AI应用开发-技术架构 PAFR介绍
介绍
PAFR 是一个综合性的 AI 应用开发技术架构,由纯 Prompt 问答(Prompt)、Agent + Function Calling、Fine - tuning、RAG(Retrieval Augmented Generation)四个核心部分构成。每个部分都在 AI 应用开发中扮演着独特且关键的角色,它们相互协作,共同推动 AI 应用实现更智能、更高效、更精准的功能。
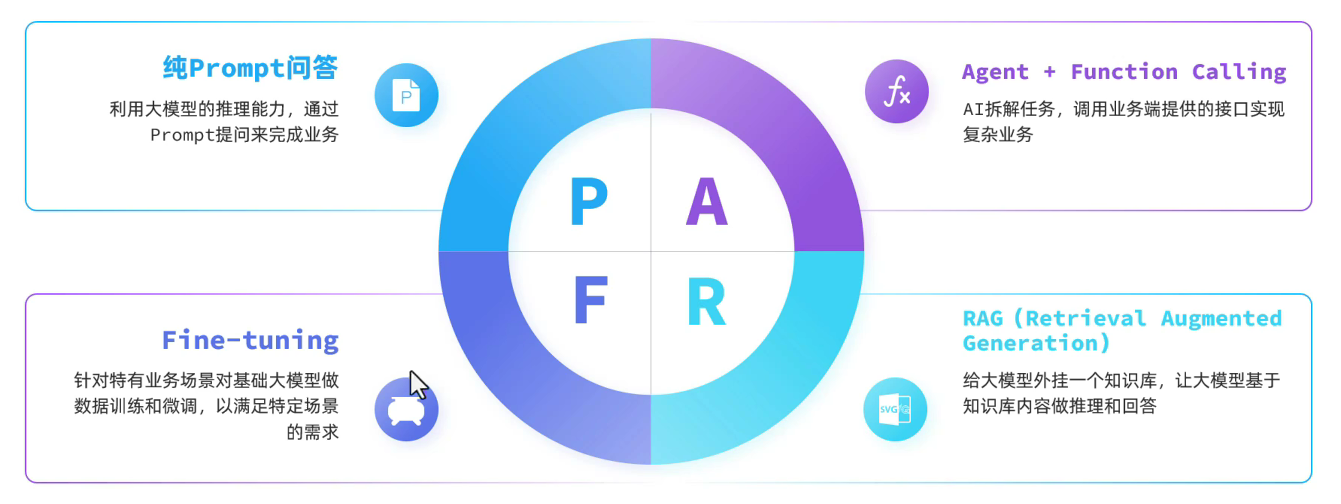
P: 纯 Prompt 问答(Prompt)
纯 Prompt 问答是 PAFR 架构中最基础且直观的部分。它依赖于大模型强大的预训练知识和推理能力,通过用户或开发者精心设计的提示词(Prompt)来引导模型产生期望的输出。
从技术原理来看,大模型在预训练阶段吸收了海量的文本数据,涵盖了各种语言模式、语义关系和世界知识。当输入一个 Prompt 时,模型会在其内部的参数空间中寻找与该 Prompt 匹配的语义表示,并基于此生成相应的回复。例如,在一个自然语言处理的大模型中,当输入 “请列举出三种常见的水果” 时,模型会根据其在预训练中学习到的关于水果的知识,输出如 “苹果、香蕉、橙子” 这样的答案。
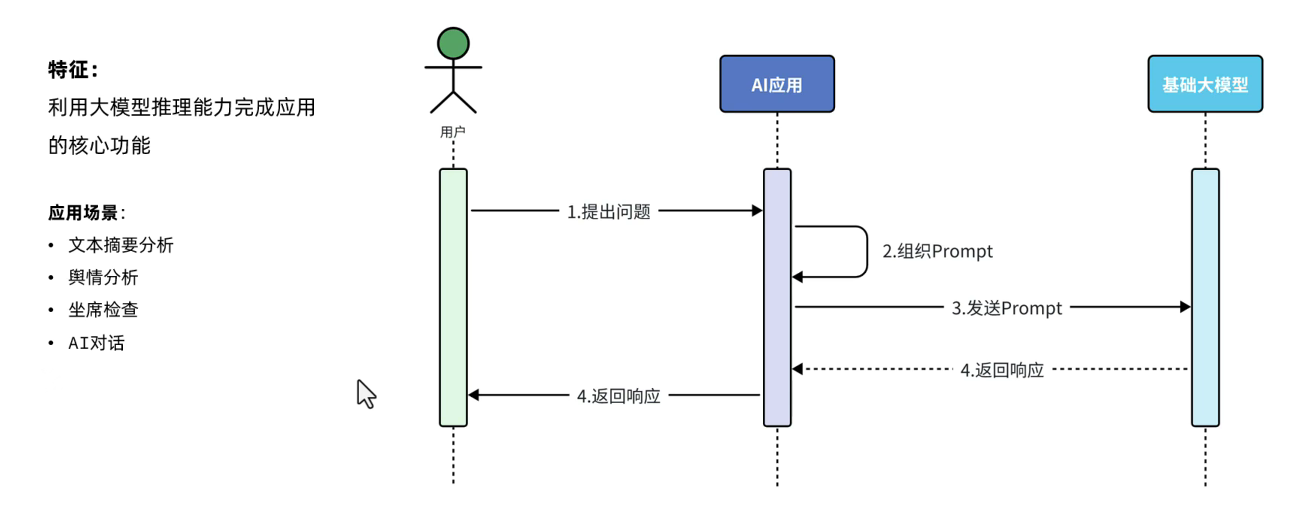
在实际应用中,纯 Prompt 问答具有广泛的用途。在智能客服场景中,简单的常见问题解答可以通过纯 Prompt 问答实现。例如,用户询问 “你们的产品保修期是多久?”,客服系统只需将这个问题作为 Prompt 输入到模型中,模型就能根据预训练的知识给出相应的答案。这种方式的优势在于其便捷性和快速部署性。无需对模型进行额外的训练或复杂的配置,只需设计合适的 Prompt,就能让模型完成多种简单任务,极大地降低了开发成本和时间。
然而,纯 Prompt 问答也存在一定的局限性。对于复杂的任务,如需要多步推理、领域特定知识深度理解的情况,单纯依靠 Prompt 可能无法获得满意的结果。因为模型的回答仅仅基于预训练的通用知识,缺乏对特定场景的深入适应性。例如,在法律领域,当用户询问 “在特定合同纠纷中,依据哪条法律条款进行处理?” 这样复杂且专业的问题时,模型可能无法给出准确的答案,因为它可能没有足够深入的法律专业知识。
A: Agent + Function Calling(Agent)
Agent + Function Calling 在 PAFR 架构中赋予了 AI 应用处理复杂业务逻辑的能力。这里的 Agent 可以看作是一个智能的任务执行者,它能够理解任务的目标,并将复杂任务拆解为多个子任务,然后通过调用业务端提供的各种函数接口(Function Calling)来完成这些子任务。
以一个智能办公助手为例,假设用户下达任务 “安排下周五下午 3 点到 5 点的团队会议,并通知所有团队成员,同时预订合适的会议室”。Agent 首先会对这个任务进行拆解,识别出需要完成的子任务包括查询团队成员的空闲时间、查找并预订可用的会议室、发送会议通知等。然后,它会调用相应的函数接口,比如调用企业内部的日历接口来查询团队成员的日程,调用会议室管理系统的接口来查找并预订会议室,调用邮件或即时通讯接口来发送会议通知。
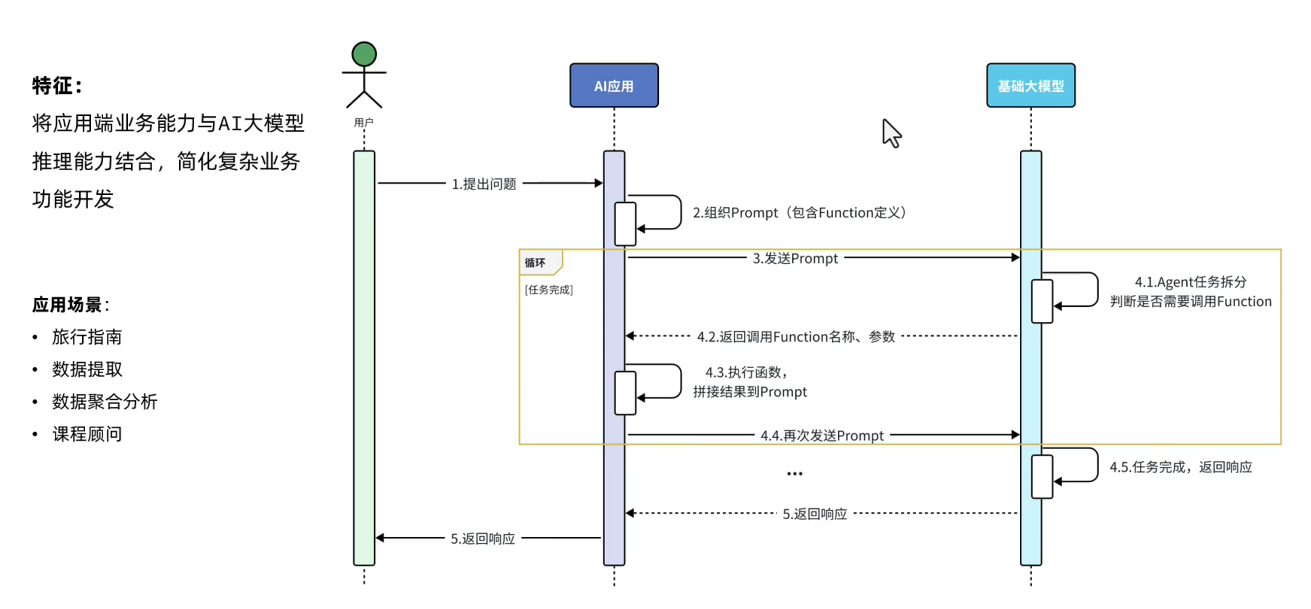
从技术层面分析,Agent 需要具备强大的自然语言理解和任务规划能力。它要能够准确理解用户任务的语义,并根据语义生成合理的任务执行计划。在调用函数接口时,需要进行参数的正确传递和结果的合理处理。例如,在调用日历接口查询团队成员空闲时间时,需要准确设置查询的时间范围、人员范围等参数,并对返回的结果进行解析和整合,以便为后续的会议室预订和通知发送提供准确的信息。
这种方式的优势在于能够充分利用现有的业务系统和功能模块,实现高度定制化的复杂业务流程自动化。它使得 AI 应用不再局限于简单的问答,而是能够深入到实际业务操作中,提高工作效率和业务处理的准确性。但同时,它也对业务系统的接口设计和稳定性提出了较高的要求。接口的变动可能会影响到 Agent 的正常工作,并且需要进行严格的权限管理和安全控制,以确保数据的安全和业务的正常运行。
F: Fine - tuning(Fine - tuning)
Fine - tuning 是使基础大模型适应特定业务场景的关键技术手段。基础大模型虽然在预训练阶段获得了广泛的知识和语言能力,但在面对特定领域或特定任务时,往往需要进一步的优化和调整。
以医疗影像诊断为例,通用的图像识别大模型在识别日常物体方面可能表现出色,但对于医疗影像中的疾病特征识别却力不从心。通过 Fine - tuning,可以使用大量的医疗影像数据,如 X 光片、CT 扫描图像等,以及对应的疾病诊断标签对基础模型进行进一步训练。在这个过程中,模型会学习到医疗影像中各种疾病的特征模式,调整其内部的参数,以更好地适应医疗影像诊断的任务需求。
从技术角度来看,Fine - tuning 通常是在预训练模型的基础上,固定部分底层参数,只对上层的部分参数进行训练。这样做的原因是预训练模型的底层参数已经学习到了通用的特征表示,如在图像领域的边缘、纹理等基础特征,在语言领域的语法结构等基础语言知识。而特定领域的知识主要体现在上层的特征表示和语义理解上。通过只对上层参数进行训练,可以在减少计算资源消耗的同时,快速让模型适应特定任务。
Fine - tuning 的优势明显,它能够显著提高模型在特定场景下的性能,使模型能够更好地满足实际业务的需求。在金融领域,通过 Fine - tuning 可以让模型更好地理解金融市场的术语、交易规则和风险评估方法,从而在信用评估、投资决策等任务中提供更准确的支持。然而,它也存在一些挑战。首先是需要大量的特定领域数据,数据的收集和标注往往需要耗费大量的人力和时间成本。其次,Fine - tuning 的过程需要一定的专业知识和计算资源,对于一些小型团队或企业来说,可能存在一定的技术门槛和成本压力。
R: RAG(Retrieval Augmented Generation)
RAG 是一种将知识库检索与模型生成能力相结合的技术。在传统的大模型中,生成的答案主要依赖于预训练时学习到的知识。而 RAG 为大模型引入了一个外部的知识库,当模型接收到问题时,首先会从知识库中检索相关的信息,然后结合检索到的信息和自身的生成能力,生成更准确、更有依据的回答。
以一个学术问答系统为例,当用户提问 “关于量子计算的最新研究进展有哪些?” 时,大模型会先从专门的学术知识库中检索最近发表的关于量子计算的研究论文、研究报告等信息。然后,模型会对这些检索到的信息进行分析和理解,结合自身的语言生成能力,以一种通俗易懂的方式向用户介绍量子计算的最新研究成果,如新型的量子算法、量子比特的改进等。
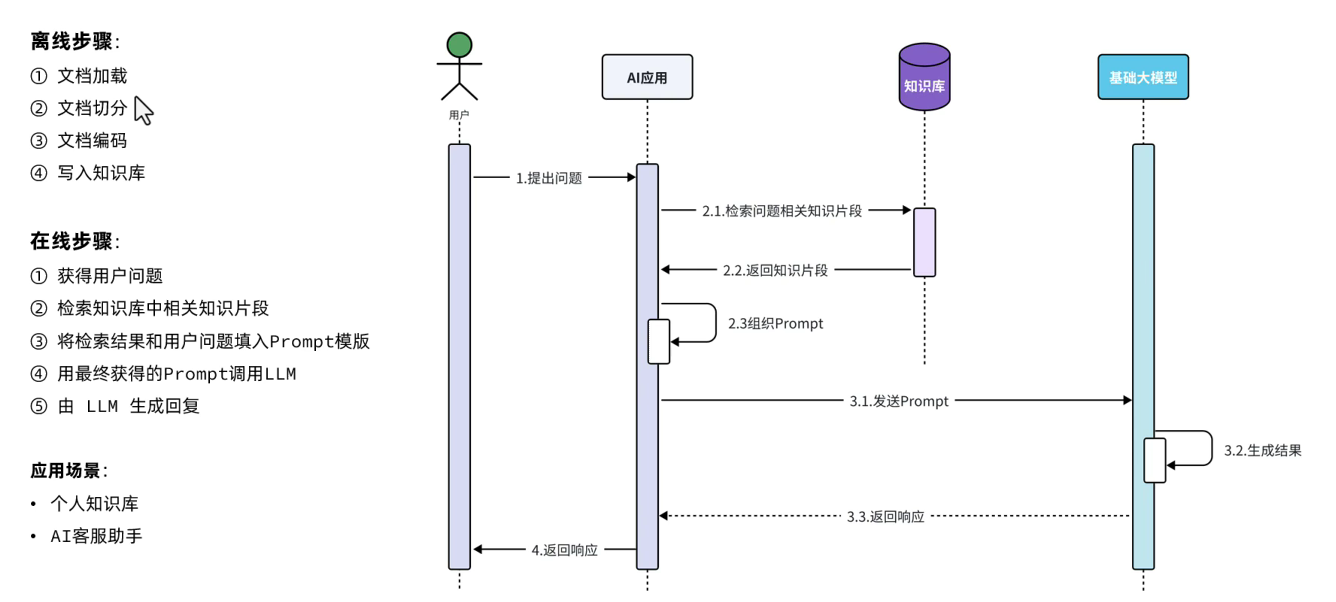
从技术实现上看,RAG 需要解决知识库的构建、高效的检索算法以及信息与生成模型的融合等问题。知识库的构建需要对大量的相关领域知识进行收集、整理和存储。检索算法要能够快速准确地从知识库中找到与问题相关的信息。在信息融合方面,模型需要能够将检索到的信息有效地整合到生成过程中,确保回答的连贯性和逻辑性。
RAG 的优势在于能够让模型在面对需要专业知识或最新信息的问题时,给出更准确、更权威的答案。它弥补了大模型预训练知识可能存在的局限性,特别是对于一些快速发展的领域,如科技、医疗等,通过不断更新知识库,可以让模型始终掌握最新的信息。但它也面临一些挑战,如知识库的维护成本较高,需要及时更新和整理知识,以确保信息的准确性和时效性。同时,检索和融合过程中的误差也可能会影响最终答案的质量。
总结
PAFR 架构是一套整合纯 Prompt 问答、Agent + Function Calling、Fine - tuning、RAG 四大核心技术的 AI 应用开发框架,各模块既独立发挥作用,又协同支撑复杂业务需求。
纯 Prompt 问答是基础模块,依托大模型预训练知识,通过 Prompt 工程设计(如少样本提示)引导模型输出,适用于文本摘要、简单问答等场景,虽便捷但受复杂任务处理能力与模型 “幻觉” 问题限制,需通过约束 Prompt、交叉验证缓解。
Agent + Function Calling 聚焦复杂任务,Agent 拆解任务后调用标准化业务接口(如日历、预订接口),多 Agent 协作可应对智能城市管理等场景,同时需注重接口安全(如 OAuth 2.0 认证、调用审计)与标准化(如 RESTful API)。
Fine - tuning 是模型领域适配关键,作为迁移学习的应用形式,通过调整超参数(学习率、训练轮数等),用特定领域数据(如医疗影像)优化模型,提升专业场景(如疾病诊断)性能,但依赖大量标注数据与计算资源。
RAG 结合知识库检索与生成能力,引入知识图谱可增强回答可解释性,还在探索与 GAN 结合优化答案质量,能解决大模型预训练知识滞后问题,适用于学术问答、法律咨询等需实时专业知识的场景,不过需持续维护知识库。
整体而言,PAFR 架构覆盖从简单到复杂、从通用到专业的 AI 应用开发需求,为开发者提供灵活高效的技术体系,推动 AI 在多领域落地。