shell-awk命令详解(理论+实战)
文章目录
- shell-awk命令详解(理论+实战)
- 一、概述
- 二、工作原理
- 三、工作流程
- 四、基本语法
- 五、实战案例
- 5.1 基础字段处理(分隔符、字段打印)
- 5.2 内建变量实战
- 5.3 BEGIN与END块应用
- 5.4 模式匹配(模糊/精确匹配)
- 5.5 高级用法(if语句、数组、循环)
- 5.6 生产脚本编写(示例:监控SSH登录失败)
- 5.7 文本提取(示例:提取jar包版本号)
- 六、总结:awk与grep、sed的区别
shell-awk命令详解(理论+实战)
一、概述
AWK 是一种处理文本文件的语言,是一个强大的文本分析工具。它是专门为文本处理设计的编程语言,也是行处理软件,通常用于扫描、过滤、统计汇总工作,数据可以来自标准输入也可以是管道或文件。20世纪70年代诞生于贝尔实验室,现在centos7用的是gawk之所以叫 AWK 是因为其取了三位创始人 Alfred Aho,Peter Weinberger, 和 Brian Kernighan 的 Family Name 的首字符。
awk:Aho, Weinberger, Kernighan,报告生成器,格式化文本输出,GNU/Linux发布的AWK目前由自由软件基金会(FSF)进行开发和维护,通常也称它为 GNU AWK
有多种版本:
-
AWK:原先来源于 AT & T 实验室的的AWK
-
NAWK:New awk,AT & T 实验室的AWK的升级版
-
GAWK:即GNU AWK。所有的GNU/Linux发布版都自带GAWK,它与AWK和NAWK完全兼容
二、工作原理
当读到第一行时,匹配条件,然后执行指定动作,再接着读取第二行数据处理,不会默认输出
如果没有定义匹配条件默认是匹配所有数据行,awk隐含循环,条件匹配多少次动作就会执行多少次
逐行读取文本,默认以空格或tab键为分隔符进行分隔,将分隔所得的各个字段保存到内建变量中,并按模式或者条件执行编辑命令。
sed命令常用于一整行的处理,而awk比较、倾向于将一行分成多个"“字段"然后再进行处理。awk信息的读入也是逐行读取的,执行结果可以通过print的功能将字段数据打印显示。在使用awk命令的过程中,可以使用逻辑操作符” &&“表示"与”、“||表示"或”、"!“表示非”;还可以进行简单的数学运算,如+、一、*、/、%、^分别表示加、减、乘、除、取余和乘方。
三、工作流程
pattern [ˈpætn] 模式 ; process [ˈprəʊses] 处理
任何 awk 语句都是由模式和动作组成,一个 awk 脚本可以有多个语句。模式决定动作语句的触发条件和触发时间。
四、基本语法
k 选项’ 模式或条件{操作}’ 文件1 文件2 …
awk -f 脚本文件 文件1 文件2 …
格式:awk关键字 选项 命令部分 ‘{xxxx}’ 文件名
**AWK 支持两种不同类型的变量:内建变量(可直接使用),自定义变量awk 内置变量(预定义变量)
如下所示:
- FS:指定每行文本的字段分隔符,默认为空格或制表位。
- NF:当前处理的行的字段个数。在执行过程中对应于当前的字段数,NF:列的个数
- NR:当前处理的行的行号(序数)。 在执行过程中对应于当前的行号
- $0:当前处理的行的整行内容。
- $n:当前处理行的第 n 个字段(第 n 列)。比如: $1 表示第一个字段,$2 表示第二个字段
- FILENAME:被处理的文件名(当前输入文件的名)。
- FNR 各文件分别计数的行号
- OFS 输出字段分隔符(默认值是一个空格)
- ORS 输出记录分隔符(默认值是一个换行符)
- RS:行分隔符。awk从文件上读取资料时,将根据Rs的定义把资料切割成许多条记录, 而awk一次仅读入一条记录,以进行处理。预设值是" \n’
简说:数据记录分隔,默认为\n,即每行为一条记录
五、实战案例
5.1 基础字段处理(分隔符、字段打印)
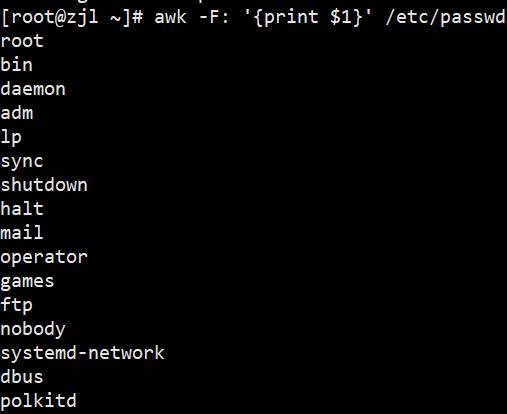
# 方法1:用-F指定分隔符(冒号),打印/etc/passwd的第1列(用户描述)
awk -F: '{print $1}' /etc/passwd# 方法2:用FS内建变量指定分隔符(冒号),效果同上
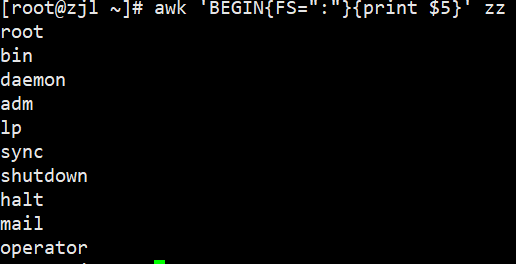
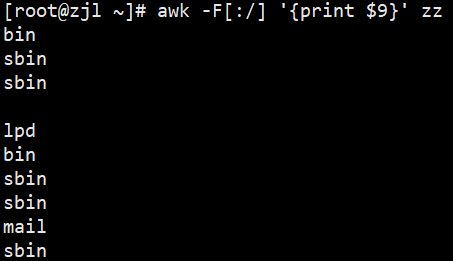
awk 'BEGIN{FS=":"}{print $5}' zz# 指定多个分隔符(冒号或斜杠),打印第9列
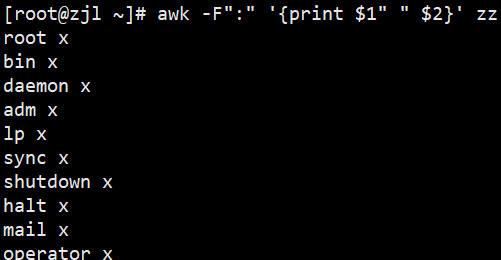
awk -F[:/] '{print $9}' zz# 1. 空格分隔打印第一、二字段
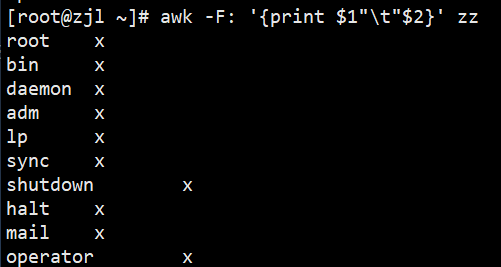
awk '{print $1" "$2}' zz# 2. Tab键分隔打印第一、二字段
awk -F: '{print $1"\t"$2}' zz# 3. 用OFS设“---”为输出分隔符,打印第一、二字段
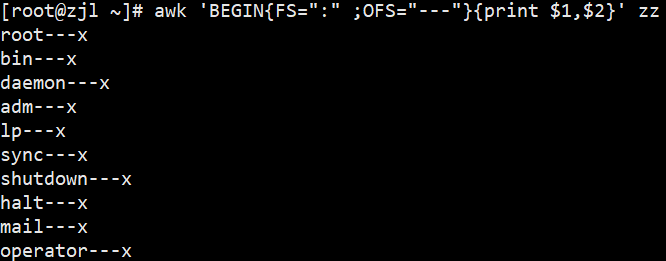
awk 'BEGIN{FS=":";OFS="---"}{print $1,$2}' zz
5.2 内建变量实战
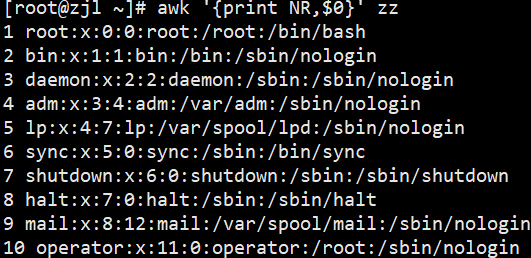
# 1. 打印行号(NR)和整行内容,连续计数(跨文件)
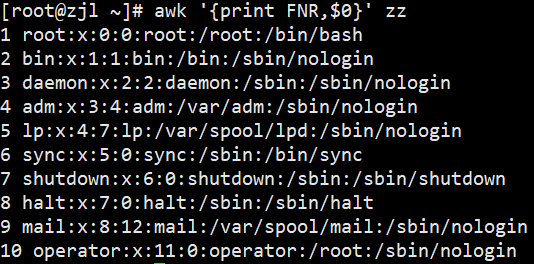
awk '{print NR,$0}' zz# 2. 打印各文件分别计数的行号(FNR)
awk '{print FNR,$0}' zz# 3. 打印每行的列数(NF)和行号(NR)
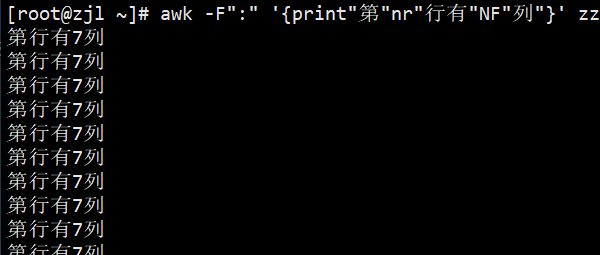
awk -F: '{print "第"NR"行有"NF"列"}' /etc/passwd# 4. 打印最后一列($NF)
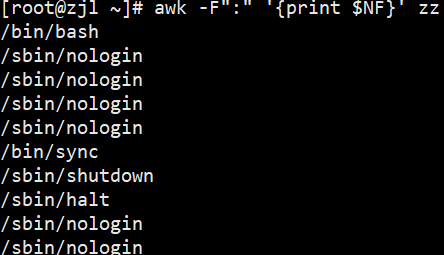
awk -F: '{print $NF}' zz# 1. 提取网卡ens33的IP地址
ifconfig ens33 | awk '/netmask/{print "本机IP:"$2}'# 2. 提取ens33的接收流量(RX)
ifconfig ens33 | awk '/RX p/{print "接收流量:"$5"字节"}'# 3. 提取根分区可用空间(df -h的第二行第四列)
df -h | awk 'NR==2{print "根分区可用:"$4}'# 4. 查看内存使用百分比
free -m | awk '/Mem:/ {print int($3/($3+$4)*100)"%"}'


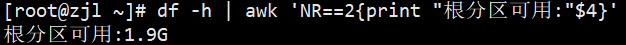

5.3 BEGIN与END块应用
# 1. 统计以“/bin/bash”结尾的行(即普通用户数)
awk 'BEGIN{x=0};/\/bin\/bash$/ {x++;print x,$0};END {print "普通用户总数:"x}' /etc/passwd# 2. 等同于grep统计(验证结果)
grep -c "/bin/bash$" /etc/passwd# 1. 变量初始化与自增
awk 'BEGIN{x=10;x++;print x}'# 2. 小数运算
awk 'BEGIN{print 2.5+3.5}'# 3. 幂运算(^和**均表示幂)
awk 'BEGIN{print 2^3,3**2}'





5.4 模式匹配(模糊/精确匹配)
# 1. 第一字段包含“ro”的行
awk -F: '$1~/ro/' /etc/passwd# 2. 第七字段不包含“nologin”的行(打印第一、七字段)
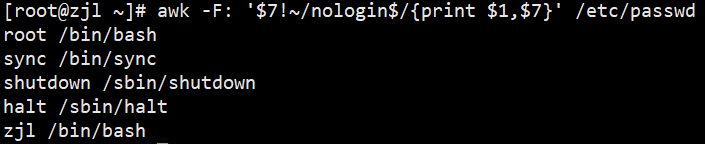
awk -F: '$7!~/nologin$/{print $1,$7}' /etc/passwd# 1. 行号等于5的行
awk 'NR==5{print}' /etc/passwd# 2. 第三字段(UID)等于0的行(root用户)
awk -F: '$3==0{print $1,$3}' /etc/passwd# 3. 第三字段(UID)>=1000的行(普通用户)
awk -F: '$3>=1000{print $1,$3}' /etc/passwd# 1. 行号大于4且小于10的行
awk -F: 'NR>4 && NR<10{print NR,$1}' /etc/passwd# 2. 第三字段<10或>=1000的行
awk -F: '$3<10 || $3>=1000{print $1,$3}' /etc/passwd





5.5 高级用法(if语句、数组、循环)
# 1. 单分支:第三字段<10的行,打印整行
awk -F: '{if($3<10){print $0}}' /etc/passwd# 2. 双分支:第三字段<10打印第三字段,否则打印第一字段
awk -F: '{if($3<10){print $3}else{print $1}}' /etc/passwd# 1. 数字下标数组
awk 'BEGIN{a[0]=10;a[1]=20;print a[0],a[1]}'# 2. 字符串下标数组
awk 'BEGIN{a["name"]="awk";a["version"]="gawk";print a["name"],a["version"]}'# 3. 统计HTTP访问日志中各IP的访问次数(生产常用)
awk '{ip[$1]++;}END{for(i in ip){print "IP:"i" 访问次数:"ip[i]}}' /var/log/httpd/access_log | sort -r# 遍历数组,打印下标和对应值
awk 'BEGIN{a[0]=10;a[1]=20;a[2]=30;for(i in a){print "下标:"i" 值:"a[i]}}'
5.6 生产脚本编写(示例:监控SSH登录失败)
#!/bin/bash
# 统计登录失败的IP及次数(IP在第11字段)
x=`awk '/Failed password/{ip[$11]++}END{for(i in ip){print i","ip[i]}}' /var/log/secure`# 遍历统计结果,判断失败次数≥3的IP
for j in $x
doip=`echo $j | awk -F "," '{print $1}'` # 提取IPnum=`echo $j | awk -F "," '{print $2}'` # 提取失败次数if [ $num -ge 3 ];thenecho "警告! $ip 访问本机失败了$num次,请速速处理!"fi
done
5.7 文本提取(示例:提取jar包版本号)
cat 1.txt | sed -r 's/.*-(.*)\.jar/\1/'
六、总结:awk与grep、sed的区别
无命令