目标检测双雄:一阶段与二阶段检测器全解析
在计算机视觉的江湖里,目标检测(Object Detection)就像是一位"全能侦探"——既要认出画面中的物体(分类),又要精准定位它们的位置(定位)。而在这场"侦探大赛"中,一阶段检测器和二阶段检测器如同两大门派,各有绝学。今天我们就用最通俗的方式,揭开它们的神秘面纱!
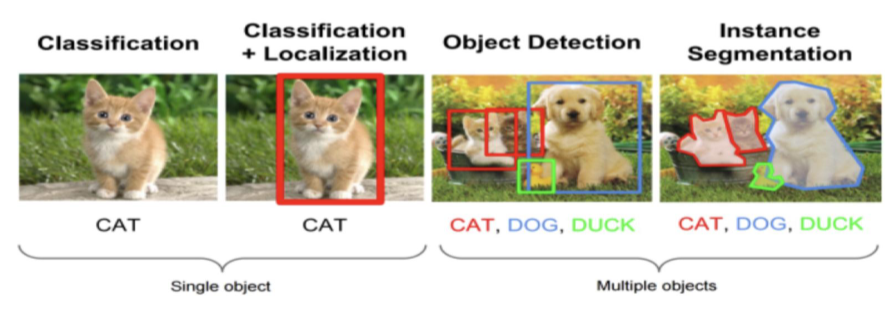
🐢什么是目标检测?
目标检测是计算机视觉中的一项重要技术,它的任务是从图像或视频中找出感兴趣的目标,并检测出它们的位置和大小。
与简单的图像分类不同,目标检测需要同时解决两个问题:物体识别(分类) 和物体定位(边界框回归)。这就好比不仅要认出图片中有猫和狗,还要用框标出它们各自在什么位置。
🌈一阶段检测器:速度与激情的代表
🏎️核心思想:"一步到位"
想象你是一名赛车手,目标检测就是要在赛道上快速识别并标记所有车辆。一阶段检测器就像一位"极速车手",直接在整张图片上同时预测所有物体的类别和位置,无需先生成候选区域(Region Proposal)。
以YOLO算法为例,利用整张图作为网络的输入,直接在输出层回归 bounding box(边界框) 的位置及其所属的类别。如下图:
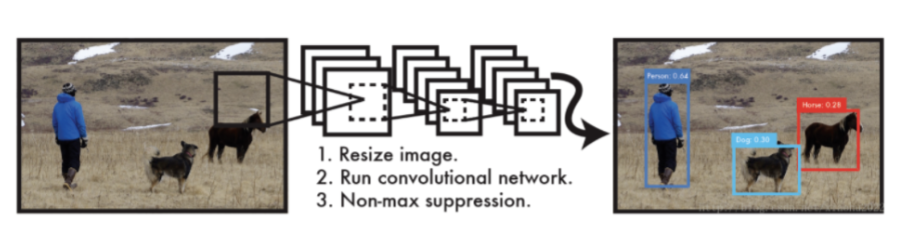
💡经典代表:YOLO系列、SSD、RetinaNet
YOLO(You Only Look Once):
🔥 名字就透着霸气!它将图片划分为网格,每个网格直接预测边界框和类别概率。最新版YOLOv10甚至去掉了后处理NMS,速度更快!
📊 特点:速度快(实时检测)、结构简单,但小目标检测稍弱。SSD(Single Shot MultiBox Detector):
🎯 通过多尺度特征图检测不同大小的物体,像"撒网捕鱼"一样覆盖全图。
📊 特点:平衡速度与精度,适合中等规模目标。RetinaNet:
🎯 引入Focal Loss解决正负样本不均衡问题,让检测器更关注难样本。
📊 特点:精度高,尤其适合复杂场景。
🚀优势与局限
- ✅ 优势:速度快(适合实时应用,如自动驾驶、视频监控)。
- ❌ 局限:对小目标、密集目标的检测精度略低。
🛡️二阶段检测器:精度至上的匠人
🔍核心思想:"先筛选,再精修"
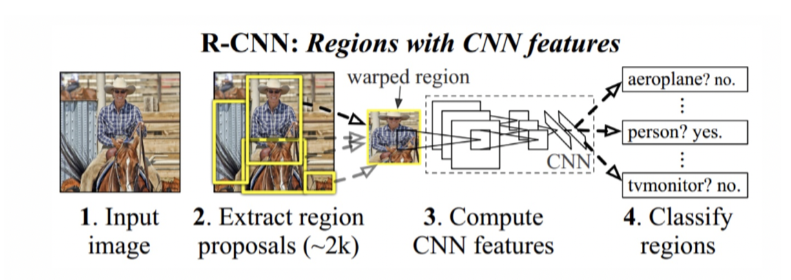
二阶段检测器像一位"匠人",先通过区域提议网络(RPN)生成一堆候选区域(可能包含物体的区域),再对这些区域进行精细分类和位置调整。
下图为R-CNN流程图,先在检测的图片中找出2000个可能存在目标的候选区域。使用CNN提取候选区域的特征向量。通过训练的支持向量机(SVM)来辨别目标物体和背景。最后通过线性回归模型为每个辨识到的物体生成精确的边界框。
💡经典代表:R-CNN系列、Faster R-CNN、Mask R-CNN
R-CNN(Region-based CNN):
📜 开山之作!先用选择性搜索(Selective Search)生成2000个候选区域,再用CNN提取特征,最后用SVM分类。
📊 特点:精度高,但速度慢(一张图片需47秒!)。Faster R-CNN:
⚡ 改进版!用RPN替代选择性搜索,速度提升10倍!
📊 特点:精度与速度的平衡,成为工业界主流。Mask R-CNN:
🎨 在Faster R-CNN基础上增加实例分割分支,能同时检测物体并勾勒出精确轮廓。
📊 特点:适合需要高精度定位的任务(如医疗影像分析)。
🛡️优势与局限
- ✅ 优势:精度高(尤其小目标、复杂场景)。
- ❌ 局限:速度慢(难以实时应用),结构复杂(调试难度大)。
🔥一阶段 vs 二阶段:如何选择?
| 维度 | 一阶段检测器 | 二阶段检测器 |
|---|---|---|
| 速度 | 快(实时检测) | 慢(非实时) |
| 精度 | 中等(小目标稍弱) | 高(复杂场景优势明显) |
| 适用场景 | 自动驾驶、视频监控、移动端 | 医疗影像、工业检测、安防分析 |
| 代表模型 | YOLO、SSD、RetinaNet | Faster R-CNN、Mask R-CNN |
🌌未来趋势:融合与超越
近年来,研究者们开始尝试融合一阶段与二阶段的优势:
- ATSS:揭示锚框(Anchor)与无锚框(Anchor-free)检测器的本质差异在于正负样本定义方式。
- DETR:基于Transformer的端到端检测器,直接输出预测结果,无需NMS后处理。
- EfficientDet:通过复合缩放(Compound Scaling)平衡速度与精度,成为新一代"全能选手"。
📌总结
- 选一阶段:如果你需要实时检测(如自动驾驶、直播监控),或资源有限(移动端、嵌入式设备)。
- 选二阶段:如果你追求极致精度(如医疗诊断、精密制造),或目标尺寸差异大、背景复杂。
目标检测的江湖永远在进化,无论是速度派还是精度派,最终目标都是让机器"看"得更清楚、更智能!
互动时间:你更看好一阶段还是二阶段检测器?欢迎在评论区留言讨论!💬