量化金融|基于算法和模型的预测研究综述

一、研究背景与发展历程
- 1.
量化投资理论演进
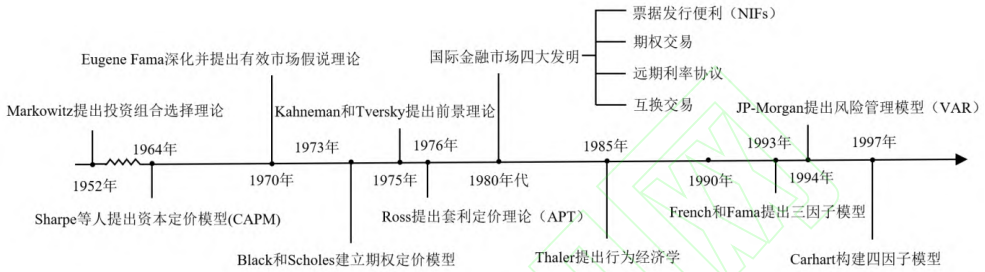
- •奠基阶段(1950s-1960s):Markowitz均值方差理论(1952)、CAPM模型(1964)奠定现代量化投资基础
- •衍生品定价(1970s-1980s):Black-Scholes期权定价模型(1973)、套利定价理论(APT,1976)
- •风险管理(1990s):VaR模型、行为金融学兴起
- •AI融合(21世纪):深度学习、强化学习与大语言模型(LLM)推动量化投资智能化发展
- 2.
技术驱动因素
- •大数据时代多源异构数据(股价、新闻、政策文本)的爆发式增长
- •机器学习在非线性模式识别与时序预测中的突破性应用
二、核心预测模型与技术对比
1. 传统机器学习模型
模型类型 | 典型算法 | 优势 | 局限性 | 代表研究 |
|---|---|---|---|---|
支持向量机 | SVM/SVR | 小样本非线性分类 | 核函数选择敏感 | Parray等(2020)准确率89.93% |
集成学习 | RF/XGBoost | 抗过拟合、特征重要性分析 | 解释性弱 | Han等(2023)胜率65.3% |
特征工程优化 | 小波去噪+TSVR | 噪声分离、计算效率高 | 可能丢失有效信息 | Zhang等(2023)命中率提升5.87% |
2. 深度学习模型
模型架构 | 创新点 | 应用场景 | 性能表现 | 文献案例 |
|---|---|---|---|---|
CNN-LSTM | 时空特征联合提取 | 多模态数据融合预测 | MAE 27.564(上证指数) | Lu等(2020) |
BiLSTM+注意力机制 | 双向时序依赖建模 | 股价与情感因子协同分析 | MAE降低20% | 袁婧等(2024) |
GAN-TrellisNet | 生成对抗网络改进 | 局部特征捕捉与训练加速 | MAE 0.0438 | 葛业波等(2023) |
3. 强化学习与大语言模型
- 强化学习:
- 框架特点:基于POMDP建模,动态调整投资组合(如TD3算法)
- 优势:自适应市场变化,夏普比率达2.68(Kabbani等,2023)
- 挑战:奖励函数设计复杂,需平衡收益与风险控制
- 大语言模型(LLM):
- 创新应用:
- 金融文本语义推理(Elahi等,2024)
- 检索增强生成框架FinSeer(Xiao等,2025)
- 局限:实时性不足,存在"幻觉生成"风险
- 创新应用:
三、关键技术突破
- 1.数据融合方法
- 多模态对齐:通过VMD分解解决政策文本与行情数据时间粒度差异
- 弱信号挖掘:停牌股/新股数据保留(Liu等,2024提出LSTMA+TCNA架构)
- 2.算法优化方向
- •参数搜索:改进麻雀算法优化BP神经网络(Liu等,2023)
- •约束设计:LASSO+PCA因子降维(胡聿文,2021)
- 3.可解释性增强
- LIME框架:可视化MLP模型决策过程(Wu等,2022)
- 直觉模糊推理:IIFI模型提供特征贡献度量化(Wang等,2022)
以下是基于论文《基于模型和算法的量化投资方法股票预测研究综述》的内容总结与模型分析:
一、研究背景与发展历程
- 1.
量化投资理论演进
- •
奠基阶段(1950s-1960s):Markowitz均值方差理论(1952)、CAPM模型(1964)奠定现代量化投资基础
- •
衍生品定价(1970s-1980s):Black-Scholes期权定价模型(1973)、套利定价理论(APT,1976)
- •
风险管理(1990s):VaR模型、行为金融学兴起
- •
AI融合(21世纪):深度学习、强化学习与大语言模型(LLM)推动量化投资智能化发展
- •
- 2.
技术驱动因素
- •
大数据时代多源异构数据(股价、新闻、政策文本)的爆发式增长
- •
机器学习在非线性模式识别与时序预测中的突破性应用
- •
二、核心预测模型与技术对比
1. 传统机器学习模型
模型类型 | 典型算法 | 优势 | 局限性 | 代表研究 |
|---|---|---|---|---|
支持向量机 | SVM/SVR | 小样本非线性分类 | 核函数选择敏感 | Parray等(2020)准确率89.93% |
集成学习 | RF/XGBoost | 抗过拟合、特征重要性分析 | 解释性弱 | Han等(2023)胜率65.3% |
特征工程优化 | 小波去噪+TSVR | 噪声分离、计算效率高 | 可能丢失有效信息 | Zhang等(2023)命中率提升5.87% |
2. 深度学习模型
模型架构 | 创新点 | 应用场景 | 性能表现 | 文献案例 |
|---|---|---|---|---|
CNN-LSTM | 时空特征联合提取 | 多模态数据融合预测 | MAE 27.564(上证指数) | Lu等(2020) |
BiLSTM+注意力机制 | 双向时序依赖建模 | 股价与情感因子协同分析 | MAE降低20% | 袁婧等(2024) |
GAN-TrellisNet | 生成对抗网络改进 | 局部特征捕捉与训练加速 | MAE 0.0438 | 葛业波等(2023) |
3. 强化学习与大语言模型
- •
强化学习:
- •
框架特点:基于POMDP建模,动态调整投资组合(如TD3算法)
- •
优势:自适应市场变化,夏普比率达2.68(Kabbani等,2023)
- •
挑战:奖励函数设计复杂,需平衡收益与风险控制
- •
- •
大语言模型(LLM):
- •
创新应用:
- •
金融文本语义推理(Elahi等,2024)
- •
检索增强生成框架FinSeer(Xiao等,2025)
- •
- •
局限:实时性不足,存在"幻觉生成"风险
- •
三、关键技术突破
- 1.
数据融合方法
- •
多模态对齐:通过VMD分解解决政策文本与行情数据时间粒度差异
- •
弱信号挖掘:停牌股/新股数据保留(Liu等,2024提出LSTMA+TCNA架构)
- •
- 2.
算法优化方向
- •
参数搜索:改进麻雀算法优化BP神经网络(Liu等,2023)
- •
约束设计:LASSO+PCA因子降维(胡聿文,2021)
- •
- 3.
可解释性增强
- •
LIME框架:可视化MLP模型决策过程(Wu等,2022)
- •
直觉模糊推理:IIFI模型提供特征贡献度量化(Wang等,2022)
- •
四、挑战与未来方向
- 1.
现存问题
- •
数据噪声与市场反身性导致模型泛化能力不足
- •
黑箱模型难以满足金融监管透明度要求
- •
- 2.
前沿趋势
- •因果推理:结合领域知识构建可解释预测框架
- •联邦学习:跨机构数据协作下的隐私保护建模
- •实时决策系统:高频交易场景的轻量化部署
五、典型模型性能对比
(以下表格摘自原文Table 1 & Table 2)
机器学习模型对比
模型 | 平均准确率 | 优势领域 |
|---|---|---|
XGBoost | 65.3% | 技术指标分析 |
AdaBoost+MVaR | MAE 0.0826 | 风险调整后收益优化 |
深度学习模型对比
模型 | RMSE | 创新点 |
|---|---|---|
CNN-BiLSTM | 0.4606 | 多头注意力机制 |
TELM(迁移学习) | 0.0530 | 多尺度数据分解 |