(Arxiv-2025)MOSAIC:通过对应感知的对齐与解缠实现多主体个性化生成
MOSAIC:通过对应感知的对齐与解缠实现多主体个性化生成
paper title:MOSAIC: Multi-Subject Personalized Generation via Correspondence-Aware Alignment and Disentanglement
paper是字节跳动发布在Arxiv 2025的工作
Code:链接
Abstract
多主体个性化生成在图像合成中面临独特的挑战,特别是在基于多个参考主体时保持身份一致性和语义连贯性。现有方法常常由于对不同主体在共享表征空间中应如何交互的建模不足,而出现身份混淆与属性泄漏的问题。我们提出了 MOSAIC,这是一个以表征为中心的框架,通过显式的语义对应和正交特征解缠重新思考多主体生成。我们的核心洞察是,多主体生成需要在表征层面实现精确的语义对齐——确切地知道生成图像中的哪些区域应该对应于各参考主体的哪些部分。为此,我们引入了 SemAlign-MS,这是一个经过精心标注的数据集,提供了多个参考主体与目标图像之间的细粒度语义对应,而这是该领域之前所缺乏的。在此基础上,我们提出了语义对应注意力损失(semantic correspondence attention loss),用于强制实现精确的点对点语义对齐,确保每个参考主体在指定区域上的高一致性。此外,我们还提出了多参考解缠损失(multi-reference disentanglement loss),将不同主体推入正交的注意力子空间,从而防止特征干扰,同时保留个体的身份特征。大量实验表明,MOSAIC 在多个基准测试上实现了最先进(SOTA)的性能。值得注意的是,当现有方法在处理超过 3 个主体时通常会出现性能下降,MOSAIC 在 4 个及以上参考主体的场景中仍能保持高保真度,从而为复杂的多主体合成应用开辟了新的可能性。
1 Introduction

图 1 我们提出的 MOSAIC 在单主体与多主体驱动的生成任务中展现了其能力。
在可控图像合成中,多主体个性化生成面临重大挑战:既要保持身份一致性,又要避免属性纠缠。近期的一些方法尝试了不同策略来应对这一问题:MS-Diffusion [29] 和 SSR-Encoder [36] 将空间布局引导融入交叉注意力层,将不同主体绑定到专属区域;DreamO [21] 则将路由约束直接嵌入 DiT 模块中,实现架构层面的控制;而最新的 XVerse [2] 引入了针对 token 的调制偏移,从而实现独立的主体表征控制。
然而,这些方法存在一个关键局限:它们缺乏对潜在扩散表征的显式优化,既无法实现参考主体与目标图像的精确多主体对齐,也无法有效解缠参考主体之间的特征。这一问题在主体数量增加时愈发严重,大多数方法在超过 3–4 个主体时都会因特征干扰累积而显著退化。
为了理解现有方法为何失效,我们分析了多主体生成的基本需求,并识别出两个关键缺陷。首先是对应问题:如果没有显式建模参考图像的哪些具体区域应该对应目标潜在部分,模型就无法在多个主体之间保持语义一致性。其次是多参考特征整合问题:当多个主体共享同一潜在空间时,它们的表征会自然互相干扰,而现有方法没有显式机制来解缠这些混合特征。这些观察引出了一个核心问题:如何设计优化目标,在同时保持单个主体忠实度的同时,确保不同主体表征之间的可分性?
为了解决这些根本性局限,我们提出了 MOSAIC,这是一个将多主体个性化生成重新表述为表征优化问题的系统化框架。MOSAIC 的基础是通过精心构建的数据集建立显式的语义对应,该数据集在参考图像与目标图像对之间提供了密集标注的对齐点。这一对应基础使得注意力机制在参考-目标对齐和跨主体区分上能够直接获得监督——这是现有方法所缺乏的关键能力。
借助这些语义点对应,MOSAIC 实现了两个互补的优化目标:
- 对齐目标(alignment objective):在对应标签条件下对注意力分布进行交叉熵监督,从而强制建立参考与目标表征之间的精确空间映射。这一机制保证了参考图像的特征能够在语义上连贯地传播到指定的目标位置。
- 解缠目标(disentanglement objective):通过对称 KL 正则化最大化跨主体注意力的差异性,推动不同参考主体之间形成正交的注意力模式,从而有效缓解多参考场景中的跨主体特征干扰。
这一设计有效缓解了长期存在的多参考干扰问题。值得注意的是,我们的方法能够在 4 个及以上参考主体的情况下,仍然实现高质量且一致的生成,而现有方法无法达到这一水平。
我们的贡献如下:
- 我们提出了 MOSAIC,一个以表征为中心的框架,通过显式监督目标图像与参考图像之间的注意力对应,学习主体一致且解缠的表征,并结合对齐与解缠优化目标。
- 我们引入了 SemAlign-MS,这是首个大规模、全面标注的细粒度语义对应数据集,专门为多主体驱动的生成任务设计。
- 我们在多个基准上展示了显著优于现有方法的性能,尤其是在包含 4 个及以上主体的复杂场景中,同时通过即插即用的设计保持了计算效率。
2 Related works
主体驱动的图像生成。主体驱动的图像生成旨在合成既能保持参考主体的身份与外观,又能符合文本描述的图像。近期的进展主要集中在改进扩散框架中的参考编码与注意力机制。OminiControl [27] 将生成模型本身用作参考图像编码器,展示了扩散 Transformer 在保持主体一致性方面的能力。针对多主体场景,UNO [31] 提出了一个系统化的数据生成流程,而 DreamO [20] 构建了一个路由机制,以便将注意力集中在目标主体上。XVerse [2] 采用文本流调制,将参考图像转化为 token 特定的偏移,从而更好地整合主体特定的线索。然而,现有方法主要依赖于全局特征匹配,缺乏参考与目标区域之间的显式细粒度约束。这一局限常常导致空间对齐不精确、参考保真度下降以及在同时处理多个主体时出现属性纠缠。我们的工作通过引入显式的语义点对应来解决这些根本性挑战,从而实现精确的空间对齐与跨参考解缠,在增强主体一致性的同时避免了跨主体干扰。
生成中的视觉对应。视觉对应用于建立图像间语义相似区域的空间关系,是众多计算机视觉任务的基础 [14, 15, 18]。传统方法依赖于手工特征,如 SIFT [17] 与 SURF [1];而近期的深度学习方法则借助带标注数据集的监督学习 [6, 19, 32]。一个有前景的方向是利用扩散模型进行对应估计。诸如 DIFT [28]、SD-DINO [33] 与 GeoAware-SC [34] 等方法表明,预训练的扩散特征能够在无需大量监督的情况下,在不同图像间建立可靠的对应。然而,这些对应尚未被有效应用于多主体生成任务。我们的工作弥补了这一空白,首次将语义点对应引入到多主体驱动的生成中。我们建立了一个系统化流程来构建高质量的对应,并通过语义对应注意力对齐和多参考解缠机制将其显式地融入生成过程。
3 SemAlign-MS: A High-Quality Multi-Subject Dataset with Semantic Point Correspondences
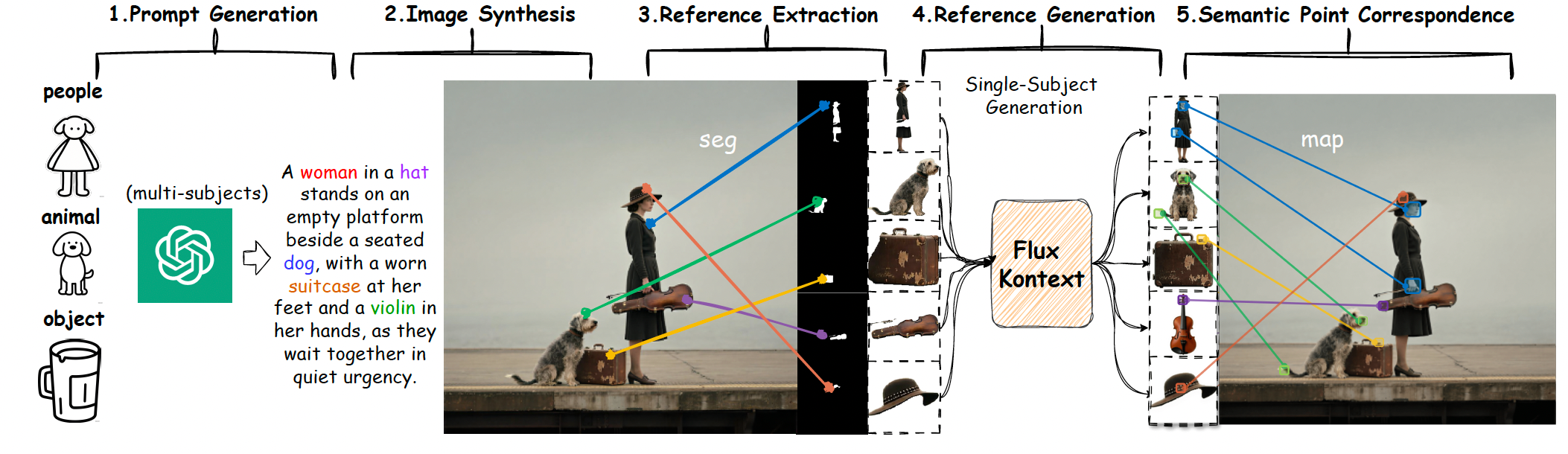
图 2 SemAlign-MS 数据集构建流程。一个五阶段的系统化流程,用于生成具有验证过语义对应关系的高质量多参考训练数据。
我们的数据构建遵循一个系统化的五阶段流程,旨在同时保证多样性与质量。首先,我们利用经过精心设计模板的 GPT-4o [9] 自动生成包含多主体的多样化提示,涵盖人物、动物、物体及其交互的各种组合,以确保全面覆盖现实应用中常见的多主体场景。
接着,这些生成的提示会通过最先进的文本到图像(T2I)模型进行图像合成,在此过程中我们实施了一个多标准的自动化筛选策略,对图像质量、主体清晰度以及构图连贯性进行评估,仅保留最高质量的合成图像。 随后,我们采用 Lang-SAM [11] 对合成图像中的所有主体进行鲁棒的开放词汇检测与分割,从而能够精确识别和分离各个主体,不论其语义类别为何,这为后续的对应关系建立提供了基础。 最后,我们使用 FLUX Kontext [13] 在保持语义一致性的前提下进行视角校正,大幅提升了数据集的多样性,并确保在不同视角与姿态下的全面外观覆盖。
一旦我们获得了大规模数据,我们会在每个目标图像和多个参考图像之间建立语义点对应,其中每个参考图像提供P(k)P^{(k)}P(k)个从参考空间中采样的语义点,这些点被映射到目标潜在空间中的相应位置,且P(k)∈NP^{(k)} \in \mathbb{N}P(k)∈N表示第kkk个参考图像的语义对应点数量。形式化地,令
D={({Iref(i,k)}k=1K,Itgt(i))}i=1N\mathcal{D} = \{(\{\mathcal{I}_{\text{ref}}^{(i,k)}\}_{k=1}^{K}, \mathcal{I}_{\text{tgt}}^{(i)})\}_{i=1}^{N} D={({Iref(i,k)}k=1K,Itgt(i))}i=1N
表示我们的数据集,其中NNN是训练批次中目标图像的总数,MMM是参考图像的最大数量,Itgt(i)\mathcal{I}_{\text{tgt}}^{(i)}Itgt(i)表示第iii个目标图像,Iref(i,k)\mathcal{I}_{\text{ref}}^{(i,k)}Iref(i,k)表示第iii个目标对应的第kkk个参考图像。当参考图像少于KKK时,我们使用黑色占位图像填充剩余位置以保持批次维度一致。对于每一对(Iref(i,k),Itgt(i))(\mathcal{I}_{\text{ref}}^{(i,k)}, \mathcal{I}_{\text{tgt}}^{(i)})(Iref(i,k),Itgt(i)),我们定义语义对应集合为:
C(i,k)={(ui,j,vi,j)}j=1P(k)(1)\mathcal{C}^{(i,k)} = \{(u_{i,j}, v_{i,j})\}_{j=1}^{P^{(k)}} \tag{1} C(i,k)={(ui,j,vi,j)}j=1P(k)(1)
其中ui,ju_{i,j}ui,j表示在参考图像Iref(k)\mathcal{I}_{\text{ref}}^{(k)}Iref(k)中的第jjj个采样点坐标,vi,jv_{i,j}vi,j表示其在目标潜在空间中的对应语义点。为防止不同参考图像映射到相同目标 token 时产生冲突,我们在不同参考图像之间强制执行对应互斥(correspondence disjointness):
V(i,k)≜{vi,j∣(ui,j,vi,j)∈C(i,k)},\mathcal{V}^{(i,k)} \triangleq \{v_{i,j} \mid (u_{i,j}, v_{i,j}) \in \mathcal{C}^{(i,k)}\}, V(i,k)≜{vi,j∣(ui,j,vi,j)∈C(i,k)},
满足
V(i,k1)∩V(i,k2)=∅,∀k1≠k2,(2)\mathcal{V}^{(i,k_1)} \cap \mathcal{V}^{(i,k_2)} = \varnothing, \quad \forall k_1 \neq k_2, \tag{2} V(i,k1)∩V(i,k2)=∅,∀k1=k2,(2)
其中V(i,k)\mathcal{V}^{(i,k)}V(i,k)表示第iii个训练样本中第kkk个参考图像的第jjj个采样点对应的目标 token 位置。该约束确保每个目标潜在位置vi,jv_{i,j}vi,j至多与一个参考图像相关联,从而避免多个参考同时竞争同一目标区域时的监督歧义。通过这一系统化流程,我们成功收集了120万对高质量图像对,并带有经过验证的语义对应,这些构成了SemAlign-MS数据集的基础。
4 Methodology
4.1 Overview of MOSAIC
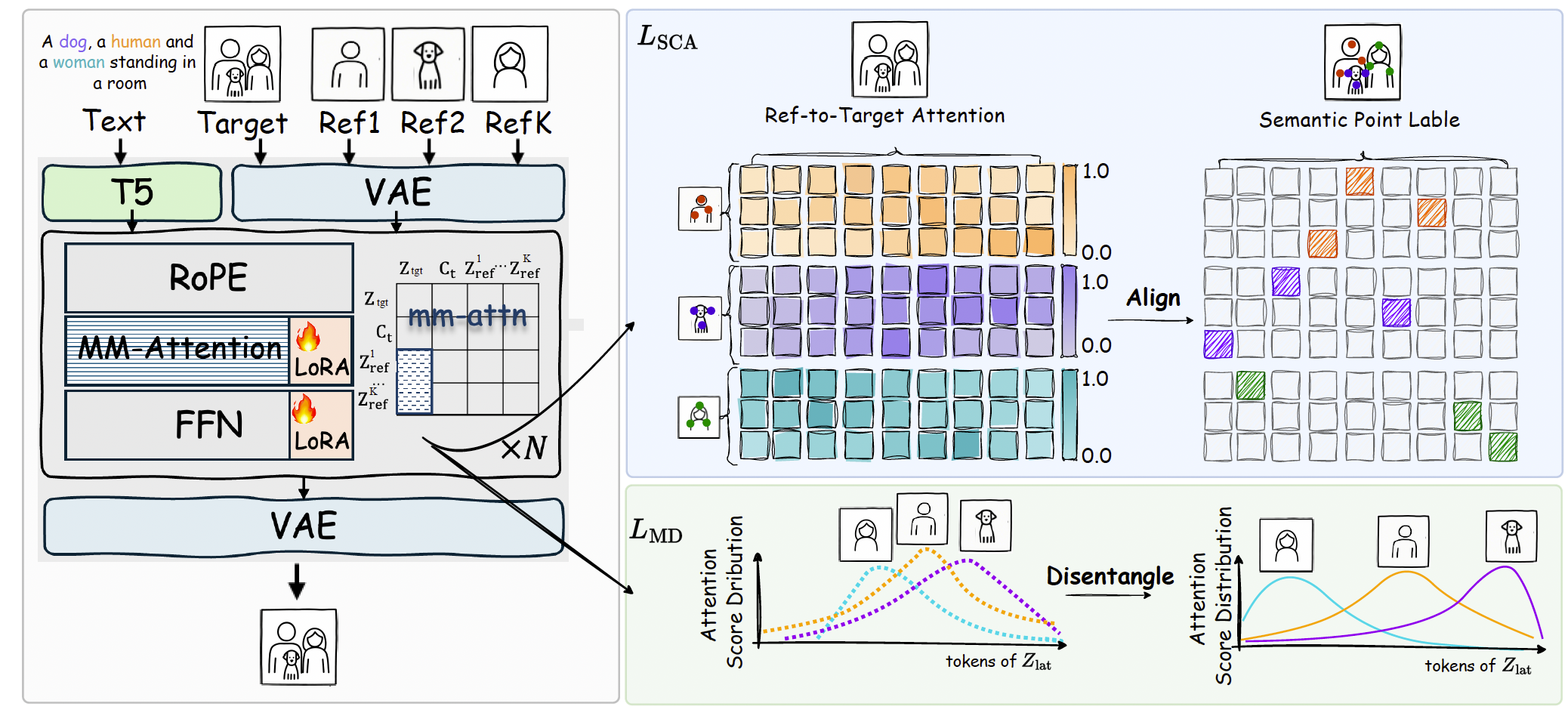
图 3 MOSAIC 框架概览。MOSAIC 引入了两个关键监督:(1) 语义对应注意力损失(蓝色区域),强制参考 token 与目标潜在空间中对应位置之间的精确点对点对齐,从而确保高度一致性;(2) 多参考解缠损失(绿色区域),最大化不同参考之间注意力分布的差异性,将每个主体推入正交的表征子空间。
架构。如图 3 所示,给定KKK个参考图像{Iref(k)}k=1K\{\mathcal{I}_{\text{ref}}^{(k)}\}_{k=1}^{K}{Iref(k)}k=1K(表示不同的主体)、一个文本提示T\mathbf{T}T以及要生成的目标图像Itgt\mathcal{I}_{\text{tgt}}Itgt。在训练过程中,我们对目标图像施加噪声,得到
Itgt=Itgt+ϵ,ϵ∼N(0,1)。\mathcal{I}_{\text{tgt}} = \mathcal{I}_{\text{tgt}} + \epsilon, \quad \epsilon \sim \mathcal{N}(0,1)。 Itgt=Itgt+ϵ,ϵ∼N(0,1)。
随后,VAE 编码器将带噪图像和所有参考图像转化为潜在表示:
ztgt=VAEenc(Itgt),zref(k)=VAEenc(Iref(k))(3)z_{\text{tgt}} = \text{VAE}_{\text{enc}}(\mathcal{I}_{\text{tgt}}), \quad z_{\text{ref}}^{(k)} = \text{VAE}_{\text{enc}}(\mathcal{I}_{\text{ref}}^{(k)}) \tag{3} ztgt=VAEenc(Itgt),zref(k)=VAEenc(Iref(k))(3)
其中k=1,…,Kk = 1, \ldots, Kk=1,…,K。文本提示由 T5 [24] 编码以获得文本嵌入Ct=T5(T)\mathbf{C}_{t} = \text{T5}(\mathbf{T})Ct=T5(T)。为了确保参考潜在变量与目标潜在变量之间的空间解缠,采用了带有不同频率基的修改版旋转位置嵌入(RoPE)[26]。
MM-Attention 中的多参考。MOSAIC 的核心在于多个参考潜在变量与目标潜在变量如何通过注意力机制交互。借鉴 OmniControl [27],我们采用了一个带 LoRA 增强的分支来处理参考,同时保持去噪分支的原始模型权重。关键的是,我们将所有参考潜在变量拼接成统一的表示,以实现联合处理。在每个 transformer 块lll中,注意力计算过程如下:
Qtgt(l),Ktgt(l),Vtgt(l)=fθ(ztgt(l)),Q_{\text{tgt}}^{(l)}, K_{\text{tgt}}^{(l)}, V_{\text{tgt}}^{(l)} = f_{\theta}(z_{\text{tgt}}^{(l)}), Qtgt(l),Ktgt(l),Vtgt(l)=fθ(ztgt(l)),
Qtext(l),Ktext(l),Vtext(l)=fϕ(Ct),(4)Q_{\text{text}}^{(l)}, K_{\text{text}}^{(l)}, V_{\text{text}}^{(l)} = f_{\phi}(\mathbf{C}_{t}), \tag{4} Qtext(l),Ktext(l),Vtext(l)=fϕ(Ct),(4)
其中fθf_{\theta}fθ与fϕf_{\phi}fϕ分别表示用于目标潜在变量与文本嵌入的 mm-attention 投影权重。对于参考图像,我们首先将它们的潜在表示拼接为:
zref(l)=[zref(1,l);zref(2,l);…;zref(K,l)]。(5)z_{\text{ref}}^{(l)} = [z_{\text{ref}}^{(1,l)}; z_{\text{ref}}^{(2,l)}; \ldots ; z_{\text{ref}}^{(K,l)}]。 \tag{5} zref(l)=[zref(1,l);zref(2,l);…;zref(K,l)]。(5)
然后通过fθf_{\theta}fθ的 LoRA 分支处理它们,该分支记作ΔθLoRA\Delta \theta_{\text{LoRA}}ΔθLoRA。
Qref(l),Kref(l),Vref(l)=fθ+ΔθLoRA(zref(l)).(6)Q_{\text{ref}}^{(l)}, K_{\text{ref}}^{(l)}, V_{\text{ref}}^{(l)} = f_{\theta + \Delta \theta_{\text{LoRA}}}(z_{\text{ref}}^{(l)}). \tag{6} Qref(l),Kref(l),Vref(l)=fθ+ΔθLoRA(zref(l)).(6)
然后,这些特征在不同模态间进行拼接,并通过多头注意力机制处理:
Q(l)=[Qtgt(l);Qtext(l);Qref(l)],Q^{(l)} = [Q_{\text{tgt}}^{(l)}; Q_{\text{text}}^{(l)}; Q_{\text{ref}}^{(l)}], Q(l)=[Qtgt(l);Qtext(l);Qref(l)],
K(l)=[Ktgt(l);Ktext(l);Kref(l)],K^{(l)} = [K_{\text{tgt}}^{(l)}; K_{\text{text}}^{(l)}; K_{\text{ref}}^{(l)}], K(l)=[Ktgt(l);Ktext(l);Kref(l)],
V(l)=[Vtgt(l);Vtext(l);Vref(l)].(7)V^{(l)} = [V_{\text{tgt}}^{(l)}; V_{\text{text}}^{(l)}; V_{\text{ref}}^{(l)}]. \tag{7} V(l)=[Vtgt(l);Vtext(l);Vref(l)].(7)
注意力得分计算为
A(l)=softmax(Q(l)(K(l))Td),A^{(l)} = \text{softmax}\left(\frac{Q^{(l)} (K^{(l)})^{T}}{\sqrt{d}}\right), A(l)=softmax(dQ(l)(K(l))T),
其中ddd是特征维度。
需要注意的是,在A(l)A^{(l)}A(l)中,参考到目标的潜在注意力子矩阵
Aref→tgt(l)∈RNref×NtgtA_{\text{ref} \to \text{tgt}}^{(l)} \in \mathbb{R}^{N_{\text{ref}} \times N_{\text{tgt}}} Aref→tgt(l)∈RNref×Ntgt
捕捉了所有参考图像中的每个 token 如何关注带噪的潜在变量,其中NrefN_{\text{ref}}Nref是所有参考图像 token 的总长度,NtgtN_{\text{tgt}}Ntgt是目标潜在变量的 token 长度。
4.2 Semantic Corresponding Attention Alignment
为了忠实保留细粒度的语义细节,尤其是在需要精确结构对应的区域,我们设计了语义对应注意力损失(SCAL),以在参考到目标的注意力机制中显式地强制点对点的语义对齐。
如图 3 所示,参考到目标的潜在注意力机制允许参考图像中的每个 token 关注带噪目标潜在表示的所有 token 位置。对于参考 token 位置uuu和目标潜在位置vvv,在所有 DiT 块NblockN_{\text{block}}Nblock上的平均参考到目标潜在注意力计算如下:
Aref→tgt[u,v]=1Nblock∑l=1Nblockexp(QuKv⊤/d)∑v=1Ntgtexp(QuKv⊤/d)(8)A_{\text{ref} \to \text{tgt}}[u,v] = \frac{1}{N_{\text{block}}} \sum_{l=1}^{N_{\text{block}}} \frac{\exp\left(Q_u K_v^{\top} / \sqrt{d}\right)}{\sum_{v=1}^{N_{\text{tgt}}} \exp\left(Q_u K_v^{\top} / \sqrt{d}\right)} \tag{8} Aref→tgt[u,v]=Nblock1l=1∑Nblock∑v=1Ntgtexp(QuKv⊤/d)exp(QuKv⊤/d)(8)
其中QuQ_uQu和KvK_vKv分别是参考 token 在位置uuu和潜在位置vvv的 query 与 key 嵌入。为了将局部参考坐标映射到拼接后的参考表示中的全局 token 索引,我们定义:
G(ui,j(k))=∑idx=1k−1N(idx)+ui,j(k)(9)G(u_{i,j}^{(k)}) = \sum_{idx=1}^{k-1} N^{(idx)} + u_{i,j}^{(k)} \tag{9} G(ui,j(k))=idx=1∑k−1N(idx)+ui,j(k)(9)
其中idxidxidx表示参考主体的索引。对于每个对应对(ui,j(k),vi,j(k))(u_{i,j}^{(k)}, v_{i,j}^{(k)})(ui,j(k),vi,j(k)),为了监督参考 token 在位置ui,j(k)u_{i,j}^{(k)}ui,j(k)的注意力能够聚焦到对应的潜在位置vi,j(k)v_{i,j}^{(k)}vi,j(k),我们定义:
LSCA=−1K∑k=1K1P(k)∑j=1P(k)logAref→tgt[G(ui,j(k)),vi,j(k)](10)\mathcal{L}_{\text{SCA}} = -\frac{1}{K} \sum_{k=1}^{K} \frac{1}{P^{(k)}} \sum_{j=1}^{P^{(k)}} \log A_{\text{ref} \to \text{tgt}}\big[G(u_{i,j}^{(k)}), v_{i,j}^{(k)}\big] \tag{10} LSCA=−K1k=1∑KP(k)1j=1∑P(k)logAref→tgt[G(ui,j(k)),vi,j(k)](10)
通过将LSCA\mathcal{L}_{\text{SCA}}LSCA融入训练目标,我们的模型被有效地引导去学习参考图像与生成图像之间的精确语义映射。这显著提升了对局部结构、纹理和细节的保真度,突破了全局相似性或隐式特征对齐的局限。
4.3 Multi-Reference Corresponding Disentanglement
虽然对齐能够保证高度一致性,但多主体驱动生成的一个关键问题是不同参考图像之间可能产生的干扰。我们引入了多参考解缠损失(multi-reference disentanglement loss, MDL),它促进不同参考之间形成差异化的注意力模式。MDL 强调区分来自不同主体的注意力图,从而防止特征混淆。
具体而言,对于第kkk个参考图像,我们在对应位置收集注意力模式。对于每个对应点(uj,vj)∈C(i,k)(u_j, v_j) \in \mathcal{C}^{(i,k)}(uj,vj)∈C(i,k):
aj(k)=[Aref→tgt[uj,t]∣t∈Ntgt]∈RNtgt(11)a_j^{(k)} = [A_{\text{ref} \to \text{tgt}}[u_j, t] \mid t \in N_{\text{tgt}}] \in \mathbb{R}^{N_{\text{tgt}}} \tag{11} aj(k)=[Aref→tgt[uj,t]∣t∈Ntgt]∈RNtgt(11)
随后,我们将这些注意力响应在每个参考内部进行聚合:
a(k)=∥1P(k)∑j=1P(k)aj(k)∥∈RNtgt(12)a^{(k)} = \left\| \frac{1}{P^{(k)}} \sum_{j=1}^{P^{(k)}} a_j^{(k)} \right\| \in \mathbb{R}^{N_{\text{tgt}}} \tag{12} a(k)=P(k)1j=1∑P(k)aj(k)∈RNtgt(12)
其中∥⋅∥\|\cdot\|∥⋅∥表示归一化操作。接着,两个参考a(i)a^{(i)}a(i)和a(j)a^{(j)}a(j)之间的距离定义为:
dist(a(i),a(j))=12DKL(a^(i)∥a^(j))+12DKL(a^(j)∥a^(i))(13)\text{dist}(a^{(i)}, a^{(j)}) = \tfrac{1}{2}\mathcal{D}_{\text{KL}}(\hat{a}^{(i)} \| \hat{a}^{(j)}) + \tfrac{1}{2}\mathcal{D}_{\text{KL}}(\hat{a}^{(j)} \| \hat{a}^{(i)}) \tag{13} dist(a(i),a(j))=21DKL(a^(i)∥a^(j))+21DKL(a^(j)∥a^(i))(13)
其中DKL\mathcal{D}_{\text{KL}}DKL表示 KL 散度。最终,我们强制不同参考之间的注意力模式彼此区分:
LMD=−1K(K−1)∑i=1K∑j=1,j≠iKdist(a(i),a(j))(14)\mathcal{L}_{\text{MD}} = -\frac{1}{K(K-1)} \sum_{i=1}^{K} \sum_{j=1, j \neq i}^{K} \text{dist}(a^{(i)}, a^{(j)}) \tag{14} LMD=−K(K−1)1i=1∑Kj=1,j=i∑Kdist(a(i),a(j))(14)
通过最大化注意力模式的差异性,该损失防止参考之间在相同注意力区域中竞争,从而减轻跨参考的特征干扰。整体损失定义为:
L=Ldiff+αLSCA+βLMD(15)\mathcal{L} = \mathcal{L}_{\text{diff}} + \alpha \mathcal{L}_{\text{SCA}} + \beta \mathcal{L}_{\text{MD}} \tag{15} L=Ldiff+αLSCA+βLMD(15)
其中Ldiff\mathcal{L}_{\text{diff}}Ldiff是 [5] 中使用的流匹配损失,α\alphaα和β\betaβ是用于平衡权重的两个系数。