【LLM】使用 Transformer 强化学习的 GRPO
🔎大家好,我是Sonhhxg_柒,希望你看完之后,能对你有所帮助,不足请指正!共同学习交流
🔎
📝个人主页-Sonhhxg_柒的博客_CSDN博客 📃
🎁欢迎各位→点赞👍 + 收藏⭐️ + 留言📝
📣系列专栏 - 机器学习【ML】 自然语言处理【NLP】 深度学习【DL】
🖍foreword
✔说明⇢本人讲解主要包括Python、机器学习(ML)、深度学习(DL)、自然语言处理(NLP)等内容。
如果你对这个系列感兴趣的话,可以关注订阅哟👋
了解 HuggingFaces 的 TRL 如何实现 GRPO 和自定义奖励函数
一、介绍
大型语言模型(LLM)最初的应用主要聚焦于海量数据训练,帮助各机构构建基础模型。近年来,随着训练后优化技术的突破,LLM性能得到显著提升,特别是在推理能力方面,即便在参数受限的情况下也能出色发挥。DeepSeek就是典型代表,其推理表现甚至超越了ChatGPT等知名模型。虽然影响因素众多,但强化微调技术GRPO(组相对策略优化)发挥了关键作用。本文将深入探讨:
- LLM发展的关键阶段
- GRPO在LLM训练中的核心作用
- GRPO提升推理能力的内在机制
- GRPO的简易实现及效果评估
二、LLM训练阶段
下图展示了 LLM 的简化训练流程
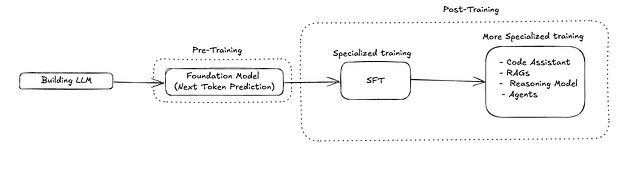
2.1、预训练(PT)
预训练包括在大量数据语料库上训练 LLM,最终目标是预测下一个 token。它会爬取大量的维基百科页面、文章、博客以及更多在线资料。这有助于模型理解文本中的模式,例如句子结构、语法、句法和词语关系。
2.2、监督微调(SFT)
预训练确实有助于模型理解大型语料库中存在的模式,但它也有一些局限性,例如无法执行特定任务、无法遵循用户提供的指令、模型会存在数据内部的偏见。
为了克服这些限制,模型必须经历监督微调 (SFT) 阶段,在此阶段,模型将基于有限的专家数据(即人工筛选的数据)进行训练,这些数据规模有限,但信息量巨大。监督微调模型将学习各种任务,例如摘要、问答、完成句子以及其他一些遵循指令的任务。
2.3、专业化训练
尽管模型的专业化进程主要始于监督微调(SFT)阶段——此时模型学习如何遵循用户指令或完成特定任务,但该阶段仍可能导致模型出现轻微偏差、行为不一致或响应格式不规范等问题。在处理系统设计、数学求解或多步骤规划这类复杂且结构化的任务时,模型的推理能力尤为重要。此时,思维链(CoT)提示等技术就展现出其独特价值:不仅能辅助模型得出正确答案,还可帮助用户验证大语言模型(LLM)的响应质量。
为进一步优化模型表现,我们可以采用强化学习(RL)等高级技术。这类方法通过基于人类偏好反馈或任务特定奖励信号来优化模型输出。本文将重点探讨一种基于奖励的RL方法——组相对策略优化(GRPO),并对其原理和应用进行深入解析。
2.4、基于奖励的强化学
强化学习 (RL) 主要帮助 LLM 以尽可能大的奖励实现主要目标。该奖励可以以适当的格式输出,遵循任何特定规则,或在响应中具有适当的相关性和正确性。
传统的基于奖励的强化学习模型主要通过选择离散步骤还是连续步骤来实现目标,并尽可能获得最大奖励。而 LLM 拥有海量的词汇,它必须从中选择一个 token 才能获得最高奖励。
简化的 RL 流程主要采用 3 个阶段循环,直到损失收敛
- 定义奖励函数——创建一个奖励函数,为每个输出生成一个分数。输出的期望响应越高,其奖励分数就越高。例如,对于摘要任务,响应越精确,其分数就越高。
- 使用强化学习进行微调——一旦确定了奖励函数,LLM 模型就会使用该奖励函数进行微调。对于每个响应,都会根据响应的期望程度生成奖励分数,并根据该奖励分数更新模型权重。这是进行探索和利用的阶段。
- 反馈循环——根据奖励分数,模型进行更新,并且此循环持续进行,直到损失收敛。
2022 年,在 ChatGPT 中,RLHF 与 PPO 的结合展现了 RL 的潜在应用,而 PPO 的一个变体 GRPO 则进一步推进了这一应用。下图展示了 PPO 和 GRPO 的架构。现在,让我们深入探讨一下。
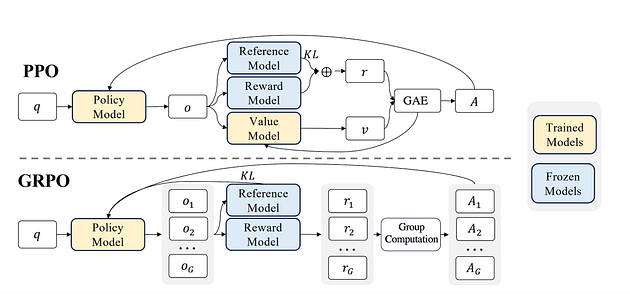
让我们分解上图中的每个组件。并比较一下 GRPO 与 PPO 的区别。
| 策略模型 (Policy Model) | - 正在训练的主要模型,针对问题 (q) 生成输出 (o)。 - 在 GRPO 中,针对每个问题 (q),它会生成一组输出 (Og)。 |
|---|---|
| 参考模型 (Reference Model) | - 原始预训练模型的冻结副本。用于计算 KL 散度,以防止策略模型与原始预训练模型偏离过多。 |
| 奖励模型 (Reward Model) | - 当用户对 LLM 的响应提供反馈时,这些反馈会被存储并用于训练一个称为奖励模型的模型。该模型进一步用于为 LLM 生成的输出打分。 - 在 GRPO 中,会对策略模型的每个输出生成一个奖励 (rg),这通常通过一个奖励函数来完成。 |
| 价值模型 (Value Model) | - 与策略模型一同训练,用于估计预期奖励 (v)。用于计算优势值 (A)(即一个响应比预期好多少)。 |
| KL 散度 (KL) | - 一种数据漂移计算技术,在这里充当正则化器。它避免最终模型与原始模型偏离过多。 |
| 优势值 (Advantage, A) | - 在 PPO 和 GRPO 中都会计算优势值。对于 PPO,由于只有一个输出,因此计算一个优势值;对于 GRPO,则为每个输出计算优势值。唯一的区别是:PPO 的优势值基于奖励和价值计算,而 GRPO 的优势值基于组内响应的相对性(即奖励被归一化)来计算。 |
| 组计算 (Group Computation) | - 这是 GRPO 中的一个附加部分,其中每个输出都会有一个奖励分数。这些分数在组内进行比较,并计算相对优势。这有助于策略模型根据排名较高的响应进行更新,从而增加排名最高输出的概率,并抑制排名较低的输出。 |
三、TRL中的GRPO实现
GRPO 是使用开源TRL(Transformer 强化学习)实现的,它提供了用于监督微调、GRPO、DPO 以及更多 LLM 后期训练支持的工具包。在本博客中,我们将使用这个开源软件包,通过 GRPO 方法对语言模型进行微调。
3.1、使用 GRPO 训练基础模型
在GRPO中,奖励函数是塑造模型行为的关键,这与SFT中使用的真实标签不同。奖励函数接收模型输出并返回一个数值分数,该分数表示LLM响应的质量。一般而言,奖励值越高,LLM响应的质量就越好。
以下是一个示例,其中Qwen指令模型使用GRPO进行微调,以生成大约200个字符长的输出。我们使用TLDR(太长不读)Reddit数据集进行微调。理想情况下,该模型应首先在TLDR数据集上进行监督微调(SFT),然后使用GRPO来控制输出长度。然而,为了简单起见,在本博客中我们将仅重点介绍应用GRPO。
# train_grpo.py
from datasets import load_dataset
from trl import GRPOConfig, GRPOTrainer## 将数据样本作为对完整数据的调优需要花费大量时间
dataset = load_dataset("trl-lib/tldr", split="train[:75]")def format(example):"""Changing the prompt of dataset"""return {"prompt": f"Summarize: {example['prompt']}\n\n"}dataset = dataset.map(format)# Reward function: closer to 200 characters = better
def reward_len(completions, **kwargs):rewards = [-abs(200 - len(c)) for c in completions]return rewardsoutput_dir="Qwen2-0.5B-GRPO"
model_name = "Qwen/Qwen2-0.5B-Instruct"training_args = GRPOConfig(## 更新策略模型的步长learning_rate=1e-5,## 将最终优化的模型保存在此目录中output_dir=output_dir, ## 每10步后打印日志logging_steps=10, ## 控制LLM响应的随机性temperature = 0.8, ## KL散度用于定义模型应偏离参考模型的程度epsilon = 0.2,## 每25步保存一次模型检查点save_steps = 25 )
trainer = GRPOTrainer(model=model_name,reward_funcs=reward_len,args=training_args,train_dataset=dataset
)
trainer.train()# 保存模型权重
trainer.model.save_pretrained(output_dir)# 再次保存原始配置(可选但有用)
from transformers import AutoConfig
config = AutoConfig.from_pretrained(model_name)
config.save_pretrained(output_dir)reward_len 函数输出的一些示例
| Output Length (len(c)) | Calculation | Reward Score |
|------------------------|---------------------------|--------------|
| 100 | -abs(200 - 100) = -100 | -100 |
| 150 | -abs(200 - 150) = -50 | -50 |
| 180 | -abs(200 - 180) = -20 | -20 |
| 195 | -abs(200 - 195) = -5 | -5 |
| 200 | -abs(200 - 200) = 0 | 0 |
| 205 | -abs(200 - 205) = -5 | -5 |
| 220 | -abs(200 - 220) = -2 | -20 |
| 250 | -abs(200 - 250) = -50 | -50 |
| 300 | -abs(200 - 300) = -100 | -100 |以下是一些自定义奖励函数的示例
# 示例1:
# 惩罚有害性反应,使模型反应更加公正和无害
from detoxify import Detoxifytox_model = Detoxify("original")def reward_toxicity(completions, **kwargs):toxicities = tox_model.predict(completions)['toxicity']return [-t for t in toxicities] # Less toxic = higher reward# 示例2:
# 训练,使LLM响应采用特定格式
# 这有助于模型提供统一的响应格式。可以根据我们的用例进行定制
import redef format_reward_func(completions, **kwargs):"""奖励功能,检查完成是否具有特定格式。"""pattern = r"^<think>.*?</think><answer>.*?</answer>$"completion_contents = [completion[0]["content"] for completion in completions]matches = [re.match(pattern, content) for content in completion_contents]return [1.0 if match else 0.0 for match in matches]与上述类似,我们可以构建并使用许多奖励函数来将 LLM 的行为塑造成我们期望的响应。这些多个奖励函数可以传递给单个模型,以改变其行为。
3.2、将 GRPO 训练的 Qwen 模型与基础模型进行比较
现在,让我们比较一下普通 Qwen 模型和 GRPO 微调 Qwen 模型的输出长度,下面是代码和输出
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
from datasets import load_dataset# 采集数据样本
dataset = load_dataset("trl-lib/tldr", split="train[1000:1010]")# Format: prompt -> input_text, completion -> target_text
def format(example):return {"prompt": f"Summarize: {example['prompt']}\n\n"}# 用一个恰当的提示词来总结一个句子
dataset = dataset.map(format)# Reload the fine-tuned model
model_name = "Qwen/Qwen2-0.5B-Instruct"
model_path = "./Qwen2-0.5B-GRPO_200/checkpoint-100"tokenizer = AutoTokenizer.from_pretrained(model_name)
grpo_model = AutoModelForCausalLM.from_pretrained(model_path)
pt_model = AutoModelForCausalLM.from_pretrained(model_name)# 确保标记器配置仍然兼容
tokenizer.pad_token = tokenizer.eos_token
grpo_model.config.pad_token_id = tokenizer.pad_token_id
pt_model.config.pad_token_id = tokenizer.pad_token_idgrpo_model.eval()
pt_model.eval()
i = 1for prompt in dataset:inputs = tokenizer(prompt['prompt'], return_tensors="pt").to(grpo_model.device)with torch.no_grad():grpo_outputs = grpo_model.generate(**inputs,max_new_tokens=300,do_sample=False,)pt_outputs = pt_model.generate(**inputs,max_new_tokens=300,do_sample=False,)# 仅解码新生成的部分grpo_text = tokenizer.decode(grpo_outputs[0][inputs.input_ids.shape[-1]:], skip_special_tokens=True)pt_text = tokenizer.decode(pt_outputs[0][inputs.input_ids.shape[-1]:], skip_special_tokens=True)print(f"\n==== Prompt {i} ====\n")print(f"(Length: {len(grpo_text)} characters)")print(f"(Length: {len(pt_text)} characters)")i += 1输出
==== Prompt 1 ====(Length: 134 characters)
(Length: 1283 characters)==== Prompt 2 ====(Length: 150 characters)
(Length: 305 characters)==== Prompt 3 ====(Length: 109 characters)
(Length: 1233 characters)==== Prompt 4 ====(Length: 206 characters)
(Length: 986 characters)==== Prompt 5 ====(Length: 216 characters)
(Length: 801 characters)==== Prompt 6 ====(Length: 157 characters)
(Length: 945 characters)==== Prompt 7 ====(Length: 179 characters)
(Length: 1247 characters)==== Prompt 8 ====(Length: 339 characters)
(Length: 1006 characters)==== Prompt 9 ====(Length: 117 characters)
(Length: 970 characters)==== Prompt 10 ====(Length: 156 characters)
(Length: 880 characters)输出显示,GRPO根据reward_len函数改变了模型的行为,即将LLM的输出保持在约200个字符左右,我们可以通过将其与上述模块中经过指令调优的Qwen模型进行比较来观察到这种差异。
3.3、GRPO TRL 代码
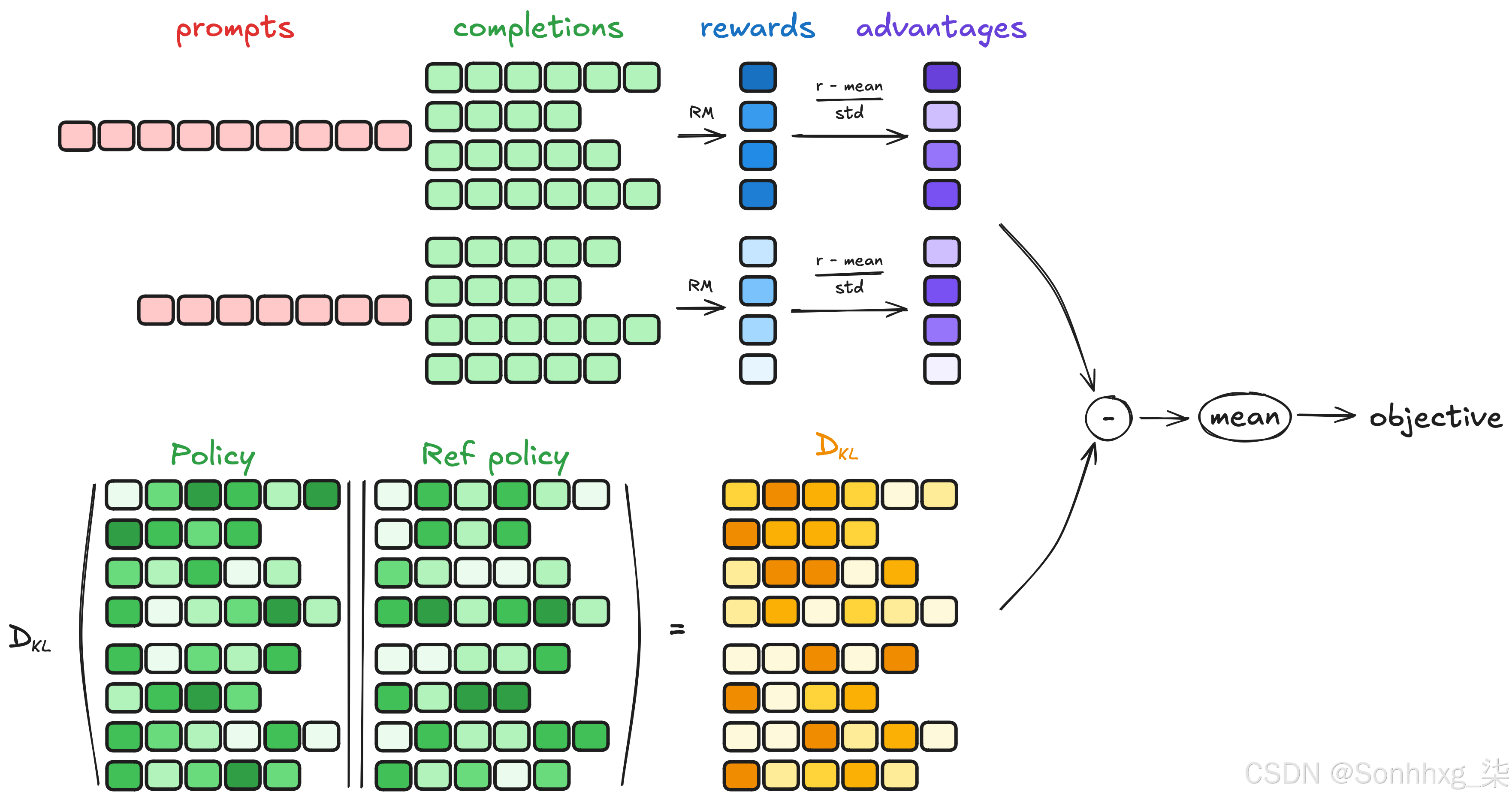
该Github仓库曾用于上述GRPO训练,通过浏览代码片段将大大有助于理解。在本篇博客中,我们将涵盖代码最重要的部分——损失函数的计算。但在深入理解之前,建议先通过这篇博客掌握损失计算的基础知识。
输入:
- prompt_ids(提示词ID)、completion_ids(生成文本ID):来自输入提示和生成文本的词元ID
- prompt_mask(提示掩码)、completion_mask(生成掩码):标识真实(非填充)词元的注意力掩码
- advantages(优势值):根据奖励计算的每个样本的优势值
- old_per_token_logps(旧策略对数概率):旧策略产生的词元级对数概率
- ref_per_token_logps(参考策略对数概率,可选):参考策略模型产生的词元级对数概率
- β(beta):KL散度正则化权重
- ε_low、ε_high:策略比例的裁剪阈值
- loss_type(损失类型):决定损失聚合策略('grpo'、'bnpo'或'dr_grpo')
- π_θ(当前策略模型)
步骤1:准备输入
- 拼接提示词ID和生成文本ID形成完整输入序列
- 同样拼接完整序列的注意力掩码
步骤2:计算模型输出
- 将完整输入序列输入当前模型
- 提取词元级对数概率,但仅保留生成文本部分
步骤3(可选):计算KL散度
- 若beta不为零:
- 使用参考模型的对数概率计算词元级KL散度
- KL = exp(参考对数概率 - 模型对数概率) - (参考对数概率 - 模型对数概率) - 1(详情参阅)
步骤4:计算策略比例并应用裁剪
- 计算新旧策略比例:比例 = exp(当前对数概率 - 旧对数概率)
- 将比例裁剪到[1 - ε_low, 1 + ε_high]区间
步骤5:计算词元级损失
- 计算两个候选损失:
- 使用未裁剪比例计算的损失
- 使用裁剪后比例计算的损失
- 对每个词元选择较小值
- 若beta不为零,向词元损失添加KL散度项
步骤6:根据策略聚合总损失(可选策略:['grpo', 'bnpo', 'dr_grpo'])
步骤7:计算并记录指标
- 若计算过KL散度,记录平均KL散度
- 跟踪被裁剪比例的词元数量:
- 低裁剪:比例 < 1 - ε_low 且 优势值 < 0
- 高裁剪:比例 > 1 + ε_high 且 优势值 > 0
- 区域裁剪:任意被裁剪的词元
- 记录这些裁剪比例的均值、最小值、最大值用于分析
输出:
- 返回最终标量损失值用于训练
四、结论
群体相对策略优化(GRPO)在语言模型微调领域迈出了重要一步,尤其适用于通过相对反馈提升推理能力、响应排序或输出质量。
该技术的优势在于:既能处理相对反馈,又通过KL正则化限制与基础模型的偏离,同时还支持多输出推理,因此非常适合改进大型语言模型的复杂行为(如推理与决策)。
从DeepSeek等模型及TRL系列实验可见,相比其他技术,GRPO能以极低计算成本实现显著提升。这项技术使研究者和实践者能够优化大型语言模型,生成更优质的响应。