Transformer架构:深度学习中的革命性模型
Transformer架构:深度学习中的革命性模型
摘要
Transformer架构是一种革命性的深度学习模型,它完全摒弃了传统的循环神经网络(RNN)和卷积神经网络(CNN)的设计,转而使用自注意力机制来处理序列数据。这种架构在自然语言处理(NLP)领域取得了巨大的成功,尤其是在机器翻译和文本生成任务中。本文将详细介绍Transformer架构的背景、原理、实现步骤、结果、应用场景以及未来的发展趋势。
背景
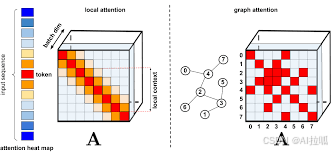
在Transformer出现之前,RNN和CNN是处理序列数据的主要模型。RNN通过递归的方式处理序列数据,但存在梯度消失和梯度爆炸的问题,难以处理长序列依赖。CNN则通过局部感受野来提取特征,但在处理长距离依赖时效果不佳。为了克服这些问题,Google的研究团队在2017年提出了Transformer架构,这是一种完全基于自注意力机制的模型。
原理
Transformer的核心思想是通过自注意力机制(Self-Attention)来捕捉序列中不同位置之间的依赖关系。自注意力机制允许模型在处理每个位置的输入时,同时考虑整个序列的信息,而不是仅仅依赖于前面的隐藏状态。这种机制使得Transformer能够并行处理序列数据,大大提高了训练速度。