残差网络ResNet
目录
一.传统卷积神经网络的问题
1、梯度消失和梯度爆炸
2、退化问题
二.ResNet(残差网络)解决方案
三.残差网络核心原理
四.残差网络的结构和组成
五.自定义一个简单的残差网络
一.传统卷积神经网络的问题
卷积神经网络都是通过卷积层和池化层的叠加组成的。 在实际的试验中发现,随着卷积层和池化层的叠加,学习效果不会逐渐变好,反而出现2个问题:
1、梯度消失和梯度爆炸
梯度消失:若每一层的误差梯度小于1,反向传播时,网络越深,梯度越趋近于0
梯度爆炸:若每一层的误差梯度大于1,反向传播时,网络越深,梯度越来越大
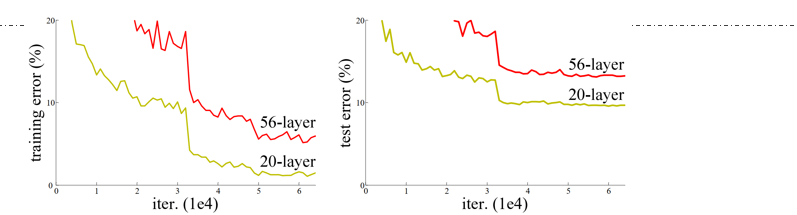
2、退化问题
当网络变得非常深时,会出现“网络退化”现象,即更深的网络反而性能下降。
二.ResNet(残差网络)解决方案
- 使用Batch Normalization(批量归一化)层来缓解梯度消失和梯度爆炸问题。
- 为了解决深层网络中的退化问题,可以人为地让神经网络某些层跳过下一层神经元的连接,隔层相连,弱化每层之间的强联系。这种神经网络被称为 残差网络 (ResNets)。
三.残差网络核心原理
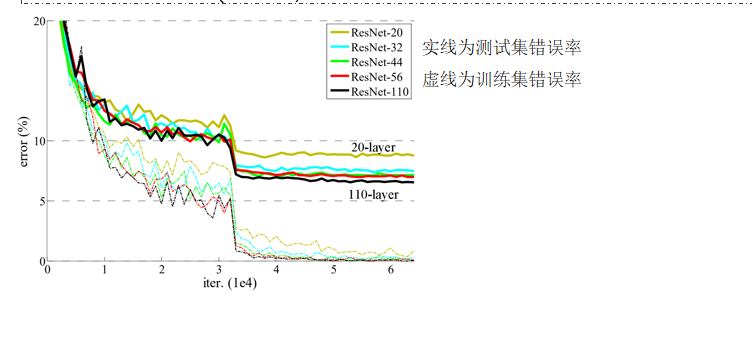
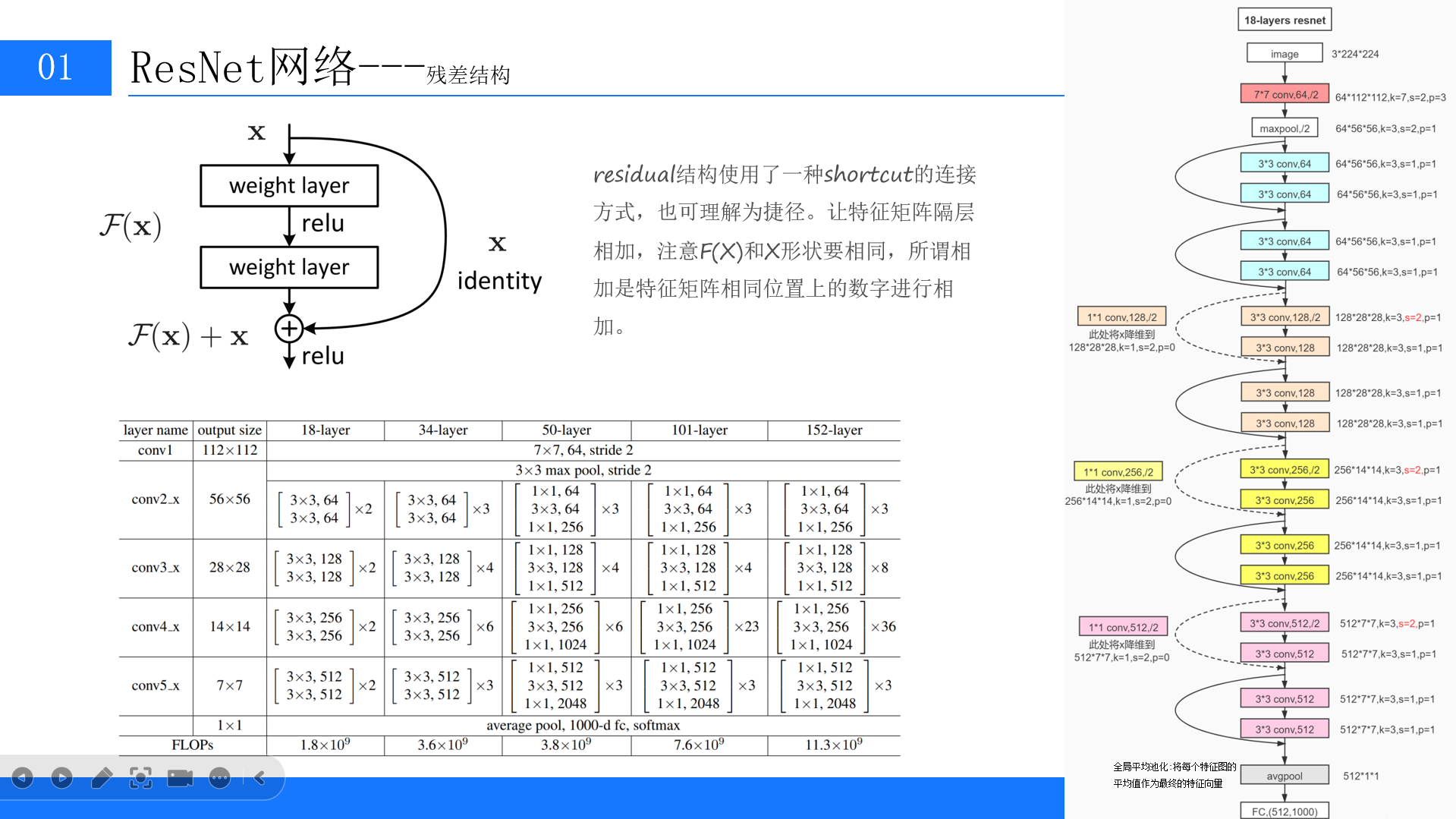
- 为解决深层网络训练中的梯度消失和信息丢失问题,引入了“跨层连接”或“捷径”(shortcut)机制,将浅层的特征图与深层的特征图进行相加。
- 该机制的作用是保留和强化原始的有效特征信息,防止因前几层的学习错误而导致后续网络性能急剧下降。
四.残差网络的结构和组成
- 常见的残差网络有18层、34层、50层、101层和152层等多种规模,各层通过不同的卷积核(如3x3、1x1)和跨层连接组合而成。
- 网络的第一层通常为7x7的卷积,随后经过Max Pooling层。
- 全局平均值池化(GAP)层被用来代替传统的全连接层,将最终的特征图转换为固定长度的特征向量。

五.自定义一个简单的残差网络
残差网络最重要的就是定义一个残差模块如下图所示的结构
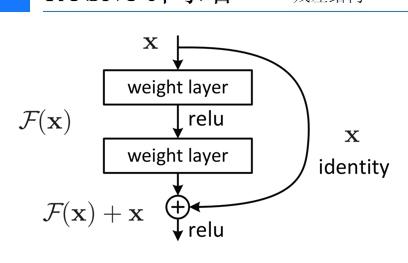
现在我们定义一个残差模块类
class ResBlock(nn.Module):def __init__(self,channel_in):super().__init__()self.conv1=nn.Conv2d(channel_in,30,5,padding=2)self.conv2=nn.Conv2d(30,channel_in,3,padding=1)def forward(self,x):out=self.conv1(x)out=self.conv2(out)return torch.relu(out+x)最后的返回值torch.relu(out+x)则实现了跨层连接
接下来我们来定义ResNet模型
可以看到我们使用了三次残差模块
class ResNet(nn.Module):def __init__(self):super().__init__()self.conv1=nn.Conv2d(1,20,5)self.conv2=nn.Conv2d(20,30,3)self.conv3=nn.Conv2d(30,50,3)self.maxpool=nn.MaxPool2d(2)self.resblock1=ResBlock(channel_in=20)self.resblock2=ResBlock(channel_in=30)self.resblock3=ResBlock(channel_in=50)self.full_c=nn.Linear(50,10)def forward(self,x):size=x.shape[0]x=torch.relu(self.maxpool(self.conv1(x)))x=self.resblock1(x)x=torch.relu(self.maxpool(self.conv2(x)))x=self.resblock2(x)x = torch.relu(self.maxpool(self.conv3(x)))x=self.resblock3(x)x=x.view(size,-1)x=self.full_c(x)return x其余代码与之前手写数字识别的代码并无差异,完整代码如下:
import torch
from torch import nn#导入神经网络模块
from torch.utils.data import DataLoader#数据包管理工具,打包数据
from torchvision import datasets#封装了很多与图像相关的模型,和数据集
from torchvision.transforms import ToTensor#将其他数据类型转化为张量train_data=datasets.MNIST(root='data',train=True,#是否读取下载后数据中的训练集download=True,#如果之前下载过则不用下载transform=ToTensor()
)
test_data=datasets.MNIST(root='data',train=False,download=True,transform=ToTensor()
)#残差模块
class ResBlock(nn.Module):def __init__(self,channel_in):super().__init__()self.conv1=nn.Conv2d(channel_in,30,5,padding=2)self.conv2=nn.Conv2d(30,channel_in,3,padding=1)def forward(self,x):out=self.conv1(x)out=self.conv2(out)return torch.relu(out+x)class ResNet(nn.Module):def __init__(self):super().__init__()self.conv1=nn.Conv2d(1,32,5)self.conv2=nn.Conv2d(32,64,3)self.conv3=nn.Conv2d(64,128,3)self.maxpool=nn.MaxPool2d(2)self.resblock1=ResBlock(channel_in=32)self.resblock2=ResBlock(channel_in=64)self.resblock3=ResBlock(channel_in=128)self.full_c=nn.Linear(128,10)def forward(self,x):size=x.shape[0]x=torch.relu(self.maxpool(self.conv1(x)))x=self.resblock1(x)x=torch.relu(self.maxpool(self.conv2(x)))x=self.resblock2(x)x = torch.relu(self.maxpool(self.conv3(x)))x=self.resblock3(x)x=x.view(size,-1)x=self.full_c(x)return xtrain_loader = DataLoader(train_data, batch_size=64)
test_loader = DataLoader(test_data, batch_size=64)device = 'cuda' if torch.cuda.is_available() else 'mps' if torch.backends.mps.is_available() else 'cpu'
print(f'Using {device} device')
model=ResNet().to(device)
def train(dataloader,model,loss_fn,optimizer):model.train()batch_size_num = 0loss_sum = 0for X, y in dataloader:X, y = X.to(device), y.to(device)pred = model(X)loss = loss_fn(pred, y)optimizer.zero_grad()loss.backward()optimizer.step()loss_value = loss.item()loss_sum += loss_valueif batch_size_num % 100 == 0:print(f'loss:{loss_value:>7f} [number:{batch_size_num}]')batch_size_num += 1return loss_sum / batch_size_num
def test(dataloader,model,loss_fn):model.eval()len_data=len(dataloader.dataset)correct,loss_sum=0,0num_batch=0with torch.no_grad():for X, y in dataloader:X, y = X.to(device), y.to(device)pred = model(X)loss_sum += loss_fn(pred, y).item()correct+=(pred.argmax(1)==y).type(torch.float).sum().item()num_batch+=1loss_avg=loss_sum/num_batchaccuracy=correct/len_dataprint(f'Accuracy:{100 * accuracy}%\nLoss Avg:{loss_avg}')loss_fn=nn.CrossEntropyLoss()
optimizer=torch.optim.Adam(model.parameters(),lr=0.001)
scheduler=torch.optim.lr_scheduler.StepLR(optimizer=optimizer,step_size=3,gamma=0.5)#每3个epoch更新学习率lr*gamma,gamma学习率衰减因子
# optimizer=torch.optim.Adam(model.parameters(),lr=0.001)
# scheduler=torch.optim.lr_scheduler.ReduceLROnPlateau(
# optimizer=optimizer,mode='min',factor=0.5,patience=2,verbose=False,threshold=0.0001,
# threshold_mode='rel',cooldown=0,min_lr=0,eps=1e-08)epochs=17
for i in range(epochs):print(f'==========第{i + 1}轮训练==============')loss=train(train_loader, model, loss_fn, optimizer)scheduler.step()# scheduler.step(loss)print(f'第{i + 1}轮训练结束')test(test_loader,model,loss_fn)