利用棒棒糖图探索Office (US)的IMDB评分
利用棒棒糖图探索Office (US)的IMDB评分
import numpy as np
import pandas as pd
import matplotlib.colors as mc
import matplotlib.image as image
import matplotlib.pyplot as pltfrom matplotlib.cm import ScalarMappable
from matplotlib.lines import Line2D
from matplotlib.offsetbox import OffsetImage, AnnotationBbox
from mpl_toolkits.axes_grid1.inset_locator import inset_axes
from palettable import cartocolors # 获得好看的颜色
数据探索
以下数据如果有需要的同学可关注公众号HsuHeinrich,回复【数据可视化】自动获取~
df_office = pd.read_csv("https://raw.githubusercontent.com/rfordatascience/tidytuesday/master/data/2020/2020-03-17/office_ratings.csv")
df_office.head()
season:季度
episode:剧集编号
imdb_rating:IMDB评级
total_votes:每个评级使用的投票数
df_office_avg = df_office.sort_values(["season", "episode"])
# 生成episode_id:自增序列
df_office_avg["episode_id"] = np.arange(len(df_office_avg)) + 1
df_office_avg["episode_mod"] = df_office_avg["episode_id"] + (9 * df_office_avg["season"])
df_office_avg = df_office_avg.assign(avg = df_office_avg.groupby("season")["imdb_rating"].transform("mean"),mid = df_office_avg.groupby("season")["episode_mod"].transform("mean")
)df_office_avg.head()
创建df_lines数据集:以便于绘制表示每个季度评分平均值的水平线,这些线将在每个季度的第一个和最后一个剧集之间延伸,并稍微超过这些点
df_lines = df_office_avg.groupby("season").agg(start_x = ("episode_mod", min),end_x = ("episode_mod", max),y = ("avg", max) # 每个season的avg一样,用max获取唯一值
).reset_index()# 在每个方向上稍微延长水平线
df_lines["start_x"] -= 5
df_lines["end_x"] += 5df_lines = pd.melt(df_lines, id_vars=["season", "y"], value_vars=["start_x", "end_x"], var_name="type", value_name="x"
)
df_lines["x_group"] = np.where(df_lines["type"] == "start_x", df_lines["x"] + 0.1, df_lines["x"] - 0.1)
df_lines["x_group"] = np.where((df_lines["type"] == "start_x").values & (df_lines["x"] == np.min(df_lines["x"])).values, df_lines["x_group"] - 0.1, df_lines["x_group"]
)
df_lines["x_group"] = np.where((df_lines["type"] == "end_x").values & (df_lines["x"] == np.max(df_lines["x"])).values, df_lines["x_group"] + 0.1, df_lines["x_group"]
)
df_lines = df_lines.sort_values(["season", "x_group"])
df_lines.head()
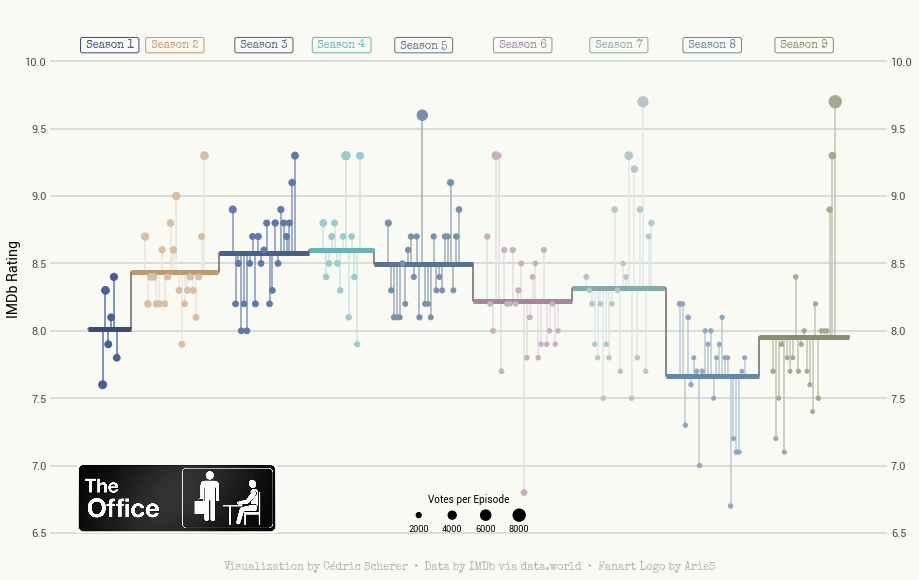
绘制棒棒糖图
图片logo为the-office,可在网上自行下载,也可以关注公众号HsuHeinrich,回复【可视化素材】自动获取~
def adjust_lightness(color, amount=0.5):'''调整颜色亮度:低于 1 的值使其变暗,高于 1 的值使其变亮'''import matplotlib.colors as mcimport colorsystry:c = mc.cnames[color]except:c = colorc = colorsys.rgb_to_hls(*mc.to_rgb(c))return colorsys.hls_to_rgb(c[0], max(0, min(1, amount * c[1])), c[2])
# 定义一些变量# 颜色
GREY82 = "#d1d1d1"
GREY70 = "#B3B3B3"
GREY40 = "#666666"
GREY30 = "#4d4d4d"
BG_WHITE = "#fafaf5"# 季节颜色调整
COLORS = ["#486090", "#D7BFA6", "#6078A8", "#9CCCCC", "#7890A8","#C7B0C1", "#B5C9C9", "#90A8C0", "#A8A890"]
COLORS_DARK = [adjust_lightness(color, 0.8) for color in COLORS]
COLORS_LIGHT = [adjust_lightness(color, 1.2) for color in COLORS]# 三种颜色调整函数
cmap_regular = mc.LinearSegmentedColormap.from_list("regular", COLORS)
cmap_dark = mc.LinearSegmentedColormap.from_list("dark", COLORS_DARK)
cmap_light = mc.LinearSegmentedColormap.from_list("light", COLORS_LIGHT)# 对季节进行缩放
normalize = mc.Normalize(vmin=1, vmax=9)# 图片存储
IMAGE = image.imread("pic/the-office.jpg")# 水平线
HLINES = [6.5, 7, 7.5, 8, 8.5, 9, 9.5, 10]
VOTES_MAX = df_office_avg["total_votes"].max()
VOTES_MIN = df_office_avg["total_votes"].min()# 缩放票数,用于棒棒糖的大小
def scale_to_interval(x, low=15, high=150):return ((x - VOTES_MIN) / (VOTES_MAX - VOTES_MIN)) * (high - low) + low
# 初始化布局
fig, ax = plt.subplots(figsize = (15, 10))# 背景颜色
fig.patch.set_facecolor(BG_WHITE)
ax.set_facecolor(BG_WHITE)# 绘制水平参考线,zorder=0位于图层最下方
for h in HLINES:plt.axhline(h, color=GREY82, zorder=0)# 垂直线段:代表剧集评分与平均评分的偏差
plt.vlines(x="episode_mod", ymin="imdb_rating", ymax="avg",color=cmap_light(normalize(df_office_avg["season"])),data = df_office_avg
)# 水平线:连接平均值的灰线
plt.plot("x", "y", "-", color=GREY40, data=df_lines)# 水平线:每个赛季的平均分
for season in df_lines["season"].unique():d = df_lines[df_lines["season"] == season]plt.plot("x_group", "y", "", color=cmap_dark(normalize(season)), lw=5, data=d, solid_capstyle="butt")# 点:每集的评分,大小由投票数决定
plt.scatter("episode_mod", "imdb_rating",s = scale_to_interval(df_office_avg["total_votes"]),color=cmap_regular(normalize(df_office_avg["season"])), data=df_office_avg,zorder=3
)# Season标签
midpoints = df_office_avg["mid"].unique()
for season, mid in enumerate(midpoints):color = cmap_dark(normalize(season + 1))plt.text(mid, 10.12, f" Season {season + 1} ", color=color,weight="bold",ha="center",va="center",fontname="Special Elite",fontsize=11,bbox=dict(facecolor="none", edgecolor=color, linewidth=1,boxstyle="round", pad=0.2))# ------------------------自定义布局------------------------# 隐藏边框
ax.spines["right"].set_color("none")
ax.spines["top"].set_color("none")
ax.spines["bottom"].set_color("none")
ax.spines["left"].set_color("none")# 自定义y轴
plt.tick_params(axis="y", labelright=True, length=0)
plt.yticks(HLINES, fontname="Roboto", fontsize=11, color=GREY30)
plt.ylim(0.98 * 6.5, 10.2 * 1.02)# 移除x刻度
plt.xticks([], "")# 设置y标签
plt.ylabel("IMDb Rating", fontname="Roboto", fontsize=14)# 添加著作信息
plt.text(0.5, -0.03, "Visualization by Cédric Scherer • Data by IMDb via data.world • Fanart Logo by ArieS", fontname="Special Elite", fontsize=11, color=GREY70,ha="center", va="center", transform=ax.transAxes # so coordinates are in terms of the axis.
)# 放置图片logo
ab = AnnotationBbox(OffsetImage(IMAGE, zoom=0.2), (1, 6.75), xycoords="data", box_alignment=(0, 0.5),pad=0, frameon=False
)
ax.add_artist(ab)# ------------------------自定义图例------------------------# 水平图例点及其标签的位置
x_pos = [0.44, 0.48, 0.52, 0.56]
votes = [2000, 4000, 6000, 8000]# 绘制图例点
plt.scatter(x_pos, [0.065] * 4, s=scale_to_interval(np.array(votes)), color="black",transform=ax.transAxes
)# 添加图例标签名
plt.text(0.5, 0.0875, "Votes per Episode", fontname="Roboto", fontsize=10, ha="center", transform=ax.transAxes)# 将图例放在图例标记下方
for (xpos, vote) in zip(x_pos, votes):plt.text(xpos, 0.035, f"{vote}", fontname="Roboto", fontsize=9, ha="center", transform=ax.transAxes)plt.show()
参考:The Office Ratings with Python and Matplotlib
共勉~