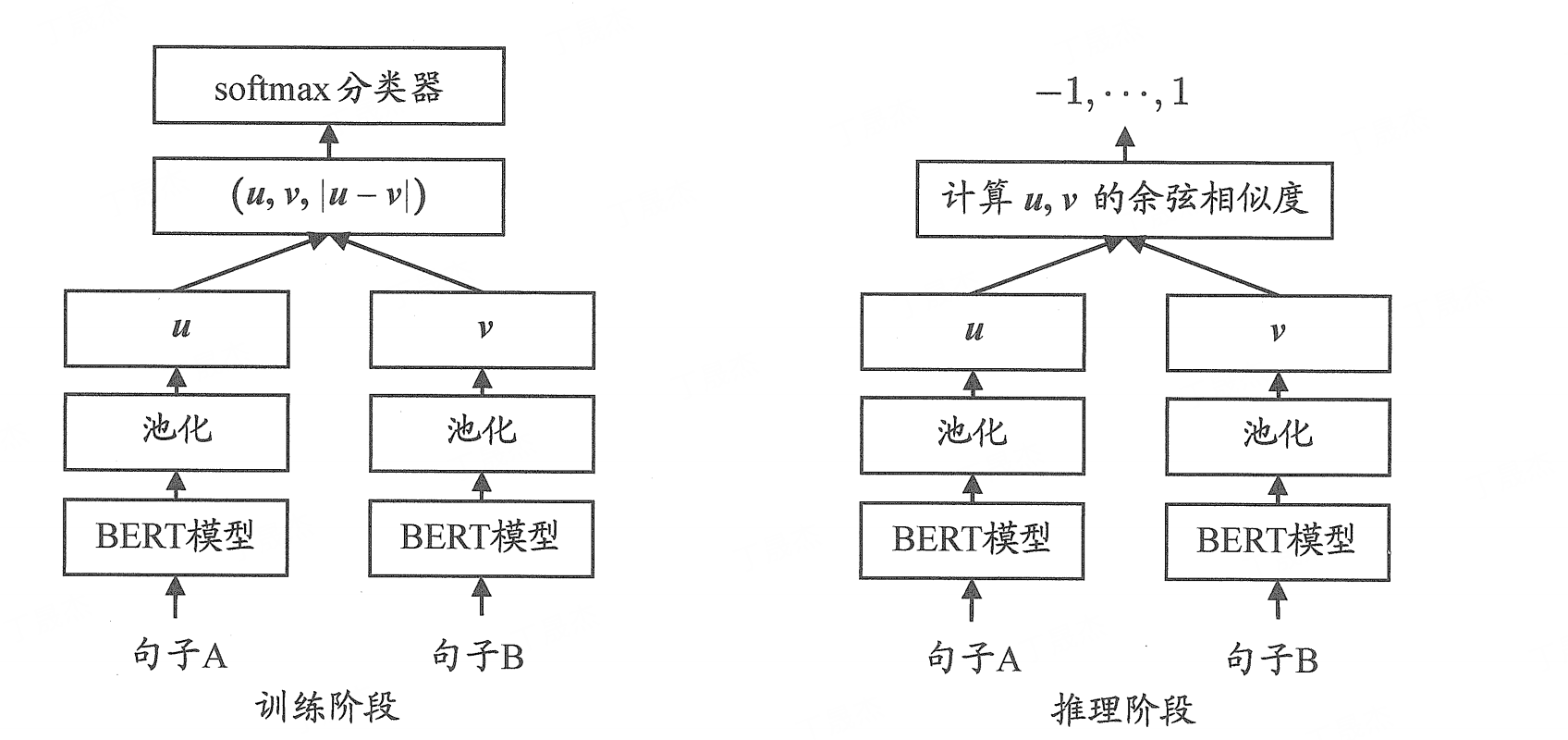
如图所示,模型在训练的时候有 3 种任务。
(1) 使用句子的 (u,v,∣u−v∣)(u, v,|u-v|)(u,v,∣u−v∣) 拼接起来做分类任务。
(2) 对于 u,vu, vu,v 的余弦相似度,使用均方误差当作回归任务进行训练。
(3) 构造类锚点(anchor)样本,拉远与负例样本之间的距离,同时拉近与正例样本之间的距离。
以上 3 种任务的根本思想是把两个句子表征之间的距离加入模型的训练中。任务 (3) 最终需要的最大化目标函数可以形式化为:
max(∥sa−sp∥−∥sa−sn∥+ϵ,0)\max \left(\left\|s_{a}-s_{p}\right\|-\left\|s_{a}-s_{n}\right\|+\epsilon, 0\right)max(∥sa−sp∥−∥sa−sn∥+ϵ,0)
其中, sas_{a}sa 表示句子 aaa 的句子向量, ppp 表示正例, nnn 表示负例, 在训练过程中需要进行负采样。在推理的时候使用余弦相似度可以刻画出不同句子向量之间的语义相似性。
SBERT 中的实验尝试了多种池化方式, 最终证明取各个词元表征的平均值作为整个句子的表征, 可以使得 SBERT 输出的句子表征具备最好的聚类特性, 从而在向量空间中均匀分布。
SimCSE
- SimCSE (Simple Contrastive Sentence Embeddings) 是另一种基于对比学习的句子表征方法, 它在 Sentence-BERT 的基础上进行了改进, 提出了 SimCSE。与使用监督损失拉远负例之间的距离从而得到比较好的表征空间的 SBERT相比, **SimCSE 提出了一种不使用标注数据的无监督训练方法,其核心是通过构造 “正样本对” 和 “负样本对”,训练模型学习到更具区分性的句子向量。与传统对比学习方法(如 SBERT)相比,SimCSE 的创新点在于利用 “dropout 随机性” 自动生成正样本,避免了复杂的负样本构建过程。
对比学习的目标是学习一个编码器 f(·),使得:
- 对于语义相似的句子对
(x, x⁺)(正样本对),它们的向量f(x)和f(x⁺)尽可能接近; - 对于语义不相似的句子对
(x, x⁻)(负样本对),它们的向量f(x)和f(x⁻)尽可能远离。
损失函数通常采用 InfoNCE 损失:
L=−logexp(sim(f(x),f(x+))/τ)∑x′∈N(x)exp(sim(f(x),f(x′))/τ)
\mathcal{L} = -\log\frac{\exp(\text{sim}(f(x), f(x^+))/\tau)}{\sum_{x'\in\mathcal{N}(x)}\exp(\text{sim}(f(x), f(x'))/\tau)}
L=−log∑x′∈N(x)exp(sim(f(x),f(x′))/τ)exp(sim(f(x),f(x+))/τ)
其中:
sim(a, b)是向量a和b的余弦相似度;τ是温度参数(控制相似度分布的陡峭程度);$\mathcal{N}(x)$是包含正样本x⁺和所有负样本x⁻的集合。
SimCSE 的创新:正样本与负样本的构建
SimCSE 分为 无监督版 和 有监督版,核心差异在于正样本的来源:
无监督 SimCSE(Unsupervised SimCSE)
- 正样本构建:利用模型中 dropout 层的随机性,对同一句话
x进行两次编码(即通过同一编码器但 dropout 随机失活不同神经元),得到两个略有差异的向量f(x)和f'(x),将(x, x)视为正样本对(f(x), f'(x))。- 原理:dropout 相当于对句子进行“微小扰动”,两次编码的向量仍保留核心语义,可作为正样本。
- 负样本构建:在一个 batch 中,除正样本外的其他句子均为负样本(即同一 batch 内的其他句子
x_j,j≠i)。
有监督 SimCSE(Supervised SimCSE)
- 正样本构建:利用自然语言推理(NLI)数据集中的“蕴含关系”(entailment),将互为蕴含的句子对
(x, y)作为正样本(如“他在吃苹果”和“他在吃水果”)。 - 负样本构建:
- 同一 NLI 样本中的“矛盾句”(contradiction)作为硬负样本(语义高度相关但不相似);
- 同一 batch 中的其他句子作为普通负样本。
具体而言, 在训练过程中, 模型中应用的 Dropout 技术会使得前后两次前向传播产生的结果存在差异。如果能够最小化模型对同一个句子的表征差距, 使其即使经过 Dropout 干扰, 仍然保持较为接近的表征结果, 同时确保不是同一个句子的两个表征逐渐远离, 那么就可以通过这种对比学习的方法进行模型的优化,提升其性能表现。假设现在有 16 个句子作为一个 batch (批次) 输入到模型中, 在做数据输入时, 将其处理成 2×162 \times 162×16 的矩阵形式。损失函数进行模型训练:
Li=−logesim(hii,hisi)/τ∑j=1Nesim(hii,hjsj)/τ\mathcal{L}_{i}=-\log \frac{\mathrm{e}^{\operatorname{sim}\left(h_{i}^{i}, h_{i}^{s i}\right) / \tau}}{\sum_{j=1}^{N} \mathrm{e}^{\operatorname{sim}\left(h_{i}^{i}, h_{j}^{s j}\right) / \tau}}Li=−log∑j=1Nesim(hii,hjsj)/τesim(hii,hisi)/τ
这一损失函数是基于组内相似度 softmax 的,其中,sim(hizi,hizi)\operatorname{sim}\left(\boldsymbol{h}_i^{z_i}, \boldsymbol{h}_i^{z_i}\right)sim(hizi,hizi) 表示同一个句子经过两次 Dropout 计算后的结果,是一种无监督的相似度训练对比损失。所谓“对比”,就是要让模型最大化不同样本之间的区别,优化目标是拉远不同句子之间的距离。经过无监督训练的模型已经对句子具备了比较强的均匀化表征能力,因此,在下游任务中,只需要使用较少量的有监督数据进行微调,就能够让模型的表征效果实现显著提升。在有监督的设定下,模型的优化目标是尽量提升正例之间的相似度,同时拉远负例之间的相似度距离,其优化目标可以形式化为:
Li=−logesim(hi,hi+)/τ∑j=1N(esim(hi,hj+)/τ+esim(hi,hj−)/τ)\mathcal{L}_i=-\log \frac{\mathrm{e}^{\operatorname{sim}\left(\boldsymbol{h}_i, \boldsymbol{h}_i^{+}\right) / \tau}}{\sum_{j=1}^{N}\left(\mathrm{e}^{\operatorname{sim}\left(\boldsymbol{h}_i, \boldsymbol{h}_j^{+}\right) / \tau}+\mathrm{e}^{\operatorname{sim}\left(\boldsymbol{h}_i, \boldsymbol{h}_j^{-}\right) / \tau}\right)}Li=−log∑j=1N(esim(hi,hj+)/τ+esim(hi,hj−)/τ)esim(hi,hi+)/τ
其中,sim(hi,hi+)\operatorname{sim}\left(\boldsymbol{h}_i, \boldsymbol{h}_i^{+}\right)sim(hi,hi+) 表示有监督的正例之间的相似度。
SimCSE 无监督训练阶段的自正例采样方法也存在一些问题。在大部分情况下,一个 batch 中的句子长度是不相同的(不包括填充部分),这样模型可能会错误地认为长度
SimCSE 的训练流程
以无监督 SimCSE 为例,训练流程如下:
- 输入准备:将同一句话
x复制两份,组成输入对(x, x); - 编码:通过预训练语言模型(如 BERT)对输入对进行编码,由于 dropout 的随机性,得到两个向量
u = f(x)和v = f'(x); - 构造样本集:在一个 batch 中,对于每个句子
x_i,其正样本是v_i,负样本是其他句子的编码向量u_j, v_j(j≠i); - 计算损失:对每个
u_i,用 InfoNCE 损失计算其与正样本v_i和所有负样本的相似度,优化模型参数; - 迭代训练:通过多轮训练,让模型学会将语义相似的句子向量聚集在一起。
SimCSE局限性
- 长度偏差问题:SimCSE使用dropout作为最小数据增强方法来构建正例对,同一条样本衍生出的正例对长度是相同的,而batch内其他样本构建的负例对长度可能不同。由于Transformer通过位置向量编码句子的长度信息,模型会将样本长度作为识别正负例的重要特征,导致倾向于将长度相近的语句认定为相似。无监督SimCSE在长度相似(≤3)的句子上的性能远远超过在长度差异较大(>3)的句子上的性能。
- 负例构建的局限性:SimCSE直接将一个batch内与自己不同的样本都作为负样本,理论上更多的负例对可以让模型学习效果更好,但SimCSE中更大的batch size并不总是更好的选择,例如对于无监督的SimCSE - BERT_base模型,最佳batch size大小为64,batch size设置过大会导致性能下降。
- 温度系数的影响:当温度系数趋向于无穷大时,对比损失对所有负样本都一视同仁,失去了对困难样本关注的特性,可能会影响模型的学习效果。
- 微调对非对称语义检索效果差:SimCSE的微调适用于对称语义检索,而对非对称语义检索的效果很差。例如,对于“你的工作,你的职业”这样的对称语义检索效果较好,但对于“你的工作,计算机相关”这种非对称语义检索,微调效果不佳。
更多词向量模型面试问题
🔹 一、基础概念类问题(入门级)
-
什么是词向量?常见的词向量模型有哪些?
回答要点:Word2Vec(Skip-gram/CBOW)、GloVe、FastText;分布式假设;语义相似性可通过向量距离衡量。
-
词向量是如何训练的?基于什么假设?
分布式假设(Distributional Hypothesis):“上下文相似的词,语义也相似”。
-
词向量可以用于句子表示吗?怎么组合成句向量?
方法:平均池化(Average Pooling)、加权平均(如 SIF)、LSTM 编码等。
缺点:忽略语法结构、无法处理多义词。 -
BERT 能直接用来做句子相似度计算吗?比如取 [CLS] 向量或平均所有 token 向量?效果如何?
可以但效果差。实验证明原始 BERT 输出的句向量缺乏判别性,不同句子间余弦相似度高,不适合聚类或检索。
-
为什么 BERT 原生输出的句向量不适合直接用于聚类或语义搜索?
关键原因:
- 向量空间高度各向异性(anisotropy),即句向量集中在狭窄锥形区域;
- 不同句子之间相似度偏高,难以区分;
- 训练目标(MLM + NSP)不鼓励生成有判别性的句向量。
🔹 二、SBERT 相关问题(进阶级)
-
SBERT 是什么?它解决了什么问题?
Sentence-BERT:使用 Siamese/Bi-encoder 结构微调 BERT,生成固定维度的句向量,适用于语义相似度计算、聚类、STS 任务。
-
SBERT 的网络结构是怎样的?用了什么损失函数?
结构:双塔 BERT 共享参数;
损失函数:- 回归损失(Mean Squared Error)用于 STS 任务;
- 三元组损失(Triplet Loss)或对比损失用于句子匹配。
-
SBERT 如何提升句向量的聚类性能?
通过监督信号(如标注的相似句对)进行微调,使相似句子在向量空间中靠近,不相似的远离,从而增强可分性和聚类能力。
-
SBERT 的优点和缺点分别是什么?
✅ 优点:推理快(双塔结构)、句向量质量高、适合下游任务;
❌ 缺点:需要标注数据(监督训练)、微调成本高、泛化依赖训练数据分布。
🔹 三、SimCSE 相关问题(重点!必考)
-
SimCSE 是什么?它的核心思想是什么?
SimCSE(Simple Contrastive Learning of Sentence Embeddings)是一种通过对比学习构建高质量句向量的方法,分为无监督和有监督两个版本。
-
无监督 SimCSE 是如何工作的?正样本是怎么构造的?
- 输入一个句子,经过两次 dropout 得到两个不同的 BERT 输出作为正样本对;
- 其他句子的输出作为负样本;
- 使用对比损失(InfoNCE)拉近正样本距离,推远负样本。
-
为什么只用 dropout 就能构造有效的正样本?这不会让模型学到噪声吗?
Dropout 引入了轻微扰动,保留语义一致性的同时增加多样性,有助于模型学习更鲁棒的表示。实验表明这种方式非常有效。
-
有监督 SimCSE 和无监督的区别?用了哪些额外信息?
使用标注的语义相似句对(如同义句、NLI 数据中的蕴含对)作为正样本,进一步提升性能。
-
SimCSE 如何缓解句向量空间的“各向异性”问题?
对比学习迫使模型将语义相近的句子映射到相近位置,同时拉开无关句子的距离,有助于扩展向量分布,减轻坍缩现象。
-
训练细节与聚类性能
SimCSE 的损失函数是什么?(如 InfoNCE 损失)它如何让 “语义相似的向量更接近,语义无关的更疏远”?
为什么 SimCSE 生成的句子向量适合聚类任务?(如向量分布更紧凑、语义表征更精细、无需额外标注数据)
无监督 SimCSE 与 SBERT(无监督版)相比,在聚类任务上的性能如何?各自的适用场景有什么差异(如数据是否有标注、任务对速度的要求)? -
SimCSE 相比 SBERT 有什么优势?
- 无需复杂结构(仍是单塔);
- 无监督版无需标注数据;
- 更简单高效,性能更强;
- 更好地解决各向异性问题。
🔹 四、句向量构建方法分类与演进(综合理解)
-
请对句子向量构建方法进行分类总结。
✅ 主要类别:
- 基于词向量组合:平均 Word2Vec / TF-IDF 加权平均
- 基于 RNN/LSTM:编码器最后状态或池化
- 基于预训练模型(直接使用):BERT 取 [CLS] 或平均
- 微调型句向量模型:SBERT、SimCSE、ConSERT
- 非对比方法:Unsupervised BERT-flow, Whitening
-
什么是 BERT-flow?它和 SimCSE 有何异同?
- BERT-flow:对 BERT 输出的句向量拟合一个流模型(flow-based model),将其变换为标准正态分布,缓解各向异性。
- 不需要对比学习或负样本,完全无监督。
- 效果不如 SimCSE,但也是早期重要尝试。
-
什么是向量白化(Whitening)?它是如何改善句向量质量的?
对句向量进行线性变换,使其协方差矩阵变为单位阵,打破各向异性,提升余弦相似度的判别性。
实现简单、速度快,常作为后处理技巧配合其他方法使用。 -
目前最主流的无监督/有监督句向量方法分别是什么?
- 无监督:SimCSE(+ Whitening 后处理)
- 有监督:Supervised SimCSE、SBERT、DeBERTa + Pooler
🔹 五、开放性 / 设计类问题(高阶)
-
如果你只有少量标注数据,如何构建一个好的句向量模型?
建议路线:
- 先用无监督 SimCSE 预训练;
- 再用少量标注数据 fine-tune(有监督 SimCSE 或 SBERT);
- 可结合数据增强(EDA、回译)扩充训练集。
-
如何评估句向量的质量?有哪些常用指标和基准?
- 标准数据集:STS Benchmark、SICK-R、MRPC、QQP
- 指标:皮尔逊相关系数、Spearman 秩相关、聚类准确率、检索召回率(R@k)
- 可视化:t-SNE 观察聚类效果
-
能否用对比学习的思想改进传统的词向量模型?
可以,例如 Contrastive Contextual Word Embeddings,或在 Skip-gram 中引入对比损失。
-
为什么 SimCSE 的无监督版性能接近甚至超过某些监督方法?
因为 BERT 本身已经学到了丰富的语义知识,加上对比学习的有效引导,即使没有人工标注也能挖掘出强语义关系。
📌 加分项提示:
- 能画出 SBERT/SimCSE 的结构图;
- 能写出 InfoNCE 损失公式:
L=−logexp(sim(hi,hj)/τ)∑k=1Nexp(sim(hi,hk)/τ) \mathcal{L} = -\log \frac{\exp(\text{sim}(h_i, h_j)/\tau)}{\sum_{k=1}^N \exp(\text{sim}(h_i, h_k)/\tau)} L=−log∑k=1Nexp(sim(hi,hk)/τ)exp(sim(hi,hj)/τ) - 提到
sentence-transformers库的实际使用经验。