【VLNs篇】09:NavA³—理解任意指令,导航任意地点,找到任意物体
文章目录
- 论文摘要介绍表
- 论文具体实现流程
- 有趣的白话版详细解说
- 摘要
- 1. 引言
- 2. 相关工作
- 3. 方法论
- 4. 实验
- 5. 定性分析
- 6. 结论
论文摘要介绍表
| 项目 | 内容介绍 |
|---|---|
| 研究问题 | 现有的机器人导航系统难以理解模糊、高级的人类指令(如“我想喝咖啡”),也无法在复杂的真实环境中完成需要多步推理的长时程导航任务。 |
| 核心思想 | 提出一个名为 NavA³ 的分层导航框架,模仿人类的“先思考规划,再动手寻找”的模式。该框架将复杂任务分解为两个阶段。 |
| 创新点 | 1. 分层策略(Hierarchical Framework):首创性地将导航任务分解为“全局规划”和“局部搜索”两步,有效降低了任务的复杂性。 2. 高级指令理解:利用强大的视觉语言模型(Reasoning-VLM),使机器人能像人一样理解抽象指令,并推理出具体目标(“喝咖啡” -> “找咖啡机”)和目标区域(“咖啡机” -> “在茶水间”)。 3. 精准空间感知与定位:提出了 NaviAfford 模型(Pointing-VLM),通过在百万级样本上训练,使其具备强大的空间“可供性”(Affordance)理解能力,能精准定位开放词汇的物体及其空间关系(如“桌子左边的杯子”)。 4. 现实世界有效性:在真实环境中进行了大量实验,并成功部署于不同形态的机器人(轮式、四足),证明了其通用性和实用性。 |
| 主要组件 | 1. Reasoning-VLM (全局策略):负责理解指令、进行语义和空间推理,并确定大致的目标区域。 2. Pointing-VLM / NaviAfford (局部策略):负责在目标区域内进行精细化搜索,利用强大的视觉和空间理解能力,准确定位目标物体。 |
| 实验结果 | 在多个真实场景的导航任务中,NavA³的平均成功率达到 66.4%,远超之前最好的方法(25.2%),导航误差也显著降低,证明了其卓越性能。 |
论文具体实现流程
NavA³框架的实现流程可以看作一个“从宏观到微观”的决策与执行过程:
输入 (Input):
- 高级人类指令 (High-level Human Instruction):一句自然语言指令,例如“帮我把衣服晾起来”。
- 全局3D场景地图 (Global 3D Scene Map):一个预先构建好的、带有语义标注(如“会议室”、“阳台”)的环境3D地图。
- 实时感官数据 (Real-time Sensory Data):机器人摄像头提供的实时RGB-D(彩色+深度)图像。
流程 (Flow):
阶段一:全局策略 (Global Policy) - 思考与规划
- 指令解析:输入的指令“帮我把衣服晾起来”被送入 Reasoning-VLM (论文中使用了GPT-4o)。
- 目标推理:Reasoning-VLM进行推理,将指令分解为具体目标。
- 语义推理: “晾衣服” -> 需要找到 “衣架”。
- 空间推理:结合全局3D地图的语义信息,推理“衣架”最可能出现在哪个区域 -> “阳台”。
- 生成全局目标:全局策略的输出是一个高概率的目标区域,即“阳台”。机器人接下来需要导航到这个区域。
阶段二:局部策略 (Local Policy) - 探索与定位
- 导航至目标区域:机器人移动到全局策略指定的“阳台”区域。
- 系统性探索:一旦进入该区域,机器人开始执行探索。它会移动到一个一个的路点(waypoints)。
- 全景扫描与定位:在每个路点,机器人会旋转摄像头,拍摄一张360度的全景RGB图像。
- 目标检测:将全景图像和当前的目标查询(例如“找到衣架”)输入到 Pointing-VLM (NaviAfford模型) 中。
- 决策与行动:
- 如果找到目标:NaviAfford模型会输出目标物体“衣架”在图像中的精确像素坐标。系统利用深度信息将这些2D坐标转换为3D世界坐标,然后规划路径,驱动机器人移动到目标物体旁边。任务完成。
- 如果未找到目标:系统会决策下一步行动。它可能会在当前区域内选择一个新的、未探索过的路点继续搜索。或者,如果当前区域探索完毕仍未找到,它可能会重新咨询Reasoning-VLM,判断是否需要去其他区域(例如,也许衣架被放在了“工作站”)继续寻找。
输出 (Output):
- 机器人成功导航到目标物体1米范围内的位置。
数据流 (Data Flow):
- 3D场景构建:研究人员首先使用带有LiDAR的设备扫描真实环境,生成点云数据,然后重建出3D模型。这个模型被转换成带语义标签的2D俯视图,供全局策略使用。
- NaviAfford模型训练:为了让Pointing-VLM有精准的定位能力,研究人员收集了包含100万个“图像-问题-答案”对的数据集进行训练。这些数据专门用于学习物体的空间关系和“可供性”(例如,一个空着的柜子是“可放置物品的”)。
有趣的白话版详细解说
想象一下,你刚搬进一个超级大的新家,想让你的机器人管家“小智”帮你拿一罐可乐。
在过去,你可能得像指挥游戏角色一样对它说:“向前走10步,左转90度,再走5步,打开那个白色的门…”,这简直太麻烦了!而且万一你记错了,小智就彻底蒙圈了。
而这篇论文提出的 NavA³ 系统,就是让小智变得真正“智能”的关键。现在,你只需要对小智说一句人话:“小智,我渴了,想喝可乐。”
接下来,小智的大脑(也就是NavA³系统)就开始工作了,整个过程就像一个聪明的侦探在办案:
第一步:大脑风暴(全局策略)
小智的“超级大脑”——Reasoning-VLM (你可以想象成它内置了一个最强的GPT模型)——开始分析你的指令。
- “解码”你的心思:它首先会想,“主人说‘想喝可乐’,那我的任务就是找到‘一罐可乐’。” 它把一个模糊的想法,变成了一个明确的目标。
- “推理”藏宝地点:然后,它会调出整个房子的地图,开始推理:“可乐嘛,一般都放在哪儿呢?肯定不是卧室,也不是书房…啊哈!最有可能的地方是厨房!”
好了,第一阶段完成!小智现在有了一个明确的大方向:去厨房! 它不会再像无头苍蝇一样在整个豪宅里乱逛了。
第二步:火眼金睛(局部策略)
小智晃晃悠悠地来到了厨房门口。现在,它切换到了“精确索敌”模式。
- 开启“鹰眼”扫描:它启动了它的“火眼金睛”——NaviAfford模型。这个模型可是个见过大世面的高手,研究人员给它“看”了上百万张图片,专门训练它理解各种东西是怎么摆放的。比如,它知道杯子通常在桌上,书在书架上,而“桌子左边的空位”意味着可以放东西。
- 地毯式搜索:小智会在厨房里走来走去,每到一个新位置,就360度环顾四周,把看到的画面传给NaviAfford。它心里默念着:“找可乐,找可乐…”
- 锁定目标!:突然,NaviAfford在一个画面里发现了目标!它不仅认出了可乐,还能精确地告诉小智:“目标在冰箱里,位于中间那层!” 它甚至能直接输出可乐的精确三维坐标。
- 任务完成:小智接收到坐标,径直走向冰箱,打开门,取出可乐,然后送到你面前。完美!
总结一下,NavA³就像给机器人装上了一个“会推理的大脑”和一个“懂空间布局的眼睛”。 大脑负责从宏观上规划,眼睛负责在局部精确查找。两者完美配合,让机器人能够像人一样思考和行动,去完成那些听起来很简单但做起来很复杂的任务。
我的观点和理解:
我觉得这项工作非常酷,因为它离我们想象中的“家庭服务机器人”又近了一大步。它解决了一个核心痛点:如何让机器人自然地融入我们的生活,听懂我们的话,而不是让我们去学习“机器人的语言”。
- 实用价值巨大:这种技术如果成熟,将极大地推动智能家居、养老助残等领域的发展。以后让机器人帮忙做家务、取东西、照顾老人,都会变得像使唤一个真人助手一样简单。
- 技术思路的巧妙:将复杂问题“降维打击”的思路非常经典且有效。面对一个几乎不可能一步到位的任务(从一句话到一个具体物体),它通过“全局-局部”的分解,让每一步都变得清晰可控。
- 挑战依然存在:当然,这还不是终点。现实世界是动态的,家里可能会突然多一把椅子,或者有人在走来走去挡住路。如何让机器人在这种不断变化的环境中保持稳定,是下一步需要解决的难题。此外,如果指令更加模糊,比如“帮我找个能看书的地方”,这对机器人的推理能力提出了更高的要求。
总而言之,NavA³为具身智能领域描绘了一幅激动人心的蓝图。它不仅仅是一个算法的进步,更是一种让机器更懂人、更能融入人类世界的哲学思考的体现。未来,我们的机器人伙伴或许真的能“察言观色”,“心灵手巧”。
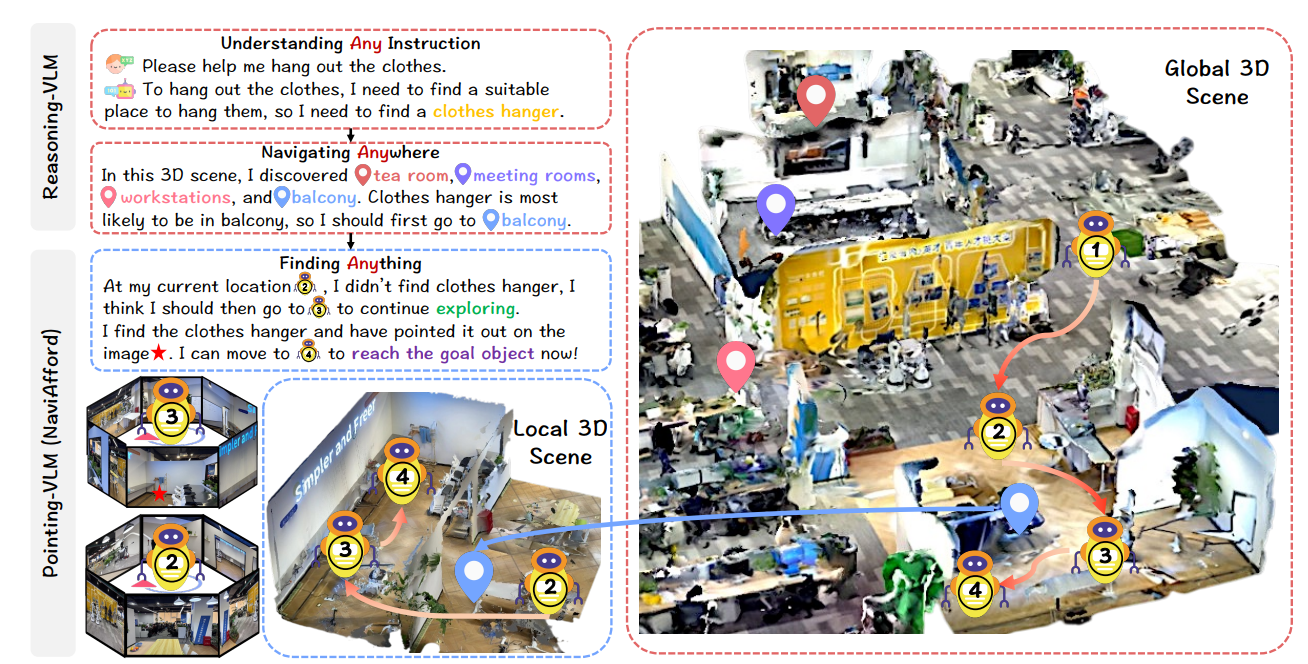
图1:NavA³的执行流程。全局策略使用Reasoning-VLM来解释高级指令(例如,“晾衣服”→“衣架”)并利用3D场景理解来确定目标位置(阳台)。局部策略使用Pointing-VLM来导航至路点,并执行精确的物体定位,利用我们的NaviAfford模型,该模型利用空间可供性理解来准确定位目标物体(衣架)。
摘要
具身导航是具身智能的一项基本能力,使机器人能够在物理环境中移动和互动。然而,现有的导航任务主要集中在预定义的对象导航或指令跟随上,这与真实世界场景中涉及复杂、开放式场景的人类需求有很大不同。为了弥合这一差距,我们引入了一项具有挑战性的长时程导航任务,该任务要求在真实世界环境中理解高级人类指令并执行具有空间感知能力的物体导航。由于在理解高级人类指令和定位开放词汇对象方面的局限性,现有的具身导航方法难以应对此类任务。在本文中,我们提出了NavA³,一个分为两个阶段的分层框架:全局和局部策略。在全局策略中,我们利用Reasoning-VLM的推理能力来解析高级人类指令,并将其与全局3D场景视图相结合。这使我们能够推理并导航到最有可能包含目标对象的区域。在局部策略中,我们收集了一个包含100万个空间感知对象可供性样本的数据集来训练NaviAfford模型(Pointing-VLM),该模型为复杂环境中的精确目标识别和导航提供了强大的开放词汇对象定位和空间感知能力。大量实验表明,NavA³在导航性能方面取得了SOTA(state-of-the-art)成果,并能在真实世界环境中成功完成不同机器人形态的长时程导航任务,为通用具身导航铺平了道路。数据集和代码将公开发布。项目网站:https://NavigationA3.github.io/。
1. 引言
具身导航(Zheng et al. 2024a; Morad et al. 2021)是具身智能的一项基础能力,对于机器人在物理环境中执行复杂任务至关重要。这种能力使自主智能体能够在真实世界空间中导航和互动,为更复杂的具身行为(如操作、探索和人机协作)奠定了基础(Hao et al. 2025b; Tang et al. 2025; Zhang et al. 2025c; Tang et al. 2025; Hao et al. 2024a, 2025d, 2024b; Li et al. 2024a; Hao et al. 2025c; Zhang et al. 2025e,a; Hao et al. 2025a; Zhao et al. 2025; Zhang et al. 2025d)。尽管该领域取得了显著进展,但现有研究主要集中在相对低级的任务上,如指令跟随和基本对象导航,这些任务未能完全捕捉动态环境中人类需求的细微差别。当前的具身导航方法可大致分为两种主要方法:视觉和语言导航(VLN)(Hong et al. 2021; Zheng et al. 2025; Chen et al. 2024b)和对象导航(ObjectNav)(Cai et al. 2024a; Qi et al. 2025; Gao et al. 2025; Gong et al. 2025)。VLN任务要求智能体遵循详细的、逐步的指令,例如“左转,出门,然后直走”。虽然这些任务需要精确的空间理解,但它们通常依赖于人类在自然环境中很少提供的过于具体的指令。相反,ObjectNav任务旨在定位预定义的对象类别(例如,“找到场景中的任何椅子”),并且在遇到目标对象的任何实例时即告成功,无论其空间背景或具体要求如何。
然而,真实世界的人类指令常常涉及需要复杂推理和空间感知的高级意图。例如,像“我想要一杯咖啡”或“我想吃茶几左边的水果”这样的请求,不仅需要理解潜在的目标,还需要对物体之间的空间关系进行推理。这凸显了当前导航任务与真实世界需求之间的根本差距,严重阻碍了能够实现高级人机交互的具身智能体的发展。
为了应对长时程导航的挑战,我们提出了NavA³,这是一个新颖的分层框架,将这个复杂问题分解为两个阶段:全局策略和局部策略。如图1所示,全局策略利用了视觉语言模型(VLM)强大的推理能力(Ji et al. 2025; O’Neill et al. 2024; Tan et al. 2025; Zhai et al. 2024),我们称之为Reasoning-VLM,来解析高级人类指令。Reasoning-VLM根据这些指令识别关键对象,并使用带注释的全局3D场景来确定目标对象最可能的空间位置。例如,当给出指令“我想要一杯咖啡”时,全局策略会推断出咖啡机很可能位于茶水间,从而引导智能体前往这个高概率区域。在全局策略完成后,局部策略接管,专注于在已识别的目标区域内进行探索和精确的对象定位。该VLM被称为Pointing-VLM,它从局部3D场景中选择路点进行探索。在每个路点,我们执行全景感知,并利用我们专门训练的NaviAfford模型(Pointing-VLM的一个实现)进行准确的目标对象识别。如果检测到目标对象,我们将其位置从智能体的视角转换到机器人的坐标系,从而实现到最终目标的导航。NaviAfford模型在一个包含100万个样本对的空间对象可供性数据集上进行训练,促进了空间感知的对象和可供性定位。这使得模型能够理解复杂的空间关系,例如“窗边的杯子”或“桌子左侧的空位”。广泛的实验评估表明,NavA³在大型真实世界环境中的长时程导航任务中达到了最先进的性能。此外,我们的系统表现出优秀的跨形态能力,使其能够适应各种机器人实例,并凸显了其实际应用的潜力。
我们的贡献总结如下:
- 我们引入了一个具有挑战性且现实的长时程导航任务,要求智能体在复杂的室内环境中理解高级人类指令,并定位具有复杂空间关系的开放词汇对象。
- 我们提出了NavA³,一个利用全局和局部策略的新颖分层框架。该框架能够理解多样化的高级指令,跨区域导航,并找到任何对象。
- 我们收集了一个包含100万个空间感知对象可供性样本的数据集来训练NaviAfford模型,使其能够有效理解复杂的空间关系并执行准确的对象指向。
- 大量实验证明,我们的方法与现有方法相比,在导航性能上达到了最先进的水平,为在真实世界场景中开发通用具身导航系统铺平了道路。
2. 相关工作
具身导航 具身导航研究主要集中在两个范式上:视觉语言导航(VLN)和对象目标导航(ObjectNav)(Chattopadhyay et al. 2021; Truong, Chernova, and Batra 2021)。在VLN中,像NavGPT(Zhou, Hong, and Wu 2024)这样的系统利用GPT-4o(Hurst et al. 2024)进行自主行动生成,而DiscussNav(Long et al. 2024)则减少了人类的参与。InstructNav(Long et al. 2025)将导航分解为子任务,Nav-CoT(Lin et al. 2025)则使用思维链推理进行模拟。MapNav(Zhang et al. 2025b)通过空间表示优化记忆,NaVid(Zhang et al. 2024b)则保持时间上下文。对于ObjectNav,像Pirl-Nav(Ramrakhya et al. 2023)和XGX(Wasserman et al. 2024)这样的方法模仿人类演示,而其他方法如L3MVN(Yu, Kasaei, and Cao 2023)和Uni-NaVid(Zhang et al. 2024a)则构建语义地图或利用VLM来增强性能。然而,这些方法主要关注详细指令,并且缺乏理解高级人类命令或执行开放词汇对象的空间感知定位的能力,这限制了它们在长时程导航任务中的有效性。
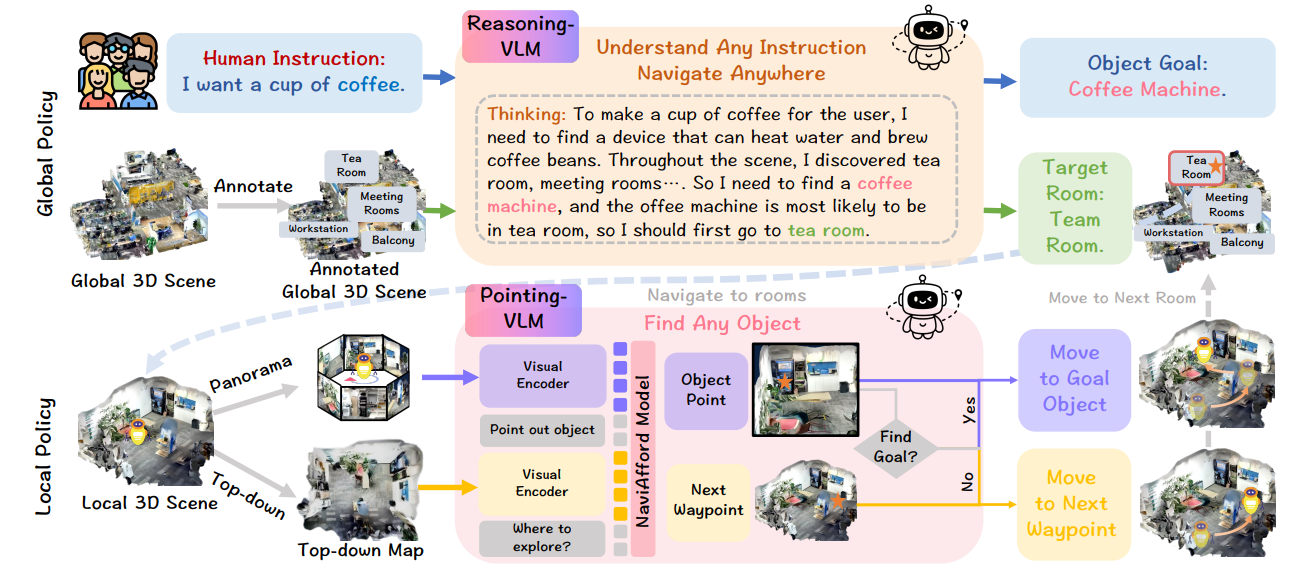
图2:NavA³框架概览。我们的分层方法包括两个阶段:全局策略使用Reasoning-VLM来解释高级人类指令,并在3D场景中标记出可能的区域。到达目标区域后,局部策略使用Pointing-VLM在每个路点搜索目标对象。如果未找到,它会预测下一个路点;如果检测到,它会在自我中心图像上标记出对象,并导航到最终目的地。
基于VLM的空间推理 空间推理对于机器人与物理世界互动至关重要(Beyer et al. 2024; Wang et al. 2023; Luo et al. 2023; Liu et al. 2024, 2023; Doveh et al. 2024)。研究人员已经开发了多种方法来增强VLM通过从图像中提取空间信息的空间理解能力。例如,SpatialVLM(Chen et al. 2024a)将图像转换为以对象为中心的点云,而SpatialRGPT(Cheng et al. 2024)通过空间场景图增强了区域级别的推理。RoboPoint(Yuan et al. 2025)引入了一个用于精确动作预测的合成数据集,而像SpatialBot(Cai et al. 2024b)这样的研究使用RGB-D数据进行全面的空间理解。最近的进展,如SpatialCoT(Liu et al. 2025)和VILASR(Wu et al. 2025),专注于优化推理过程。然而,这些方法在开放词汇的空间感知对象指向和长时程导航集成方面仍然存在困难,而这对于实际应用至关重要。
3. 方法论
如图2所示,我们的NavA³框架采用了一种分层的从全局到局部的策略,将语义推理与精确的空间定位相结合,以解决长时程导航任务。全局策略利用Reasoning-VLM来解释高级人类指令(例如,“我想要一杯咖啡”),推断出目标对象(咖啡机)并确定可能的房间(例如,茶水间、厨房区域)。到达这个房间后,局部策略使用我们的NaviAfford模型(Pointing-VLM)来分析每个路点的全景RGB观测和局部地图。该模型判断目标对象是否存在;如果存在,它会指向其位置进行导航;如果不存在,它会预测下一个最佳路点或咨询Reasoning-VLM以继续探索,直到目标被定位。
问题定义 我们将长时程具身导航任务表述如下:给定一个高级人类指令I(例如,“我想要咖啡”或“帮我把衣服晾在阳台上”),具身智能体必须在一个大型室内环境E中导航,以定位并到达一个满足指令所隐含的语义和空间要求的特定目标对象O。智能体从任意位置p₀开始,并可以访问自我中心的RGB-D观测oₜ和全局3D场景表示S。与传统ObjectNav任务不同(在找到预定义对象类别的任何实例时终止),我们的任务需要多步推理来从高级指令中推断特定目标对象(例如,从“我想要咖啡”推断出“咖啡机”),识别最可能的空间位置(例如,厨房或茶水间),并导航到满足上下文要求的精确对象实例。成功的定义是智能体到达目标对象O一米范围内并保持视线,这展示了在复杂的真实世界环境中准确的语义理解和精确的空间导航。
3D场景构建 为了在真实世界环境中实现有效导航,我们使用一个直接的重建流程构建了一个分层的3D场景表示,如图3所示。我们的流程从多个视点捕获的一系列RGB图像开始,这些图像通过一个2D到3D的重建流程进行处理。
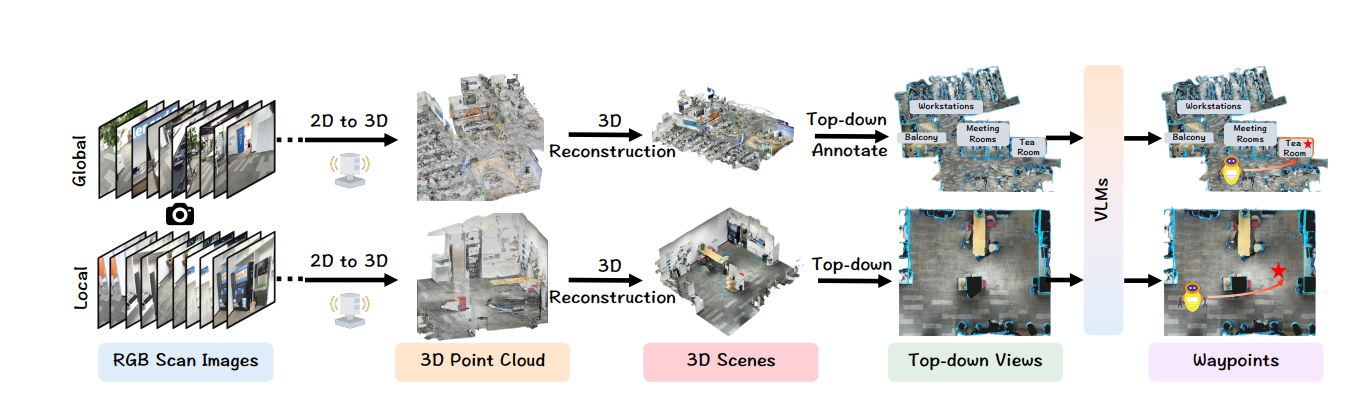
图3:3D场景的构建过程。我们使用2D到3D重建技术从RGB扫描图像中重建3D场景。然后,这些场景被转换为带注释的俯视图,随后由视觉语言模型(VLM)处理以进行导航规划。这种方法提高了导航任务的准确性和效率。
通过使用配备LiDAR传感器的移动设备,我们生成一个密集的点云,表示为:
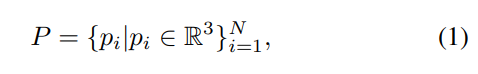
其中每个点pᵢ表示场景中的一个3D坐标。重建过程采用特征点匹配算法来建立连续帧之间的对应关系,然后进行网格重建以生成连贯的3D几何体。一个3D扫描仪应用程序被用来简化这个过程并确保高质量的结果。
重建的3D场景被转换为用于全局和局部策略的俯视图。对于全局策略,我们使用MapNav(Zhang et al. 2025b)的注释方法来提供房间级和区域级的语义注释,例如“茶水间”、“会议室”、“阳台”和“工作站”。这使得VLM能够有效地理解空间语义并对对象位置进行推理。带注释的全局场景表示为:
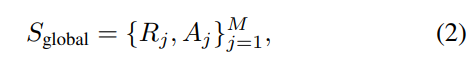
其中Rⱼ表示几何区域,Aⱼ表示相应的语义注释。对于局部策略,我们直接使用没有注释的俯视图地图M_local。
全局策略
全局策略利用视觉语言模型(Reasoning-VLM)的先进推理能力,来弥合高级人类指令和导航目标之间的语义鸿沟。如图2所示,给定人类指令I和一个带注释的全局3D场景S_global,我们将全局推理任务视为一个多模态问题,其中Reasoning-VLM执行语义对象推理和空间位置预测。
为了支持系统性推理,我们设计了一个结构化的提示模板来有效引导Reasoning-VLM:
“你需要完成人类指令:I。现在给定这个俯瞰场景视图 S_global 和几个可选区域,请思考你应该找到什么物体来完成指令,以及你应该在哪里寻找这个物体。请展示你的思考过程并在最后给出你的答案。”
Reasoning-VLM处理文本指令和带注释的全局场景的视觉表示,以实现分层推理。它首先通过语义分解推断出完成指令所需的目标对象O*:O∗=fsemantic(I)O* = f_{semantic}(I)O∗=fsemantic(I)。然后,模型分析空间语义关系以确定目标区域R*,即对象最有可能被定位的地方,定义为 R* = argmax_{Rⱼ∈S_global} P(O*|Rⱼ, Aⱼ),其中P(O*|Rⱼ, Aⱼ)表示在区域Rⱼ中找到带有注释Aⱼ的O*的条件概率。
在确定目标区域R后,我们在其局部边界内随机采样一个路点w ∈ R,并使用Pointing-VLM来引导智能体。这种策略促进了稳健的探索,同时有效地将搜索空间缩小到目标对象可能位于的相关子区域,从而提高了搜索过程的效率。
局部策略
NaviAfford模型 为了实现精确的空间对象定位,我们开发了NaviAfford模型(Pointing-VLM),如图4所示。在训练期间,我们从LVIS和Where2Place数据集中整理了一个包含约5万张图像和100万个问答对的数据集。我们将实例分割掩码转换为带有边界框坐标(x₁, y₁, x₂, y₂)的对象检测格式,并在每个框内采样5-8个代表性点,以增强空间粒度并提高定位精度,支持Reasoning-VLM的能力。
我们的数据集构建系统地生成两种类型的可供性注释,以实现全面的空间理解。对于对象可供性,我们计算方向关系(上、下、左、右、前、后)来识别特定上下文中的目标对象。例如,给定查询“找到沙发前的电视”,我们确定目标对象及其与参考对象的空间关系。对于空间可供性,我们识别满足这些约束的自由空间,使模型能够理解可用于导航和放置的区域。这种双重可供性方法创建了捕捉真实世界导航所需复杂空间关系的训练样本。
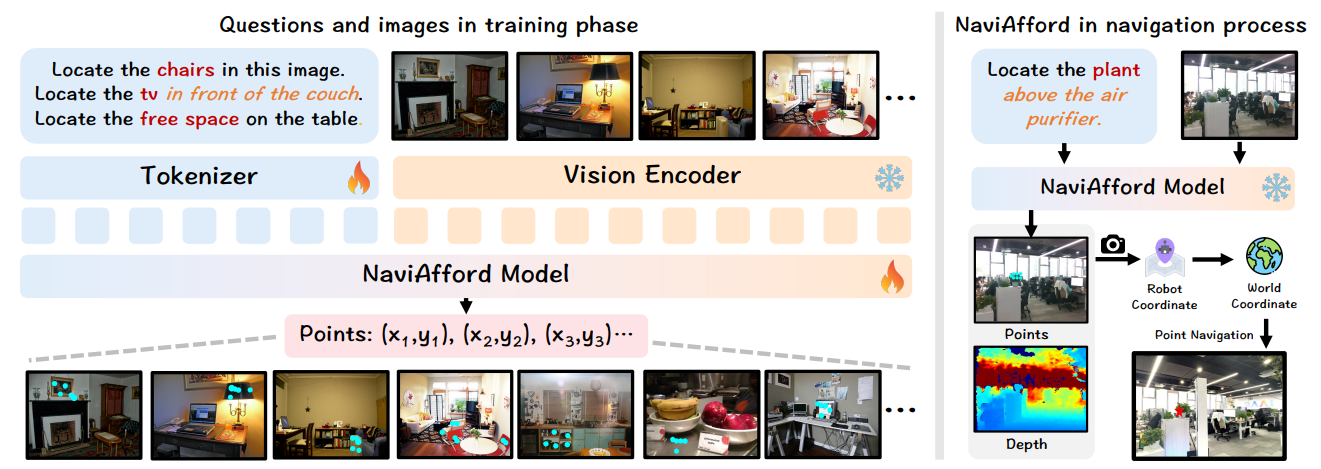
图4:NaviAfford模型的训练和部署过程。NaviAfford模型从各种室内场景中学习对象和空间可供性,以输出精确的点坐标。在导航期间,它执行实时对象定位并生成目标点,局部策略将其转换为机器人坐标,以实现到目标对象的有效导航。
NaviAfford模型架构遵循视觉语言框架,通过独立的tokenizer和视觉编码器路径处理输入问题Q和RGB图像V。该架构表示为:
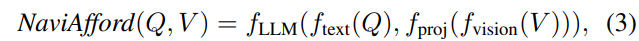
其中f_text处理文本查询,f_vision编码视觉输入,f_proj将视觉特征映射到LLM嵌入空间。函数f_LLM生成文本点坐标。训练目标使用带有损失函数的监督微调(SFT):
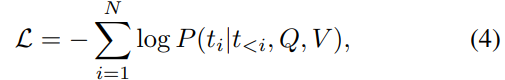
其中tᵢ表示目标文本序列中包含点坐标的第i个token。在NaviAfford的局部策略中,我们输入以自我为中心的RGB视图和基于空间关系的目标对象查询,将模型零样本部署在真实世界环境中。模型输出精确的点坐标,具体用法在局部策略中有详细说明。
导航过程 在局部策略中,我们的系统采用基于系统性路点探索的精细化对象定位和导航策略。如图2所示,智能体通过旋转扫描在每个路点捕获全景RGB视图。NaviAfford模型处理这些视图以检测并准确定位目标对象。检测到后,模型输出多个点坐标,我们通过平均选择中心点以实现稳健的定位。
为了将像素坐标转换为机器人坐标,我们使用相机内参函数:
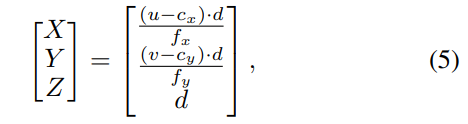
其中fₓ和fᵧ是焦距,cₓ和cᵧ是主点,d是像素(u, v)处的深度。这确保了到目标对象的有效导航。
接下来,我们使用旋转和平移将相机坐标转换为机器人坐标:
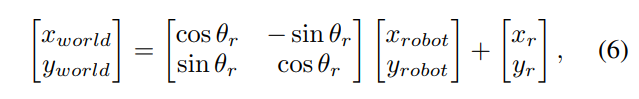
其中(xᵣ, yᵣ, θᵣ)是机器人的世界位姿,(xrobot,yrobot)(x_{robot}, y_{robot})(xrobot,yrobot)从相机坐标导出:xrobot=zcam,yrobot=−xcamx_{robot} = z_{cam}, y_{robot} = -x_{cam}xrobot=zcam,yrobot=−xcam。
如果未检测到目标对象,系统将遵循一个两阶段决策过程。首先,Reasoning-VLM分析局部3D场景和历史探索数据,以决定是继续探索当前区域还是转换到新区域。如果选择继续,NaviAfford模型会识别下一个最佳探索点。否则,它会根据先前的搜索选择最有希望探索的房间或空间,从而促进高效的转换。
4. 实验
实验细节
评估基准 为了评估长时程导航性能,我们建立了一个包含五个不同场景的基准:会议室A、会议室B、茶水间、工作站和阳台。每个场景包括10个导航任务,总共50个任务。对于每种方法,我们为每个任务进行10次 rollout 以最小化随机性。人类专家定义了高级指令和相关的语义对象,确保了每个场景中目标对象的唯一性。每个任务在不同的起始条件下测试了五次。在执行过程中,智能体自由地与环境互动,利用自我中心的RGB-D感知、路点选择和动作控制。为了评估不同的PointVLM模型,我们选择了1000张未出现在训练集中的图像。
表1:与SOTA方法的导航性能比较。*表示我们修改了该方法以使其能够完成我们的任务。我们的NavA³在导航性能上优于所有SOTA方法。
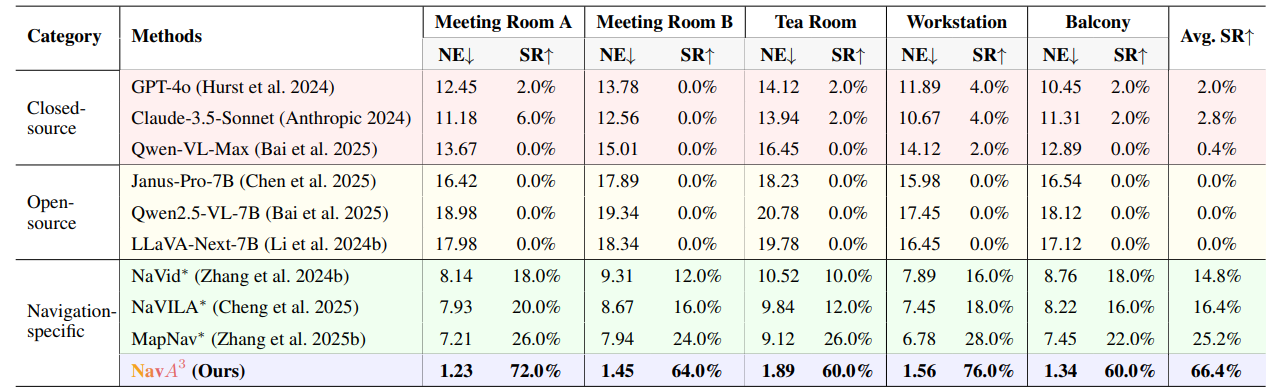
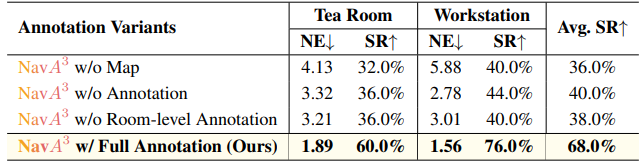
表2:注释成分的消融研究。
评估指标 我们在具身导航中采用了两个标准指标:导航误差(NE)和成功率(SR)。NE测量智能体最终位置与目标之间的欧几里得距离(米),值越低表示性能越好。SR反映了智能体成功到达目标的导航事件的百分比,定义为在一米以内。我们在10个任务中计算SR,每个任务测试5次(总共50次试验),并报告平均SR(Avg. SR)。此外,对于PointVLM评估,我们使用准确率(Acc),定义为正确预测的点在地面真实掩码内的比例与总预测点的比例。
实现细节 对于Reasoning-VLM,我们利用GPT-4o来解释高级人类指令并做出空间决策。Pointing-VLM采用了NaviAfford模型,该模型在1.0M空间感知对象可供性数据集上进行训练,使用预训练的Qwen2.5-VL-7B权重进行初始化,并按照(Zheng et al. 2024b)中的描述进行完全微调。实验在四个H100 GPU上进行,使用AdamW作为优化器,学习率为10⁻⁵,训练一个epoch。每个GPU处理的批量大小为4,梯度累积设置为2步,从而实现有效的批量大小为32。为了验证跨形态能力,我们将系统部署在RealMan轮式机器人和Unitree Go2四足机器人上,两者都配备了用于RGB-D感知的Intel RealSense D435i相机。
基线模型 现有的导航方法通常难以处理涉及高级人类指令的长时程任务。为了确保公平比较,我们通过修改指令格式以提供明确指导来调整它们的任务公式:“你需要完成以下指令:我想喝咖啡。找到目标对象以完成指令并在其附近停止。”此外,我们为基线模型提供了俯瞰的全局3D场景信息。我们评估了三种类型的基线模型:(1)闭源通用VLM,包括GPT-4o(Hurst et al. 2024)、Claude-3.5-Sonnet(Anthropic 2024)和Qwen-VL-Max(Bai et al. 2025);(2)开源通用VLM,如Janus-Pro-7B(Chen et al. 2025)、Qwen2.5-VL-7B(Bai et al. 2025)和LLaVA-Next-7B(Li et al. 2024b);以及(3)导航特定方法,包括NaVid(Zhang et al. 2024b)、NaVILA(Cheng et al. 2025)和MapNav(Zhang et al. 2025b),这些方法需要为我们的长时程导航任务进行适配。
与SOTA方法的比较
如表1所示,NavA³在所有评估场景中均显著优于现有的最先进方法,成功率(SR)平均达到66.4%,与最佳基线MapNav(Zhang et al. 2025b)的25.2%相比,提高了41.2个百分点。具体来说,NavA³在会议室A的SR提高了46.0%(72.0% vs. 26.0%),在会议室B提高了40.0%(64.0% vs. 24.0%),在茶水间提高了34.0%(60.0% vs. 26.0%),在工作站提高了48.0%(76.0% vs. 28.0%),在阳台提高了38.0%(60.0% vs. 22.0%)。它还在所有场景中显著降低了导航误差(NE):在会议室A降低了5.98m(1.23m vs. 7.21m),在会议室B降低了6.49m(1.45m vs. 7.94m),在茶水间降低了7.23m(1.89m vs. 9.12m),在工作站降低了5.22m(1.56m vs. 6.78m),在阳台降低了6.11m(1.34m vs. 7.45m)。虽然通用VLM(包括闭源和开源)在这一具有挑战性的长时程导航任务中通常实现接近于零的成功率,但我们的分层方法有效地弥合了高级命令理解和真实世界环境中精确空间导航之间的差距。
消融研究
注释的效果 为了评估我们的注释策略,我们在茶水间和工作站进行了消融研究。表2的结果证明了长时程导航中语义注释的重要性。
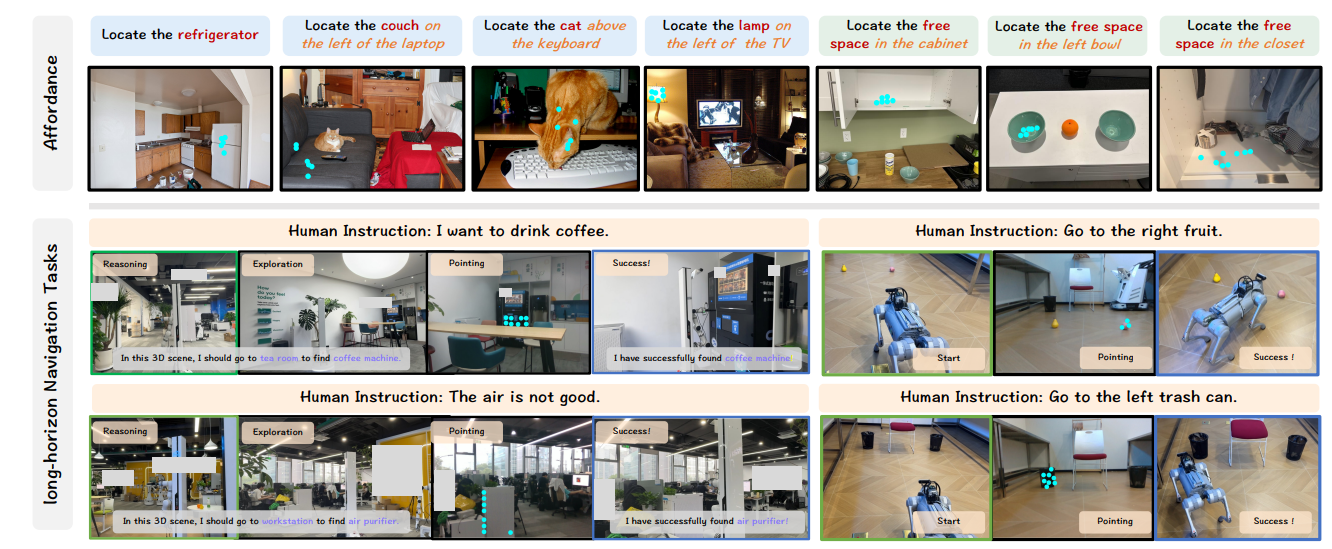
图5:对NaviAfford和NavA³的定性分析。可供性可视化包括NaviAfford模型在对象可供性和空间可供性上的性能。长时程导航任务可视化包括NavA³分层系统在真实世界环境中的性能及其跨形态部署能力。
表3:不同Reasoning-VLM的消融研究。
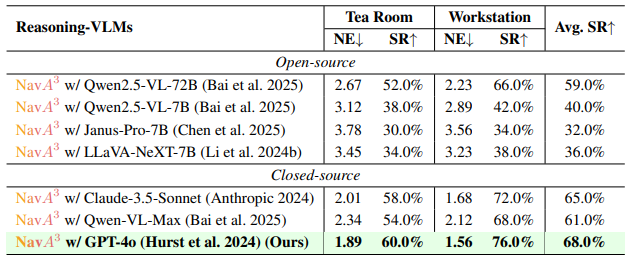
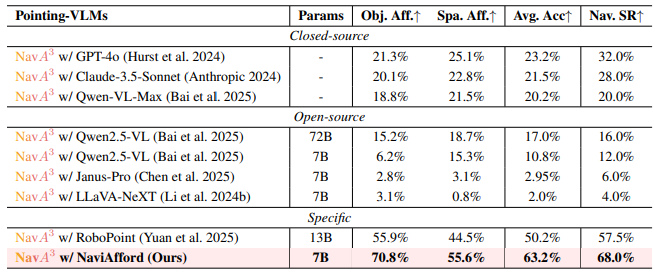
表4:不同Pointing-VLM的消融研究。
与没有地图的NavA³相比,带有完整注释的NavA³(我们的方法)在茶水间的成功率提高了28.0%(60.0% vs. 32.0%),在工作站提高了36.0%(76.0% vs. 40.0%),平均SR提高了32.0%(68.0% vs. 36.0%)。与没有注释的NavA³相比,我们在茶水间实现了24.0%的改进(60.0% vs. 36.0%),在工作站实现了32.0%的改进(76.0% vs. 44.0%),平均提升了28.0%。相对于没有房间级注释的NavA³,我们的策略在茶水间实现了24.0%的改进(60.0% vs. 36.0%),在工作站实现了36.0%的改进(76.0% vs. 40.0%),平均提升了30.0%。这些发现证实了详细的语义注释能改善Reasoning-VLM对空间关系的理解。
Reasoning-VLM的效果 为了评估不同Reasoning-VLM模型对导航性能的影响,我们在茶水间和工作站场景中进行了消融研究。表3的结果揭示了不同VLM架构之间的显著差异。我们基于GPT-4o(Hurst et al. 2024)的Reasoning-VLM实现了最高的成功率(SR),达到68.0%。像Claude-3.5-Sonnet(Anthropic 2024)和Qwen-VL-Max(Bai et al. 2025)这样的闭源模型分别下降了3.0%(65.0%)和7.0%(61.0%)。开源模型,如Qwen2.5-VL-72B(Bai et al. 2025),下降了9.0%(59.0%)。较小的7B模型,包括Qwen2.5-VL-7B(Bai et al. 2025)、Janus-Pro-7B(Chen et al. 2025)和LLaVA-NeXT-7B(Li et al. 2024b),分别下降了28.0%、32.0%和36.0%。这些发现凸显了在复杂空间任务中推理能力的重要性。
Pointing-VLM的效果 为了评估不同Pointing-VLM在对象定位方面的有效性,我们将NaviAfford模型与基线方法进行比较。表4的结果凸显了NaviAfford在可供性理解基准上的卓越性能,与之前的最先进方法RoboPoint(Yuan et al. 2025)相比,平均可供性准确率提高了13.0%(70.8% vs. 55.9%)。这种强大的可供性理解转化为增强的导航性能,NaviAfford的成功率(SR)比RoboPoint提高了10.5%(68.0% vs. 57.5%),比GPT-40(Hurst et al. 2024)提高了36.0%(68.0% vs. 32.0%),比最好的开源模型Qwen2.5-VL-72B(Bai et al. 2025)提高了52.0%(68.0% vs. 16.0%)。这些结果表明,我们的空间可供性训练有效地连接了准确的对象定位和实际的导航执行。
5. 定性分析
我们进行了定性评估,以展示NavA³在可供性理解、导航和跨形态部署方面的能力,如图5所示。可供性可视化凸显了NaviAfford的空间感知能力,能准确识别像“笔记本电脑左侧的沙发”和“壁橱里的空位”这样的参照物,同时在杂乱的环境中定位对象。长时程导航可视化展示了我们框架的系统性方法,追溯了从指令解析(例如,“我想要咖啡”)到在多房间环境中实现目标的清晰推理过程。跨形态实验展示了NavA³的多功能性,在四足机器人的任务中(如“走到右边的水果那里”)实现了一致的性能。这些发现证实了我们的方法在各种机器人平台上的适应性。
6. 结论
本文介绍了NavA³,一个连接具身导航研究与真实世界人类需求的分层框架,使机器人能够解释高级指令并在复杂环境中导航。我们的方法将导航分为两个阶段:一个利用Reasoning-VLM进行指令解析和目标识别的全局策略,以及一个使用我们的NaviAfford模型进行精确对象定位的局部策略。大量实验表明,NavA³在管理复杂空间关系和开放词汇指向方面优于最先进的方法。在轮式和四足机器人上的成功部署凸显了其多功能性。未来的工作将侧重于增强在动态环境中的适应性,并集成额外的感官输入以提升导航性能。