Redis集群(redis cluster (去中心化))
1.集群介绍
1.1 概念
官方文档地址
https://redis.io/docs/manual/scaling/分布式存储实现中心化,数据分片存于不同master节点解决海量存储;高可用,master可挂多个slave,master故障时slave升为新master;无中心节点,客户端连任意节点操作,key不在该节点时返回转向指令指向正确节点
1.2Redis集群的优势
a.去中心化,无需代理中间件,客户端可直接来连接任意节点操作,简化架构
b.数据分片存储,将数据分散到多个master节点,支持海量数据存储与扩展
c.内置高可用机制,master节点挂接slave,故障时自动提升slave为新master,保障服务连续性
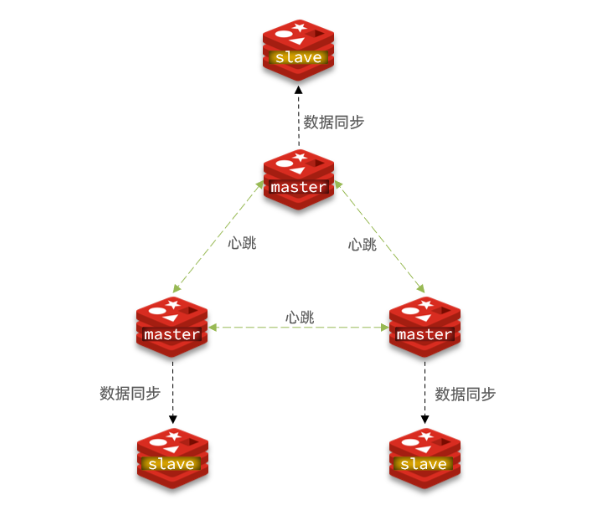
1.3数据分布式存储
Redis集群引入了哈希槽实现数据的分布式存储
Redis集群有16384个哈希槽,每个key通过CRC16校验后对16384取模来决定放置哪一个槽,集群的每一个节点负责一部分hash槽,比如当前集群有3个节点,那么:
a.节点A包含0到5500号哈希槽
b.节点B包含5501到11000号哈希槽
c.节点C包含11001到16383号哈希槽
这种结构很容易添加或者删除节点,比如想新添加个节点,只需要从节点A,B,C中得到部分哈希槽并分配到D上即可,如果想移除节点A,需要将A中的槽移到B和C节点上,然后将没有任何槽的A节点从集群中移除即可,由于从一个节点将哈希槽移动到另一个节点并不会停止服务,所以无论添加删除或者改变某个节点的哈希槽的数量都不会造成集群不可用的状态
注意:
假设具有A,B,C三个节点的集群,在没有复制模型的情况下,如果节点B失败了,那么整个集群就会以为缺少5501-11000这个范围的槽而不可用,然而如果在集群创建的时候为每个节点添加一个从节点A1,B1,C1,那么整个集群便有三个master节点和三个slave节点组成,这样在节点B失败后,集群便会选举B1为新的主节点继续服务,整个集群便不会因为槽找不到而不可用了,但是当B和B1都失败后,集群是不可用的
2.配置集群
2.1配置环境
按照如下示例,需要准备6台服务器:
| 主机 | IP地址 | 端口 |
| redis-master | 192.168.75.181/24 | 6379 |
| redis-slave | 192.168.75.181/24 | 6380 |
| redis-master1 | 192.168.75.182/24 | 6379 |
| redis-slave1 | 192.168.75.182/24 | 6380 |
| redis-master2 | 192.168.75.183/24 | 6379 |
| redus-slave2 | 192.168.75.183/24 | 6380 |
注意:本次实验用在三台服务器,每一台服务器上运行一主一从
2.2redis主机配置
2.2.1在master修改端口6379(redis自身端口号)的配置文件
[root@redis-master ~]# vim /etc/redis/redis.conf
port 6379 # 修改端口号
pidfile /var/run/redis_6379.pid # 修改pid文件名
dir /var/lib/redis # 持久化文件存放目录
dbfilename dump_6379.rdb # 修改持久化文件名
bind 0.0.0.0 # 绑定地址
daemonize yes # 让redis后台运行
protected-mode no # 关闭保护模式
logfile /var/log/redis/redis_6379.log # 指定日志
cluster-enabled yes # 开启集群功能
cluster-config-file nodes-6379.conf #设定节点配置文件名,不需要我们创建,由redis自己维护
cluster-node-timeout 10000 # 节点心跳失败的超时时间,超过该时间(毫秒),集群自动进行主从切换2.2.2启动第一个redis并查看端口号
[root@redis-master ~]# systemctl restart redis
[root@redis-master ~]# ss -lntup | grep redis
tcp LISTEN 0 511 0.0.0.0:6379 0.0.0.0:* users:(("redis-server",pid=31745,fd=6))
2.2.3在master主机启动6380端口
a.拷贝编辑好的6379端口文件给6380端口文件
[root@redis-master ~]# cp /etc/redis/redis.conf /etc/redis/redis-6380.confb.编辑6380端口文件
[root@redis-master ~]# vim /etc/redis/redis.conf
port 6380 # 修改端口号
pidfile /var/run/redis_6380.pid # 修改pid文件名
dir /var/lib/redis # 持久化文件存放目录
dbfilename dump_6380.rdb # 修改持久化文件名
bind 0.0.0.0 # 绑定地址
daemonize yes # 让redis后台运行
protected-mode no # 关闭保护模式
logfile /var/log/redis/redis_6379.log # 指定日志
cluster-enabled yes # 开启集群功能
cluster-config-file nodes-6380.conf #设定节点配置文件名,不需要我们创建,由redis自己维护
cluster-node-timeout 10000 # 节点心跳失败的超时时间,超过该时间(毫秒),集群自动进行主从切换c.启动6380端口文件将其放到后台运行
[root@redis-master ~]# redis-server /etc/redis/redis-6380.conf &d.查看是否有两个redis实例
[root@redis-master ~]# ss -lntup | grep redis
tcp LISTEN 0 511 0.0.0.0:6379 0.0.0.0:* users:(("redis-server",pid=31745,fd=6))
tcp LISTEN 0 511 0.0.0.0:6380 0.0.0.0:* users:(("redis-server",pid=31677,fd=6))
2.2.4将文件复制到两台主机依次启动
a.192.168.75.182
[root@redis-slave1 ~]# scp /etc/redis/redis.conf /etc/redis/redis-6380.conf root@192.168.75.182:/etc/redis
root@192.168.75.182's password:
redis.conf 100% 92KB 44.0MB/s 00:00
redis-6380.conf 100% 92KB 59.7MB/s 00:00
启动redis
[root@redis-slave1 ~]# systemctl restart redis
[root@redis-slave2 ~]# redis-server /etc/redis/redis-6380.conf &b.192.168.75.183
[root@redis-slave2 ~]# scp /etc/redis/redis.conf /etc/redis/redis-6380.conf root@192.168.75.183:/etc/redis
root@192.168.75.183's password:
redis.conf 100% 92KB 44.0MB/s 00:00
redis-6380.conf 100% 92KB 59.7MB/s 00:00启动redis
[root@redis-slave1 ~]# systemctl restart redis
[root@redis-slave2 ~]# redis-server /etc/redis/redis-6380.conf &注意:启动好后全部Redis服务器后,接下来就是如何把这6台服务器按预先规划的结构来组合成集群,在做接下来的操作之前,一定要先确保所有Redis实例已经成功启动,并且对应实例的节点配置文件都已经成功生成
c.查看所有主机上所有实例生成的rdb文件和nodes文件
[root@redis-slave2 ~]# ls /var/lib/redis/
dump_6379.rdb dump_6380.rdb nodes-6379.conf nodes-6380.conf
2.2.5创建集群
a.创建集群的格式
redis-cli --cluster create --cluster-replicas 副本数 主机IP:端口号 主机IP:端口号#create 创建集群
#节点总数 ÷ (replicas + 1)得到的就是master的数量
#节点列表中的前n个就是master,其它节点都是slave节点,随机分配到不同master
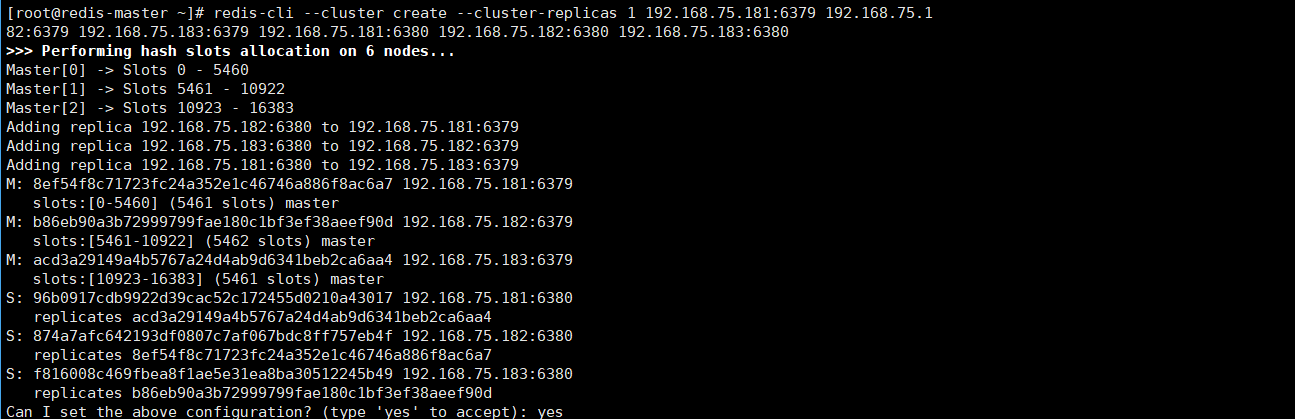
#(Redis 的分配原则是:尽量保证每个主数据库运行在不同的IP地址,每个从库和主库不在一个IP地址上)b.在redis-master上创建集群
[root@redis-master ~]# redis-cli --cluster create --cluster-replicas 1 192.168.75.181:6379 192.168.75.182:6379 192.168.75.183:6379 192.168.75.181:6380 192.168.75.182:6380 192.168.75.183:6380
运行结果图
c.查看集群状态
[root@redis-master ~]# redis-cli -p 6379 cluster nodes
8ef54f8c71723fc24a352e1c46746a886f8ac6a7 192.168.75.181:6379@16379 myself,master - 0 1757237132000 1 connected 0-5460
96b0917cdb9922d39cac52c172455d0210a43017 192.168.75.181:6380@16380 slave acd3a29149a4b5767a24d4ab9d6341beb2ca6aa4 0 1757237135118 3 connected
b86eb90a3b72999799fae180c1bf3ef38aeef90d 192.168.75.182:6379@16379 master - 0 1757237132098 2 connected 5461-10922
f816008c469fbea8f1ae5e31ea8ba30512245b49 192.168.75.183:6380@16380 slave b86eb90a3b72999799fae180c1bf3ef38aeef90d 0 1757237133000 2 connected
acd3a29149a4b5767a24d4ab9d6341beb2ca6aa4 192.168.75.183:6379@16379 master - 0 1757237133105 3 connected 10923-16383
874a7afc642193df0807c7af067bdc8ff757eb4f 192.168.75.182:6380@16380 slave 8ef54f8c71723fc24a352e1c46746a886f8ac6a7 0 1757237134112 1 connected
d.测试
#连接集群存储数据
[root@redis-master ~]# redis-cli -p 6379 -c
127.0.0.1:6379> set cluster 1
-> Redirected to slot [14041] located at 192.168.75.183:6379
OK
192.168.75.183:6379> set cluster 2
OK
192.168.75.183:6379> get cluster
"2"
注意:错误示范
在集群环境下,由于redis-cli每次录入,查询键值时,Redis都会计算该key对应的插槽值,并交给对应插槽所在的节点进行处理,如果不是该客户端对应服务器的插槽Redis会报错,并告知应前往Redis实例地址和端口
[root@redis-master ~]# redis-cli -p 6379
127.0.0.1:6379> set cluster 1
(error) MOVED 14041 192.168.75.183:6379
127.0.0.1:6379> set cluster 3
(error) MOVED 14041 192.168.75.183:6379 #结果报错
e.查看集群信息
192.168.75.183:6379> cluster nodes
874a7afc642193df0807c7af067bdc8ff757eb4f 192.168.75.182:6380@16380 slave 8ef54f8c71723fc24a352e1c46746a886f8ac6a7 0 1757237311011 1 connected
acd3a29149a4b5767a24d4ab9d6341beb2ca6aa4 192.168.75.183:6379@16379 myself,master - 0 1757237312000 3 connected 10923-16383
b86eb90a3b72999799fae180c1bf3ef38aeef90d 192.168.75.182:6379@16379 master - 0 1757237312018 2 connected 5461-10922
96b0917cdb9922d39cac52c172455d0210a43017 192.168.75.181:6380@16380 slave acd3a29149a4b5767a24d4ab9d6341beb2ca6aa4 0 1757237312018 3 connected
f816008c469fbea8f1ae5e31ea8ba30512245b49 192.168.75.183:6380@16380 slave b86eb90a3b72999799fae180c1bf3ef38aeef90d 0 1757237311000 2 connected
8ef54f8c71723fc24a352e1c46746a886f8ac6a7 192.168.75.181:6379@16379 master - 0 1757237310000 1 connected 0-5460
注意:这里的从只能实现故障切换,从只能在主出现故障的时候,并且成为主了,才能看到主之前的内容,当主和从都存在的时候,在从查找主里面的内容时,从会转发给主,然后在主上面查找,从只能起到转发的作用
2.3故障转移
2.3.1模拟redis-master宕机
[root@redis-master ~]# redis-cli -p 6379
127.0.0.1:6379> shutdown2.3.2在6380端口登录redis
#可以看到master已经切换到了192.168.75.182:6380
[root@redis-master ~]# redis-cli -p 6380
127.0.0.1:6380> cluster nodes
96b0917cdb9922d39cac52c172455d0210a43017 192.168.75.181:6380@16380 myself,slave acd3a29149a4b5767a24d4ab9d6341beb2ca6aa4 0 1757237645000 3 connected
874a7afc642193df0807c7af067bdc8ff757eb4f 192.168.75.182:6380@16380 master - 0 1757237646582 7 connected 0-5460
acd3a29149a4b5767a24d4ab9d6341beb2ca6aa4 192.168.75.183:6379@16379 master - 0 1757237646000 3 connected 10923-16383
f816008c469fbea8f1ae5e31ea8ba30512245b49 192.168.75.183:6380@16380 slave b86eb90a3b72999799fae180c1bf3ef38aeef90d 0 1757237644000 2 connected
8ef54f8c71723fc24a352e1c46746a886f8ac6a7 192.168.75.181:6379@16379 master,fail - 1757237587102 1757237582064 1 disconnected
b86eb90a3b72999799fae180c1bf3ef38aeef90d 192.168.75.182:6379@16379 master - 0 1757237646582 2 connected 5461-10922
2.3.3再次启动192.168.75.181:6379,可以发现192.168.75.181:6379已经变成从
[root@redis-master ~]# systemctl start redis
[root@redis-master ~]# redis-cli -p 6379
127.0.0.1:6379> cluster nodes
874a7afc642193df0807c7af067bdc8ff757eb4f 192.168.75.182:6380@16380 master - 0 1757237756000 7 connected 0-5460
96b0917cdb9922d39cac52c172455d0210a43017 192.168.75.181:6380@16380 slave acd3a29149a4b5767a24d4ab9d6341beb2ca6aa4 0 1757237758991 3 connected
8ef54f8c71723fc24a352e1c46746a886f8ac6a7 192.168.75.181:6379@16379 myself,slave 874a7afc642193df0807c7af067bdc8ff757eb4f 0 1757237757000 7 connected
f816008c469fbea8f1ae5e31ea8ba30512245b49 192.168.75.183:6380@16380 slave b86eb90a3b72999799fae180c1bf3ef38aeef90d 0 1757237758000 2 connected
acd3a29149a4b5767a24d4ab9d6341beb2ca6aa4 192.168.75.183:6379@16379 master - 0 1757237757985 3 connected 10923-16383
b86eb90a3b72999799fae180c1bf3ef38aeef90d 192.168.75.182:6379@16379 master - 0 1757237756977 2 connected 5461-10922
问题:如果所有某段插槽的主从节点都宕机了,Redis服务是否还能继续?
答:当发生某段插槽的主从都宕机后,如果在redis.conf配置文件中的cluster-require-full-coverage 参数的值为yes,那么整个集群都挂掉,如果参数的值为no,那么该段插槽数据全都不能使用,也无法存储,其他段可以正常存储
3.集群扩容
3.1向集群中添加两个节点(一主一从)
主节点的端口号为6381,从节点的端口号为6382
3.1.1拷贝redis配置文件到6381和6382的端口redis配置文件
[root@redis-master ~]# cp /etc/redis/redis.conf /etc/redis/redis-6381.conf
[root@redis-master ~]# cp /etc/redis/redis.conf /etc/redis/redis-6382.conf
3.1.2将文件里面的6379改为6382
[root@redis-master ~]# sed -i 's/6379/6381/' /etc/redis/redis-6381.conf
[root@redis-master ~]# sed -i 's/6379/6382/' /etc/redis/redis-6382.conf
3.1.3启动实例
[root@redis-master ~]# redis-server /etc/redis/redis-6382.conf &
[2] 32101
[root@redis-master ~]# redis-server /etc/redis/redis-6381.conf &
[3] 321063.1.4查看是否启动成功
[root@redis-master ~]# ss -lntup | grep redis
tcp LISTEN 0 511 0.0.0.0:6379 0.0.0.0:* users:(("redis-server",pid=31745,fd=6))
tcp LISTEN 0 511 0.0.0.0:6380 0.0.0.0:* users:(("redis-server",pid=31677,fd=6))
tcp LISTEN 0 511 0.0.0.0:6381 0.0.0.0:* users:(("redis-server",pid=32106,fd=6))
tcp LISTEN 0 511 0.0.0.0:6382 0.0.0.0:* users:(("redis-server",pid=32101,fd=6))
tcp LISTEN 0 511 0.0.0.0:16379 0.0.0.0:* users:(("redis-server",pid=31745,fd=8))
tcp LISTEN 0 511 0.0.0.0:16380 0.0.0.0:* users:(("redis-server",pid=31677,fd=8))
tcp LISTEN 0 511 0.0.0.0:16381 0.0.0.0:* users:(("redis-server",pid=32106,fd=8))
tcp LISTEN 0 511 0.0.0.0:16382 0.0.0.0:* users:(("redis-server",pid=32101,fd=8))
3.2添加节点
3.2.1添加节点到集群语法格式
redis-cli --cluster add-node new_host:new_port existing_host:existing_port--cluster-slave--cluster-master-id <arg>add-node命令用于添加节点到集群中,参数说明如下:
- new_host:被添加节点的主机地址
- new_port:被添加节点的端口号
- existing_host:目前集群中已经存在的任一主机地址
- existing_port:目前集群中已经存在的任一端口地址
- --cluster-slave:用于添加从(Slave)节点
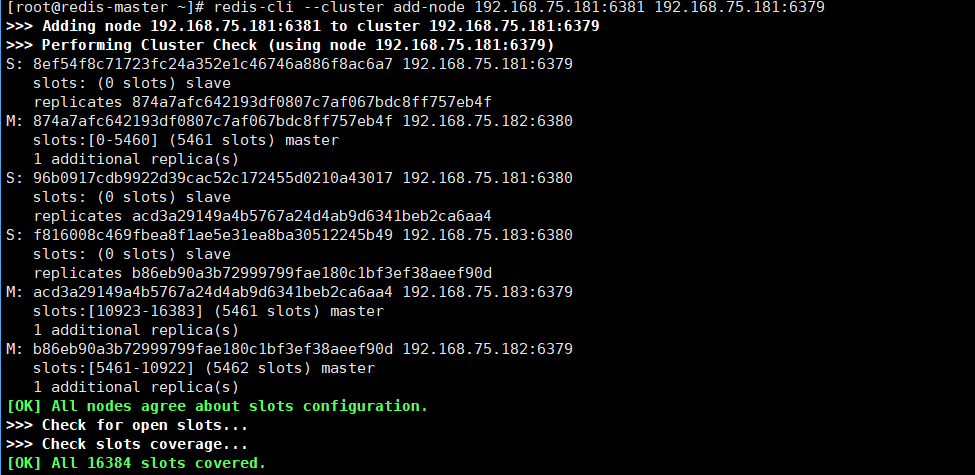
- --cluster-master-id:指定主(Master)节点的ID(唯一标识)字符串3.2.2添加主节点(6381)
[root@redis-master ~]# redis-cli --cluster add-node 192.168.75.181:6381 192.168.75.181:6379运行结果图
3.2.3查看主节点(6381)的ID值
[root@redis-master ~]# redis-cli -p 6381
127.0.0.1:6381> cluster nodes
874a7afc642193df0807c7af067bdc8ff757eb4f 192.168.75.182:6380@16380 master - 0 1757241758000 7 connected 0-5460
acd3a29149a4b5767a24d4ab9d6341beb2ca6aa4 192.168.75.183:6379@16379 master - 0 1757241759000 9 connected 10923-16383
f816008c469fbea8f1ae5e31ea8ba30512245b49 192.168.75.183:6380@16380 slave b86eb90a3b72999799fae180c1bf3ef38aeef90d 0 1757241757745 2 connected
96b0917cdb9922d39cac52c172455d0210a43017 192.168.75.181:6380@16380 slave acd3a29149a4b5767a24d4ab9d6341beb2ca6aa4 0 1757241758752 9 connected
7e969e8f9d3293f76b21c76d8d5d86bf33e1e4f5 192.168.75.181:6381@16381 myself,master - 0 1757241758000 0 connected
8ef54f8c71723fc24a352e1c46746a886f8ac6a7 192.168.75.181:6379@16379 slave 874a7afc642193df0807c7af067bdc8ff757eb4f 0 1757241757000 7 connected
b86eb90a3b72999799fae180c1bf3ef38aeef90d 192.168.75.182:6379@16379 master - 0 1757241759756 2 connected 5461-10922
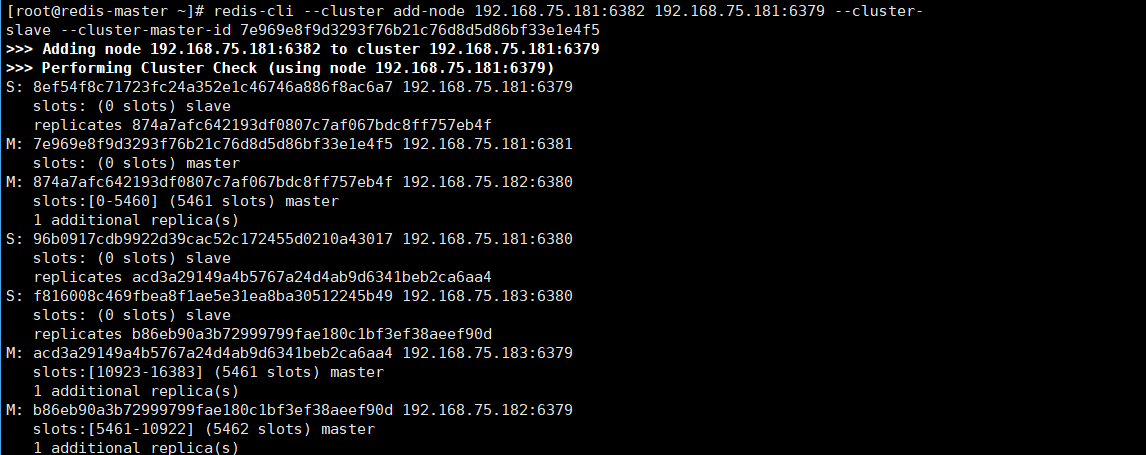
3.2.4添加从节点
#将192.168.75.181:6382作为拥有此ID的7e969e8f9d3293f76b21c76d8d5d86bf33e1e4f5
的slave身份加入192.168.75.181:6379所在集群
[root@redis-master ~]# redis-cli --cluster add-node 192.168.75.181:6382 192.168.75.181:6379 --cluster-slave --cluster-master-id 7e969e8f9d3293f76b21c76d8d5d86bf33e1e4f5
运行结果图
3.2.5数据重新分片
由于集群中增加了新节点,需要对现有的数据重新进行分片操作,重新分片的语法如下
redis-cli --cluster reshard host:port--cluster-from <arg>--cluster-to <arg>--cluster-slots <arg>--cluster-yes--cluster-timeout <arg>--cluster-pipeline <arg>--cluster-replacereshard命令用于重新分片,参数说明如下:
- host:集群中已经存在的任意主机地址
- port:集群中已经存在的任意主机对应的端口号
- --cluster-from:表示slot目前所在的master节点node ID(不能写从ID),多个ID用逗号分隔
- --cluster-to:表示需要分配节点的node ID,写master的ID
- --cluster-slot:分配的slot数量
- --cluster-yes:指定迁移时的确认输入
- --cluster-timeout:设置migrate命令的超时时间
- --cluster-pipeline:定义cluster getkeysinslot命令一次取出的key数量,不传的话使用默认值为10
- --cluster-replace:是否直接replace到目标节点3.2.6重新分片命令
#分配100个插槽(两个只能为主,其他的一律不可以)
[root@redis-master ~]# redis-cli --cluster reshard 192.168.75.181:6379 --cluster-from acd3a29149a4b5767a24d4ab9d6341beb2ca6aa4 --cluster-to 7e969e8f9d3293f76b21c76d8d5d86bf33e1e4f5 --cluster-slots 100 --cluster-yes --cluster-timeout 5000 --cluster-pipeline 10 --cluster-replace
运行结果图
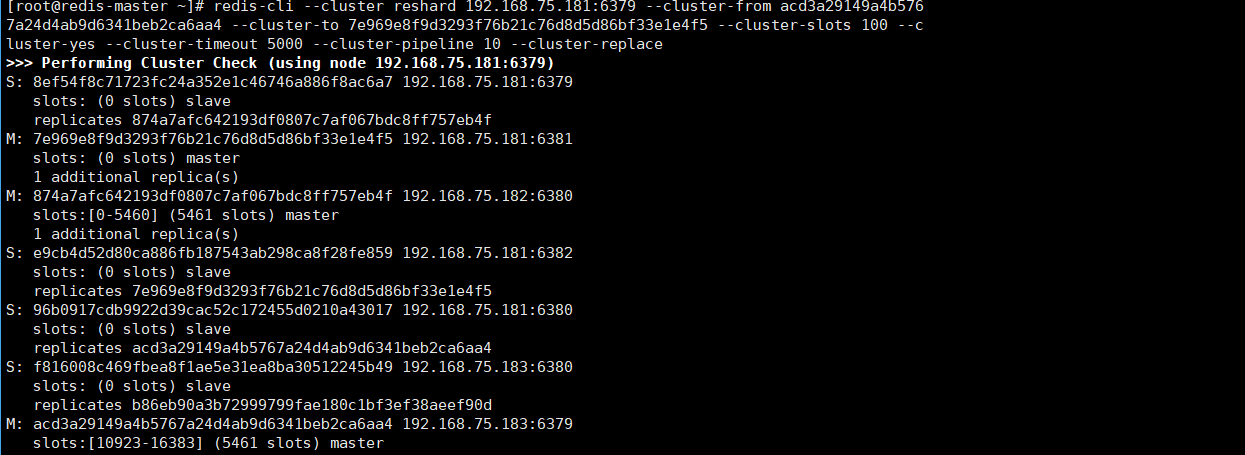
3.2.7查看插槽分配情况
[root@redis-master ~]# redis-cli -p 6379
127.0.0.1:6379> cluster nodes
7e969e8f9d3293f76b21c76d8d5d86bf33e1e4f5 192.168.75.181:6381@16381 master - 0 1757242060118 10 connected 10923-11022
874a7afc642193df0807c7af067bdc8ff757eb4f 192.168.75.182:6380@16380 master - 0 1757242061000 7 connected 0-5460
e9cb4d52d80ca886fb187543ab298ca8f28fe859 192.168.75.181:6382@16382 slave 7e969e8f9d3293f76b21c76d8d5d86bf33e1e4f5 0 1757242061000 10 connected
96b0917cdb9922d39cac52c172455d0210a43017 192.168.75.181:6380@16380 slave acd3a29149a4b5767a24d4ab9d6341beb2ca6aa4 0 1757242063136 9 connected
8ef54f8c71723fc24a352e1c46746a886f8ac6a7 192.168.75.181:6379@16379 myself,slave 874a7afc642193df0807c7af067bdc8ff757eb4f 0 1757242061000 7 connected
f816008c469fbea8f1ae5e31ea8ba30512245b49 192.168.75.183:6380@16380 slave b86eb90a3b72999799fae180c1bf3ef38aeef90d 0 1757242061124 2 connected
acd3a29149a4b5767a24d4ab9d6341beb2ca6aa4 192.168.75.183:6379@16379 master - 0 1757242062130 9 connected 11023-16383
b86eb90a3b72999799fae180c1bf3ef38aeef90d 192.168.75.182:6379@16379 master - 0 1757242061124 2 connected 5461-10922
4.集群缩容
4.1查看要被迁移的节点上有多少插槽
[root@redis-master ~]# redis-cli --cluster check 192.168.75.181:6379
192.168.75.181:6381 (7e969e8f...) -> 0 keys | 100 slots | 1 slaves.
192.168.75.182:6380 (874a7afc...) -> 1 keys | 5461 slots | 1 slaves.
192.168.75.183:6379 (acd3a291...) -> 1 keys | 5361 slots | 1 slaves.
192.168.75.182:6379 (b86eb90a...) -> 0 keys | 5462 slots | 1 slaves.
[OK] 2 keys in 4 masters.
4.2将100个哈希槽从指定主节点迁移到目标主节点
[root@redis-master ~]# redis-cli --cluster reshard 192.168.75.181:6379 --cluster-from 7e969e8f9d3293f76b21c76d8d5d86bf33e1e4f5 --cluster-to acd3a29149a4b5767a24d4ab9d6341beb2ca6aa4 --cluster-slots 100
#启动Redis集群的重分片工具
redis-cli --cluster reshard
#指定集群中任意一个正常节点的地址
192.168.75.181:6379
#指定槽位的源节点ID
--cluster-from
#指定槽位的目标节点ID
--cluster-to
#指定要迁移的哈希槽数量为 100 个
--cluster-slots 100运行结果图
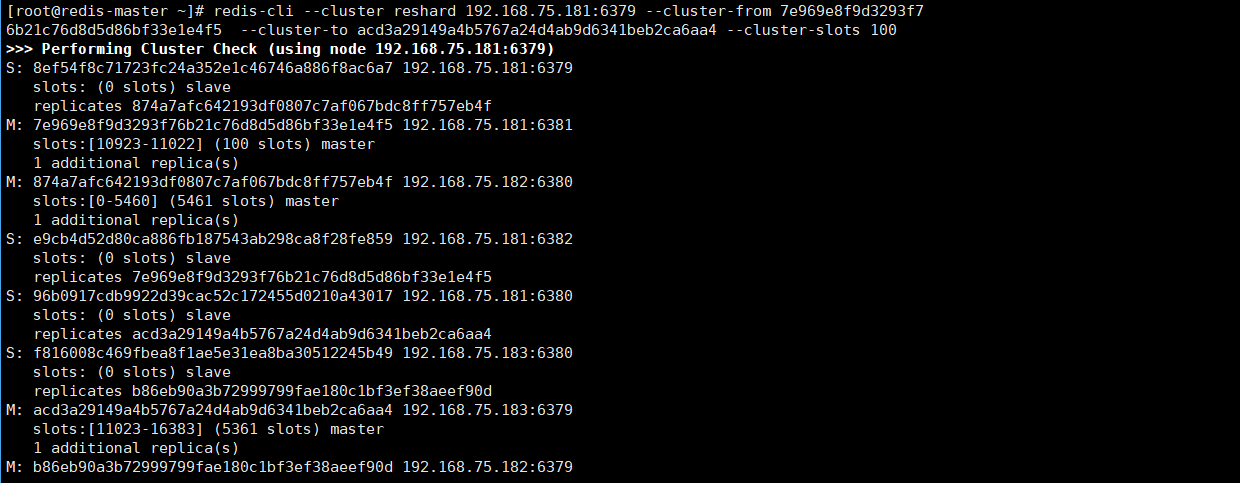
4.3删除节点
4.3.1删除节点语法格式(先删除从节点,在删除主节点,如果先删除主节点,从会故障转移)
redis-cli --cluster del-node host:port node_iddel-node命令用于从集群中删除节点,参数说明如下:- host:集群中已经存在的主机地址
- port:集群中已经存在的主机对应的端口号
- node_id:要删除的节点ID4.3.2删除从节点
[root@redis-master ~]# redis-cli --cluster del-node 192.168.75.181:6379 e9cb4d52d80ca886fb187543ab298ca8f28fe859
>>> Removing node e9cb4d52d80ca886fb187543ab298ca8f28fe859 from cluster 192.168.75.181:6379
>>> Sending CLUSTER FORGET messages to the cluster...
>>> Sending CLUSTER RESET SOFT to the deleted node.
4.3.3删除主节点
[root@redis-master ~]# redis-cli --cluster del-node 192.168.75.181:6379 7e969e8f9d3293f76b21c76d8d5d86bf33e1e4f5
>>> Removing node 7e969e8f9d3293f76b21c76d8d5d86bf33e1e4f5 from cluster 192.168.75.181:6379
>>> Sending CLUSTER FORGET messages to the cluster...
>>> Sending CLUSTER RESET SOFT to the deleted node.
4.3.4检查是否删除成功
[root@redis-master ~]# redis-cli -p 6379
127.0.0.1:6379> cluster nodes
874a7afc642193df0807c7af067bdc8ff757eb4f 192.168.75.182:6380@16380 master - 0 1757242271434 7 connected 0-5460
96b0917cdb9922d39cac52c172455d0210a43017 192.168.75.181:6380@16380 slave acd3a29149a4b5767a24d4ab9d6341beb2ca6aa4 0 1757242271000 11 connected
8ef54f8c71723fc24a352e1c46746a886f8ac6a7 192.168.75.181:6379@16379 myself,slave 874a7afc642193df0807c7af067bdc8ff757eb4f 0 1757242269000 7 connected
f816008c469fbea8f1ae5e31ea8ba30512245b49 192.168.75.183:6380@16380 slave b86eb90a3b72999799fae180c1bf3ef38aeef90d 0 1757242270429 2 connected
acd3a29149a4b5767a24d4ab9d6341beb2ca6aa4 192.168.75.183:6379@16379 master - 0 1757242269423 11 connected 10923-16383
b86eb90a3b72999799fae180c1bf3ef38aeef90d 192.168.75.182:6379@16379 master - 0 1757242269000 2 connected 5461-10922