pytest(2):测试用例查找原理详解(从默认规则到高级钩子定制)
pytest(2):测试用例查找原理详解(从默认规则到高级钩子定制)
- 前言
- 一、 什么是测试用例发现(Test Discovery)?
- 二、 Pytest 的默认用例发现规则
- 三、 Pytest 用例发现的内部流程:深入 Collection Phase(收集阶段)
- 四、 定制化你的测试发现规则
- 五、 常见问题与排查技巧 (Troubleshooting)
- 六、 总结与最佳实践
- 结语
前言
今天,我想和大家深入聊聊我们日常工作中广泛使用的 Python 测试框架——Pytest,特别是它核心的用例查找(Test Discovery)机制。
Pytest 之所以如此受欢迎,除了其简洁的断言、强大的 Fixture 系统外,其“约定优于配置”的用例自动发现能力也是关键因素之一。我们通常只需要按照简单的规则编写测试文件和函数,运行 pytest 命令,它就能精确地找到并执行所有测试。在这背后,隐藏着一套精密且可定制的规则和流程。理解这套机制,不仅能帮助我们更高效地组织测试代码,还能在遇到“用例找不到”或“不期望的用例被执行”等问题时,快速定位并解决。
本文将带你深入 Pytest 的内部,详细剖析其用例查找的全过程,包括默认规则、查找流程、定制化配置以及常见问题排查。准备好了吗?让我们开始这场探索之旅!文章较长,干货满满,建议收藏备用。
一、 什么是测试用例发现(Test Discovery)?
在软件测试自动化中,测试用例发现指的是测试框架自动识别项目中哪些代码是测试用例,并将它们收集起来准备执行的过程。相比于需要手动注册每个测试用例的古老方法(例如,某些单元测试框架需要你将测试方法添加到一个测试套件中),自动发现极大地提高了效率,尤其是在大型项目中。
Pytest 的设计哲学之一就是减少样板代码,让测试编写更自然、更符合 Pythonic 风格。它的自动发现机制正是这一哲学的体现。
二、 Pytest 的默认用例发现规则
Pytest 的核心魅力在于其强大的默认约定。如果你遵循这些约定,通常无需任何额外配置。以下是 Pytest 查找测试用例时遵循的标准规则:

-
起始点(Starting Point):
- 如果你在命令行中没有指定任何目录或文件参数,Pytest 会从当前工作目录开始查找。
- 如果你指定了文件或目录(例如
pytest tests/或pytest test_login.py),Pytest 会从指定的路径开始查找。 - Pytest 会递归地进入它找到的目录进行搜索。
-
目录递归(Directory Recursion):
- Pytest 会递归遍历所有子目录,除非目录名符合
norecursedirs的配置(默认为.*,build,dist,CVS,_darcs,{arch},*.egg,venv,.git,.hg,.tox等)。这意味着以.开头的隐藏目录、常见的构建输出目录和虚拟环境目录默认会被忽略。
- Pytest 会递归遍历所有子目录,除非目录名符合
-
测试文件(Test File)识别:
- Pytest 会查找符合
python_files配置 glob 模式的文件。默认情况下,它会查找名为test_*.py或*_test.py的 Python 文件。
- Pytest 会查找符合
-
测试类(Test Class)识别:
- 在找到的测试文件中,Pytest 会查找符合
python_classes配置名称模式的类。默认情况下,它会查找以Test开头的类(例如class TestLogin:)。 - 重要: Pytest 不会将在包含
__init__方法的类视为测试类。这是为了防止将普通的业务逻辑类或基类误识别为测试集合。如果你的测试类确实需要__init__方法(虽然不常见,通常 Fixture 是更好的选择),你需要确保基类不以Test开头,或者通过其他方式组织。
- 在找到的测试文件中,Pytest 会查找符合
-
测试函数/方法(Test Function/Method)识别:
- 在测试文件(模块级别)或测试类内部,Pytest 会查找符合
python_functions配置名称模式的函数或方法。默认情况下,它会查找以test_开头的函数或方法(例如def test_login_success():或def test_invalid_password(self):)。
- 在测试文件(模块级别)或测试类内部,Pytest 会查找符合
总结一下默认规则:
- 文件:
test_*.py或*_test.py - 类:
Test*(且不能有__init__方法) - 函数/方法:
test_*
只要你的测试代码遵循这些简单的命名约定,Pytest 就能自动发现它们。
三、 Pytest 用例发现的内部流程:深入 Collection Phase(收集阶段)
当我们运行 pytest 命令时,它首先进入的是 Collection Phase(收集阶段)。这个阶段的目标就是根据上述规则(或自定义规则)找到所有的测试项(Test Items)。这个过程大致可以分为以下几个步骤:

-
初始化与配置加载:Pytest 启动,加载命令行参数、
pytest.ini/pyproject.toml/setup.cfg配置文件以及所有conftest.py文件。配置信息(包括发现规则的定制)会影响后续的收集行为。 -
根节点与起始路径:Pytest 确定一个或多个文件系统路径作为收集的起点(基于命令行参数或当前目录)。每个起点对应一个
FSCollector(文件系统收集器)或Session根收集器。 -
递归收集(Recursive Collection):
- 从起始路径开始,Pytest 递归地遍历目录结构。
- 对于每个遇到的目录和文件,Pytest 会尝试为其创建一个 Collector 节点。
- 目录 Collector (
Package/Directory): 如果目录是一个 Python 包(包含__init__.py,虽然对于测试目录非必需,但影响导入),它可能被视为Package节点;否则是普通的Directory节点。Collector 会继续递归其子项。 - 文件 Collector (
Module): 当遇到一个 Python 文件 (.py) 时,Pytest 会调用pytest_collect_file钩子(Hook)。默认实现会检查文件名是否匹配python_files模式。如果匹配,则创建一个ModuleCollector 节点。这个Module节点负责收集该文件内部的测试项。 - 非 Python 文件: Pytest 也可以通过插件或钩子收集非
.py文件中的测试(例如.yaml文件定义的测试场景),但这超出了默认行为。
-
模块内收集 (
ModuleCollector):Module节点会导入对应的 Python 文件。- 它会遍历模块的全局命名空间,查找符合条件的类和函数:
- 查找测试类: 检查每个类名是否匹配
python_classes模式,并且该类是否没有__init__方法。如果匹配,则创建一个ClassCollector 节点。 - 查找测试函数: 检查每个函数名是否匹配
python_functions模式。如果匹配,则直接创建一个FunctionItem 节点(这是一个最终的测试项,不是 Collector)。
- 查找测试类: 检查每个类名是否匹配
-
类内收集 (
ClassCollector):Class节点负责收集其内部的测试方法。- 它会实例化测试类(如果需要,例如使用 Fixture),然后遍历类的属性。
- 检查每个方法名是否匹配
python_functions模式。如果匹配,则创建一个FunctionItem 节点(通常称为测试方法)。对于同一个类,可能会根据参数化(Parametrization)生成多个FunctionItem 节点。
-
生成测试项(Test Items)与 Node ID:
- 收集过程的最终产物是一系列的 Test Item 节点(主要是
Function节点)。每个 Item 代表一个独立的、可执行的测试单元。 - Pytest 为每个收集到的节点(包括 Collector 和 Item)分配一个唯一的 Node ID。Node ID 是一个字符串,通常反映了测试项在项目结构中的路径,例如:
tests/unit/test_auth.py::TestLogin::test_valid_credentials。这个 ID 非常重要,用于测试报告、选择性执行 (-k选项)、以及内部跟踪。
- 收集过程的最终产物是一系列的 Test Item 节点(主要是
-
收集后处理 (
pytest_collection_modifyitems):- 在所有测试项初步收集完毕后,Pytest 会调用
pytest_collection_modifyitems钩子。这个钩子允许插件或conftest.py对收集到的测试项列表进行修改,例如:- 过滤: 移除不满足特定条件的测试项(例如,基于标记
-m的过滤就是在这里实现的)。 - 重新排序: 改变测试项的执行顺序。
- 添加/修改参数化: 动态地改变测试项的参数。
- 过滤: 移除不满足特定条件的测试项(例如,基于标记
- 在所有测试项初步收集完毕后,Pytest 会调用
-
收集完成: Collection Phase 结束,Pytest 打印出收集到的测试项数量,然后进入 Execution Phase(执行阶段)。
这个流程展示了 Pytest 如何通过分层的 Collector 结构(Session -> Package/Directory -> Module -> Class)逐步深入,最终找到并组织所有的 Function 测试项。
四、 定制化你的测试发现规则
虽然默认规则在大多数情况下够用,但有时我们需要根据项目特点调整发现行为。Pytest 提供了多种方式进行定制:
- 通过配置文件 (
pytest.ini,pyproject.toml,setup.cfg)
这是最常用也推荐的方式。在项目根目录下的 pytest.ini 文件(或 pyproject.toml 中的 [tool.pytest.ini_options] 表,或 setup.cfg 中的 [tool:pytest] 段)中,你可以修改以下选项:
-
python_files: Glob 文件模式,用于匹配测试文件。可以设置多个模式,用空格分隔。[pytest]python_files = test_*.py check_*.py *_spec.py -
python_classes: Glob 类名模式,用于匹配测试类。可以设置多个模式。注意,Test前缀是默认包含的,除非你完全覆盖它。通常是添加模式,例如让Check开头的类也被识别。[pytest] python_classes = Test* Check* *Suite -
python_functions: Glob 函数/方法名模式,用于匹配测试函数。可以设置多个模式。[pytest] python_functions = test_* check_* scenario_* -
norecursedirs: 空格分隔的目录名模式列表,指定哪些目录在递归查找时应该被忽略。[pytest] norecursedirs = .git .* venv dist build tmp* docs
- 通过命令行选项
--ignore=path: 忽略指定的路径(文件或目录)。可以多次使用。pytest --ignore=tests/legacy --ignore=tests/integration/test_slow.py--ignore-glob=pattern: 忽略匹配 glob 模式的路径。可以多次使用。pytest --ignore-glob='*_vendor/*'--collect-only或--co: 只执行收集阶段,不执行测试。用于检查哪些测试会被发现,非常适合调试发现问题。配合-q(quiet) 或-v(verbose) 使用效果更佳。pytest --collect-only -q # 安静模式,只列出 Node ID pytest --collect-only -v # 详细模式,显示收集过程
- 通过
conftest.py文件
conftest.py 是 Pytest 的本地插件文件,它允许你在特定目录下定制 Pytest 行为,包括测试发现。
-
collect_ignore列表: 在conftest.py文件中定义一个名为collect_ignore的列表,包含相对于该conftest.py所在目录的子目录名或文件名字符串,这些路径将被忽略。# tests/conftest.py collect_ignore = ["helpers", "fixtures/data.py"] # 忽略 tests/helpers/ 目录和 tests/fixtures/data.py 文件 -
collect_ignore_glob列表 (Pytest 6.0+): 类似于--ignore-glob,在conftest.py中定义collect_ignore_glob列表,包含 glob 模式。# tests/conftest.py collect_ignore_glob = ["*_integration.py"] # 忽略所有以 _integration.py 结尾的文件注意:
conftest.py中的collect_ignore和collect_ignore_glob只影响其所在目录及其子目录的收集行为。 -
实现 Collection Hooks: 这是最高级的定制方式。你可以在
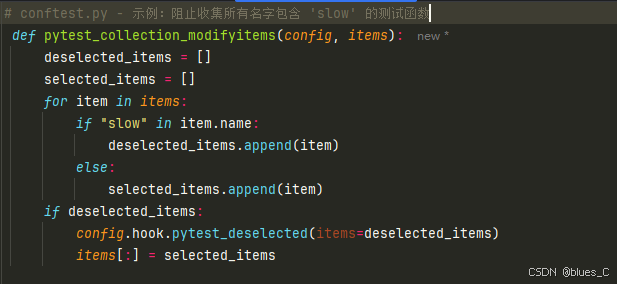
conftest.py或安装的插件中实现 Pytest 的 Collection Hooks(收集钩子)来完全控制发现逻辑。pytest_collect_file(path, parent): 决定是否要为一个给定的文件路径path创建一个ModuleCollector。你可以返回一个自定义的 Collector 节点,或者返回None来阻止默认的收集行为。这对于收集非 Python 文件中的测试很有用。pytest_pycollect_makemodule(path, parent): 定制Module节点的创建。pytest_pycollect_makeitem(collector, name, obj): 当Module或ClassCollector 发现一个潜在的测试项(函数或方法obj,名为name)时调用。你可以返回一个自定义的测试项节点、多个节点(例如用于生成测试),或者返回None来阻止该项被收集。pytest_collection_modifyitems(session, config, items): 如前所述,在收集完成后修改items列表。
使用 Collection Hooks 需要对 Pytest 的内部结构有较深的理解,通常用于插件开发或非常特殊的项目需求。
五、 常见问题与排查技巧 (Troubleshooting)
理解了原理,当遇到问题时就能更有条理地排查:
-
测试用例没有被发现:
- 检查命名: 是否符合
python_files,python_classes,python_functions的模式?(最常见) - 检查
__init__: 测试类是否包含了__init__方法? - 检查目录/文件是否被忽略: 是否在
norecursedirs配置中?是否被--ignore或conftest.py中的collect_ignore/collect_ignore_glob排除? - 检查语法错误: 文件是否能被 Python 正常导入?Pytest 在导入失败时会跳过该文件。运行
python -m py_compile path/to/your/test_file.py检查。 - 使用
pytest --collect-only -v: 这是你的首选调试工具!它会显示 Pytest 尝试收集的每个文件和目录,以及为什么某些项被跳过或收集。仔细阅读其输出。 - 检查
conftest.py: 是否有conftest.py中的钩子意外地阻止了收集?
- 检查命名: 是否符合
-
不希望执行的函数/类被当作测试执行了:
- 检查命名: 是否意外地匹配了测试命名模式?(例如,一个辅助函数名为
test_helper()) - 调整命名规则: 如果项目中有大量非测试代码遵循了默认模式,考虑在
pytest.ini中使用更精确的模式,例如python_functions = test_* test_scenario_*,避免过于宽泛的模式。 - 使用
_前缀: Python 约定,以下划线_开头的函数或类通常表示内部使用,Pytest 默认不会收集它们。可以将辅助函数命名为_helper_function()。 - 使用
pytest.mark.skip或pytest.mark.skipif: 如果只是临时不想执行某个测试,或者在特定条件下跳过,使用标记是更好的方式。
- 检查命名: 是否意外地匹配了测试命名模式?(例如,一个辅助函数名为
-
__init__.py文件在测试目录中的影响:- 在测试根目录或子目录中放置
__init__.py文件会将其标记为 Python 包。这对于使用相对导入组织测试代码或 Fixture 是有用的。 - 通常,它不会影响 Pytest 的文件和目录发现本身(Pytest 仍然会递归进入),但它会影响 Python 的模块导入行为。
- 再次强调,测试类内部的
__init__方法会导致该类不被 Pytest 收集。
- 在测试根目录或子目录中放置
-
收集阶段性能问题:
- 在非常大的项目中,如果收集阶段花费时间过长:
- 确保
norecursedirs配置包含了所有不需要检查的大型目录(如node_modules,build输出等)。 - 检查是否有低效的 Collection Hooks。
- 考虑拆分测试项目或更精细地指定要运行的测试子集。
- 使用
pytest --collect-only --durations=0查看收集各个文件的时间。
- 确保
- 在非常大的项目中,如果收集阶段花费时间过长:
六、 总结与最佳实践
Pytest 的用例发现机制是其易用性和强大功能的基石。通过理解其默认规则、内部收集流程以及各种定制化手段,我们可以:
- 高效组织测试: 遵循约定,让 Pytest 自动完成繁琐的查找工作。
- 灵活适应项目: 通过配置或钩子,让 Pytest 适应特殊的项目结构或测试类型。
- 快速定位问题: 当发现行为不符合预期时,能有针对性地排查命名、配置或
conftest.py。
几点最佳实践建议:
- 优先遵循默认约定: 这是最简单、最通用、最易于团队协作的方式。
- 保持清晰的目录结构: 例如,将所有测试放在一个
tests/目录下,按功能或模块划分小子目录。 - 谨慎使用
__init__: 避免在测试类中使用__init__方法,优先使用 Fixture 进行设置和拆卸。测试目录中的__init__.py按需使用。 - 配置文件优于钩子: 对于常见的定制需求(如修改命名模式、忽略路径),优先使用
pytest.ini等配置文件,它们更直观易懂。仅在需要深度定制或实现插件时才使用 Collection Hooks。 - 善用
--collect-only: 它是你调试发现问题的得力助手。
结语
通过本文的学习,相信你已经掌握了 Pytest 的用例发现原理,并透析Pytest测试框架内部运作。希望这本文能帮助你更熟练地驾驭 Pytest,编写出更健壮、更易于维护的自动化测试。