常用优化器及其区别
一、优化器
(优化器有什么用?)
深度学习模型通过引入损失函数,用来计算目标预测的错误程度。根据损失函数计算得到的误差结果,需要对模型参数(即权重和偏差)进行很小的更改,以期减少预测错误。但问题是如何知道何时应更改参数,如果要更改参数,应更改多少?这就是引入优化器的时候了。简单来说,优化器可以优化损失函数,优化器的工作是以使损失函数最小化的方式更改可训练参数,损失函数指导优化器朝正确的方向移动。
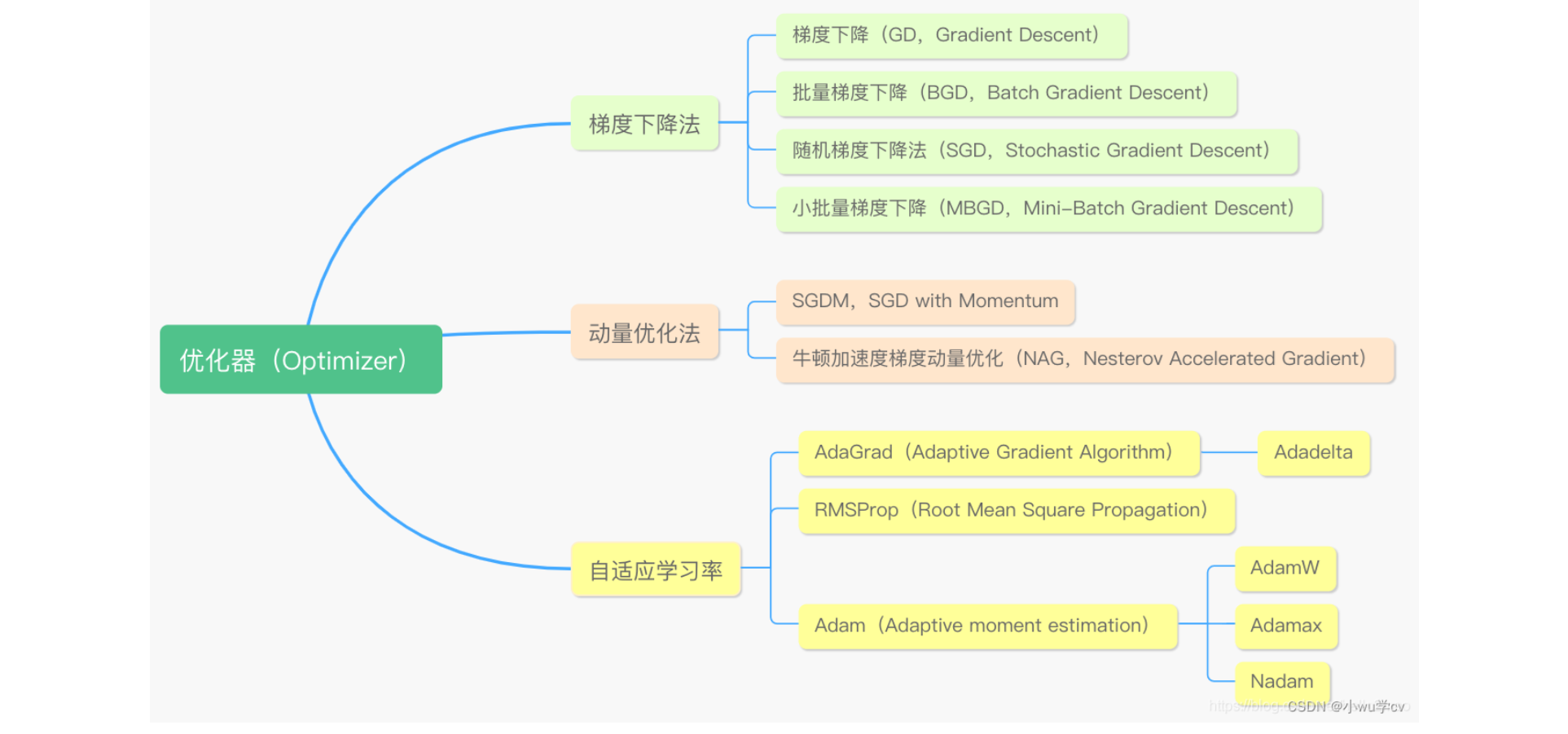
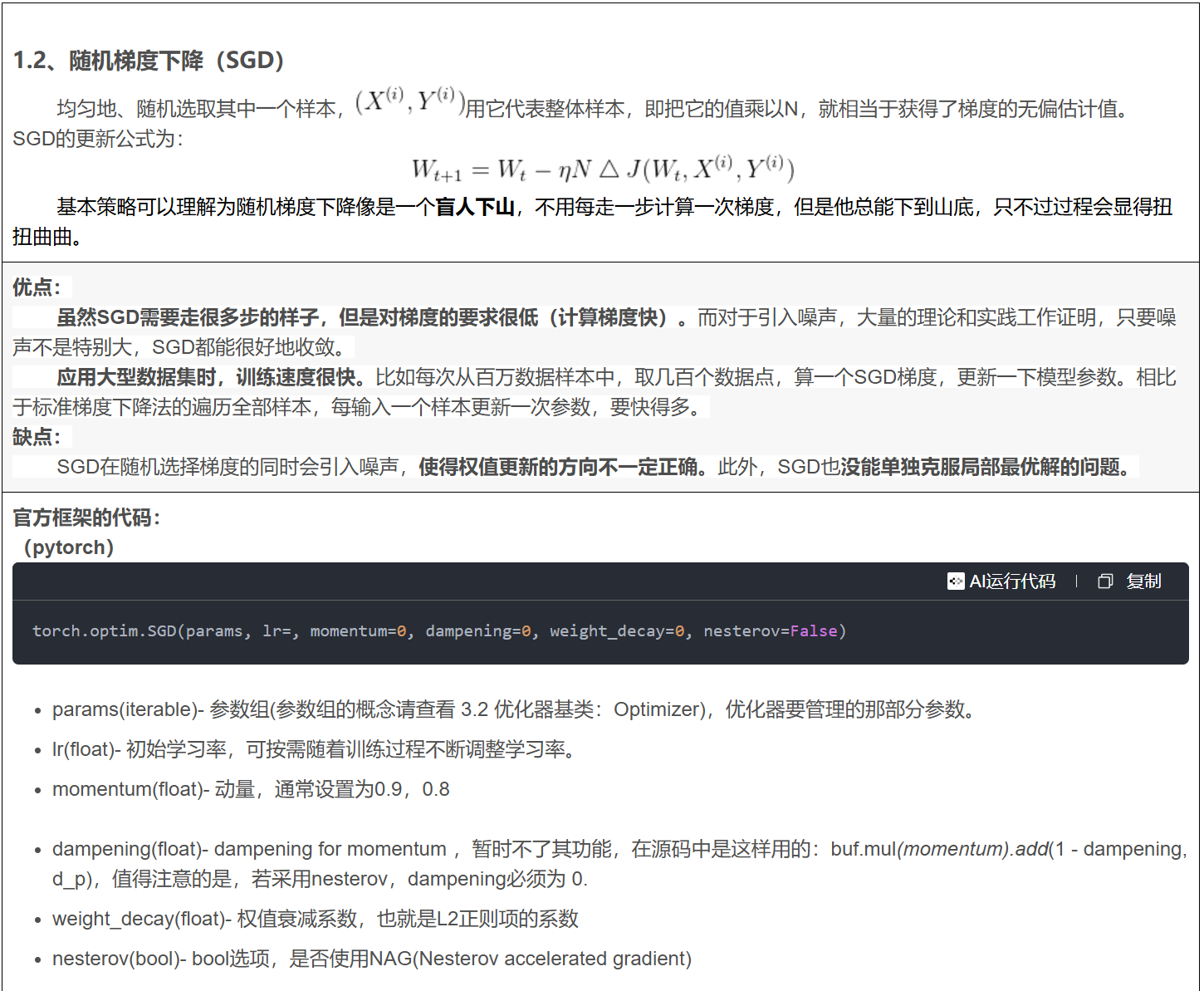
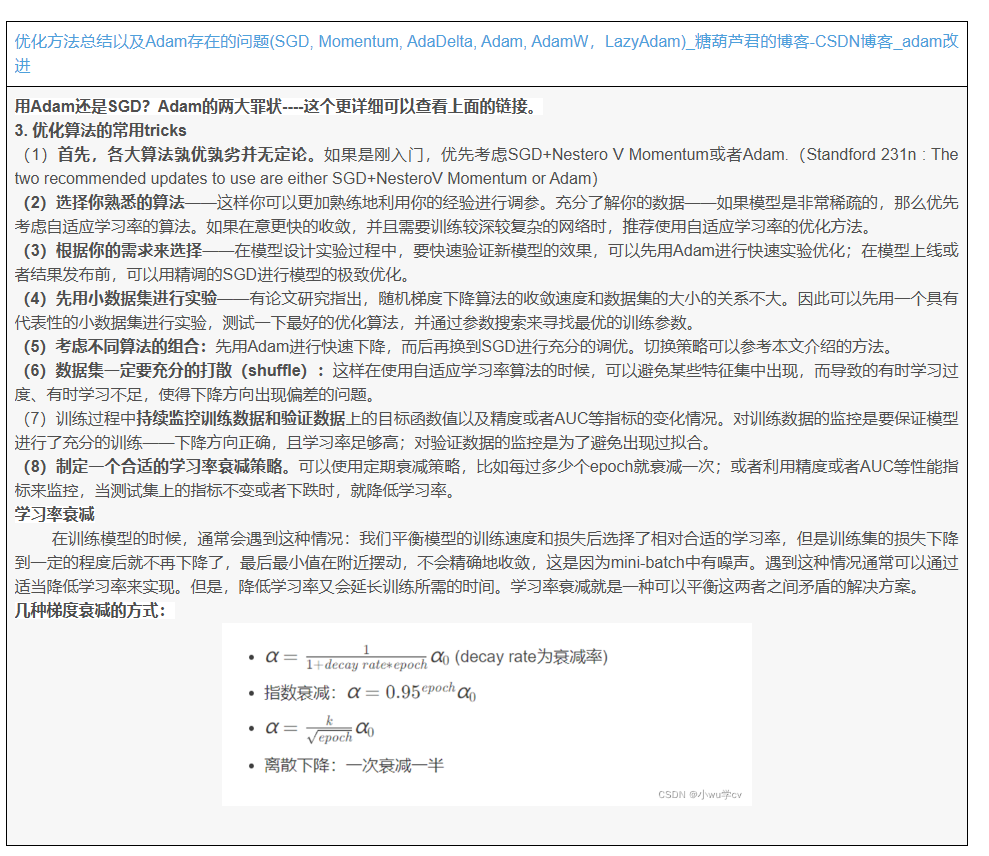
优化器即优化算法是用来求取模型的最优解的,通过比较神经网络自己预测的输出与真实标签的差距,也就是Loss函数。为了找到最小的loss(也就是在神经网络训练的反向传播中,求得局部的最优解),通常采用的是梯度下降(Gradient Descent)的方法,而梯度下降,便是优化算法中的一种。总的来说可以分为三类,一类是梯度下降法(Gradient Descent),一类是动量优化法(Momentum),另外就是自适应学习率优化算法。
常见的一些优化器有:SGD、Adagrad、Adadelta、RMSprop、Adam、Adamax、Nadam、TFOptimizer等等。