【完整源码+数据集+部署教程】海底水下垃圾分类检测图像分割系统源码和数据集:改进yolo11-attention
背景意义
研究背景与意义
随着全球经济的快速发展和城市化进程的加快,海洋和水体污染问题日益严重,尤其是海底垃圾的堆积,已成为影响生态环境和海洋生物多样性的重要因素。海底垃圾不仅对海洋生物造成直接威胁,还可能通过食物链影响人类健康。因此,开展海底垃圾的分类检测与管理工作显得尤为重要。传统的海底垃圾检测方法多依赖人工调查和目视识别,效率低下且易受主观因素影响,难以满足现代环境保护的需求。
近年来,计算机视觉技术的迅猛发展为海底垃圾检测提供了新的解决方案。基于深度学习的目标检测和图像分割技术,尤其是YOLO(You Only Look Once)系列模型,因其高效的实时检测能力而受到广泛关注。YOLOv11作为该系列的最新版本,具备更强的特征提取能力和更高的检测精度,能够在复杂的水下环境中有效识别和分类多种类型的垃圾。
本研究旨在基于改进的YOLOv11模型,构建一个海底水下垃圾分类检测图像分割系统。该系统将利用包含1400幅图像的多类别数据集,涵盖电子产品、塑料瓶、金属等七种垃圾类型,进行实例分割和分类。通过对数据集的深度学习训练,期望实现对海底垃圾的高效识别与分类,从而为海洋环境保护提供科学依据和技术支持。
本项目的实施不仅有助于提升海底垃圾检测的自动化水平,还能为后续的垃圾清理和管理提供数据支持,推动海洋生态环境的可持续发展。通过对海底垃圾的精确监测与分类,能够更好地制定相应的环境保护政策,促进公众对海洋保护的关注与参与,最终实现人与自然的和谐共生。
图片效果
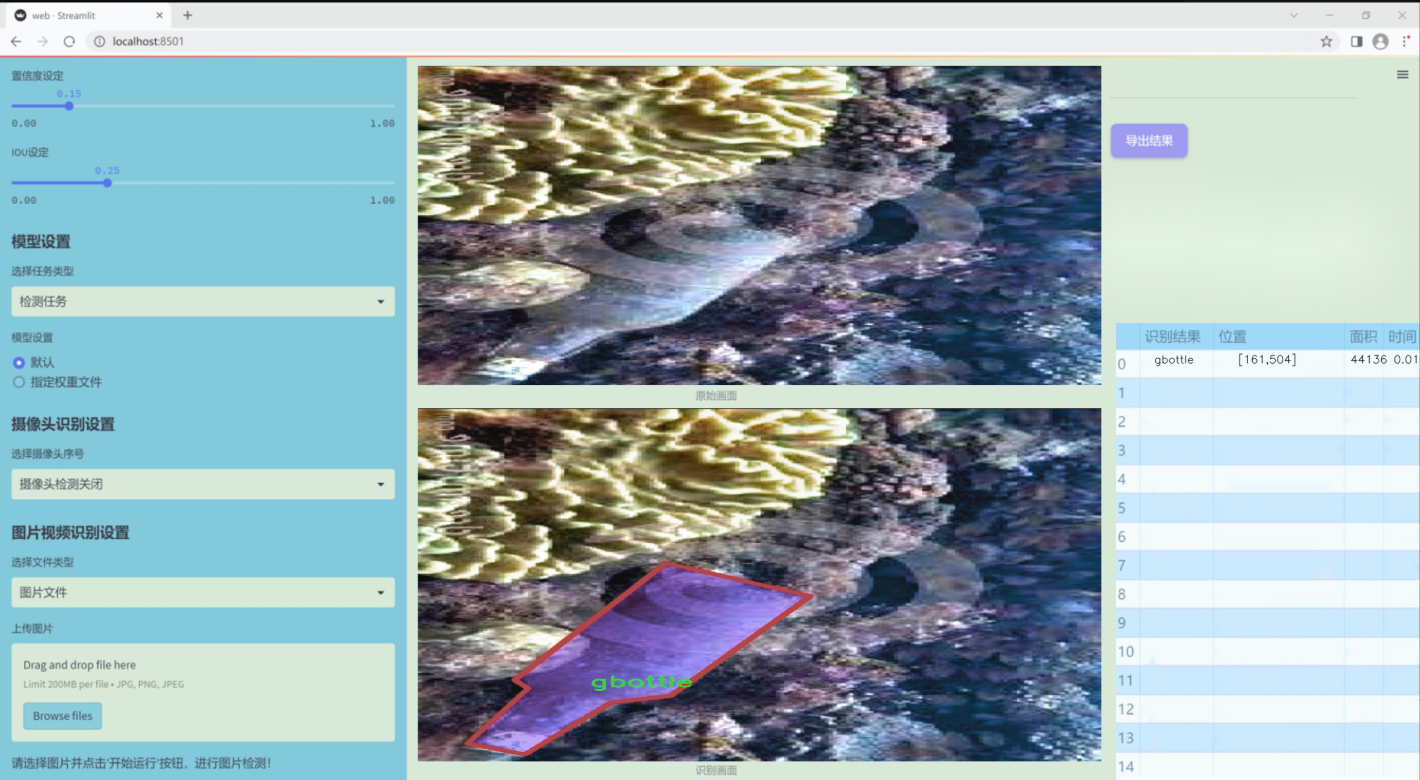
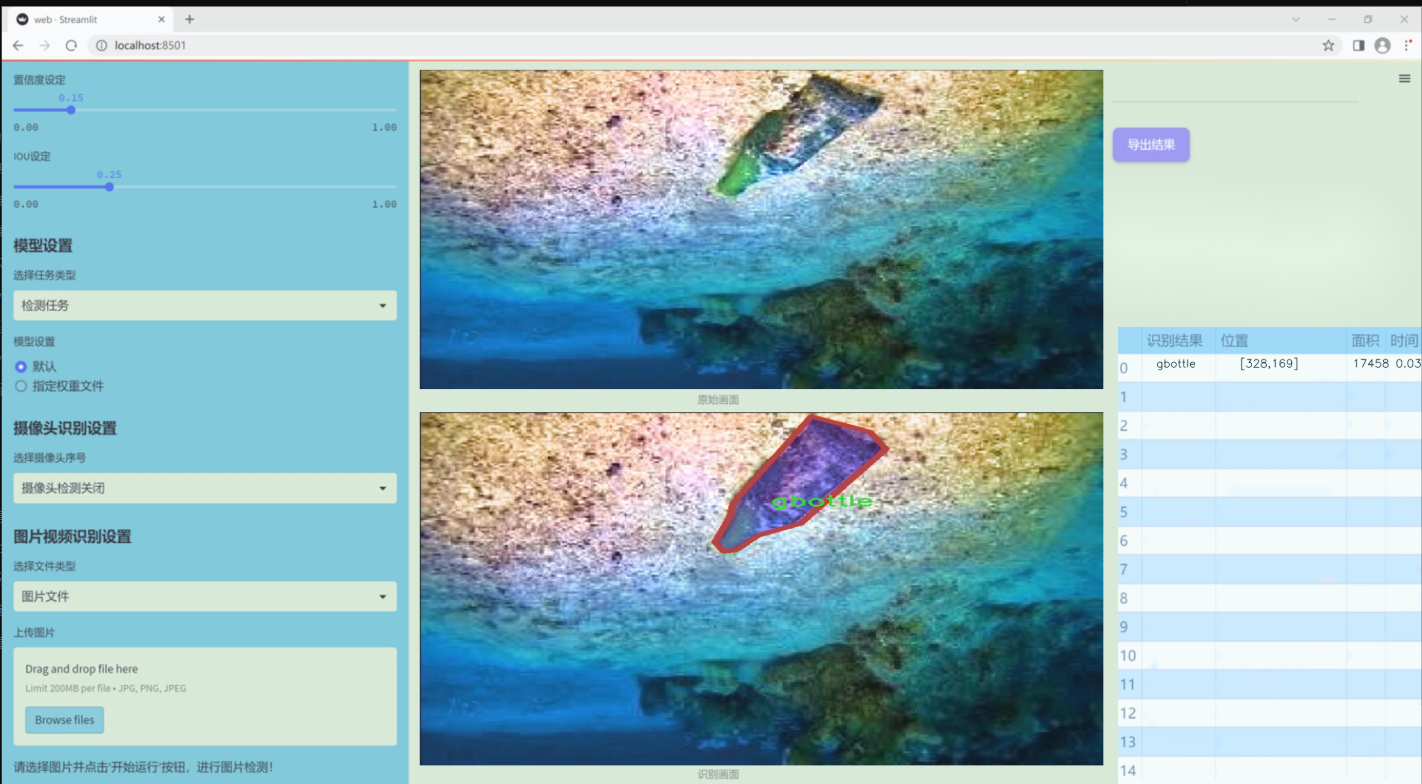
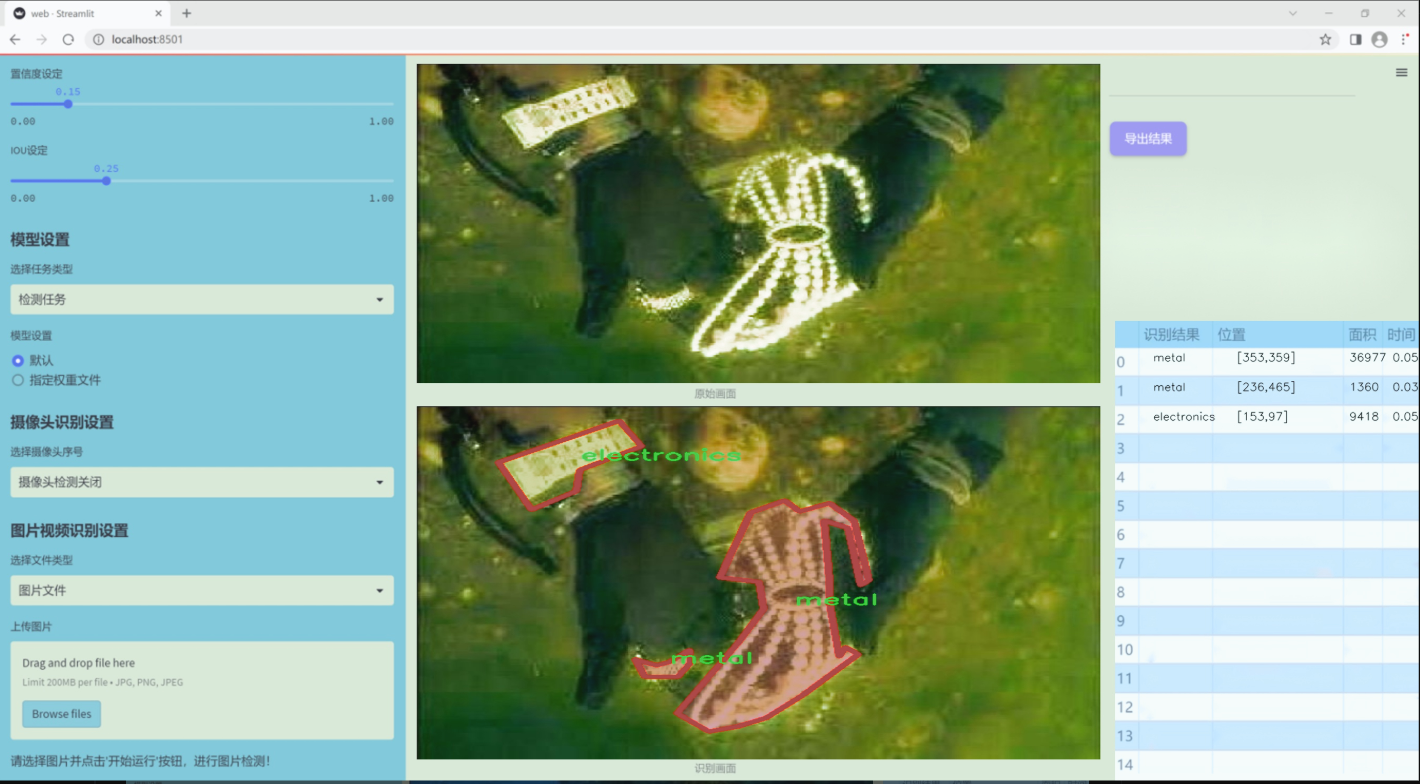
数据集信息
本项目数据集信息介绍
本项目所使用的数据集专注于海底水下垃圾的分类与检测,旨在通过改进YOLOv11模型,提升图像分割系统在海洋环境中的应用效果。数据集的主题为“bendib”,它涵盖了多种常见的水下垃圾类型,具有重要的环境保护和生态监测意义。该数据集包含七个类别,具体包括电子产品(electronics)、玻璃瓶(gbottle)、口罩(mask)、金属物品(metal)、塑料袋(pbag)、塑料瓶(pbottle)以及其他废弃物(waste)。这些类别的选择反映了当今海洋环境中普遍存在的污染物,尤其是在城市化和工业化加速的背景下,海洋垃圾问题日益严重。
在数据集的构建过程中,研究团队收集了大量的水下图像,确保每个类别的样本数量均衡,以便为YOLOv11模型的训练提供充分的多样性和代表性。这些图像不仅包括不同种类的垃圾,还涵盖了多种水下环境条件,如光照变化、不同水深以及水流的影响等,旨在增强模型的鲁棒性和适应性。通过精细标注每个类别的边界框和分割区域,数据集为模型的训练提供了高质量的监督信号。
此外,为了确保数据集的实用性和有效性,研究团队还进行了数据增强处理,包括旋转、缩放、翻转等操作,以增加样本的多样性并减少过拟合的风险。这一系列的准备工作为改进YOLOv11模型在海底水下垃圾分类检测中的应用奠定了坚实的基础,期待通过这一项目能够为海洋保护和环境治理提供有效的技术支持。





核心代码
以下是代码中最核心的部分,并附上详细的中文注释:
import torch
import torch.nn.functional as F
def selective_scan_easy(us, dts, As, Bs, Cs, Ds, delta_bias=None, delta_softplus=False, return_last_state=False, chunksize=64):
“”"
选择性扫描函数,进行状态更新和输出计算。
参数:
us: 输入张量,形状为 (B, G * D, L)
dts: 时间增量张量,形状为 (B, G * D, L)
As: 系数矩阵,形状为 (G * D, N)
Bs: 权重张量,形状为 (B, G, N, L)
Cs: 输出权重张量,形状为 (B, G, N, L)
Ds: 偏置项,形状为 (G * D)
delta_bias: 可选的偏置调整,形状为 (G * D)
delta_softplus: 是否应用softplus函数
return_last_state: 是否返回最后的状态
chunksize: 每次处理的块大小
"""def selective_scan_chunk(us, dts, As, Bs, Cs, hprefix):"""处理单个块的选择性扫描。参数:us: 输入张量块dts: 时间增量张量块As: 系数矩阵Bs: 权重张量块Cs: 输出权重张量块hprefix: 前一个状态返回:ys: 输出张量hs: 状态张量"""ts = dts.cumsum(dim=0) # 计算时间增量的累积和Ats = torch.einsum("gdn,lbgd->lbgdn", As, ts).exp() # 计算系数矩阵的指数scale = 1 # 缩放因子rAts = Ats / scale # 归一化的系数矩阵duts = dts * us # 计算增量的输入dtBus = torch.einsum("lbgd,lbgn->lbgdn", duts, Bs) # 计算增量的权重hs_tmp = rAts * (dtBus / rAts).cumsum(dim=0) # 计算状态hs = hs_tmp + Ats * hprefix.unsqueeze(0) # 更新状态ys = torch.einsum("lbgn,lbgdn->lbgd", Cs, hs) # 计算输出return ys, hs# 数据类型设置
dtype = torch.float32
inp_dtype = us.dtype # 输入数据类型
has_D = Ds is not None # 检查是否有偏置项
if chunksize < 1:chunksize = Bs.shape[-1] # 设置块大小# 处理输入数据
dts = dts.to(dtype)
if delta_bias is not None:dts = dts + delta_bias.view(1, -1, 1).to(dtype) # 应用偏置调整
if delta_softplus:dts = F.softplus(dts) # 应用softplus函数# 处理张量维度
Bs = Bs.unsqueeze(1) if len(Bs.shape) == 3 else Bs
Cs = Cs.unsqueeze(1) if len(Cs.shape) == 3 else Cs
B, G, N, L = Bs.shape
us = us.view(B, G, -1, L).permute(3, 0, 1, 2).to(dtype)
dts = dts.view(B, G, -1, L).permute(3, 0, 1, 2).to(dtype)
As = As.view(G, -1, N).to(dtype)
Bs = Bs.permute(3, 0, 1, 2).to(dtype)
Cs = Cs.permute(3, 0, 1, 2).to(dtype)
Ds = Ds.view(G, -1).to(dtype) if has_D else None
D = As.shape[1] # 状态维度oys = [] # 输出列表
hprefix = us.new_zeros((B, G, D, N), dtype=dtype) # 初始化前一个状态
for i in range(0, L, chunksize):ys, hs = selective_scan_chunk(us[i:i + chunksize], dts[i:i + chunksize], As, Bs[i:i + chunksize], Cs[i:i + chunksize], hprefix, )oys.append(ys) # 添加输出hprefix = hs[-1] # 更新前一个状态oys = torch.cat(oys, dim=0) # 合并输出
if has_D:oys = oys + Ds * us # 应用偏置项
oys = oys.permute(1, 2, 3, 0).view(B, -1, L) # 调整输出维度return oys.to(inp_dtype) if not return_last_state else (oys.to(inp_dtype), hprefix.view(B, G * D, N).float())
代码核心部分说明:
selective_scan_easy:主函数,接收输入数据和参数,进行选择性扫描。
selective_scan_chunk:处理单个数据块的函数,计算状态和输出。
张量处理:包括输入数据的维度调整、类型转换、偏置应用等。
输出合并:将多个块的输出合并为最终结果,并处理偏置项。
以上是代码的核心部分及其详细注释,帮助理解选择性扫描的实现逻辑。
这个程序文件 test_selective_scan_easy.py 是一个用于实现和测试选择性扫描(Selective Scan)算法的 PyTorch 代码。选择性扫描是一种用于处理序列数据的技术,常用于深度学习中的时间序列预测、序列建模等任务。以下是对代码的详细说明。
首先,代码导入了一些必要的库,包括 math、functools、torch、torch.nn.functional、pytest 和 einops。这些库提供了数学运算、函数式编程、张量操作和测试功能。
接下来,定义了一个名为 selective_scan_easy 的函数,该函数实现了选择性扫描的核心逻辑。函数的输入包括多个张量,如 us、dts、As、Bs、Cs 和 Ds,这些张量代表了输入数据、时间差、参数矩阵等。函数内部定义了一个名为 selective_scan_chunk 的嵌套函数,用于处理数据块的选择性扫描。
在 selective_scan_chunk 函数中,使用了张量运算来计算状态和输出。通过对输入数据进行累加和矩阵乘法,计算出当前时间步的状态和输出。函数的返回值是当前时间步的输出和状态。
在 selective_scan_easy 函数中,首先对输入数据进行类型转换和形状调整,然后通过循环处理每个数据块,调用 selective_scan_chunk 函数进行计算。最终,函数返回计算得到的输出和最后的状态。
接下来,定义了一个名为 SelectiveScanEasy 的类,继承自 torch.autograd.Function,用于实现自定义的前向和反向传播。类中定义了 forward 和 backward 静态方法,分别用于计算前向传播和反向传播的梯度。前向传播中调用了 selective_scan_easy 函数,而反向传播则通过保存的张量计算梯度。
此外,代码还定义了一些其他的选择性扫描变体函数,如 selective_scan_easyv2 和 selective_scan_easyv3,这些函数实现了不同的选择性扫描逻辑,可能用于不同的应用场景或优化。
最后,代码中包含了一个测试函数 test_selective_scan,使用 pytest 框架对选择性扫描的实现进行单元测试。测试中使用了多种参数组合,验证了选择性扫描函数的正确性和性能。
总体而言,这个程序文件实现了选择性扫描算法的核心逻辑,并提供了多种变体和测试用例,适用于深度学习中的序列数据处理任务。
10.4 shiftwise_conv.py
以下是经过简化和详细注释的核心代码部分:
import math
import torch
import torch.nn as nn
import torch.nn.functional as F
def get_conv2d(in_channels, out_channels, kernel_size, stride, padding, dilation, groups, bias):
“”"
创建一个2D卷积层
“”"
return nn.Conv2d(
in_channels, out_channels, kernel_size, stride, padding, dilation, groups, bias
)
def get_bn(channels):
“”"
创建一个批归一化层
“”"
return nn.BatchNorm2d(channels)
class Mask(nn.Module):
“”"
定义一个Mask类,用于生成可学习的权重掩码
“”"
def init(self, size):
super().init()
# 初始化权重参数,范围在[-1, 1]之间
self.weight = torch.nn.Parameter(data=torch.Tensor(*size), requires_grad=True)
self.weight.data.uniform_(-1, 1)
def forward(self, x):# 应用sigmoid激活函数,生成掩码权重w = torch.sigmoid(self.weight)masked_wt = w.mul(x) # 将输入x与掩码权重相乘return masked_wt
class ReparamLargeKernelConv(nn.Module):
“”"
定义一个重参数化的大卷积核层
“”"
def init(self, in_channels, out_channels, kernel_size, small_kernel=5, stride=1, groups=1, small_kernel_merged=False, Decom=True, bn=True):
super(ReparamLargeKernelConv, self).init()
self.kernel_size = kernel_size
self.small_kernel = small_kernel
self.Decom = Decom
padding = kernel_size // 2 # 计算填充大小
# 根据是否合并小卷积核来选择不同的卷积层if small_kernel_merged:self.lkb_reparam = get_conv2d(in_channels=in_channels,out_channels=out_channels,kernel_size=kernel_size,stride=stride,padding=padding,dilation=1,groups=groups,bias=True,)else:if self.Decom:self.LoRA = conv_bn(in_channels=in_channels,out_channels=out_channels,kernel_size=(kernel_size, small_kernel),stride=stride,padding=padding,dilation=1,groups=groups,bn=bn)else:self.lkb_origin = conv_bn(in_channels=in_channels,out_channels=out_channels,kernel_size=kernel_size,stride=stride,padding=padding,dilation=1,groups=groups,bn=bn,)if (small_kernel is not None) and small_kernel < kernel_size:self.small_conv = conv_bn(in_channels=in_channels,out_channels=out_channels,kernel_size=small_kernel,stride=stride,padding=small_kernel // 2,groups=groups,dilation=1,bn=bn,)self.bn = get_bn(out_channels) # 批归一化层self.act = nn.SiLU() # 激活函数def forward(self, inputs):"""前向传播函数"""if hasattr(self, "lkb_reparam"):out = self.lkb_reparam(inputs) # 使用重参数化卷积elif self.Decom:out = self.LoRA(inputs) # 使用LoRA卷积if hasattr(self, "small_conv"):out += self.small_conv(inputs) # 加上小卷积的输出else:out = self.lkb_origin(inputs) # 使用原始卷积if hasattr(self, "small_conv"):out += self.small_conv(inputs) # 加上小卷积的输出return self.act(self.bn(out)) # 返回经过激活和归一化的输出def get_equivalent_kernel_bias(self):"""获取等效的卷积核和偏置"""eq_k, eq_b = fuse_bn(self.lkb_origin.conv, self.lkb_origin.bn) # 融合卷积和批归一化if hasattr(self, "small_conv"):small_k, small_b = fuse_bn(self.small_conv.conv, self.small_conv.bn)eq_b += small_b # 加上小卷积的偏置eq_k += nn.functional.pad(small_k, [(self.kernel_size - self.small_kernel) // 2] * 4) # 填充小卷积核return eq_k, eq_b # 返回等效卷积核和偏置def switch_to_deploy(self):"""切换到部署模式"""if hasattr(self, 'lkb_origin'):eq_k, eq_b = self.get_equivalent_kernel_bias() # 获取等效卷积核和偏置self.lkb_reparam = get_conv2d(in_channels=self.lkb_origin.conv.in_channels,out_channels=self.lkb_origin.conv.out_channels,kernel_size=self.lkb_origin.conv.kernel_size,stride=self.lkb_origin.conv.stride,padding=self.lkb_origin.conv.padding,dilation=self.lkb_origin.conv.dilation,groups=self.lkb_origin.conv.groups,bias=True,)self.lkb_reparam.weight.data = eq_k # 设置等效卷积核权重self.lkb_reparam.bias.data = eq_b # 设置等效偏置self.__delattr__("lkb_origin") # 删除原始卷积属性if hasattr(self, "small_conv"):self.__delattr__("small_conv") # 删除小卷积属性
代码核心部分说明:
卷积和批归一化的创建:get_conv2d和get_bn函数用于创建卷积层和批归一化层。
Mask类:用于生成可学习的权重掩码,应用于输入数据。
ReparamLargeKernelConv类:实现了重参数化的大卷积核层,支持小卷积核的合并与分解。
前向传播:在forward方法中实现了不同卷积层的调用和输出的组合。
等效卷积核和偏置的获取:get_equivalent_kernel_bias方法用于计算卷积层的等效卷积核和偏置,以便在部署时使用。
切换到部署模式:switch_to_deploy方法用于将模型切换到部署模式,减少计算开销。
这个程序文件 shiftwise_conv.py 定义了一个用于实现大核卷积的深度学习模块,主要包含了几种卷积操作和相关的功能。文件中使用了 PyTorch 框架,主要涉及到卷积层、批归一化层以及一些自定义的操作。
首先,文件中定义了一些辅助函数,比如 get_conv2d 和 get_bn,用于创建卷积层和批归一化层。get_conv2d 函数根据输入参数创建一个 nn.Conv2d 对象,并处理可能的填充参数。get_bn 函数则创建一个 nn.BatchNorm2d 对象。
接下来,定义了一个 Mask 类,它是一个自定义的模块,包含一个可学习的权重参数。这个权重通过 Sigmoid 函数进行激活,并与输入相乘,形成一个掩码效果。
conv_bn_ori 函数用于创建一个包含卷积层和可选的批归一化层的序列。它根据输入参数配置卷积层的属性,并在需要时添加批归一化层。
LoRAConvsByWeight 类实现了一种特殊的卷积操作,它结合了大核和小核的卷积,通过权重的方式进行通道的重排。这个类的构造函数接收多个参数,初始化卷积层和掩码,并根据需要添加批归一化层。在 forward 方法中,首先通过小卷积层处理输入,然后通过 forward_lora 方法处理输出,最终将两个结果相加。
forward_lora 方法负责处理卷积输出的重排和归一化。它通过 rearrange_data 方法根据指定的方向(水平或垂直)对输出进行重排,并根据需要添加填充。
rearrange_data 方法根据卷积的参数计算新的填充,并调整输出的维度,以确保卷积操作的有效性。
shift 方法用于计算填充和窗口的索引,确保卷积操作不改变特征图的大小。
conv_bn 函数根据输入的卷积核大小决定使用哪种卷积操作,如果是单一卷积核,则调用 conv_bn_ori,如果是大核和小核的组合,则调用 LoRAConvsByWeight。
fuse_bn 函数用于将卷积层和批归一化层融合,返回融合后的卷积核和偏置。
最后,ReparamLargeKernelConv 类是主要的卷积模块,它支持大核卷积和小核卷积的组合。构造函数中根据输入参数初始化卷积层和批归一化层,并在 forward 方法中执行前向传播。该类还提供了 get_equivalent_kernel_bias 方法用于获取等效的卷积核和偏置,以及 switch_to_deploy 方法用于在部署时转换为可直接使用的卷积层。
整体而言,这个文件实现了一个灵活且高效的卷积操作模块,支持多种卷积核的组合和处理,适用于深度学习中的图像处理任务。
源码文件

源码获取
欢迎大家点赞、收藏、关注、评论啦 、查看👇🏻获取联系方式👇🏻