Netty从0到1系列之Buffer【上】
文章目录
三、Java NIO Buffer: 数据操作的基石
3.1 Buffer 是什么?
Buffer 是 Java NIO 中的核心组件,用于与 NIO Channel 进行数据交互。它是一个特定基本类型数据的容器,本质上是一个可以写入数据、读取数据的内存块(通常是数组),提供了结构化访问数据的方法和机制。
Buffer 的核心特性:
- 容量固定:创建时指定容量,不可改变
- 位置控制:通过 position、limit、capacity 控制读写位置
- 双向操作:支持读写切换,通过 flip() 方法实现
- 内存高效:支持堆内存和直接内存两种实现
- 类型特定:为各种基本类型提供了相应的 Buffer 实现
🌟 核心定位:
Buffer是一个固定大小的数据容器- 所有 I/O 操作必须通过
Buffer进行- 它维护一组状态变量,控制数据的读写边界
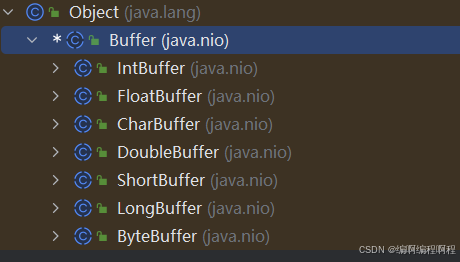
3.2 Buffer 的继承体系与类型
Java NIO 为各种基本数据类型提供了相应的 Buffer 实现:
public abstract class Buffer {// Invariants: mark <= position <= limit <= capacityprivate int mark = -1;private int position = 0;private int limit;private int capacity;// ...
}
Buffer-> ByteBuffer (最常用)-> MappedByteBuffer (内存映射文件)-> CharBuffer-> ShortBuffer-> IntBuffer-> LongBuffer-> FloatBuffer-> DoubleBuffer
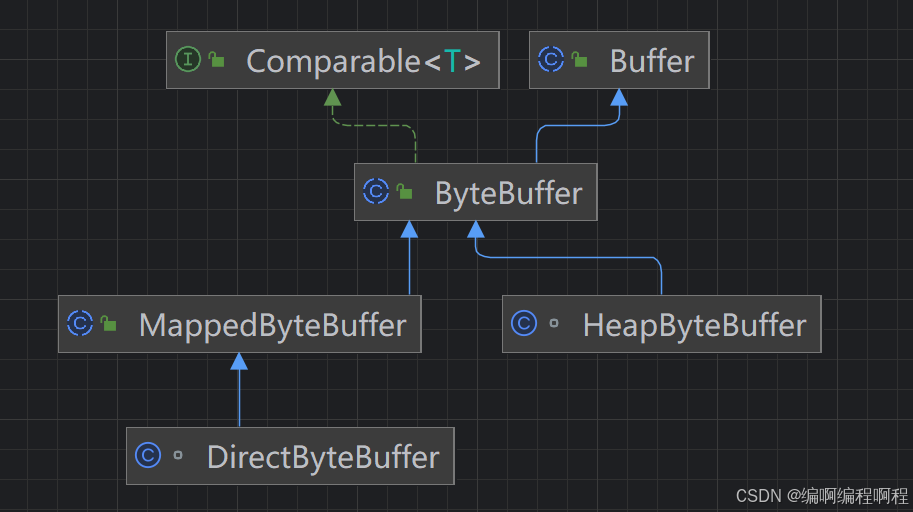
重要的实现类ByteBuffer
public abstract class ByteBufferextends Bufferimplements Comparable<ByteBuffer>
3.3 Buffer 的核心属性与状态机制
Buffer 通过三个核心属性来控制数据的读写位置和边界:
每个 Buffer 都有四个关键属性,它们共同管理数据的读写过程:
| 属性 | 类型 | 说明 |
|---|---|---|
| capacity | int | 容量,Buffer 最多能容纳的数据量(不可变) |
| position | int | 位置,下一个要读或写的索引(0 ≤ position ≤ limit) |
| limit | int | 上限,可读/写数据的边界(0 ≤ limit ≤ capacity) |
| mark | int | 标记,可记录某个位置,后续可通过 reset() 回到该位置 |
🌟 核心规则:
- 0 ≤ mark ≤ position ≤ limit ≤ capacity
- 调用
reset()可将position回到mark位置mark初始为-1,表示未设置
3.4 Buffer的工作模式: 读写切换
Buffer 有两种工作模式: 读模式和写模式.
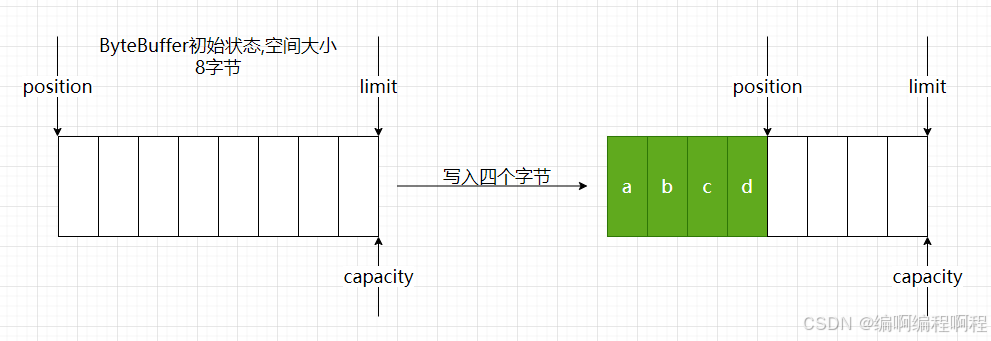
3.4.1 ✅ 写模式(Write Mode)
- 应用程序向 Buffer 写入数据
position指向下一个可写位置limit通常等于capacity
3.4.2 ✅ 读模式(Read Mode)
- 从 Buffer 读取数据到应用程序
position指向下一个可读位置limit指向可读数据末尾
3.4.3 模式切换
🌟 模式切换:通过 flip() 方法完成写 → 读的切换
3.5 Buffer的核心API
这里以ByteBuffer为例进行说明.
3.5.1 ByteBuffer对象的创建
// 分配新的直接字节缓冲区。
// 新缓冲区的位置将为零,其限制将是其容量,其标记将未定义,其每个元素将初始化为零,其字节顺序将为 BIG_ENDIAN。它是否有 a backing array 尚未指定。
// 参数:
// capacity – 新缓冲区的容量(以字节为单位)
// 返回:
// 新字节缓冲区
public static ByteBuffer allocateDirect(int capacity) {return new DirectByteBuffer(capacity);
}// 分配新的字节缓冲区。
// 新缓冲区的位置将为零,其限制将是其容量,其标记将未定义,其每个元素将初始化为零,其字节顺序将为 BIG_ENDIAN。它将有一个 backing array,并且它 array offset 将为零。
// 参数:
// capacity – 新缓冲区的容量(以字节为单位)
// 返回:
// 新字节缓冲区
// 抛出:
// IllegalArgumentException – 如果 是 capacity 负整数
public static ByteBuffer allocate(int capacity) {if (capacity < 0)throw createCapacityException(capacity);return new HeapByteBuffer(capacity, capacity, null);
}// 将字节数组包装到缓冲区中。
// 新缓冲区将由给定的字节数组支持;也就是说,对缓冲区的修改将导致数组被修改,反之亦然。新缓冲区的容量将为 array.length,其位置将为 offset,其限制将为 offset + length,其标记将未定义,其字节顺序将为 BIG_ENDIAN。它 backing array 将是给定的数组,并且为 array offset 零。
// 参数:
// array – 将支持新缓冲区的数组
// offset– 要使用的子数组的偏移量;必须为非负数且不大于 array.length。新缓冲区的位置将设置为此值。
// length– 要使用的子数组的长度;必须为非负数且不大于 array.length - offset。新缓冲区的限制将设置为 offset + length。
// 返回:
// 新字节缓冲区
// 抛出:
I// ndexOutOfBoundsException– 如果 和 length 参数上的offset先决条件不成立
public static ByteBuffer wrap(byte[] array,int offset, int length)
{try {return new HeapByteBuffer(array, offset, length, null);} catch (IllegalArgumentException x) {throw new IndexOutOfBoundsException();}
}// 将字节数组包装到缓冲区中。
// 新缓冲区将由给定的字节数组支持;也就是说,对缓冲区的修改将导致数组被修改,反之亦然。新缓冲区的容量和限制将为 array.length,其位置为零,其标记将未定义,其字节顺序将为 BIG_ENDIAN。它 backing array 将是给定的数组,并且为 array offset 零。
// 参数:
// array – 将支持此缓冲区的数组
// 返回:
// 新字节缓冲区
public static ByteBuffer wrap(byte[] array) {return wrap(array, 0, array.length);
}
3.5.2 ByteBuffer原理解析
四重要的属性:
private int mark = -1;
private int position = 0; // 写入位置
private int limit; // 写入或者读取的限制
private int capacity; // 容量大小
读取操作, 必须调用flip()方法
public Buffer flip() {limit = position; // 将limit赋值到当前position位置position = 0; // position归0mark = -1;return this;
}
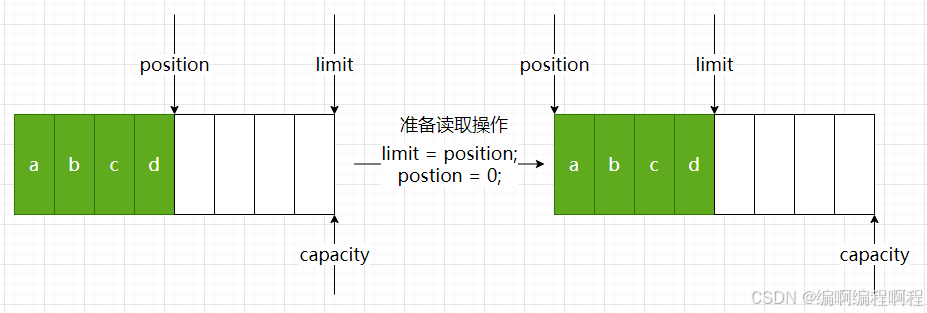
读取4个字节之后, postion位置移动到limit位置.
final int nextGetIndex() { // package-privateint p = position;if (p >= limit)throw new BufferUnderflowException();position = p + 1; // 每读取一个字节, position位置往后加1.return p;
}
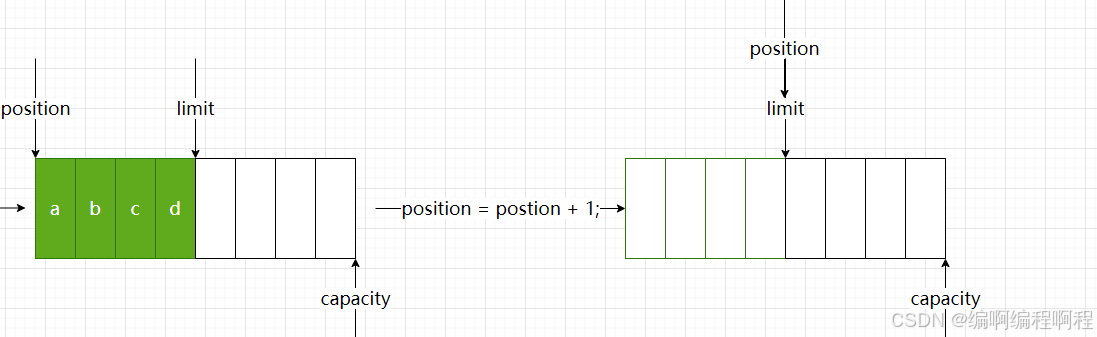
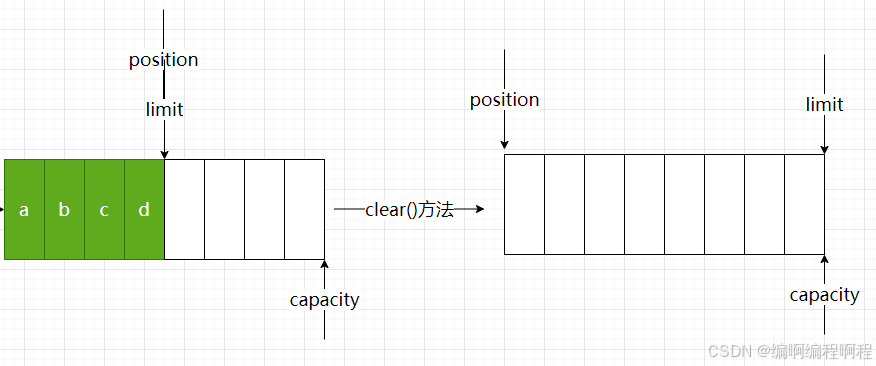
如果想继续将channel读取的数据存储到ByteBuffer当中, 必须调用: clear()方法.
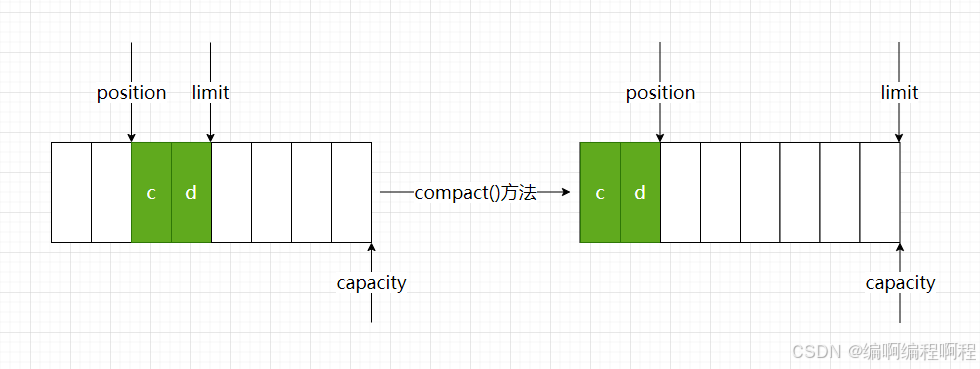
compact方法, 把未读完的部分向前压缩,然后切换为: 【写模式】.
public MappedByteBuffer compact() {int pos = position();int lim = limit();assert (pos <= lim);int rem = (pos <= lim ? lim - pos : 0);try {// null is passed as destination Scope to avoid checking scope() twiceSCOPED_MEMORY_ACCESS.copyMemory(scope(), null, null,ix(pos), null, ix(0), (long)rem << 0);} finally {Reference.reachabilityFence(this);}position(rem);limit(capacity());discardMark();return this;
}
3.5.3 内存分配
直接内存和堆内存:
- 堆内存, 读写效率低, 受到
JVM的限制. - 直接内存,读写效率高(少拷贝一次数据), 大小不受JVM限制.有受垃圾回收的影响.分配内存效率低一些.
Buffer 有两种内存分配方式:
- 堆内存 (Heap Buffer):通过
allocate(int capacity)创建,基于 JVM 堆内存- 直接内存 (Direct Buffer):通过
allocateDirect(int capacity)创建,基于操作系统的本地内存
@Test
public void allocateTest(){ByteBuffer buff1 = ByteBuffer.allocate(10); // 在jvm堆内存分配固定10字节的空间ByteBuffer buff2 = ByteBuffer.allocateDirect(10); // 在直接内存上分配固定10字节的空间log.info("buff1: 对象的名称是: {}", buff1.getClass());log.info("buff2: 对象的名称是: {}", buff2.getClass());
}
19:57:16.949 [main] INFO cn.tcmeta.ByteBufferDemo02 -- buff1: 对象的名称是: class java.nio.HeapByteBuffer
19:57:16.953 [main] INFO cn.tcmeta.ByteBufferDemo02 -- buff2: 对象的名称是: class java.nio.DirectByteBuffer
| 类型 | 创建方式 | 说明 |
|---|---|---|
| 堆内 Buffer | ByteBuffer.allocate(100) | 数据在 JVM 堆中,受 GC 管理 |
| 堆外 Buffer | ByteBuffer.allocateDirect(100) | 数据在 native memory,减少系统调用拷贝 |
🌟 性能对比:
- 堆外 Buffer:I/O 性能更高(零拷贝)
- 堆内 Buffer:创建/回收更快,适合小数据
堆内存特点- 垃圾回收器管理:
堆内存中的对象由 Java 垃圾回收器管理。这意味着当没有引用指向这个ByteBuffer时,垃圾回收器会在适当的时候回收它所占用的内存空间。 - 方便性:在编程中使用相对方便,因为它是 Java 对象,可以直接在 Java 代码中进行操作和管理。
- 可能的性能开销:由于垃圾回收的不确定性,可能会在某些情况下导致性能开销。特别是在频繁进行内存分配和回收的场景下,垃圾回收可能会暂停应用程序的执行,从而影响性能。
- 垃圾回收器管理:
直接内存特点- 不受垃圾回收影响:直接内存不由 Java 垃圾回收器管理,因此在某些情况下可以避免垃圾回收带来的性能开销。
- 适合特定场景:
对于一些需要大量内存、频繁进行 I/O 操作(如网络通信和文件读写)的场景,直接内存可能会提供更好的性能。这是因为直接内存可以与本机 I/O 操作更好地交互,减少数据在 Java 堆内存和本机内存之间的复制次数。 - 内存管理复杂性:使用直接内存需要手动管理内存,并且在使用不当的情况下可能会导致内存泄漏。例如,如果忘记释放不再使用的直接内存,可能会导致本机内存耗尽。
- 可能的内存溢出问题:直接内存的分配不受 Java 堆大小的限制,但它仍然受到本机内存总量的限制。如果分配过多的直接内存,可能会导致本机内存不足,从而引发
OutOfMemoryError错误。
如何选择直接内存和堆内存?
- 性能需求:如果应用程序对性能要求较高,特别是在频繁进行 I/O 操作的情况下,可以考虑使用直接内存。但是,需要进行性能测试以确定直接内存是否确实能提高性能,因为在某些情况下,堆内存的性能可能更好。
- 内存管理:使用直接内存需要更加小心地管理内存,确保及时释放不再使用的内存。否则,可能会导致内存泄漏和本机内存耗尽。
- 应用场景:对于一些需要与本机代码进行交互或者需要大量内存的场景,直接内存可能更合适。而对于一般的应用程序,如果没有特殊的性能需求,堆内存可能是更简单和安全的选择