线上API接口响应慢?一套高效排查与定位问题的心法
目录
第一阶段:急诊室初诊(5分钟快速检查)
第二阶段:深入检查室(15-30分钟深入排查)
1. 应用层"CT扫描":看看代码内部
2. 数据库层"胃镜检查":最常见的病根所在
3. 外部依赖"会诊"
第三阶段:康复与预防
1. 压力测试复现
2. 优化方案实施
快速排查清单(贴在你的工位上!)
总结
你的API突然变慢,就像一个人突然生病。作为"医生"的我们,不能直接开药,而是要系统性地"望闻问切",找到真正的病因。
第一阶段:急诊室初诊(5分钟快速检查)
当API突然变慢,我们首先需要判断这是"流行病"还是"个别病例"。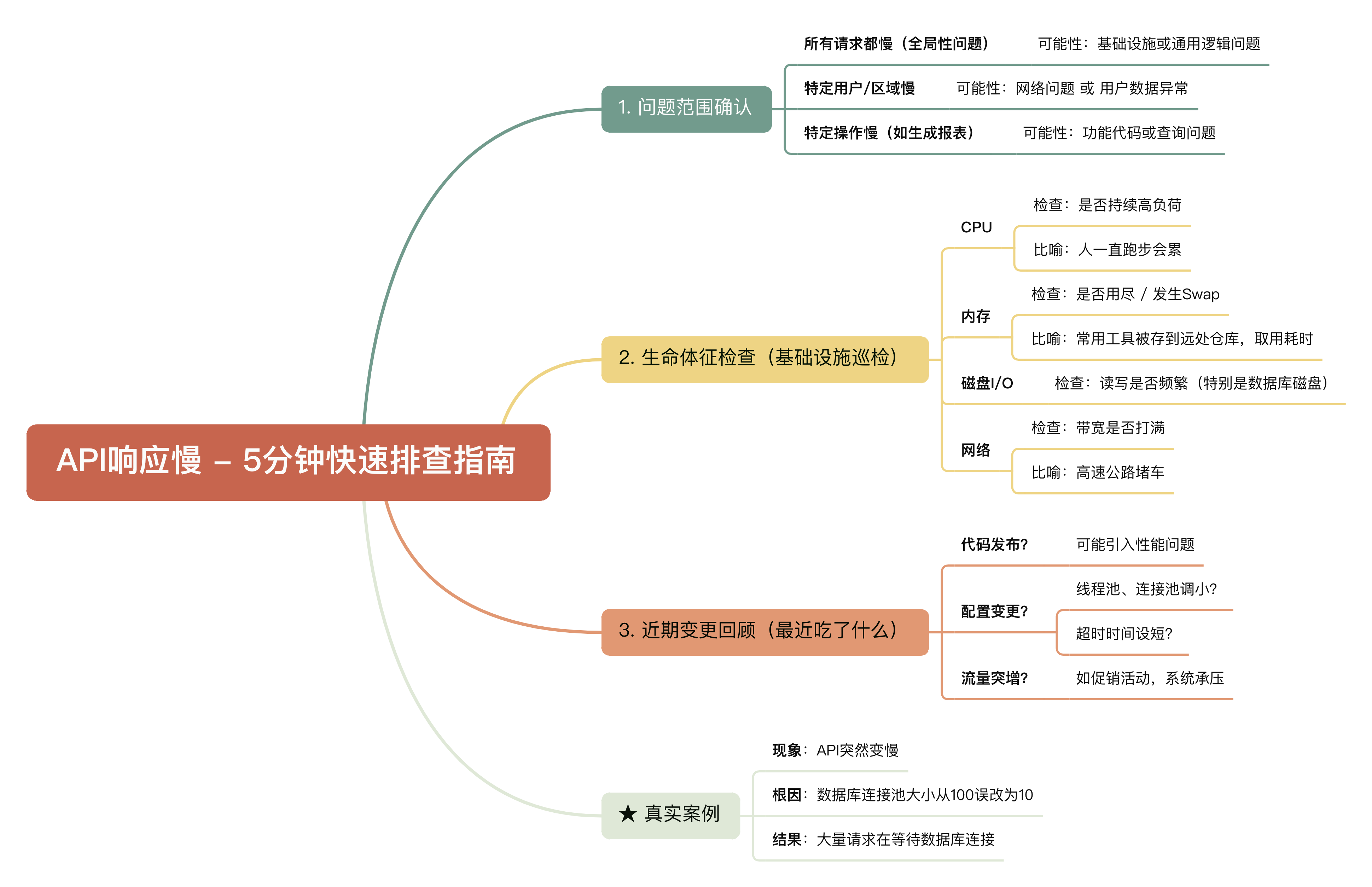
1. 是普遍现象还是个别问题?
打开你的监控系统(比如Prometheus+Grafana),看看这个接口的响应时间曲线:
-
- 如果所有请求都像蜗牛一样慢 → 可能是基础设施或通用逻辑出了问题
- 只有特定用户或区域慢 → 可能是网络问题或用户数据异常
- 只有某个具体操作慢(如"生成报表") → 很可能是这个功能本身的代码或查询有问题
2. 生命体征检查(基础设施巡检)
就像医生先测体温血压一样,我们先看服务器基础指标:
-
- CPU:是否持续高负荷?就像人一直跑步会累,CPU满了处理请求就会慢
- 内存:是否用尽了?特别是是否发生了Swap(内存交换),这就像把常用的工具放到了很远的仓库,取用极其耗时
- 磁盘I/O:读写是否频繁?特别是数据库磁盘
- 网络:带宽是否打满?就像高速公路堵车了
3. 最近吃了什么(近期变更)
询问最近是否有过:
-
- 代码发布?→ 可能引入了性能问题
- 配置变更?→ 线程池、连接池调小了?超时时间设短了?
- 流量突增?→ 比如促销活动,系统承受不住正常流量了
真实案例:有一次我们的API突然变慢,最后发现是因为有人把数据库连接池大小从100误改为了10,导致大部分请求在等待数据库连接!
第二阶段:深入检查室(15-30分钟深入排查)
如果初诊没发现问题,就需要更专业的"医疗器械"了。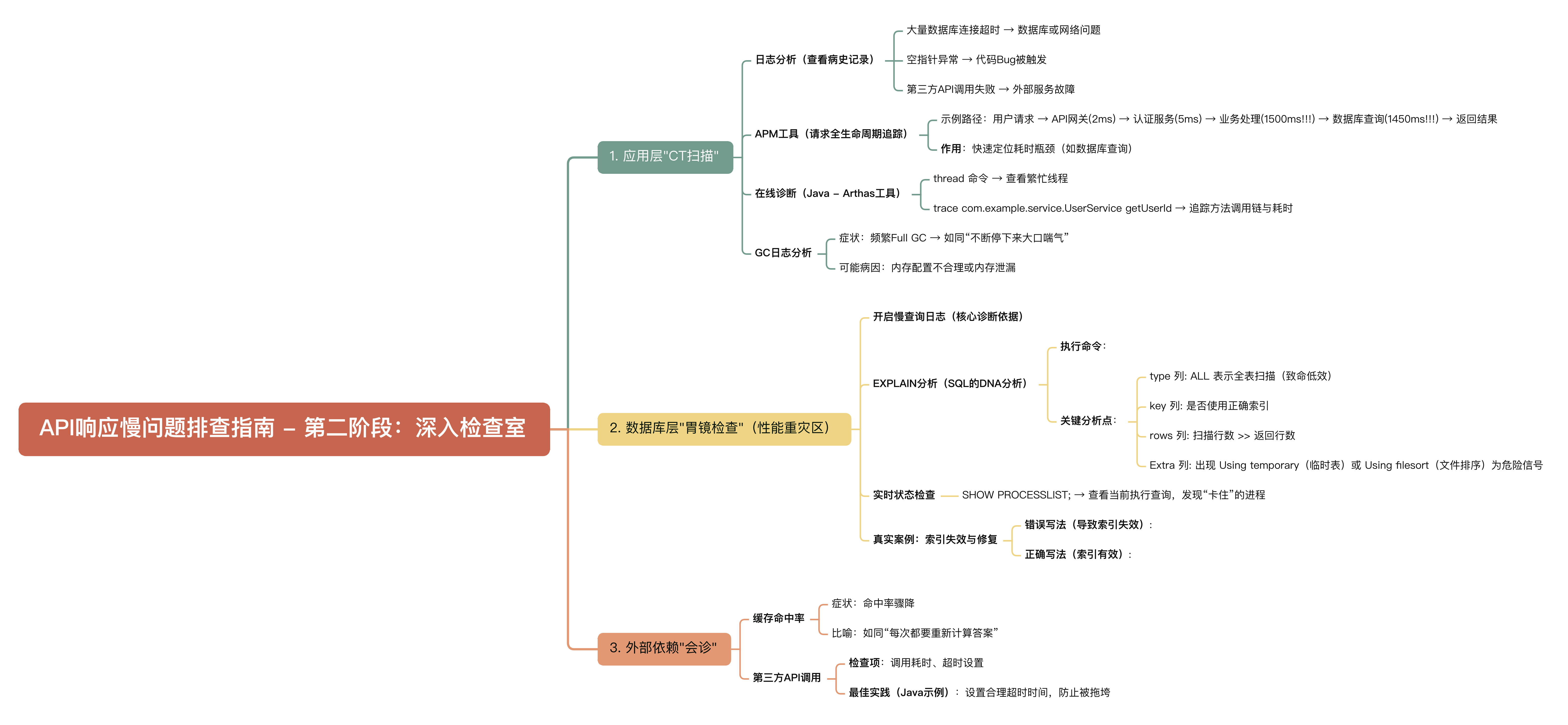
1. 应用层"CT扫描":看看代码内部
日志分析:搜索错误日志,就像查看病人的病史记录
- 大量数据库连接超时?→ 数据库或网络有问题
- 空指针异常?→ 代码bug被触发
- 第三方API调用失败?→ 外部服务出问题了
APM工具(强烈推荐):
这就像是给请求装上了"运动手环",可以完整记录它的一生:
用户请求 → API网关(2ms) → 认证服务(5ms) → 业务处理(1500ms!!!) → 数据库查询(1450ms!!!) → 返回结果
一眼就能看出时间主要消耗在数据库查询上!
在线诊断(Java应用):
使用Arthas就像是用"听诊器"听应用的心脏:
# 查看哪些线程在忙
thread# 追踪某个方法的调用链和时间
trace com.example.service.UserService getUserIdGC日志分析:
频繁的Full GC就像一个人不断停下来大口喘气,没法持续跑步。检查GC频率和暂停时间,如果发现频繁的Full GC,很可能是内存配置不合理或内存泄漏。
2. 数据库层"胃镜检查":最常见的病根所在
数据库往往是性能问题的"重灾区"。
慢查询日志:这是我们的"主要诊断依据"
# 开启慢查询日志
SET GLOBAL slow_query_log = 'ON';
SET GLOBAL long_query_time = 1; # 超过1秒的查询记为慢查询EXPLAIN分析:对于找到的慢查询,使用EXPLAIN就像做"DNA分析"
EXPLAIN SELECT * FROM orders WHERE user_id = 123 AND status = 'pending';
重点关注:
- type:如果是ALL,说明进行了全表扫描(就像在图书馆里一本本书找,而不是用检索系统)
- key:是否使用了正确的索引
- rows:扫描的行数是否远大于实际返回的行数
- Extra:是否有"Using temporary"(使用临时表)或"Using filesort"(文件排序)
实时状态检查:
SHOW PROCESSLIST; -- 查看当前正在执行的查询,有没有"卡住"的
真实案例:我们发现一个API很慢,EXPLAIN后发现本该使用索引的查询却在全表扫描,原来是因为函数处理导致索引失效:
-- 坏查询:索引失效
SELECT * FROM users WHERE DATE(create_time) = '2023-10-01';-- 好查询:索引有效
SELECT * FROM users WHERE create_time >= '2023-10-01' AND create_time < '2023-10-02';3. 外部依赖"会诊"
缓存命中率:如果缓存命中率突然下降,就像突然所有人都来问同样的问题,而你每次都要重新计算答案
第三方调用:
- 检查调用外部API的耗时
- 确保设置了合理的超时时间(避免被慢第三方拖垮)
// 示例:设置合理的超时
HttpClient client = HttpClient.newBuilder().connectTimeout(Duration.ofSeconds(2)) // 连接超时2秒.readTimeout(Duration.ofSeconds(5)) // 读取超时5秒.build();第三阶段:康复与预防
找到问题并修复后,工作还没结束。
1. 压力测试复现
在测试环境使用JMeter等工具模拟线上流量,验证修复效果:
# 使用wrk进行简单压测
wrk -t12 -c400 -d30s https://api.example.com/endpoint2. 优化方案实施
根据找到的问题根源,选择合适的优化手段:
代码层面:
- 优化算法复杂度(从O(n²)到O(n))
- 使用批量操作代替循环中的单次操作
// 不好:循环中单次插入
for (User user : users) {userRepository.insert(user);
}// 好:批量插入
userRepository.batchInsert(users);SQL层面:
- 添加缺失的索引
- 重写低效查询
- 避免N+1查询问题
架构层面:
- 引入缓存(Redis等)
- 异步处理耗时操作(消息队列)
- 数据库读写分离
配置层面:
- 调整JVM内存参数
- 优化数据库连接池配置
- 调整线程池大小
快速排查清单(贴在你的工位上!)
- [ ] 看监控:CPU/内存/磁盘IO/网络流量
- [ ] 看链路:APM工具定位耗时最长环节
- [ ] 查日志:应用错误日志+数据库慢查询
- [ ] 看线程:jstack或Arthas检查线程状态
- [ ] 析SQL:EXPLAIN分析慢查询执行计划
- [ ] 测网络:ping/traceroute检查网络状况
- [ ] 做复盘:完善监控和流程,避免再次发生
总结
排查API性能问题就像破案,需要系统性的思维和合适的工具。不要盲目猜测,而是要从全局到局部,从外部到内部,一步步缩小嫌疑范围,最终找到真正的"罪犯"。
记住:80%的性能问题来自于20%的代码,而数据库往往是最大的嫌疑犯。掌握了正确的排查方法,你就能快速定位问题,让你的API重新"健步如飞"!
希望这篇"看病指南"能帮助你在下次遇到API性能问题时,能够冷静分析,快速定位!如果你有特别的性能排查经历,欢迎在评论区分享~