Proximal SFT:用PPO强化学习机制优化SFT,让大模型训练更稳定
监督微调(SFT)基本上是现在训练大模型时必走的路。不管你要让模型干什么,先用 SFT 让它学会基本的指令跟随和对话能力,然后再通过 PPO 或者 GRPO 这些强化学习方法进一步调优。
但 SFT 有个老毛病:容易过拟合。模型会死记硬背训练数据,泛化能力变差。更要命的是,经过 SFT 训练的模型在后续的强化学习阶段往往探索能力不足,这就是所谓的"熵坍塌"现象 - 模型变得过于确定,生成的内容单调乏味。
这篇论文提出了 Proximal Supervised Fine-Tuning (PSFT),本质上是把 PPO 的思路引入到 SFT 中。这个想法挺巧妙的:既然 PPO 能够稳定策略更新,那为什么不用类似的机制来稳定监督学习的参数更新呢?
SFT 到底在做什么
先说说传统的监督微调怎么回事。SFT 就是拿一堆(提示,回答)这样的数据对,让模型学会从提示生成对应的回答。

最小化模型预测的 token 分布和真实 token 之间的交叉熵损失。但问题在于,如果训练数据和预训练数据的分布差异比较大,每一步的参数更新可能都很激进,导致模型忘记之前学到的通用能力。


PPO vs. GRPO
这种激进更新还会引发熵坍塌。简单说就是模型在选择下一个 token 时变得过于自信,几乎没有不确定性。这样一来,模型生成的内容就会变得非常可预测,缺乏多样性。更糟的是这种低熵状态会让模型在后续的强化学习训练中失去探索新策略的能力。
从强化学习的角度看语言建模
要理解 PSFT,得先把语言生成过程理解成一个马尔可夫决策过程(MDP)。这听起来很抽象,但其实挺直观的:

在语言生成的 MDP 中,状态空间包含智能体可能处于的所有可能状态,动作空间包含智能体可以采取的所有可能动作或移动,转移概率
P(s'|s, a)
表示当智能体采取动作
a
时,从状态
s
移动到
s'
的可能性。
具体到语言模型:状态
s(t)
就是当前的上下文(输入 query 加上已经生成的所有 token),动作
a(t)
就是要生成的下一个 token,转移概率是确定性的(等于1),因为选定 token 后新状态就确定了。
大语言模型的输出分布
π(θ)
就是我们的策略。对于输入
x
,模型生成输出
y
的联合概率是:
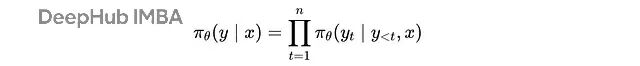
给定查询 ‘x’ 生成输出 ‘y’ 的联合概率是在每个时间步 ‘t’ 给定其前置上下文 (y(<t), x) 下生成每个令牌 ‘y(t)’ 的概率的乘积。
SFT 的损失函数就是标准的交叉熵:
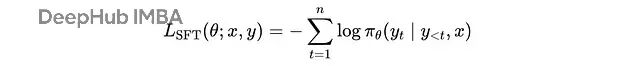
每个提示-完成对 (x, y) 的 SFT 损失
这里
y(t)
是时间步
t
的生成令牌,
n
是生成令牌的总数,
y(<t), x
是每个时间步的上下文,
π(θ)
是参数为
θ
的大语言模型。
对整个训练集,SFT 损失可以写成:
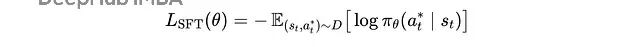
训练期间使用梯度下降最小化的 SFT 损失
这里
s(t)
是时间步
t
的上下文,
a*(t)
表示正确的下一个令牌。
SFT 其实是策略梯度的特例
强化学习里有三大类算法:基于价值的方法(比如 Q-learning)、策略梯度方法(比如 REINFORCE)、还有混合方法(比如 Actor-Critic)。
策略梯度方法的目标函数是:
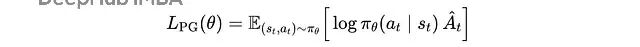
强化学习训练期间使用梯度上升最大化的策略梯度目标
这里
s(t), a(t)
是从当前策略采样的状态-动作对,
log π(θ)(a(t)|s(t))
是策略采取动作的对数概率,
Â(t)
是优势函数,告诉我们这个动作比平均水平好多少。
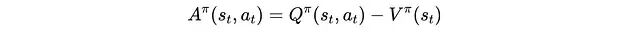
优势函数是在特定状态下采取动作的 Q 函数与给定状态的价值函数之间的差值。
如果
Â(t) > 0
,说明这个动作比预期好,训练会增加它的概率。
仔细看看,SFT 其实就是策略梯度的简化版本:
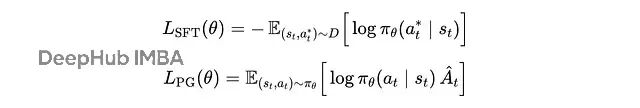
SFT 损失 vs. 策略梯度目标
区别在于:SFT 不是从策略采样轨迹,而是从固定数据集采样;SFT 把优势函数固定为 1,也就是假设数据集里的动作都是"好的"。
从 REINFORCE 到 PPO
传统的策略梯度方法比如 REINFORCE 有个问题:如果某一步更新太大,新策略可能偏离旧策略太远,导致训练不稳定。
TRPO(信任区域策略优化)通过引入 KL 散度约束来解决这个问题:
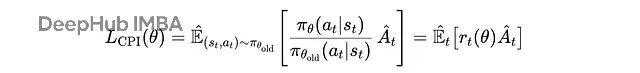
TRPO 的代理目标(保守策略迭代)目标,在强化学习训练期间使用梯度上升最大化,其中
r(t)(θ)
是重要性采样比率。
这里用重要性采样来修正新旧策略之间的差异,同时用 KL 散度约束来限制更新幅度:
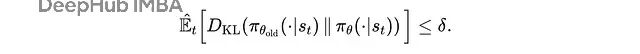
在 TRPO 中,代理目标在使用新策略
π(θ)
和旧策略
π(θ)(old)
之间的 KL 散度对策略更新大小的约束下最大化。
但 TRPO 计算量太大,不太实用。PPO 就简单多了,直接在目标函数里加个 clipping:
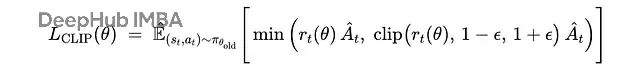
PPO 中最大化的裁剪代理目标,其中
r(t)(θ)
是重要性采样比率,ϵ 通常是一个小值(例如,0.2)。在 TRPO 和 PPO 中,优势
Â(t)
的近似值使用广义优势估计(GAE)计算。
PPO 通过裁剪重要性采样比率来防止策略更新过大,既简单又有效。
PSFT:给 SFT 加上 PPO 的稳定性
既然知道了 SFT 是策略梯度的特例,那我们能不能给它也加上 PPO 的稳定性机制?答案就是 PSFT。
PSFT 的目标函数是:
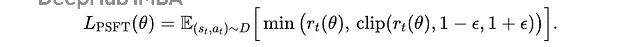
近似监督微调(PSFT)目标
展开重要性采样比率:
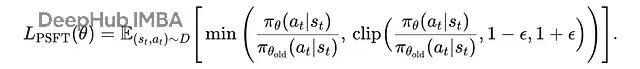
展开的近似监督微调(PSFT)目标
这个设计很巧妙:通过比较新旧策略的概率比值并进行裁剪,PSFT 能够防止模型参数更新过于激进。这样既能学习新任务,又能保持原有的通用能力,同时避免熵坍塌。
实验效果怎么样
研究者在 Qwen2.5-7B-Instruct 和 Llama3.1-8B-Instruct 上做了实验,主要看数学推理能力的提升。
首先是熵的变化。PSFT 能够维持更平滑的熵曲线,避免了传统 SFT 中的熵坍塌现象:
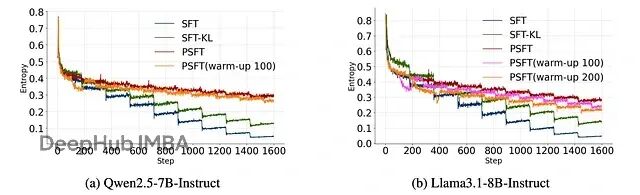
显示两个大语言模型在训练期间熵的图。SFT-KL 是一种应用 KL 惩罚以保持微调模型更接近预训练模型分布的方法。PSFT (warm-up) 是一种在切换到 PSFT 之前开始短暂的初始 SFT 阶段的方法,用于训练稳定性。
在域内数学任务上,PSFT 的表现至少和标准 SFT 持平,在某些情况下还更好:
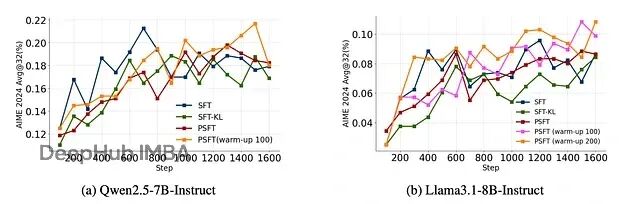
显示域内性能训练动态的图
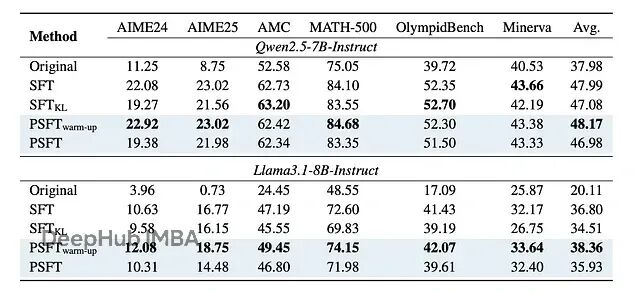
域内性能的结果,其中对于 AIME 和 AMC 基准,结果是 avg@32。对于其余的,结果是 avg@8。
更重要的是域外性能。PSFT 训练的模型在非数学任务上也表现很好,说明它确实提高了泛化能力:
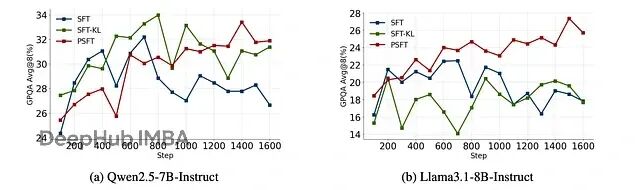
显示域外性能训练动态的图
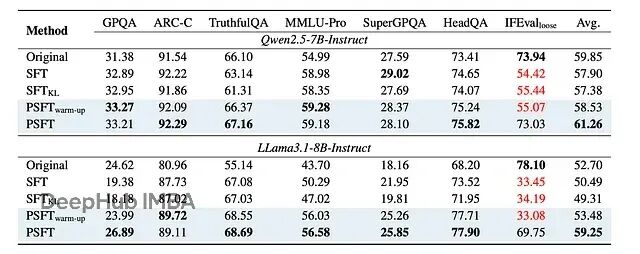
域外性能的结果。对于 GPQA、ARC-C、TruthfulQA 和 IFEval,结果是 avg@8。对于其余的,结果是 pass@1。
在后续的强化学习训练中,PSFT 训练的模型保持了更高的熵,说明探索能力得到了保留:
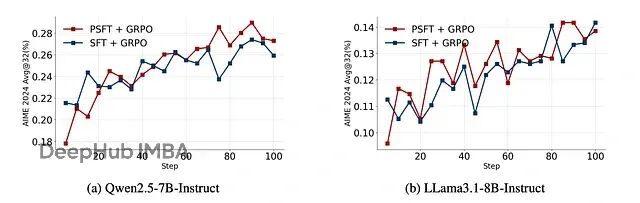
显示强化学习实验中域内性能训练动态的图
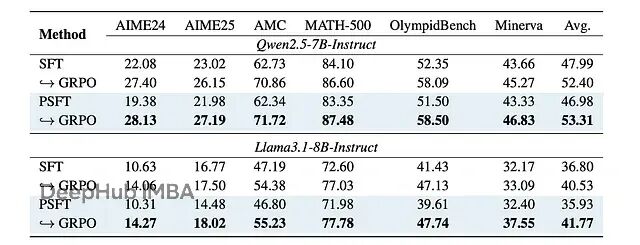
强化学习实验中域内性能的结果
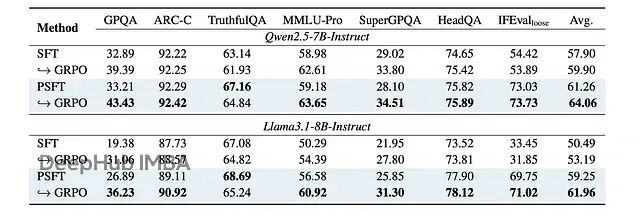
强化学习实验中域外性能的结果
PSFT 的优势不只体现在数学推理上,在模型对齐方面也有帮助。用 DPO 进行对齐训练时,PSFT 预训练的模型表现更稳定:
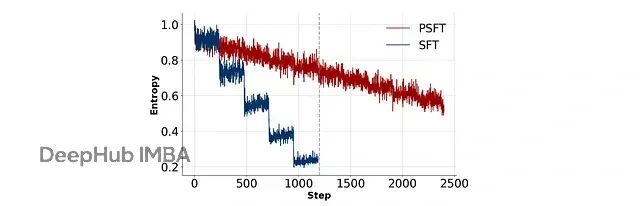
显示 SFT/PSFT 后跟 DPO 的对齐训练期间熵演变的图
在各种对齐基准上,PSFT 都比传统 SFT 表现更好:
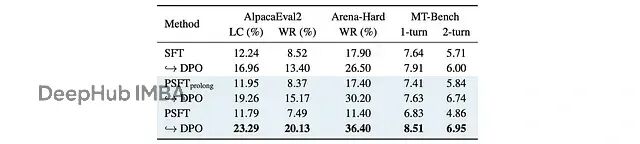
在不同对齐基准上对 Qwen3–4B-Base 进行 DPO 训练的结果。PSFT(prolong) 是 PSFT 的扩展版本,继续训练更多步骤。
总结
PSFT 本质上是把强化学习中稳定策略更新的思想引入到监督学习中。通过借鉴 PPO 的裁剪机制,PSFT 能够:
- 防止模型参数更新过于激进
- 保持模型的通用能力和探索性
- 避免熵坍塌现象
- 为后续的强化学习训练打下更好的基础
这个工作挺有意思的,它展示了监督学习和强化学习之间深层的联系。更重要的是,它提供了一个简单有效的方法来改善现有的训练流程。如果你正在做大模型的训练工作,PSFT 绝对值得试试。
https://avoid.overfit.cn/post/e933ddbf941a4530b7bf09782c70bbea
作者:Dr. Ashish Bamania