多模态大模型---第1节
专栏: 大模型算法
个人主页:云端筑梦狮
主要内容(极度适合于初学者)
多模态的基础概念, 多模态大模型的架构,模型的预训练, CLIP, Llava(包括所有的代码)
一.多模态大模型的基本概念
1. 概念
多模态大模型是一种能够处理和理解多种模态数据的人工智能模型。模态指的是数据的表现形式,例如文字、图像、音频、视频等。多模态大模型通过结合不同模态数据的特性,利用深度学习技术和大规模的训练数据,构建一个统一的框架来实现跨模态的感知、理解和生成能力。例如,一个多模态大模型可以同时处理文本描述和对应的图片,完成图像生成、描述生成、跨模态检索等任务。
为啥多模态难度高?所有数据结构的差别非常大,难以结合起来。
例如
1. 文字数据
text(bs, seq_len, d_model) == (30,100, 512)30个自然段 每个自然段100个词 每个词被变为了512个维度 chunk为文段 token为字数 seq_len为有多少行 d_model为有多少列
2. 表格数据
table (sample_size, features) 只有二维表 (多少个样本,每个样本的特征数)
3. 图像数据
image (sample_size, C, H, W) (多少张图,(代表chenels通道 RGB / RYB),高度, 宽度)
4. 音频数据
video (sample_size, Time_step, F) (音频的时长,时间步,声音频率)
5. 视频数据
video (sample, time_step, C, Height, Width) (多少个视频,每段视频的时间戳,C, H , W 同上图像) 帧数/帧率 (30,45,60)越高越清晰 越流畅 注意这个是没有声音的!!!
只要是文字的3维 transformer都能够处理 但是好不好就不一定了
放在同一个算法的难度点:不同数据的结构要统一 ---多模态数据的结构对齐 多模态数据的时间对齐 图像和时序的一一对应 必须图像 文字 等在时间轴上一一对应的(通过预处理来搞定)
多模态大模型广泛应用于多场景任务,如自动,驾驶中的视觉和语言指令结合、医疗影像分析中的图像和文本报告结合、智能客服中的语音与文字结合等。这种模型能更好地模拟人类在复杂情境中处理多种信息的能力。
多模态数据的最大挑战在于它们不在一个空间中,每种模态的结构和分布差异巨大,需要处理四种数据 文本数据 图像数据 视频数据 音频数据
2. 跨数据类型
- 图像数据:
- 结构:4 维 (N, C, H, W)。
- N:批量大小 (batch size)。
- C:通道数 (通常为 3,RGB)。
- H 和 W:图像高度和宽度。
- 特性:数据通常是局部相关 (如相邻像素相关),需要卷积操作提取局部特征。
- 结构:4 维 (N, C, H, W)。
- 时间序列数据:
- 结构:3 维 (N, T, F)。
- N:批量大小。
- T:时间步长。
- F:特征维度 (如传感器数据的特征数)。
- 特性:时间相关性强,依赖递归网络 (如 RNN) 或 Transformer 提取时间序列特征。
- 结构:3 维 (N, T, F)。
- 文本数据:
- 结构:2 维 (N, L) 或 3 维 (N, L, D)
- N:批量大小。
- L:句子长度 (不同样本可能长度不同)。
- 特性:离散数据,依赖序列建模 (如 Transformer) 理解上下文。
- 结构:2 维 (N, L) 或 3 维 (N, L, D)
- 视频数据:
- 结构:5 维 (N, T, C, H, W)。
- N:批量大小。
- T:时间帧数。
- C:通道数。
- H 和 W:帧的高度和宽度。
- 特性:视频数据包含时间和空间信息,既需要卷积提取空间特征,又需要时序建模处理时间相关性。
- 结构:5 维 (N, T, C, H, W)。
- 音频数据:
- 结构:3 维 (N, T, F)。
- N:批量大小。
- T:时间步长。
- F:频谱特征 (如 Mel 频谱的频率维度)。
- 特性:通常是时间相关数据,需要结合卷积和序列建模。
- 结构:3 维 (N, T, F)。
3. 多模态模型分类
一般分为两大类:多模态理解模型(主打能够理解多模态,但是不输出多模态)和多模态生成模型(多模态生成多模态)
- 多模态理解模型:这类模型的输入是多模态数据(如图像和文本),但输出不一定是多模态的,通常是一个预测结果或单一模态的数据(如分类标签或文字)。
- 例子:
- CLIP:输入图像和文本,用于在共享语义空间中匹配图像和文本,输出相似度或分类结果。
- LLaVA:输入图像和问题文本,输出自然语言回答。
- Flamingo:能够将视觉和文本信息结合,用于多模态对话或问答。
- ActionCLIP:视频理解模型,输入视频和文本描述,输出动作分类结果。
- 例子:
- 多模态生成模型:这类模型不仅可以理解多模态信息,其输出也可以是多模态的(如图像生成、视频生成或音频生成)。---非常费卡
- 例子:
- DALL・E:输入文本描述,生成对应的图像。
- Stable Diffusion:输入文本描述,生成高质量图像。
- SORA:输入视频和文本,生成符合语义的视频片段。
- VideoGPT:输入语义信息,生成动态的视频内容。
- GATO:支持输入和输出都是多模态的任务,例如从图像输入到动作输出。
- 例子:
这些模型在多模态处理上展现了强大的能力,多模态理解模型通常专注于模态间语义的对齐和推理,多模态生成模型则进一步实现了从语义到多模态内容的生成。多模态生成模型可以理解为多模态理解模型 + 一个生成解码器,因为生成模型不仅需要理解输入,还需要在解码阶段根据输入模态生成输出模态。理解多模态--->理解语义--->根据此通过生成器来生成多模态内容

注:这个表单可以拿去面试!
- 理解模型:输入数据 → 编码器 → 共享语义空间 → 输出单一模态预测。
- 理解模型架构:
- Encoder(CNN/Vit + transformer)多模态数据转为高维向量
- Aligenment Moudle:对比学习/跨模态对齐 对齐到共享语义空间
- Prediction Head:根据具体任务输出结果
- 生成模型:输入数据 → 编码器 → 跨模态交互模块 → 解码器 → 输出多模态内容。
- Encoder:和上面类似的
- Generative Decoder:图像 文字 视频用的编码器都不一样
- Cross-Model Interaction Module: 生成过程中多种模态需要反复交互
- 训练CLIP 0.4B --- RTX3090 两张
-
多模态微调---对齐好 可以接入任何的架构
二.模型架构-CLIP
CLIP(Contrastive Language - Image Pre - training)是 OpenAI 于 2021 年发布的一种多模态预训练模型,它能够将图像和文本嵌入到同一向量空间中,实现同一模型系统下的跨模态理解。其基本结构包括图像编码器和文本编码器,分别处理图像和文本数据。图像编码器通常采用卷积神经网络(如 ResNet)或 Vision Transformer(ViT),而文本编码器则使用 Transformer 模型。这些编码器分别处理图像和文本数据,并将它们投影到一个共同的嵌入空间中、从而实现图文分类、文本 - 图像检索等基础的多模态任务。
- 独创性的架构:CLIP 是一个无监督的、端到端的多模态系统,它是图文同向量空间对齐思路下效果最好的模型之一,它采用了经典的 Transformer 架构,是我们理解深度学习世界星罗棋布的多模态算法的根基。
- 独创性的预训练流程:CLIP 创新了精彩的预训练方式对比学习预训练(contrastive learning)、这种训练方式不仅不需要对数据进行标注(互联网上面公开就行)、还使得多模态模型的训练样本从 “特定任务数据” 拓展到了 “” 使得 CLIP 能够在下游任务中实现零样本学习,即在未见过的类别上进行分类或检索、使其在文本生成图像描述、跨模态搜索、图文匹配等任务中展现了前所未有的灵活性和效率、大大拓展了多模态模型的应用场景。
- Llava 必备基础:多模态大模型 Llava 借鉴了 CLIP 的思想与板块,因此理解 CLIP 可以帮我们更好地学习 Llava 模型
- 最最重要的是CLIP老好发文章了
最大的难度 就是在编码部分
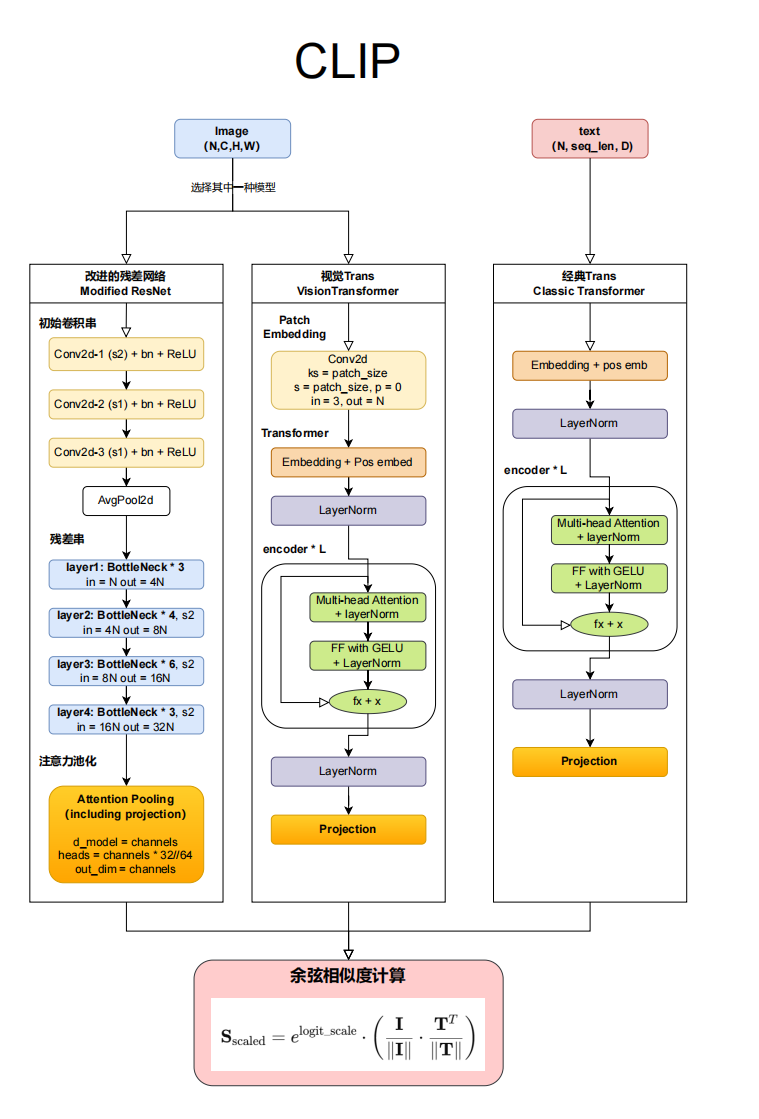
1. 关于文字的信息 架构如何处理
transformer输出的三维结构(bs, seq_len, d_model) ==> Projection
CNN(sz, C, H, W)==> Projection
Projection投影 全部压缩为(sample_size, information)information维度可以是多个列,但是它就是所有样本的信息
token-level => words进行一次输出/获取一些信息
sentence-level=>sentence/graph进行一次输出
输入为(bs,seq_len,d_model)时,会得到 token - level 的(bs,seq_len,information);
输入为(bs,seq_len,d_model)时,会得到 sentence - level 的(bs,information)很显然CLIP用的是这个,因为CLIP用的是图文匹配,这个任务很少能够用token来完成,所以通常是sentence , 很多模态基本就是sentence-level.
CNN(sz,C,H,W)经过 Projection 后,得到(sample_size,4096)
2. 余弦相似度
二维图和二维向量计算余弦相似度来看携带信息是否相似,来进行惩罚模型。


3. 图像的编码器部分
在 CLIP(Contrastive Language - Image Pretraining)中,选择使用残差网络(ResNet)或视觉 Transformer(ViT)取决于任务需求、计算资源、模型复杂度以及性能目标。
ResNet 作为 CLIP 的图像编码器,适用于以下情况:
- 轻量化场景:
ResNet 的计算效率较高,尤其在参数量和计算复杂度受限时,其优化的卷积设计和残差连接使其在嵌入计算效率和性能之间取得较好平衡。 - 小规模数据和有限资源:
如果计算资源有限或需要快速部署,ResNet 的高效架构更适合,因为它训练速度较快,并且对小数据集的泛化能力较强。 - 对局部特征依赖较强的任务:
ResNet 通过卷积操作擅长提取图像的局部特征,因此在局部信息对模型性能至关重要的任务中表现较好。例如单一花朵就一个目标很适合 但是在城市这种大景观就不适合了 - 经典的卷积架构迁移:
ResNet 是传统卷积神经网络的代表,许多现成的优化方法和技术(如权重初始化、批归一化、迁移学习)都能直接套用,便于快速调整和扩展。
ViT 作为 CLIP 的图像编码器,适用于以下情况:
-
大规模数据集(如 LAION - 400M 等):
ViT 对大规模训练数据表现更佳,因为其自注意力机制能够捕获更丰富的全局信息,并且在数据充足的情况下展现出极强的特征学习能力。 -
对全局特征建模需求高的任务:
ViT 通过 Transformer 架构的自注意力机制,可以更好地捕获图像的全局关系,因此在需要语义对齐或全局信息理解的任务中效果更强。 -
追求更高性能和模型可扩展性:
ViT 在模型扩展性和性能上有优势,尤其是在高计算资源场景中,ViT 能够利用更深层次的注意力机制提升图像表征能力。 -
跨领域迁移能力强:
ViT 具备较好的跨领域迁移能力,在图像特征需要进一步跨模态对齐或迁移到其他任务时表现出色。 -
数据规模和计算资源:
如果数据规模较小,或者计算资源受限,优先选择 ResNet。如果有足够的数据和计算资源,则 ViT 表现更优。 -
特征建模需求:
ResNet 更适合依赖局部特征的任务,而 ViT 更适合全局语义建模。 -
部署需求:
ResNet 因其较低的计算需求和较高的部署成熟度,适合需要快速、轻量部署的场景;而 ViT 适合在追求性能极限的离线或高性能计算环境中使用。
残差网---这个很简单 大家应该都明白就简单去说了
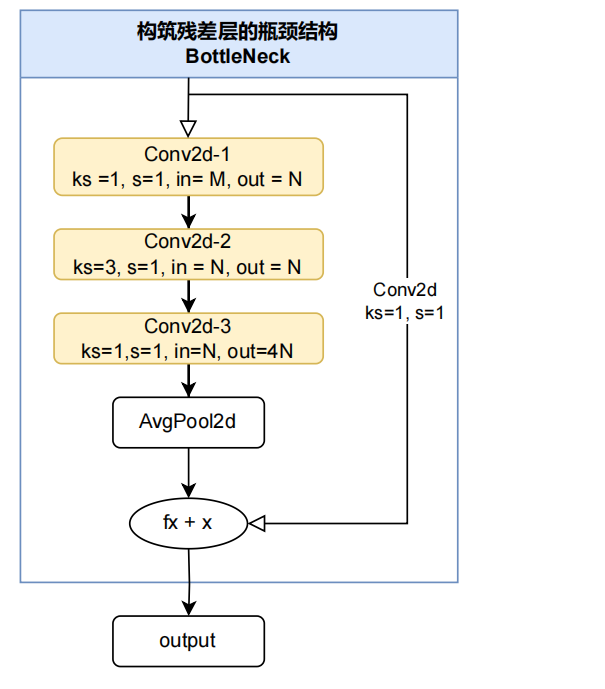
---后续内容和代码会推出第二节