面向OS bug的TypeState分析
PATA
- 1.PATA
- 1.1.Introduction
- 1.2.Approach
- 1.2.1.别名分析
- 1.2.2.Typestate Tracking
- 1.2.3.路径验证
- 1.3.Evaluation
- 2.SPATA
- 2.1.Summary-based方法
- 2.1.1.Alias Summary
- 2.1.2.在summary中添加typestate信息
- 2.1.3.在summary中添加路径约束信息
- 2.1.4.跨函数分析
- 2.2.Evaluation
- 参考文献
PATA (path-sensitive alias-aware typestate analysis)发表于ASPLOS 22,随后作者24年在TOCS对其进行扩展为SPATA (summary-based, alias-aware, and path-sensitive typestate analysis)。关于typestate analysis这篇blog里有简单介绍。
1.PATA
参考文献 [1]^{[1]}[1],关于题目中的词语path-sensitive应该是在每个分支处都会fork一下分析结果(不过type state分析本身就是path-sensitive的),alias-aware应该是说原始ESP算法没有考虑变量间的别名情况,PATA考虑了。
1.1.Introduction
分析OS有以下难点:
-
(1).难以基于指针分析进行别名分析(SVF分析很多项目都会有这个问题),这是由于OS是多模块以及application-driven的。其中许多函数并没有caller,因此参数的指向集为空,丢失了许多别名信息。下面示例中
dev->plat_dev和pdev存在别名关系并且1282行如果pdev == NULL那么存在空指针异常。不过,s5p_mfc_probe函数是在另一个OS模块通过platform_driver的.probe字段进行调用的,因此在分析当前模块时,pts(pdev)=∅\text{pts}(\text{pdev}) = \emptysetpts(pdev)=∅,dev->plat_dev和pdev的别名关系并没有建立。虽然可以在分析COPY语句时记录别名关系,但是难以应用到OS等大型code base上。 -
(2).OS Codebase非常大,进行typestate分析的开销也随之增大。虽然可以遍历value-flow graph减少遍历CFG的开销,但value-flow graph基于指针分析构造,而OS下指针分析的结果也不sound。
// FILE: linux-5.6/drivers/media/platform/s5p-mfc/s5p_mfc.c
1266. static int s5p_mfc_probe(struct platform_device *pdev) { ......
1280. dev->plat_dev = pdev; // create alias relationship
1281. if (!dev->plat_dev) { // pdev can be NULL
1282. dev_err(&pdev->dev, ...); // Null-pointer dereference!
1283. return -ENODEV;
1284. }......
1415. }// These interface functions have no explicit caller functions // in the OS code
1664. static struct platform_driver s5p_mfc_driver = {
1665. .probe = s5p_mfc_probe,
1666. .remove = s5p_mfc_remove, ......
1672. }
下面示例中展示了PATA找出的Zephyr蓝牙子系统的一个空指针异常,2709行的 model->user_data 和 cfg 存在别名关系,2720行进行了判空。表明了这两个值可能为 NULL,在 NULL 分支后面会调用 send_friend_status,里面 cfg->frnd 存在空指针解引用。其中存在横跨多个函数的别名关系。
// FILE: zephyr-2.1.0/subsys/bluetooth/cfg_srv.c
2680. static void send_friend_status(type *model, ...) { ......
2684. struct bt_mesh_cfg_srv *cfg = model->user_data; // Alias ......
2687. net_buf_simple_add_u8(&msg, cfg->frnd); // Unsafe dereference! ......
2692. }2705. static void friend_set(...) { ......
2709. struct bt_mesh_cfg_srv *cfg = model->user_data; // Alias ......
2720. if (!cfg) { // Pointer cfg can be NULL
2721. BT_WARN(...);
2722. goto send_status;
2723. }
......
2747. send_status:
2748. send_friend_status(model, ctx);
2749. }
Challenge:C1.如何在不进行指针分析的前提下基于CFG路径和access path分析别名关系。C2.OS中的变量非常多,没法对每个变量维护SMT symbol以及typestate,得使用别名关系减少typestate追踪和路径验证的开销。
Solution:C1.提出了path-based alias analysis,对于control-flow path在每一个程序点维护一个alias graph表示这个path下的别名关系,同时基于被分析的指令以及相关变量的access paths更新alias graph。C2.提出了alias-aware typestate tracking method分析不同类型的bug以及alias-aware path-validation method来验证bug路径的可行性。
之前的typestate分析方法对于每个变量维护一个typestate以及一个SMT symbol,而PATA对于一个alias graph下的所有变量维护一个typestate以及一个SMT symbol,并且只要一个变量被写入了就修改typestate。此外ESP [4]^{[4]}[4] 似乎只分析scalar数据没有考虑指针别名。
1.2.Approach
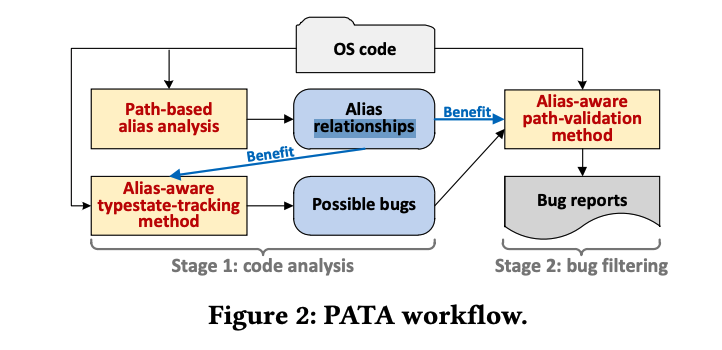
Workflow如下,主要有3部分:1.Path-Based Alias Analysis:进行别名分析;2.Alias-Aware Typestate-Tracking Method:进行IFDS分析找bug;3.Alias-Aware Path-Validation Method:进行路径条件分析。
在分析过程中,PATA会从OS代码中没有caller function的函数开始沿着CFG path分析,每个path对应1个alias graph,当遇到多个后继结点时alias graph会clone一份。每个程序点分析完时会调用typestate tracking分析是否潜在存在bug。注意:跟Pinpoint等方法一样,为了避免分析循环和递归调用带来的开销,PATA将循环和递归调用展开1次,因此理论上CFG中不存在环路,同时PATA会跳过间接调用分析。
1.2.1.别名分析
作者基于alias graph [3]^{[3]}[3] 进行别名分析。alias graph的每个结点 nnn 表示一个别名集合 Vars(n)\text{Vars}(n)Vars(n),其中集合中所有变量互为别名;每条边标有一个field或者解引用 *。下面alias graph有4个结点 n1n_1n1, n2n_2n2, n3n_3n3, n4n_4n4,推测代表的代码片段如下。这4个结点的alias set分别为:{ x }, { y }, { p, q, &x->f, &y->g }, { s, *p, *q, *(&x->f), *(&y->g) }。可以看出一个结点的别名集合基于alias graph反向遍历获得。
p = &x->f;
q = &y->g;
p = q;
s = *p;
alias graph表示为 ⟨N,E⟩\langle N, E \rangle⟨N,E⟩,用 Node(v)\text{Node}(v)Node(v) 表示变量 vvv 对应的结点,更新规则如下,其中对于所有变量 v1,v2v_1, v_2v1,v2 有:n1=Node(v1),n2=Node(v2)n_1 = \text{Node}(v_1), n_2 = \text{Node}(v_2)n1=Node(v1),n2=Node(v2)。n2→∗n1n_2 \stackrel{*}{\rightarrow} n_1n2→∗n1 表示 ∗v2*v_2∗v2 和 v1v_1v1 存在别名关系,n2→fn1n_2 \stackrel{f}{\rightarrow} n_1n2→fn1 表示 &v2->f\&v_2\text{->}f&v2->f 和 v1v_1v1 存在别名关系 。更新过程会涉及到结点的合并。
| 语句类型 | 示例 | 规则 | 说明 |
|---|---|---|---|
Copy | v1=v2v_1 = v_2v1=v2 | v1∈Vars(n2),Vars(n1)\v1v_1 \in \text{Vars}(n_2), \text{Vars}(n_1) \;\backslash \; v_1v1∈Vars(n2),Vars(n1)\v1 | v1v_1v1 被重新赋值,之前的别名关系被kill |
Store | ∗v2=v1*v_2 = v_1∗v2=v1 | E\n2→∗nx,n2→∗n1∈EE \;\backslash \; n_2 \stackrel{*}{\rightarrow} n_x, n_2 \stackrel{*}{\rightarrow} n_1 \in EE\n2→∗nx,n2→∗n1∈E | kill其它 nxn_xnx 对 v2v_2v2 的存储操作,添加 n1n_1n1 对 v2v_2v2 的存储 |
Load | v1=∗v2v_1 = *v_2v1=∗v2 | 1.Vars(n1)\v1,v1∈Vars(nx)∣∀n2→∗nx∈E\text{Vars}(n_1) \;\backslash\; v_1, v_1 \in \text{Vars}(n_x) \mid \forall n_2 \stackrel{*}{\rightarrow} n_x \in EVars(n1)\v1,v1∈Vars(nx)∣∀n2→∗nx∈E. 2.n2→∗n1∈E∣∄n2→∗nx∈En_2 \stackrel{*}{\rightarrow} n_1 \in E \mid \nexists n_2 \stackrel{*}{\rightarrow} n_x \in En2→∗n1∈E∣∄n2→∗nx∈E | 如果存在 store 操作 ∗v2=vx*v_2 = v_x∗v2=vx,那么 v1v_1v1 和 vxv_xvx 存在别名关系。否则暂时标记 v1v_1v1 和 ∗v2*v_2∗v2 别名。 |
Gep | v1=&v2->fv_1 = \&v_2\text{->}fv1=&v2->f | 1.Vars(n1)\v1,v1∈Vars(nx)∣∀n2→fnx∈E\text{Vars}(n_1) \;\backslash\; v_1, v_1 \in \text{Vars}(n_x) \mid \forall n_2 \stackrel{f}{\rightarrow} n_x \in EVars(n1)\v1,v1∈Vars(nx)∣∀n2→fnx∈E. 2.n2→fn1∈E∣∄n2→fnx∈En_2 \stackrel{f}{\rightarrow} n_1 \in E \mid \nexists n_2 \stackrel{f}{\rightarrow} n_x \in En2→fn1∈E∣∄n2→fnx∈E | 如果存在gep关系 vx=&v2->fv_x = \&v_2\text{->}fvx=&v2->f,那么 v1v_1v1 和 vxv_xvx 存在别名关系。否则暂时标记 v1v_1v1 和 &v2->f\&v_2\text{->}f&v2->f 别名。 |
Call | r=f(a1,...,an)r = f(a_1, ..., a_n)r=f(a1,...,an) | 添加 copy 关系 fpi=aif_{p_i} = a_ifpi=ai 以及 r=fretr = f_{\text{ret}}r=fret 并处理 | 添加caller实参到callee形参以己callee返回值到caller receiver的 copy 关系。 |
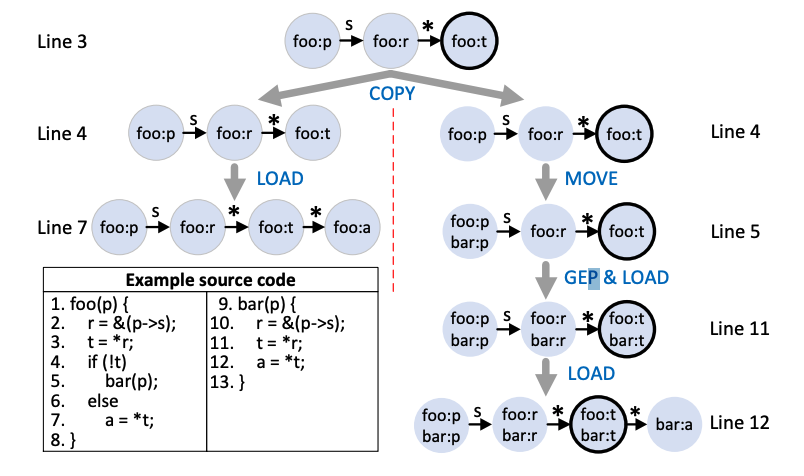
下面代码的alias graph如下
1. foo(p) {2. r = &(p->s);3. t = *r;4. if (!t)5. bar(p);6. else7. a = *t;8. }9. bar(p) {
10. r = &(p->s);
11. t = *r;
12. a = *t;
13. }
-
分析完line 3有
&p->s和r的别名关系以及*r和t的别名。 -
line 4有多个后继,会clone一份当前的alias graph。
-
执行
else分支分析完line 7后,多出别名关系*t和a。
1.2.2.Typestate Tracking
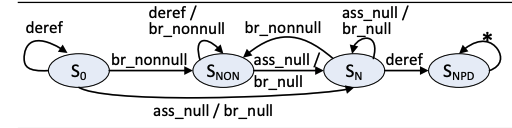
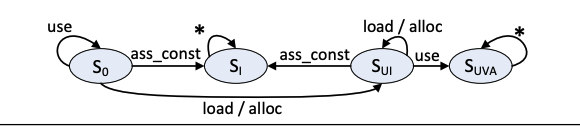
这里每个程序点分析完更新alias graph后就会进行typestate分析。Typestate分析的原理这篇blog里介绍过,这里作者定义了3个FSM来分别进行null-pointer dereferences (NPD), uninitialized-variable accesses (UVA) memory leaks (ML)的检测。这里每个alias graph上的每个结点(alias set)都会有一个type state。
| Bug类型 | 状态 | 说明 |
|---|---|---|
| 所有 | S0S_0S0 | 初始状态 |
| NPD | SNONS_{\text{NON}}SNON | 当前alias set非空 |
| NPD | SNS_{N}SN | 当前alias set为空 |
| NPD | SNPDS_{NPD}SNPD | 空指针异常 |
| UVA | SUIS_{\text{UI}}SUI | 局部变量或者heap object未初始化 |
| UVA | SIS_{I}SI | 局部变量或者heap object已初始化 |
| UVA | SUVAS_{\text{UVA}}SUVA | 访问未初始化变量 |
| ML | SNFS_{\text{NF}}SNF | heap object未被 free |
| ML | SFS_{F}SF | heap object已被 free |
| ML | SMLS_{\text{ML}}SML | 内存泄漏 |
| Bug类型 | 操作 | 说明 |
|---|---|---|
| NPD | ass_null | 分配空值 |
| NPD | br_null | 指针空的时候跳转,比如 if (!t) 时为 true 的时候 |
| NPD | br_nonnull | 指针非空的时候跳转 |
| NPD | deref | 解引用指针 |
| UVA | ass_const | 给变量分配常量值 |
| UVA | load | 从未初始化的heap object或者struct field加载值 |
| UVA | alloc | 加载局部变量的值 |
| UVA | use | 访问局部变量或者heap object |
| ML | malloc | 分配heap object |
| ML | free | 释放heap object |
| ML | ret | 执行 ret 指令 |
3个checker的FSM分别如下
NPD
UVA
ML
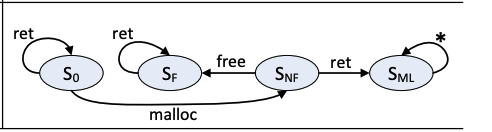
下面示例的NPD分析过程如下
1. foo(p) {2. r = &(p->s);3. t = *r;4. if (!t)5. bar(p);6. else7. a = *t;8. }9. bar(p) {
10. r = &(p->s);
11. t = *r;
12. a = *t;
13. }
line 4后在 if (!t) 的情况下跳转后到line 12后检测到NPD。PATA通过别名关系将别名变量合并到一个结点简化了typestate分析过程。
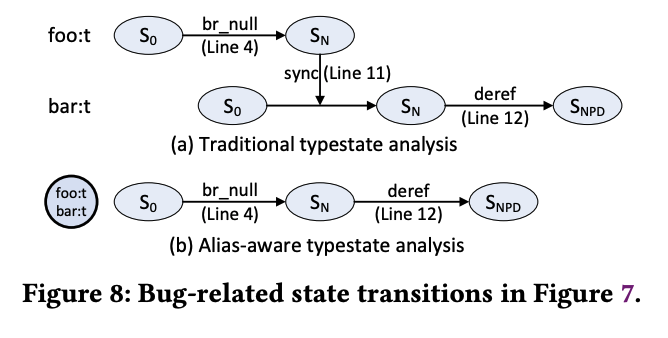
1.2.3.路径验证
作者观察到:1.潜在有bug的path只占所有path的一小部分、2.在给定的path中,Vars(n)Vars(n)Vars(n) 中所有变量应该满足相同的约束,因此这些变量可以在SMT求解器中由同一个符号表示。作者基于这两个观察提出了一个路径验证方法,推测该方法每当触发bug时会回溯当前alias graph对应的路径生成路径约束。
对于一个path作者定义了3个函数 TvarsT_{\text{vars}}Tvars, TexpT_{\text{exp}}Texp, TstmT_{\text{stm}}Tstm 来生成SMT约束,这3个函数分别处理左值、表达式、语句。用 R(v)R(v)R(v) 表示 vvv 的右值。
| 函数 | 处理对象 | 结果 |
|---|---|---|
| TvarsT_{\text{vars}}Tvars | 变量 vvv | R(v)R(v)R(v) |
| TexpT_{\text{exp}}Texp | 常量 ccc | ccc |
| TexpT_{\text{exp}}Texp | 变量 vvv | Tvars(v)T_{\text{vars}}(v)Tvars(v) |
| TexpT_{\text{exp}}Texp | 双目运算 e1⊕e2e_1 \oplus e_2e1⊕e2 | Texp(e1)⊕Texp(e2)T_{\text{exp}}(e_1) \oplus T_{\text{exp}}(e_2)Texp(e1)⊕Texp(e2) |
| TexpT_{\text{exp}}Texp | 单目运算 ⊕e\oplus e⊕e | ⊕Texp(e)\oplus T_{\text{exp}}(e)⊕Texp(e) |
| TstmT_{\text{stm}}Tstm | 恒等 v==ev == ev==e | Tvars(v)==Texp(e)T_{\text{vars}}(v) == T_{\text{exp}}(e)Tvars(v)==Texp(e) |
| TstmT_{\text{stm}}Tstm | 条件 true 跳转 brt(e)\text{br}_t(e)brt(e) | Texp(e)==1T_{\text{exp}}(e) == 1Texp(e)==1 |
| TstmT_{\text{stm}}Tstm | 条件 false 跳转 brf(e)\text{br}_f(e)brf(e) | Texp(e)==0T_{\text{exp}}(e) == 0Texp(e)==0 |
下面代码存在潜在的空指针解引用路径 2→3→4→6→72 \rightarrow 3 \rightarrow 4 \rightarrow 6 \rightarrow 72→3→4→6→7,line 7解引用 *q。在line 7处存在alias set: {t, p}, {t->f, p->f}, {q};路径约束生成时,处理完line 2有 R(q)==NULLR(q) == \text{NULL}R(q)==NULL,处理完line 3有 R(p->f)==0R(p\text{->}f) == 0R(p->f)==0,处理完line 6有 R(t->f)!=0R(t\text{->}f) != 0R(t->f)!=0,p, t 别名,因此line 3和line 6生成的约束冲突,该bug不成立。
1. void func(p, q) {
2. if (q == NULL)
3. p->f = 0;
4. t = p;
5. ......
6. if (t->f != 0)
7. *p = *q;
8. }
1.3.Evaluation
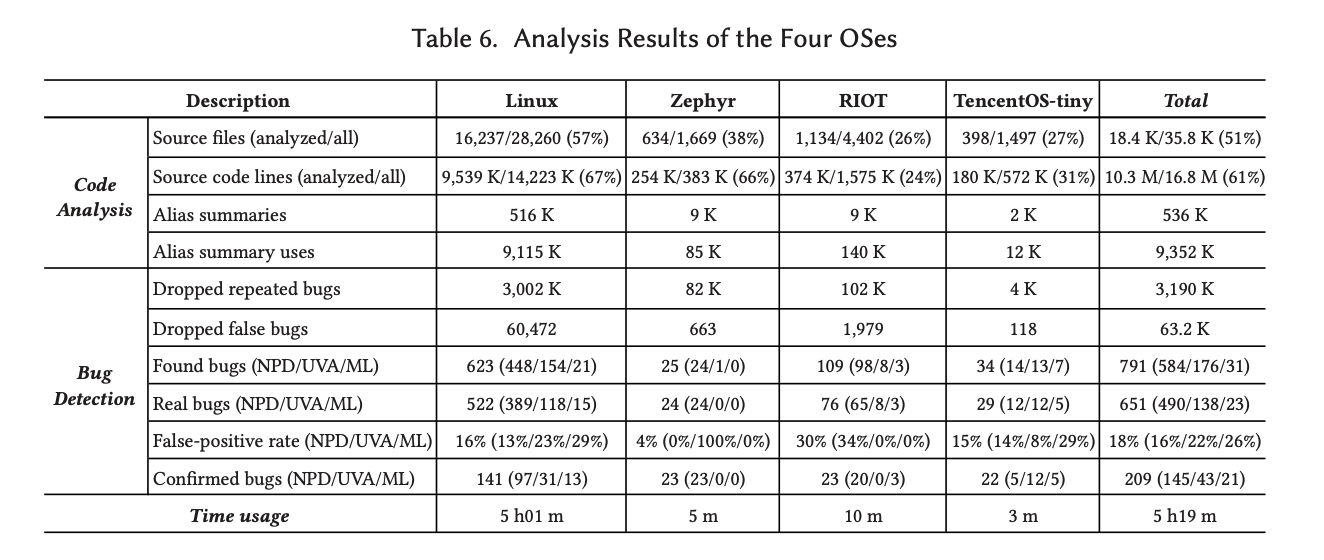
作者选择了4个OS来进行分析
| OS | Version | Source files (*.c) | LOC |
|---|---|---|---|
| Linux kernel | 5.6 | 28,260 | 14.2M |
| Zephyr | 2.1.0 | 1,669 | 383K |
| RIOT | 2020.04 | 4,402 | 1,575K |
| TencentOS-tiny | Commit 23313e | 1,497 | 572K |
PATA找到了797个bug,作者花了12小时人工验证,其中574为true positive,包括463个NPD、90个UVA、21个ML,总体误报率28%。作者随机挑选了200个linux kernel bug发送到linux community,120个IOT OS的bug全部发送给了开发者, 206个被确认(138个linux bug、23个Zephyr、23个RIOT以及22个TencentOS-tiny)。
作者对bug进行了进一步分析,发现在linux下设备驱动bug占比达到75%,而在IOT OS下,第三方库bug占比达到68%。这是由于这部分代码由第三方组织维护质量比OS社区维护的差。
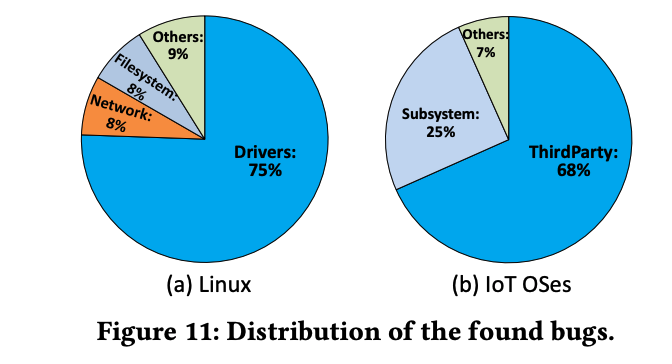
至于为什么PATA还有误报,作者总结了3点原因:
-
1.当array索引非常量时,PATA采用array-insensitive方法,
array[i+1],array[i]会被视为别名。 -
2.当涉及到复杂的算数运算以及跨多个函数的数据依赖时,PATA难以处理。循环条件也是影响PATA性能的一大因素。
-
3.忽略并发内存访问。
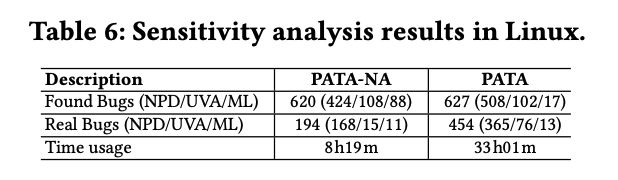
为了验证别名关系的作者,作者实现了一个alias-unaware的PATA-NA,对比后如下,可以发现PATA-NA的误报率远高于PATA。
2.SPATA
与PATA相比,SPATA面临的挑战还包括:如何在不同的calling context下区分别名关系。为SPATA针对每个function都会构造一个summary,相比PATA加速了6.7倍。这里提到了pinpoint,尽管提出的SEG加速了分析,但是在每个callsite遍历SEG依旧非常耗时。相比已有的summary-based方法,SPATA考虑了跨函数的别名情况。和PATA一样的地方是对循环、递归、数组访问、间接调用等处理。
2.1.Summary-based方法
2.1.1.Alias Summary
summary尤其需要考虑到callee对caller的side-effect,主要来自以下几个方面:
-
S1.哪些局部变量与来自caller的参数别名(
Ref/Load):下面示例中&p->f和u别名,因此对u的store操作会影响caller。 -
S2.callee会修改caller中的哪些别名信息(
Mod/Store):*u = r会将r写入到&p->f指向的区域,造成side-effect。 -
S3.哪些指令与typestate tracking相关:
*u = r同时会修改caller中别名变量的状态。 -
S4.哪些SMT约束能改变代码路径可行性:约束
r == 0会影响跨函数路径验证。
1. typedef struct {
2. int f;
3. } T;
4. void func(T* p, int r) {
5. u = &(p->f);
6. if (r == 0)
7. *u = r;
8. ....
9. }
考虑到以上4点作者对PATA中的alias graph进行了改进,目前alias graph可以表示为 ⟨N,E,ET,I,C⟩\langle N, E, \mathbb{ET}, \mathbb{I}, \mathbb{C} \rangle⟨N,E,ET,I,C⟩,在分析规则方面函数内分析和PATA基本一致,主要是更新 NNN 和 EEE,剩下3个集合暂时没更新。
-
ET\mathbb{ET}ET 为一个边标签集合, EEE 中的边包括
load/gep标签为Ref,store为Mod。EEE 中的Ref边会在后续用来进行top-down bug检测,而Mod边会在bottom-up更新alias graph中用到。 -
I\mathbb{I}I 是一个typestate-transition-related指令序列,每个指令可以更改alias graph表示的变量集合的状态。
-
C\mathbb{C}C 是一个SMT约束集合。
function summary可以表示为一个由 ⟨AS,path⟩\langle \text{AS}, \text{path} \rangle⟨AS,path⟩ 组成的列表。AS\text{AS}AS 可是精简后的alias graph。精简的方式是只保留与形参和返回值可达的 Ref/Mod 边对应的边和结点,path\text{path}path 即alias graph对应的路径。下图(b)为初始alias graph,( c )为summary(不过似乎也没修剪)。
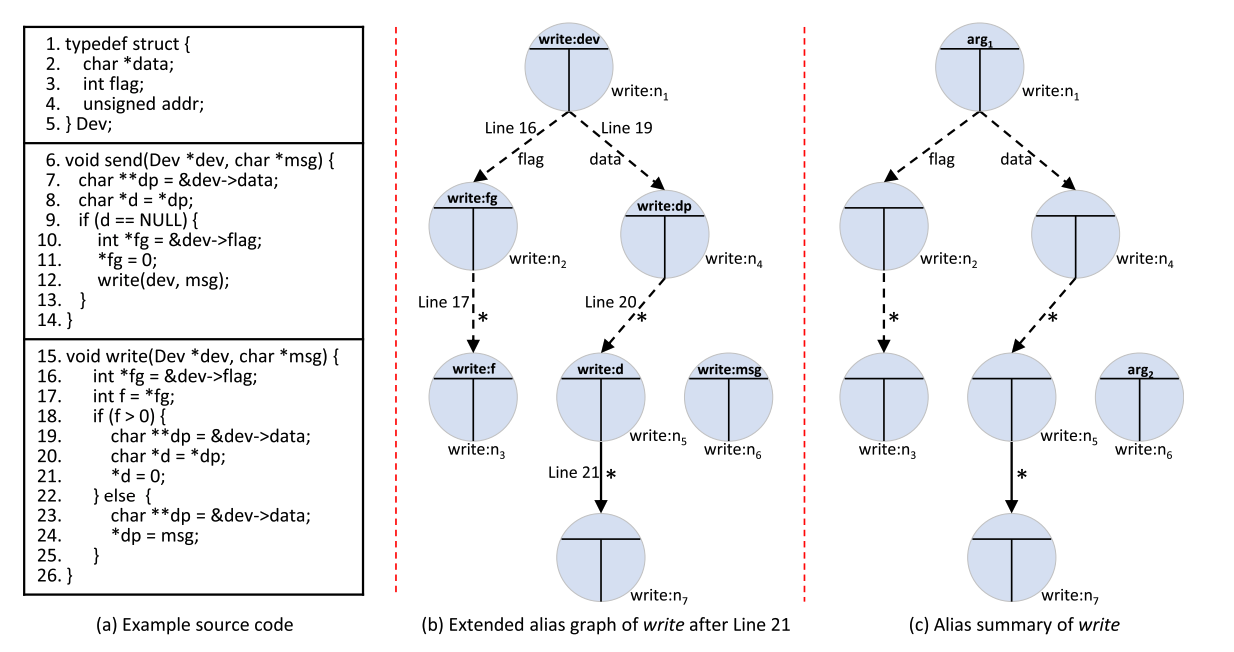
在alias graph分析规则方面,SPATA相比PATA主要差别在 call 和 ret 的处理上。在bug检测方面,SPATA包括函数内bug检测以及跨函数bug检测。跨函数检测在分析callsite触发,检测callee中的bug。
| 分析工具 | 语句类型 | 示例 | 规则 | 说明 |
|---|---|---|---|---|
| PATA | Call/Ret | r=f(a1,...,an)r = f(a_1, ..., a_n)r=f(a1,...,an) | 添加 copy 关系 fpi=aif_{p_i} = a_ifpi=ai 以及 r=fretr = f_{\text{ret}}r=fret 并处理 | 添加caller实参到callee形参以己callee返回值到caller receiver的 copy 关系。 |
| SPATA | Call | r=f(a1,...,an)r = f(a_1, ..., a_n)r=f(a1,...,an) | TopDownAnalysis(f,G)\text{TopDownAnalysis}(f, G)TopDownAnalysis(f,G), BottomUpAnalysis(f,G)\text{BottomUpAnalysis}(f, G)BottomUpAnalysis(f,G) | 通过caller -> callee 的top-down分析bug以及验证对应路径条件;通过 callee -> caller 的bottom-up分析更新caller的summary。 |
| SPATA | Ret | retv\text{ret} \; vretv | AS=GenSummary(G)\text{AS} = \text{GenSummary}(G)AS=GenSummary(G), ⟨AS,path⟩∈Summary(f)\langle \text{AS}, \text{path} \rangle \in \text{Summary}(f)⟨AS,path⟩∈Summary(f) | 生成当前 ret 指令在当前函数 fff 中的summary graph AS\text{AS}AS,并添加到 fff 的summary中,对应路径 path\text{path}path |
2.1.2.在summary中添加typestate信息
这部分就是更新某个function的summary中的 I\mathbb{I}I 集合,对于summary对应的path中的每个指令,首先找到其操作数对应的node,然后将该指令存储在找到的节点中以进行类型状态追踪,用于跨函数bug检测。
在跨函数typestate分析过程中,在callee的summary中,首先找到指向与caller alias graph中节点相同object的结点,然后利用该找到的节点中存储的指令来更新alias graph中对应结点的状态。如果该状态变化触发了某种bug,则检测到一个潜在的bug。同时,将找到的结点中存储的指令追加到alias graph的相应结点上,作为被分析函数summary的一部分。在下面示例中,17行和20行分别对 fg 和 dp 进行了 load,21行对 d 进行了 store,因此被添加到对应结点中。
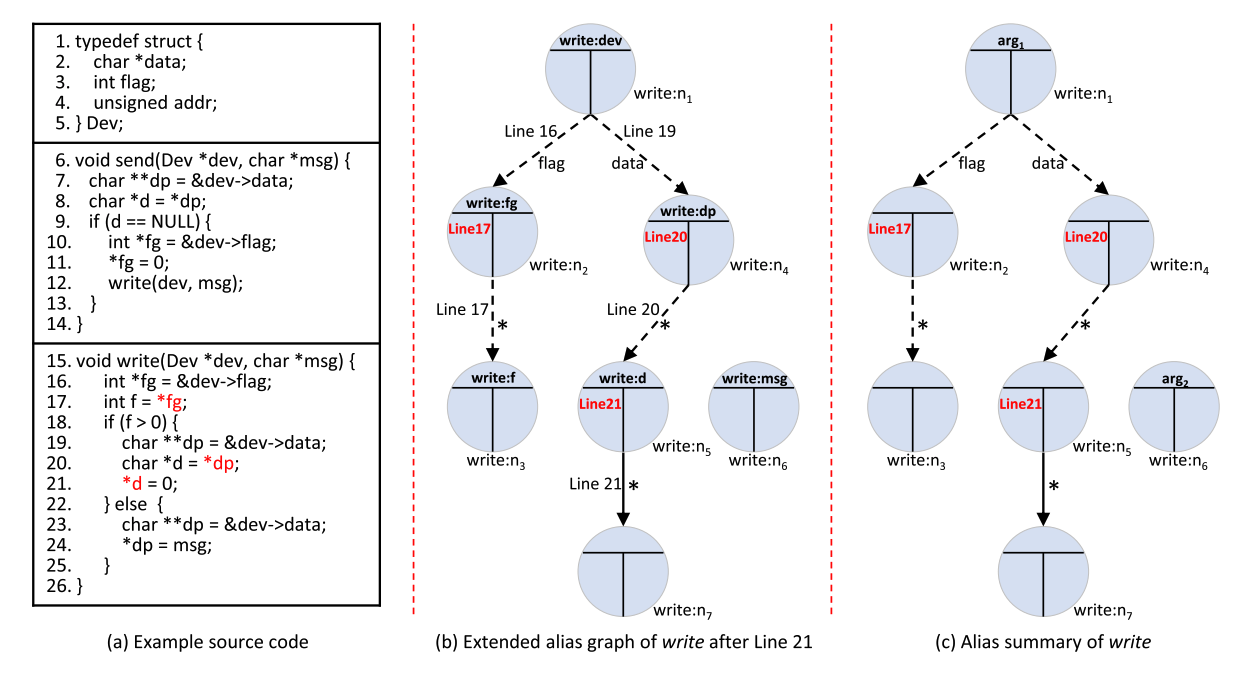
2.1.3.在summary中添加路径约束信息
在给定path下,同一个alias set中所有变量的约束相同。当分析到callsite需要merge callee summary时,在callee的summary中,首先找到与caller存在别名关系的结点,然后结合各自的summary中存储的路径约束进行检查,并添加 calleeCond == callerCond 的约束条件。下面示例中分别对 f = *fg、*d = 0 添加路径约束 X3>0X_3 > 0X3>0、X7==0X_7 == 0X7==0。
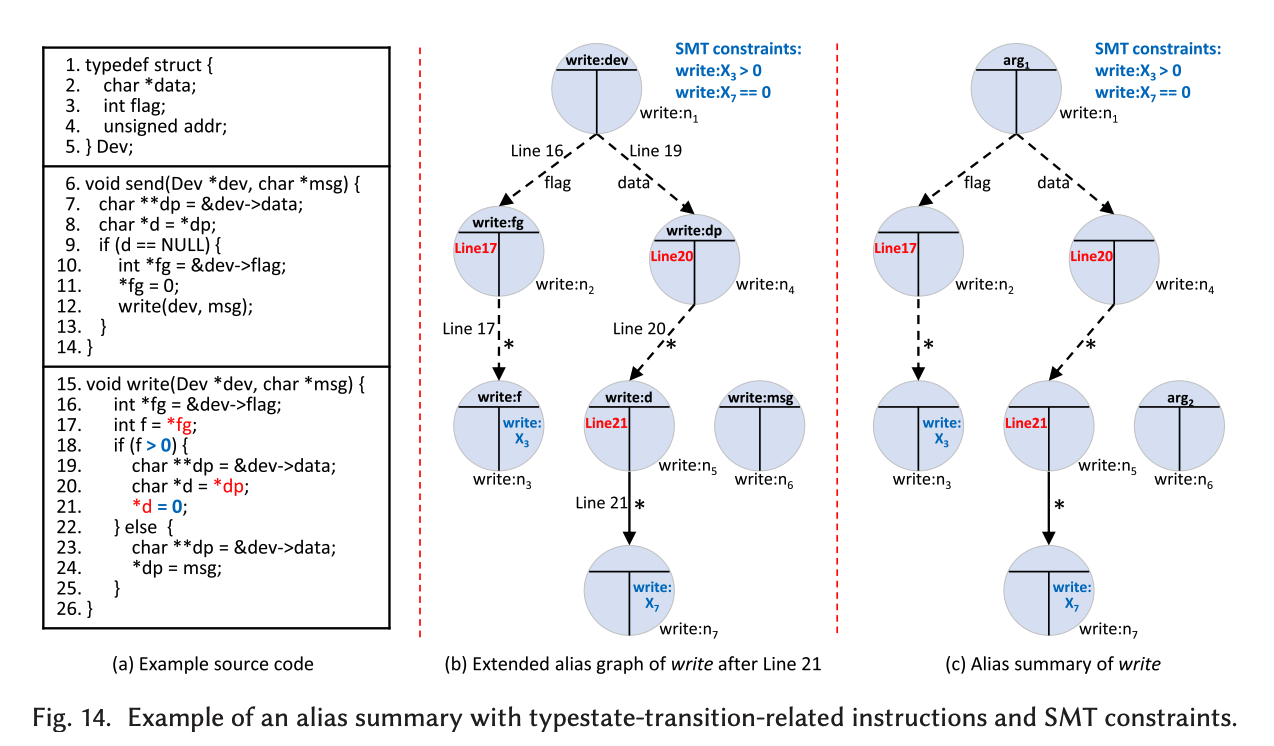
2.1.4.跨函数分析
这部分主要对应分析callsite中如何同步callee的summary,分别通过top-down分析找出callee中潜在的bug并验证路径条件可行性以及bottom-up分析更新caller的summary。分析规则分别如下,其中 ⟨N,E,ET,I,C⟩\langle N, E, \mathbb{ET}, \mathbb{I}, \mathbb{C} \rangle⟨N,E,ET,I,C⟩ 是caller的alias graph,⟨N′,E′,ET′,I′,C′⟩\langle N^{'}, E^{'}, \mathbb{ET}^{'}, \mathbb{I}^{'}, \mathbb{C}^{'} \rangle⟨N′,E′,ET′,I′,C′⟩ 是callee的alias graph,stk\text{stk}stk 和 stk′\text{stk}^{'}stk′ 分别表示caller实参和callee形参变量。

2.2.Evaluation
用的benchmark和PATA一样。检测效果如下
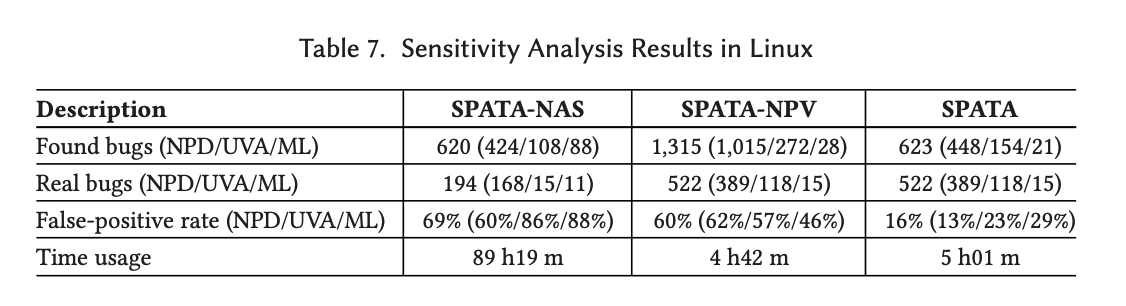
消融实验方面作者实现了non-alias、non-summary的SPATA-NAS以及non-path-validation的SPATA-NPV,对比效果如下。
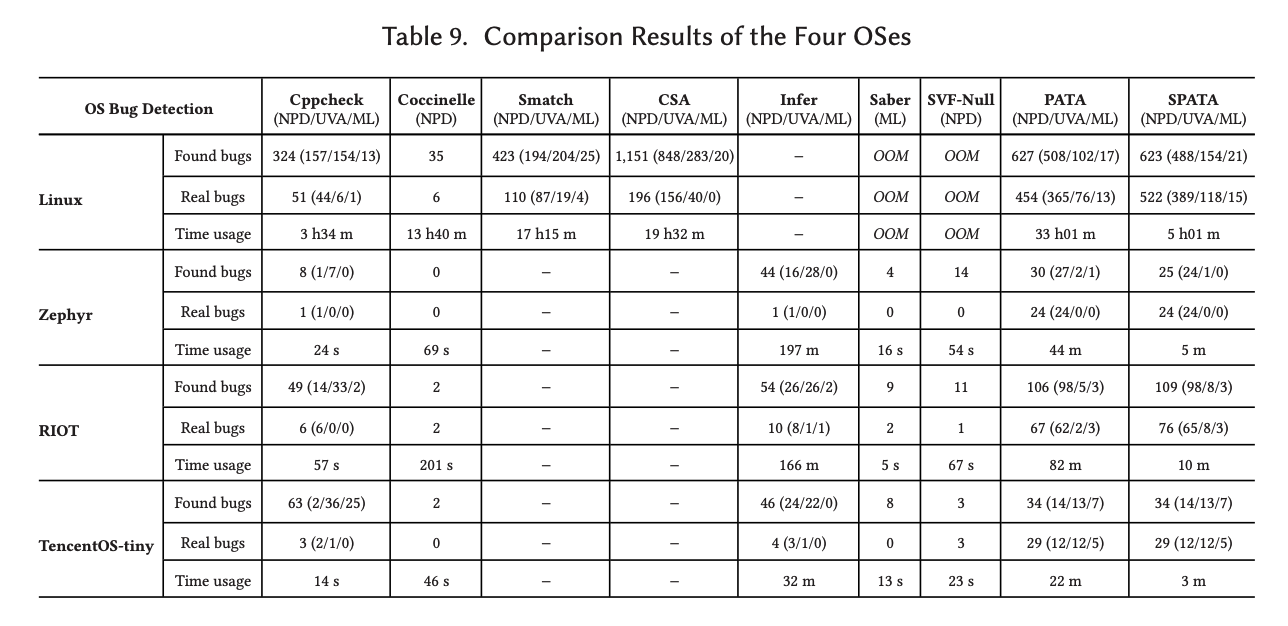
和其它工具检测工具的对比效果如下:
参考文献
[1].Li T, Bai J J, Sui Y, et al. Path-sensitive and alias-aware typestate analysis for detecting os bugs[C]//Proceedings of the 27th ACM International Conference on Architectural Support for Programming Languages and Operating Systems. 2022: 859-872.
[2].Li T, Bai J J, Sui Y, et al. SPATA: Effective OS bug detection with summary-based, alias-aware, and path-sensitive typestate analysis[J]. ACM Transactions on Computer Systems, 2024, 42(3-4): 1-40.
[3].George Kastrinis, George Balatsouras, Kostas Ferles, Nefeli Prokopaki-Kostopoulou, and Yannis Smaragdakis. 2018. An efficient data structure for must-alias analysis. In Proceedings of the 27th International Conference on Compiler Construction (CC '18). Association for Computing Machinery, New York, NY, USA, 48–58.
[4].Manuvir Das, Sorin Lerner, and Mark Seigle. 2002. ESP: Path-Sensitive Program Verification in Polynomial Time. In Proceedings of the ACM SIGPLAN 2002 conference on Programming language design and implementation (PLDI ’02). ACM.