ZSet
介绍
ZSet作为Redis中应用作为广泛的一种兼具集合特性和排序能力的高级数据结构,他在保留Set集合无重复元素特性的同时,为每一个元素(member)关联了一个分数(score)来实现元素的有序排列。
每个member是唯一的,不允许重复,但是score是可以重复的,如果向Redis中添加已存在的member,Redis 不会新增一个重复 member,而是会用新的 score 覆盖该 member 原有的 score,并根据新 score 重新调整其在有序集合中的位置。
底层数据结构
Redis为ZSet设计了两种底层实现,会根据数据量自动切换,以平衡性能和内存占用
在Redis7.0中,压缩列表数据结构已经被废弃了,交由listpack数据结构来实现了
当ZSet中元素数量<=128&&每个元素的member的长度<=64字节时,用的是压缩列表(ZipLIst)
其余情况用跳表(SkipList)+哈希表(HashTable)
跳表负责有序排列和范围查询,存储score+member的映射,元素按score升序排列
哈希表负责快速查找,存储member-score的映射
两种结构共享同一份 member 和 score 数据(仅存储一次),保证数据一致性。
下面来讲一下跳表的原理
跳表是通过分层索引优化链表的查询效率,本质是多层有序链表
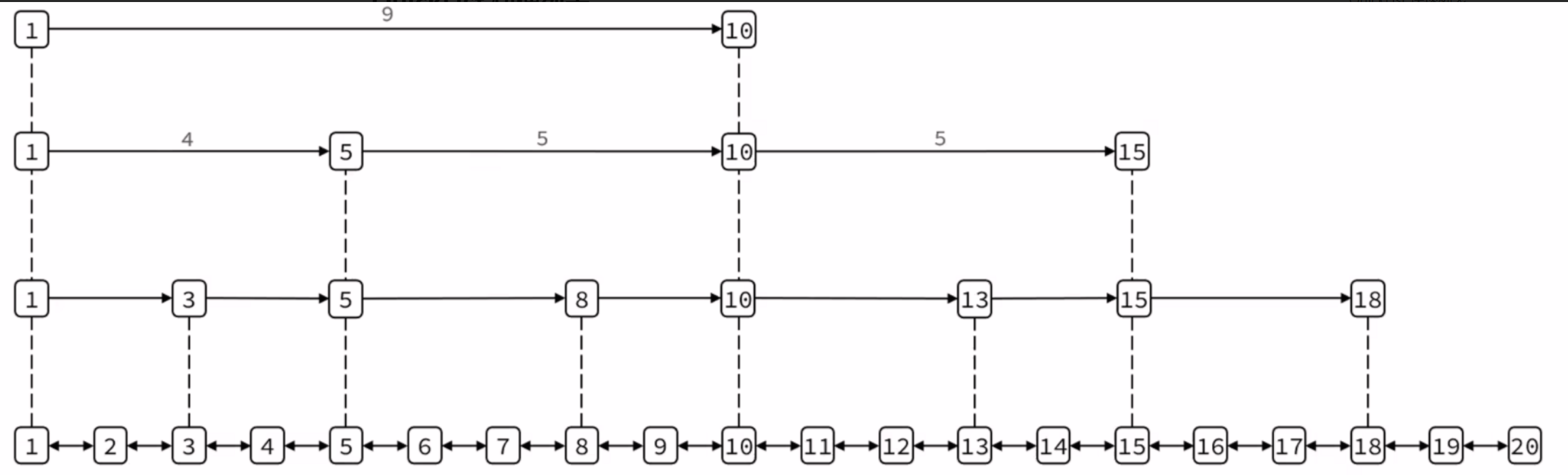
它的最底层是一个普通的有序的按score升序链表,包含所有元素
上层就是索引层,每一层都是下层的抽样(比如每隔 2 个元素取一个索引),用于快速定位元素范围
他的查询过程是从顶层索引该死,沿水平方向查找,遇到比目标打的元素时向下一层,直到底层找到目标
应用场景
1. 排行榜系统(最经典)
需求:用户积分排名、商品销量排名、文章阅读量排名等,支持实时更新和 “Top N” 查询。
实现:
用 ZSET 的 member 存储用户 ID / 商品 ID,score 存储积分 / 销量 / 阅读量。
新增 / 更新时用 ZADD 或 ZINCRBY 调整分数。
查询前 10 名用 ZREVRANGE key 0 9。
查询某个用户的名次用 ZREVRANK。
2. 延迟队列
需求:实现 “定时任务”(如 10 分钟后发送短信、订单 30 分钟未支付自动取消)。
实现:
用 ZSET 的 score 存储 任务执行时间戳,member 存储任务 ID / 详情。
生产者:ZADD delay_queue <timestamp> <task_id>。
消费者:通过 ZRANGEBYSCORE delay_queue 0 <current_timestamp> LIMIT 0 1 轮询获取 “已到执行时间” 的任务,拿到后用 ZREM 删除任务(避免重复执行)。
3. 范围查询与去重
需求:存储用户的身高 / 年龄等数值型数据,支持查询 “180-190cm 的用户”,且保证用户唯一。
实现:
member 存储用户 ID,score 存储身高 / 年龄。
范围查询用 ZRANGEBYSCORE,天然去重(ZSET 不允许重复 member)。
4. 好友亲密度排序
需求:根据用户与好友的互动次数(聊天、点赞)计算亲密度,按亲密度降序显示好友列表。
实现:
为每个用户维护一个 ZSET(如 friend_intimacy:user1),member 存储好友 ID,score 存储亲密度。
互动时用 ZINCRBY 增加亲密度分数。
展示好友列表时用 ZREVRANGE 按亲密度降序查询。