4.1-中间件之Redis
目录
4.1.1-初识Redis
Redis的应用
4.1.2-Redis的pipeline与驱动
事物原子性实现方法1
事物原子性实现方法2
客户端连接上Redis的驱动
4.1.3-Redis单线程但高性能的原因
reactor网络模型 io多路复用
value数据结构高效
kv的数据组织方式高效
4.1.4-Redis的持久化与高可用性
Redis的持久化实现
Redis的高可用性实现
基础:数据备份(主从复制)
进阶:主从切换
4.1.1-初识Redis
Redis是一个远程的,可访问的数据存储服务器,类似mysql。
数据存储方式是:内存为基准,而mysql是磁盘为基准。
数据操作方式是:KV,就是通过Key去操作value,进行增删改查
数据组织方式是:unorderedmap组织key-value的映射,而value的数据结构可以是string/list/hash/set/zset 其中zset是有序的set。
Redis的应用
redis的命令与value选用的数据结构有关.
value类型为string时,可以用于存储对象,将对象索引为key,对象属性打包成json格式作为value,缺点是因为打包成了json不易于修改。还可以用于签到功能,因为string是二进制字符串,可以按照 "setbit 年月 日 是否签到" 的格式进行操作,其中年月就是key,可以通过"bitcount 年月"来统计签到天数。
value类型为list时,可以用来实现栈(lpush + lpop)或者队列(lpush + rpop),或者阻塞队列(lpush+brpop)。也可以用于记录查询功能,lpush 存储后,通过ltrim say 0 4 可以保存五条记录,注意是 l左插左截,或者r右插右截,这一对"插截"通常要通过lua脚本保证原子性。
value类型为hash时,可以用于存储对象,比如"hmset hash:1001 name jack old 18 sex male",而且比string更方便,因为不是json格式,所以易于修改。hash的redis可以理解为两个key 对应一个value,在具体上是 key - > value = (field -> ans)。
value类型为set时,可以应用在抽奖(利用集合元素不重叠性质设置抽奖号码)。可以应用在好友推荐功能,对A用户和B用户各自的好友集合做一个差集,随后推荐给两人。
value类型为zset时,可以用来实现排行榜(利用有序唯一的性质)。
4.1.2-Redis的pipeline与驱动
pipeline模式在之前的kvstore项目中也有实现,目的是为了一次发送多条客户端的指令,减少网络io次数。
Redis的处理方式与kvstore项目不同的地方是:
可能会有多个用户连接到Redis上,属于多条并发连接环境,所以需要保证每次发来的pipeline上的多条指令是一个事物(不同于原子操作,原子操作是多核心环境),即执行多条指令的过程是不可见的,其余用户无法触碰多条指令正在操作的key。
所以实现pipeline模式需要保证事务的原子性。
事物原子性实现方法1
事物创建指令
客户端A:对num值翻倍watch num 100 会在事物提交之前 监测这个key有没有被别的客户修改MULTI 开启事物指令1:get num
指令2:set num 200EXEC 提交事物
事物与原子操作的区别:
事物可以进行回滚,比如Redis的事物加的是"乐观锁":即假设其余B,C客户端不会操作当前A客户端提交的事物中的key,但如果最后发现被操作了,那就返回事物失败,即可以一起成功,也可以一起失败。
事物原子性实现方法2
而在具体工作中,还有更高效的保障事物原子性的方法:lua脚本
在Redis内部,有一个lua虚拟机,不同的客户端可以提交执行lua代码,但是lua虚拟机只会一个人一个人执行,不会出现被打断情况。
lua脚本的优化:对事物原子性的需求很多,有时候很多执行多lua代码会有高度重复,比如多次翻倍。那么可以把lua脚本写成一个函数,可以接收参数,并且提交给Redis服务器编译后通过sha1产生一个函数对应的id返回给客户端,那么客户端就可以通过ID,直接传入参数即可获得结果。举例:
A客户端:给num 值翻4倍指令1:SCRIPT LOAD “local key = KEYS[1];local val = redis.call("get",key);if not val then val = 100 end;redis.call("set",key,2*val);return 2* val;”响应:“akuwbfdajwygdfaiuwd19278”指令2:evalsha akuwbfdajwygdfaiuwd19278 1 num指令3:evalsha akuwbfdajwygdfaiuwd19278 1 num注:1表示1个参数实际工作中,这样的lua脚本函数很多,中服务器启动前要全部编译,并且把lua ID与sha1产生的hx ID通过unorderedmap建立映射,便于用户访问。
分析事物:ACID特性分析
A:原子性 C:一致性 I:隔离性 D:持久性
Redis具有原子性与隔离性,不满足持久性和一致性
满足隔离性是因为Redis是单线程的,天然只能一个一个执行lua脚本。不满足持久性因为若执行lua脚本中间指令有一条是错误指令,而错误指令前的指令会被正确执行,错误指令后面的指令却都不会执行,所以会出现一致性错误。一般不满足持久性,即把数据从内存保存到磁盘文件上,除非在特殊策略下配置特殊配置文件可以实现。
客户端连接上Redis的驱动
同步连接(阻塞io):
通过hiredis头文件,里面提供的redisConnectWithTimeout接口,填入Redis服务器ip,端口,超时时间,建立连接。通过提供的redisComman来执行redis命令。
异步连接:
也是利用hiredis,里面提供了适配reactor网络模型的异步驱动方式。
所以异步连接Redis需要
1.适配事件对象;
我们的reactor事件
struct event_s {int fd;reactor_t *r;buffer_t *in;buffer_t *out;event_callback_fn read_fn;event_callback_fn write_fn;error_callback_fn error_fn;
};typedef struct event_s event_t;Redis运行需要的事件
typedef struct {event_t e; 继承我们写的reactor事件int mask;redisAsyncContext *ctx; 主要是加这个,所有Redis命令都需要这个上下文
} redis_event_t;
2.适配事件函数(注册/注销 读/写事件)
我们(客户端)的事件函数:
int add_event(reactor_t *R, int events, event_t *e);int del_event(reactor_t *R, event_t *e);int enable_event(reactor_t *R, event_t *e, int readable, int writeable);add_event(reactor_t *R, int events, event_t *e) { 传入一个event事件struct epoll_event ev;ev.events = events;ev.data.ptr = e; data本质:将epoll事件和数据绑定,避免触发后再通过fd查找简单场景直接ev.data.fd 复杂场景使用ptr指针if (epoll_ctl(R->epfd, EPOLL_CTL_ADD, e->fd, &ev) == -1) {printf("add event err fd = %d\n", e->fd);return 1;}return 0;
}Redis(服务端)连接函数:static int redisAttach(reactor_t *r, redisAsyncContext *ac) {redisContext *c = &(ac->c);redis_event_t *re;/* Nothing should be attached when something is already attached */if (ac->ev.data != NULL)return REDIS_ERR;/* Create container for ctx and r/w events */re = (redis_event_t*)hi_malloc(sizeof(*re));if (re == NULL)return REDIS_ERR;
构造一个Redis event:re->ctx = ac;re->e.fd = c->fd;re->e.r = r;// dont use event buffer, using hiredis's bufferre->e.in = NULL;re->e.out = NULL;re->mask = 0;Redis的事件接口:ac->ev.addRead = redisAddRead;ac->ev.delRead = redisDelRead;ac->ev.addWrite = redisAddWrite;ac->ev.delWrite = redisDelWrite;ac->ev.cleanup = redisCleanup;ac->ev.data = re;return REDIS_OK;
}客户端通过reactor与Redis建立异步连接的流程:
1.socket设置非阻塞 ;2.connect建立连接,立刻返回 ;3.注册socket写事件 ;
4.写事件触发,建立连接成功 ;5.注销写事件,注册读事件 ;
6.发送命令到Redis,如果发生失败或者不完全,再注册写事件。
4.1.3-Redis单线程但高性能的原因
1.内存数据库 2.reactor网络模型 3.value数据结构高效 4.kv的数据组织方式高效
第一点上面有描述,下面介绍二、三、四点。
reactor网络模型 io多路复用
Redis命令处理是单线程的,可以有很好的隔离性,也可以更加适配多样的业务处理(因为多线程+value复杂的数据结构,加锁很麻烦;频繁切换上下文也耗时)。但单线程也有单线程的局限性,在有耗时操作(io耗时操作或者cpu耗时操作),会对性能产生较大影响。所以redis有针对方案:
1、针对io密集型
(1)磁盘io
在有持久化redis需求的时候,需要大量的访问磁盘操作,redis有异步aof刷盘线程,进行异步操作。
(2)网络io
在接收io上,如果有多个客户端连接,redis尽管只有单线程接收,但是因为reactor模型,可以非阻塞的建立连接,实现io多路复用。
在处理io上,如果多个连接的操作都是需要的send、recv耗时操作,那redis也会开启io多线程进行处理。原先的过程是recv->decode->业务处理->encode->send,如果有多个用户发送请求,则只能串行执行全过程。在开启io多线程后,会将所有用户发送的内容存入一个队列,随后用多个线程recv,多个线程read。但是业务处理过程还是只能串行执行。
2、针对cup密集型
对于每个连接的请求,如果是具体的计算业务需求,可以通过数据结构的优化,减少时间复杂度,或者分治的方式,将大段计算时间分治成很多小段计算。
value数据结构高效
value中的数据类型不同与正常的数据类型,他有自己的编码方式,如 REDIS_STRING、REDIS_LIST。
基本原理都是在数量少的时候放弃时间复杂度争取空间,在数量多的时候空间换时间。
对于字符串REDIS_STRING,通常以64个字节作为分隔符,因为一个cacheline的大小通常是64字节,这样访问字符串对象只需要一次缓存加载。而64个字节的字符串中的字符串内容,只有64 - RedisObject (16 bytes) - SDS header (至少 3 bytes,sdshdr8) - 结束符‘/0’(1bytes) = 44字节。
REDIS_STRING的编码方式有三种:
int:字符串长度<=20且能转为整数的情况下,用int编码,因为只要4字节
embstr:字符串长度<=44的情况下,用embstr编码
raw:字符串长度>44的情况下,用raw编码
介绍SDS与RedisObject:
struct __attribute__ ((__packed__)) sdshdr8 {uint8_t len; // 字符串当前长度(1 字节)uint8_t alloc; // 分配的总容量(1 字节)unsigned char flags;// (1 字节)char buf[]; 实际字符串数据(柔性数组) 无需额外分配和释放,返回sizeof也没有他
};SDS是什么?
SDS 是 Redis 对 C 原生字符串(char*)的增强版,解决了原生字符串的以下问题:二进制安全:允许存储 \0 等特殊字符(C 字符串以 \0 结尾,无法存储二进制数据)。
O(1) 时间复杂度获取长度:C 字符串需要 strlen() 遍历,而 SDS 直接记录长度。
自动扩容:避免缓冲区溢出(如 strcat 可能越界)。
内存预分配:减少频繁扩容的开销(空间换时间)。typedef struct redisObject {unsigned type:4; // 数据类型(4 bits),如 REDIS_STRING、REDIS_LISTunsigned encoding:4; // 编码方式(4 bits),如 OBJ_ENCODING_EMBSTR、OBJ_ENCODING_RAWunsigned lru:24; // LRU 时间戳或 LFU 计数(24 bits)int refcount; // 引用计数(32 bits)void *ptr; // 指向实际数据的指针(64 bits)
} robj;RedisObject是什么?
RedisObject 是 Redis 中所有数据类型的统一抽象。
无论是字符串、列表、哈希表还是集合,Redis 在内部都会将它们封装为一个 RedisObject。对于zset,Redis的实现方式有压缩列表(节点数量<128)和跳表(节点数量>128),其中跳表的实现过程经历一个理想跳表->概率跳表->实际跳表的过程,时间复杂度都是logn。具体演变是因为理想跳表不适合增删改,所以有一个1/2和1/4的概率向上层进行操作。演化出了后面两种概率跳表和实际跳表。
kv的数据组织方式高效
在Redis中,一个kv键值对的存储方式是hashtable,可以O(1)取出一个键值对,即一个哈希+数组链表,具体的过程是将key值做一个hash,得到一个整数后,对数组长度取余,加入到对应位置的链表当中。但是随kv键值对的扩张也会出现数组不够用的情况,那么就需要哈希扩容,也有对应的哈希缩容。
哈希扩容
扩容:当哈希冲突的 哈希负载因子>1 的时候,需要对哈希数组进行一个翻倍扩容。具体的扩容过程是:创建一个长度等于原数组两倍的新数组,将原数组的内容,rehash到一个新的数组里。
但是不能一次性rehash完,这会让单线程处理命令的主线程阻塞很久。需要采用渐进式rehash.
rehash方法1:按步频
把数组的每个元素称为一个步频,那么redis采用的方法是,每次处理增删查改任务,就rehash一个步频,把rehash的时间分散。
rehash方法2:按定时器
在没有fork子进程特殊业务的时候,rehash 1ms的时间,不管多少个步频。但如果哈希负载因子>5了,就立即rehash 1ms
4.1.4-Redis的持久化与高可用性
Redis的持久化实现
Redis作为一个内存型数据库,也要实现断电后的数据保存,具体的实现操作是fork进程写时复制机制。
什么是写时复制?
从父进程fork一个子进程,为了加速fork,会直接将父进程的页表复制给子进程,页表指向的都是同一片物理内存,而且会将他们的页表都改为只读状态,当Redis需要修改内容的时候,无论是使用的父进程修改还是子进程修改,都会遭遇页表的只读,就会触发保护机制,将需要修改的进程指向一片新的物理内存(由原先共同的物理内存复制),随后将两个进程的页表都改为读写状态。
Redis的持久化实现方案选择
1.aof。默认的aof也有三种参数选择,(always、ervery_sec、no),分别表示Redis每指向一条指令就把其结果写盘、每秒写盘一次、不主动写盘,等到Redis采用内存淘汰机制的时候再写盘。
缺点是:可能会保存SET name 1、SET name 2、SET name 3这样的冗余操作,实际只需要保存最后一条。
aof-rewrite:fork进程,根据内存当前数据生成aof文件,并且在执行期间,如果Redis又写了数据,附加到aof文件末尾
2.rdb。通过fork进行持久化,基于内存中的对象编码直接持久化。
缺点是:fork只能暂存当前状态,如果期间Redis进行了写操作,数据会丢失。
rdb-aof混用:效果类似aof-rewrite,可以实现 不冗余 + 不丢失。
Redis的内存淘汰是什么?有哪些策略?
在Redis中,有一个maxmemory的临界值,超过这个值,Redis就会开始进行内存淘汰,一般会选用磁盘大小的一半,因为可能会有哈希扩容,需要创建双倍空间。
淘汰策略:
1、加上volatile字段,在过期的key中选择。在淘汰之前,就有在SET key value的时候加上expire 100s的键值对,即使100s没到,还没销毁这个键值对,但这些设置过expire或者pexpire的字段属于 “过期的key”。再进行LRU或者LFU或者random淘汰。
2、每加volatile字段,对所有的key一视同仁,进行LRU或者LFU或者random淘汰。
Redis的高可用性实现
高可用性即,在Redis服务器遇到问题宕机的情况下,采用怎么样的补救方案,尽可能少的波及用户体验,这就体现了一个集群的高可用性。
那就主要依赖两个方面,一个是数据备份机制,这个是基础,再一个就是主机宕机的情况下,顶替主机供服务器连接的从机选择策略。
基础:数据备份(主从复制)
复制细节:
是从机主动向主机建立连接,拉取数据。并且在拉去数据备份的过程中,从机有一个偏移量,主机有一个ring buffer(保存最近修改的内容),如果这个偏移量还在ring buffer中,则执行增量数据同步,如果不在了,则需要主机进行rdb内存落盘后,对rdb二进制文件进行一个全量数据同步。
复制策略:
1.异步复制,Redis收到SET key value操作后,就直接给对方返回OK,再执行复制给从机的操作。 缺点:可能会复制给从机失败,导致数据不一致
2.同步复制,Redis收到SET key value操作后,等所有从机都存储了这个键值对且给主机返回OK后,主机再给服务器返回OK,否则返回写错误。 缺点:写失败概率高
3.超过一半的从机返回OK,则主机给服务器返回OK。
进阶:主从切换
在有数据备份的情况下,如何高效的选举一个从机顶替主机工作是重要的,下面介绍三种策略。
1.哨兵模式:麻烦但安全性高
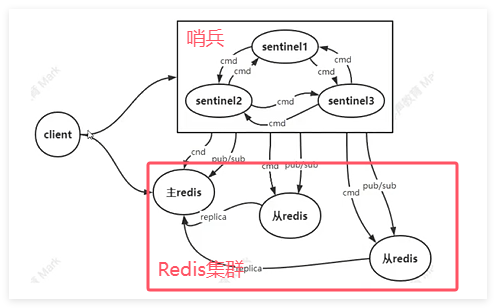
哨兵负责作为客户端和Redis集群的桥梁,client在连接Redis之前,先与哨兵建立连接,询问Redis集群ip地址,并且监听哨兵,由哨兵告诉client连接的地址。这样在主Redis宕机的时候,哨兵能检测到并且选举一个从机作为主机,告知client对应的ip,实现高可用。
缺点:为了维护一个主Redis运行,有五个服务器节点都在为他服务,部署麻烦,并且没有数据扩展机制,每台redis机器都存储的是同一份数据,没有有效的利用三台机器的空间。
2.cluster模式:去中心化且可数据扩容
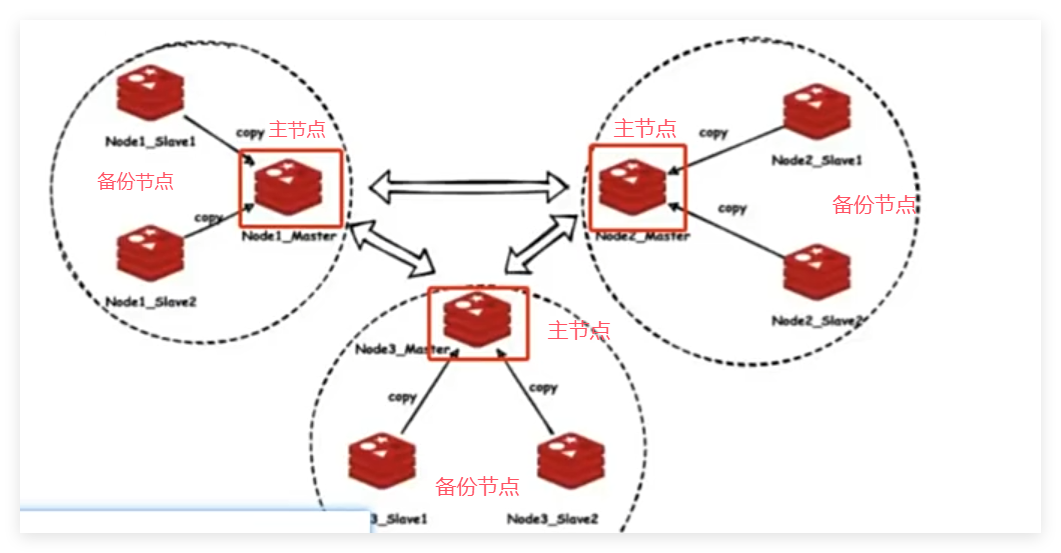
将所有数据划分为16384(2的14次方)个槽位,每个redis主节点均分槽位。redis主节点可以利用Hash分别存储不同的KV键值对,即对key值进行%16384,随后客户端可以从图中9个节点任意一个结点进入集群,因为会通过key%16384,让客户端与集群对应的某主结点重定向,直接到对应的节点取数据。
故障处理
当有一个redis节点宕机了,图中的另外两个集群的节点会选举一个最新的从节点为主节点,新的主节点会把原先主节点分配的槽,全部指派给自己。
数据扩容
当容量不够,再有一个redis想加入,他会分走已经有的三个redis主节点的槽,做到四等份。