ChatAI项目-ChatGPT-SDK组件工程
需求分析:
搭建一个 ChatGPT-SDK 组件工程,专门用于封装对 OpenAI 接口的使用。由于 OpenAI 接口本身较多,并有各类配置的设置,所以开发一个共用的 SDK 组件,更合适我们在各类工程中扩展使用。
所以我们将OpenAI 抽象为会话模型,建立工程结构设计。其实这也是架构设计的一部分。并在本次的 ChatGPT-SDK 组件工程中,开发简单的对话功能模块实现。
之所以要单独提供 sdk 的原因:
1. 分而治之,不同的模块修改,不会影响到整体的变动。比如就只是 sdk 调整,或者再引入新的 sdk 都会非常容易管理。
2. 资源问题,如果公司内有多个系统都需要用到这个 sdk,那么如果你让这些系统都调用你的 gpt-api,就会出现一个问题。如果外部有100台机器,那么你也会随时扩容服务,否则就扛不住调用。但如果是把 sdk 让对方去引入使用,就不会涉及内部在提供一个服务,导致资源的过多占用。
涉及知识
SDK
SDK 是 Software Development Kit 的缩写,中文名为软件开发工具包。它是一组工具、库、文档和代码示例的集合, 用于帮助开发者更方便地创建特定软件、应用程序或进行特定功能的开发。
SDK 的组成部分
开发工具:比如编译器、调试器等
库文件:是 SDK 的核心部分,包含了一系列已经编写好的代码模块 。以 ChatGPT-SDK 为例,它可能包含了处理与 OpenAI 服务器通信、数据格式转换等功能的代码库,开发者无需从头编写这些复杂功能的代码,直接调用库中的函数或类即可。
文档:详细介绍了 SDK 中各个功能模块的使用方法、参数说明、返回值类型等。
代码示例:通过具体的示例代码展示如何使用 SDK 完成常见的任务。比如在使用微信支付 SDK 时,官方提供的示例代码能帮助开发者快速了解如何实现支付功能的接入
工厂模型
通俗理解:就像 “奶茶店”(工厂)专门负责制作 “奶茶”(对象),你不需要知道奶茶是怎么做的,只要告诉店员要什么口味(参数),就能拿到做好的奶茶。
这里的作用:文中的 “工厂模型” 是
OpenAiSessionFactory,它负责创建OpenAiSession(会话对象)。你不用关心会话内部是怎么初始化的,只需通过工厂的openSession()方法,就能直接拿到可用的会话对象,简化了对象创建的过程。
OkHttp3
通俗理解:它是一个 “网络通讯工具”,就像你电脑上的浏览器,负责帮你发送 HTTP 请求(比如访问网页、调用接口)并接收响应。
这里的作用:封装了底层的网络通讯细节(比如建立连接、处理超时等),
OpenAiSession会用它来实际发送请求到 OpenAI 的接口(比如https://apis.itedus.cn/v1/chat/completions)。
Retrofit2
通俗理解:它是 OkHttp3 的 “高级助手”,能把 HTTP 接口(比如 POST /v1/chat/completions)转换成 Java 中的接口方法,让你用 “调用 Java 方法” 的方式来发网络请求,不用手动拼接 URL 和参数。
核心用法:
定义一个接口(比如
IOpenAiApi),用注解描述请求信息:// 用 @POST 注解说明这是 POST 请求,路径是 "chat/completions"@POST("chat/completions")// 方法参数用 @Body 注解,直接传 Java 对象(会自动转成 JSON)Single<ChatCompletionResponse> completions(@Body ChatCompletionRequest request);这样调用接口时,就像调用普通 Java 方法一样简单:
// 创建请求参数对象ChatCompletionRequest request = new ChatCompletionRequest(...);// 调用接口方法,Retrofit 会自动处理网络请求ChatCompletionResponse response = iOpenAiApi.completions(request).blockingGet();
实现思路:
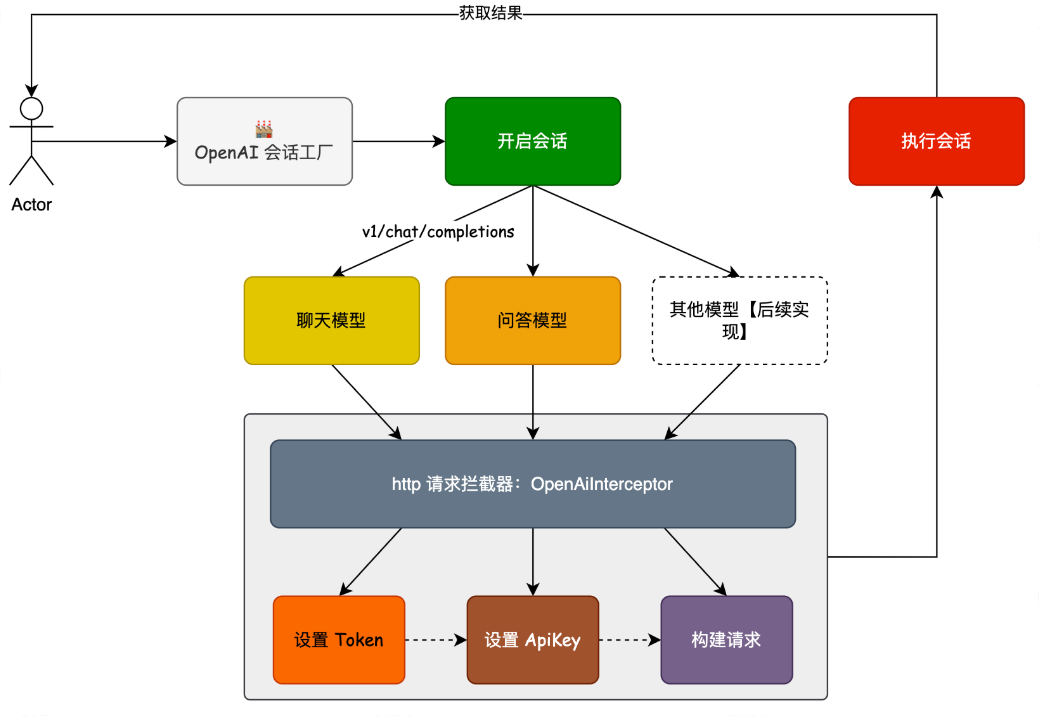
整个流程为:以会话模型为出口,驱动整个服务的调用链路。并对外提供会话工厂的创建和使用。
在本章中,我们通过工厂模型,开启一个使用 okhttp3 封装的 OpenAI 会话服务,进行流程的调用。同时这里还包括请求拦截的处理,因为我们需要对http请求设置一些必要的参数信息,如;ApiKey、Token 等。
这里还需要用到 Retrofit2 组件,Retrofit2 可以将 HTTP API 转化为 Java 接口,并通过注解的方式描述请求参数和响应结果等信息,从而方便地发送网络请求。具体可以的代码对 IOpenAiApi 的赋值实现。
模块结构
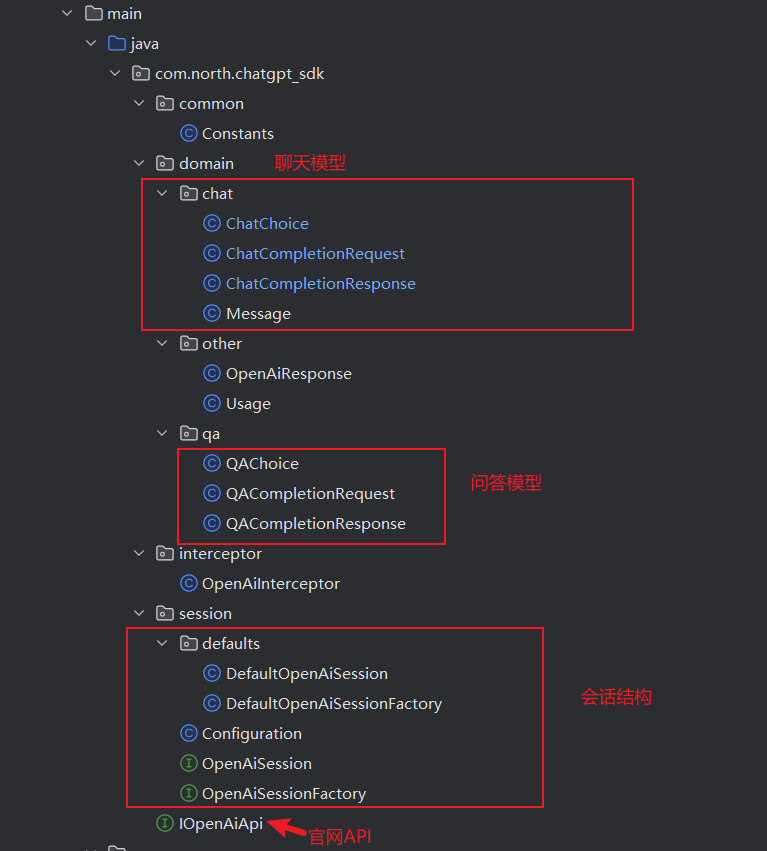
ChatGPT 的 API (测试)包含;简单问答模型 - v1/completions、会话聊天模型- v1/chat/completions 所以在工程的 domain 下也添加了对应的这两部分请求和应答对象。
之后就是以 session 会话为入口,管理整个服务的启动、调用、封装结果信息。
为了让大家更好理解,把最基本简单调用,写到 HttpClientTest 里。之后此工程也是从 HttpClientTest 的调用链路使用设计模式进行职责隔离和拆分。
定义并配置API接口
在 IOpenAiApi 接口中定义访问接口,这里后续会不断地进行扩展,包括;模型列表、消耗额度、流式对话、画图等各类方法。
注意;这个接口是没有对应的硬编码实现类的,它的存在只是定义标准,之后由 Retrofit 工具包进行创建服务,
如:IOpenAiApi openAiApi = new Retrofit.Builder() 你可以把这想象成是对 DAO 接口与数据库的连接数据源之间的操作。

import com.north.chatgpt_sdk.domain.chat.ChatCompletionRequest;
import com.north.chatgpt_sdk.domain.chat.ChatCompletionResponse;
import com.north.chatgpt_sdk.domain.qa.QACompletionRequest;
import com.north.chatgpt_sdk.domain.qa.QACompletionResponse;
import io.reactivex.Single;
import retrofit2.http.Body;
import retrofit2.http.POST;public interface IOpenAiApi {/*** 文本问答* @param qaCompletionRequest 请求信息* @return 返回结果*/@POST("v1/completions")Single<QACompletionResponse> completions(@Body QACompletionRequest qaCompletionRequest);/*** 默认 GPT-3.5 问答模型* @param chatCompletionRequest 请求信息* @return 返回结果*/@POST("v1/chat/completions")Single<ChatCompletionResponse> completions(@Body ChatCompletionRequest chatCompletionRequest);}
依赖与包导入
导入了与 ChatGPT SDK 相关的领域模型类(
ChatCompletionRequest、ChatCompletionResponse、QACompletionRequest、QACompletionResponse),这些类用于封装请求参数和响应结果。导入了
io.reactivex.Single,这是 RxJava2 中的类,用于异步处理网络请求的响应Single表示只会发射一个数据或者一个错误。
导入了 Retrofit2 的注解
@Body和@POST,用于描述 HTTP 请求的相关信息。
接口定义
接口 IOpenAiApi 中定义了两个用于不同场景的方法:
(1)completions 方法(文本问答,对应 v1/completions 接口)
@POST("v1/completions"):表示这是一个 POST 请求,请求的相对路径是v1/completions。参数:
@Body QACompletionRequest qaCompletionRequest@Body注解表示将QACompletionRequest对象作为 HTTP 请求的请求体(会被 Retrofit2 自动序列化为 JSON 等格式发送到服务端)。
返回值:
Single<QACompletionResponse>,这里会调用返回聊天模型得对象表示该请求是异步的,成功时会返回
QACompletionResponse类型的响应结果。这个方法主要用于普通的文本问答场景。
异步就是 “不等待,先干活,结果回来再处理”,避免程序卡在耗时操作(如网络请求)上,是提升程序效率和用户体验的常用方式。
Single就是实现这种异步操作的工具之一。
(2)completions 方法(默认 GPT - 3.5 问答模型,对应 v1/chat/completions 接口)
@POST("v1/chat/completions"):表示这是一个 POST 请求,请求的相对路径是v1/chat/completions参数:
@Body ChatCompletionRequest chatCompletionRequest是将
ChatCompletionRequest对象作为请求体发送。
返回值:
Single<ChatCompletionResponse>这里会调用返回聊天模型得对象异步返回
ChatCompletionResponse类型的响应结果,适用于基于聊天模型的问答场景。
3. 整体作用
通过 Retrofit2 定义这样的接口后,结合 Retrofit2 的创建和配置(指定基础 URL、转换器等),就可以非常方便地调用 OpenAI 的这两个 API 接口,而不需要手动去处理 HTTP 连接、请求
语言模型
ChatChoice类——映射 API 响应中的 choices 数组元素
这个 ChatChoice 类是 ChatGPT - SDK 中用于封装 OpenAI 对话接口返回结果中「选择项」信息的数据模型类,
主要作用是映射 API 响应中的 choices 数组元素。
@Data//这是 Lombok 框架的注解,会自动生成该类的//getter、setter、toString、equals、hashCode 等方法
@JsonIgnoreProperties(ignoreUnknown = true)//这是 Jackson 库的注解,用于 JSON 反序列化时忽略响应中存在但该类未定义的字段,//避免因字段不匹配导致的反序列化错误。public class ChatChoice implements Serializable {//实现 Serializable 接口:// 表明该类的对象可以被序列化,便于在网络传输或持久化存储时使用。private long index;//表示当前选择项在 choices 数组中的索引位置,用于标识多个返回结果的顺序。/** stream = true 请求参数里返回的属性是 delta */@JsonProperty("delta")private Message delta;//当调用接口时设置 stream = true(流式响应)//接口会通过该字段返回增量的消息内容,类型为Message(消息模型类)/** stream = false 请求参数里返回的属性是 delta */@JsonProperty("message")private Message message;//当调用接口时设置 stream = false(非流式响应),//接口会通过该字段返回完整的消息内容,类型同样为 Message。@JsonProperty("finish_reason")private String finishReason;private String logprobs;//表示当前选择项结束的原因//可能的取值有 stop(正常结束)、length(达到最大长度限制)等,用于判断对话生成是否完成。}ChatCompletionRequest类——对应接口的请求参数
这段代码定义了一个 ChatCompletionRequest 类,用于封装调用 AI 对话接口(如 OpenAI 的 chat/completions)的请求参数,是对接 AI 聊天功能的核心数据模型
@Data
@Builder
//@Builder:Lombok 注解,提供建造者模式(Builder Pattern)支持,
//方便通过链式调用构建对象
//如 ChatCompletionRequest.builder().model(xxx).messages(xxx).build()。
@Slf4j
@JsonInclude(JsonInclude.Include.NON_NULL)
@NoArgsConstructor
@AllArgsConstructor
@JsonIgnoreProperties(ignoreUnknown = true)public class ChatCompletionRequest implements Serializable {/** 默认模型 *///指定调用的 OpenAI 模型,默认使用 gpt-3.5-turbo。//通过内部枚举 Model 定义了常用模型(gpt-3.5-turbo、gpt-4 等),避免硬编码错误private String model = Model.GPT_3_5_TURBO.getCode();/** 问题描述 *///对话历史列表,每个元素是 Message 类型(包含角色 role 和内容 content)//用于上下文对话。private List<Message> messages;/** 控制温度【随机性】;0到2之间。较高的值(如0.8)将使输出更加随机,而较低的值(如0.2)将使输出更加集中和确定 */private double temperature = 0.2;/** 多样性控制:* 使用温度采样的替代方法称为核心采样,其中模型考虑具有top_p概率质量的令牌的结果。* 因此,0.1 意味着只考虑包含前 10% 概率质量的代币 */@JsonProperty("top_p")private Double topP = 1d;/** 为每个提示生成的完成次数 */private Integer n = 1;/** 是否为流式输出;就是一蹦一蹦的,出来结果 */private boolean stream = false;/** 停止输出标识 */private List<String> stop;/** 输出字符串限制;0 ~ 4096 */@JsonProperty("max_tokens")private Integer maxTokens = 2048;/** 频率惩罚;降低模型重复同一行的可能性 */@JsonProperty("frequency_penalty")private double frequencyPenalty = 0;/** 存在惩罚;增强模型谈论新话题的可能性 */@JsonProperty("presence_penalty")private double presencePenalty = 0;/** 生成多个调用结果,只显示最佳的。这样会更多的消耗你的 api token */@JsonProperty("logit_bias")private Map logitBias;/** 调用标识,避免重复调用 */private String user;@Getter@AllArgsConstructorpublic enum Model {/** gpt-3.5-turbo */GPT_3_5_TURBO("gpt-3.5-turbo"),/** GPT4.0 */GPT_4("gpt-4"),/** GPT4.0 超长上下文 */GPT_4_32K("gpt-4-32k"),;private String code;}}
ChatCompletionResponse类——JSON响应映射为Java对象
是ChatGPT-SDK中用于封装 OpenAI 对话接口(chat/completions)返回结果的核心数据模型类,
主要作用是将接口返回的JSON响应映射为Java对象,方便开发者提取和使用响应信息。
@Data
@JsonIgnoreProperties(ignoreUnknown = true)
public class ChatCompletionResponse implements Serializable {/** ID */private String id;/** 对象 */private String object;/** 模型 */private String model;/** 对话 */private List<ChatChoice> choices;/** 创建 */private long created;/** 耗材 */private Usage usage;/*** 该指纹代表模型运行时使用的后端配置。* https://platform.openai.com/docs/api-reference/chat*/@JsonProperty("system_fingerprint")private String systemFingerprint;}Message类——定义对话信息对象
这段代码定义了一个 Message 类,用于封装消息相关的信息(通常用于对话场景,比如和 AI 聊天时的消息内容)结合了 Lombok 注解、Jackson 注解和建造者模式,
@Data
@JsonInclude(JsonInclude.Include.NON_NULL)//指定 JSON 序列化时只包含非 null 的字段。//例如,如果 name 为 null,序列化后的 JSON 中不会出现 name 字段,减少无效数据。
@JsonIgnoreProperties(ignoreUnknown = true)//JSON 反序列化时忽略类中不存在的字段。//比如接口返回的JSON里有一个timestamp字段,而Message类没有这个属性,反序列化时不会报错。
public class Message implements Serializable {//实现可序列化//标记类可序列化,方便在网络传输或持久化时将对象转换为字节流//(比如通过 Retrofit 发送请求时,对象会被序列化为 JSON 字节流)。private String role;private String content;private String name;public Message() {}private Message(Builder builder) {this.role = builder.role;this.content = builder.content;this.name = builder.name;}
//无参构造器 主要是为了JSON序列化和反序列化时使用
//私有的 Builder 构造器 用于通过 Builder 模式构造 Message 对象public static Builder builder() {return new Builder();}/*** 建造者模式* Builder 模式的优势在于,它允许你通过一步一步的设置各个属性,* 最终构造出一个 Message 对象,而不需要提供一个复杂的构造函数。*/public static final class Builder {private String role;private String content;private String name;public Builder() {}public Builder role(Constants.Role role) {//通过 Builder 模式,你可以一次性设置多个属性,并且可以按任意顺序进行设置,不会因为顺序不对而导致参数错误。//方法返回 this,实现了 链式调用。因此,代码变得更加简洁,阅读性更强。this.role = role.getCode();return this;//这个方法接收一个 Constants.Role 类型的参数,调用其 getCode() 方法,并设置 role 字段。// Constants.Role 类是一个枚举,getCode() 方法返回该枚举值的代码。}public Builder content(String content) {this.content = content;return this;}public Builder name(String name) {this.name = name;return this;}public Message build() {return new Message(this);}//build() 方法使用构造器中的值创建一个 Message 对象,并返回它。}}1. 类注解说明
@Data:Lombok 提供的注解,自动生成类的getter、setter、toString、equals、hashCode等方法。@JsonInclude(JsonInclude.Include.NON_NULL):Jackson 提供的注解,指定 JSON 序列化时只包含非 null 的字段例如,如果
name为null,序列化后的 JSON 中不会出现name字段,减少无效数据。
@JsonIgnoreProperties(ignoreUnknown = true):Jackson 注解,JSON 反序列化时忽略类中不存在的字段。比如接口返回的 JSON 里有一个
timestamp字段,而Message类没有这个属性,反序列化时不会报错。
implements Serializable:标记类可序列化,方便在网络传输或持久化时将对象转换为字节流比如通过 Retrofit 发送请求时,对象会被序列化为 JSON 字节流。
2. 类属性
private String role; // 角色(比如 "user" 表示用户,"assistant" 表示 AI)
private String content; // 消息内容(比如用户的提问或 AI 的回答)
private String name; // 消息发送者的名称(可选,可能用于区分不同用户)
3. 构造方法
无参构造方法
public Message() {}:JSON 反序列化时需要无参构造器,否则 Jackson 无法实例化对象。
私有的 Builder 构造器 用于通过 Builder 模式构造
Message对象。
4. 建造者模式(Builder 内部类)
这是核心部分,Message 类的构建是通过 Builder 模式 来完成的。
Builder 模式的优势在于,它允许你通过一步一步的设置各个属性,最终构造出一个 Message 对象,而不需要提供一个复杂的构造函数。(可以直接使用了,无需在后续使用中构造或编写构造类)
通过 Builder 模式,你可以一次性设置多个属性,并且可以按任意顺序进行设置,不会因为顺序不对而导致参数错误。
(1)使用步骤
构造方法:Builder 没有任何参数的构造方法,这是常见的 Builder 模式实现方法,它通过 Builder 的 链式方法(每个方法调用后都返回 this)来逐步设置各个属性。
public Builder role(Constants.Role role) {this.role = role.getCode();return this;}(2)Builder 方法解析
role(Constants.Role role):接收Constants.Role枚举(比如USER、ASSISTANT),通过role.getCode()获取枚举对应的字符串(比如USER对应 "user"),避免直接写死字符串,减少错误。content(String content)、name(String name):直接设置消息内容和名称,返回Builder自身,支持链式调用。build():调用私有构造器new Message(this),将Builder中设置的属性传递给Message对象并返回。
5. 整体作用
Message 类主要用于封装对话中的单条消息,例如:
调用 AI 接口时,需要传递用户的提问消息(
role="user",content="1+1等于几")。接口返回 AI 的回答时,会包含 AI 的消息(
role="assistant",content="等于2")。
通过 Lombok 注解简化了 getter/setter 等方法,Jackson 注解保证了 JSON 序列化 / 反序列化的兼容性,建造者模式则让对象创建更灵活、可读性更高。
对接API配置类

这两个类是用于处理 OpenAI API 响应数据的 Java 实体类,分别负责封装通用响应结构和令牌使用统计信息,设计上兼顾了灵活性和兼容性。
一、OpenAiResponse<T> 类:通用响应封装(泛型设计)
@Data
@JsonIgnoreProperties(ignoreUnknown = true)
public class OpenAiResponse<T> implements Serializable {private String object;private List<T> data;private Error error;@Datapublic class Error {private String message;private String type;private String param;private String code;}}这个类是一个泛型容器,用于统一接收 OpenAI 各种接口的响应数据
核心特点是通过泛型适配不同类型的返回内容。
关键属性
String object:表示响应对象的类型(OpenAI 接口规范中的字段)List<T> data:泛型列表,存储接口返回的核心数据。T是泛型参数,可根据具体接口动态指定类型:例如调用对话接口时,
T可以是ChatCompletionResponse(对话结果);调用模型列表接口时,
T可以是Model(模型信息)。这种设计让
OpenAiResponse成为 “万能容器”,无需为每个接口单独定义响应类。
Error error:错误信息对象,当接口调用失败时(如参数错误、权限问题),OpenAI 会返回错误详情,通过这个内部类接收。
内部类 Error
封装接口返回的错误信息,包含:
message:错误描述(如 “API 密钥无效”);type:错误类型(如 “invalid_request_error”);param:出错的参数名(如 “model”);code:错误代码(如 “invalid_api_key”)。
这些信息用于快速定位接口调用失败的原因。
二、Usage 类:令牌使用统计(计费核心数据)
@JsonIgnoreProperties(ignoreUnknown = true)
public class Usage implements Serializable {/** 提示令牌 */@JsonProperty("prompt_tokens")private long promptTokens;/** 完成令牌 */@JsonProperty("completion_tokens")private long completionTokens;/** 总量令牌 */@JsonProperty("total_tokens")private long totalTokens;public long getPromptTokens() {return promptTokens;}public void setPromptTokens(long promptTokens) {this.promptTokens = promptTokens;}public long getCompletionTokens() {return completionTokens;}public void setCompletionTokens(long completionTokens) {this.completionTokens = completionTokens;}public long getTotalTokens() {return totalTokens;}public void setTotalTokens(long totalTokens) {this.totalTokens = totalTokens;}}OpenAI API 按 “令牌(Token)” 计费,Usage 类专门用于对接、接收、记录一次接口调用中令牌的消耗情况。
关键属性
promptTokens:提示令牌数(用户输入的内容转换的令牌数);completionTokens:完成令牌数(AI 生成的响应内容转换的令牌数);totalTokens:总令牌数(前两者之和,是计费的核心依据)。
三、两个类的关联与作用
在实际接口调用中,这两个类通常配合使用:
调用 OpenAI 接口(如对话接口)后,返回的 JSON 响应会被反序列化为
OpenAiResponse<具体数据类型>;具体数据类型(如
ChatCompletionResponse)内部通常会包含一个Usage类型的属性,用于记录本次调用的令牌消耗。
总结
OpenAiResponse<T>是通用响应框架,通过泛型实现对不同接口响应数据的兼容,同时统一处理错误信息;Usage是专项数据载体,专注于记录令牌消耗,直接关联 API 调用成本;
两者均通过 Jackson 注解保证 JSON 解析的兼容性,通过序列化接口支持数据传输,是对接 OpenAI API 不可或缺的基础类。
问答模型
方法废弃推荐使用 test_chat_completions
一、QAChoice 类:AI 响应的 “选项” 封装
@Data
@JsonIgnoreProperties(ignoreUnknown = true)
public class QAChoice implements Serializable {private long index;private String text;private Object logprobs;@JsonProperty("finish_reason")private String finishReason;}用于封装 AI 对单个问题生成的一条回答结果(如果请求时设置 n > 1,会生成多个 QAChoice)。
属性说明:
index:回答的序号(如果生成多个回答,用于区分顺序)。text:AI 生成的回答文本(核心内容)。logprobs:回答的概率信息(调试用,通常为null或Object类型,可忽略)。@JsonProperty("finish_reason"):JSON 字段finish_reason映射到finishReason属性,标识回答结束的原因(如stop表示正常结束)。
二、QACompletionRequest 类:请求参数的 “全能配置”
@Data
@Builder
@Slf4j
@JsonInclude(JsonInclude.Include.NON_NULL)
@NoArgsConstructor
@AllArgsConstructor
@JsonIgnoreProperties(ignoreUnknown = true)
public class QACompletionRequest implements Serializable {/** 默认模型 */@NonNull@Builder.Defaultprivate String model = Model.TEXT_DAVINCI_003.getCode();/** 问题描述 */@NonNullprivate String prompt;private String suffix;/** 控制温度【随机性】;0到2之间。较高的值(如0.8)将使输出更加随机,而较低的值(如0.2)将使输出更加集中和确定 */private double temperature = 0.2;/** 多样性控制;使用温度采样的替代方法称为核心采样,其中模型考虑具有top_p概率质量的令牌的结果。因此,0.1 意味着只考虑包含前 10% 概率质量的代币 */@JsonProperty("top_p")private Double topP = 1d;/** 为每个提示生成的完成次数 */private Integer n = 1;/** 是否为流式输出;就是一蹦一蹦的,出来结果 */private boolean stream = false;/** 停止输出标识 */private List<String> stop;/** 输出字符串限制;0 ~ 4096 */@JsonProperty("max_tokens")private Integer maxTokens = 2048;@Builder.Defaultprivate boolean echo = false;/** 频率惩罚;降低模型重复同一行的可能性 */@JsonProperty("frequency_penalty")private double frequencyPenalty = 0;/** 存在惩罚;增强模型谈论新话题的可能性 */@JsonProperty("presence_penalty")private double presencePenalty = 0;/** 生成多个调用结果,只显示最佳的。这样会更多的消耗你的 api token */@JsonProperty("best_of")@Builder.Defaultprivate Integer bestOf = 1;private Integer logprobs;@JsonProperty("logit_bias")private Map logitBias;/** 调用标识,避免重复调用 */private String user;@Getter@AllArgsConstructorpublic enum Model {TEXT_DAVINCI_003("text-davinci-003"),TEXT_DAVINCI_002("text-davinci-002"),DAVINCI("davinci"),;private String code;}}用于向 OpenAI 发送文本问答请求时,配置所有必要的参数(如模型、问题、随机性等)。
核心注解:
@NoArgsConstructor/@AllArgsConstructor:生成无参 / 全参构造器(JSON 反序列化需要无参构造器)。@JsonIgnoreProperties(ignoreUnknown = true):同上,兼容接口新增字段。implements Serializable:支持序列化。
关键属性:
model:调用的 AI 模型(通过内部枚举Model定义常用模型,避免硬编码错误,默认text-davinci-003)。prompt:问题描述(必填,如 “1+1 等于几?”)。temperature:控制回答的随机性(0~2,值越高越随机,默认 0.2 更确定)。topP:替代temperature的采样方式(0~1,如 0.1 只从概率前 10% 的词汇中选)。n:为每个问题生成的回答数量(默认 1)。stream:是否流式输出(true则结果分块返回,类似 “打字效果”)。stop:停止生成的标识(如设置["。"],遇到句号就停止)。maxTokens:回答的最大长度(0~4096,默认 2048)。frequencyPenalty/presencePenalty:惩罚机制(降低重复内容 / 增强新话题的可能性)。user:调用者标识(防止重复请求)。
内部枚举
Model:定义常用模型的字符串标识(如TEXT_DAVINCI_003对应text-davinci-003),避免直接写字符串出错。
三、QACompletionResponse 类:响应结果的 “统一封装”
@Data
@JsonIgnoreProperties(ignoreUnknown = true)
public class QACompletionResponse implements Serializable {/** ID */private String id;/** 对象 */private String object;/** 模型 */private String model;/** 对话 */private QAChoice[] choices;/** 创建 */private long created;/** 耗材 */private Usage usage;}用于接收 OpenAI 接口返回的完整响应数据,包含回答、模型、耗材等信息。
属性说明:
id:请求的唯一标识(用于追踪)。object:响应对象类型(OpenAI 接口规范字段,如text_completion)。model:实际使用的模型(和请求时的model对应)。choices:AI 生成的回答列表(QAChoice[]类型,每个元素是一条回答)。created:响应生成的时间戳。usage:令牌(Token)消耗统计(关联Usage类,记录本次请求的令牌使用量,用于计费)。
四、三个类的关联与作用
在文本问答流程中,这三个类的协作关系是:
构建
QACompletionRequest:设置问题、模型、随机性等参数。发送请求到 OpenAI 接口。
接收响应并反序列化为
QACompletionResponse:从中获取choices(AI 回答)和usage(令牌消耗)。
总结
这三个类是文本问答场景的核心数据模型:
QACompletionRequest负责 “发请求的参数”;QAChoice负责 “单条回答的参数”;QACompletionResponse负责 “收响应的参数”。
身份认证拦截
这段代码定义了一个名为 OpenAiInterceptor 的类,它实现了 OkHttp3 库中的 Interceptor 接口,用于在发送 HTTP 请求到 OpenAI 相关接口时,对请求进行拦截和预处理,主要是添加认证相关的信息。

public class OpenAiInterceptor implements Interceptor {/** OpenAi apiKey 需要在官网申请 */private String apiKey;/** 访问授权接口的认证 Token */private String authToken;public OpenAiInterceptor(String apiKey, String authToken) {this.apiKey = apiKey;this.authToken = authToken;}@NotNull@Overridepublic Response intercept(Chain chain) throws IOException {return chain.proceed(this.auth(apiKey, chain.request()));}private Request auth(String apiKey, Request original) {// 设置Token信息;如果没有此类限制,是不需要设置的。HttpUrl url = original.url().newBuilder().addQueryParameter("token", authToken).build();// 创建请求return original.newBuilder().url(url).header(Header.AUTHORIZATION.getValue(), "Bearer " + apiKey).header(Header.CONTENT_TYPE.getValue(), ContentType.JSON.getValue()).method(original.method(), original.body()).build();}}OpenAiInterceptor 是一个请求拦截器,其核心功能是在 HTTP 请求发送到 OpenAI 接口之前,自动为请求添加必要的认证参数和头部信息,以确保请求能够通过 OpenAI 的身份验证并被正确处理。
成员变量
private String apiKey;:OpenAI 的 API 密钥,用于身份验证,需要在 OpenAI 官网申请获取。private String authToken;:访问授权接口的认证令牌,可能用于特定的授权验证场景。
构造方法
public OpenAiInterceptor(String apiKey, String authToken) {this.apiKey = apiKey;this.authToken = authToken;
}
通过构造方法传入 apiKey 和 authToken,以便在拦截请求时使用这些认证信息。
intercept 方法
Interceptor 就是在 HTTP 请求发送前、或响应返回后,对请求 / 响应进行 “拦截处理” 的组件。
@NotNull
@Override
public Response intercept(Chain chain) throws IOException {return chain.proceed(this.auth(apiKey, chain.request()));
}
这是 Interceptor 接口要求实现的方法。Chain 对象代表了请求的调用链
chain.request() 可以获取到原始的 Request 对象。该方法首先调用 auth 方法对原始请求进行认证信息的添加,然后通过 chain.proceed(request) 将处理后的请求继续传递下去,最终返回响应 Response。
在 OkHttp 的拦截器机制中,
Chain(请求链)对象可以理解为 “请求的传递管道”,它连接了多个拦截器,并负责将请求从一个拦截器传递到下一个,最终发送到服务器并返回响应。
auth 方法
private Request auth(String apiKey, Request original) {// 设置Token信息;如果没有此类限制,是不需要设置的。HttpUrl url = original.url().newBuilder().addQueryParameter("token", authToken).build();// 创建请求return original.newBuilder().url(url).header(Header.AUTHORIZATION.getValue(), "Bearer " + apiKey).header(Header.CONTENT_TYPE.getValue(), ContentType.JSON.getValue()).method(original.method(), original.body()).build();
}
首先,通过
original.url().newBuilder()获取原始请求的 URL 构建器,然后使用addQueryParameter("token", authToken)向 URL 中添加token查询参数,参数值为authToken。这一步是为了在 URL 中携带认证令牌信息。
接着,使用
original.newBuilder()创建一个新的请求构建器。url(url):将修改后的 URL(添加了token参数的 URL)设置到新的请求中。header(Header.AUTHORIZATION.getValue(), "Bearer " + apiKey):添加
Authorization头部信息,值为Bearer加上apiKey,这是 OpenAI 常用的身份验证方式,Bearer是一种授权类型,后面跟着 API 密钥。
header(Header.CONTENT_TYPE.getValue(), ContentType.JSON.getValue()):添加
Content-Type头部信息,指定请求体的内容类型为 JSON,因为与 OpenAI 交互的请求体通常是 JSON 格式。
method(original.method(), original.body()):保持原始请求的 HTTP 方法(如GET、POST等)和请求体不变。
最后,通过
build()方法构建出新的Request对象并返回。
总结
OpenAiInterceptor 类的作用是在每次发送到 OpenAI 相关接口的 HTTP 请求时,自动为请求添加 URL 中的 token 查询参数、Authorization 头部的 API 密钥以及 Content-Type 头部的 JSON 类型声明,从而实现请求的认证和格式适配,确保请求能够被 OpenAI 接口正确识别和处理。
简单测试
JUnit 测试类
@Slf4j//这段代码是一个用于测试 ChatGPT - SDK 功能的 JUnit 测试类 ApiTest,
//主要目的是验证 SDK 对 OpenAI 对话接口的封装和调用是否正常。
public class ApiTest {private OpenAiSession openAiSession;@Before//该方法会在每个 @Test 方法执行前运行,用于初始化测试环境(这里是初始化与 OpenAI 交互的会话)。//构建 Configuration 对象,配置 API 主机地址和授权 Token(替代传统的 API Key 认证)。//通过 DefaultOpenAiSessionFactory(默认会话工厂)创建会话工厂实例。//从工厂获取 OpenAiSession 会话对象,供后续测试用例使用。public void test_OpenAiSessionFactory() {// 1. 配置文件//构建 Configuration 对象,配置 API 主机地址和授权 Token(替代传统的 API Key 认证)。Configuration configuration = new Configuration();//configuration.setApiHost("https://pro-share-aws-api.zcyai.com/");configuration.setApiHost("https://*************.cn/");//configuration.setApiHost("https://api.openai.com");configuration.setApiKey("sk-****************************************************");// 可以根据课程首页评论置顶说明获取 apihost、apikey:https://t.zsxq.com/0d3o5FKvc//configuration.setAuthToken("********************************************************************");// 2. 创建会话工厂OpenAiSessionFactory factory = new DefaultOpenAiSessionFactory(configuration);// 3. 获取并开启会话this.openAiSession = factory.openSession();}/*** 简单问答模式,方法废弃推荐使用 test_chat_completions*/@Testpublic void test_qa_completions() throws JsonProcessingException {//调用completions方法,传入问题,请求 OpenAI 生成回答。//结果通过 ObjectMapper 序列化为 JSON 并打印日志。QACompletionResponse response01 = openAiSession.completions("写个java冒泡排序");log.info("测试结果:{}", new ObjectMapper().writeValueAsString(response01.getChoices()));}/*** 此对话模型 3.5 接近于官网体验** 文档:https://platform.openai.com/docs/guides/text-generation/chat-completions-api* 你可以替换能访问的 apihost【https://api.openai.com】 和 $OPENAI_API_KEY 进行 http 测试* curl https://api.openai.com/v1/chat/completions \* -H "Content-Type: application/json" \* -H "Authorization: Bearer $OPENAI_API_KEY" \* -d '{* "model": "gpt-3.5-turbo",* "messages": [* {* "role": "system",* "content": "You are a helpful assistant."* },* {* "role": "user",* "content": "Who won the world series in 2020?"* },* {* "role": "assistant",* "content": "The Los Angeles Dodgers won the World Series in 2020."* },* {* "role": "user",* "content": "Where was it played?"* }* ]* }'*/@Testpublic void test_chat_completions() {// 1. 创建参数ChatCompletionRequest chatCompletion = ChatCompletionRequest.builder().messages(Collections.singletonList(Message.builder().role(Constants.Role.USER).content("写个java冒泡排序").build())).model(ChatCompletionRequest.Model.GPT_3_5_TURBO.getCode()).build();// 2. 发起请求ChatCompletionResponse chatCompletionResponse = openAiSession.completions(chatCompletion);// 3. 解析结果chatCompletionResponse.getChoices().forEach(e -> {log.info("测试结果:{}", e.getMessage());});}}写一个 JUnit 测试类,用于测试基于 OpenAI API 封装的 SDK 功能,主要验证和 OpenAI 对话接口的交互是否正常。
成员变量与初始化(@Before 逻辑)
private OpenAiSession openAiSession;:用于和 OpenAI 进行会话交互的对象。@Before方法(test_OpenAiSessionFactory):在每个测试方法(@Test标注的方法)执行前运行,用于初始化openAiSession。配置信息设置:创建
Configuration对象,设置 API 主机地址(如https://apis.itedus.cn/)和 API Key(用于 OpenAI 身份验证)。会话工厂创建:通过
DefaultOpenAiSessionFactory创建会话工厂实例,会话工厂负责创建和管理与 OpenAI 的会话。会话获取:从会话工厂获取
OpenAiSession会话对象,供后续测试用例使用。
测试方法 test_qa_completions
@Test:标注该方法为 JUnit 测试方法。功能:测试简单问答模式(该方法已废弃,推荐使用
test_chat_completions)。调用
openAiSession.completions方法,传入问题 “写个 java 冒泡排序”,请求 OpenAI 生成回答。使用
ObjectMapper将响应结果序列化为 JSON 字符串,并通过日志打印出来。
测试方法 test_chat_completions
功能:测试更接近 OpenAI 官网体验的对话模型(基于
gpt-3.5-turbo)。创建请求参数:使用建造者模式创建
ChatCompletionRequest对象,设置对话消息(用户角色,问题为 “写个 java 冒泡排序”)和模型(gpt-3.5-turbo)。发起请求:调用
openAiSession.completions方法,传入创建好的请求参数,获取响应ChatCompletionResponse。解析结果:遍历响应中的每个选项(
Choice),打印出 AI 生成的消息内容。
总结
这个测试类的作用是验证封装后的 SDK 能够正确地与 OpenAI API 进行交互,发送请求并获取符合预期的响应。通过不同的测试方法,分别测试了简单问答和更复杂的对话模型场景,确保 SDK 在这些场景下的功能正常。
调用 AI 对话接口
这段代码是一个使用 OkHttp + Retrofit 调用 AI 对话接口的示例程序,功能是向指定的 API 发送请求(生成 Java 冒泡排序代码)并打印返回结果。
public class HttpClientTest {public static void main(String[] args) {HttpLoggingInterceptor httpLoggingInterceptor = new HttpLoggingInterceptor();httpLoggingInterceptor.setLevel(HttpLoggingInterceptor.Level.BODY);OkHttpClient okHttpClient = new OkHttpClient.Builder().addInterceptor(httpLoggingInterceptor).addInterceptor(chain -> {Request original = chain.request();// 从请求中获取 token 参数,并将其添加到请求路径中HttpUrl url = original.url().newBuilder().addQueryParameter("token", "eyJhbGciOiJIUzI1NiJ9.eyJzdWIiOiJ4ZmciLCJleHAiOjE2ODMyNzIyMjAsImlhdCI6MTY4MzI2ODYyMCwianRpIjoiOTkwMmM4MjItNzI2MC00OGEwLWI0NDUtN2UwZGZhOGVhOGYwIiwidXNlcm5hbWUiOiJ4ZmcifQ.Om7SdWdiIevvaWdPn7D9PnWS-ZmgbNodYTh04Tfb124").build();Request request = original.newBuilder().url(url).header(Header.AUTHORIZATION.getValue(), "Bearer " + "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").header(Header.CONTENT_TYPE.getValue(), ContentType.JSON.getValue()).method(original.method(), original.body()).build();return chain.proceed(request);}).build();IOpenAiApi openAiApi = new Retrofit.Builder().baseUrl("http://api.xfg.im/b8b6/").client(okHttpClient).addCallAdapterFactory(RxJava2CallAdapterFactory.create()).addConverterFactory(JacksonConverterFactory.create()).build().create(IOpenAiApi.class);Message message = Message.builder().role(Constants.Role.USER).content("写一个java冒泡排序").build();ChatCompletionRequest chatCompletion = ChatCompletionRequest.builder().messages(Collections.singletonList(message)).model(ChatCompletionRequest.Model.GPT_3_5_TURBO.getCode()).build();Single<ChatCompletionResponse> chatCompletionResponseSingle = openAiApi.completions(chatCompletion);ChatCompletionResponse chatCompletionResponse = chatCompletionResponseSingle.blockingGet();chatCompletionResponse.getChoices().forEach(e -> {System.out.println(e.getMessage());});}}一、核心作用
手动构建网络请求客户端
调用 AI 接口(类似 OpenAI 的对话接口)
发送 “写一个 Java 冒泡排序” 的请求
接收并打印 AI 的回答
二、代码分步解析
1. 日志拦截器:打印请求 / 响应详情
// 创建日志拦截器,用于打印网络请求的详细信息(方便调试)
HttpLoggingInterceptor httpLoggingInterceptor = new HttpLoggingInterceptor();
httpLoggingInterceptor.setLevel(HttpLoggingInterceptor.Level.BODY); // 打印请求体、响应体等完整信息
作用:记录请求发送的内容、URL、头部信息,以及服务器返回的响应内容,方便开发时排查问题。
2. 构建 OkHttp 客户端:配置网络请求参数
OkHttpClient okHttpClient = new OkHttpClient.Builder().addInterceptor(httpLoggingInterceptor) // 添加日志拦截器.addInterceptor(chain -> { // 添加自定义拦截器(处理认证信息)Request original = chain.request(); // 获取原始请求// 1. 给 URL 添加上 token 参数(类似访问密码,放在网址里)HttpUrl url = original.url().newBuilder().addQueryParameter("token", "eyJhbGciOiJIUzI1NiJ9...") // 具体的 token 值.build();// 2. 构建新的请求,添加认证头部和内容类型Request request = original.newBuilder().url(url) // 使用添加了 token 的新 URL.header(Header.AUTHORIZATION.getValue(), "Bearer " + "sk-hIaAI4y5cdh8weSZblxm...") // API 密钥(类似登录密码).header(Header.CONTENT_TYPE.getValue(), ContentType.JSON.getValue()) // 声明请求体是 JSON 格式.method(original.method(), original.body()) // 保持原始请求的方法(如 POST)和请求体.build();return chain.proceed(request); // 让处理后的请求继续发送}).build(); // 完成客户端构建
作用:OkHttpClient 是发送网络请求的 “工具”,这里通过配置拦截器,自动给所有请求添加认证信息(token 和 API Key),不用每次发请求都手动写,简化代码。
3. 构建 Retrofit 实例:关联接口与客户端
IOpenAiApi openAiApi = new Retrofit.Builder().baseUrl("http://api.xfg.im/b8b6/") // API 的基础地址(类似网址的“前缀”).client(okHttpClient) // 关联上面创建的 OkHttp 客户端.addCallAdapterFactory(RxJava2CallAdapterFactory.create()) // 支持 RxJava 的异步处理(Single 类型).addConverterFactory(JacksonConverterFactory.create()) // 自动把 JSON 响应转换成 Java 对象.build() // 构建 Retrofit 实例.create(IOpenAiApi.class); // 创建接口的实现类(Retrofit 动态生成)
作用:Retrofit 是 OkHttp 的 “高级包装”,把 HTTP 接口(IOpenAiApi)转换成 Java 方法,让调用接口像调用普通方法一样简单。
4. 构建请求参数:告诉 AI 要做什么
// 1. 创建一条消息:角色是“用户”,内容是“写一个java冒泡排序”
Message message = Message.builder().role(Constants.Role.USER) // 角色:用户(提问者).content("写一个java冒泡排序") // 具体问题.build();// 2. 构建完整的请求对象
ChatCompletionRequest chatCompletion = ChatCompletionRequest.builder().messages(Collections.singletonList(message)) // 把上面的消息放进列表(支持多轮对话).model(ChatCompletionRequest.Model.GPT_3_5_TURBO.getCode()) // 指定使用的 AI 模型(GPT-3.5).build();
作用:像 “填写表单” 一样,告诉 AI 问题内容、使用的模型等信息,这些参数会被转换成 JSON 发送给服务器。
5. 发送请求并处理结果
// 1. 调用接口方法,获取异步响应(Single 是 RxJava 的异步类型)
Single<ChatCompletionResponse> chatCompletionResponseSingle = openAiApi.completions(chatCompletion);// 2. 阻塞等待响应结果(实际开发中常用异步回调,这里简化为同步等待)
ChatCompletionResponse chatCompletionResponse = chatCompletionResponseSingle.blockingGet();// 3. 遍历结果并打印 AI 的回答
chatCompletionResponse.getChoices().forEach(e -> {System.out.println(e.getMessage()); // 打印 AI 返回的消息内容
});
作用:发送请求到 API 服务器,等待 AI 生成回答后,打印出结果(这里会输出冒泡排序的 Java 代码)。
三、整体流程总结
准备工具:创建 OkHttp 客户端(带日志和认证拦截器)和 Retrofit 实例(关联接口)。
填写请求:构建包含问题的请求参数(用户角色 + 问题内容 + 模型)。
发送请求:调用 Retrofit 生成的接口方法,发送请求到服务器。
处理结果:接收 AI 的回答并打印。
这个过程就像 “用代码模拟浏览器访问 AI 网站”,自动完成登录(认证)、提问、接收回答的全过程。
运行接口调用流程
简单文本问答模式
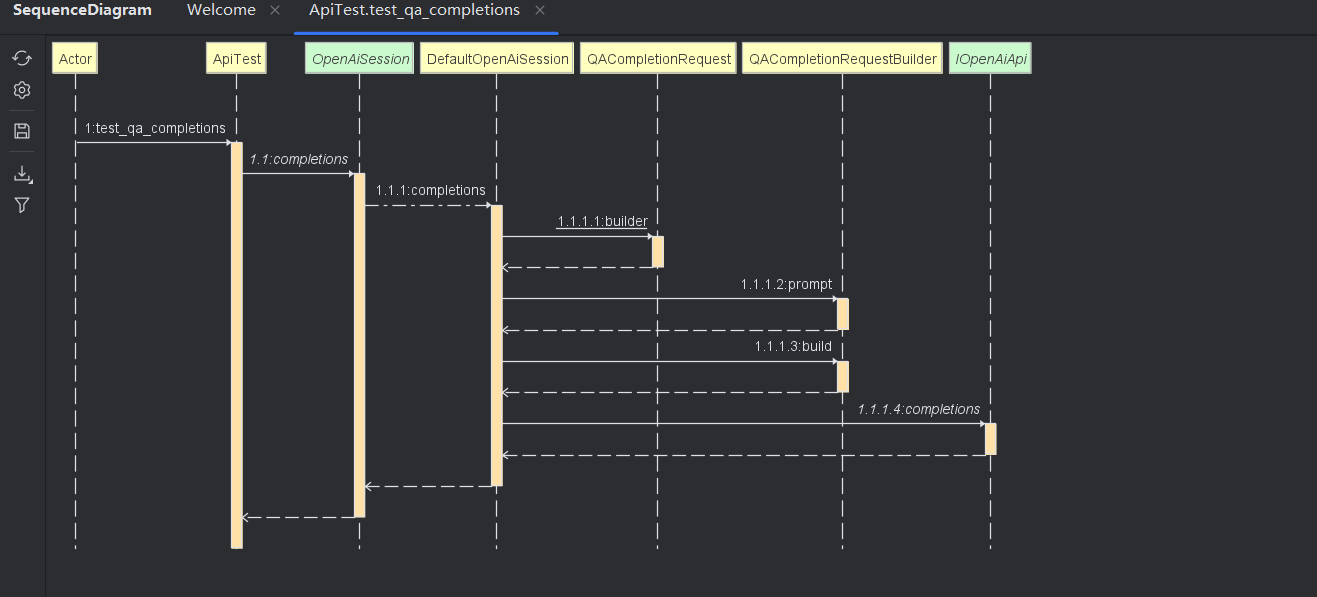
Chat-GPT3.5 对话模型
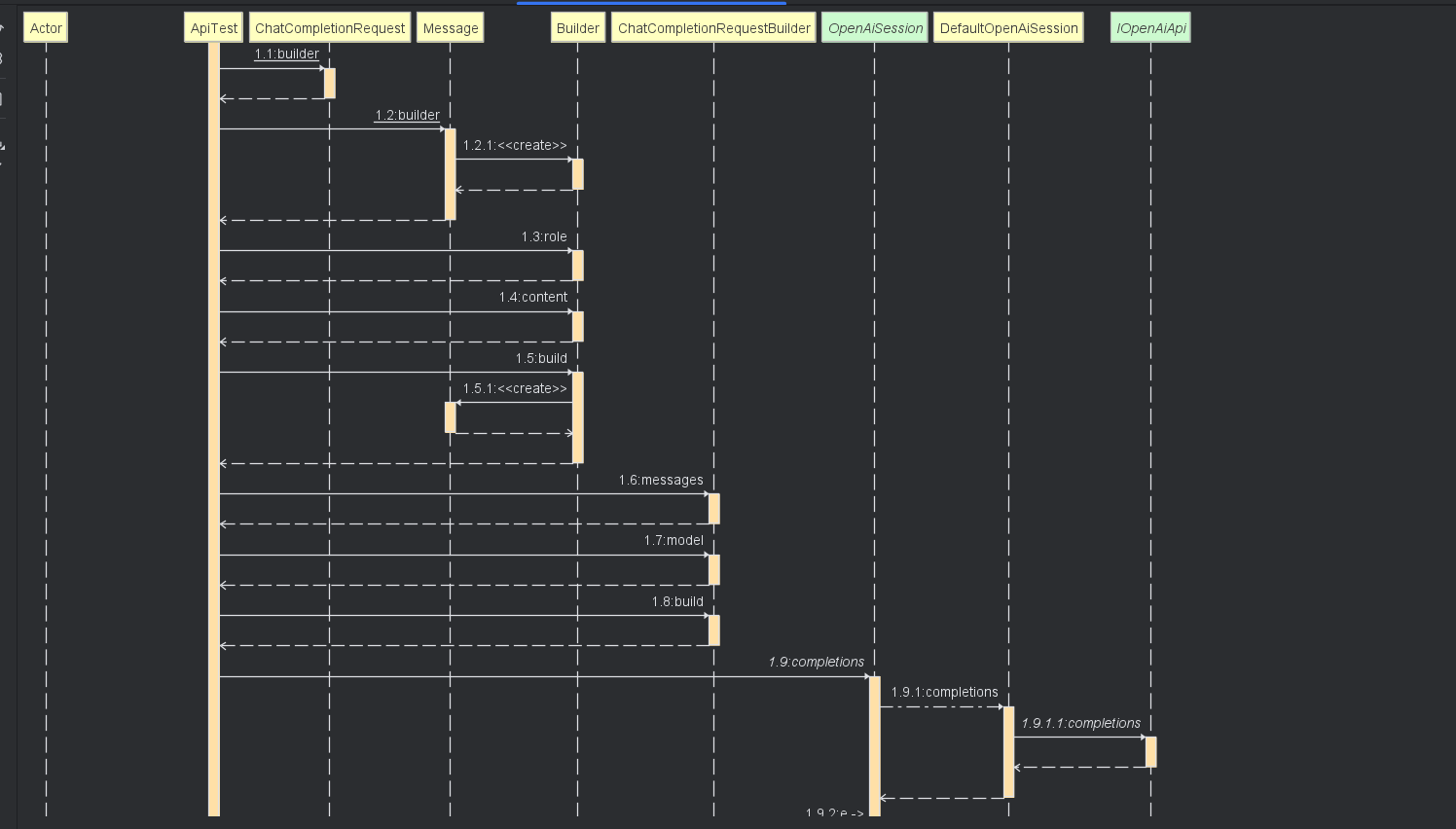
完成测试
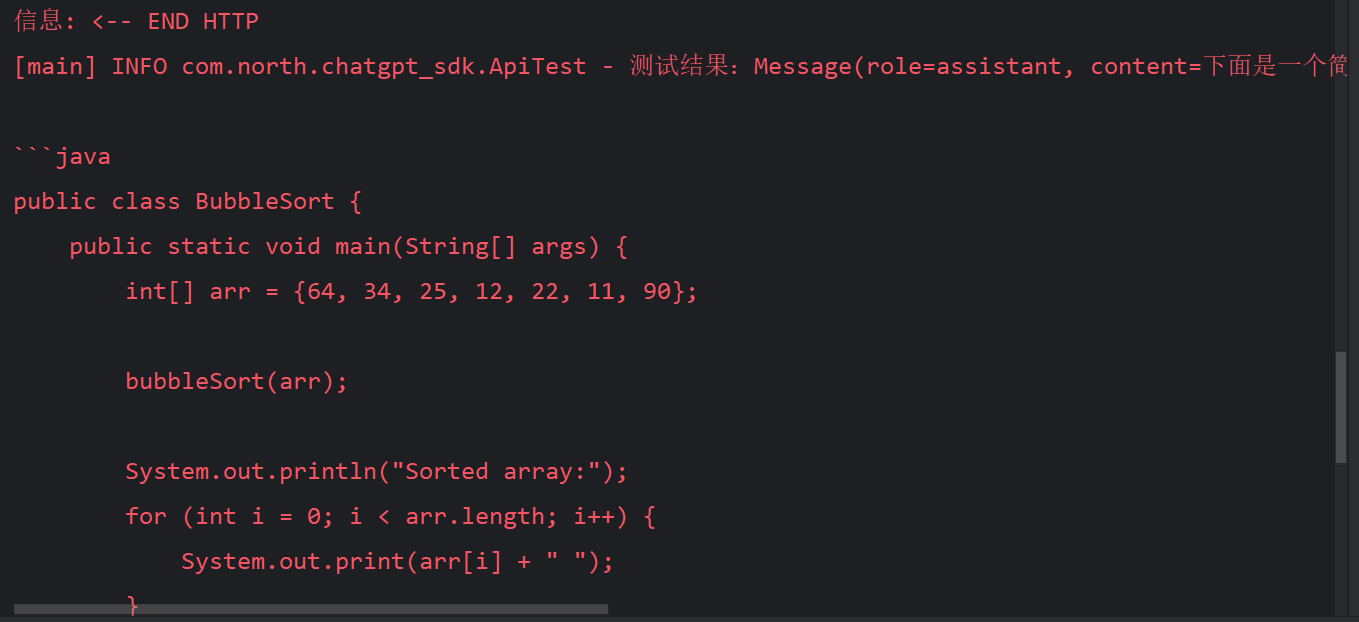
信息: <-- END HTTP
[main] INFO com.north.chatgpt_sdk.ApiTest - 测试结果:Message(role=assistant, content=下面是一个简单的Java冒泡排序的实现:```java
public class BubbleSort {public static void main(String[] args) {int[] arr = {64, 34, 25, 12, 22, 11, 90};bubbleSort(arr);System.out.println("Sorted array:");for (int i = 0; i < arr.length; i++) {System.out.print(arr[i] + " ");}}public static void bubbleSort(int[] arr) {int n = arr.length;for (int i = 0; i < n - 1; i++) {for (int j = 0; j < n - i - 1; j++) {if (arr[j] > arr[j + 1]) {// Swap arr[j] and arr[j+1]int temp = arr[j];arr[j] = arr[j + 1];arr[j + 1] = temp;}}}}
}
```在这个例子中,我们定义了一个`bubbleSort`方法来实现冒泡排序。我们首先遍历数组,然后在每次遍历中比较相邻的元素,如果顺序不对则交换它们。最终,通过多次遍历和比较,数组中的元素将按照升序排列。, name=null)Process finished with exit code 0