爬虫实战练习
1 所需技术
通过使用爬虫技术爬取门户网站相关新闻,将新闻存储在数据库做后续分析。并通过使用飞书智能表格进一步分析
1.1 beautifulSoup
BeautifulSoup是一个强大的Python库,专门用于网页抓取(web scraping)和解析HTML、XML文件 。它能够优雅地处理不完整或格式不规范的HTML代码,提供Pythonic风格的API来导航、搜索和修改解析树。BeautifulSoup与解析器(如lxml或html.parser)配合使用,让开发者能够通过CSS选择器、标签名称或其他属性轻松提取网页中的特定数据。这个库因其简单易用的特性而广受欢迎,是数据采集、网页分析和自动化任务的必备工具。
官方文档
其他技术文档链接:
A Step-by-Step Guide to Web Scraping with Python and Beautiful Soup
Beginner’s guide to Web Scraping in Python using BeautifulSoup
BeautifulSoup Web Scraping Guide
Web Scraping using Python (and Beautiful Soup)
1.2 PostgreSQL
PostgreSQL是一个功能强大的开源对象关系数据库管理系统(ORDBMS),起源于加州大学伯克利分校开发的POSTGRES 4.2版本。它不仅支持标准SQL查询,还支持JSON等非关系型数据查询,提供了高度的可扩展性和可靠性。作为一个企业级数据库,PostgreSQL具备丰富的功能,包括复杂数据类型处理、强大的查询能力、事务完整性和多版本并发控制。它被广泛应用于各种规模的应用程序中,从简单的数据存储到复杂的数据分析系统。
官方文档
PostgreSQL Tutorial
What is PostgreSQL? Key Features, Benefits, and Real-World Uses
Introduction to postgresql
1.3 飞书多维表格
飞书多维表格(Base)是一款表格形态的在线数据库工具,它融合了电子表格的轻盈易用和业务系统的强大功能。与传统电子表格不同,多维表格不仅能实现数据的存储、分析及可视化,还支持多种数据视图(如表格、看板、甘特图等)的自由切换。它具备丰富的字段类型设置能力,确保数据格式规范,同时提供强大的权限管理机制,可精确控制到行列级别。飞书多维表格还支持自动化流程功能,帮助团队打通数据业务流程,其技术基础设施能够处理高达1000万行数据的实时分析。作为新一代效率应用,飞书多维表格满足个性化团队协作需求,帮助企业实现信息管理和业务升级。
快速上手多维表格
2 实现过程
2.1 建立数据表
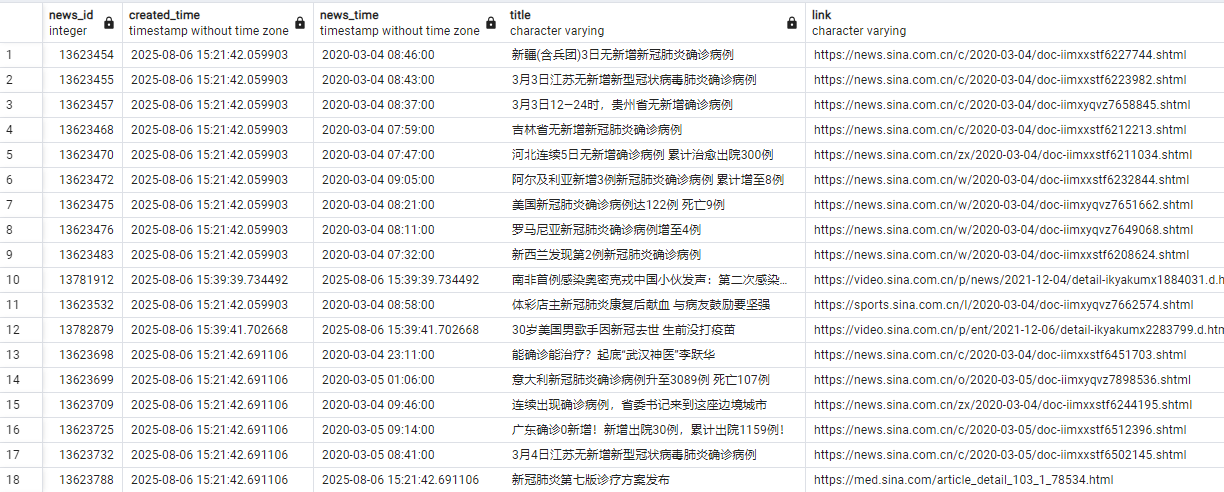
建立一张表用于存放爬虫获取的新闻,字段包括新闻时间、新闻标题、更新时间等。
DROP TABLE IF EXISTS public.news_daily;CREATE TABLE IF NOT EXISTS public.news_daily
(news_id integer NOT NULL DEFAULT nextval('all_id_seq'::regclass),created_time timestamp without time zone DEFAULT CURRENT_TIMESTAMP,news_time timestamp without time zone DEFAULT CURRENT_TIMESTAMP,title character varying COLLATE pg_catalog."default",link character varying COLLATE pg_catalog."default",source character varying COLLATE pg_catalog."default",comments character varying COLLATE pg_catalog."default",joins character varying COLLATE pg_catalog."default",content character varying COLLATE pg_catalog."default",updated_time timestamp without time zone DEFAULT CURRENT_TIMESTAMP,CONSTRAINT news_daily_link_unique UNIQUE (link)
)
COMMENT ON COLUMN news_daily.news_id IS '主键';
COMMENT ON COLUMN news_daily.created_time IS '创建时间';
COMMENT ON COLUMN news_daily.news_time IS '新闻发布时间';
COMMENT ON COLUMN news_daily.title IS '标题';
COMMENT ON COLUMN news_daily.link IS '链接';
COMMENT ON COLUMN news_daily.source IS '新闻来源';
COMMENT ON COLUMN news_daily.comments IS '评论数';
COMMENT ON COLUMN news_daily.joins IS '参与数';
COMMENT ON COLUMN news_daily.content IS '板块';
COMMENT ON COLUMN news_daily.updated_time IS '更新时间';TABLESPACE pg_default;ALTER TABLE IF EXISTS public.news_dailyOWNER to postgres;
2.2 获取新闻资源
新浪新闻可以按照日期查找过去的新闻,很适合用于爬取。本文仅用于教学目的,严禁商用

确定新闻url后将目标网页F12进行解构分析,使用bs进行编码。本文遍历2019年12月1日至2023年1月1日期间的所有已发布新闻。
def get_sina_news():start_date = [2019, 12, 1]end_date = [2023,1,1]dates = date_range(start_date, end_date)for date in dates:print(f"当前日期是{date}")infos = get_html_info(f'https://news.sina.com.cn/head/news{date}am.shtml', 'list_14', 'ul') #, encoding='gbk')to_insert_data = []for info in infos:# print(f"新闻是:{info['text']}")to_insert_data.append((info['href'], info['text']))execute_sql_many('insert into news_daily(link, title) values (%s, %s) ON CONFLICT (link) DO NOTHING',to_insert_data,False)
新闻导入数据库后,需要进行二次清洗,比如根据标签进行分类
def update_sina_all_news():listoes = [{'type':'组图', 'link': 'slide'},{'type': '视频', 'link': 'video'},{'type': '快讯', 'link': 'k'},{'type': '汽车', 'link': 'auto'},{'type':'vip', 'link': 'vip'},{'type':'城市', 'link': 'city'},{'type':'新浪新闻', 'link': 'sinanews'},{'type':'丽人', 'link': 'eladies'},{'type':'科技', 'link': 'tech'},{'type':'军事', 'link': 'mil'}]for listo in listoes:update_sql_all = f"update news_daily set updated_time = now(), content = %s where link like %s or link like %s"execute_sql_params(update_sql_all, (listo['type'], f"http://{listo['link']}%", f"https://{listo['link']}%"), False)print(listo)
有一些新闻链接已经失效,无法有些访问,将其筛选处理。
def update_sina_news():select_sql = f"select link from news_daily where link like '%html' and source is null and created_time > '2025-8-6 10:56:44'"results = execute_sql_result(select_sql)for rst in results:try:news_title = get_html_info(rst[0], 'date-source', label='span')if len(news_title) < 1:news_title = [{'text':'1970年1月5日 00:00'}]news_time = convert_chinese_date(news_title[0]['text'], '%Y年%m月%d日 %H:%M')source = (news_title[1].get('text') if len(news_title) > 1 and isinstance(news_title[1], dict) else '') or ''update_sql = f"update news_daily set updated_time = now(), news_time = %s, source = %s where link = %s"execute_sql_params(update_sql, (news_time, source, rst[0]), False)print(news_time)except Exception as e:# 处理错误的代码print(f"处理 {rst} 时出错: {e}")# 可选: 记录错误# 继续下一次循环continue
新闻获取结果

2.3 飞书多维表格进行分析
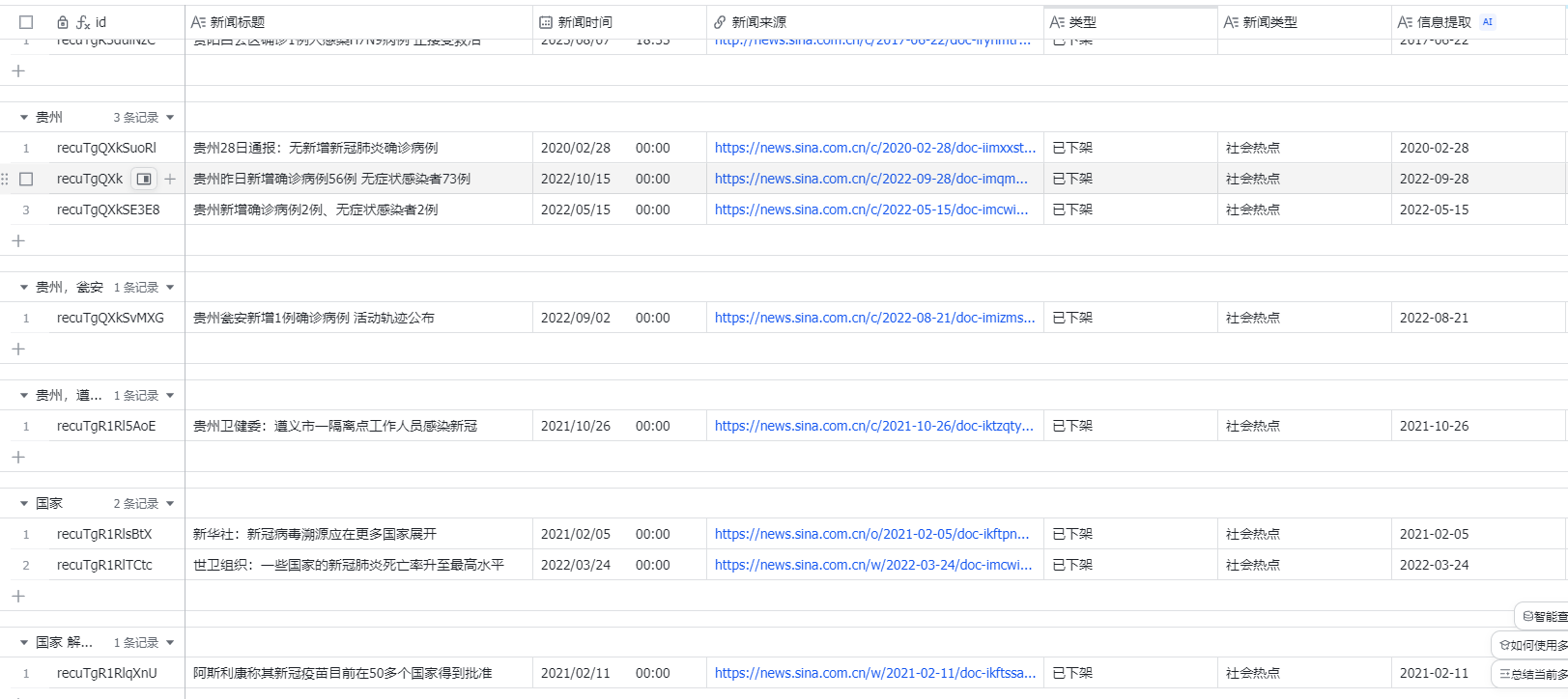
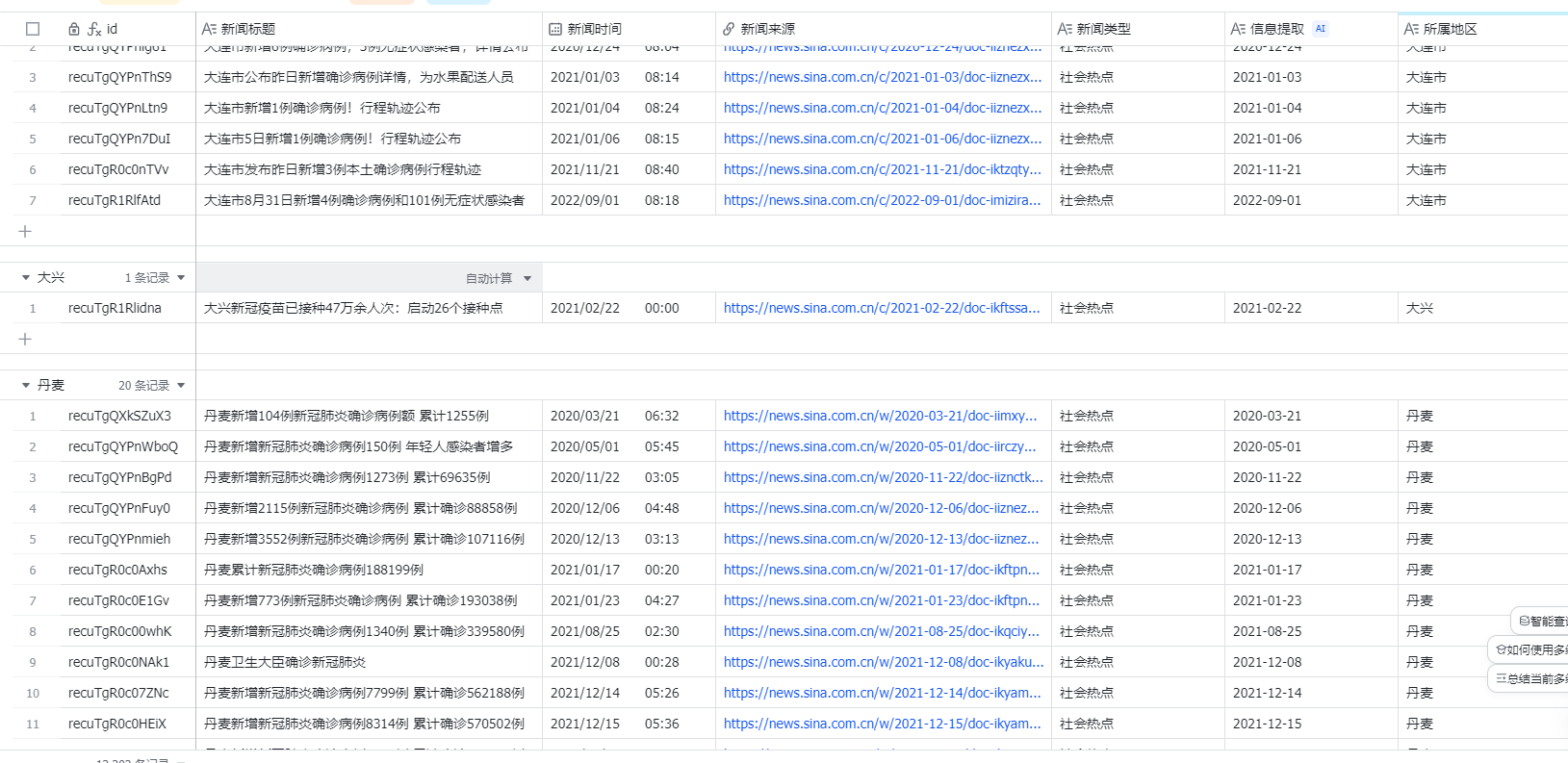
筛选出与新冠疫情相关的新闻
SELECT * FROM public.news_daily where title like '%新冠%' or title like '%确诊%'
将上述查询结果复制粘贴至飞书多维表格,【需提前建好表结构】
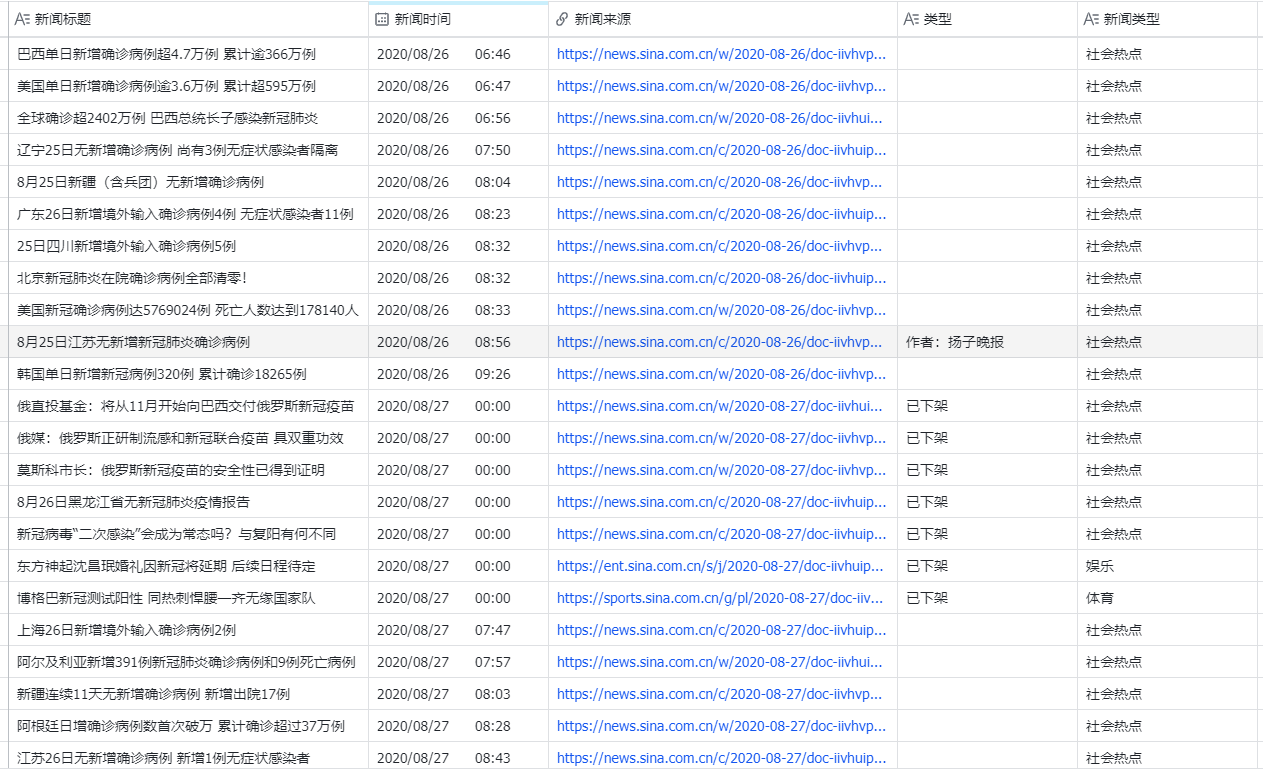
根据飞书的AI智能提取功能,识别新闻标题中的地名,将其提取并新增一列
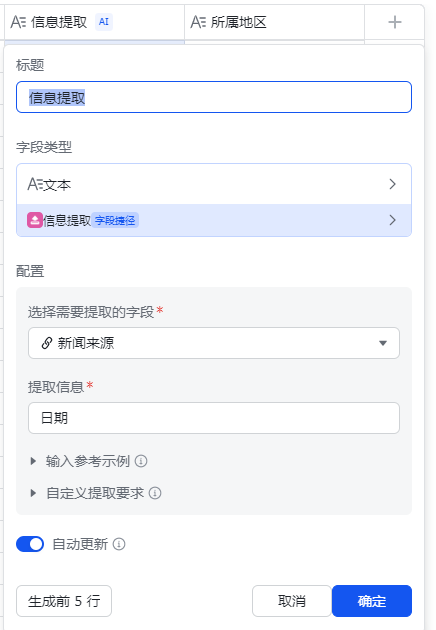
类似的,根据新闻链接获取其新闻日期,与之前爬虫获取的news_time对比,凡是news_time无效的新闻均是已下架的,将已下架的新闻标注