AI编程:重塑软件开发范式的三大支柱
引言
我们正站在软件开发范式转移的关键节点。传统的“手动编写每一行代码”的模式正在被一种新的、由人工智能驱动的协作模式所取代。这场变革的核心是三大相互关联的支柱:自动化代码生成、低代码/无代码开发 和 AI辅助的算法优化。它们并非要完全取代开发者,而是将开发者从重复性、机械性的劳动中解放出来,使其能更专注于架构设计、创造性解决问题和核心业务逻辑等更高价值的工作。本文将深入探讨这三大领域,通过技术细节、实践案例和未来展望,描绘出一幅AI如何重塑编程世界的全景图。
第一部分:自动化代码生成
自动化代码生成是指利用AI模型,根据自然语言描述、部分代码片段或规范自动生成完整、可用代码的技术。其核心是大型语言模型在代码语料上进行的预训练。
1.1 技术核心:基于Transformer的代码模型
当前的代码生成模型(如OpenAI的Codex、Salesforce的CodeT5、Hugging Face的StarCoder)大多基于Transformer架构。它们在包含代码和注释的海量数据集上进行训练,学会了编程语言的语法、语义乃至一些常见模式和实践。
流程图:自动化代码生成的工作流程
flowchart TDA[用户输入自然语言Prompt] --> B(AI代码模型<br>如GPT-4, CodeLlama)B -- 推理生成 --> C{生成代码}C --> D[单元测试生成]C --> E[代码解释生成]C --> F[功能代码生成]D --> G[执行与测试]E --> H[验证与学习]F --> GG --> I{测试通过?}I -- Yes --> J[✅ 代码集成]I -- No --> K[❌ 错误反馈]K --> B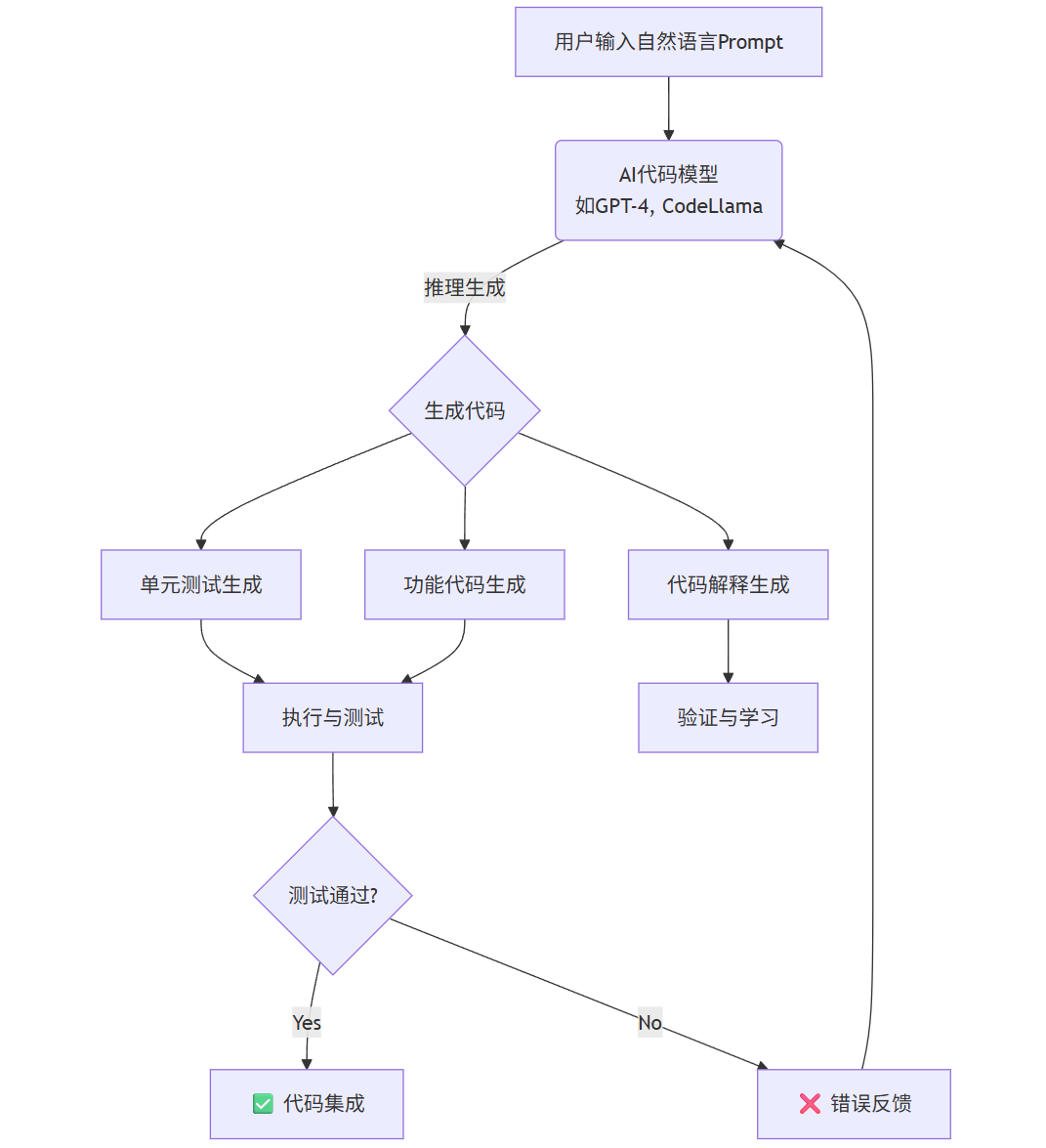
1.2 实践示例:使用OpenAI API生成Python代码
以下是一个使用OpenAI API(模拟)根据自然语言描述生成Python代码的示例。
Prompt示例:
text
请生成一个Python函数,名为 `calculate_statistics`,它接受一个数字列表作为输入,并返回一个字典,包含该列表的平均值、中位数、众数、最大值和最小值。要求使用标准库,并处理空列表的情况。
生成的代码可能如下所示:
python
from typing import List, Dict, Optional
from statistics import mode, median, meandef calculate_statistics(numbers: List[float]) -> Optional[Dict[str, Optional[float]]]:"""计算一个数字列表的描述性统计信息。Args:numbers: 一个包含数字的列表。Returns:一个包含以下键的字典:- 'mean': 平均值,如果列表为空则为None- 'median': 中位数,如果列表为空则为None- 'mode': 众数,如果列表为空或没有众数则为None- 'max': 最大值,如果列表为空则为None- 'min': 最小值,如果列表为空则为None"""if not numbers:return {'mean': None,'median': None,'mode': None,'max': None,'min': None}try:mode_value = mode(numbers)except StatisticsError: # 处理没有唯一众数的情况mode_value = Nonereturn {'mean': mean(numbers),'median': median(numbers),'mode': mode_value,'max': max(numbers),'min': min(numbers)}# 测试函数
if __name__ == "__main__":test_data = [1, 2, 3, 4, 5, 5, 6]stats = calculate_statistics(test_data)print(stats)# 输出: {'mean': 3.714..., 'median': 4, 'mode': 5, 'max': 6, 'min': 1}empty_stats = calculate_statistics([])print(empty_stats)# 输出: {'mean': None, 'median': None, 'mode': None, 'max': None, 'min': None}代码分析:
类型提示: 生成的代码包含了丰富的类型提示,提高了代码的可读性和可维护性。
文档字符串: 生成了完整的Google风格文档字符串,说明了参数和返回值。
异常处理: 正确处理了空列表和没有唯一众数的情况,体现了模型的逻辑严密性。
标准库使用: 按照要求使用了
statistics标准库。
1.3 高级应用:上下文学习与代码补全
更强大的代码生成工具(如GitHub Copilot、Amazon CodeWhisperer)能够集成到IDE中,理解当前文件的上下文(如导入的库、已定义的变量、函数等),提供更精准的代码补全和建议。
Prompt示例(在IDE中):
假设你正在编写一个FastAPI应用,已经定义了一个Pydantic模型Item和一个列表items。当你开始输入以下代码时:
python
@app.get("/items/{item_id}")
def read_item(item_id: int):# 此时AI可能会自动建议完整的函数体for item in items:if item.id == item_id:return itemreturn {"error": "Item not found"}AI会根据@app.get装饰器、已有的Item模型和items列表,自动推断出你的意图是查找一个特定ID的item,并生成相应的代码。
第二部分:低代码/无代码开发
低代码/无代码平台通过图形化界面、拖拽组件和模型驱动逻辑,让非专业开发者或业务专家也能构建应用程序。AI的融入使这些平台变得更加智能和强大。
2.1 AI在LCNC中的角色
智能组件推荐: 根据用户正在构建的界面,AI推荐最可能被用到的下一个组件(如表单、按钮、图表)。
自然语言到UI: 用户用文字描述想要的界面(如“创建一个包含姓名、邮箱输入框和提交按钮的用户注册表单”),AI自动生成对应的UI组件和布局。
工作流自动化: 用自然语言描述业务逻辑(如“当新订单产生时,如果金额大于1000元,则发邮件给经理并通知库存系统”),AI自动生成对应的流程图或配置规则。
数据模型生成: 根据描述性的需求文档,AI自动推断并生成数据库表结构(Schema)。
2.2 实践示例:使用AI辅助构建一个简单的数据看板
假设我们使用一个虚构的名为“SmartBuilder”的AI增强型低代码平台。
步骤1: 用自然语言创建数据源
用户输入: “连接到我公司的MySQL数据库,读取‘sales’表中的所有数据。”
AI动作: 自动生成数据库连接字符串的配置界面,并预填充了可能的数据表字段映射。
步骤2: 用自然语言设计UI
用户输入: “我想要一个仪表板,顶部是一个显示总销售额的卡片,中间是一个按月份展示销售额趋势的折线图,底部是一个按产品类别分类的销售额饼图。”
AI动作:
自动布局页面,创建所需的卡片和图表组件。
自动为“总销售额卡片”绑定SQL查询:
SELECT SUM(amount) FROM sales。自动为“折线图”生成查询:
SELECT MONTH(sale_date) AS month, SUM(amount) AS total_sales FROM sales GROUP BY MONTH(sale_date)。自动为“饼图”生成查询:
SELECT category, SUM(amount) AS total_sales FROM sales GROUP BY category。
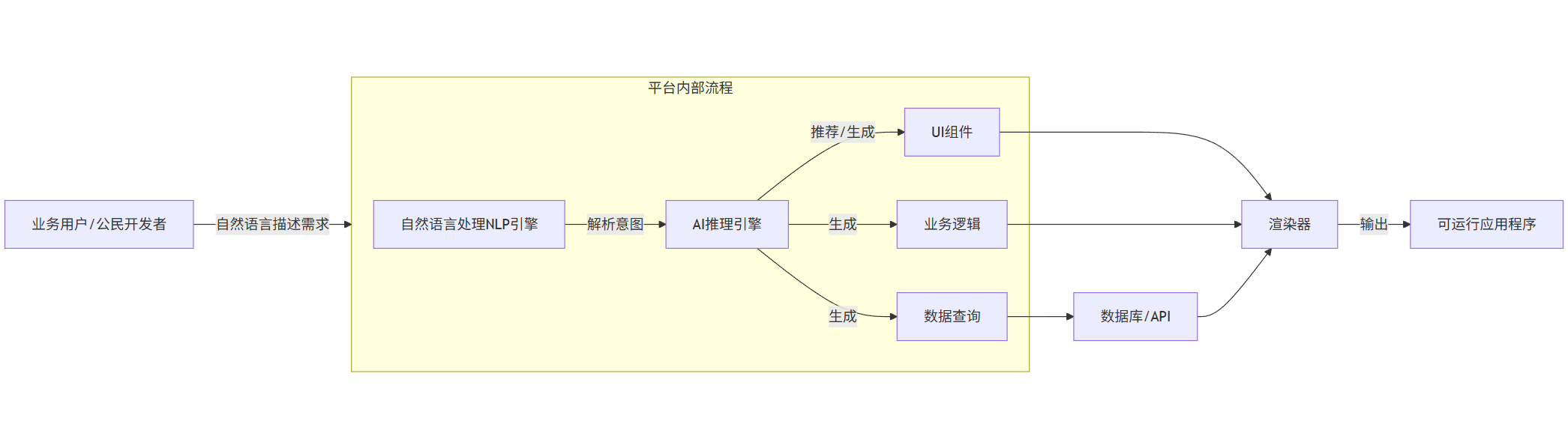
流程图:AI增强的低代码应用开发流程
flowchart LRU[业务用户/公民开发者] -->|自然语言描述需求| P[AI低代码平台]subgraph P [平台内部流程]direction TBNLP[自然语言处理NLP引擎]NLP -->|解析意图| AI_Engine[AI推理引擎]AI_Engine -->|推荐/生成| Com[UI组件]AI_Engine -->|生成| Logic[业务逻辑]AI_Engine -->|生成| DataQuery[数据查询]endCom --> R[渲染器]Logic --> RDataQuery --> DB[数据库/API]DB --> RR -->|输出| App[可运行应用程序]
2.3 从UI到后端:AI生成完整CRUD应用
更先进的平台能从一个概念生成前后端全部代码。
Prompt示例(对平台说):
“创建一个员工管理系统,包含员工ID、姓名、部门、入职日期字段。支持增删改查和按部门筛选。”
AI可能生成的输出结构:
text
employee-management-system/ ├── backend/ │ ├── models/Employee.py # Pydantic/SQLAlchemy 模型 │ ├── routes/employees.py # FastAPI/Flask 路由 (GET, POST, PUT, DELETE) │ └── main.py # 应用入口 ├── frontend/ │ ├── src/ │ │ ├── components/EmployeeTable.vue # 员工表格组件 │ │ ├── components/EmployeeForm.vue # 表单组件 │ │ └── views/HomeView.vue # 主视图 │ └── package.json └── database.sql # 数据库建表语句
AI不仅生成了基本的代码骨架,甚至可能包含表单验证、错误处理等细节,极大地提升了开发效率。
第三部分:AI辅助的算法优化实践
对于专业开发者而言,AI不仅是代码生成器,更是高级的“结对编程”伙伴,尤其在复杂的算法优化和系统调优方面。
3.1 算法选择与优化建议
当开发者编写了一段性能关键的代码时,AI可以分析其时间/空间复杂度,并提出优化建议或替代算法。
示例:优化一个低效的查找函数
原始代码:
python
def find_duplicates(nums):"""查找列表中的所有重复元素。"""duplicates = []for i in range(len(nums)):for j in range(i + 1, len(nums)):if nums[i] == nums[j] and nums[i] not in duplicates:duplicates.append(nums[i])return duplicates
向AI提问的Prompt:
“请分析以下Python函数的时间复杂度,并提出一个更高效的优化方案。”
AI的反馈可能包括:
复杂度分析: “该函数的时间复杂度为O(n²),内部使用了嵌套循环,并且
not in列表操作在最坏情况下也是O(n),导致总体复杂度接近O(n³)。空间复杂度为O(k),k是重复元素的数量。”优化建议: “建议使用哈希集合来记录已见过的元素,将时间复杂度降低到O(n)。”
优化后的代码:
python
def find_duplicates_optimized(nums):"""使用集合来高效查找重复元素。"""seen = set()duplicates = set()for num in nums:if num in seen:duplicates.add(num)else:seen.add(num)return list(duplicates)
3.2 代码重构与现代化
AI可以帮助将旧的代码风格或库迁移到新的、更佳实践的模式。
Prompt示例:
“将以下使用requests库的同步HTTP请求代码,重构为使用aiohttp的异步版本。”
原始代码:
python
import requestsdef fetch_urls(urls):results = []for url in urls:response = requests.get(url)results.append(response.text)return results
AI生成的重构代码:
python
import aiohttp import asyncioasync def fetch_url(url, session):async with session.get(url) as response:return await response.text()async def fetch_urls_async(urls):async with aiohttp.ClientSession() as session:tasks = [fetch_url(url, session) for url in urls]results = await asyncio.gather(*tasks)return results# 使用示例 # urls = ['http://example.com/1', 'http://example.com/2'] # results = asyncio.run(fetch_urls_async(urls))
3.3 性能剖析与瓶颈识别
AI可以模拟或分析代码的性能剖面,指出热点和瓶颈所在。
假设我们有一段复杂的数据处理脚本,运行缓慢。
Prompt: “以下代码运行很慢,请分析可能的原因并提出改进方法。”
python
# ... 一段很长的数据处理代码 ...
AI可能回复:
“检测到在循环内部多次调用了一个计算昂贵的函数
expensive_calculation(x)。建议使用缓存(如functools.lru_cache)或预计算其结果。”“发现循环中进行了大量的列表拼接操作
result += [new_item],这在Python中非常低效。建议改为使用列表推导式或预先分配列表。”“注意到您使用了Pandas的
iterrows(),对于大型DataFrame,这是性能杀手。建议使用向量化操作或apply()方法进行优化。”
第四部分:挑战与未来展望
4.1 当前挑战
幻觉与准确性: AI可能会生成语法正确但逻辑错误或完全虚构的代码(尤其是使用不熟悉的库时)。必须进行严格的人工审查和测试。
安全漏洞: 生成的代码可能包含安全漏洞(如SQL注入、XSS等)。开发者需要具备足够的安全意识来识别这些问题。
知识产权与合规性: 训练数据的版权问题以及生成代码的版权归属尚存在法律灰色地带。
依赖与黑盒: 过度依赖AI可能导致开发者技能退化,并且对AI生成的复杂代码的理解和调试本身可能成为一个新挑战。
4.2 未来展望
AI原生开发环境: IDE将深度集成AI,从被动的代码补全变为主动的协作伙伴,实时提供架构建议、错误预警和优化方案。
自我调试与修复: AI将能够自动理解错误信息,定位bug,并生成修复补丁或编写单元测试。
需求到代码的直接转换: AI能力进一步增强,可能只需产品需求文档(PRD)或详细的用户故事,就能直接生成一个可运行的原型系统。
个性化与上下文感知: AI模型将更深入地理解单个开发者的编码风格、项目的特定技术栈和业务领域知识,提供高度个性化的支持。
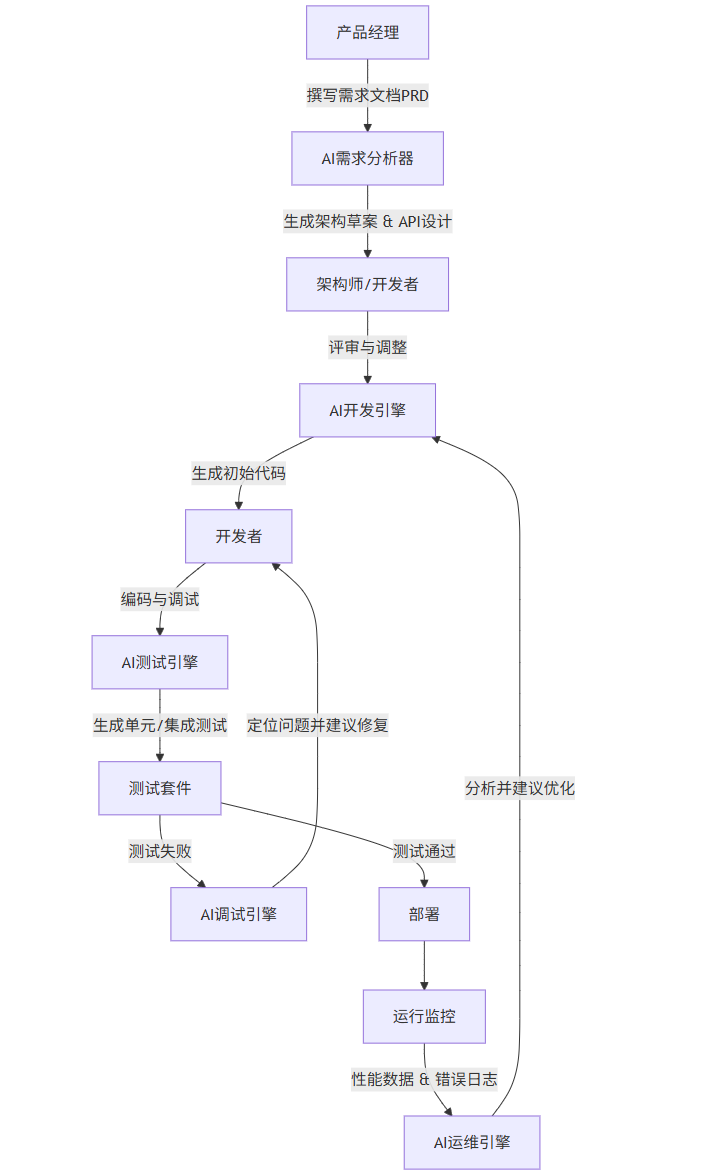
未来软件开发循环图
flowchart TDPM[产品经理] -->|撰写需求文档PRD| AI_Req[AI需求分析器]AI_Req -->|生成架构草案 & API设计| Arch[架构师/开发者]Arch -->|评审与调整| AI_Dev[AI开发引擎]AI_Dev -->|生成初始代码| Dev[开发者]Dev -->|编码与调试| AI_Test[AI测试引擎]AI_Test -->|生成单元/集成测试| Tests[测试套件]Tests -- 测试失败 --> AI_Debug[AI调试引擎]AI_Debug -->|定位问题并建议修复| DevTests -- 测试通过 --> Deploy[部署]Deploy --> Monitor[运行监控]Monitor -- 性能数据 & 错误日志 --> AI_Ops[AI运维引擎]AI_Ops -->|分析并建议优化| AI_Dev
结论
AI编程不是遥远的未来,而是正在发生的现实。自动化代码生成、低代码/无代码开发和算法优化实践这三大支柱,正在共同构建一个全新的软件开发范式。
对于开发者而言,这不是一场“取代”的危机,而是一次“进化”的机遇。未来的成功开发者,将是那些能够高效利用AI作为强大杠杆的人。他们的核心价值将不再是 memorizing syntax 或 writing boilerplate code,而是体现在提出正确的问题(Prompt Engineering)、进行精准的架构设计、做出明智的技术决策、严格审查AI输出以及解决更复杂的抽象问题上。
拥抱AI,善用工具,持续学习,专注于创造力和批判性思维,这将是我们在这个AI时代保持领先的关键。这场变革最终将释放出巨大的生产力,让软件更快、更好、更普惠地服务于社会的每一个角落。