009=基于YOLO12与PaddleOCR的车牌识别系统(Python+PySide6界面+训练代码)
文章目录
- 一、环境配置
- 1.1 GPU环境配置
- 1.2 Python环境配置
- 二、数据集介绍
- 2.1 数据集类别
- 2.2 数据集展示(部分)
- 三、系统演示视频
- 四、模型原理
- 4.1 网络结构概述
- 4.2 区域注意力机制(Area Attention)
- 4.3 残差效率层聚合网络(R-ELAN)
- 4.4 注意力架构优化策略
- 4.5 多任务支持能力
- 4.6 推理与部署优势
- 4.6 PaddleOCR
- 五、代码实现
- 5.1 训练代码(yolo_train.py)
- 5.2 验证代码(yolo_val)
- 5.3 推理代码(yolo_detect)
- 5.4 主界面代码(main_ui.py)
- 六、性能评估
- 6.1 训练结果
- 七、工程获取
从0搭建YOLO目标检测系统:实战项目+完整流程+界面开发(附源码)
一、环境配置
1.1 GPU环境配置
- 如果您的电脑配备了
NVIDIA GPU并希望使用GPU进行训练、推理或验证操作,请先确认是否已正确安装CUDA。 - 打开命令提示符,输入以下命令:
nvcc -V
- 如果在命令提示符出现下图所示,则说明已经安装好了CUDA。否则请根据教程2025 CUDA 和 cuDNN 在 Windows 上如何安装配置(保姆级详细版)_windows cudnn安装-CSDN博客
- 请添加图片描述

1.2 Python环境配置
- 安装
torch(以cu113+torch1.12.0为例,若想安装其他版本请到官网)
pip install torch==1.12.0+cu113 torchvision==0.13.0+cu113 torchaudio==0.12.0 --extra-index-url https://download.pytorch.org/whl/cu113
- 安装
ultralytics
pip install ultralytics
- 安装
pyside6
pip install pyside6
- 安装
numpy,在运行时可能出现RuntimeError: Numpy is not available则需要降低numpy版本:
pip install numpy==1.23.5
- 虚拟环境百度网盘下载地址:python虚拟环境百度网盘地址
注意:除了上述环境外,还需要
PaddleOCR库,请参考https://zhuanlan.zhihu.com/p/638836038安装
二、数据集介绍
2.1 数据集类别
- [“new_energy”,“fuel_vehicles”] 新能源汽车 和 燃油汽车
2.2 数据集展示(部分)
- 部分数据集展示如下:

| 数据集 | 图像数量 | 描述 |
|---|---|---|
| 训练集 | 856张 | 用于模型训练 |
| 验证集 | 245张 | 用于调整模型参数和用于最终效果评估 |
三、系统演示视频
- 演示与介绍视频(参考):基于yolov8柑橘检测系统_哔哩哔哩_bilibili

四、模型原理
YOLOv12(You Only Look Once Version 12)是由上海人工智能实验室等机构于 2024 年发布的 YOLO 系列全新版本。YOLOv12 首次将注意力机制作为模型设计的核心,提出多个轻量高效的注意力模块,显著提升了检测精度与推理效率,特别适用于边缘设备的部署场景。
4.1 网络结构概述
YOLOv12 采用典型的三段式结构:Backbone(骨干网络)+ Neck(特征融合)+ Head(预测头),但全面以注意力机制为主导,摒弃传统卷积堆叠方案。
- Backbone:基于区域注意力机制构建的高效主干网络,具备更大感受野和全局建模能力;
- Neck:引入改进版的 R-ELAN 模块,提升特征聚合能力;
- Head:兼容目标检测、分割、姿态估计等多任务场景,结构更加灵活。
整体网络更加轻量、计算开销更低,适配多种部署平台(边缘端到云端)。
4.2 区域注意力机制(Area Attention)
区域注意是一种新型轻量化注意力机制,设计目标是在减少计算量的同时扩展感受野。
- 将特征图按横向或纵向划分为
l个大小相等的区域(默认 l=4); - 在每个区域内独立计算注意力并合并;
- 显著减少计算复杂度(从 O(H²W²) 降至 O((H/l)²W²) 或 O(H²(W/l)²));
- 可与 FlashAttention 结合,进一步减少显存访问压力;
- 相较标准自注意,具备更好的效率与全局感知能力。
4.3 残差效率层聚合网络(R-ELAN)
R-ELAN 是 YOLOv12 中引入的特征聚合模块,基于 YOLOv7 的 ELAN 结构改进而来,优化了在大规模注意力模型中的表现。
- 加入块级残差连接,提升训练稳定性;
- 引入缩放因子(LayerScale),抑制梯度爆炸;
- 构建类似瓶颈结构的路径拓扑,增强特征传递效率;
- 相较 ELAN,参数量减少约 18%,FLOPs 降低 24%。
4.4 注意力架构优化策略
YOLOv12 对标准 Transformer 架构进行了一系列定制化优化,使其适配 YOLO 风格的高效检测体系:
- 去除位置编码:通过引入 7×7 可分离卷积(Position Aware)实现隐式位置信息建模;
- 引入 FlashAttention:减少内存访问次数,提高显存使用效率;
- 调整 MLP 扩展比例:将原始 4 缩小至 1.2~2,以减少前馈层计算冗余;
- 减少堆叠层数:提升训练收敛速度和推理效率;
- 合理融合卷积结构:利用卷积的局部建模能力,增强模型表达性。
这些优化措施综合提高了 YOLOv12 的稳定性、效率与精度。
4.5 多任务支持能力
YOLOv12 提供完整的多任务支持,适配各种复杂视觉场景。
- ✅ 目标检测(Object Detection)
- ✅ 实例分割(Instance Segmentation)
- ✅ 图像分类(Image Classification)
- ✅ 姿态估计(Pose Estimation)
- ✅ 定向目标检测(Oriented Object Detection,OBB)
其统一的注意力架构为多任务融合提供了更强的泛化能力与可扩展性。
4.6 推理与部署优势
YOLOv12 在模型压缩、推理速度与平台兼容性方面进行了全面优化,适合多种实际应用场景。
- 支持多平台部署(Jetson、Raspberry Pi、GPU、服务器);
- 推理延迟低(在 RTX 3080 上延迟仅 4.1ms);
- 精度与速度同时优于同类 Anchor-Free 和 Transformer 检测器(如 RT-DETR);
- 可导出为 ONNX、TensorRT 等格式,便于边缘设备部署;
- 支持从轻量级(YOLOv12-N)到高精度(YOLOv12-X)的多尺度模型选择。
4.6 PaddleOCR
PaddleOCR 是百度基于飞桨框架开发的开源 OCR 工具库,集成文本检测与识别核心功能,凭借高精度、多语言支持(覆盖 80 余种语言)、轻量化部署(超轻量模型适配移动端等场景)及丰富场景适配(如票据、手写体、弯曲文本等)成为热门选择。
它完全开源免费,支持 Python、C++、Docker 等多种部署方式,文档详尽且易用性强,无论是开发者集成到项目中,还是普通用户提取图片文字,都能高效满足需求,广泛应用于办公自动化、教育、生活工具等领域。
五、代码实现
5.1 训练代码(yolo_train.py)
# -*- coding: UTF-8 -*-
import warnings warnings.filterwarnings('ignore')
from ultralytics import YOLO if __name__ == '__main__': # 加载预训练模型 model = YOLO('yolov8n.pt') # 可以是 yolov8n/s/m/l/x.pt # 训练模型 model.train(data=r"填写你数据集data.yaml文件的地址", # 如果大家任务是其它的'ultralytics/cfg/default.yaml'找到这里修改task可以改成detect, segment, classify, pose imgsz=640, # 图像大小 epochs=100, # 训练轮数 single_cls=False, # 是否是单类别检测 batch=4, # 批大小 close_mosaic=0, # 倒数多少轮关闭mosaic workers=0, # 线程数 device='0', # 选择GPU还是CPU optimizer='SGD', # using SGD 优化器 默认为auto建议大家使用固定的. # resume=, # 续训的话这里填写True, yaml文件的地方改为lats.pt的地址,需要注意的是如果你设置训练200轮次模型训练了200轮次是没有办法进行续训的. amp=True, # 如果出现训练损失为Nan可以关闭amp project='runs/train', # 保存的项目 name='exp', # 保存的名称 )
5.2 验证代码(yolo_val)
# -*- coding: UTF-8 -*-
import warnings warnings.filterwarnings('ignore')
from ultralytics import YOLO # 加载训练好的模型
model = YOLO('runs/train/exp/weights/best.pt') # 替换为你的最佳模型路径
if __name__ == '__main__': # 验证模型 metrics = model.val( data='coco128.yaml', # 数据集配置文件路径 batch=16, # 批量大小 imgsz=640, # 输入图像大小 # conf=0.25, # 对象置信度阈值 # iou=0.6, # NMS IoU阈值 task='val', # 可以是 'val', 'test' 或 'speed' device='0', # 使用GPU (可以是 '0', '0,1,2,3' 或 'cpu') half=False, # 使用FP16半精度推理 dnn=False, # 使用OpenCV DNN进行ONNX推理 plots=True, # 保存验证结果图 save_json=False, # 保存结果为JSON文件 save_hybrid=False, # 保存混合版本标签 save_conf=False, # 保存结果带置信度 save_txt=False, # 保存结果为.txt文件 save_dir='runs/val', # 保存目录 name='exp', # 实验名称 exist_ok=False, # 是否覆盖现有项目 augment=False, # 增强推理 verbose=True, # 打印详细输出 )
5.3 推理代码(yolo_detect)
# -*- coding: UTF-8 -*-
import warnings warnings.filterwarnings('ignore')
from ultralytics import YOLO if __name__ == '__main__': # 加载训练好的模型 model = YOLO('runs/train/exp/weights/best.pt') # 替换为你的最佳模型路径 # 图像推理 results = model.predict( source='path/to/image.jpg', # 可以是文件/文件夹/URL/glob/PIL/numpy/mp4/ conf=0.25, # 对象置信度阈值 iou=0.7, # NMS IoU阈值 imgsz=640, # 推理图像大小 device='0', # 使用GPU (可以是 '0', '0,1,2,3' 或 'cpu') show=False, # 显示结果 save=True, # 保存结果 save_txt=False, # 保存结果为.txt文件 save_conf=False, # 保存结果带置信度 save_crop=False, # 保存裁剪的预测框 show_labels=True, # 显示标签 show_conf=True, # 显示置信度 max_det=300, # 每张图像最大检测数 augment=False, # 增强推理 visualize=False, # 可视化模型特征 agnostic_nms=False, # 类别无关NMS retina_masks=False, # 使用高分辨率分割掩码 classes=None, # 按类别过滤结果 boxes=True, # 在分割预测中显示框 line_thickness=3, # 边界框厚度 (像素) half=False, # 使用FP16半精度推理 dnn=False, # 使用OpenCV DNN进行ONNX推理 vid_stride=1, # 视频帧率步长 stream_buffer=False, # 缓冲所有流帧 (True) 或返回最新帧 (False) project='runs/detect', # 保存项目名称 name='exp', # 实验名称 exist_ok=False, # 是否覆盖现有项目 )
5.4 主界面代码(main_ui.py)
# -*- coding: UTF-8 -*-
import warnings
warnings.filterwarnings("ignore")
import sys
import os
import time import cv2
import numpy as np
from ultralytics import YOLO
from PySide6.QtWidgets import QFileDialog, QHBoxLayout, QDialog
from PySide6.QtWidgets import QApplication, QMainWindow, QMessageBox, QPushButton
from PySide6.QtCore import Qt, QThread, Signal, QTimer
from PySide6.QtGui import QPixmap, QImage
from PySide6 import QtGui, QtCore from yolov8Qt import Ui_MainWindow def convert2QImage(img): height, width, channel = img.shape return QImage(img, width, height, width * channel, QImage.Format_RGB888) #图形界面按钮的方法绑定
class MainWindow(QMainWindow, Ui_MainWindow): def __init__(self, parent=None): super(MainWindow, self).__init__(parent) self.setupUi(self) # 加载pyside6的UI self.timer = QTimer() # 加载定时器 self.timer.setInterval(100) # 设置定时器触发时间 self.video = None self.is_running = False self.weights_path = 'runs/orange/weights/best.pt' try: self.model = YOLO(self.weights_path) self.model(np.zeros((800, 800, 3)).astype(np.uint8)) #预先加载推理模型 except: pass # 初始化conf和iou self.conf = self.doubleSpinBox_conf.value() if hasattr(self, 'doubleSpinBox_conf') else 0.5 self.iou = self.doubleSpinBox_iou.value() if hasattr(self, 'doubleSpinBox_iou') else 0.7 self.bind_slots() # 事件绑定 def bind_slots(self): self.Button_checkImg.clicked.connect(self.select_images) # 检测图片 self.Button_openCamera.clicked.connect(self.open_camera) # 检测摄像头 self.Button_checkVideo.clicked.connect(self.select_video) # 检测视频 # self.Button_select_folder.clicked.connect(self.select_folder) # 检测文件夹 self.Button_select_w_p.clicked.connect(self.select_weights) # 选择权重 self.pushButton_bofang.clicked.connect(self.run_stop) # 播放暂停 self.timer.timeout.connect(self.video_pred) # conf/iou参数绑定 if hasattr(self, 'doubleSpinBox_conf'): self.doubleSpinBox_conf.valueChanged.connect(self.update_conf) if hasattr(self, 'doubleSpinBox_iou'): self.doubleSpinBox_iou.valueChanged.connect(self.update_iou) # horizontalSlider绑定 if hasattr(self, 'horizontalSlider_conf'): self.horizontalSlider_conf.valueChanged.connect(self.update_hor_conf) if hasattr(self, 'horizontalSlider_iou'): self.horizontalSlider_iou.valueChanged.connect(self.update_hor_iou) def update_conf(self, value): self.conf = value if hasattr(self, 'horizontalSlider_conf'): self.horizontalSlider_conf.setValue(int(value * 100)) def update_iou(self, value): self.iou = value if hasattr(self, 'horizontalSlider_iou'): self.horizontalSlider_iou.setValue(int(value * 100)) def update_hor_conf(self, value): conf = value * 0.01 self.conf = conf if hasattr(self, 'doubleSpinBox_conf'): self.doubleSpinBox_conf.setValue(conf) def update_hor_iou(self, value): iou = value * 0.01 self.iou = iou if hasattr(self, 'doubleSpinBox_iou'): self.doubleSpinBox_iou.setValue(iou) def video_pred(self): ret, frame = self.video.read() if not ret: self.run_stop() else: # 进度条处理 if hasattr(self, 'progressBar') and self.video: try: current_frame = int(self.video.get(cv2.CAP_PROP_POS_FRAMES)) total_frames = int(self.video.get(cv2.CAP_PROP_FRAME_COUNT)) if total_frames > 0: percent = int(current_frame / total_frames * 100) self.progressBar.setValue(percent) except Exception: pass start_time = time.time() results = self.model(frame, conf=self.conf, iou=self.iou) end_time = time.time() img_bgr = results[0].plot() num = len(results[0].boxes) if hasattr(self, 'label_nums'): self.label_nums.setText(str(num)) if hasattr(self, 'label_times'): self.label_times.setText(f"{(end_time - start_time)*1000:.1f} ms") # 自动保存视频帧 if hasattr(self, 'checkBox_isSave') and self.checkBox_isSave.isChecked(): save_dir = r'./save_result' os.makedirs(save_dir, exist_ok=True) if not hasattr(self, 'video_writer') or self.video_writer is None: fourcc = cv2.VideoWriter_fourcc(*'mp4v') h, w = img_bgr.shape[:2] # 判断是摄像头还是视频文件 if hasattr(self, 'video_path') and self.video_path: base_name = os.path.splitext(os.path.basename(self.video_path))[0] save_path = os.path.join(save_dir, f'{base_name}.mp4') fps = int(self.video.get(cv2.CAP_PROP_FPS)) or 25 else: import datetime now = datetime.datetime.now().strftime('%Y%m%d_%H%M%S') save_path = os.path.join(save_dir, f'camera_{now}.mp4') fps = int(1000 // self.timer.interval()) self.video_writer = cv2.VideoWriter(save_path, fourcc, fps, (w, h)) self.video_writer.write(img_bgr) height, width = img_bgr.shape[:2] width_ratio = 1280 / height height_ratio = 720 / width scale_ratio = min(width_ratio, height_ratio) new_width = int(width * scale_ratio) new_height = int(height * scale_ratio) img_bgr = cv2.resize(img_bgr, (new_width, new_height)) img_rgb = cv2.cvtColor(img_bgr, cv2.COLOR_BGR2RGB) self.label_result.setPixmap(QPixmap.fromImage(convert2QImage(img_rgb))) def select_images(self): options = QFileDialog.Options() options |= QFileDialog.ReadOnly image_path, _ = QFileDialog.getOpenFileName(self, "Select Image", "", "Images (*.png *.jpg *.jpeg *.bmp *.gif);;All Files (*)", options=options) if image_path: if hasattr(self, 'progressBar'): self.progressBar.setValue(100) start_time = time.time() results = self.model(image_path, conf=self.conf, iou=self.iou) end_time = time.time() img_bgr = results[0].plot() num = len(results[0].boxes) if hasattr(self, 'label_nums'): self.label_nums.setText(str(num)) if hasattr(self, 'label_times'): self.label_times.setText(f"{(end_time - start_time)*1000:.1f} ms") # 自动保存图片 if hasattr(self, 'checkBox_isSave') and self.checkBox_isSave.isChecked(): save_dir = r'./save_result' os.makedirs(save_dir, exist_ok=True) cv2.imwrite(os.path.join(save_dir, os.path.basename(image_path)), img_bgr) height, width = img_bgr.shape[:2] width_ratio = 1440 / height height_ratio = 960 / width scale_ratio = min(width_ratio, height_ratio) new_width = int(width * scale_ratio) new_height = int(height * scale_ratio) img_bgr = cv2.resize(img_bgr, (new_width, new_height)) img_rgb = cv2.cvtColor(img_bgr, cv2.COLOR_BGR2RGB) self.label_result.setPixmap(QPixmap.fromImage(convert2QImage(img_rgb))) def select_weights(self): options = QFileDialog.Options() weights_path, _ = QFileDialog.getOpenFileName(self, '选择pt权重', '', 'pt (*.pt)', options=options) if weights_path: # self.end_thread() self.line_weights.setText(weights_path) self.weights_path = weights_path self.model = YOLO(self.weights_path) self.model(np.zeros((800, 800, 3)).astype(np.uint8)) #预先加载推理模型 def open_camera(self): self.video = cv2.VideoCapture(0) self.video_path = None # 摄像头时清空video_path bool_open = self.video.isOpened() if not bool_open: QMessageBox.warning(self, u"Warning", u"打开摄像头失败", buttons=QMessageBox.Ok, defaultButton=QMessageBox.Ok) def select_video(self): options = QFileDialog.Options() video_path, _ = QFileDialog.getOpenFileName(self, '选择视频', '', 'Videos (*.mp4 *.avi *.mkv);;All Files (*)', options=options) if video_path: self.video = cv2.VideoCapture(video_path) self.video_path = video_path # 记录当前视频路径 else: self.video_path = None def run_stop(self): if not self.video: QMessageBox.warning(self, u"Warning", u"请选择视频或者摄像头", buttons=QMessageBox.Ok, defaultButton=QMessageBox.Ok) return else: self.is_running = not self.is_running # 切换状态 icon = QtGui.QIcon() if self.is_running: self.timer.start() icon.addPixmap(QtGui.QPixmap("icon/暂停.png"), QtGui.QIcon.Normal, QtGui.QIcon.Off) else: self.timer.stop() icon.addPixmap(QtGui.QPixmap("icon/播放.png"), QtGui.QIcon.Normal, QtGui.QIcon.Off) # 关闭视频保存 if hasattr(self, 'video_writer') and self.video_writer is not None: self.video_writer.release() self.video_writer = None self.pushButton_bofang.setIcon(icon) self.pushButton_bofang.setIconSize(QtCore.QSize(32, 32)) if __name__ == "__main__": app = QApplication(sys.argv) myWin = MainWindow() myWin.show() sys.exit(app.exec())
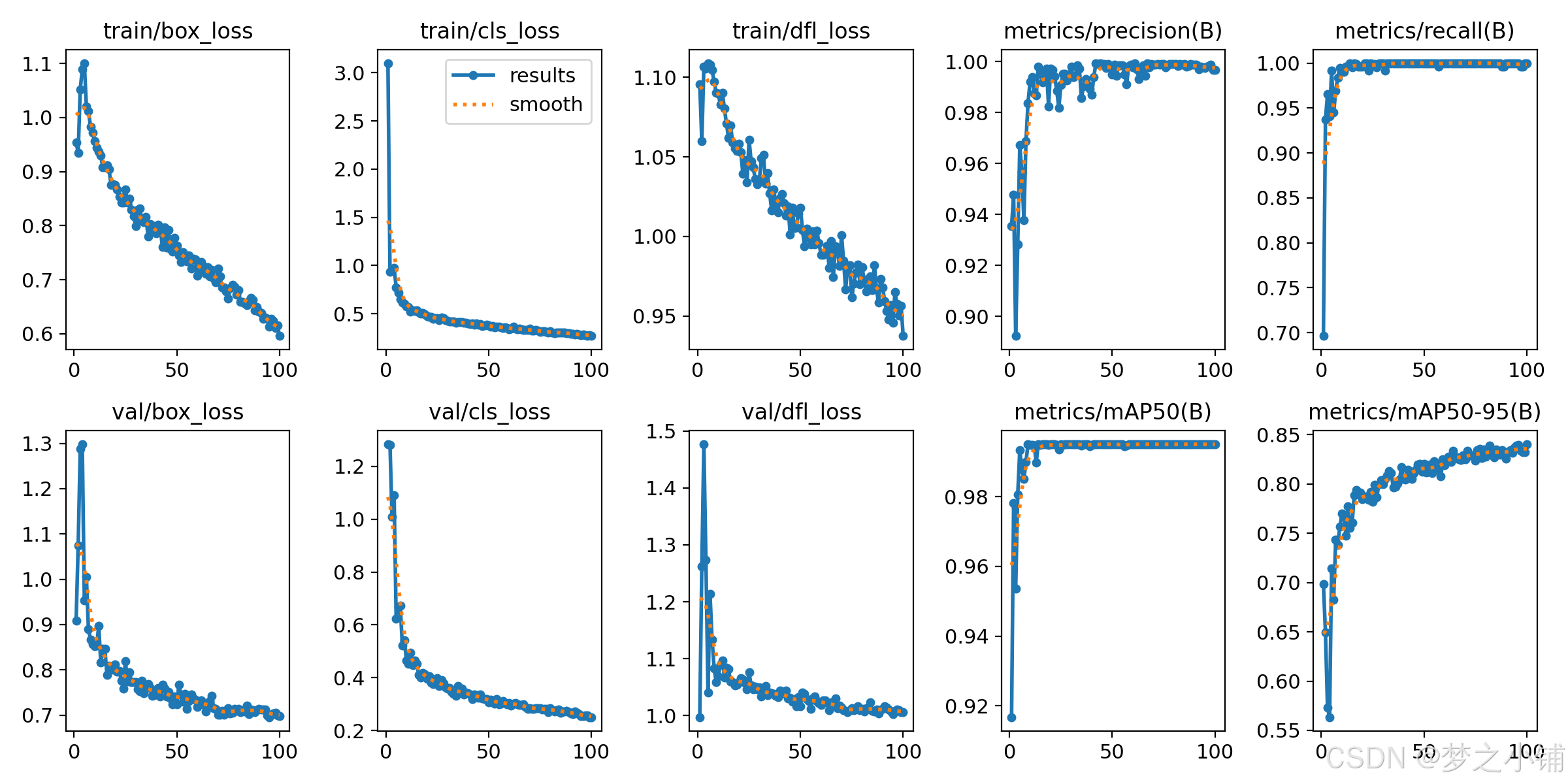
六、性能评估
6.1 训练结果
- 模型
map为99%。
七、工程获取
