Transformer核心—自注意力机制
Transformer基础—自注意力机制
当我们处理文本、语音这类序列数据时,总会遇到一个老问题:模型到底该怎么理解“前后文”呢?
RNN 和 LSTM 曾经是热门的答案,它们沿着时间顺序一点点地读数据,但读得太慢,还容易忘记前面的信息。后来 CNN 被搬了进来,靠卷积核抓住局部模式,可要想看远处的信息,就得堆一大堆层,效率也不高。
于是研究者开始换个思路:如果模型能直接跳过中间环节,把注意力放到序列中真正相关的位置,不是更聪明吗? 这就是注意力机制的出发点。而当这种机制被应用到同一个序列内部时,就诞生了今天大名鼎鼎的——自注意力机制(Self-Attention)。
一、基本概念
什么是自注意力机制?
自注意力机制就是找到序列当前词与序列所有词之间的关系,也就是说我们的模型要知道这个词“是谁”、“在哪”。
当我们说“模型要知道这个词是谁、在哪、该关注谁”时,其实就需要一种可计算的方式来衡量词和词之间的关系。
这时候就引出了自注意力的三大主角:Q(查询向量:Query)、K(键向量:Key)、V(值向量:Value)。
我们知道:在传统的 RNN 模型里,每个词都会被转化成一个 词向量(Embedding),这个向量基本上就代表了“这个词是谁”。RNN 会把这些向量按照顺序依次读入,再结合隐状态去理解上下文。
但在自注意力机制中,研究者觉得:光有一个词向量还不够。如果我们想让模型判断“这个词应该关注谁”,就得从不同角度去看待它。
于是,同一个词的词向量会被投影成三份不同的表示:
- Q(Query):我去发起“提问”,看看我应该关心哪些词;
- K(Key):我拿出自己的“身份标签”,告诉别人“我是什么”;
- V(Value):我还准备了一份“内容”,如果有人关注我,就把这份内容贡献出来。
这样一来,词嵌入不再只是一个“静态身份”,而是被拆解成查询、标识和内容三种角色,从而让模型能够灵活地建立联系。
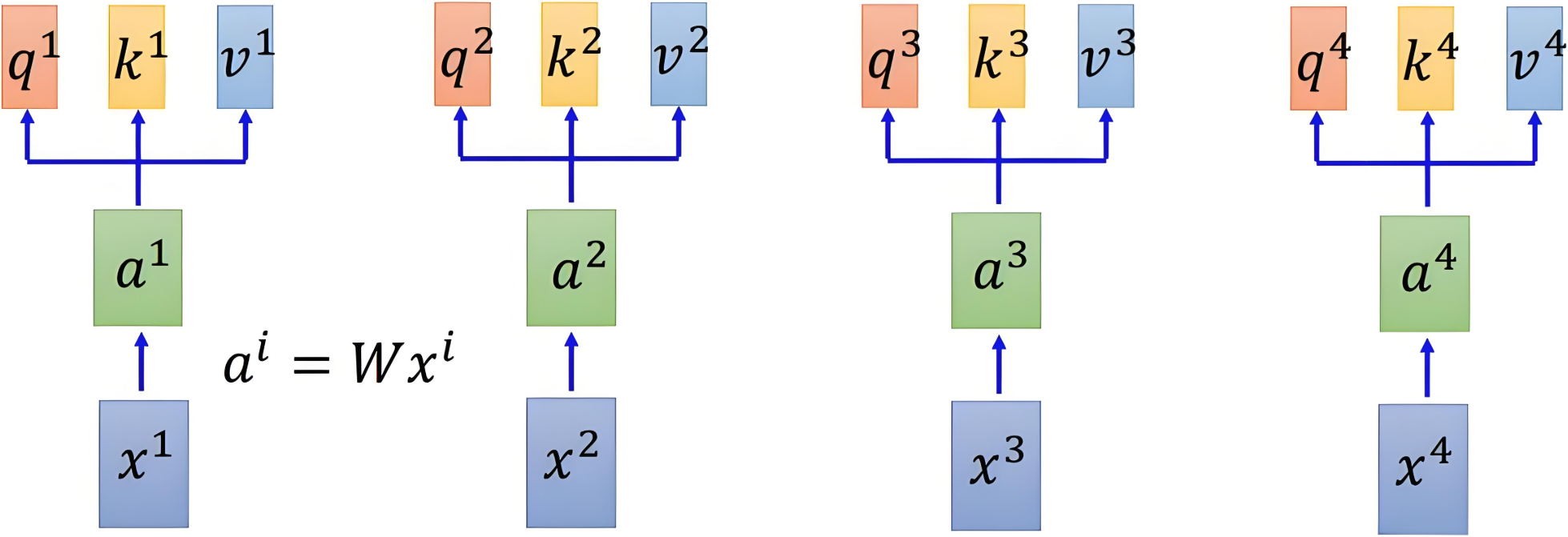
我们能够理解为:我们将一个词最开始的一个词向量进行了三次线性变换(也就是乘上三个不同的矩阵),得到的结果就是Q、K、V,他们都是这个这个词得词向量。
虽然一个词从最开始的一个词向量变为了三个词向量,但是这三个词向量仅仅只是表示这一个词,没有和上下文建立联系,那么我们是如何实现上下文联系的呢?
二、实现过程
1.计算注意力得分
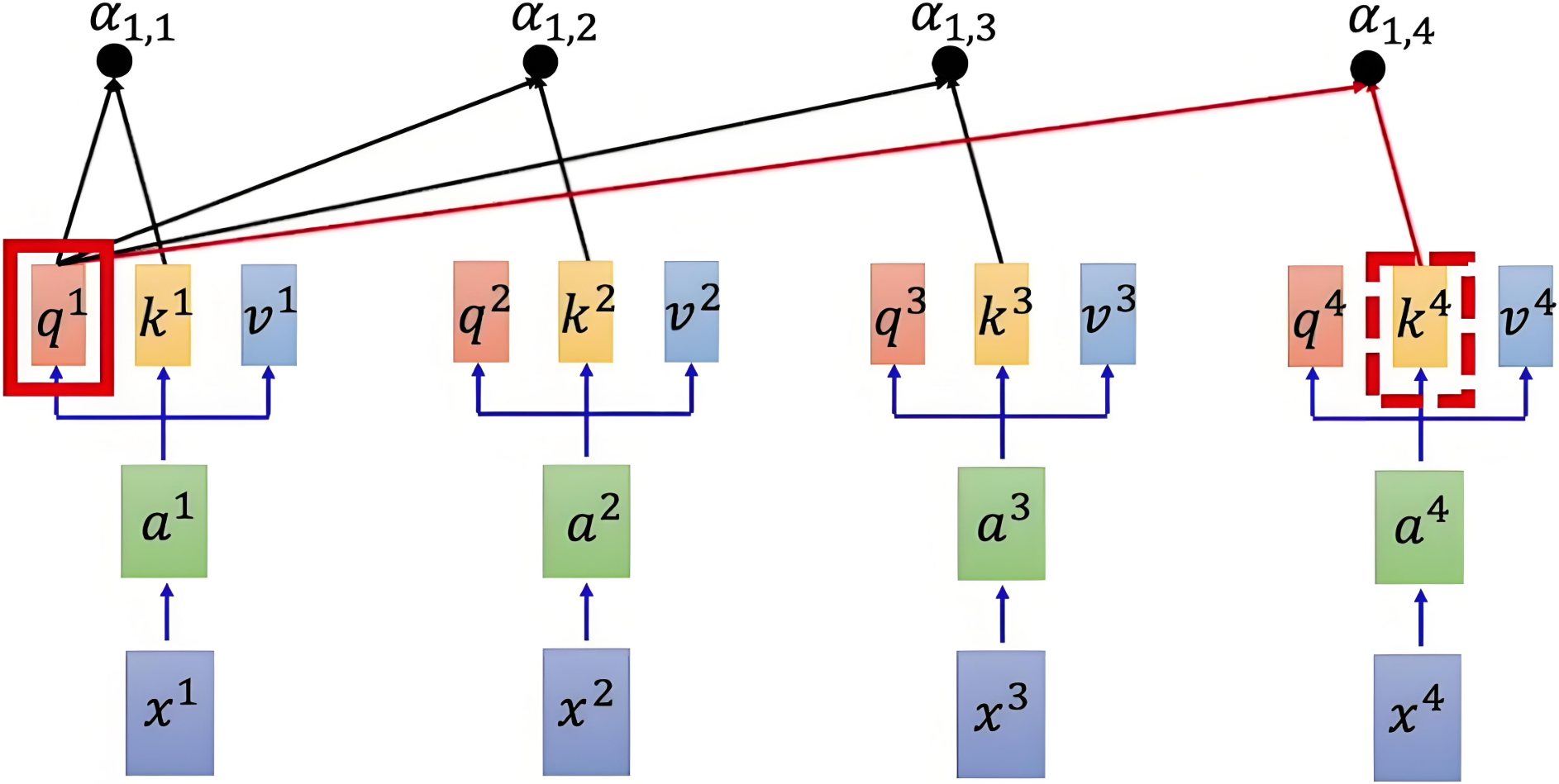
我们将序列当前词的Q向量与序列任何一个词的K向量做点积,得到的这个值能够作为当前词与另外一个词的相似度判断依据,值越大,说明这两个词越相似,但是数值可能会过大,所以需要引入一个缩放因子限制数值大小,使得梯度能够稳定更新。因此就有了注意力得分矩阵公式:
Attention(Q,K)=QKTdk
\text{Attention}(Q, K) = \frac{QK^T}{\sqrt{d_k}}
Attention(Q,K)=dkQKT
这个矩阵的形状为n×nn\times nn×n,其中n表示的是序列的长度,矩阵中的元素(i,j)(i,j)(i,j)表示序列第iii个元素与第jjj个元素的注意力得分,也就是它们的相似度。
图示:
 |
|---|
| 得到QKV向量 |
 |
|---|
| 计算第一个词和序列中所有词的每个注意力得分α1,i=q1⋅kidk\alpha_{1,i} = \frac{q^1 \cdot k^i}{\sqrt{d_k}}α1,i=dkq1⋅ki |
2.归一化
我们要将得到的注意力得分转换为概率分布,即将值得范围控制在[0,1]之间,这个想法我们可以通过softmaxsoftmaxsoftmax函数得到实现,并且它确保了每一行的权重和为1,也就是一个词对于序列所有词的注意力权重之和为1。(注意:计算注意力得分和权重的时候,包括词自己本身,也就是用某个词的Q向量去乘上自己的V向量)
Attention Weight=softmax(QKTdk)
\text{Attention Weight} = \text{softmax} \left( \frac{QK^T}{\sqrt{d_k}} \right)
Attention Weight=softmax(dkQKT)
3.加权求和
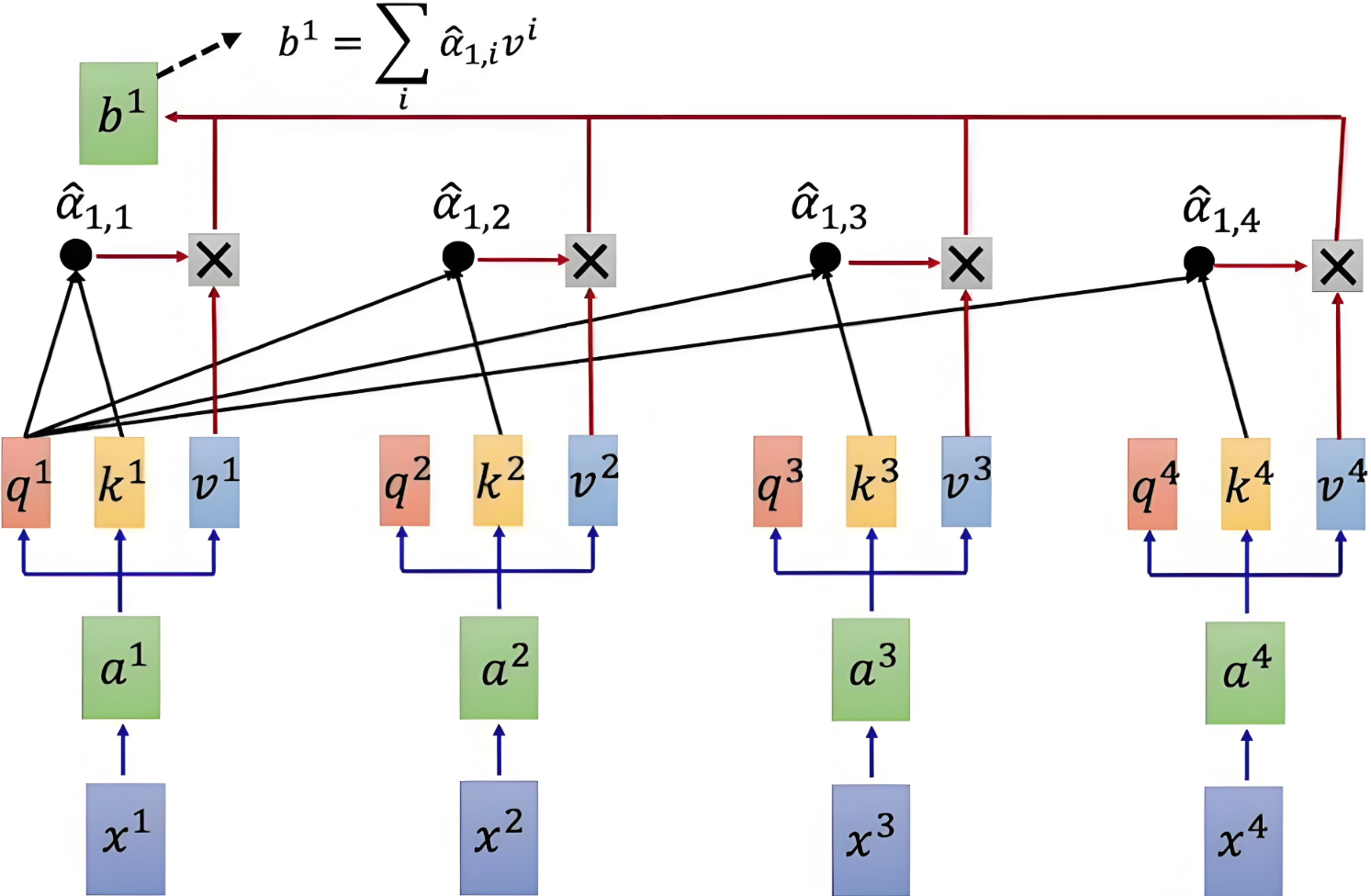
得到了每个词对于序列的注意力权重矩阵之后,接下来就是与V矩阵进行相乘,进行加权求和,最终得到的就是带有上下文联系的词向量。
Output=Attention Weight×V=softmax(QKTdk)×V
\text{Output} =\text{Attention Weight} \times V = \text{softmax} \left( \frac{QK^T}{\sqrt{d_k}} \right) \times V
Output=Attention Weight×V=softmax(dkQKT)×V
计算图示意:
 |
|---|
| Q和K计算相似度后,经 softmaxsoftmaxsoftmax 得到注意力,再乘V,最后相加得到包含注意力的输出 |
三、多头注意力
现在我们已经知道了什么是自注意力机制,那么接下来介绍以下自注意力机制的拓展,也就是transformer所真正运用到的注意力机制——多头注意力机制
多头注意力机制顾名思义,将注意力机制中的Q、K、VQ、K、VQ、K、V向量分成了多个“头”,也就是分成了nnn个组,每个组算出各自的注意力结果,然后将每组的输出进行拼接,最后再通过线性变换(乘上一个权重矩阵做特征融合)得到最终的输出。
【这种思路类似于CNN中的分组卷积】
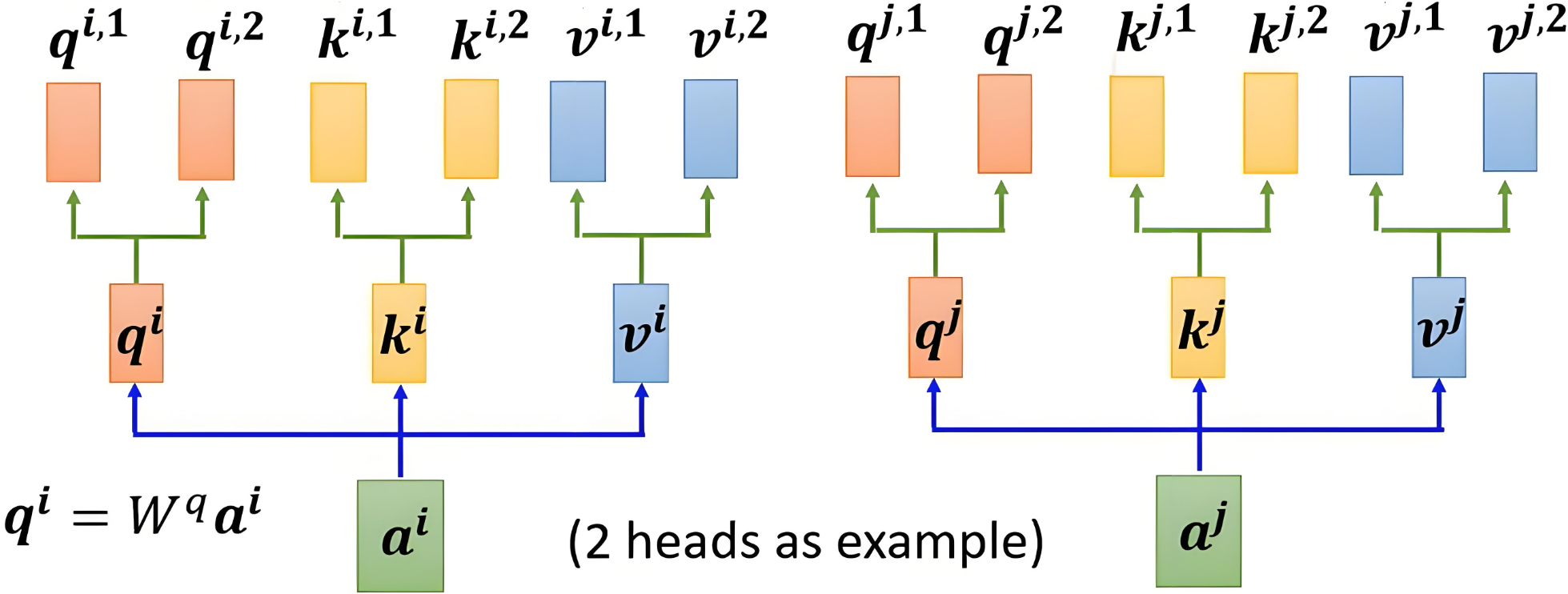
比如将一个512维度的词分为2个组(也就是两个头),那么每组QKV向量的维度就应该是256维度,一共有两组QKV。
 |
|---|
| aia^iai和aja^jaj为两个不同的词,他们分别有两组QKV向量 |
多头注意力的目的
总的来说,多头注意力的目的就是为了提高模型的表达能力。我们可以用多组注意力去关注这个词的不同特征,比如一个词有32组注意力,那么一组可以是表示这个词的情感特征、一组表示这个词的词法特征、一组表示这个词的词性特征等等…
这就让我们的模型学习到了更多的上下文信息,能够在不同场景下表达合适的意思,也就是更有语境。
PyTorch封装好的多头注意力层nn.MultiheadAttention:
import torch
import torch.nn as nnmultihead_atten_layer = nn.MultiheadAttention(embed_dim=512,num_heads=8,batch_first=True
)
embedding_layer = nn.Embedding(10, 512)
X = torch.randint(0, 10, (1, 10))X = embedding_layer(X)atten_out, atten_weights = multihead_atten_layer(# 内部自动用可学习的 W^Q, W^K, W^V 把 X 投影成 QKVquery=X,key=X,value=X,
)# 打印注意力得分以及权重矩阵
print(atten_out.shape, atten_weights.shape)# torch.Size([1, 10, 512]) torch.Size([1, 10, 10])以上是博主对transformer注意力机制的一些总结笔记,若文章中出现错误请及时指正博主,感谢浏览☆噜~☆