从零开始的python学习——文件
ʕ • ᴥ • ʔ
づ♡ど
🎉 欢迎点赞支持🎉

个人主页:励志不掉头发的内向程序员;
专栏主页:python学习专栏;
文章目录
前言
一、文件是什么
二、文件路径
三、文件操作
(1)打开文件
(2)关闭文件
(3)写文件
(4)读文件
四、上下文管理器
总结
前言
本章节我们就来了解了解我们计算机是如何保存我们的数据的,为什么我们的程序运行完数据就没了,但是我们的计算机却能在不断的关机重启中还能保存我们的数据,我们一起来看看吧。

一、文件是什么
变量是把数据保存到内存中,如果程序重启/主机重启,内存中的数据就会丢失。
要想能让数据被持久化存储,就可以把数据存储到硬盘中,也就是在文件中保存。
在 Windows "此电脑中",看到的内容都是文件。
通过文件的后缀名,可以看到文件的类型,常见的文件类型如下:
- 电影文件(mp4)
- 歌曲文件(mp3)
- 图片文件(jpg)
- 文本文件(tet)
- 表格文件(xlsx)
虽然它们里面保存的内容都不一样,但是它们有一个共同点,就是它们的数据都是保存在硬盘上的。
在此电脑中,我们C盘、D盘等,里面的内容都是硬盘上的内容,也都是文件。文件夹也叫目录,也是一种特殊的文件,叫目录文件。
但即使都是文件,在文件里面存储的内容和格式差异还是非常大的,还比较复杂。我们文章中重点学习的是文本文件。
二、文件路径
一个机器上,会存在很多文件,为了让这些文件更方便的被组织,往往会使用很多的 "文件夹"(也叫目录)来整理文件。实际一个文件往往是放在一系列的目录结构之中的。
为了方便确定一个文件所在位置,使用文件路径来进行描述。
例如在这里打开一个 WPS 软件。

它头顶就是它的文件路径。
![]()
在 D 盘中有个 WPS 目录,WPS 目录中有个 wps2024 目录, wps2024目录中有个 WPS Office 目录.....。最后就可以看到这里有很多的文件。我们 WPS 相关的很多文件,就是包含在上述文件路径之中。
所以我们为了表示 WPS.exe 这个文件位置,我们就可以通过路径的方式来表示。
我们点一下头顶的文件路径。

我们可以按照 D:\WPS\wps2024\WPS Office\12.1.0.21915\office6\ + 文件名 找到这里面的任意一个文件。我们把这一串字符串称之为文件的路径。当然,知道了文件路径,也就可以进一步的知道这个文件里都有啥了,就可以使用这个文件了。
文件路径也可以视为是文件在硬盘上的身份标识,每个文件对应的路径都是唯一的。
我们目录名之间,使用 \ 来分割。但是使用 / 其实也行。在代码中表示一个文件路径,用 / 更多。因为使用 \ 不太方便,\ 在字符串中有特殊的含义,表示 "转义字符"。\\ 在字符中才表示 字符 \。
三、文件操作
要使用文件,主要是通过文件来保存数据,并且在后续把保存的数据读取出来。
但是要想读写文件,需要先 "打开文件",读写完毕之后还要 "关闭文件"。
(1)打开文件
使用内置函数 open 打开一个文件。
我们的系统是不会区分大小写的。open 的第一个参数就是你要打开的文件路径,我在这里的 D 盘的 Python 环境中新创建了一个 test.txt 文件,这里就打开这个文件,文件路径就是:
D:/Python环境/test.txt
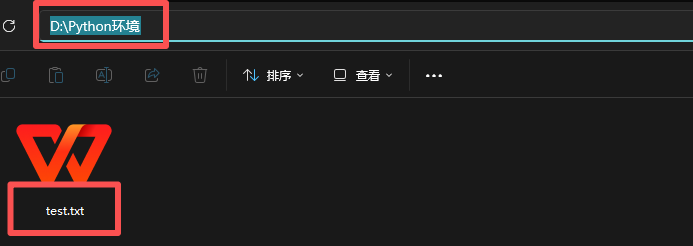
当然有的人的后面的文件类型是默认隐藏的,想要打开可以在查看中打开。
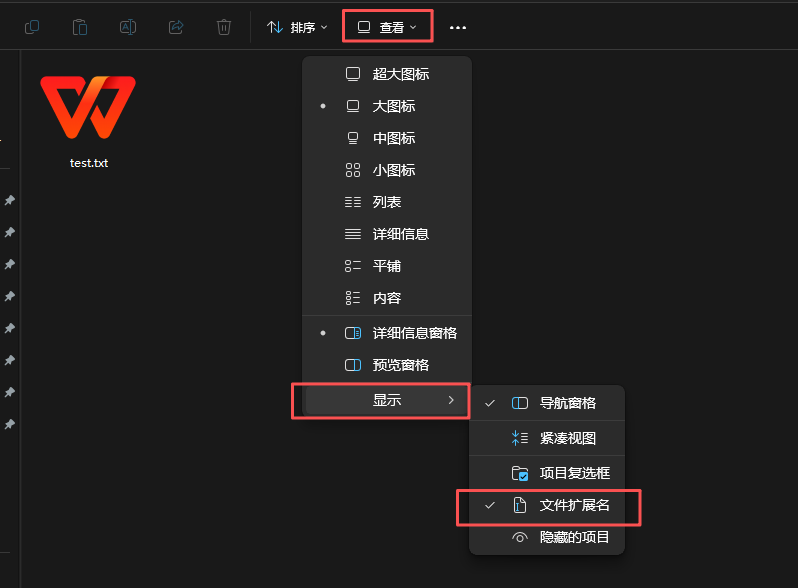
这样就可以看到了。
我们第二个参数也是一个字符串。它的作用是决定了文件的打开方式。
- r 表示 read,按照读的方式打开,只能读,不能修改。
- w 表示 write,按照写的方式打开,只能写,不能读。
- a 表示 append,也是写的方式打开,但是是把内容写到原有文件末尾。
# 使用 open 打开一个文件
f = open('d:/Python环境/test.txt', 'r')
print(f)
print(type(f))如果打开文件成功,返回一个文件对象,后续的读写文件操作都是围绕这个文件对象展开。f 此处相当于 file 缩写,意思是这是一个文件对象。

文件中涉及到了一些信息,文件路径,打开方式以及编码方式。而文件类型名字是 Python 内部给起的名字,我们没必要纠结。
当然,如果路径指定的文件不存在或者其他事情导致打开文件夹失败,就会抛出异常。
# 使用 open 打开一个文件
f = open('d:/Python环境/test1.txt', 'r')
此时我们没有文件 test1.txt,文件会打开失败。

我们运行时就会抛出异常,错误信息就是文件没找到。
open 的返回值是一个文件对象,我们文件内容是在硬盘上的,而此处的文件对象,则是内存上的一个变量。后续读写文件操作,都是拿着这个文件对象来进行操作的。此处的文件对象就像一个 "遥控器",我们借助这个遥控器间接访问硬盘。
计算机中也把这样远程操控的 "遥控器" 称为 "句柄"。
(2)关闭文件
使用 close 方法关闭已经打开的文件。
f.close()使用完毕的文件要记得及时关闭。打开文件其实就是在申请一定的系统资源,不使用文件的时候,资源就应该及时释放。否则就可能造成文件资源泄露,进一步导致其他部分的代码无法顺利打开文件了。
正是因为一个系统的资源是有限的,因此一个程序能打开的文件个数是有上限的。
# 打开文件个数的上限
flist = []
count = 0
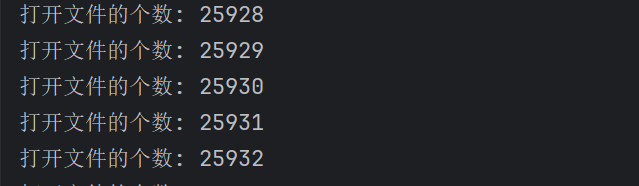
while True:f = open('d:/Python环境/test.txt', 'r')flist.append(f)count += 1print(f'打开文件的个数: {count}')
我们来运行一下上面的程序,这个程序就是一直循环打开我们的文件。每打开一个文件我们的count 计数器就会 +1。我们来看看一共可以打开多少文件。
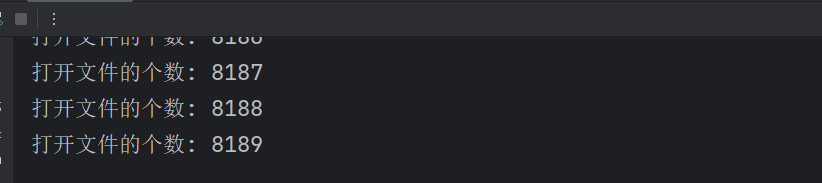
虽然这里显示我们最多打开的文件数量是 8189,但是你不能说最多能打开 8189 个文件。因为在系统中,是可以通过一些设置项来配置能打开文件的最大数目的。但是无论配置多少都不是无穷无尽的,所以我们一定要记得关闭文件。"有借有还,再借不难"。
当然我们如果仔细观察就会发现,我们这里打开文件的最大个数如果 +3 就是 2 的 13 次方,其实我们计算机中的很多数据都是按照 2 的多少次方这样来表示的,所以在程序猿眼中,1000 不是一个很整齐的数字,1024(2 的 10 次方)才是一个比较整齐的数字。
也就是说其实计算机默认打开了 3 个文件,它们分别是:
1、标准输入 对应键盘
2、标准输出 对应显示器
3、标准错误 对应显示器
我们的 print 就是通过标准输出来读取数据,而 input 就是通过我们标准输入来读取数据。
文件资源泄露,其实是一个挺重要的问题,因为它不会第一时间暴露出来,而是在角落里,冷不丁的偷袭一下。
我们 Python 中有一个重要的机制就是垃圾回收机制(GC),它会默认把我们不使用的变量进行释放。
count = 0
while True:f = open('d:/Python环境/test.txt', 'r')count += 1print(f'打开文件的个数: {count}')由于我们打开的文件没有使用,所以 Python 认为是垃圾而自动回收了。所以这里就可以一直打开文件。
但是我们也不能完全依赖 Python 的回收机制,因为这个释放不一定及时,它还得判断是否是垃圾。
(3)写文件
文件打开之后,就可以写文件了。
- 写文件,要使用写的方式打开,open 第二个参数设为 'w'
- 使用 write 方法写入文件
# 使用 open 打开一个文件
f = open('d:/Python环境/test.txt', 'w')
f.write('hello')f.close()
我们运行程序可以发现我们的控制台没有任何的输出。

此时我们打开我们的文件看看。

我们的文件中就有了我们打印的内容。
f = open('d:/Python环境/test.txt', 'r')
f.write('hello')f.close()我们如果使用 r 方式打开后去写文件就会出现问题。

错误信息为不支持此操作。
当然,我们写方式有两种,一种是直接写方式打开,另外一种是追加写方式打开。它们之间有所不同。
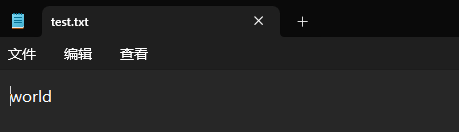
我们往刚才的文件中接着写一些内容看看,我们已经往文件中写了一个 "hello" 了,我们继续写一个 "world" 看看。
f = open('d:/Python环境/test.txt', 'w')
f.write('world')f.close()我们的 hello 没了。
我们这次打印一个空字符串看看。
f.write('')
我们文件啥也没了。
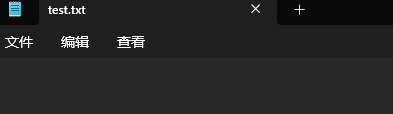
所以如果直接写方式打开的文件,系统会把文件原本的内容清空。
如果想要关注我们的旧的数据,我们就得使用 a 的方式打开文件,这种方式不会清空,写的内容会追加在原有内容末尾。
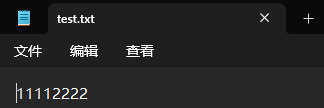
f = open('d:/Python环境/test.txt', 'a')
f.write('1111')f.close()此时我们文件就会写入 '1111'。

此时我们再写入 '2222'。
f.write('2222')我们原有的数据没有清空,而是在后面继续写入我们想要的内容了。
如果想要换行,我们只需要输入换行符即可,换行符是一种转义字符,它的写法是 \n。
f.write('\n2222')
如果文件对象已经关闭,那么意味着系统中和该文件相关的内存资源已经释放了,强行去写就会出异常。
f = open('d:/Python环境/test.txt', 'w')
f.close()f.write('3333')
(4)读文件
- 读文件内容需要使用 'r' 的方式打开文件。
- 使用 read 方法完成读操作,参数表示 "读取几个字符"
先准备一个文件,文件内容如下。
床前明月光
疑是地上霜
举头望明月
低头思故乡
我们针对这一首诗来进行读文件操作。
# 使用 read 读取文件内容,指定读取几个字符
f = open('d:/Python环境/test.txt', 'r')
result = f.read(2)
print(result)
f.close()我们这样去尝试读取文件中前两个字符,运行时却报错了。
![]()
这是关于一个字符编码的问题,在我们的代码中,我们要尝试读取一个中文。中文和英文类似,在计算机中都是使用 "数字" 来表示字符的,但是具体时那个数字对应哪个汉字,在计算机中有多个版本,现在最主流的版本有两个,一个是 GBK,另一个是 UTF8。我们在实际开发时就需要保证,文件内容的编码方式和代码中操作文件的编码方式匹配。
所以我们得先确认一下我们文件的编码格式。
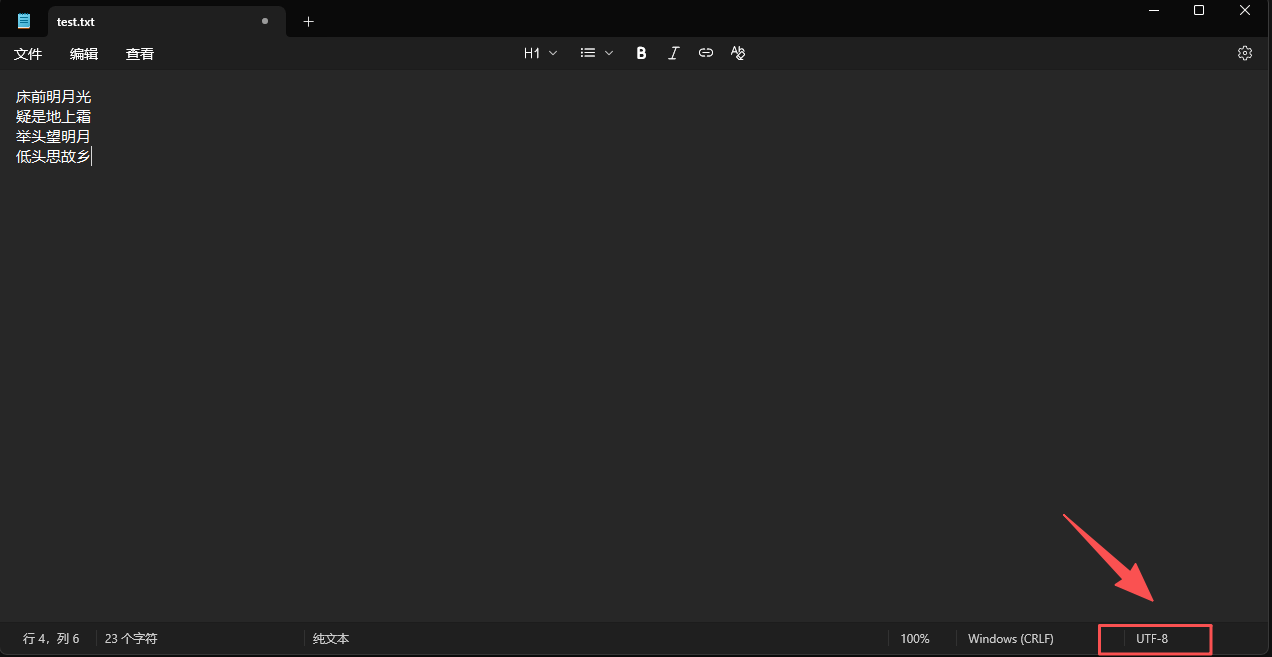
所以我们可以看到我们的格式是 UTF8,所以我们得让我们代码中按照 UTF8 来解析,但是代码中默认是GBK,所以就会报错。当然,相比于 GBK,UTF8 是使用的更广泛的编码方式。
我们在 open 后面再加一个 encoding = 'utf8' 即可。
# 使用 read 读取文件内容,指定读取几个字符
f = open('d:/Python环境/test.txt', 'r', encoding = 'utf8')
result = f.read(2)
print(result)
f.close()我们前面两个是位置参数,而 encoding 是关键字参数,这里就能够看到我们位置参数和关键字参数是可以混着用的。
![]()
如果文件是多行文本,可以使用 for 循环一次读取一行。
f = open('d:/Python环境/test.txt', 'r', encoding = 'utf8')
for line in f:print(f'line = {line}')
f.close()此处的 line 是我们创建的一个局部变量,它表示我们文件中每一行的内容,第一次循环就对应第一行,第二次循环就对应第二行以此类推,直到读完循环就结束了。

但是我们发现打印的时候行与行之间带了一个空行。之所以多了一个空行是因为本来读到的文件内容的末尾就带有换行符(\n)。此处使用 print 打印又会自动加一个换行符(\n)。
我们可以给 print 再多设定一个参数,修改 print 自动换行的行为。
f = open('d:/Python环境/test.txt', 'r', encoding = 'utf8')
for line in f:print(f'line = {line}', end = '')
f.close()此时我们 end 参数就表示我们每打印一次就要在末尾加一个什么,默认是换行符(\n)。

我们还可以使用 readlines 方法直接把整个文件所有内容都读出来,按照行组织到一个列表里。
f = open('d:/Python环境/test.txt', 'r', encoding = 'utf8')
lines = f.readlines()
print(lines)
f.close()![]()
四、上下文管理器
我们写代码时,还是很容易忘记我们的文件的,所以为了确保我们的关闭可以及时有效的进行,Python 就引入了上下文管理器来帮助我们解决容易忘记关闭的问题。
有的时候我们很难避免不会忘记关闭文件。
def func():f = open('d:/Python环境/test.txt', 'r', encoding='utf8')# 中间代码中如果有条件判断,函数返回,抛出异常等if cond:# 进行条件处理return# 另外一些代码f.close()此时我们就有可能造成内存泄漏。
此时我们使用上下文管理器就能解决这个问题
def func():with open('d:/Python环境/test.txt', 'r', encoding = 'utf8') as f:# 进行文件处理的逻辑if cond1:returnif cond2:return我们通过 as 赋值,此处的 f 仍然是 open 的返回值,但是已经被 with 监控起来了。此时我们不管有多少个 return 都没有关系了,因为只要我们结束了下面的 with 的代码块,我们 with 就会自动调用 close 去释放资源。
这样就可以避免资源的泄露。
总结
以上便是我们文件的基本操作,通过本章学习,我们就可以明白我们计算机的内存和外存该如何交互,以及我们在使用一些数据时计算机是怎么保存我们的数据的,大家下去可以在 Python 库中学习更多的内容,当然基础也得好好吸收。
🎇坚持到这里已经很厉害啦,辛苦啦🎇
ʕ • ᴥ • ʔ
づ♡ど
