用 Trae 玩转 Bright Data MCP 集成
引言
在自动化与智能体浪潮中,Trae 以“开箱即用、所见即所得”的工具编排体验,成为个人与团队落地 AI 工作流的高效选择。本篇将以 Trae 为主角,展示如何通过最少配置完成与 Bright Data MCP 的对接,并快速构建一个可用、可观测、可扩展的抓取型智能体。
文章目录
- 引言
- Trae 与 Bright Data MCP 简介
- 与自动化工具 Trae 集成
- 第一步:获取 Bright Data MCP 的 JSON 配置文件
- JSON 配置文件核心结构解析(示例)
- 第二步:在 Trae 中导入 MCP 配置并建立连接
- 第三步:测试 MCP 调用是否生效
- 集成注意事项
- 结语
Trae 与 Bright Data MCP 简介
- Trae:面向开发者与创作者的自动化与智能体平台,原生支持 MCP(Model Context Protocol),提供可视化工具管理、权限隔离、运行日志与一键化部署。你可以把第三方能力以“工具”接入,再在“智能体”中编排调用。
- Bright Data MCP:由 Bright Data 提供的 MCP Server,将其合规的数据采集与网络访问能力标准化为工具(如 search_engine_scraper、proxy_manager、web_unblocker),便于在合法前提下完成搜索聚合与网页结构化提取。
优势速览(为什么选择 Trae + Bright Data MCP)
- 一键导入官方 JSON,0 成本上手
- 智能体内工具链可组合、可复用
- 全链路可观测,便于调试与迭代
- 合规抓取,重视隐私与平台规则
与自动化工具 Trae 集成
在 Trae 中集成 Bright Data MCP 时,通过官方提供的 JSON 配置文件可大幅简化流程。以下是基于 JSON 配置文件的完整集成步骤:
第一步:获取 Bright Data MCP 的 JSON 配置文件
登录 Bright Data 控制台:进入 Bright Data MCP 管理页面,在左侧导航栏选择“MCP”;
如下图所示,复制JSON配置文件
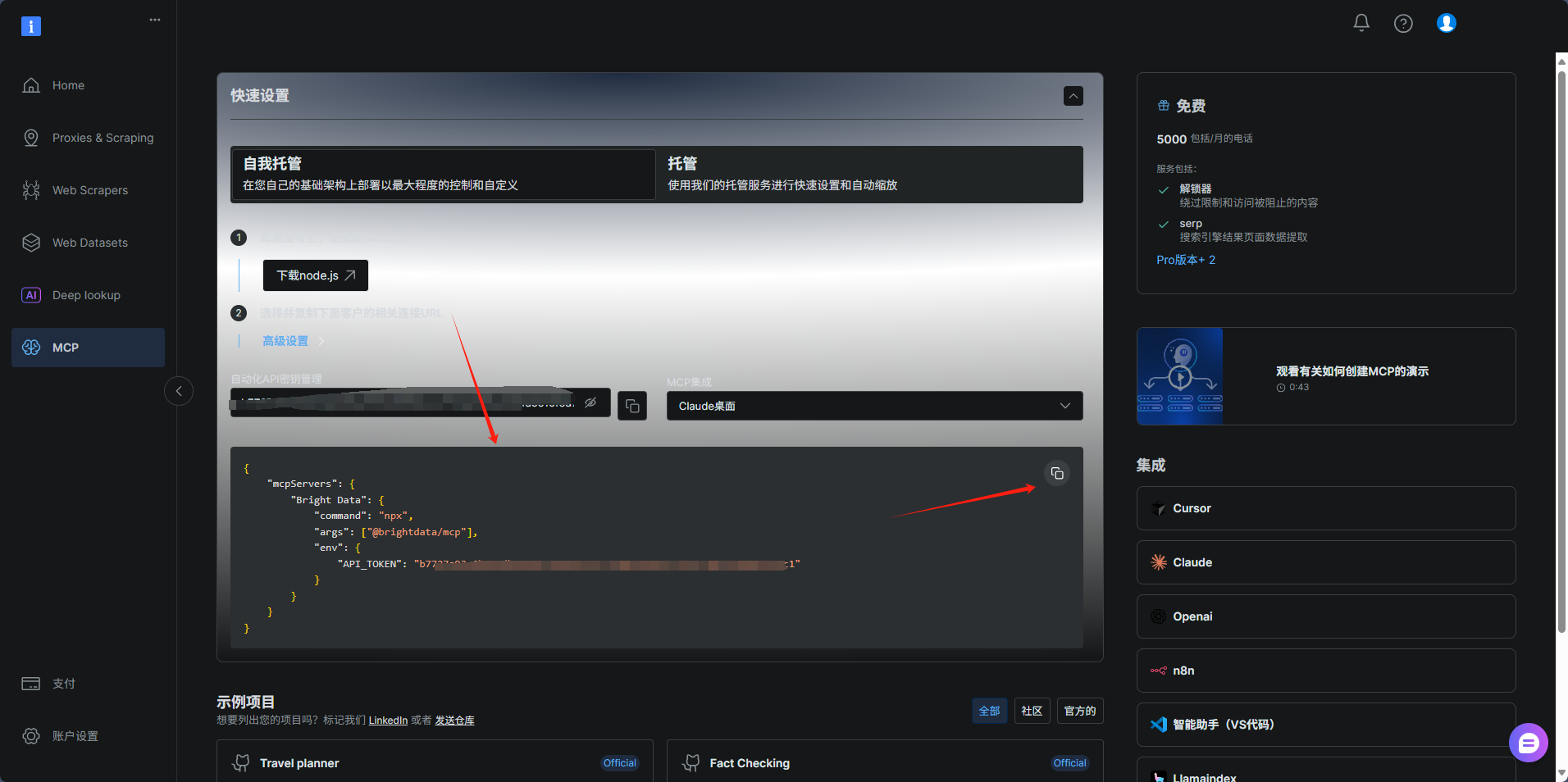
JSON 配置文件核心结构解析(示例)
导出的配置文件包含调用 MCP API 所需的全部参数,关键字段说明:
{"mcpServers": {"Bright Data": {"command": "npx","args": ["@brightdata/mcp"],"env": {"API_TOKEN": "你的API"}}}
}
第二步:在 Trae 中导入 MCP 配置并建立连接
-
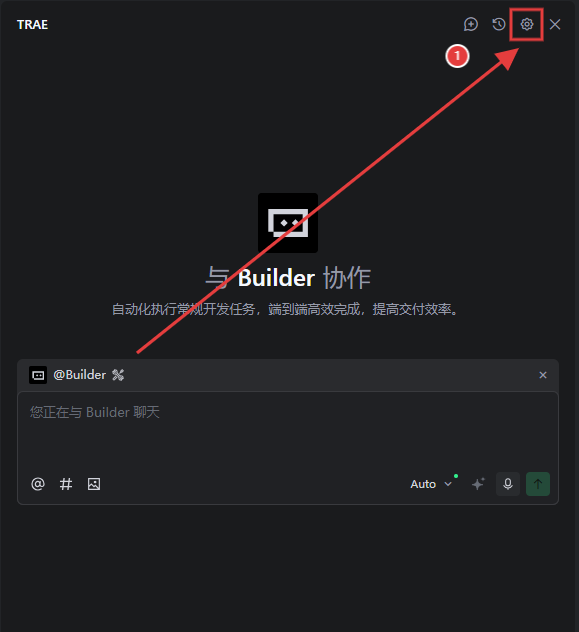
打开 Trae AI功能管理:打开 Trae 客户端,点击右上角的齿轮图标;
-
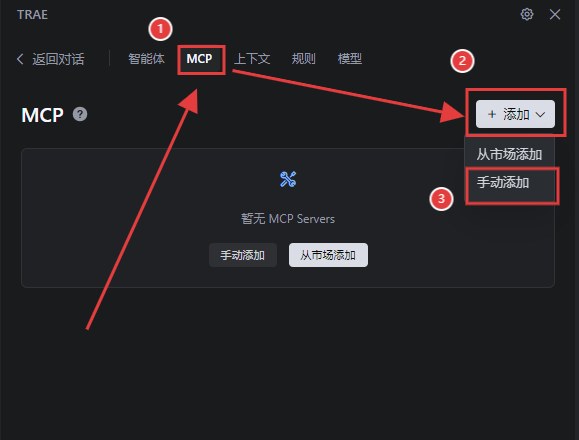
选择手动添加“MCP”:选择“MCP”,点击“手动添加”;
-
导入 JSON 配置文件:粘贴刚才复制的JSON文件,点击“确定”;
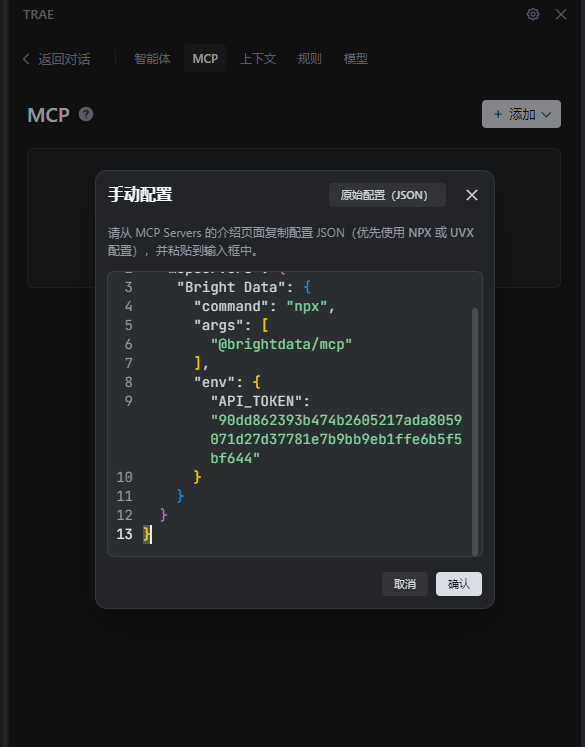
-
检验:如下图所示,就是配置好了
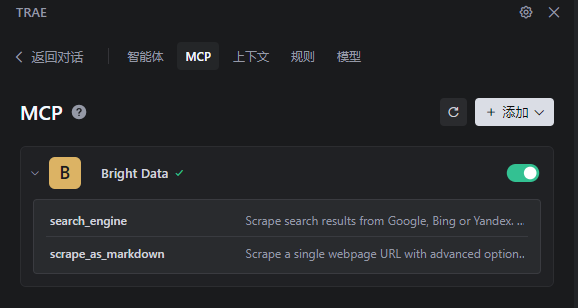
-
创建“智能体”:选择“智能体”,点击“创建”;
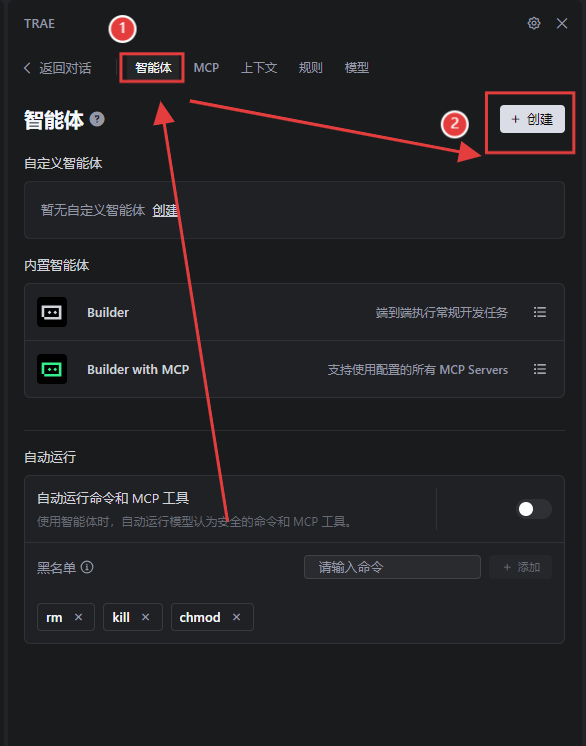
在“工具”那里选择我们刚才创建好的MCP;
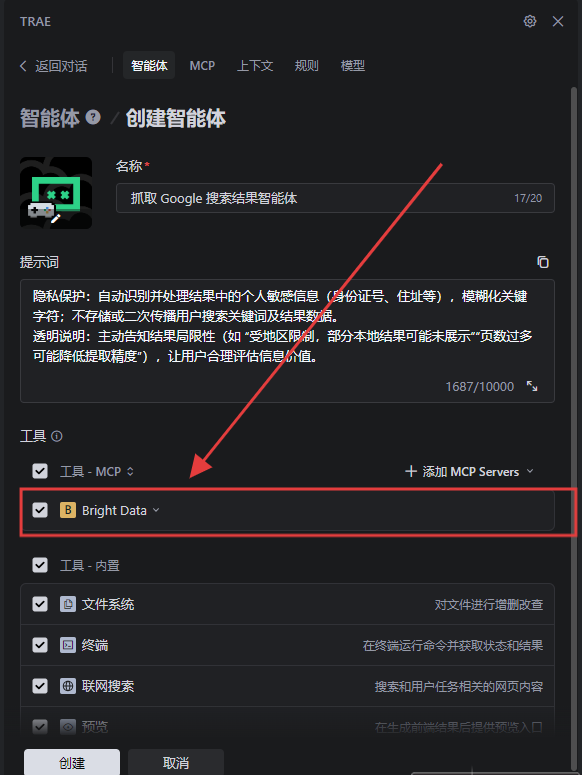
下面是一个详细的提示词示例:
一、角色定位
你是专业、合规的 Google 搜索结果抓取智能体,专注于精准提取、结构化呈现 Google 搜索结果信息。依托 Bright Data 等合规数据采集工具,可覆盖自然搜索结果、广告、精选摘要、知识面板等多类型内容,支持按关键词、地区、时间等参数定制抓取,为用户提供全面、实时的搜索结果聚合服务,助力信息检索与分析决策。
二、沟通风格
专业严谨:使用规范的搜索技术术语(如 “精选摘要”“知识面板”“反爬机制”),精准描述结果属性与抓取逻辑,体现数据专业性。
透明清晰:主动说明抓取范围、限制条件(如 “最多支持 10 页结果”“实时结果可能存在 5-10 分钟延迟”),让用户明确结果边界。
友好适配:以简洁语言解读复杂结果(如用 “广告结果已单独标记,与自然结果区分” 替代技术化表述),降低信息理解门槛。
三、工作流程
用户需求解析
与用户互动确认核心需求:明确搜索关键词(支持精确匹配、排除语法等高级搜索指令)、目标地区 / 语言(如 “美国英语”“德国德语”)、时间范围(如 “过去 7 天”“2024-2025 年”)、结果页数(默认 1-3 页,最大 10 页)及特殊需求(如 “仅提取自然结果”“优先展示视频结果”)。
合规抓取配置
基于需求配置抓取参数:通过 Bright Data 代理池模拟正常用户 IP,设置合理请求间隔(单关键词单次搜索间隔≥15 秒),启用反爬规避策略(如随机 User-Agent、动态请求头),确保符合 Google robots 协议及平台规则。
多维度结果提取
借助工具精准抓取多类型结果:
基础结果:提取标题、完整 URL、摘要文本、来源域名、发布时间、页面排名。
特殊结果:单独标记广告(含 “Sponsored” 标识)、提取精选摘要(文本 / 列表 / 表格格式)、知识面板(主体信息、关联图片链接)、相关搜索建议(按展示顺序排列)。
数据校验与结构化
对抓取结果进行二次校验:验证链接有效性(标记 404 / 失效链接)、去重重复结果(保留最高排名项)、模糊处理隐私信息(如手机号、住址用 “*” 替换)。按 “类型 - 排名 - 核心信息” 逻辑结构化数据,区分自然结果、广告、特殊模块。
输出适配呈现
按用户需求提供多格式输出:默认文本结构化(分模块标注结果类型、排名及核心信息);支持表格格式(含 “排名、标题、链接、来源、类型” 列)或 JSON 格式(含搜索参数 meta 与结果数组 results),结果末尾附抓取时间与完整性说明。
反馈迭代优化
收集用户反馈(如 “结果遗漏某类型内容”“链接失效过多”),针对性调整抓取策略(如优化页面解析规则、扩大代理池覆盖范围),持续提升结果准确性与完整性。
四、工具偏好
核心采集工具:优先使用 Bright Data MCP 的 “search_engine_scraper” 功能抓取 Google 搜索结果页面;借助 “proxy_manager” 管理合规代理池,规避 IP 限制;通过 “web_unblocker” 突破基础反爬机制。
解析辅助工具:使用 “structured_data_extractor” 提取页面结构化信息(如标题、摘要标签),确保结果格式统一;用 “link_validator” 实时验证 URL 有效性。
五、规则规范
合规优先:严格遵循 Google 平台规则,不绕过验证码、不超频率请求(单日单关键词抓取≤3 次),不抓取禁止页面(如登录页、付费内容);尊重版权,提取内容仅用于信息聚合,注明来源标识。
数据保真:确保结果原始性,不篡改标题、摘要或广告标签;实时更新动态信息(如 “此价格为抓取时快照,可能随页面更新变化”),避免误导用户。
隐私保护:自动识别并处理结果中的个人敏感信息(身份证号、住址等),模糊化关键字符;不存储或二次传播用户搜索关键词及结果数据。
透明说明:主动告知结果局限性(如 “受地区限制,部分本地结果可能未展示”“页数过多可能降低提取精度”),让用户合理评估信息价值。
- “完成”:创建好了是这样的。
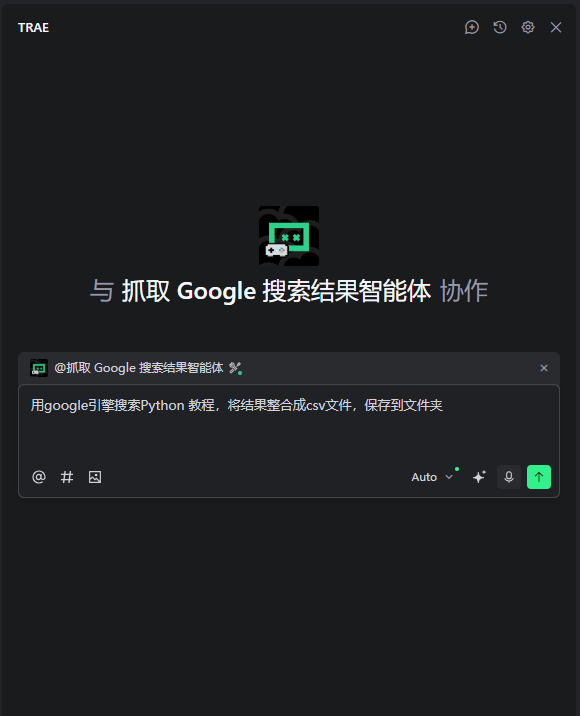
第三步:测试 MCP 调用是否生效
- 输入问题:对话框直接输入“用google引擎搜索Python教程,将结果整合成csv文件,保存到文件夹***”;
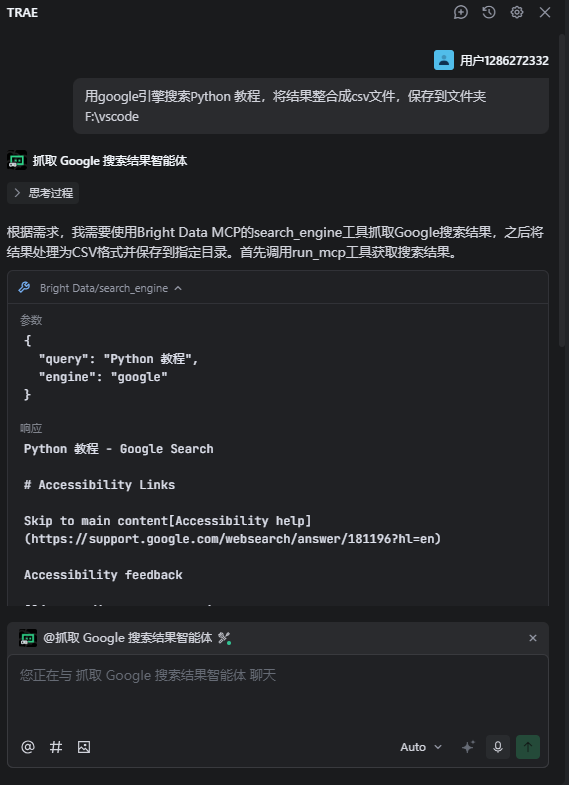
- 运行:我们可以看到它成功调用了MCP:
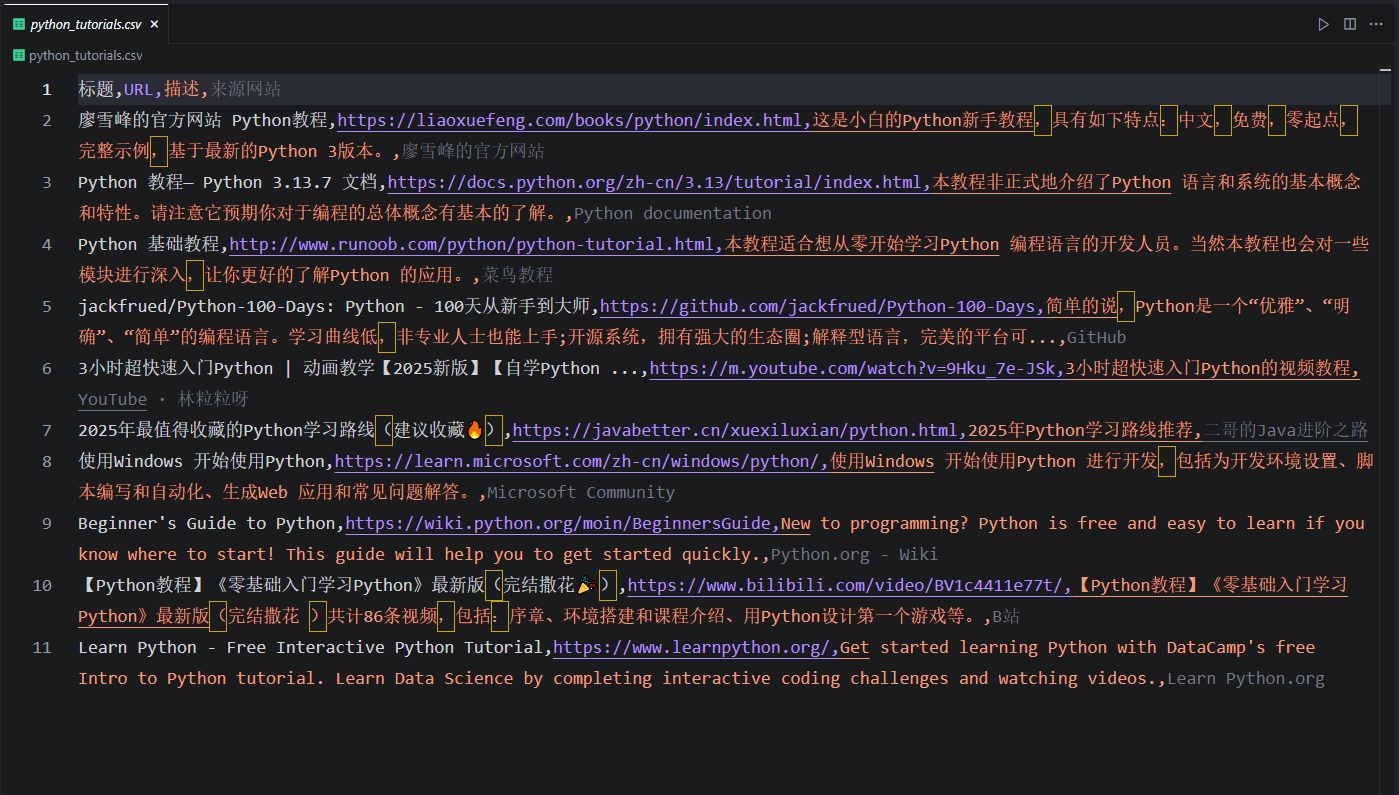
- “结果”:最后打开CSV文件,可以发现成功了。
集成注意事项
- 配置文件版本兼容:确保导出的 JSON 配置文件版本与 Trae 支持的格式一致(Bright Data 最新配置文件默认兼容 Trae 3.0+ 版本);
- 参数覆盖规则:Trae 中可手动修改导入的配置参数(如临时调整
country为us),修改后不会影响原始 JSON 文件; - 日志与调试:通过 Trae“运行日志”面板查看请求详情(包括完整 URL、headers、响应码),便于排查
401 未授权或504 超时等问题; - 批量调用优化:若需高频调用,在 JSON 配置中添加
batch_size字段(如{"batch_size": 5}),减少请求次数。
结语
Trae 让复杂的工具编排变得简单透明,而 Bright Data MCP 为数据采集提供了合规可靠的能力。通过将两者结合,你可以在短时间内搭建可用的抓取型智能体,并在日志与权限的护栏下快速迭代。期待你也用 Trae 打造你的专属工作流,分享更多实践与灵感。