预处理——嵌入式学习笔记
目录
前言
一、宏定义
1、程序编译过程和说明
(1)编写的源程序(.c文件或者.cpp文件等),是否可以直接在ubuntu、开发板系统运行起来?
(2)编译过程
a、预处理(cpp)
b、编译(cc1)
c、汇编(as)
d、链接(Id)
2、预处理语句
(1)概念:
(2)分类:
(3)基本语法:
(4)预处理是整个编译全过程的第一步:
(5)查看预处理结果:
3、宏的概念
4、无参宏
5、带参宏
6、宏定义的符号粘贴
二、条件编译
1、无值宏定义
2、条件编译
(1)有值宏条件编译(#if ... #elif ... #elif ... endif)
(2)无值宏条件编译
a、ifdef ... #endif语句
b、ifndef ... #endif语句
三、头文件
1、头文件的作用
2、头文件的格式
3、头文件的内容
4、头文件的使用
前言
在C语言的世界里,预处理阶段就像是代码的"化妆师"和"后勤总管",它在编译正式开始前默默完成所有准备工作。无论是简单的宏替换,还是复杂的条件编译,预处理指令都在幕后发挥着不可或缺的作用。
想象一下:当你写下
#include <stdio.h>时,预处理程序便会将整个标准输入输出库的头文件内容插入到你的代码中;当你使用#define PI 3.14159时,它会在编译前将所有PI替换为具体的数值。这些看似简单的操作,实则极大地增强了代码的灵活性、可读性和可移植性。预处理不仅是C语言的独特特性,更是理解编译过程的钥匙。掌握预处理技巧,能够让你写出更加优雅、高效的代码。本篇将带你深入探索C语言预处理的奥秘,从基础指令到高级技巧,一步步揭开这个隐藏在代码背后的魔法世界。
一、宏定义
1、程序编译过程和说明
(1)编写的源程序(.c文件或者.cpp文件等),是否可以直接在ubuntu、开发板系统运行起来?
我们编写的C语言源程序(
.c文件)或C++源程序(.cpp文件)无法直接在Ubuntu系统或开发板系统中运行。原因在于:
机器无法理解高级语言:计算机硬件只能识别和执行二进制机器指令(0和1)
代码需要转换:高级语言编写的代码必须经过一系列处理步骤,转换为机器可执行的格式
系统差异:不同的硬件架构和操作系统需要不同的可执行文件格式
(2)编译过程
预处理(cpp):C Preprocessor,C预处理器编译(cc1): C Compiler 1(或 C Compiler, Phase 1),它是 GCC(GNU Compiler Collection) 中负责将预处理后的 C 代码编译成汇编代码的核心组件。汇编(as): Assembler(汇编器),它是 GNU 工具链中负责将 汇编代码(.s 文件) 转换为 机器码(目标文件 .o) 的核心工具。链接(ld): Linker 或 Loader(链接器/加载器),它是 GNU Binutils 工具链的核心组件,负责将多个目标文件(.o)和库文件(.a/.so)合并成一个可执行文件(a.out 或自定义名称)或共享库。a、预处理(cpp)
作用:处理源代码中的预处理指令,为编译做准备
主要功能:
展开所有
#include指令,插入头文件内容处理
#define宏定义,进行文本替换条件编译(
#if,#ifdef,#ifndef等)删除注释内容
添加行号和文件名标识,用于调试
注意:预处理程序的输出结果还是一个源程序文件,以.i为扩展名
输入:
.c源文件
输出:预处理后的文本文件(通常为.i)终端的命令:gcc main.c -o main.i -E(注意:是大写)b、编译(cc1)
作用:将预处理后的C代码转换为特定平台的汇编代码
主要功能:
词法分析和语法分析
语义检查和类型检查
代码优化
生成平台相关的汇编代码
输入:预处理后的
.i文件
输出:汇编代码文件(.s)终端的命令: gcc main.i -o main.s -S(注意:是大写)c、汇编(as)
作用:将汇编代码转换为机器可执行的目标代码
主要功能:
将汇编指令逐条翻译为机器指令
生成可重定位的目标文件
创建符号表和数据段信息
输入:汇编代码
.s文件
输出:目标文件(.o或.obj)终端的命令: gcc main.s -o main.o -c(注意:是小写)d、链接(Id)
作用:将多个目标文件和库文件合并为最终的可执行文件
主要功能:
解析符号引用,解决外部依赖
合并代码段、数据段等各个段
重定位地址引用
链接静态库(
.a)和动态库(.so)输入:一个或多个
.o目标文件 + 库文件
输出:可执行文件(如a.out或自定义名称)终端的命令:gcc main.o -o main // (如果工程里有多个源文件,则是多个.o文件一起链接编译在工程中)
2、预处理语句
(1)概念:
在C语言程序源码中,凡是以井号(#)开头的语句被称为预处理语句。这些语句严格意义上并不属于C语言语法的范畴,它们在编译的阶段统一由预处理器(cpp)来处理。
所谓预处理,指的是真正的C程序编译之前预先进行的一些处理步骤。
(2)分类:
基本指令
头文件包含:
#include宏定义:
#define取消宏:
#undef条件编译指令
#if、#ifdef、#ifndef
#else、#elif
#endif特殊指令
显示错误:
#error修改文件名和行号:
#line编译器特定指令:
#pragma(后面STM32再详细讲解)(3)基本语法:
一个逻辑行只能出现一条预处理指令
多个物理行需要用反斜杠()连接成一个逻辑行
(4)预处理是整个编译全过程的第一步:
预处理(预处理指令) → 编译(C语言、C++) → 汇编(汇编语句) → 链接(将各个.o文件链接成可执行文件)(5)查看预处理结果:
可以通过如下编译器选项来限定编译只进行预处理操作:
# 终端命令:将预处理结果输出到example.i文件 gcc example.c -o example.i -E(注意:是大写)
3、宏的概念
概念:
宏(macro) 实际上就是一段特定字串,在源码中用以替换为指定的表达式。
例:
#define PI 3.14命名规范
宏一般情况下使用大写字母来表达
目的是区分于变量和函数
这不是语法规定,而是一种编程
示例代码:
#include <stdio.h>// 宏定义 #define PI 3.14// 主函数 int main(int argc, char const *argv[]) {printf("圆周率 == %f\n", PI);return 0; }宏的作用:
1. 增强代码可读性
字串单词一般比纯数字更容易让人理解其含义
#define MAX_SIZE 100 #define TIMEOUT 50002. 便于程序修改
修改宏定义,即修改了所有该宏替换的表达式
// 只需修改这里,所有使用BUFFER_SIZE的地方都会更新 #define BUFFER_SIZE 10243. 提高程序运行效率
程序的执行不再需要函数切换开销,而是就地展开
// 宏函数示例 #define SQUARE(x) ((x) * (x))练习题:现在有一个小且需要频繁调用的函数,为了节省程序的开销,应该如何设置?
C语言:使用#define定义宏函数C++:使用inline内联函数定义这个函数
4、无参宏
概念:
无参宏意味着使用宏的时候,无需指定任何参数
例子:
#include <stdio.h>// 自定义无参宏 #define PI 3.14 // 圆周率 #define SCREEN_WIDTH 800 // 屏幕宽度 #define SCREEN_HEIGHT 480 // 屏幕高度 #define BUFFER_SIZE 1024 // 缓冲区大小// 系统常见的无参宏(示例) #define NULL ((void*)0) // 空指针定义 #define TRUE 1 // 真值 #define FALSE 0 // 假值int main() {// 使用自定义宏printf("圆周率 = %f\n", PI);printf("屏幕分辨率 = %dx%d\n", SCREEN_WIDTH, SCREEN_HEIGHT);printf("缓冲区大小 = %d字节\n", BUFFER_SIZE);// 使用系统宏int *ptr = NULL;if (ptr == NULL) {printf("指针为空\n");}return 0; }预处理后
int main() {printf("圆周率 = %f\n", 3.14);printf("屏幕分辨率 = %dx%d\n", 800, 480);printf("缓冲区大小 = %d字节\n", 1024);int *ptr = ((void*)0);if (ptr == ((void*)0)) {printf("指针为空\n");}return 0; }
5、带参宏
概念:
带参宏意味着宏定义可以携带"参数",从形式上看跟函数很像,但在预处理阶段会进行文本替换。
示例代码:
#include <stdio.h>// 枚举定义机器状态 enum {reset, // 重启running, // 运行sleep, // 休眠stop // 停止,关机 };// 比较大小的宏函数 - 正确写法 #define MAX(A, B) ((A) > (B) ? (A) : (B))// 机器状态选择宏函数 #define ROBOT_STATUS(STATU)switch (STATU){\case reset:printf("我重生了,这一世我拿回属于我的一切\n");break;case running:\printf("工作中\n");break;case sleep:printf("我正在睡觉,不要打扰我\n");break;case stop:printf("啊,飞升了\n");break;} // 注意:\的后面不要有任何字符,包括空格int main(int argc, char const *argv[]) {// 1、比较两个数的大小int a = 100;int b = 200;printf("两个数中,最大的数为 == %d\n", MAX(a, b));// 2、机器的运行状态ROBOT_STATUS(stop);return 0; }预处理后:
int main(int argc, char const *argv[]) {int a = 100;int b = 200;printf("两个数中,最大的数为 == %d\n", ((a) > (b) ? (a) : (b)));switch (stop){case reset:printf("我重生了,这一世我拿回属于我的一切\n");break;case running:printf("工作中\n");break;case sleep:printf("我正在睡觉,不要打扰我\n");\break;case stop:printf("啊,飞升了\n");\break;}return 0; }
- 注意事项:
- 问题:由于宏仅仅做文本替换,中间不涉及任何语法检查、类型匹配、数值运算,因此用起来相对函数要麻烦得多
#include <stdio.h>// 比谁小的宏定义函数 #define MIN(A, B) A<B?A:B // 没有括号的话,那么产生很多的歧义(因为#define不会进行优先级判断,只是单纯地进行替换而已)// 主函数 int main(int argc, char const *argv[]) {int x = 100;int y = 200;printf("两个数中,最小的数为 == %d\n", MIN(x, y==200?888:999));/*解析:预处理后,上面的#define语句变为这个printf("两个数中,最大的数为 == %d\n", x<y==200?888:999?x:y==200?888:999);说明:第一步: x<y == 0 ==》 1==200?888:999?x:y==200?888:999第二步: 1==200 y==200 ==》 0?888:999?x:1?888:999第三步: 1?888:999 ==》 0?888:999?x:888第四步: 999?x:888 ==》 0?888:100第五步: 0?888:100 ==》 100*/ }
- 解决:将宏定义中所有能够用括号括起来得部分,都括起来
#include <stdio.h>// 比谁小的宏定义函数 #define MIN(A, B) (A)<(B)?(A):(B) // 主函数 int main(int argc, char const *argv[]) {int x = 100;int y = 200;printf("两个数中,最小的数为 == %d\n", MIN(x, y==200?888:999));/*解析:预处理后,上面的#define语句变为这个printf("两个数中,最小的数为 == %d\n", (x)<(y==200?888:999)?(x):(y==200?888:999) );说明:第一步: y==200 ==》 (x)<(1?888:999)?(x):(y==200?888:999);第二步: 1?888:999 ==》 (x)<(888)?(x):(y==200?888:999);第三步: (x)<(888) ==》 (1)?(x):(y==200?888:999); // 1已经确定为真,不会再确定右边的式子 第四步: (1)?(x) ==》 x(不会再计算后面的(y==200?888:999)); */ }
6、宏定义的符号粘贴
概念:
在某些情况下,宏参数中的符号并非用来传递参数值,而是用来形成多种不同的字串。这种技术常用于系统函数和框架设计中,用于规范化函数命名和结构。
例:
#include <stdio.h>// 普通函数(4个规范的函数) void __zinitcall_service_1(void) {printf("__zinitcall_service_1\n"); }void __zinitcall_service_2(void) {printf("__zinitcall_service_2\n"); }void __zinitcall_feature_1(void) {printf("__zinitcall_feature_1\n"); }void __zinitcall_feature_2(void) {printf("__zinitcall_feature_2\n"); }// 符号粘贴宏定义 #define LAYER_INITCALL(layer, num) __zinitcall_##layer##_##numint main(int argc, char const *argv[]) { // 形成多种不同的字串,并调用对应函数LAYER_INITCALL(service, 1)(); // 等价于 __zinitcall_service_1();LAYER_INITCALL(service, 2)(); // 等价于 __zinitcall_service_2();LAYER_INITCALL(feature, 1)(); // 等价于 __zinitcall_feature_1();LAYER_INITCALL(feature, 2)(); // 等价于 __zinitcall_feature_2();return 0; }注意事项:
注意1:##运算符的正确使用
在书写非字符串的字串拼接时,使用双井号(##)来粘贴字串
如果字串出现在最末尾,则最后的双井号必须去除
#define LAYER_INITCALL(layer, num) __zinitcall_##layer##_##num注意2:#和##的区别
#运算符:将宏参数转换为字符串字面量
##运算符:将两个标记连接成一个新的标

二、条件编译
1、无值宏定义
概念:
定义无参宏的时候,不一定需要带值,无值得宏定义经常在条件编译中作为判断条件出现
例:
#define BIG_ENDIAN // 大小端 #define __CPLUSPLUS // C++ #define DEBUG // 是否要调试2、条件编译
(1)有值宏条件编译(#if ... #elif ... #elif ... endif)
概念:
有条件的编译,通过控制某些宏的值,来决定编译哪段代码
形式:
判断表达式MACRO是否为真,据此决定其所包含的代码段是否要编译
例子:
// 单独判断 #if A... // 如果 MACRO 为真,那么该段代码将被编译,否则被丢弃 #endif// 二路分支 #if A... #elif B... #endif// 多路分支 #if A... #elif B... #elif C... #endif注意:#if形式条件编译需要有值宏
示例代码:
#include <stdio.h> // 有值宏定义 #define A 0 // 网卡A #define B 1 // 网卡B #define C 0 // 网卡C// 主函数 int main(int argc, char const *argv[]) {#if Aprintf("选择网卡A插入到电脑的驱动内核里面\n"); #elif Bprintf("选择网卡B插入到电脑的驱动内核里面\n"); #elif Cprintf("选择网卡C插入到电脑的驱动内核里面\n"); #endifreturn 0; }(2)无值宏条件编译
a、ifdef ... #endif语句
形式:
判断宏MACRO 是否已经被定义,据此决定其所包含的代码段是否要编译
示例:
// 单独判断 #ifdef MACRO... #endif// 二路分支 #ifdef MACRO... #else... #endif例:
格式:gcc main.c -o main -DMACRO 例子:gcc main.c -o main -DDEBUG(其中-D定义宏定义选项, DEBUG是宏定义名字)示例代码:
#include <stdio.h> int main(int argc, char const *argv[]) {// (1)、无值宏定义的实际使用1(调试):判断宏MACRO 是否已经被定义,据此决定其所包含的代码段是否要编译int num = 100; #ifdef DEBUG // 这里一般作为调试信息使用printf("打印调试信息 num == %d\n", num); #endifreturn 0; }输出:
gec@ubuntu:002__无值宏定义$ gcc main.c -o main -DDEBUG gec@ubuntu:002__无值宏定义$ ./main 打印调试信息 num == 100b、ifndef ... #endif语句
形式:
判断宏MACRO是否未被定义,据此决定其所包含的代码段是否要编译
例:
// 单独判断 #ifndef MACRO... #endif// 二路分支 #ifndef MACRO... #else... #endif示例代码:
my.h
// 防止递归包含(编译器多次进入到此处,浪费资源) #ifndef __MY_H // 如果没有定义这个宏标志__MY_H #define __MY_H // 帮你定义这个宏标志(意味着只能进入这里面1次)// 头文件 #include <stdio.h>// 函数声明 extern void TEST_Func(void);#endifmain.c
#include "my.h"int main(int argc, char const *argv[]) {// (1)、无值宏定义的实际使用1(调试):判断宏MACRO 是否已经被定义,据此决定其所包含的代码段是否要编译// 方式2:二路分支int num2 = 0; #ifndef DEBUG2 // 这里一般作为调试信息使用num2 = 110; #elseprintf("打印调试信息 num2 == %d\n", num2); #endif// (2)、无值宏定义的实际使用2(防止编译器多次进入功能):TEST_Func();return 0; }test.c
#include "my.h"void TEST_Func(void) {printf("TEST_Func: hello world!\n"); }
三、头文件
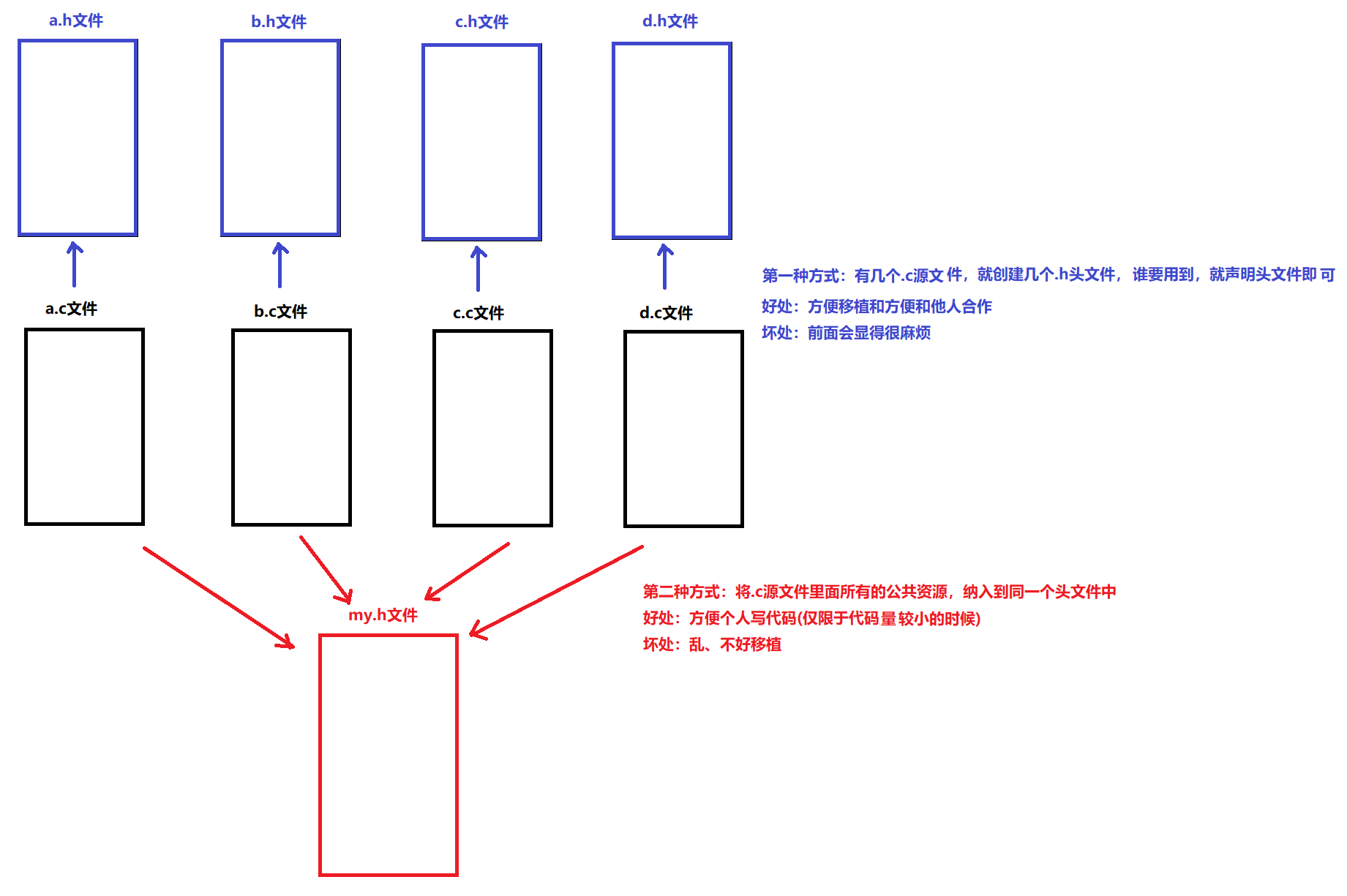
1、头文件的作用
说明:
在C语言程序中,通常一个项目会包含多个源码文件(.c)。当某些公共资源需要在各个源码文件中使用时,为了避免多次编写相同的代码,一般的做法是将这些公共资源放入头文件(.h)中,然后在各个源码文件中通过
#include指令包含即可。图解:
头文件的优势
1. 代码复用
避免在不同源文件中重复编写相同的声明和定义
提高代码的可维护性
2. 模块化开发
每个模块对应一个头文件和一个源文件
清晰的功能划分,便于团队协作
3. 编译优化
修改实现文件(.c)时,只需要重新编译该文件
头文件变化时,所有包含该头文件的源文件都需要重新编译
4. 接口与实现分离
头文件提供接口声明
源文件提供具体实现
隐藏实现细节,提供抽象接口
2、头文件的格式
说明:
头文件包含指令
#include的本质是复制粘贴,并且一个头文件中可以嵌套包含其它头文件,因此很容易出现头文件被重复包含的情况。解决方法:条件编译
// 防止递归包含(编译器多次进入到此处,浪费资源) #ifndef __HEADNAME_H // 如果没有定义这个宏标志__HEADNAME_H #define __HEADNAME_H // 定义这个宏标志(意味着只能进入这里面1次)// 头文件正文内容 // 函数声明、宏定义、类型定义等#endif // __HEADNAME_H3、头文件的内容
说明:
头文件所存放的内容,就是各个源码文件的彼此可见的公共资源,主要包括以下7个方面:
包括:
其它头文件
// 系统头文件 #include <stdint.h> #include <stdbool.h>// 第三方库头文件 #include <json-c/json.h>// 项目内部头文件 #include "config.h" #include "types.h"宏定义(函数、变量、常量)
// 常量宏 #define BUFFER_SIZE 4096 #define VERSION "1.2.3"// 函数式宏 #define ARRAY_SIZE(arr) (sizeof(arr) / sizeof((arr)[0])) #define DEBUG_PRINT(fmt, ...) printf("[DEBUG] " fmt, ##__VA_ARGS__)自定义类型(结构体、联合体、枚举、函数指针类型等...)
// 结构体 typedef struct {uint32_t id;char name[50];float score; } Student;// 枚举 typedef enum {COLOR_RED,COLOR_GREEN,COLOR_BLUE } Color;// 函数指针类型 typedef void (*CallbackFunc)(int status, void* data);函数声明
// 基本函数声明 int calculate_sum(int* array, int length); void initialize_system(void);// 带默认参数的函数声明(C99以上) void set_options(int timeout, int retries);全局变量声明
// 外部全局变量声明 extern int connection_count; extern double pi_value; extern const char* error_messages[];静态函数定义
// 内联静态函数 static inline int clamp(int value, int min, int max) {if (value < min) return min;if (value > max) return max;return value; }// 静态工具函数 static int validate_input(const char* input) {return input != NULL && strlen(input) > 0; }静态变量定义
// 静态常量 static const int MAX_RETRIES = 3; static const char* LOG_PREFIX = "[APP]";// 静态内联变量(C99) static inline const double E = 2.71828;特别说明:
全局变量和普通函数
// 在源文件(.c)中定义 int global_counter = 0; void process_data(void) { /* 实现 */ }// 在头文件(.h)中声明 extern int global_counter; extern void process_data(void);静态函数和变量
// 静态函数/变量只在当前编译单元可见 // 如果多个文件都需要使用,放在头文件中定义最方便// 在头文件中定义静态工具函数 static int helper_function(void) {return 42; }头文件包含策略
// 原则:最小化包含 // 只在必要的地方包含头文件// 在.c文件中包含实现所需的头文件 // 在.h文件中只包含声明所需的头文件
4、头文件的使用
说明:
头文件编写好后,可以被各个需要的源码文件包含,包含头文件的预处理指令如下:
基本语法:
// main.c 文件中使用自定义头文件和系统头文件 #include "head.h" // 包含自定义的头文件 #include <stdio.h> // 包含系统预定义的头文件int main(void) {// 使用头文件中定义的函数和变量return 0; }两种引用方式:
1. 双引号包含
""
搜索路径:先在指定位置搜索,然后在系统标准路径搜索
适用场景:自定义头文件、项目内部头文件
示例:
#include "my_header.h"2. 尖括号包含
<>
搜索路径:只在系统标准路径搜索
适用场景:系统标准头文件、第三方库头文件
示例:
#include <stdio.h>由于自定义的头文件一般放在源码文件的周围,因此需要在编译的时候通过特定的选项来指定位置,而系统头文件都统一放在标准路径下,一般无需指定位置。
假设在源码文件 main.c 中,包含了两个头文件:head.h 和 stdio.h ,由于他们一个是自定义头文件,一个是系统标准头文件,前者放在项目 pro/inc 路径下,后者存放于系统头文件标准路径下(一般位于 /usr/include),因此对于这个程序的编译指令应写作:
gec@ubuntu:~/pro$ gcc main.c -o main -I /home/gec/pro/inc /*其中-I,是指定头文件路径的意思其中/home/gec/pro/inc 是自定义头文件 head.h 所在的路径 */语法要点:
预处理指令 #include 的本质是复制粘贴:将指定头文件的内容复制到源码文件中。
系统标准头文件路径可以通过编译选项 -v 来获知,比如:
gec@ubuntu:~/pro$ gcc main.c -I /home/gec/pro/inc -v ... ... #include "..." search starts here: #include <...> search starts here:/home/gec/pro/inc/usr/lib/gcc/x86_64-linux-gnu/7/include/usr/local/include/usr/lib/gcc/x86_64-linux-gnu/7/include-fixed/usr/include/x86_64-linux-gnu/usr/include ... ...