关于在自然语言处理深层语义分析中引入公理化体系的可行性、挑战与前沿展望
摘要
随着深度学习模型,特别是以Transformer为基础的预训练语言模型(如BERT、GPT系列)在自然语言处理(NLP)领域取得主导地位,学术界和工业界对模型的“黑箱”特性、逻辑推理能力的缺失以及可解释性的担忧日益加剧 。为了突破当前范式的局限,实现更深层次的、可信赖的语义理解,研究界重新将目光投向了符号主义AI,探索其与连接主义的融合之道。“神经-符号”(Neuro-Symbolic)方法应运而生 其中,引入公理化体系作为一种实现形式化、可解释推理的路径,展现出巨大的理论潜力。
本文章旨在系统性地分析公理化体系在NLP深层语义分析中的应用。报告将从公理模型的设计思路出发,深入探讨其关键技术实现要点,剖析在设计和实践中需注意的平衡点与核心挑战,并通过具体案例展示其应用潜力。最后,报告将对该领域的未来发展,特别是与小样本学习(Few-shot Learning)等前沿技术的结合,进行展望。
一、 公理模型在深层语义分析中的设计思路
将公理化体系引入深层语义分析的核心思想,在于为语言的语义表示建立一个形式化的、基于规则的逻辑框架,从而使机器不仅能“感知”文本模式,更能“理解”和“推理”其内在含义。这种设计思路可以分解为以下几个层面:
1. 核心元素的定义:原始概念与公理规则
- 原始概念(Primitive Concepts) :这是公理系统的基石。在NLP中,这些概念通常是语义的基本单元,例如语义角色(如施事者、受事者、工具、地点)、事件类型(如“交易”、“移动”、“创造”)、实体类别(如“人物”、“组织”、“时间”)等。这些概念构成了逻辑表达式的原子术语。
- 公理规则(Axiomatic Rules) :公理是在原始概念之上建立的一系列无需证明的、被认为是普适真理的逻辑断言。它们定义了概念之间的关系、约束和推理模式。例如,一条基础公理可以是:“若事件E的施事者(Agent)是X,受事者(Patient)是Y,则可推断出X对Y施加了一个动作关系
Action(X, Y)”。这些规则为语义推导提供了坚实的基础。
2. 形式化的逻辑表达
为了让机器能够处理,公理和由其推导出的语义信息必须用形式化语言进行表达。
- 一阶谓词逻辑(First-Order Predicate Logic) :这是一种强大且成熟的工具,能够清晰地表示实体、属性和关系。例如,句子“马云创立了阿里巴巴”可以表示为
创立(马云, 阿里巴巴)。 - λ演算(Lambda Calculus) :在语义解析(Semantic Parsing)任务中,λ演算常被用来将自然语言句子映射为可执行的逻辑形式或数据库查询 。例如,问题“科罗拉多州有哪些河流?”可能被解析为类似
answer(river(loc_2(stateid('colorado'))))的λ表达式(此示例源自用户提示,其思想与中提到的语义表达式相符),这种结构化的表达式非常适合作为公理推理系统的输入。
3. 句法结构的约束作用
公理推理并非凭空进行,它需要从文本的句法结构中获取初始输入和约束。依存句法分析(Dependency Parsing) 在此扮演了关键角色。依存树揭示了词语之间的支配和修饰关系,如主谓宾(nsubj-verb-dobj)结构,这可以直接映射为“施事者-事件-受事者”的初始语义角色假设,为后续的公理化推理提供结构化输入。
4. 知识图谱作为先验知识库
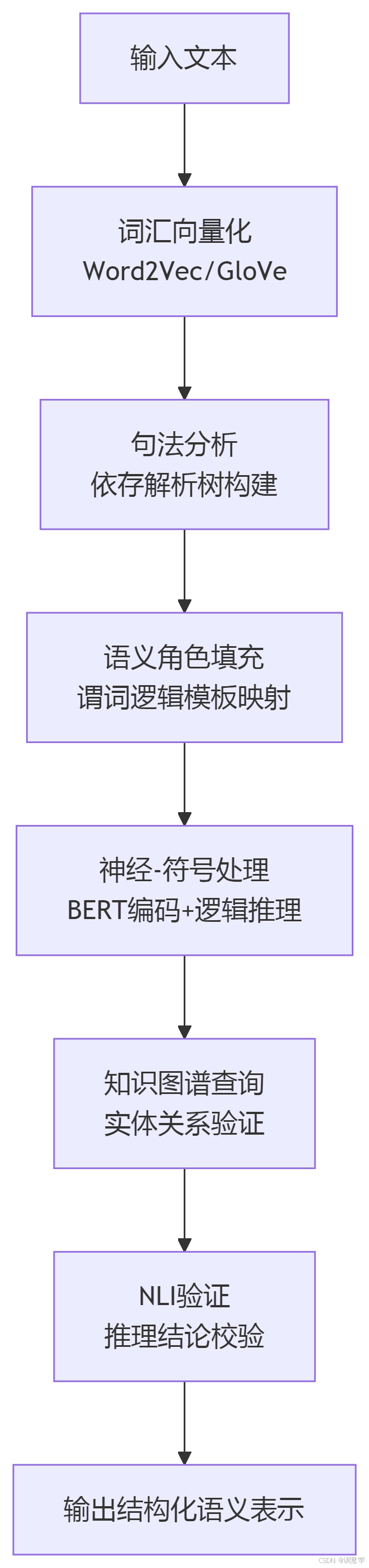
公理系统并非封闭的。知识图谱(Knowledge Graphs) 可以作为其外部的、大规模的“事实公理”知识库 。知识图谱中存储的大量实体关系(如“乔布斯 是 苹果公司的 创始人”)可以被视为公理实例。当模型进行推理时,可以查询知识图谱来验证或补充由文本推导出的结论,极大地丰富了公理系统的知识广度。
5. 逻辑推理机制的实现
经典的逻辑推理规则是公理模型进行语义推导的引擎。
- 分离规则(Modus Ponens) :即
(P ∧ (P → Q)) → Q。如果公理系统已知“P为真”且存在公理“若P则Q”,那么系统可以推断出“Q为真”。 - 三段论(Hypothetical Syllogism) :即
((P → Q) ∧ (Q → R)) → (P → R)。这允许系统通过链接一系列公理规则来构建更长的推理链。
6. 基于自然语言推理(NLI)的验证
为了弥合纯符号推理与复杂自然语言表达之间的鸿沟,可以引入 自然语言推理(NLI) 技术作为验证层。在公理系统得出一个结论后(例如,从“A公司收购了B公司”推导出“A公司现在拥有B公司”),可以利用强大的NLI模型(如基于BERT的模型 来判断这个推导出的结论是否与原始文本构成蕴含关系,从而为符号推理提供来自数据驱动模型的支持和校验。
二、 关键技术实现要点
将上述设计思路转化为一个可运行的系统,需要整合多种前沿技术,形成一个分层的、混合的架构。
1. 词汇-句法-语义的分层映射
这是一个自底向上的信息抽取和转换过程。首先,利用词嵌入模型(如Word2Vec、GloVe)将词汇转换为向量。接着,通过依存句法分析器构建句法树。然后,设计规则或训练模型,沿着依存路径(dependency path)抽取语义角色,并将其填充到预定义的谓词逻辑模板中,完成从非结构化文本到结构化逻辑表达式的映射。
2. 符号主义与连接主义的深度融合(神经-符号架构)
这是当前公理化方法实现的核心,也是最具挑战性的部分。单纯的符号系统过于脆弱,而单纯的神经网络缺乏可解释的推理能力 。神经-符号方法旨在取长补短 。
- 实现范式:典型的做法是使用一个强大的预训练语言模型(如BERT或其变体)作为“神经感知”前端 。BERT凭借其强大的上下文编码能力,可以生成高质量的文本和实体表示 。
- 集成方式:这些表示随后被送入一个“符号推理”后端。集成的具体方式多种多样:
- 流水线模式:BERT负责识别实体、关系和事件触发词,其输出作为符号推理机(如Prolog引擎)的输入事实 。
- 向量映射:将BERT生成的上下文向量映射到谓词逻辑中的变量或常量,让逻辑推理过程可以利用这些富含语义的表示。
- 混合训练:设计一个包含神经模块损失和符号约束损失的联合损失函数,通过端到端训练使神经网络的输出自然地满足公理约束 。例如,一个研究方向是探索将符号知识注入到BERT的嵌入层中 ,或者利用BERT生成可由符号化程序执行的代码来回答问题 。
3. 动态可扩展的公理模块
一个通用的公理集难以覆盖所有领域。因此,系统设计应是模块化的,允许针对特定领域(如医疗、法律、金融)动态加载专属的公理模块。例如,在医疗领域,可以定义关于“药物-疾病-症状”的特定公理,这能显著提升模型在专业任务上的准确性和实用性。
4. 矛盾检测机制
公理系统的一大优势在于其维持逻辑一致性的能力。通过明确定义互斥关系(例如,公理:“若药物X是抗生素,则X不具有抗病毒功效”),系统可以在推理过程中实时检测并标记语义矛盾,这对于事实核查、信息可信度判断等应用至关重要。
5. 增强可解释性的可视化工具
为了充分发挥公理模型的可解释性优势,开发配套的可视化工具至关重要。例如,可以设计一个界面,将最终的推理结论以图形化方式展示出来,其推理路径(即激活了哪些公理)可以与原始文本的依存句法树叠加显示,让用户能够清晰地追溯和理解模型的决策过程。
6. 面向白盒的量化评估指标
传统的NLP评估严重依赖于端到端的黑盒指标,如准确率、F1值等 。这些指标无法衡量模型推理过程的正确性。当前,NLP领域尚缺乏专门为公理化或神经-符号系统设计的标准化评估基准 (根据对的综合分析)。因此,设计新的评估体系成为一个关键要点,例如:
- 公理覆盖率(Axiom Coverage) :评估在测试集中,模型的推理过程利用了多少比例的预定义公理。
- 公理推理准确率(Axiom Inference Accuracy) :人工标注一批数据的正确推理路径,评估模型生成的推理链与“黄金标准”的匹配度。
这些“白盒”指标能够补充现有基准(如GLUE、SQuAD 的不足,为模型提供更全面的评估。
三、 设计注意事项与核心挑战
尽管前景广阔,但在设计和应用公理模型时,必须审慎处理一系列内在的矛盾和挑战。
1. 抽象性与领域适配性的平衡
公理的设计需要在通用性(抽象性)和特定性(领域适配性)之间取得平衡。过于抽象的公理(如“实体之间存在关系”)缺乏实用价值;而过于具体的公理(如针对某个特定产品的规则)则会导致泛化能力差。一个好的实践是,在核心模型中只保留最本质、最稳定的公理集(如时间、空间、因果等核心概念),而将易变的业务逻辑相关的公理外移到可插拔的服务层或领域模块中。
2. 最小公理集的定义与维护
公理系统的复杂性会随着规则数量的增加而呈指数级增长。因此,定义一个“最小完备公理集”至关重要。这要求公理之间应尽可能满足独立性(无冗余)、一致性(无内在矛盾)和对目标领域的完备性(足以覆盖主要推理场景)。这需要大量的专家知识和反复的迭代验证,知识获取本身就是一个巨大的瓶颈。
3. 上下文敏感的推理
自然语言具有高度的上下文依赖性。同一个谓词在不同语境下可能触发完全不同的语义框架和公理。例如,“打开”在“打开一扇门”和“打开一个文件”中,其背后的物理操作和数字操作截然不同。解决这一挑战的关键在于前文提到的神经-符号融合,可以利用Transformer的注意力机制,根据BERT编码的全局上下文动态地为不同的公理分配权重或选择最合适的公理子集。
4. 公理的增量学习与自动发现
手动定义和维护一个大规模公理集成本极高且难以扩展。因此,系统需要具备增量学习机制,能够从新的语料中自动或半自动地发现潜在的公理。可以借鉴关联规则挖掘、因果推断等技术,在知识图谱或大规模文本中挖掘频繁出现的、稳定的实体关系模式,并将其作为候选公理提交给专家审核。
5. 计算效率问题
复杂的逻辑推理,特别是涉及全局优化的图算法(如图匹配或全局最优的依存分析算法Eisner),其计算复杂度通常很高(例如O(n³)或更高),这在处理长文本或要求实时响应的场景中是不可接受的。因此,需要在推理的完备性与计算效率之间做出权衡,例如采用基于转移(transition-based)的轻量级解析方法(如Arc-Eager),或者对推理深度和广度进行剪枝。
6. 多语言与低资源场景的适配
为每种语言都构建一套独立的公理系统是不现实的。一个可行的方案是利用多语言预训练模型(如mBERT、XLM-R)生成跨语言对齐的语义表示。在此基础上,可以构建一个共享的核心公理层,再辅以少量针对特定语言语法特性的适配规则,从而实现向多语言和低资源语言的迁移。
四、 实际应用场景示例
为了更具体地说明公理模型的运作方式,我们以一个复杂的问答场景为例:
输入问题:“谁创立了阿里巴巴并出生在杭州?”
一个基于公理的深层语义分析系统会按以下步骤处理:
句法与语义解析:系统首先解析问题,识别出这是一个关于人物“谁(X)”的查询,并且包含两个并列的条件:
- 条件1:
创立(X, 阿里巴巴) - 条件2:
出生于(X, 杭州)
- 条件1:
实体链接:系统将“阿里巴巴”链接到知识图谱中的实体
dbr:Alibaba_Group,将“杭州”链接到dbr:Hangzhou。公理应用与推理:
- 系统激活相关公理进行类型约束和推理。
- 公理1 (类型公理):
创立(X, Y) → 人物(X) ∧ 组织(Y)。此公理确认了待查目标X的类型是“人物”。 - 公理2 (地点公理):
出生于(X, Z) → 人物(X) ∧ 地点(Z)。此公理再次确认X是“人物”,Z是“地点”。 - 公理3 (查询分解公理):
查询(P(X) ∧ Q(X)) → Intersect(Find(X|P(X)), Find(X|Q(X)))。此公理指示系统分别执行两个子查询,然后取结果的交集。
知识库查询与答案生成:
- 子查询1:在知识图谱中执行
Find(X | 创立(X, dbr:Alibaba_Group)),返回结果集 {dbr:Jack_Ma,dbr:Peng_Lei, ...}。 - 子查询2:在知识图谱中执行
Find(X | 出生于(X, dbr:Hangzhou)),返回结果集 {dbr:Jack_Ma,dbr:Yu_Hua, ...}。 - 交集操作:系统计算两个结果集的交集,得到唯一的答案 {
dbr:Jack_Ma}。
- 子查询1:在知识图谱中执行
自然语言生成:系统将最终实体
dbr:Jack_Ma转化为自然语言“马云”作为最终输出。
在这个过程中,公理不仅指导了查询的分解和执行,还提供了类型检查和逻辑约束,使得整个问答过程清晰、透明且可验证。
总结与未来展望
截至2025年,将公理化体系引入NLP深层语义分析,代表了从纯数据驱动向知识与数据协同驱动范式转变的重要方向。构建这样一个系统的核心在于:以形式化逻辑为内核,保证推理的严谨性和可解释性;以神经-符号混合架构为支撑,利用深度学习模型强大的表示能力弥合语言与逻辑之间的鸿沟。然而,该路径的成功与否,取决于能否在公理的抽象性与领域适配性、逻辑的完备性与计算的高效性、系统的可解释性与易用性之间找到精妙的平衡。
展望未来,该领域至少有两个极具潜力的发展方向:
与小样本学习(Few-Shot Learning, FSL)的结合:当前研究显示,将FSL与公理模型结合的直接探索仍然非常稀少 (根据对等多个相关查询的分析)。这是一个巨大的机遇。公理获取是系统的主要瓶颈,而FSL,特别是大型语言模型(如GPT系列)展示出的上下文学习能力 有望通过少量示例快速生成或适配特定领域的公理规则,从而极大地降低公理系统的构建门槛,加速其在低资源领域的落地 。
向多模态语义理解的扩展:未来的AI需要理解整合了文本、图像、声音等多种信息的世界。公理系统可以作为跨模态推理的统一框架。例如,通过定义跨模态的公理(如“图像中
位于文本描述的‘桌子’上方的物体是‘苹果’”),模型可以对图文信息进行联合推理,实现比单一模态更深刻的场景理解。
综上所述,虽然公理化方法在NLP中的实际应用仍处于探索阶段,且面临诸多挑战,但它为解决当前深度学习模型的根本性缺陷提供了清晰的理论路径。随着神经-符号技术的不断成熟以及与FSL等多项前沿技术的融合,基于公理的深层语义分析系统有望在未来要求高可靠性、高可解释性的关键NLP应用中发挥不可或缺的作用。
关键代码示例(神经-符号架构伪代码):
# 神经-符号集成示例(流水线模式)
import torch
from transformers import BertTokenizer, BertModel
from logic_reasoner import PrologEngine # 假设的符号推理引擎# BERT前端处理
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
model = BertModel.from_pretrained('bert-base-uncased')
inputs = tokenizer("马云创立了阿里巴巴", return_tensors="pt")
outputs = model(**inputs)# 实体和关系提取(简化示例)
entities = extract_entities(outputs.last_hidden_state)
relations = extract_relations(outputs.last_hidden_state)# 转换为符号事实
facts = []
for rel in relations:facts.append(f"{rel.type}({rel.subject}, {rel.object})")# 符号推理引擎
engine = PrologEngine()
engine.load_axioms('core_axioms.pl') # 加载公理库
engine.add_facts(facts)
result = engine.query("创始人(谁, 阿里巴巴)") # 执行查询
print(result) # 输出: ['马云']以下是一个简化的神经-符号推理系统的代码框架,展示了如何结合神经网络与符号推理:
import torch
from transformers import AutoTokenizer, AutoModel
import numpy as np# 1. 神经感知模块:使用预训练模型获取上下文表示
class NeuralPerception:def __init__(self, model_name="bert-base-uncased"):self.tokenizer = AutoTokenizer.from_pretrained(model_name)self.model = AutoModel.from_pretrained(model_name)def extract_entities_relations(self, text):inputs = self.tokenizer(text, return_tensors="pt", padding=True, truncation=True)with torch.no_grad():outputs = self.model(**inputs)# 实际应用中这里会有更复杂的实体和关系提取逻辑return {"entities": [...], "relations": [...]}# 2. 符号推理模块:处理公理和应用逻辑规则
class SymbolicReasoner:def __init__(self):self.axiom_base = self.load_axioms()self.knowledge_base = self.load_knowledge_graph()def load_axioms(self):# 定义核心公理集axioms = {"founder_type": "∀x, y (Founder(x, y) → Person(x) ∧ Organization(y))","born_in_type": "∀x, z (BornIn(x, z) → Person(x) ∧ Location(z))","query_intersection": "Query(P(x) ∧ Q(x)) → Intersect(Find(x|P(x)), Find(x|Q(x)))"}return axiomsdef apply_axioms(self, query_structure):# 应用公理进行推理和类型约束reasoning_steps = []# 实际应用中这里会有复杂的逻辑推理return reasoning_steps# 3. 主控制系统:整合神经和符号组件
class NeuroSymbolicSystem:def __init__(self):self.neural_module = NeuralPerception()self.symbolic_module = SymbolicReasoner()def answer_question(self, question):# 神经模块处理neural_output = self.neural_module.extract_entities_relations(question)# 符号模块处理symbolic_output = self.symbolic_module.apply_axioms(neural_output)# 知识库查询和答案生成final_answer = self.query_knowledge_base(symbolic_output)return final_answer, symbolic_output # 返回答案和推理路径def query_knowledge_base(self, symbolic_output):# 模拟知识图谱查询# 实际应用中会连接真实知识库如Wikidata或DBpediareturn "马云"# 使用示例
if __name__ == "__main__":system = NeuroSymbolicSystem()question = "谁创立了阿里巴巴并出生在杭州?"answer, reasoning_path = system.answer_question(question)print(f"问题: {question}")print(f"答案: {answer}")print(f"推理路径: {reasoning_path}")