【Docker】Docker基础
目录
Docker简介
什么是虚拟化、容器化
案例
为什么要虚拟化、容器化?
虚拟化实现方式
应用程序执行环境分层
虚拟化常见类别
虚拟机
容器
JVM之类的虚拟机
常见虚拟化实现
主机虚拟化(虚拟机)实现
容器虚拟化实现
容器虚拟化实现原理
容器虚拟化基础之NameSpace
NameSpace空间隔离实战
基础知识
实战操作一(PID隔离)
实战操作二(Mount隔离)
容器虚拟化基础之cgroups
CGroups资源控制实战
基础知识
实操一、cgroups信息查看
实操二、使用cgroups对内存进行控制
实操三、使用cgroups对cpu进行控制
容器虚拟化基础之LXC
LXC容器化实战
基础知识
LXC容器操作实战
Docker是什么
Docker本质
Docker的引擎迭代
Docker和虚拟机的区别
Docker为什么比虚拟机资源利用率高,启动快
Docker和JVM虚拟化的区别?
Docker版本
Docker官方网站
Docker架构
官方架构
生活案例
Docker生态
新时代软件诉求
Docker 解决方案
Docker简介
什么是虚拟化、容器化
物理机:实际的服务器或者计算机。相对于虚拟机而言的对实体计算机的称呼。物理机提供给虚拟机以硬件环境,有时也称为“寄主”或“宿主”。
虚拟化:是指通过虚拟化技术将一台计算机虚拟为多台逻辑计算机。在一台计算机上同时运行多个逻辑计算机,每个逻辑计算机可运行不同的操作系统,并且应用程序都可以在相互独立的空间内运行而互不影响,从而显著提高计算机的工作效率。
容器化:容器化是一种虚拟化技术,又称操作系统层虚拟化(Operating system level virtualization),这种技术将操作系统内核虚拟化,可以允许用户空间软件实例(instances)被分割成几个独立的单元,在内核中运行,而不是只有一个单一实例运行。这个软件实例,也被称为是一个容器(containers)。对每个实例的拥有者与用户来说,他们使用的服务器程序,看起来就像是自己专用的。容器技术是虚拟化的一种。docker是现今容器技术的事实标准。
案例
举个生活中的例子。
物理机如下,就像一个庄园,独立占用了一块土地,花园都是自己的,其他人无法共享使用。

虚拟机相当于开发商的一个楼盘,一栋楼一套房子一户人家,共享一块宅基地,共享小区的花园,共享小区的游乐设施。

容器相当于在1个房子里面,开辟出来一个又一个的胶囊公寓,共享这套房子的卫生间、共享厨房、共享WiFi,只有衣服、电脑等私人物品是你自己的。

为什么要虚拟化、容器化?
我们从上面的历史发展来看,虚拟化和容器化的最主要目的就是资源隔离,随着资源隔离的实现逐渐也带来了更大的收益。
•资源利用率高
将利用率较低的服务器资源进行整合,用更少硬件资源运行更多业务,降低IT支出和运维管理成本。比如上图中我们的土地直接复用,使用这块土地的人多了,但是成本还是庄园那块地。
•环境标准化
一次构建,随处执行。实现执行环境的标准化发布,部署和运维。开发过程中一个常见的问题是环境一致性问题。由于开发环境、测试环境、生产环境不一致,导致有些bug 并未在开发过程中被发现。而Docker 的镜像提供了除内核外完整的运行时环境,确保了应用运行环境一致性,从而不会再出现「这段代码在我机器上没问题啊」这类问题。

•资源弹性伸缩
根据业务情况,动态调整计算、存储、网络等硬件及软件资源。比如遇到双11了,把服务扩容100个,双11过去了, 把扩容的100个收回去。
•资源弹性伸缩
根据业务情况,动态调整计算、存储、网络等硬件及软件资源。比如遇到双11了,把服务扩容100个,双11过去了, 把扩容的100个收回去。

•差异化环境提供
同时提供多套差异化的执行环境,限制环境使用资源。
比如我的服务一个以来Ubuntu 操作系统,一个服务依赖CentOS操作系统,但是没有预算购买两个物理机,这个时候容器化就能很好的提供多种不同的环境。
•沙箱安全
为避免不安全或不稳定软件对系统安全性、稳定性造成影响,可使用虚拟化技术构建虚拟执行环境。比如我在容器里面执行rm -rf /* 不会把整个服务器搞死,也不影响其他人部署的程序使用。

•容器对比虚拟机更轻量,启动更快
传统的虚拟机技术启动应用服务往往需要数分钟,而Docker 容器应用,由于直接运行于宿主内核,无需启动完整的操作系统,因此可以做到秒级、甚至毫秒级的启动时间。大大的节约了开发、测试、部署的时间。
docker不需要虚拟内核,所以启动可以更快,相当于windows的开机时间省去了。
•维护和扩展容易
Docker 使用的分层存储以及镜像的技术,使得应用重复部分的复用更为容易,也使得应用的维护更新更加简单,基于基础镜像进一步扩展镜像也变得非常简单。此外,Docker 团队同各个开源项目团队一起维护了一大批高质量的官方镜像,既可以直接在生产环境使用,又可以作为基础进一步定制,大大的降低了应用服务的镜像制作成本。比如docker hub提供了很多镜像,各个系统的一个命令就可以拿到了,研发也可以自己定制镜像分享给各个产品。

虚拟化实现方式
应用程序执行环境分层

硬件层:提供硬件抽象,包括指令集架构、硬件设备及硬件访问接口
操作系统层:提供系统调用接口,管理硬件资源
程序库层:提供数据结构定义及函数调用接口
虚拟化常见类别
虚拟机
存在于硬件层和操作系统层间的虚拟化技术。虚拟机通过“伪造”一个硬件抽象接口,将一个操作系统以及操作系统层以上的层嫁接到硬件上,实现和真实物理机几乎一样的功能。比如我们在一台Windows 系统的电脑上使用Android 虚拟机,就能够用这台电脑打开Android 系统上的应用。
容器
存在于操作系统层和函数库层之间的虚拟化技术。容器通过“伪造”操作系统的接口,将函数库层以上的功能置于操作系统上。以Docker 为例,其就是一个基于Linux 操作系统的Namespace 和Cgroup 功能实现的隔离容器,可以模拟操作系统的功能。简单来说,如果虚拟机是把整个操作系统封装隔离,从而实现跨平台应用的话,那么容器则是把一个个应用单独封装隔离,从而实现跨平台应用。所以容器体积比虚拟机小很多,理论上占用资源更少。容器化就是应用程序级别的虚拟化技术。容器提供了将应用程序的代码、运行时、系统工具、系统库和配置打包到一个实例中的标准方法。容器共享一个内核(操作系统),它安装在硬件上。
JVM之类的虚拟机
存在于函数库层和应用程序之间的虚拟化技术。Java 虚拟机同样具有跨平台特性,所谓跨平台特性实际上也就是虚拟化的功劳。我们知道Java 语言是调用操作系统函数库的,JVM 就是在应用层与函数库层之间建立一个抽象层,对下通过不同的版本适应不同的操作系统函数库,对上提供统一的运行环境交给程序和开发者,使开发者能够调用不同操作系统的函数库。
常见虚拟化实现
主机虚拟化(虚拟机)实现
主机虚拟化的原理是通过在物理服务器上安装一个虚拟化层来实现。这个虚拟化层可以在物理服务器和客户操作系统之间建立虚拟机,使得它们可以独立运行。
从软件框架的角度上,根据虚拟化层是直接位于硬件之上还是在一个宿主操作系统之上,将虚拟化划分为Type1和Type2.
Type1类的Hypervisor(Hypervisor是一种系统软件,它充当计算机硬件和虚拟机之间的中介,负责有效地分配和利用由各个虚拟机使用的硬件资源,这些虚拟机在物理主机上单独工作,因此,Hypervisor也称为虚拟机管理器。)直接运行在硬件之上,没有宿主机操作系统,Hypervisor直接控制硬件资源和客户机。典型框架为Xen、Vmware ESX。
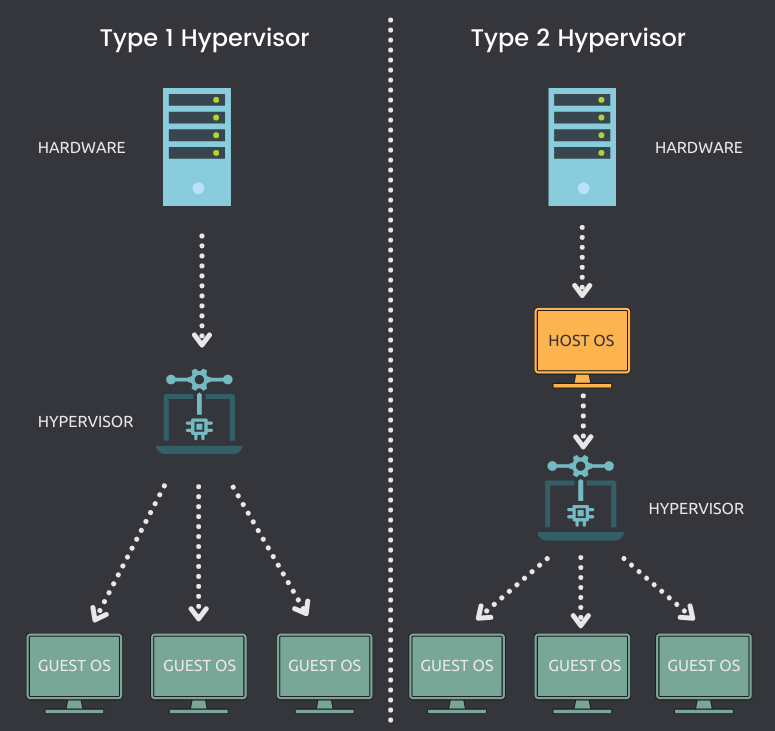
Type2类的Hypervisor运行在一个宿主机操作系统之上(Vmware Workstation)或者系统里面,Hypervisor作为宿主机操作系统中的一个应用程序,客户机就是在宿主机操作系统上的一个进程。
容器虚拟化实现
容器虚拟化实现原理
容器虚拟化,有别于主机虚拟化,是操作系统层的虚拟化。通过namespace进行各程序的隔离,加上cgroups进行资源的控制,以此来进行虚拟化。
容器虚拟化基础之NameSpace
什么是Namespace(命名空间)
namespace 是Linux 内核用来隔离内核资源的方式。通过namespace 可以让一些进程只能看到与自己相关的一部分资源,而另外一些进程也只能看到与它们自己相关的资源,这两拨进程根本就感觉不到对方的存在。具体的实现方式是把一个或多个进程的相关资源指定在同一个namespace 中。
Linux namespaces 是对全局系统资源的一种封装隔离,使得处于不同namespace 的进程拥有独立的全局系统资源,改变一个namespace 中的系统资源只会影响当前namespace 里的进程,对其他namespace 中的进程没有影响。
Linux 提供了多个API 用来操作namespace,它们是clone()、setns() 和unshare() 函数,为了确定隔离的到底是哪项namespace,在使用这些API 时,通常需要指定一些调用参数:CLONE_NEWIPC、CLONE_NEWNET、CLONE_NEWNS、CLONE_NEWPID、CLONE_NEWUSER、CLONE_NEWUTS 和CLONE_NEWCGROUP。如果要同时隔离多个namespace,可以使用| (按位或)组合这些参数。
举个例子
三年一班的小明和三年二班的小明,虽说他们名字是一样的,但是所在班级不一样,那么,在全年级排行榜上面,即使出现两个名字一样的小明,也会通过各自的学号来区分。对于学校来说,每个班级就相当于是一个命名空间,这个空间的名称是班级号。班级号用于描述逻辑上的学生分组信息,至于什么学生分配到1班,什么学生分配到2班,那就由学校层面来统一调度。

| namespace | 系统调用参数 | 被隔离的全局系统资源 | 引入内核版本 |
|---|---|---|---|
| UTS | CLONE_NEWUTS | 主机名和域名 | 2.6.19 |
| IPC | CLONE_NEWIPC | 信号量、消息队列和共享内存-- 进程间通信 | 2.6.19 |
| PID | CLONE_NEWPID | 进程编号 | 2.6.24 |
| Network | CLONE_NEWNET | 网络设备、网络栈、端口等 | 2.6.29 |
| Mount | CLONE_NEWNS | 文件系统挂载点 | 2.4.19 |
| User | CLONE_NEWUSER | 用户和用户组 | 3.8 |
以上命名空间在容器环境下的隔离效果:
UTS:每个容器能看到自己的hostname,拥有独立的主机名和域名。
IPC:同一个IPC namespace的进程之间能互相通讯,不同的IPC namespace之间不能通信。
PID:每个PID namespace中的进程可以有其独立的PID,每个容器可以有其PID为1的root 进程。
Network:每个容器用有其独立的网络设备,IP地址,IP路由表,/proc/net目录,端口号。
Mount:每个容器能看到不同的文件系统层次结构。
User:每个container可以有不同的user和group id。
想想以下如果我们要隔离两个进程需要怎么办?
(1)首先容器进程与进程之间需要隔离,所以需要PID隔离
(2)首先容器A进程不能读取容器B进程通讯内容需要隔离信号量等,所以需要IPC隔离
(3)首先容器A进程不能读取容器B进程的文件,所以需要Mount隔离
(4)首先容器A进程不能读取容器B进程的socket,所以需要网络隔离、主机隔离
(5)Docker 允许用户在主机和容器间共享文件夹,同时不需要限制容器的访问权限,这就容易让容器突破资源限制。需要借助用户空间来完成用户之间的隔离。
NameSpace空间隔离实战
基础知识
dd命令详解
Linux dd 命令用于读取、转换并输出数据。
dd 可从标准输入或文件中读取数据,根据指定的格式来转换数据,再输出到文件、设备或标准输出。
• 语法
Shell
dd OPTION• 参数
○if=文件名:输入文件名,默认为标准输入。即指定源文件。
○of=文件名:输出文件名,默认为标准输出。即指定目的文件。
○ibs=bytes:一次读入bytes个字节,即指定一个块大小为bytes个字节。obs=bytes:一次输出bytes个字节,即指定一个块大小为bytes个字节。bs=bytes:同时设置读入/输出的块大小为bytes个字节。
○cbs=bytes:一次转换bytes个字节,即指定转换缓冲区大小。
○skip=blocks:从输入文件开头跳过blocks个块后再开始复制。
○seek=blocks:从输出文件开头跳过blocks个块后再开始复制。
○count=blocks:仅拷贝blocks个块,块大小等于ibs指定的字节数。
○conv=<关键字>,关键字可以有以下11种:
▪ conversion:用指定的参数转换文件。
▪ ascii:转换ebcdic为ascii
▪ ebcdic:转换ascii为ebcdic
▪ ibm:转换ascii为alternate ebcdic
▪ block:把每一行转换为长度为cbs,不足部分用空格填充
▪ unblock:使每一行的长度都为cbs,不足部分用空格填充
▪ lcase:把大写字符转换为小写字符
▪ ucase:把小写字符转换为大写字符
▪ swap:交换输入的每对字节
▪ noerror:出错时不停止
▪ notrunc:不截短输出文件
▪ sync:将每个输入块填充到ibs个字节,不足部分用空(NUL)字符补齐。
○--help:显示帮助信息
○--version:显示版本信息
• 案例
Shell # 生成1个镜像文件
dd if=/dev/zero of=fdimage.img bs=8k count=10240
#将testfile文件中的所有英文字母转换为大写,然后转成为testfile_1文件
dd if=testfile_2 of=testfile_1 conv=ucasemkfs命令详解
用于在设备上创建Linux文件系统,俗称格式化,比如我们使用U盘的时候可以格式化。
• 语法
mkfs [-V] [-t fstype] [fs-options] filesys [blocks]
• 参数
-t fstype:指定要建立何种文件系统;如ext3,ext4
filesys :指定要创建的文件系统对应的设备文件名;
blocks:指定文件系统的磁盘块数。
-V : 详细显示模式
fs-options:传递给具体的文件系统的参数
• 实例
Shell
#将sda6分区格式化为ext4格式
mkfs -t ext4 /dev/sda6
#格式化镜像文件为ext4
mkfs -t ext4 ./fdimage.imgdf命令详解
Linux df(英文全拼:disk free) 命令用于显示目前在Linux 系统上的文件系统磁盘使用情况统计。
• 语法
df [OPTION]... [FILE]...
• 常见参数
○-a, --all 包含所有的具有0 Blocks 的文件系统
○-h, --human-readable 使用人类可读的格式(预设值是不加这个选项的...)
○-H, --si 很像-h, 但是用1000 为单位而不是用1024
○-t, --type=TYPE 限制列出文件系统的TYPE
○-T, --print-type 显示文件系统的形式
• 案例
Shell
#查看磁盘使用情况
df -h
#查看磁盘的系统类型
df -Thmount命令详解
mount命令用于加载文件系统到指定的加载点。此命令的也常用于挂载光盘,使我们可以访问光盘中的数据,因为你将光盘插入光驱中,Linux并不会自动挂载,必须使用Linux mount命令来手动完成挂载。
Linux系统下不同目录可以挂载不同分区和磁盘设备,它的目录和磁盘分区是分离的,可以自由组合(通过挂载)
不同的目录数据可以跨越不同的磁盘分区或者不同的磁盘设备。
挂载的实质是为磁盘添加入口(挂载点)。
• mount常见用法
mount [-l]
mount [-t vfstype] [-o options] device dir
• 常见参数
-l:显示已加载的文件系统列表;
-t: 加载文件系统类型支持常见系统类型的ext3,ext4,iso9660,tmpfs,xfs等,大部分情况可以不指定,mount可以自己识别
-o options 主要用来描述设备或档案的挂接方式。
loop:用来把一个文件当成硬盘分区挂接上系统
ro:采用只读方式挂接设备
rw:采用读写方式挂接设备
device: 要挂接(mount)的设备。
dir: 挂载点的目录
• 案例
Shell
#将 /dev/hda1 挂在 /mnt 之下。
mount /dev/hda1 /mnt
#将镜像挂载到/mnt/testext4下面,需要确保挂载点也就是目录存在
mkdir -p /mnt/testext4
mount ./fdimage.img /mnt/testext4unshare命令详解
unshare主要能力是使用与父程序不共享的名称空间运行程序。
• 语法
unshare [options] program [arguments]
• 常用参数
| 参数 | 含义 |
| -i, --ipc | 不共享IPC空间 |
| -m, --mount | 不共享Mount空间 |
| -n, --net | 不共享Net空间 |
| -p, --pid | 不共享PID空间 |
| -u, --uts | 不共享UTS空间 |
| -U, --user | 不共享用户 |
| -V, --version | 版本查看 |
| --fork | 执行unshare 的进程fork 一个新的子进程,在子进程里执行unshare 传入的参数。 |
| --mount-proc | 执行子进程前,将proc优先挂载过去 |
• 案例
Shell
#hostname隔离
root@139-159-150-152:~# unshare -u /bin/bash
root@139-159-150-152:~# hostname test1
root@139-159-150-152:~# hostname
test1
root@139-159-150-152:~# exit
exit
root@139-159-150-152:~# hostname
139-159-150-152
root@139-159-150-152:实战操作一(PID隔离)
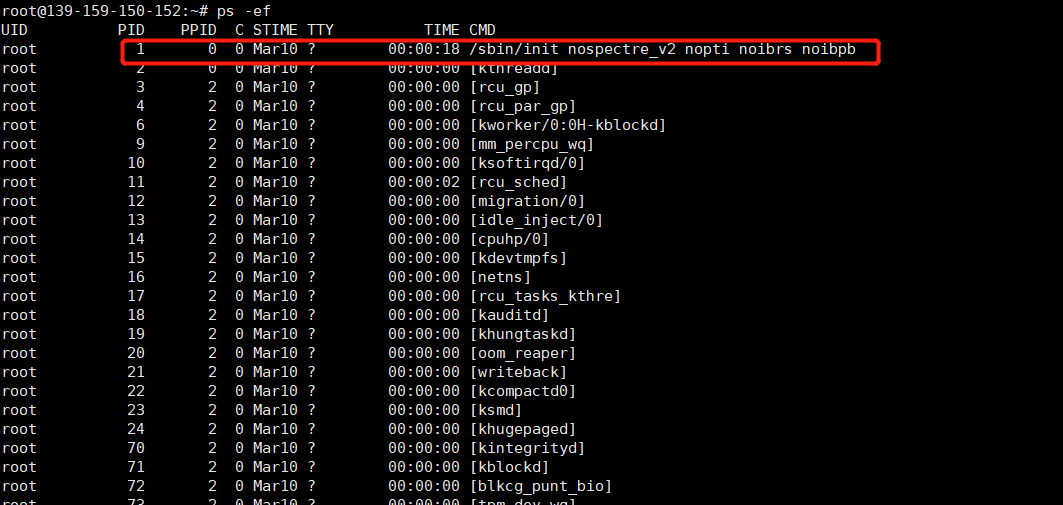
1. 在主机上执行ps -ef,可以看到进程列表如下,其中启动进程PID 1 为init进程
2. 我们打开另外一个shell ,执行下面命令创建一个bash 进程,并且新建一个PID Namespace:
--fork新建了一个bash进程,是因为如果不建新进程,新的namespace会用unshare的PID作为新的空间的父进程,而这个unshare进程并不在新的namespace中,所以会报个错Cannot allocate memory
--pid表示我们的进程隔离的是pid,而其他命名空间没有隔离
mount-proc是因为Linux下的每个进程都有一个对应的/proc/PID 目录,该目录包含了大量的有关当前进程的信息。对一个PID namespace 而言,/proc 目录只包含当前namespace 和它所有子孙后代namespace 里的进程的信息。创建一个新的PID namespace 后,如果想让子进程中的top、ps 等依赖/proc 文件系统的命令工作,还需要挂载/proc 文件系统。而文件系统隔离是mount namespace管理的,所以linux特意提供了一个选项--mount-proc来解决这个问题。如果不带这个我们看到的进程还是系统的进程信息。
Shell
unshare --fork --pid --mount-proc /bin/bash3. 执行 ps -ef查看进程信息,我们可以看到此时进程空间内的内容已经变了,而且启动进程也变成了我们的bash进程。说明我们已经看不到主机上的进程空间了,我们的进程空间发生了隔离。

4.执行exit退出进程
Shell
exit实战操作二(Mount隔离)
1. 打开第一个shell窗口A,执行命令, df -h ,查看主机默认命名空间的磁盘挂载情况
Shell
root@139-159-150-152:~# df -h
Filesystem Size Used Avail Use% Mounted on
udev 948M 0 948M 0% /dev
tmpfs 199M 1.1M 198M 1% /run
/dev/vda1 40G 8.0G 30G 22% /
tmpfs 992M 0 992M 0% /dev/shm
tmpfs 5.0M 4.0K 5.0M 1% /run/lock
tmpfs 992M 0 992M 0% /sys/fs/cgroup
tmpfs 199M 0 199M 0% /run/user/0
/dev/loop0 50M 50M 0 100% /snap/snapd/18357
/dev/loop1 56M 56M 0 100% /snap/core18/2697
/dev/loop2 55M 55M 0 100% /snap/erlang/101
/dev/loop3 56M 56M 0 100% /snap/core18/27082. 打开一个新的shell窗口B,执行Mount隔离命令
Shell
# --mount表示我们要隔离Mount命名空间了
# --fork 表示新建进程
unshare --mount --fork /bin/bash
mkdir -p /data/tmpmount3. 在窗口B中添加新的磁盘挂载
Shell
dd if=/dev/zero of=fdimage.img bs=8k count=10240
mkfs -t ext4 ./fdimage.img
mount ./fdimage.img /data/tmpmount4. 在窗口B挂载的磁盘中添加文件
Shell
echo "Hello world!" > /data/tmpmount/hello.txt5. 查看窗口B中的磁盘挂载信息
Shell
root@139-159-150-152:/data/maxhou/mounttest# df -h
Filesystem Size Used Avail Use% Mounted on
/dev/vda1 40G 23G 15G 61% /
udev 948M 0 948M 0% /dev
tmpfs 992M 0 992M 0% /dev/shm
tmpfs 199M 2.4M 196M 2% /run
tmpfs 5.0M 4.0K 5.0M 1% /run/lock
tmpfs 199M 8.0K 199M 1% /run/user/1000
tmpfs 199M 0 199M 0% /run/user/1002
tmpfs 199M 0 199M 0% /run/user/1001
tmpfs 199M 0 199M 0% /run/user/0
tmpfs 992M 0 992M 0% /sys/fs/cgroup
/dev/loop2 55M 55M 0 100% /snap/erlang/101
/dev/loop4 56M 56M 0 100% /snap/core18/2714
overlay 40G 23G 15G 61% /data/myworkdir/fs/merged
/dev/loop1 50M 50M 0 100% /snap/snapd/18596
/dev/loop5 56M 56M 0 100% /snap/core18/2721
/dev/loop3 54M 54M 0 100% /snap/snapd/18933
overlay 40G 23G 15G 61% /data/var/lib/docker/overlay2/922af407c456f95d898fea95ca148b30607b20ff6c3e7c3ff1b61cff3fae4cfd/merged overlay 40G 23G 15G 61% /data/var/lib/docker/overlay2/e0783839b4cf83c86574efa690a8d7f0ee3ab56cfc58932f61b7259a29169f2d/merged overlay 40G 23G 15G 61% /data/var/lib/docker/overlay2/9b230a4ec2179c894e7ef7e02ad8110a2fc82f73947b9b1d6ac52d8f530888a5/merged overlay 40G 23G 15G 61% /data/var/lib/docker/overlay2/136daee7deb5833e762c4f15f669446a0953cb7cbc4402db8ede275b360bd860/merged overlay 40G 23G 15G 61% /data/var/lib/docker/overlay2/56b1378d1428401284a83392403f82816c5ae6dde3c446d0e9f5bc59a1ce7d22/merged overlay 40G 23G 15G 61% /data/var/lib/docker/overlay2/2673569d857e88b099d669886ef555934bb6156d24e96fec47ad6edfc2ac861b/merged overlay 40G 23G 15G 61% /data/var/lib/docker/overlay2/b30c60e4b02fa47646ab76bc0fc8f44ca4118d03d1b7c976e4e9398396ae9c85/merged
overlay 40G 23G 15G 61% /data/var/lib/docker/overlay2/0c1c00f53f152528ccf805682e71335901a35aef0a51656a4fd148b4bf63de73/merged overlay 40G 23G 15G 61% /data/var/lib/docker/overlay2/59e9cbe3e4e352cfafcbd14fed1b9ac346ab2aa41121130d6d6005c46192fd1f/merged overlay 40G 23G 15G 61% /data/var/lib/docker/overlay2/9efca1404a5c76c5f02d8955c364837c9e655292c4a43335645aa6dfbd3c2e82/merged overlay 40G 23G 15G 61% /data/var/lib/docker/overlay2/14f66040cb71227dbcbb6234a08355a45e54f241eccedfce3ffb349eb48041ab/merged overlay 40G 23G 15G 61% /data/var/lib/docker/overlay2/1a1750c0319256058b1d6ca2cb88f000a75138126bf8db4ddd95c1abfb1bcb84/merged overlay 40G 23G 15G 61% /data/var/lib/docker/overlay2/970c9cfe0e5dfbacee73b19ac28a15c81607fd329113d392db3d085c3fcba334/merged overlay 40G 23G 15G 61% /data/var/lib/docker/overlay2/71d23ff71232c534c92c2f900737360c3a6392a0858f6e4becfe36379e17c9be/merged
/dev/loop0 74M 60K 68M 1% /data/tmpmount6. 查看窗口A中的磁盘挂载信息
Shell
root@139-159-150-152:/data/tmpmount# df -h
Filesystem Size Used Avail Use% Mounted on
udev 948M 0 948M 0% /dev
tmpfs 199M 2.4M 196M 2% /run
/dev/vda1 40G 23G 15G 61% /
tmpfs 992M 0 992M 0% /dev/shm
tmpfs 5.0M 4.0K 5.0M 1% /run/lock
tmpfs 992M 0 992M 0% /sys/fs/cgroup
/dev/loop2 55M 55M 0 100% /snap/erlang/101
/dev/loop4 56M 56M 0 100% /snap/core18/2714
tmpfs 199M 8.0K 199M 1% /run/user/1000
tmpfs 199M 0 199M 0% /run/user/1002
overlay 40G 23G 15G 61% /data/myworkdir/fs/merged
tmpfs 199M 0 199M 0% /run/user/1001
/dev/loop1 50M 50M 0 100% /snap/snapd/18596
/dev/loop5 56M 56M 0 100% /snap/core18/2721
tmpfs 199M 0 199M 0% /run/user/0
/dev/loop3 54M 54M 0 100% /snap/snapd/18933
overlay 40G 23G 15G 61% /data/var/lib/docker/overlay2/922af407c456f95d898fea95ca148b30607b20ff6c3e7c3ff1b61cff3fae4cfd/merged
overlay 40G 23G 15G 61% /data/var/lib/docker/overlay2/e0783839b4cf83c86574efa690a8d7f0ee3ab56cfc58932f61b7259a29169f2d/merged
overlay 40G 23G 15G 61% /data/var/lib/docker/overlay2/9b230a4ec2179c894e7ef7e02ad8110a2fc82f73947b9b1d6ac52d8f530888a5/merged
overlay 40G 23G 15G 61% /data/var/lib/docker/overlay2/136daee7deb5833e762c4f15f669446a0953cb7cbc4402db8ede275b360bd860/merged
overlay 40G 23G 15G 61% /data/var/lib/docker/overlay2/56b1378d1428401284a83392403f82816c5ae6dde3c446d0e9f5bc59a1ce7d22/merged
overlay 40G 23G 15G 61% /data/var/lib/docker/overlay2/2673569d857e88b099d669886ef555934bb6156d24e96fec47ad6edfc2ac861b/merged
overlay 40G 23G 15G 61% /data/var/lib/docker/overlay2/b30c60e4b02fa47646ab76bc0fc8f44ca4118d03d1b7c976e4e9398396ae9c85/merged
overlay 40G 23G 15G 61% /data/var/lib/docker/overlay2/0c1c00f53f152528ccf805682e71335901a35aef0a51656a4fd148b4bf63de73/merged
overlay 40G 23G 15G 61% /data/var/lib/docker/overlay2/59e9cbe3e4e352cfafcbd14fed1b9ac346ab2aa41121130d6d6005c46192fd1f/merged
overlay 40G 23G 15G 61% /data/var/lib/docker/overlay2/9efca1404a5c76c5f02d8955c364837c9e655292c4a43335645aa6dfbd3c2e82/merged
overlay 40G 23G 15G 61% /data/var/lib/docker/overlay2/14f66040cb71227dbcbb6234a08355a45e54f241eccedfce3ffb349eb48041ab/merged
overlay 40G 23G 15G 61% /data/var/lib/docker/overlay2/1a1750c0319256058b1d6ca2cb88f000a75138126bf8db4ddd95c1abfb1bcb84/merged
overlay 40G 23G 15G 61% /data/var/lib/docker/overlay2/970c9cfe0e5dfbacee73b19ac28a15c81607fd329113d392db3d085c3fcba334/merged
overlay 40G 23G 15G 61% /data/var/lib/docker/overlay2/71d23ff71232c534c92c2f900737360c3a6392a0858f6e4becfe36379e17c9be/merged7. 查看窗口B中的文件信息
Shell
root@139-159-150-152:~# ll /data/tmpmount/
total 8
drwxrwxrwt 2 root root 60 Mar 11 18:13 ./
drwx--x--x 4 root root 4096 Mar 11 17:59 ../
-rw-r--r-- 1 root root 13 Mar 11 18:13 hello.txt
root@139-159-150-152:~# cat /data/tmpfs/hello.txt
Hello world!8. 查看窗口A中的文件信息,可以看到窗口B中新建的文件和磁盘挂载在主机的窗口中并没有,说明我们实现了文件系统隔离。
Shell root@139-159-150-152:/data/tmpfs# ll /data/tmpmount
total 8
drwxr-xr-x 2 root root 4096 Mar 11 17:59 ./
drwx--x--x 4 root root 4096 Mar 11 17:59 ../
root@139-159-150-152:/data/tmpfs# cat /data/tmpmount/hello.txt
cat: /data/tmpfs/hello.txt: No such file or directory9. 窗口B执行exit,退出
Shell
exit容器虚拟化基础之cgroups
1. 什么是cgroups
cgroups(Control Groups) 是linux 内核提供的一种机制,这种机制可以根据需求把一系列系统任务及其子任务整合(或分隔)到按资源划分等级的不同组内,从而为系统资源管理提供一个统一的框架。简单说,cgroups 可以限制、记录任务组所使用的物理资源。本质上来说,cgroups 是内核附加在程序上的一系列钩子(hook),通过程序运行时对资源的调度触发相应的钩子以达到资源追踪和限制的目的。
2. 为什么使用cgroups
其可以做到对cpu,内存等资源实现精细化的控制,目前越来越火的轻量级容器Docker 及k8s中的pod就使用了cgroups 提供的资源限制能力来完成cpu,内存等部分的资源控制。比如在一个既部署了前端web 服务,也部署了后端计算模块的八核服务器上,可以使用cgroups 限制web server 仅可以使用其中的六个核,把剩下的两个核留给后端计算模块。
3. cgroups的用途 Resource limitation: 限制资源使用,例:内存使用上限/cpu的使用限制 Prioritization: 优先级控制,例:CPU利用/磁盘IO吞吐 Accounting: 一些审计或一些统计 Control: 挂起进程/恢复执行进程
4. cgroups可以控制的子系统
| blkio | 对块设备的IO 进行限制。 |
|---|---|
| cpu | 限制CPU 时间片的分配 |
| cpuacct | 生成cgroup 中的任务占用CPU 资源的报告,与cpu 挂载在同一目录。 |
| cpuset | 给cgroup 中的任务分配独立的CPU(多处理器系统) 和内存节点 |
| devices | 限制设备文件的创建,和对设备文件的读写 |
| freezer | 暂停/恢复cgroup 中的任务。 |
| memory | 对cgroup 中的任务的可用内存进行限制,并自动生成资源占用报告。 |
| perf_event | 允许perf观测cgroup中的task |
| net_cls | cgroup中的任务创建的数据报文的类别标识符,这让Linux 流量控制器(tc 指令)可以识别来自特定cgroup 任务的数据包,并进行网络限制。 |
| hugetlb | 限制使用的内存页数量。 |
| pids | 限制任务的数量。 |
| rdma | 限制RDMA资源(Remote Direct Memory Access,远程直接数据存取) |
CGroups资源控制实战
基础知识
pidstat
• 概述
pidstat是sysstat的一个命令,用于监控全部或指定进程的CPU、内存、线程、设备IO等系统资源的占用情况。Pidstat第一次采样显示自系统启动开始的各项统计信息,后续采样将显示自上次运行命令后的统计信息。用户可以通过指定统计的次数和时间来获得所需的统计信息。
• 语法
pidstat [ 选项 ] [ <时间间隔> ] [ <次数> ]
• 参数
-u:默认参数,显示各进程的CPU使用统计
-r:显示各进程的内存使用统计
-d:显示各进程的IO使用情况
-p:指定进程号,ALL表示所有进程
-C:指定命令
-l:显示命令名和所有参数
• 安装
Ubuntu安装
Shell
#卸载
apt remove sysstat -y
#安装
apt install sysstat -yCentOS安装
Shell
#卸载
yum remove sysstat -y
#安装
yum install sysstat -ystress
• 概述
stress是Linux的一个压力测试工具,可以对CPU、Memory、IO、磁盘进行压力测试。
• 语法
stress [OPTION [ARG]]
• 参数
-c, --cpu N:产生N个进程,每个进程都循环调用sqrt函数产生CPU压力。
-i, --io N:产生N个进程,每个进程循环调用sync将内存缓冲区内容写到磁盘上,产生IO压力。通过系统调用sync刷新内存缓冲区数据到磁盘中,以确保同步。如果缓冲区内数据较少,写到磁盘中的数据也较少,不会产生IO压力。在SSD磁盘环境中尤为明显,很可能iowait总是0,却因为大量调用系统调用sync,导致系统CPU使用率sys 升高。
-m, --vm N:产生N个进程,每个进程循环调用malloc/free函数分配和释放内存。
--vm-bytes B:指定分配内存的大小
--vm-keep:一直占用内存,区别于不断的释放和重新分配(默认是不断释放并重新分配内存)
-d, --hdd N:产生N个不断执行write和unlink函数的进程(创建文件,写入内容,删除文件)
--hdd-bytes B:指定文件大小
-t, --timeout N:在N秒后结束程序
-q, --quiet:程序在运行的过程中不输出信息
• 安装
Ubuntu:
Shell
#卸载
apt remove stress -y
#安装
apt install stress -yCentOS:
Shell
#卸载
yum remove stress -y
#安装
yum install stress -y实操一、cgroups信息查看
cgroups版本查看
Shell
root@139-159-150-152:/sys/fs/cgroup# cat /proc/filesystems |grep cgroup
nodev cgroup
nodev cgroup2如果看到cgroup2,表示支持cgroup v2
cgroups子系统查看(注如果支持cgroup v2,子系统中也会多支持如rdma之类)
Shell root@139-159-150-152:/sys/fs/cgroup# cat /proc/cgroups
#subsys_name hierarchy num_cgroups enabled
cpuset 8 2 1
cpu 2 100 1
cpuacct 2 100 1
blkio 6 98 1
memory 10 124 1
devices 12 98 1
freezer 7 2 1
net_cls 4 2 1
perf_event 3 2 1
net_prio 4 2 1
hugetlb 9 2 1
pids 5 107 1
rdma 11 2 1cgroups挂载信息查看(注cgroup v2将各信息进行整合,统一进行管理,所以下面实现是在cgroup v1下进行的)
可以看到默认存储位置为/sys/fs/cgroup
Shell root@139-159-150-152:/sys/fs/cgroup# mount |grep cgroup
tmpfs on /sys/fs/cgroup type tmpfs
(ro,nosuid,nodev,noexec,mode=755)
cgroup2 on /sys/fs/cgroup/unified type cgroup2
(rw,nosuid,nodev,noexec,relatime,nsdelegate)
cgroup on /sys/fs/cgroup/systemd type cgroup (rw,nosuid,nodev,noexec,relatime,xattr,name=systemd)
cgroup on /sys/fs/cgroup/cpu,cpuacct type cgroup (rw,nosuid,nodev,noexec,relatime,cpu,cpuacct)
cgroup on /sys/fs/cgroup/perf_event type cgroup (rw,nosuid,nodev,noexec,relatime,perf_event)
cgroup on /sys/fs/cgroup/net_cls,net_prio type cgroup (rw,nosuid,nodev,noexec,relatime,net_cls,net_prio)
cgroup on /sys/fs/cgroup/pids type cgroup
(rw,nosuid,nodev,noexec,relatime,pids)
cgroup on /sys/fs/cgroup/blkio type cgroup
(rw,nosuid,nodev,noexec,relatime,blkio)
cgroup on /sys/fs/cgroup/freezer type cgroup
(rw,nosuid,nodev,noexec,relatime,freezer)
cgroup on /sys/fs/cgroup/cpuset type cgroup
(rw,nosuid,nodev,noexec,relatime,cpuset)
cgroup on /sys/fs/cgroup/hugetlb type cgroup
(rw,nosuid,nodev,noexec,relatime,hugetlb)
cgroup on /sys/fs/cgroup/memory type cgroup
(rw,nosuid,nodev,noexec,relatime,memory)
cgroup on /sys/fs/cgroup/rdma type cgroup
(rw,nosuid,nodev,noexec,relatime,rdma)
cgroup on /sys/fs/cgroup/devices type cgroup
(rw,nosuid,nodev,noexec,relatime,device查看一个进程上的cgroup限制
1. 以当前shell进程为例,查看进程的cgroup
Shell
[root@VM-8-12-centos ~]# cat /proc/$$/cgroup
11:hugetlb:/
10:memory:/user.slice
9:freezer:/
8:cpuset:/
7:perf_event:/
6:net_prio,net_cls:/
5:devices:/user.slice/user-0.slice
4:pids:/user.slice
3:cpuacct,cpu:/user.slice
2:blkio:/user.slice
1:name=systemd:/user.slice/user-0.slice/session-354304.scope2. 比如cpu在user.slice,我们可以找到这个目录,里面有对init进程的详细限制信息
Shell [root@VM-8-12-centos ~]# ll /sys/fs/cgroup/cpu/user.slice/
total 0
-rw-r--r-- 1 root root 0 Nov 21 15:30 cgroup.clone_children
--w--w--w- 1 root root 0 Nov 21 15:30 cgroup.event_control
-rw-r--r-- 1 root root 0 Nov 21 15:30 cgroup.procs
-r--r--r-- 1 root root 0 Nov 21 15:30 cpuacct.stat
-rw-r--r-- 1 root root 0 Nov 21 15:30 cpuacct.usage
-r--r--r-- 1 root root 0 Nov 21 15:30 cpuacct.usage_percpu
-rw-r--r-- 1 root root 0 Nov 21 15:30 cpu.cfs_period_us
-rw-r--r-- 1 root root 0 Nov 21 15:30 cpu.cfs_quota_us
-rw-r--r-- 1 root root 0 Nov 21 15:30 cpu.rt_period_us
-rw-r--r-- 1 root root 0 Nov 21 15:30 cpu.rt_runtime_us
-rw-r--r-- 1 root root 0 Nov 21 15:30 cpu.shares
-r--r--r-- 1 root root 0 Nov 21 15:30 cpu.stat
-rw-r--r-- 1 root root 0 Nov 21 15:30 notify_on_release
-rw-r--r-- 1 root root 0 Nov 21 15:30 tasks实操二、使用cgroups对内存进行控制
1. 创建内存的cgroup,很简单我们进入到cgroup的内存控制目录/sys/fs/cgroup/memory,我们创建目录test_memory
Shell root@139-159-150-152:/sys/fs/cgroup/memory# mkdir test_memory
root@139-159-150-152:/sys/fs/cgroup/memory# ll
total 0
dr-xr-xr-x 7 root root 0 Mar 10 14:13 ./
drwxr-xr-x 15 root root 380 Mar 10 14:13 ../
-rw-r--r-- 1 root root 0 Mar 12 14:13 cgroup.clone_children
--w--w--w- 1 root root 0 Mar 12 14:13 cgroup.event_control
-rw-r--r-- 1 root root 0 Mar 12 14:13 cgroup.procs
-r--r--r-- 1 root root 0 Mar 12 14:13 cgroup.sane_behavior
drwxr-xr-x 2 root root 0 Mar 12 14:13 docker/
drwxr-xr-x 2 root root 0 Mar 12 14:13 init.scope/
-rw-r--r-- 1 root root 0 Mar 12 14:13 memory.failcnt
--w------- 1 root root 0 Mar 12 14:13 memory.force_empty
-rw-r--r-- 1 root root 0 Mar 12 14:13 memory.kmem.failcnt
-rw-r--r-- 1 root root 0 Mar 12 14:13 memory.kmem.limit_in_bytes
-rw-r--r-- 1 root root 0 Mar 12 14:13 memory.kmem.max_usage_in_bytes
-r--r--r-- 1 root root 0 Mar 12 14:13 memory.kmem.slabinfo
-rw-r--r-- 1 root root 0 Mar 12 14:13 memory.kmem.tcp.failcnt
-rw-r--r-- 1 root root 0 Mar 12 14:13 memory.kmem.tcp.limit_in_bytes
-rw-r--r-- 1 root root 0 Mar 12 14:13 memory.kmem.tcp.max_usage_in_bytes
-r--r--r-- 1 root root 0 Mar 12 14:13 memory.kmem.tcp.usage_in_bytes
-r--r--r-- 1 root root 0 Mar 12 14:13 memory.kmem.usage_in_bytes
-rw-r--r-- 1 root root 0 Mar 12 14:13 memory.limit_in_bytes
-rw-r--r-- 1 root root 0 Mar 12 14:13 memory.max_usage_in_bytes
-rw-r--r-- 1 root root 0 Mar 12 14:13 memory.move_charge_at_immigrate
-r--r--r-- 1 root root 0 Mar 12 14:13 memory.numa_stat
-rw-r--r-- 1 root root 0 Mar 12 14:13 memory.oom_control
---------- 1 root root 0 Mar 12 14:13 memory.pressure_level
-rw-r--r-- 1 root root 0 Mar 12 14:13 memory.soft_limit_in_bytes
-r--r--r-- 1 root root 0 Mar 12 14:13 memory.stat
-rw-r--r-- 1 root root 0 Mar 12 14:13 memory.swappiness
-r--r--r-- 1 root root 0 Mar 12 14:13 memory.usage_in_bytes
-rw-r--r-- 1 root root 0 Mar 12 14:13 memory.use_hierarchy
-rw-r--r-- 1 root root 0 Mar 12 14:13 notify_on_release
-rw-r--r-- 1 root root 0 Mar 12 14:13 release_agent
drwxr-xr-x 95 root root 0 Mar 12 13:22 system.slice/
-rw-r--r-- 1 root root 0 Mar 12 14:13 tasks
drwxr-xr-x 2 root root 0 Mar 12 14:14 test_memory/
drwxr-xr-x 3 root root 0 Mar 12 13:58 user.slice/2. 可以看到内存限制文件已经自动在test_memory中创建完成了,cgroups 文件系统会在创建文件目录的时候自动创建相应的配置文件
Shell root@139-159-150-152:/sys/fs/cgroup/memory/test_memory# ll
total 0
drwxr-xr-x 2 root root 0 Mar 12 14:14 ./
dr-xr-xr-x 7 root root 0 Mar 10 14:13 ../
-rw-r--r-- 1 root root 0 Mar 12 14:14 cgroup.clone_children
--w--w--w- 1 root root 0 Mar 12 14:14 cgroup.event_control
-rw-r--r-- 1 root root 0 Mar 12 14:14 cgroup.procs
-rw-r--r-- 1 root root 0 Mar 12 14:14 memory.failcnt
--w------- 1 root root 0 Mar 12 14:14 memory.force_empty
-rw-r--r-- 1 root root 0 Mar 12 14:14 memory.kmem.failcnt
-rw-r--r-- 1 root root 0 Mar 12 14:14 memory.kmem.limit_in_bytes
-rw-r--r-- 1 root root 0 Mar 12 14:14 memory.kmem.max_usage_in_bytes
-r--r--r-- 1 root root 0 Mar 12 14:14 memory.kmem.slabinfo
-rw-r--r-- 1 root root 0 Mar 12 14:14 memory.kmem.tcp.failcnt
-rw-r--r-- 1 root root 0 Mar 12 14:14 memory.kmem.tcp.limit_in_bytes
-rw-r--r-- 1 root root 0 Mar 12 14:14 memory.kmem.tcp.max_usage_in_bytes
-r--r--r-- 1 root root 0 Mar 12 14:14 memory.kmem.tcp.usage_in_bytes
-r--r--r-- 1 root root 0 Mar 12 14:14 memory.kmem.usage_in_bytes
-rw-r--r-- 1 root root 0 Mar 12 14:14 memory.limit_in_bytes
-rw-r--r-- 1 root root 0 Mar 12 14:14 memory.max_usage_in_bytes
-rw-r--r-- 1 root root 0 Mar 12 14:14 memory.move_charge_at_immigrate
-r--r--r-- 1 root root 0 Mar 12 14:14 memory.numa_stat
-rw-r--r-- 1 root root 0 Mar 12 14:14 memory.oom_control
---------- 1 root root 0 Mar 12 14:14 memory.pressure_level
-rw-r--r-- 1 root root 0 Mar 12 14:14 memory.soft_limit_in_bytes
-r--r--r-- 1 root root 0 Mar 12 14:14 memory.stat
-rw-r--r-- 1 root root 0 Mar 12 14:14 memory.swappiness
-r--r--r-- 1 root root 0 Mar 12 14:14 memory.usage_in_bytes
-rw-r--r-- 1 root root 0 Mar 12 14:14 memory.use_hierarchy
-rw-r--r-- 1 root root 0 Mar 12 14:14 notify_on_release
-rw-r--r-- 1 root root 0 Mar 12 14:14 tasks3. 配置cgroup的策略为最大使用20M内存
Shell
root@139-159-150-152:/sys/fs/cgroup/memory# expr 20 \* 1024 \*
1024
20971520
root@139-159-150-152:/sys/fs/cgroup/memory# cat
test_memory/memory.limit_in_bytes
9223372036854771712
root@139-159-150-152:/sys/fs/cgroup/memory# echo "20971520" > test_memory/memory.limit_in_bytes
root@139-159-150-152:/sys/fs/cgroup/memory# cat
test_memory/memory.limit_in_bytes
209715204. 启动1个消耗内存的进程,每个进程占用50M内存
Shell root@139-159-150-152:/sys/fs/cgroup# stress -m 1 --vm-bytes 50M
stress: info: [62106] dispatching hogs: 0 cpu, 0 io, 1 vm, 0 hdd5. 打开一个新的shell窗口B窗口,使用pidstat查看状态,找到对应的进程id
Shell root@139-159-150-152:/sys/fs/cgroup/memory# pidstat -r -C stress -p ALL 1 10000
Linux 5.4.0-100-generic (139-159-150-152) 03/12/2023 _x86_64_ (1 CPU)
02:47:01 PM UID PID minflt/s majflt/s VSZ RSS %MEM
Command 02:47:02 PM 0 62517 0.00 0.00 3856 988
0.05 stress
02:47:02 PM 0 62518 476597.03 0.00 55060 15156
0.75 stress
02:47:02 PM UID PID minflt/s majflt/s VSZ echo 62518 > test_memory/tasks RSS %MEM Command
02:47:03 PM 0 62517 0.00 0.00 3856 988 0.05 stress
02:47:03 PM 0 62518 483459.00 0.00 55060 3540 0.17 stress 02:47:03 PM UID PID minflt/s majflt/s VSZ RSS %MEM Command
02:47:04 PM 0 62517 0.00 0.00 3856 988 0.05 stress
# 注意62518为PID
02:47:04 PM 0 62518 489336.00 0.00 55060 15156 0.75 stress6. 打开一个新的shell C窗口,将进程id移动到我们的cgroup策略
Shell
cd /sys/fs/cgroup/memory
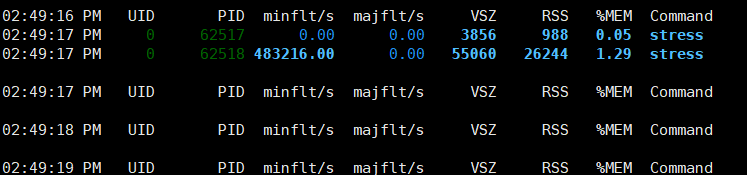
echo 62518 >> test_memory/tasks7. 可以看到进程无法申请到足够内存退出

可以看到进程消失了
实操三、使用cgroups对cpu进行控制
1. 创建内存的cgroup,很简单我们进入到cgroup的内存控制目录/sys/fs/cgroup/cpu,我们创建目录test_cpu,可以看到系统会自动为我们创建cgroup的cpu策略
Shell root@139-159-150-152:/sys/fs/cgroup/cpu# cd /sys/fs/cgroup/cpu
root@139-159-150-152:/sys/fs/cgroup/cpu# mkdir test_cpu
root@139-159-150-152:/sys/fs/cgroup/cpu# ll test_cpu
total 0
drwxr-xr-x 2 root root 0 Mar 12 14:54 ./
dr-xr-xr-x 9 root root 0 Mar 10 14:13 ../
-rw-r--r-- 1 root root 0 Mar 12 14:54 cgroup.clone_children
-rw-r--r-- 1 root root 0 Mar 12 14:54 cgroup.procs
-r--r--r-- 1 root root 0 Mar 12 14:54 cpuacct.stat
-rw-r--r-- 1 root root 0 Mar 12 14:54 cpuacct.usage
-r--r--r-- 1 root root 0 Mar 12 14:54 cpuacct.usage_all
-r--r--r-- 1 root root 0 Mar 12 14:54 cpuacct.usage_percpu
-r--r--r-- 1 root root 0 Mar 12 14:54 cpuacct.usage_percpu_sys
-r--r--r-- 1 root root 0 Mar 12 14:54 cpuacct.usage_percpu_user
-r--r--r-- 1 root root 0 Mar 12 14:54 cpuacct.usage_sys
-r--r--r-- 1 root root 0 Mar 12 14:54 cpuacct.usage_user
-rw-r--r-- 1 root root 0 Mar 12 14:54 cpu.cfs_period_us
-rw-r--r-- 1 root root 0 Mar 12 14:54 cpu.cfs_quota_us
-rw-r--r-- 1 root root 0 Mar 12 14:54 cpu.shares
-r--r--r-- 1 root root 0 Mar 12 14:54 cpu.stat
-rw-r--r-- 1 root root 0 Mar 12 14:54 cpu.uclamp.max
-rw-r--r-- 1 root root 0 Mar 12 14:54 cpu.uclamp.min
-rw-r--r-- 1 root root 0 Mar 12 14:54 notify_on_release
-rw-r--r-- 1 root root 0 Mar 12 14:54 tasks2. 打开新的shell 窗口B窗口,使用stress模拟一个任务,cpu使用率为100
Shell
root@139-159-150-152:/sys/fs/cgroup# stress -c 1
stress: info: [62576] dispatching hogs: 1 cpu, 0 io, 0 vm, 0 hdd3. 可以看到cpu的使用率为100%
Shell root@139-159-150-152:/sys/fs/cgroup/memory# pidstat -u -C stress -p ALL 1 10000
Linux 5.4.0-100-generic (139-159-150-152) 03/12/2023
_x86_64_ (1 CPU)
02:59:38 PM UID
PID %usr %system %guest %wait %CPU CPU Command
02:59:39 PM 0 62576 0.00 0.00 0.00 0.00 0.00 0 stress
02:59:39 PM 0 62577 99.01 0.00 0.00 0.99 99.01 0 stress
02:59:39 PM UID PID %usr %system %guest %wait %CPU CPU Command
02:59:40 PM 0 62576 0.00 0.00 0.00 0.00 0.00 0 stress
02:59:40 PM 0 62577 99.00 0.00 0.00 1.00
99.00 0 stress4. 打开新的shell窗口C窗口,我们设置cproup的cpu使用率为30%,cpu使用率的计算公式cfs_quota_us/cfs_period_us
1)cfs_period_us:cfs_period_us 表示一个cpu 带宽,单位为微秒。系统总CPU 带宽,默认值100000。
2)cfs_quota_us:cfs_quota_us 表示Cgroup 可以使用的cpu 的带宽,单位为微秒。cfs_quota_us 为-1,表示使用的CPU 不受cgroup 限制。cfs_quota_us 的最小值为1ms(1000),最大值为1s。 所以我们将cfs_quota_us的值设置为30000 ,从理论上讲就可以限制test_cpu控制的进程的cpu利用率最多是30% 。
Shell
cd /sys/fs/cgroup/cpu
echo 30000 > test_cpu/cpu.cfs_quota_us5. 我们可以看到进程的PID为62577,我们将该进程放到tasks文件进行控制
Shell
cd /sys/fs/cgroup/cpu
echo 62577 > test_cpu/tasks6. B窗口中可以看到我们监控的cpu的使用率由100%降低为30%
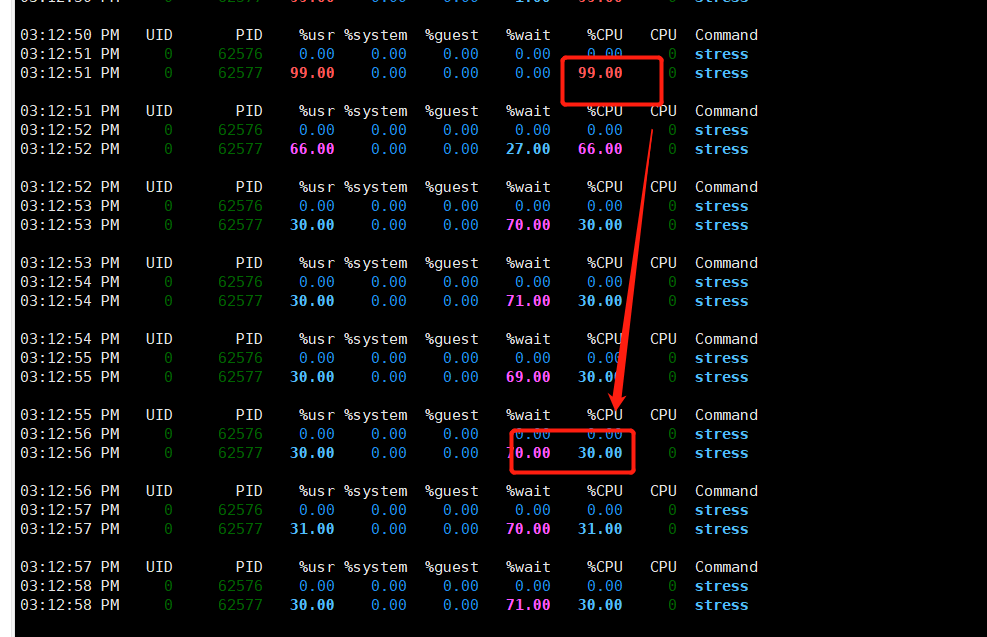
至此我们成功的模拟了对内存和cpu的使用控制,而docker本质也是调用这些的API来完成对资源的管理,只不过docker的易用性和镜像的设计更加人性化,所以docker才能风靡全球,docker课程完后我们会看下docker如何对资源控制对比这种控制可以说简单不止一倍。
容器虚拟化基础之LXC
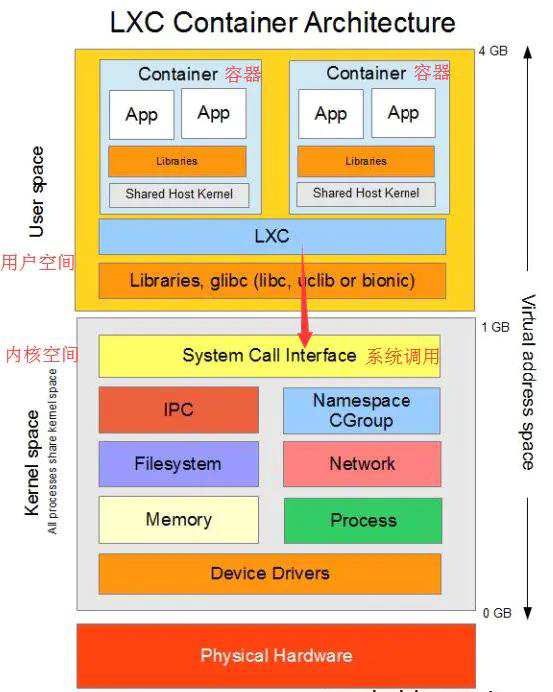
LXC是什么?
LXC(LinuX Containers)Linux容器,一种操作系统层虚拟化技术,为Linux内核容器功能的一个用户空间接口。它将应用软件系统打包成一个软件容器(Container),内含应用软件本身的代码,以及所需要的操作系统核心和库。透过统一的名字空间和共享API来分配不同软件容器的可用硬件资源,创造出应用程序的独立沙箱运行环境,使得Linux用户可以容易的创建和管理系统或应用容器。
LXC是最早一批真正把完整的容器技术用一组简易使用的工具和模板来极大的简化了容器技术使用的一个方案
LXC虽然极大的简化了容器技术的使用,但比起直接通过内核调用来使用容器技术,其复杂程度其实并没有多大降低,因为我们必须要学会LXC的一组命令工具,且由于内核的创建都是通过命令来实现的,通过批量命令实现数据迁移并不容易。其隔离性也没有虚拟机那么强大。
后来就出现了docker,所以从一定程度上来说,docker就是LXC的增强版。
LXC容器化实战
基础知识
LXC的常用命令如下:
lxc-checkconfig
检查系统环境是否满足容器使用要求;
格式:lxc-checkconfig
lxc-create
创建lxc容器;
格式:lxc-create -n NAME -t TEMPLATE_NAME [-- template-options]
lxc-start
启动容器;
格式:lxc-start -n NAME -d
lxc-ls
列出所有容器,-f表示打印常用的信息;
格式:lxc-ls -f
lxc-info
查看容器相关的信息;
格式:lxc-info -n NAME
lxc-attach
进入容器执行命令;
格式:lxc-attach --name=NAME [-- COMMAND]
lxc-stop
停止容器;
格式:lxc-stop -n NAME
lxc-destory
删除处于停机状态的容器;
格式:lxc-destory -n NAME
安装LXC
Ubuntu安装
安装前执行检查看下是否需要卸载,如果需要卸载,执行下面的命令完成卸载,不需要直接到第2步
Shell
# 一、检查是否安装。清理资源
systemctl status lxc
lxc-stop -n xxx # lxc-ls -f 遍历所有容器,停止运行的容器
lxc-destroy -n xxx # 删除对应的容器
# 二、 卸载软件 apt-get purge --auto-remove lxc lxc-templates
# 三、 检查服务已经没有该服务了 systemctl status lxc没有安装的话,执行下面的命令完成安装
Shell
#一、安装
#lxc 主程序包
#lxc-templates lxc的配置模板
#bridge-utils 网桥管理工具
apt install lxc lxc-templates bridge-utils -y
#二、检查服务是否正常运行 systemctl status lxcCentOS安装
安装前执行检查看下是否需要卸载,如果需要卸载,执行下面的命令完成卸载,不需要直接到第2步
Shell
# 一、检查是否安装。清理资源
systemctl status lxc #检查是否安装
lxc-stop -n xxx # 遍历所有容器,停止对应的容器
lxc-ls -f #删除对应的容器
lxc-destroy -n xxx # 二、 卸载软件
yum remove lxc lxc-templates lxc-libs lxc-extra libvirt debootstrap # 三、检查,提示服务不存在
systemctl status lxcCentOS安装LXC,如果已经安装,可以检查下是否需要卸载,如果需要卸载执行Centos卸载LXC
Shell
# 一、 配置源
yum -y install epel-release #这个软件包里包含epel yum源和GPG的配置 # 二、 安装程序 yum -y install lxc lxc-templates bridge-utils lxc-libs libcgroup libvirt lxc-extra debootstrap # lxc 主程序包
# lxc-templates lxc的配置模板
# bridge-utils 网桥管理工具 lxc-libs lxc所需的库文件
# libcgroup cgroup安装包
# libvirt 管理Linux的虚拟化功能所需的服务器端守护程序。 需要针对特定驱动程序的管理程序。
# debootstrap debootstrap是Debian引导程序,它允许您将Debian基本系统(例如Debian或Ubuntu)安装到当前正在运行的系统的目录中。 #三、启动和检查
#如果未运行输入以下命令完成启动
#启动lxc服务
systemctl start lxc
#启动虚拟机监控服务
systemctl start libvirtd
systemctl status lxc
systemctl status libvirtdLXC容器操作实战
1. 检查lxc是否运行
Shell root@139-159-150-152:/var/run/docker/netns# systemctl status lxc
● lxc.service - LXC Container Initialization and Autoboot Code Loaded: loaded (/lib/systemd/system/lxc.service; enabled;
vendor preset: enabled) Active: active (exited) since Fri 2023-03-17 11:27:47 CST;
1min 33s ago Docs: man:lxc-autostart man:lxc Main PID: 254137 (code=exited, status=0/SUCCESS) Tasks: 0 (limit: 2274) Memory: 0B CGroup: /system.slice/lxc.service Mar 17 11:27:47 139-159-150-152 systemd[1]: Starting LXC Container Initialization and Autoboot Code...
Mar 17 11:27:47 139-159-150-152 systemd[1]: Finished LXC Container Initialization and Autoboot Code.2. 检查lxc的功能支持情况
Shell root@139-159-150-152:/var/run/docker/netns# lxc-checkconfig
LXC version 4.0.12
Kernel configuration not found at /proc/config.gz; searching...
Kernel configuration found at /boot/config-5.4.0-100-generic
--- Namespaces ---
Namespaces: enabled
Utsname namespace: enabled
Ipc namespace: enabled
Pid namespace: enabled
User namespace: enabled
Network namespace: enabled
--- Control groups ---
Cgroups: enabled
Cgroup namespace: enabled
Cgroup v1 mount points:
/sys/fs/cgroup/systemd
/sys/fs/cgroup/cpu,cpuacct
/sys/fs/cgroup/perf_event
/sys/fs/cgroup/net_cls,net_prio
/sys/fs/cgroup/pids
/sys/fs/cgroup/blkio
/sys/fs/cgroup/freezer
/sys/fs/cgroup/cpuset
/sys/fs/cgroup/hugetlb
/sys/fs/cgroup/memory
/sys/fs/cgroup/rdma
/sys/fs/cgroup/devices Cgroup v2 mount points:
/sys/fs/cgroup/unifiedCgroup v1 clone_children flag: enabled
Cgroup device: enabled Cgroup sched: enabled
Cgroup cpu account: enabled
Cgroup memory controller: enabled
Cgroup cpuset: enabled
--- Misc ---
Veth pair device: enabled, loaded
Macvlan: enabled, not loaded
Vlan: enabled, not loaded
Bridges: enabled, loaded
Advanced netfilter: enabled, not loaded
CONFIG_IP_NF_TARGET_MASQUERADE: enabled, not loaded
CONFIG_IP6_NF_TARGET_MASQUERADE: enabled, not loaded
CONFIG_NETFILTER_XT_TARGET_CHECKSUM: enabled, loaded
CONFIG_NETFILTER_XT_MATCH_COMMENT: enabled, not loaded
FUSE (for use with lxcfs): enabled, not loaded --- Checkpoint/Restore ---
checkpoint restore: enabled
CONFIG_FHANDLE: enabled
CONFIG_EVENTFD: enabled
CONFIG_EPOLL: enabled
CONFIG_UNIX_DIAG: enabled
CONFIG_INET_DIAG: enabled
CONFIG_PACKET_DIAG: enabled
CONFIG_NETLINK_DIAG: enabled
File capabilities:Note : Before booting a new kernel, you can check its
configuration
usage : CONFIG=/path/to/config /usr/bin/lxc-checkconfig3. 查看lxc提供的容器模板
Shell root@139-159-150-152:/var/run/docker/netns# ls
/usr/share/lxc/templates/
lxc-alpine lxc-busybox lxc-debian lxc-fedora-legacy lxc-oci lxc-oracle lxc-sabayon lxc-sshd lxc-voidlinux lxc-altlinux lxc-centos lxc-download lxc-gentoo lxc-openmandriva lxc-plamo lxc-slackware lxc-ubuntu lxc-archlinux lxc-cirros lxc-fedora lxc-local lxc-opensuse lxc-pld lxc-sparclinux lxc-ubuntu-cloud4. 创建一个lxc虚拟主机,这个命令就会下载安装指定环境下的软件包,创建新容器。整个过程需要时间较长,与容器的类型有关。
Shell
#创建Ubuntu LXC容器,-t 指定模板容器,-n 指定要创建的容器名,下面创建的是ubuntu
#Centos上创建centos的命令:lxc-create -t centos --name centos1 -- --release 7 --arch x86_64 #Ubuntu上创建centos的命令,注意模板需要使用download:lxc-create --name centos7 --template=download -- --dist=centos --release=7 --arch=amd64 root@139-159-150-152:/var/run/docker/netns# lxc-create -t ubuntu --name lxchost1 -- -r xenial -a amd64
##创建完成显示 ##
# The default user is 'ubuntu' with password 'ubuntu'!
# Use the 'sudo' command to run tasks as root in the container.
##5. 下载安装完所有软件包后,LXC 容器镜像就创建完成了,你可以看到默认的登录界面。容器被放到/var/lib/lxc/<容器名> 这个目录下,容器的根文件系统放在/var/lib/lxc/<容器名>/rootfs 目录下。创建过程中下载的软件包保存在/var/cache/lxc 目录下面,当你想另外建一个一样的容器时,可以省去很多下载时间。
Shell root@139-159-150-152:/var/run/docker/netns# ll
/var/lib/lxc/lxchost1/
total 16
drwxrwx--- 3 root root 4096 Mar 17 11:44 ./
drwx------ 3 root root 4096 Mar 17 11:34 ../
-rw-r----- 1 root root 679 Mar 17 11:44 config
drwxr-xr-x 17 root root 4096 Mar 17 11:42 rootfs/
root@139-159-150152:/var/run/docker/netns# ll /var/cache/lxc/ total 12
drwx------ 3 root root 4096 Mar 17 11:34 ./
drwxr-xr-x 19 root root 4096 Mar 17 11:27 ../
drwxr-xr-x 3 root root 4096 Mar 17 11:44 xenial/6. 查看创建的容器信息。
Shell root@139-159-150-152:/var/run/docker/netns# lxc-ls -f
NAME STATE AUTOSTART GROUPS IPV4 IPV6 UNPRIVILEGED
lxchost1 STOPPED 0 - - - false7. 启动容器,我们可以看到容器状态为运行中
Shell root@139-159-150-152:/var/run/docker/netns# lxc-start -n lxchost1 -d
root@139-159-150-152:/var/run/docker/netns# lxc-ls -f
NAME STATE AUTOSTART GROUPS IPV4 IPV6 UNPRIVILEGED
lxchost1 RUNNING 0 - 10.0.3.248 - false8. 查看容器的详细信息
Shell root@139-159-150-152:/var/run/docker/netns# lxc-info -n
lxchost1 Name: lxchost1
State: RUNNING
PID: 282127
IP: 10.0.3.248
CPU use: 0.59 seconds
BlkIO use: 29.45 MiB
Memory use: 59.52 MiB
KMem use: 6.82 MiB
Link: vethbg8LKH TX bytes: 1.73 KiB RX bytes: 6.61 KiB Total bytes: 8.33 KiB9. 容器ip为10.0.3.248,我们通过ssh进入容器,查看ip地址,磁盘挂载信息,目录信息和宿主机都不一样
Shell root@139-159-150-152:/var/run/docker/netns# ssh ubuntu@10.0.3.248 ubuntu@10.0.3.248's password: ubuntu@lxchost1:~$ ip addr
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state
UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo valid_lft forever preferred_lft forever
inet6 ::1/128 scope host valid_lft forever preferred_lft forever
2: eth0@if562: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc
noqueue state UP group default qlen 1000
link/ether 00:16:3e:71:d8:3d brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 10.0.3.248/24 brd 10.0.3.255 scope global dynamic eth0 valid_lft 2844sec
preferred_lft 2844sec
inet6 fe80::216:3eff:fe71:d83d/64 scope link
valid_lft forever preferred_lft forever
ubuntu@lxchost1:~$ uname -a
Linux lxchost1 5.4.0-100-generic #113-Ubuntu SMP Thu Feb 3
18:43:29 UTC 2022 x86_64 x86_64 x86_64 GNU/Linux
ubuntu@lxchost1:~$ ll /
total 52
drwxr-xr-x 17 root root 4096 Mar 17 03:51 ./
drwxr-xr-x 17 root root 4096 Mar 17 03:51 ../
lrwxrwxrwx 1 root root 7 Mar 17 03:40 bin -> usr/bin/
drwxr-xr-x 2 root root 4096 Apr 15 2020 boot/
drwxr-xr-x 7 root root 540 Mar 17 03:51 dev/
drwxr-xr-x 63 root root 4096 Mar 17 03:51 etc/
drwxr-xr-x 3 root root 4096 Mar 17 03:44 home/
lrwxrwxrwx 1 root root 7 Mar 17 03:40 lib -> usr/lib/
lrwxrwxrwx 1 root root 9 Mar 17 03:40 lib32 -> usr/lib32/
lrwxrwxrwx 1 root root 9 Mar 17 03:40 lib64 -> usr/lib64/
lrwxrwxrwx 1 root root 10 Mar 17 03:40 libx32 -> usr/libx32/
drwxr-xr-x 2 root root 4096 Mar 17 03:40 media/
drwxr-xr-x 2 root root 4096 Mar 17 03:40 mnt/
drwxr-xr-x 2 root root 4096 Mar 17 03:40 opt/
dr-xr-xr-x 225 root root 0 Mar 17 03:51 proc/
drwx------ 2 root root 4096 Mar 17 03:40 root/
drwxr-xr-x 13 root root 420 Mar 17 04:04 run/
lrwxrwxrwx 1 root root 8 Mar 17 03:40 sbin -> usr/sbin/
drwxr-xr-x 2 root root 4096 Mar 17 03:40 srv/
dr-xr-xr-x 13 root root 0 Mar 17 03:51 sys/
drwxrwxrwt 9 root root 4096 Mar 17 04:04 tmp/
drwxr-xr-x 13 root root 4096 Mar 17 03:40 usr/
drwxr-xr-x 11 root root 4096 Mar 17 03:40 var/
ubuntu@lxchost1:~$ df -h
Filesystem Size Used Avail Use% Mounted on
/dev/vda1 40G 21G 17G 57% /
none 492K 4.0K 488K 1% /dev
tmpfs 992M 0 992M 0% /dev/shm
tmpfs 199M 108K 199M 1% /run
tmpfs 5.0M 0 5.0M 0% /run/lock
tmpfs 992M 0 992M 0% /sys/fs/cgroup
tmpfs 199M 0 199M 0% /run/user/1000
ubuntu@lxchost1:~$ ps -ef UID PID PPID C STIME TTY TIME CMD
root 1 0 0 03:51 ? 00:00:00 /sbin/init
root 44 1 0 03:51 ? 00:00:00
/lib/systemd/systemd-journald
systemd+ 72 1 0 03:51 ? 00:00:00
/lib/systemd/systemd-networkd
root 76 1 0 03:51 ? 00:00:00 /usr/sbin/cron -f
message+ 77 1 0 03:51 ? 00:00:00 /usr/bin/dbus-daemon --system --address=systemd: --nofork --nopidfile --systemd-activation --syslog-only
root 79 1 0 03:51 ? 00:00:00 /usr/bin/python3 /usr/bin/networkd-dispatcher --run-startup-
triggers
syslog 80 1 0 03:51 ? 00:00:00
/usr/sbin/rsyslogd -n -iNONE
root 81 1 0 03:51 ? 00:00:00
/lib/systemd/systemd-logind
systemd+ 82 1 0 03:51 ? 00:00:00
/lib/systemd/systemd-resolved
root 88 1 0 03:51 pts/0 00:00:00 /sbin/agetty -o -p -- \u --noclear --keep-baud console 115200,38400,9600 vt220
root 89 1 0 03:51 ? 00:00:00 sshd: /usr/sbin/sshd -D [listener] 0 of 10-100 startups
root 163 89 0 04:03 ? 00:00:00 sshd: ubuntu
[priv]
ubuntu 166 1 0 04:04 ? 00:00:00
/lib/systemd/systemd --user
ubuntu 167 166 0 04:04 ? 00:00:00 (sd-pam)
ubuntu 182 163 0 04:04 ? 00:00:00 sshd:
ubuntu@pts/5
ubuntu 183 182 0 04:04 pts/5 00:00:00 -bash
ubuntu 196 183 0 04:04 pts/5 00:00:00 ps -ef10. 在容器外面执行命令
Shell
root@139-159-150-152:/var/run/docker/netns# lxc-attach -n lxchost1 --clear-env -- echo "Hello bit"
Hello bit11. 停止容器(容器先停止才可以删除)
Shell root@139-159-150-152:/var/run/docker/netns# lxc-stop -n lxchost1
root@139-159-150-152:/var/run/docker/netns# lxc-ls -f
NAME STATE AUTOSTART GROUPS IPV4 IPV6 UNPRIVILEGED
lxchost1 STOPPED 0 - - - false12. 删除容器
Shell root@139-159-150-152:/var/run/docker/netns# lxc-destroy -n
lxchost1
root@139-159-150-152:/var/run/docker/netns# lxc-ls -f
root@139-159-150-152:/var/run/docker/netns#Docker是什么
Docker本质
Docker本质其实是LXC之类的增强版,它本身不是容器,而是容器的易用工具。容器是linux内核中的技术,Docker只是把这种技术在使用上简易普及了。Docker在早期的版本其核心就是LXC的二次封装发行版。
Docker作为容器技术的一个实现,或者说让容器技术普及开来的最成功的实现。Docker是基于Go语言实现的一个开源项目,它的主要目标是“Build,Ship and Run Any APP,Anywhere”,即通过对组件的封装、分发、部署、运行等生命周期的管理,使得用户的应用及其运行环境能够做到“一次封装,到处运行”。
早期Docker利用LXC做容器管理引擎,但是在创建容器时,不再使用模板去安装生成,而是通过镜像技术(把一个操作系统用户空间所需要使用到的组件事先编排好,并整体打包成一个文件,image文件),镜像文件集中放在一个仓库中。当需要创建容器时,Docker调用LXC的工具lxc-create,但不再通过lxc的模板去安装,而是连接到镜像服务器上下载匹配的镜像文件,而后基于镜像启动容器。所以,Docker极大的简化了容器的使用难度。以后我们创建启动容器,只需要一个命令,docker-run,docker-stop就可以启动停止一个容器了。
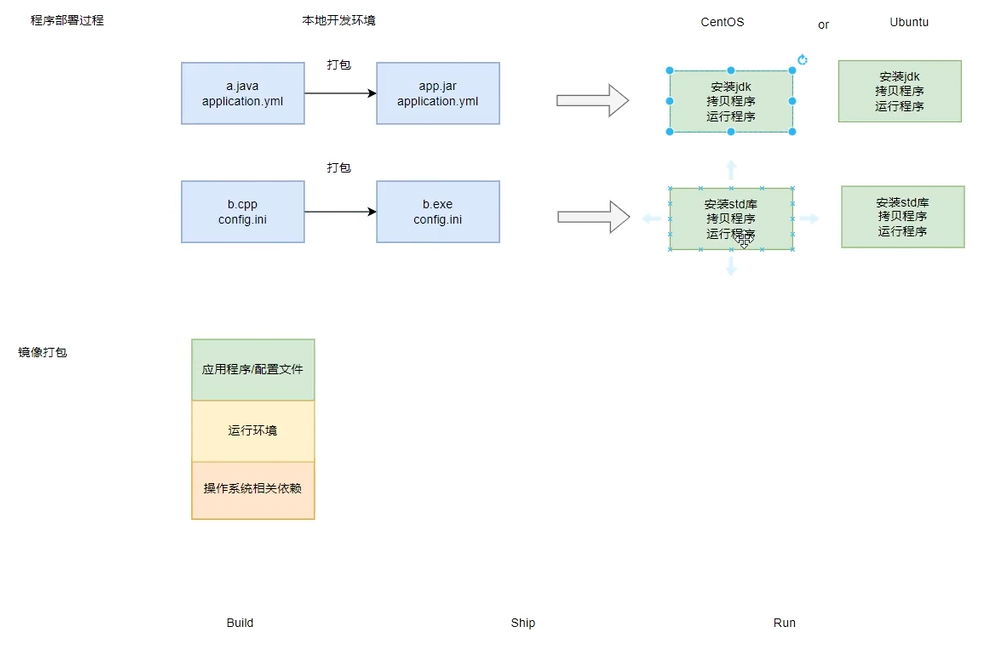
相比较原本的程序部署相将对应程序文件拷贝至系统上,再搭建对应的环境,docker直接将操作系统层之上程序所需的所有文件、依赖打包统一进行部署、派发。
Docker的引擎迭代
Docker早期是基于LXC容器管理引擎实现,当后来成熟之后,Docker自建了一个容器引擎叫libcontainer,后来CNCF的介入,Docker又研发了一个工业化标准的容器引擎runC,目前所使用的新版Docker,所使用的容器引擎就是RunC。
Docker和虚拟机的区别
| 传统虚拟机 | Docker容器 | |
|---|---|---|
| 磁盘占用 | 几个GB到几十个GB左右 | 几十MB到几百MB左右 |
| CPU内存占用 | 虚拟操作系统非常占用CPU和内存,需要通过虚拟层调用占用率高 | Docker引擎占用资源极低,直接作用于硬件资源占用少 |
| 启动速度 | (从开机到运行项目)几分钟 | (从开启容器到运行项目)几秒 |
| 安装管理 | 需要专门的运维技术 | 安装、管理方便 |
| 应用部署 | 手动部署,速度慢 | 体系化部署,可以自动化,速度快 |
| 隔离性 | 系统级别 | 进程级别 |
| 封装程度 | 打包整个操作系统 | 打包项目代码和依赖信息 |
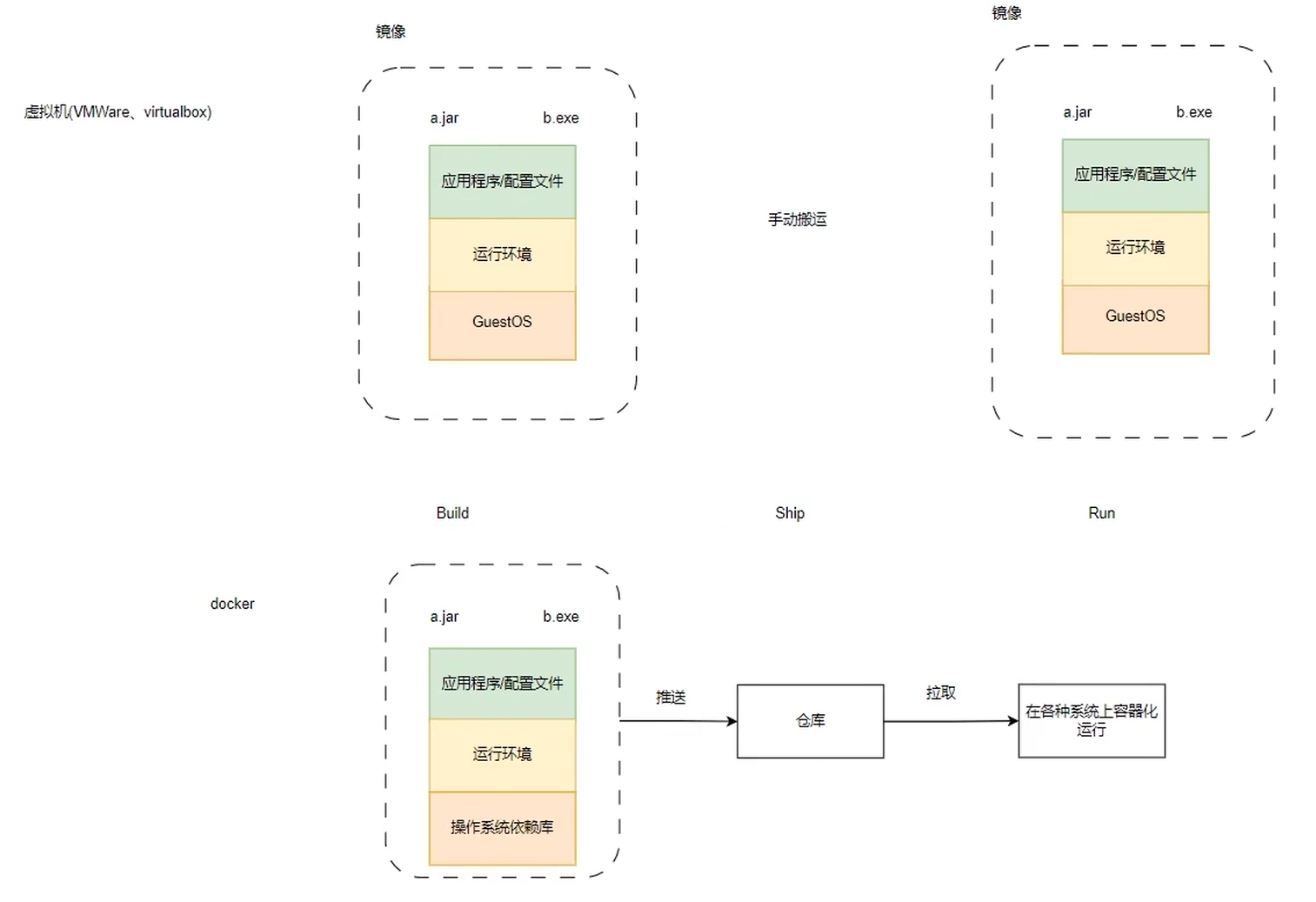
虚拟机需要将所需要的文件、环境手动搬运至新系统,而docker将所需要的一切打包,借助远程仓库,上传,其他人员就可以从仓库直接拉取下来完整的容器,容器化的直接运行程序。
Docker为什么比虚拟机资源利用率高,启动快
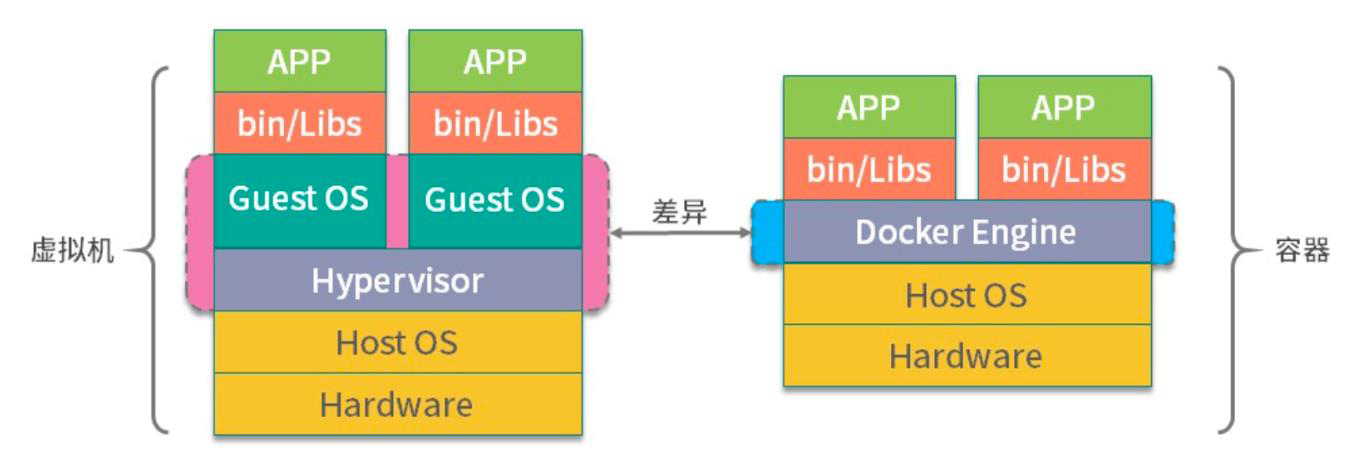
docker有比虚拟机更少的抽象层。docker不需要Hypervisor实现硬件资源虚拟化,运行在docker容器上的程序直接使用的是实际物理机的硬件资源。因此在cpu、内存利用率上docker将会在效率上有明显的优势。docker利用的是宿主机的内核,而不需要Guest OS,节省了Guest OS占用的资源。
docker不需要Guest OS,创建一个容器时,不需要和虚拟机一样重新加载一个操作系统内核。从而避免引寻、加载操作系统内核返回时耗时耗资源的过程,当新建一个虚拟机时,虚拟机软件需要加载Guest OS,返回新建过程是分钟级别的。而新建一个docker容器只需要几秒钟。
Docker和JVM虚拟化的区别?
| JVM | Docker容器 | |
|---|---|---|
| 性能 | Jvm需要占用一定的的CPU和内存 | 基本没有损失 |
| 虚拟层面 | 基于JVM虚拟机,更加上层 | 基于操作系统,更加通用 |
| 代码无关性 | 一个特定代码的执行平台,它是运行时才存在的,只能支撑特定代码的执行,并且必须是在jvm进程内 | 模拟了一整个操作系统,它是静态存在的,可以支撑任何相同平台的应用程序 |
| 主机隔离性 | jvm不隔离主机 | 通过命名空间实现隔离 |
Docker版本
Docker发展过程中衍生了以下版本,目前我们学习和使用提到的版本是docker-ce。
lxc:上文中提到,lxc是最早的linux容器技术,早期版本的docker直接使用lxc来实现容器的底层功能。虽然使用者相对较少,但lxc项目仍在持续开发演进中。
libcontainer:docker从0.9版本开始自行开发了libcontainer模块来作为lxc的替代品实现容器底层特性,并在1.10版本彻底去除了lxc。在1.11版本拆分出runc后,libcontainer也随之成为了runc的核心功能模块,runc后续变成了容器标准。
moby:moby是docker公司发起的开源项目,其中最主要的部分就是同名组件moby,事实上这个moby就是dockerd目前使用的开源项目名称,docker项目中的engine(dockerd)仓库现在就是从moby仓库fork而来的,使用containerd作为运行时标准。https://mobyproject.org/(moby一开始是docker engine的开源版本,后来改成了moby,现在的docker engine 更多的是原来的收费版)
docker-ce:docker的开源版本,CE指Community Edition。docker-ce中的组件来自于moby、containerd等其他项目。https://www.docker.com/pricing/
docker-ee:docker的收费版本,EE指Enterprise Edition。其基础组件来源和docker-ce是一样的,但附加了一些其他的组件和功能。
https://www.docker.com/pricing/
Docker官方网站
docker官网主要就相当于字典,当我们忘记一些指令,可以通过官网查询
https://www.docker.com/
Docker架构
官方架构
Docker 使用客户端-服务器(C/S) 架构模式,使用远程API来管理和创建Docker容器。
Docker 容器通过Docker 镜像来创建。
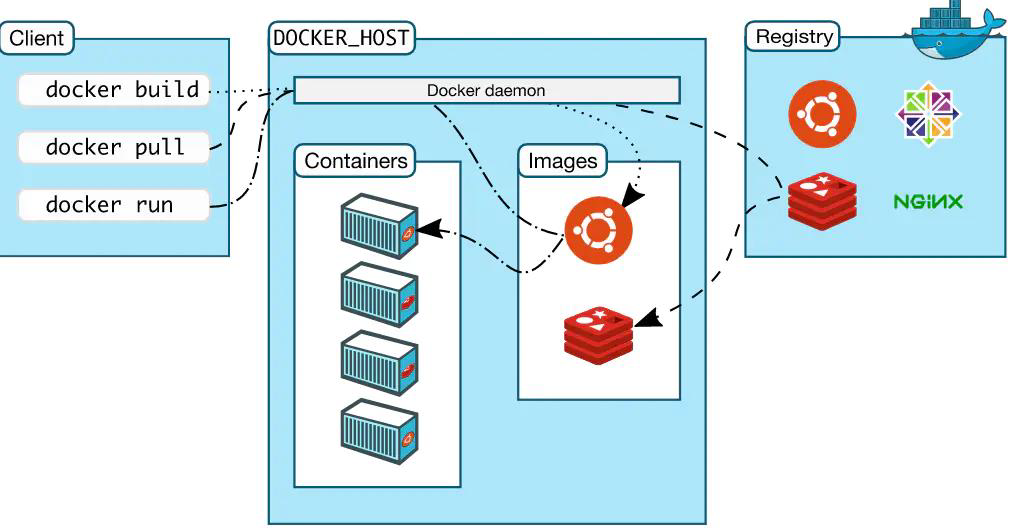
• Docker 仓库(Registry)
Docker 仓库用来保存镜像,可以理解为代码控制中的代码仓库。Docker Hub供了庞大的镜像集合供使用。
• Docker daemon
Docker daemon 是服务器组件,是Docker 最核心的后台进程,我们也把它称为守护进程。
• Docker 客户端(Client)
Docker 客户端通过命令行或者其他工具使用Docker API 与Docker 的守护进程通信。
• Docker 主机(Host)
一个物理或者虚拟的机器用于执行Docker 守护进程和容器。
• Docker 镜像(Images)
Docker 镜像是用于创建Docker 容器的模板。
• Docker 容器(Container)
容器是独立运行的一个或一组应用。
当我们的客户端docker build 之后如果发现容器内缺少某种组件,通过pull ,host会从Registry中拿取封装好的组件到images,客户端发起run,images就会将封装的组件拆封,变成容器开始运行,由于组件是各种需要的环境都是一起封装打包好的,run之后可以正常运行。
如果上述过程中images中有需要的组件,那host就不需要从Registry拿取组件,可以直接将images中已有的组件直接拆封进行run。
生活案例
上面概念比较难以理解,我们列举个生活中的案例,以一家人去旅游入住酒店为例。
我们一家人和朋友一块旅游去酒店,我们就是Docker Client

到酒店办理入住,办理退房,缴费需要酒店前台提供各种服务,酒店前台就是我们的Docker Daemon,Docker的核心服务端

酒店是建在美丽的海边,酒店的宅基地和大楼就是我们实际的物理服务器或者虚拟服务器,也就是Docker Host

酒店就1000多个房间,每个房间里面不一样,有标间、大床房、家庭房等,这就是Docker镜像仓库

酒店的标准的房间豪华大床房和双人标间,这个就是Docker 镜像,我们客户是没有办法修改的。

我们办理完入住了一个豪华大床房,然后把行李,个人物品带到了一个具体的房间号,比如9527,那么这个房间我们可以使用了,朋友也开了一间豪华大床房,虽然豪华大床房一样,当时我们携带的物品,我们的洗漱时间,睡觉时间都不一样,这个就是容器Docker Container。

容器的销毁,也就是我们一周后旅游结束了,搬出了酒店,酒店把我们的房间恢复了镜像原来的样子。
Docker生态
新时代软件诉求
我们来考虑2个问题,Docker为什么要设计镜像,然后又搭建个Docker Hub,搞个镜像仓库呢?
我们来看下现在的时代发生了什么
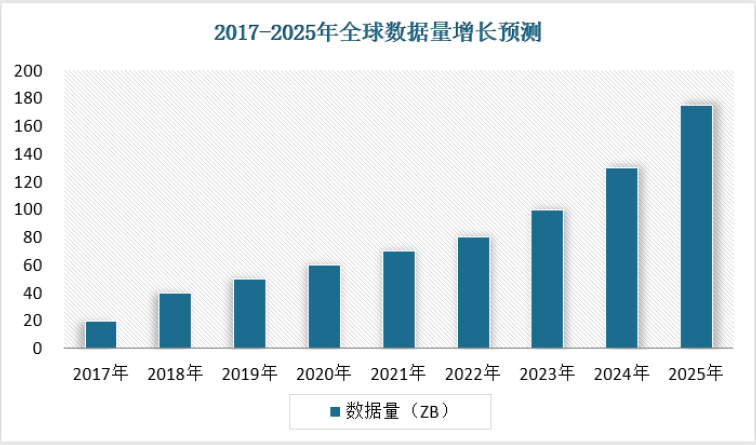
数据量疯狂增长:
随着物联网、边缘计算等智能终端设备不断普及,受到来自物联网设备信号、元数据、娱乐相关数据、云计算和边缘计算的数据增长的驱动,全球数据量呈现加速增长。根据IDC分布的《数据时代2025》预测,全球数据量将从2018年的33ZB增至2025年的175ZB,增长超过5倍;中国平均增速快于全球3%,预计到2025年将增至48.6ZB,占全球数据圈的比例由23.4%提升至27.8%。其中,中国企业级数据量将从2015年占中国数据量的49%增长到2025年的69%。
处理能力快速增加:
腾讯云全球服务器数量100w+,数据量EB+;2020年阿里云:在全国已建成5大超级数据中心,阿里云在全球22 个地域部署了上百个数据中心,服务器的总规模数已经接近200 万台。
某省疾控中心疫苗预约系统、全员核酸检测系统、健康码系统共300余台服务器,并为核酸检测系统快速扩容计算和存储资源。
软件需求爆发式增长:
•软件发布频繁
(1)研发模式从瀑布开发演变为敏捷开发,原来3个月上一次新功能,现在两周一次,而开发过程中我们也经常遇到需要修改需求,然后变更再发布的情况。
(2)软件上线有问题需要快速回滚,对软件有着极强的版本管理和回滚诉求。

•软件需要共享
软件的研发人员、研发公司在设计、研发好一款软件的时候,如何方便的共享给他人,而又能快速的使用起来。
•环境搭建复杂,技术种类繁多
每个项目组使用的语言不一样,需要不同的环境,每个都得搞一套。每次都要从yum开始一个个完成部署安装,每次都有各种奇怪的问题,运维成本很高。

Docker 解决方案
云时代需要我们针对这些诉求有一套针对的解决方案。
•我们要处理海量的数据,如何处理呢? 购买大量的服务器,并研发对应软件
•开发的需求需要频繁的变更上线,如何才能将修改的代码快速的分发到几百或者几千台服务器呢?如何共享软件呢?搞一个中心仓库,让各个服务器去下载软件包,安装,所以CentOS搞了yum仓库,docker设计了镜像仓库,docker hub是公共的托管仓库。
•软件设计好以后,怎么快速安装启动,有问题回滚呢?
将docker需要的所有信息设计一套软件格式,把所有的依赖搞进去,并打上版本标签,这样不会换一个服务器各种问题,所以Docker设计了镜像。
•不同的开发环境怎么搭建呢,一会java,一会c++?
docker设计了镜像来应对,镜像里面存放了需要运行的环境,就像我们的iPhone内置ios,我们的华为mate 50内置鸿蒙一样,一条命令就可以完成某个环境的搭建。