shell编程 函数、数组与正则表达式
目录
前言
一、Shell 函数:让代码更具复用性
1.1 函数的定义与简单调用
1.2 带参数的函数:灵活传递数据
1.3 有返回值的函数:获取执行结果
二、Shell 数组:高效存储多个数据
2.1 数组的定义
2.2 数组的读取与长度获取
2.3 数组的遍历:逐个处理元素
三、加载外部文件:实现代码分离与复用
3.1 加载外部文件的语法
3.2 实际案例演示
四、实战案例:
五、正则表达式与文本查找工具基础
5.1 正则表达式基础
5.1.1 分类
5.1.2 主要组成
5.2 grep 工具:条件查找
5.3 基础与扩展正则的主要区别
5.4. 元字符操作案例
5.4.1 查找特定字符
六、回顾总结
前言
在 Linux 系统操作和自动化任务处理中,Shell 编程是一项至关重要的技能。之前我们已经了解了 Shell 的基础语法、变量、字符串、运算符和流程控制等内容,而今天,我们将聚焦 Shell 编程中更进阶且实用的部分 —— 函数、数组、外部文件加载,以及一个趣味实战案例。这些内容能帮助大家更高效地组织代码、提升脚本复用性,让 Shell 编程能力再上一个台阶。接下来,就让我们逐一展开学习吧!
一、Shell 函数:让代码更具复用性
函数就像 Shell 脚本中的 “功能模块”,把一段实现特定功能的代码封装起来,需要时直接调用,避免重复编写,让脚本结构更清晰。
1.1 函数的定义与简单调用
在 Shell 中,函数的定义有两种常见形式,一种是带 “function” 关键字,另一种是直接写函数名。定义完成后,只需使用函数名就能调用。比如我们可以定义一个打印欢迎信息的函数:
# 带function关键字的定义方式
function print_welcome() { #print_welcome为函数名echo "欢迎使用Shell脚本功能"echo "当前脚本专注于函数、数组等进阶内容"
}# 直接写函数名的定义方式
print_info() { #print_info为函数名echo "--------------------------"echo "函数调用成功!"echo "--------------------------"
}# 调用函数
print_welcome
print_info
这里要注意,在 Shell中所有函数在使用前必须定义。这意味着必须将函数放在脚本开始
部分,直至 shell解释器首次发现它时,才可以使用。 调用函数仅使用其函数名即可。所以Shell 中的函数必须先定义再调用,把函数放在脚本的开始部分,可以确保 Shell 解释器能先识别到它们。
1.2 带参数的函数:灵活传递数据
函数不仅能执行固定逻辑,还能接收外部传递的参数,实现更灵活的功能。在函数内部,通过 “$n”(n为数字)来获取参数,比如$1 表示第一个参数,$2表示第二个参数,当n>=10时,需要用{n}” 来明确识别。
举个例子,我们定义一个处理多个参数的函数:
a() {echo "第一个参数为:$1"echo "第二个参数为:$2"echo "第十个参数为:${10}"echo "第十一个参数为:${11}"echo "参数总数有:$# 个"echo "所有参数作为一个字符串输出:$*"
}# 调用函数并传递参数
a 1 2 3 4 5 6 7 8 9 34 73
调用后,函数会根据参数位置依次解析并输出。
1.3 有返回值的函数:获取执行结果
函数执行完成后,有时需要向调用者返回一个结果,在 Shell 中可以用 “return” 关键字实现。不过要注意,return 后面只能跟一个数值,函数的返回值会默认存储在 $?中,我们可以通过$? 获取这个返回值。
比如定义一个获取两个数字中最大值的函数:
get_max() {if [ $1 -lt $2 ]; thenreturn $2 # 返回较大的数字elsereturn $1 # 返回较大的数字fi
}# 调用函数
get_max 25 48
# 获取并输出返回值(即最大值)
echo "两个数字中的最大值是:$?"
当我们调用 get_max 函数并传入 25 和 48 后,通过 “$?” 就能拿到返回的最大值 48,轻松实现了结果的传递与获取。但需要注意输入的值不能超过255.
二、Shell 数组:高效存储多个数据
在处理一组相关数据时,数组是绝佳选择。它就像一个 “数据容器”,能把多个元素有序存储起来,方便我们统一管理和操作。
2.1 数组的定义
Shell 只支持一维数组,初始化时不需要指定大小,有两种常见的定义方式。一种是直接用括号包裹元素,元素之间用空格分隔;另一种是通过索引逐个赋值。
# 直接初始化数组
my_array1=(Linux Hadoop Shell Spark)# 通过索引定义数组
my_array2[0]=MySQL
my_array2[1]=Redis
my_array2[2]=Kafka
这样,我们就创建了两个数组,分别存储了不同的技术名称,后续可以对这些元素进行各种操作。
2.2 数组的读取与长度获取
要读取数组中的元素,使用 “数组名索引的格式,索引从开始。如果想获取数组的所有元素,可以用{数组名 [*]}” 或 "{数组名[@]}";获取数组长度则用"{# 数组名 [*]}” 或 “${# 数组名 [@]}”。
# 读取单个元素
echo "my_array1的第一个元素:${my_array1[0]}"
echo "my_array2的第三个元素:${my_array2[2]}"# 读取所有元素
echo "my_array1的所有元素:${my_array1[*]}"
echo "my_array2的所有元素:${my_array2[@]}"# 获取数组长度
echo "my_array1的长度:${#my_array1[*]}"
echo "my_array2的长度:${#my_array2[@]}"
通过这些方式,我们能快速获取数组的单个元素、所有元素以及元素总数,满足不同场景下的数据读取需求。
2.3 数组的遍历:逐个处理元素
遍历数组就是逐个取出数组中的元素并进行处理,在 Shell 中通常用 for 循环实现,有两种常见的遍历方式。一种是通过 “for 变量 in ${数组名 [*]}” 直接遍历所有元素;另一种是通过索引,结合数组长度来遍历。
# 方式一:直接遍历所有元素
echo "遍历m1:"
for var in ${m1[*]}; doecho "元素:$var"
done# 方式二:通过索引遍历
echo "遍历m2:"
a1=${#m2[@]} # 先获取数组长度
for ((i=0; i<a1; i++)); doecho "索引$i的元素:${m2[$i]}"
done
两种方式各有优势,直接遍历更简洁,索引遍历则能明确元素的位置,大家可以根据实际需求选择。
三、加载外部文件:实现代码分离与复用
在实际开发中,我们可能会把一些公用的变量、函数放在单独的 Shell 文件中,然后在其他脚本中加载这些文件,实现代码的分离与复用,让脚本结构更清晰,维护更方便。
3.1 加载外部文件的语法
Shell 中加载外部文件有两种语法,一种是 “source 文件名”,另一种是 “./ 文件名”(注意点和文件名之间有空格)。这两种方式都能把外部文件中的内容加载到当前脚本中,使得当前脚本可以使用外部文件定义的变量、函数等。
3.2 实际案例演示
假设我们有一个名为 “common_vars.sh” 的外部文件,里面定义了一个公用数组:
# common_vars.sh中的内容
common_arr=(Java Python Go C++)
然后在当前脚本中加载这个文件,并使用其中的数组:
# 加载外部文件
source ./common_vars.sh
# 或者用 . ./common_vars.sh# 使用外部文件中的数组
echo "外部文件中的数组元素:${common_arr[*]}"
echo "遍历外部数组:"
for item in ${common_arr[*]}; doecho "数组元素:$item"
done
通过这种方式,我们可以把公用的配置、数据等放在外部文件中,多个脚本都能加载使用,避免了重复定义,大大提升了代码的复用性和可维护性。
四、实战案例:
4.1 案例一:输入两个值,显示并求和显示
脚本:
[root@110 function]# cat fun02.sh
#!/bin/bash
#输入两个值,显示并求和显示a(){
read -p "请输入第一个数:" a1
read -p "请输入第二个数:" a2
echo "你输入的两个值:$a1 和 $a2 "
SUM=$[a1+a2]
echo "和为: " $SUM
}
a结果:
[root@110 function]# sh fun02.sh
请输入第一个数:5
请输入第二个数:9
你输入的两个值:5 和 9
和为: 14
4.2.案例二:
脚本一:
[root@110 function]# cat fun07.sh
#!/bin/bash
echo "user cpu memory"
echo "$(whoami) $(top -bn1|grep "Cpu(s)"| awk '{print $2}') $(free -h |awk '/Mem/{print $3}')"结果:
[root@110 function]# sh fun07.sh
user cpu memory
root 5.9 657M
脚本二:
利用脚本一写
[root@110 function]# cat fun08.sh
#!/bin/bash
./fun07.sh | while read user cpu mem
doif [ "$user" = "user" ]; then #=前后加空格echo "user cpu memory hostname date"continuefihostname=$(hostname)date=$(date +"%Y-%m-%d %H:%M:%S")echo "$user $cpu $mem $hostname $date"
done结果:
[root@110 function]# sh fun08.sh
user cpu memory hostname date
root 6.2 658M 110 2025-09-01 20:18:05
五、正则表达式与文本查找工具基础
在处理文本时,正则表达式和相关工具是非常实用的,这里简单整理分享下。
5.1 正则表达式基础
正则表达式是描述字符串模式的规则,能用来检索、替换、过滤符合特定规则的字符串,在日志筛选、配置文件解析等场景很常用。
5.1.1 分类
-
BRE(基础正则表达式):功能有限,部分元字符需要转义,如
{}需写成\{n,m\},常用工具有grep、sed。 -
ERE(扩展正则表达式):功能更强,语法简洁,
+、?、()等无需转义,常用工具包括egrep(grep -E)、awk。
5.1.2 主要组成
-
普通字符:字母、数字、标点符号等本身。
-
元字符:有特殊含义的字符,比如,匹配任意单个字符(\r\n除外);
[]匹配字符集[a-z] [0-9][A-Z]中的一个字符;[^list]匹配非字符集中的字符;^匹配行首;$匹配行尾;\用于转义。 -
重复次数相关:
*表示 0 次或多次;\+(ERE 中)表示至少 1 次;\{n\}表示恰好 n 次;\{m,n\}表示 m 到 n 次等;\{n,\}表示至少n次。
5.2 grep 工具:条件查找
grep 是常用的文本查找工具,能根据模式匹配文本并输出,常用选项有:
-
-E:启用扩展正则表达式 -
-c:统计匹配的行数 -
-i:忽略大小写 -
-v:反向匹配(输出不包含匹配内容的行) -
-n:显示匹配行的行号 -
-o:只输出匹配内容
-
--color=auto : 高亮匹配
示例:
grep -c "root" /etc/passwd # 统计包含root的行数
grep -i "the" test.txt # 不区分大小写查找the
grep -n "^the" test.txt # 查找行首是the的行并显示行号
5.3 基础与扩展正则的主要区别
BRE 常见元字符
-
^行首 -
$行尾 -
.任意单字符 -
[list]匹配字符集 -
[^list]反向匹配 -
*0 或多次 -
\{n\}精确次数 -
\{n,\}至少 n 次 -
\{n,m\}n~m 次
ERE 新增功能
-
+一个或多个 -
?0 或 1 次 -
|或者(OR) -
()分组 -
()+匹配重复的组
5.4. 元字符操作案例
5.4.1 查找特定字符
grep -n 'the' test.txt # 查找 the
grep -vn 'the' test.txt # 反向匹配
5.4.2 中括号集合
grep -n 'sh[io]rt' test.txt # shirt 或 short
grep -n '[^w]oo' test.txt # 不以 w 开头的 oo
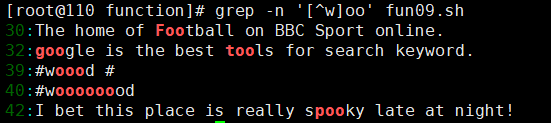
5.4.3定位符
grep -n '^the' test.txt # 行首是 the
grep -n '\.$' test.txt # 行尾是 .
grep -n '^$' test.txt # 空行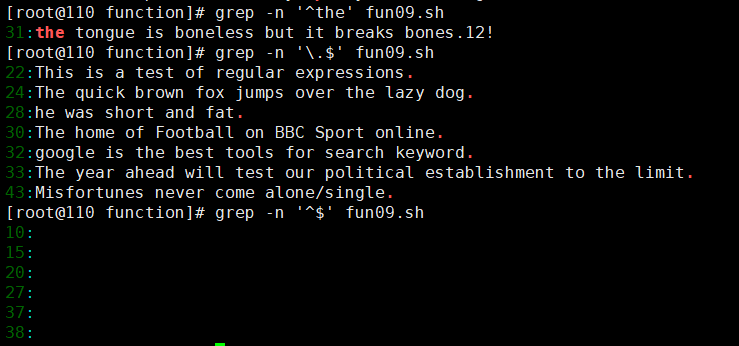
5.4.4 点与星
grep -n 'w..d' test.txt # w 开头 d 结尾,中间两个字符
grep -n 'woo*d' test.txt # w 开头 d 结尾,中间 o 可有可无
grep -n 'w.*d' test.txt # w 开头 d 结尾,中间任意字符
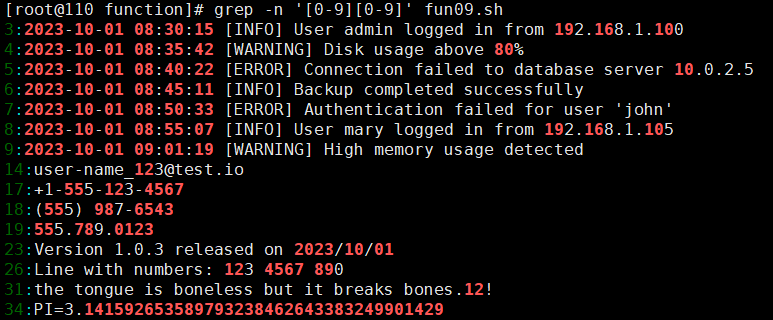
执行以下命令即可查询任意数字所在行。
grep -n '[0-9][0-9]*' test.txt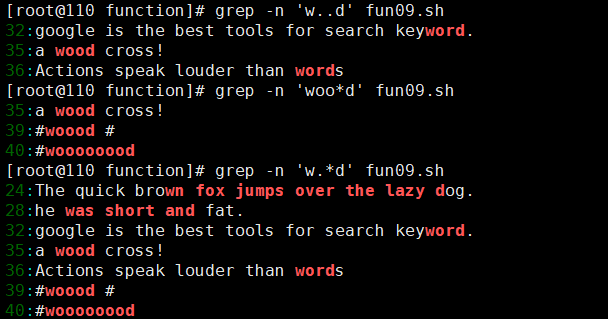
5.4.5 次数限定符
#查询两个 o 的字符。
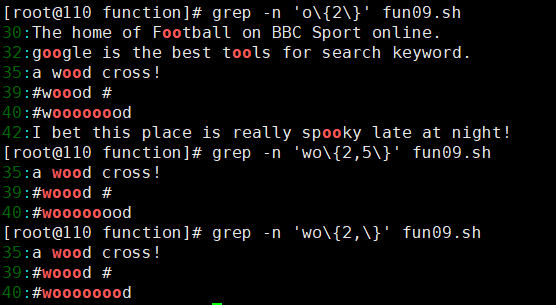
grep -n 'o\{2\}' test.txt # oo
#查询以 w 开头以 d 结尾,中间包含 2~5 个 o 的字符串
grep -n 'wo\{2,5\}d' test.txt # w 开头 d 结尾,2-5 个 o
#查询以 w 开头以 d 结尾,中间包含 2 个或 2 个以上 o 的字符串。
grep -n 'wo\{2,\}d' test.txt # 至少两个 o
六、回顾总结
函数 定义(自定义函数)
格式:
function 函数名(){程序段(命令 流程控制)
}
##调用
函数的调用: 函数名函数中的参数传递:
① 在函数中接收传递的参数可以使用: $n 例: $1 $7 ${10}
② 调用函数时传递参数: 函数名 参数1 参数2
函数调用后接收返回值:
① 在函数中使用 return数据值 的方式把数据返回出去
② 函数的返回值默认是存储在: $?
③ 可以直接使用 $? 操作返回值
数组
在shell当中 ,可通过数组名=(元素1 元素2 元素3 ........)定义数组, 用${数组名[索引]}读取元素,用for 变量 in
"${数组名[@/*]}" ; do...... done 遍历数组
(1)# 直接定义
array_name=(value1 value2 value3 ...)
# 单独定义元素
array_name[0]=value1
array_name[1]=value2(2)读取数组元素
# 读取指定索引元素(索引从0开始)
echo ${array_name[index]}# 读取所有元素
echo ${array_name[@]} # 或 ${array_name[*]}(3)遍历数组
方式1 for ceshi in " ${array_name[@]"; doecho $ceshidone方式 for (( i=0; i< ${array_name[@]};i++)); doecho ${array_name[i]}done 正则表达式:awk、grep、元字符操作