Kubernetes集群升级与etcd备份恢复指南
目录
Kubernetes etcd备份恢复
集群管理命令
环境变量
查看etcd版本
查看etcd集群节点信息
查看集群健康状态
查看告警事件
添加成员(单节点部署的etcd无法直接扩容)(不用做)
更新成员
删除成员
数据库操作命令
增加(put)
查询(get)
删除(del)
更新(put覆盖)
查询键历史记录查询
监听命令
监听单个键
同时监听多个键
租约命令
添加租约
查看租约
租约续约
删除租约
多key同一租约
备份恢复命令
生成快照
查看快照
恢复快照
备份恢复演示
恢复案例
单master集群
多master集群
Kubernetes集群升级指南
前言
一、集群升级过程辅助命令
二、升级master节点
2.1、升级kubeadm。
2.2、验证升级计划
2.3、master节点升级
三、升级node节点
总结
Kubernetes etcd备份恢复
集群管理命令
etcdctl是一个命令行的客户端,它提供了一些命令,可以方便我们在对服务进行测试或者手动修改数据库内容。etcdctl命令基本用法如下所示:
etcdctl [global options] command [command options] [args...]具体的命令选项参数可以通过 etcdctl command --help来获取相关帮助
环境变量
获得etcd数据库的访问url
[root@k8s-master ~]# kubectl -n kube-system get pods etcd-k8s-master -o yaml | grep -A10 "containers:" | grep "https://"- --advertise-client-urls=https://192.168.158.15:2379- --initial-advertise-peer-urls=https://192.168.158.15:2380- --initial-cluster=k8s-master=https://192.168.158.15:2380如果遇到使用了TLS加密的集群,通常每条指令都需要指定证书路径和etcd节点地址,可以把相关命令行参数添加在环境变量中,在~/.bashrc添加以下内容:
[root@tiaoban etcd]# cat ~/.bashrc
HOST_1=https://192.168.166.3:2379
ENDPOINTS=${HOST_1}
# 如果需要使用原生命令,在命令开头加一个\ 例如:\etcdctl command
alias etcdctl="etcdctl --cert /etc/kubernetes/pki/etcd/peer.crt --key /etc/kubernetes/pki/etcd/peer.key --endpoints=https://192.168.158.6:2379 --insecure-skip-tls-verify"
[root@tiaoban etcd]# source ~/.bashrc查看etcd版本
[root@tiaoban etcd]# etcdctl version
etcdctl version: 3.4.23
API version: 3.4查看etcd集群节点信息
etcdctl member list -w table
+------------------+---------+------------+----------------------------+----------------------------+------------+
| ID | STATUS | NAME | PEER ADDRS | CLIENT ADDRS | IS LEARNER |
+------------------+---------+------------+----------------------------+----------------------------+------------+
| eba84a8571780cea | started | k8s-master | https://192.168.166.3:2380 | https://192.168.166.3:2379 | false |
+------------------+---------+------------+----------------------------+----------------------------+------------+查看集群健康状态
etcdctl endpoint status -w table
+----------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+
| ENDPOINT | ID | VERSION | DB SIZE | IS LEADER | IS LEARNER | RAFT TERM | RAFT INDEX | RAFT APPLIED INDEX | ERRORS |
+----------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+
| https://192.168.166.3:2379 | eba84a8571780cea | 3.5.15 | 7.1 MB | true | false | 4 | 15658 | 15658 | |
+----------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+
####表格内容解析
ENDPOINT:节点的地址,这里是 https://192.168.158.6:2379。这表示该节点的网络地址和端口。ID:节点的唯一标识符,这里是 6dc5c9ae772d8898。VERSION:节点的版本号,这里是 3.5.9。DB SIZE:数据库大小,这里是 9.1 MB。IS LEADER:是否为集群的领导者节点。true 表示该节点是领导者。IS LEARNER:是否为学习者节点。false 表示该节点不是学习者节点。RAFT TERM:Raft协议中的任期编号,这里是 4。Raft协议用于分布式系统的共识机制,任期编号用于区分不同的选举周期。RAFT INDEX:Raft协议中的日志索引,这里是 30622。它表示当前日志的最新位置。RAFT APPLIED INDEX:Raft协议中已应用的日志索引,这里是 30622。它表示已提交并应用到状态机的日志位置。ERRORS:错误信息,这里为空,表示没有错误查看告警事件
如果内部出现问题,会触发告警,可以通过命令查看告警引起原因,命令如下所示:
etcdctl alarm <subcommand> [flags]常用的子命令主要有两个:
# 查看所有告警
etcdctl alarm list
# 解除所有告警
etcdctl alarm disarm添加成员(单节点部署的etcd无法直接扩容)(不用做)
当集群部署完成后,后续可能需要进行节点扩缩容,就可以使用member命令管理节点。先查看当前集群信息
[root@tiaoban etcd]# etcdctl endpoint status --cluster -w table
+----------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+
| ENDPOINT | ID | VERSION | DB SIZE | IS LEADER | IS LEARNER | RAFT TERM | RAFT INDEX | RAFT APPLIED INDEX | ERRORS |
+----------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+
| http://192.168.10.100:2379 | 2e0eda3ad6bc6e1e | 3.4.23 | 20 kB | true | false | 8 | 16 | 16 | |
| http://192.168.10.12:2379 | 5d2c1bd3b22f796f | 3.4.23 | 20 kB | false | false | 8 | 16 | 16 | |
| http://192.168.10.11:2379 | bc34c6bd673bdf9f | 3.4.23 | 20 kB | false | false | 8 | 16 | 16 | |
+----------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+在启动新的etcd节点前,先向etcd集群声明添加节点的peer-urls和节点名称
[root@tiaoban etcd]# etcdctl member add etcd4 --peer-urls=http://192.168.158.9:2380
Member b112a60ec305e42a added to cluster cd30cff36981306b
ETCD_NAME="etcd4"
ETCD_INITIAL_CLUSTER="etcd1=http://192.168.10.100:2380,etcd3=http://192.168.10.12:2380,etcd4=http://192.168.10.100:12380,etcd2=http://192.168.10.11:2380"
ETCD_INITIAL_ADVERTISE_PEER_URLS="http://192.168.10.100:12380"
ETCD_INITIAL_CLUSTER_STATE="existing"接下来使用docker创建一个版本为3.4.23的etcd节点,运行在192.168.10.100上,使用host网络模式,endpoints地址为http://192.168.10.100:12379,节点名称为etcd4。
[root@tiaoban etcd]# mkdir -p /opt/docker/etcd/{conf,data}
[root@tiaoban etcd]# chown -R 1001:1001 /opt/docker/etcd/data/
[root@tiaoban etcd]# cat /opt/docker/etcd/conf/etcd.conf
# 节点名称
name: 'etcd4'
# 指定节点的数据存储目录
data-dir: '/data'
# 监听客户端请求的地址列表
listen-client-urls: "http://192.168.10.100:12379"
# 监听URL,用于节点之间通信监听地址
listen-peer-urls: "http://192.168.10.100:12380"
# 对外公告的该节点客户端监听地址,这个值会告诉集群中其他节点
advertise-client-urls: "http://192.168.10.100:12379"
# 服务端之间通讯使用的地址列表,该节点同伴监听地址,这个值会告诉集群中其他节点
initial-advertise-peer-urls: "http://192.168.10.100:12380"
# etcd启动时,etcd集群的节点地址列表
initial-cluster: "etcd1=http://192.168.10.100:2380,etcd3=http://192.168.10.12:2380,etcd2=http://192.168.10.11:2380,etcd4=http://192.168.10.100:12380"
# etcd集群初始化的状态,new代表新建集群,existing表示加入现有集群
initial-cluster-state: 'existing'
[root@tiaoban etcd]# docker run --name=etcd4 --net=host -d -v /opt/docker/etcd/data:/data -v /opt/docker/etcd/conf:/conf bitnami/etcd:latest etcd --config-file /conf/etcd.conf
a142f38c785f2b7c217fb15f01ac62addfeb22eeb44da00363b1f7b5ce398439etcd4启动后,查看集群节点信息:
[root@tiaoban etcd]# etcdctl endpoint status --cluster -w table
+-----------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+
| ENDPOINT | ID | VERSION | DB SIZE | IS LEADER | IS LEARNER | RAFT TERM | RAFT INDEX | RAFT APPLIED INDEX | ERRORS |
+-----------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+
| http://192.168.10.100:2379 | 2e0eda3ad6bc6e1e | 3.4.23 | 20 kB | true | false | 6 | 11 | 11 | |
| http://192.168.10.12:2379 | 5d2c1bd3b22f796f | 3.4.23 | 20 kB | false | false | 6 | 11 | 11 | |
| http://192.168.10.100:12379 | b112a60ec305e42a | 3.4.23 | 20 kB | false | false | 6 | 11 | 11 | |
| http://192.168.10.11:2379 | bc34c6bd673bdf9f | 3.4.23 | 20 kB | false | false | 6 | 11 | 11 | |
+-----------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+更新成员
当etcd节点故障,启动etcd时报错**member count is unequal**。如果有保留的数据目录下的文件时,可以通过使用 member update 命令,在保留 etcd 数据的情况下初始化集群数据,重新构建一个新的etcd集群节点。 模拟192.168.10.100:12380节点故障,但数据目录文件有备份,启动一个新的节点,地址为:192.168.10.100:22380
# 停用旧节点
[root@tiaoban etcd]# docker stop etcd4
etcd4
[root@tiaoban etcd]# docker rm etcd4
etcd4
# 更新节点地址
[root@tiaoban etcd]# cat conf/etcd.conf
# 节点名称
name: 'etcd4'
# 指定节点的数据存储目录
data-dir: '/data'
# 监听客户端请求的地址列表
listen-client-urls: "http://192.168.10.100:22379"
# 监听URL,用于节点之间通信监听地址
listen-peer-urls: "http://192.168.10.100:22380"
# 对外公告的该节点客户端监听地址,这个值会告诉集群中其他节点
advertise-client-urls: "http://192.168.10.100:22379"
# 服务端之间通讯使用的地址列表,该节点同伴监听地址,这个值会告诉集群中其他节点
initial-advertise-peer-urls: "http://192.168.10.100:22380"
# etcd启动时,etcd集群的节点地址列表
initial-cluster: "etcd1=http://192.168.10.100:2380,etcd2=http://192.168.10.11:2380,etcd3=http://192.168.10.12:2380,etcd4=http://192.168.10.100:22380"
# etcd集群初始化的状态,new代表新建集群,existing表示加入现有集群
initial-cluster-state: 'existing'
# 启动新节点
[root@tiaoban etcd]# docker run --name=etcd4 --net=host -d -v /opt/docker/etcd/data:/data -v /opt/docker/etcd/conf:/conf bitnami/etcd:3.4.23 etcd --config-file /conf/etcd.conf
03c03ac7e6b50a8600cefe443ecafdb03f8f61f153b1a1138029c1726826d74e
[root@tiaoban etcd]# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
03c03ac7e6b5 bitnami/etcd:3.4.23 "/opt/bitnami/script…" 3 seconds ago Up 3 seconds etcd4执行更新member操作,指定新的节点地址。
[root@tiaoban etcd]# etcdctl member update b112a60ec305e42a --peer-urls=http://192.168.10.100:22380
Member b112a60ec305e42a updated in cluster cd30cff36981306b查看集群节点信息,节点信息更新完成。
[root@tiaoban etcd]# etcdctl endpoint status --cluster -w table
+-----------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+
| ENDPOINT | ID | VERSION | DB SIZE | IS LEADER | IS LEARNER | RAFT TERM | RAFT INDEX | RAFT APPLIED INDEX | ERRORS |
+-----------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+
| http://192.168.10.100:2379 | 2e0eda3ad6bc6e1e | 3.4.23 | 20 kB | true | false | 6 | 14 | 14 | |
| http://192.168.10.12:2379 | 5d2c1bd3b22f796f | 3.4.23 | 20 kB | false | false | 6 | 14 | 14 | |
| http://192.168.10.100:22379 | b112a60ec305e42a | 3.4.23 | 20 kB | false | false | 6 | 14 | 14 | |
| http://192.168.10.11:2379 | bc34c6bd673bdf9f | 3.4.23 | 20 kB | false | false | 6 | 14 | 14 | |
+-----------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+删除成员
主要用法如下所示:
etcdctl member remove <memberID> [flags]模拟192.168.10.100:22379节点下线操作
[root@tiaoban etcd]# docker stop etcd4
etcd4
[root@tiaoban etcd]# docker rm etcd4
etcd4
[root@tiaoban etcd]# etcdctl member remove b112a60ec305e42a
Member b112a60ec305e42a removed from cluster cd30cff36981306b
[root@tiaoban etcd]# etcdctl endpoint status --cluster -w table
+----------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+
| ENDPOINT | ID | VERSION | DB SIZE | IS LEADER | IS LEARNER | RAFT TERM | RAFT INDEX | RAFT APPLIED INDEX | ERRORS |
+----------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+
| http://192.168.10.100:2379 | 2e0eda3ad6bc6e1e | 3.4.23 | 20 kB | true | false | 6 | 16 | 16 | |
| http://192.168.10.12:2379 | 5d2c1bd3b22f796f | 3.4.23 | 20 kB | false | false | 6 | 16 | 16 | |
| http://192.168.10.11:2379 | bc34c6bd673bdf9f | 3.4.23 | 20 kB | false | false | 6 | 16 | 16 | |
+----------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+以下是 `etcdctl` 命令和选项的中文翻译:
命令:
- `alarm disarm` 停止所有告警
- `alarm list` 列出所有告警
- `auth disable` 禁用身份验证
- `auth enable` 启用身份验证
- `auth status` 返回身份验证状态
- `check datascale` 检查给定服务器端点上不同工作负载的数据存储内存使用情况
- `check perf` 检查 etcd 集群的性能
- `compaction` 压缩 etcd 中的事件历史记录
- `defrag` 对具有给定端点的 etcd 成员进行存储碎片整理
- `del` 删除指定的键或键范围 [key, range_end)
- `elect` 观察并参与领导者选举
- `endpoint hashkv` 打印 `--endpoints` 中每个端点的 KV 历史记录哈希
- `endpoint health` 检查 `--endpoints` 标志中指定的端点的健康状态
- `endpoint status` 打印 `--endpoints` 标志中指定的端点的状态
- `get` 获取键或键范围
- `help` 任何命令的帮助
- `lease grant` 创建租约
- `lease keep-alive` 保持租约活跃(续租)
- `lease list` 列出所有活跃的租约
- `lease revoke` 撤销租约
- `lease timetolive` 获取租约信息
- `lock` 获取命名锁
- `make-mirror` 在目标 etcd 集群创建镜像
- `member add` 向集群中添加成员
- `member list` 列出集群中的所有成员
- `member promote` 将集群中的非投票成员提升为投票成员
- `member remove` 从集群中移除成员
- `member update` 更新集群中的成员
- `move-leader` 将领导权转移到另一个 etcd 集群成员
- `put` 将给定的键放入存储中
- `role add` 添加新角色
- `role delete` 删除角色
- `role get` 获取角色的详细信息
- `role grant-permission` 给角色授予键
- `role list` 列出所有角色
- `role revoke-permission` 从角色中撤销键
- `snapshot restore` 将 etcd 成员快照恢复到 etcd 目录
- `snapshot save` 将 etcd 节点后端快照存储到给定文件
- `snapshot status` [已弃用] 获取给定文件的后端快照状态
- `txn` 事务处理所有请求
- `user add` 添加新用户
- `user delete` 删除用户
- `user get` 获取用户的详细信息
- `user grant-role` 给用户授予角色
- `user list` 列出所有用户
- `user passwd` 更改用户密码
- `user revoke-role` 从用户中撤销角色
- `version` 打印 etcdctl 的版本
- `watch` 监视键或前缀上的事件流
选项:
- `--cacert=""` 使用此 CA 包验证启用了 TLS 的安全服务器的证书
- `--cert=""` 使用此 TLS 证书文件标识安全客户端
- `--command-timeout=5s` 短命令的超时时间(不包括拨号超时)
- `--debug[=false]` 启用客户端调试日志记录
- `--dial-timeout=2s` 客户端连接的拨号超时时间
- `-d, --discovery-srv=""` 查询描述集群端点的 SRV 记录的域名
- `--discovery-srv-name=""` 使用 DNS 发现时查询的服务名称
- `--endpoints=[127.0.0.1:2379]` gRPC 端点
- `-h, --help[=false]` etcdctl 的帮助
- `--hex[=false]` 将字节字符串打印为十六进制编码的字符串
- `--insecure-discovery[=true]` 接受描述集群端点的不安全 SRV 记录
- `--insecure-skip-tls-verify[=false]` 跳过服务器证书验证(注意:此选项仅应在测试目的下启用)
- `--insecure-transport[=true]` 禁用客户端连接的传输安全
- `--keepalive-time=2s` 客户端连接的保活时间
- `--keepalive-timeout=6s` 客户端连接的保活超时时间
- `--key=""` 使用此 TLS 密钥文件标识安全客户端
- `--password=""` 身份验证的密码(如果使用此选项,--user 选项不应包含密码)
- `--user=""` 身份验证的用户名[:密码](如果未提供密码,将提示输入)
- `-w, --write-out="simple"` 设置输出格式(字段,JSON,protobuf,简单,表格)数据库操作命令
增加(put)
添加一个键值,基本用法如下所示:
etcdctl put [options] <key> <value> [flags]常用参数如下所示:
| 参数 | 功能描述 |
|---|---|
| –prev-kv | 输出修改前的键值 |
注意事项:
-
其中value接受从stdin的输入内容
-
如果value是以横线-开始,将会被视为flag,如果不希望出现这种情况,可以使用两个横线代替–
-
若键已经存在,则进行更新并覆盖原有值,若不存在,则进行添加
示例
[root@tiaoban etcd]# etcdctl put name cuiliang
OK
[root@tiaoban etcd]# etcdctl put location -- -beijing
OK
[root@tiaoban etcd]# etcdctl put foo1 bar1
OK
[root@tiaoban etcd]# etcdctl put foo2 bar2
OK
[root@tiaoban etcd]# etcdctl put foo3 bar3
OK查询(get)
查询键值,基本用法如下所示:
etcdctl get [options] <key> [range_end] [flags]常用参数如下所示:
| 参数 | 功能描述 |
|---|---|
| –hex | 以十六进制形式输出 |
| –limit number | 设置输出结果的最大值 |
| –prefix | 根据prefix进行匹配key |
| –order | 对输出结果进行排序,ASCEND 或 DESCEND |
| –sort-by | 按给定字段排序,CREATE, KEY, MODIFY, VALUE, VERSION |
| –print-value-only | 仅输出value值 |
| –from-key | 按byte进行比较,获取大于等于指定key的结果 |
| –keys-only | 仅获取keys |
示例
# 获取键值
[root@tiaoban etcd]# etcdctl get name
name
cuiliang
# 只获取值
[root@tiaoban etcd]# etcdctl get location --print-value-only
-beijing
# 批量取从foo1到foo3的值,不包括foo3
[root@tiaoban etcd]# etcdctl get foo foo3 --print-value-only
bar1
bar2
# 批量获取前缀为foo的值
[root@tiaoban etcd]# etcdctl get --prefix foo --print-value-only
bar1
bar2
bar3
# 批量获取符合前缀的前两个值
[root@tiaoban etcd]# etcdctl get --prefix --limit=2 foo --print-value-only
bar1
bar2
# 批量获取前缀为foo的值,并排序
[root@tiaoban etcd]# etcdctl get --prefix foo --print-value-only --order DESCEND
bar3
bar2
bar1删除(del)
删除键值,基本用法如下所示:
etcdctl del [options] <key> [range_end] [flags]常用参数如下所示:
| 参数 | 功能描述 |
|---|---|
| –prefix | 根据prefix进行匹配删除 |
| –prev-kv | 输出删除的键值 |
| –from-key | 按byte进行比较,删除大于等于指定key的结果 |
示例
# 删除name的键值
[root@tiaoban etcd]# etcdctl del name
1
# 删除从foo1到foo3且不包含foo3的键值
[root@tiaoban etcd]# etcdctl del foo1 foo3
2
# 删除前缀为foo的所有键值
[root@tiaoban etcd]# etcdctl del --prefix foo
1更新(put覆盖)
若键已经存在,则进行更新并覆盖原有值,若不存在,则进行添加。
查询键历史记录查询
etcd在每次键值变更时,都会记录变更信息,便于我们查看键变更记录
监听命令
watch是监听键或前缀发生改变的事件流, 主要用法如下所示:
etcdctl watch [options] [key or prefix] [range_end] [--] [exec-command arg1 arg2 ...] [flags]示例如下所示:
# 对某个key监听操作,当key1发生改变时,会返回最新值
etcdctl watch name
# 监听key前缀
etcdctl watch name --prefix
# 监听到改变后执行相关操作
etcdctl watch name -- etcdctl get ageetcdctl watch name – etcdctl put name Kevin,如果写成,会不会变成死循环,导致无限监视,尽量避免。 示例
监听单个键
# 启动监听命令
[root@tiaoban etcd]# etcdctl watch foo
#另一个控制台执行新增命令
[root@tiaoban ~]# etcdctl put foo bar
OK
# 观察控制台监听输出
[root@tiaoban etcd]# etcdctl watch foo
PUT
foo
bar
#另一个控制台执行更新命令
[root@tiaoban ~]# etcdctl put foo bar123
OK
# 观察控制台监听输出
[root@tiaoban etcd]# etcdctl watch foo
PUT
foo
bar
PUT
foo
bar123
#另一个控制台执行删除命令
[root@tiaoban ~]# etcdctl del foo
1
# 观察控制台监听输出
[root@tiaoban etcd]# etcdctl watch foo
PUT
foo
bar
PUT
foo
bar123
DELETE
foo同时监听多个键
# 监听前缀为foo的键
[root@tiaoban etcd]# etcdctl watch --prefix foo
# 另一个控制台执行操作
[root@tiaoban ~]# etcdctl put foo1 bar1
OK
[root@tiaoban ~]# etcdctl put foo2 bar2
OK
[root@tiaoban ~]# etcdctl del foo1
1
# 观察控制台输出
[root@tiaoban etcd]# etcdctl watch --prefix foo
PUT
foo1
bar1
PUT
foo2
bar2
DELETE
foo1
# 监听指定的多个键
[root@tiaoban etcd]# etcdctl watch -i
watch name
watch location
# 另一个控制台执行操作
[root@tiaoban ~]# etcdctl put name cuiliang
OK
[root@tiaoban ~]# etcdctl del name
1
[root@tiaoban ~]# etcdctl put location beijing
OK
# 观察控制台输出
[root@tiaoban etcd]# etcdctl watch -i
watch name
watch location
PUT
name
cuiliang
DELETE
name
PUT
location
beijing租约命令
租约具有生命周期,需要为租约授予一个TTL(time to live),将租约绑定到一个key上,则key的生命周期与租约一致,可续租,可撤销租约,类似于redis为键设置过期时间。其主要用法如下所示:
etcdctl lease <subcommand> [flags]添加租约
主要用法如下所示:
etcdctl lease grant <ttl> [flags]示例:
# 设置60秒后过期时间
[root@tiaoban etcd]# etcdctl lease grant 60
lease 6e1e86f4c6512a2b granted with TTL(60s)
# 把foo和租约绑定,设置成60秒后过期
[root@tiaoban etcd]# etcdctl put --lease=6e1e86f4c6512a29 foo bar
OK
# 租约期内查询键值
[root@tiaoban etcd]# etcdctl get foo
foo
bar
# 租约期外查询键值
[root@tiaoban etcd]# etcdctl get foo
返回为空查看租约
查看租约信息,以便续租或查看租约是否仍然存在或已过期。 查看租约详情主要用法如下所示:
etcdctl lease timetolive <leaseID> [options] [flags]示例:
# 添加一个50秒的租约
[root@tiaoban etcd]# etcdctl lease grant 50
lease 6e1e86f4c6512a32 granted with TTL(50s)
# 将name键绑定到6e1e86f4c6512a32租约上
[root@tiaoban etcd]# etcdctl put --lease=6e1e86f4c6512a32 name cuiliang
OK
# 查看所有租约列表
[root@tiaoban etcd]# etcdctl lease list
found 1 leases
6e1e86f4c6512a32
# 查看租约详情,remaining(6s) 剩余有效时间6秒;--keys 获取租约绑定的 key
[root@tiaoban etcd]# etcdctl lease timetolive --keys 6e1e86f4c6512a32
lease 6e1e86f4c6512a32 granted with TTL(50s), remaining(6s), attached keys([name])租约续约
通过刷新 TTL 值来保持租约的有效,使其不会过期。 主要用法如下所示:
etcdctl lease keep-alive [options] <leaseID> [flags]示例如下所示:
# 设置60秒后过期租约
[root@tiaoban etcd]# etcdctl lease grant 60
lease 6e1e86f4c6512a36 granted with TTL(60s)
# 把name和租约绑定,设置成 60 秒后过期
[root@tiaoban etcd]# etcdctl put --lease=6e1e86f4c6512a36 name cuiliang
OK
# 自动定时执行续约,续约成功后每次租约为60秒
[root@tiaoban etcd]# etcdctl lease keep-alive 6e1e86f4c6512a36
lease 6e1e86f4c6512a36 keepalived with TTL(60)
lease 6e1e86f4c6512a36 keepalived with TTL(60)
lease 6e1e86f4c6512a36 keepalived with TTL(60)
……删除租约
通过租约 ID 撤销租约,撤销租约将删除其所有绑定的 key。 主要用法如下所示:
etcdctl lease revoke <leaseID> [flags]示例如下所示:
# 设置600秒后过期租约
[root@tiaoban etcd]# etcdctl lease grant 600
lease 6e1e86f4c6512a39 granted with TTL(600s)
# 把foo和租约绑定,600秒后过期
[root@tiaoban etcd]# etcdctl put --lease=6e1e86f4c6512a39 foo bar
OK
# 查看租约详情
[root@tiaoban etcd]# etcdctl lease timetolive --keys 6e1e86f4c6512a39
lease 6e1e86f4c6512a39 granted with TTL(600s), remaining(556s), attached keys([foo])
# 删除租约
[root@tiaoban etcd]# etcdctl lease revoke 6e1e86f4c6512a39
lease 6e1e86f4c6512a39 revoked
# 查看租约详情
[root@tiaoban etcd]# etcdctl lease timetolive --keys 6e1e86f4c6512a39
lease 6e1e86f4c6512a39 already expired
# 获取键值
[root@tiaoban etcd]# etcdctl get foo
返回为空多key同一租约
一个租约支持绑定多个 key
# 设置60秒后过期的租约
[root@tiaoban etcd]# etcdctl lease grant 60
lease 6e1e86f4c6512a3e granted with TTL(60s)
# foo1与租约绑定
[root@tiaoban etcd]# etcdctl put --lease=6e1e86f4c6512a3e foo1 bar1
OK
# foo2与租约绑定
[root@tiaoban etcd]# etcdctl put --lease=6e1e86f4c6512a3e foo2 bar2
OK
# 查看租约详情
[root@tiaoban etcd]# etcdctl lease timetolive --keys 6e1e86f4c6512a3e
lease 6e1e86f4c6512a3e granted with TTL(60s), remaining(14s), attached keys([foo1 foo2])租约过期后,所有 key 值都会被删除,因此:
-
当租约只绑定了一个 key 时,想删除这个 key,最好的办法是撤销它的租约,而不是直接删除这个 key。
-
当租约没有绑定key时,应主动把它撤销掉,单纯删除 key 后,续约操作持续进行,会造成内存泄露。
直接删除key演示:
# 设置租约并绑定 zoo1
[root@tiaoban etcd]# etcdctl lease grant 60
lease 6e1e86f4c6512a43 granted with TTL(60s)
[root@tiaoban etcd]# etcdctl --lease=6e1e86f4c6512a43 put zoo1 val1
OK
# 续约
[root@tiaoban etcd]# etcdctl lease keep-alive 6e1e86f4c6512a43
lease 6e1e86f4c6512a43 keepalived with TTL(60)
# 此时在另一个控制台执行删除key操作:
[root@tiaoban ~]# etcdctl del zoo1
1
# 单纯删除 key 后,续约操作持续进行,会造成内存泄露
[root@tiaoban etcd]# etcdctl lease keep-alive 6e1e86f4c6512a43
lease 6e1e86f4c6512a43 keepalived with TTL(60)
lease 6e1e86f4c6512a43 keepalived with TTL(60)
lease 6e1e86f4c6512a43 keepalived with TTL(60)
...撤销key的租约演示:
# 设置租约并绑定 zoo1
[root@tiaoban etcd]# etcdctl lease grant 50
lease 32698142c52a1717 granted with TTL(50s)
[root@tiaoban etcd]# etcdctl --lease=32698142c52a1717 put zoo1 val1
OK
# 续约
[root@tiaoban etcd]# etcdctl lease keep-alive 32698142c52a1717
lease 32698142c52a1717 keepalived with TTL(50)
lease 32698142c52a1717 keepalived with TTL(50)
# 另一个控制台执行:etcdctl lease revoke 32698142c52a1717
# 续约撤销并退出
lease 32698142c52a1717 expired or revoked.
[root@tiaoban etcd]# etcdctl get zoo1
# 返回空备份恢复命令
主要用于管理节点的快照,其主要用法如下所示:
etcdctl snapshot <subcommand> [flags]生成快照
其主要用法如下所示:
etcdctl snapshot save <filename> [flags]示例如下所示:
etcdctl snapshot save etcd-snapshot.db查看快照
首先把etcd数据库中的所有数据都必须删除;rm-rf/var/lib/etcd/*
其主要用法如下所示:
etcdctl snapshot status <filename> [flags]示例如下所示:
etcdctl snapshot status etcd-snapshot.db -w table恢复快照
其主要用法如下所示:
etcdctl snapshot restore <filename> [options] [flags]备份恢复演示
-
新建一个名为name的key
[root@tiaoban ~]# etcdctl put name cuiliang
OK
[root@tiaoban ~]# etcdctl get name
name
cuiliang
[root@tiaoban ~]# etcdctl endpoint status -w table
+---------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+
| ENDPOINT | ID | VERSION | DB SIZE | IS LEADER | IS LEARNER | RAFT TERM | RAFT INDEX | RAFT APPLIED INDEX | ERRORS |
+---------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+
| 192.168.10.100:2379 | 2e0eda3ad6bc6e1e | 3.4.23 | 20 kB | true | false | 4 | 10 | 10 | |
| 192.168.10.11:2379 | bc34c6bd673bdf9f | 3.4.23 | 20 kB | false | false | 4 | 10 | 10 | |
| 192.168.10.12:2379 | 5d2c1bd3b22f796f | 3.4.23 | 20 kB | false | false | 4 | 10 | 10 | |
+---------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+-
生成快照,创建名为snap.db的备份文件
[root@k8s-work1 ~]# etcdctl snapshot save snap.db
{"level":"info","ts":1679220752.5883558,"caller":"snapshot/v3_snapshot.go:119","msg":"created temporary db file","path":"snap.db.part"}
{"level":"info","ts":"2023-03-19T18:12:32.592+0800","caller":"clientv3/maintenance.go:200","msg":"opened snapshot stream; downloading"}
{"level":"info","ts":1679220752.5924425,"caller":"snapshot/v3_snapshot.go:127","msg":"fetching snapshot","endpoint":"127.0.0.1:2379"}
{"level":"info","ts":"2023-03-19T18:12:32.595+0800","caller":"clientv3/maintenance.go:208","msg":"completed snapshot read; closing"}
{"level":"info","ts":1679220752.597161,"caller":"snapshot/v3_snapshot.go:142","msg":"fetched snapshot","endpoint":"127.0.0.1:2379","size":"25 kB","took":0.008507131}
{"level":"info","ts":1679220752.5973082,"caller":"snapshot/v3_snapshot.go:152","msg":"saved","path":"snap.db"}
Snapshot saved at snap.db-
查看备份文件详情
[root@k8s-work1 ~]# ls -lh snap.db
-rw------- 1 root root 25K 3月 19 18:12 snap.db
[root@k8s-work1 ~]# etcdctl snapshot status snap.db -w table
+----------+----------+------------+------------+
| HASH | REVISION | TOTAL KEYS | TOTAL SIZE |
+----------+----------+------------+------------+
| 8f097221 | 39 | 47 | 25 kB |
+----------+----------+------------+------------+-
把快照文件传到其他节点
[root@k8s-work1 ~]# scp snap.db 192.168.10.100:/root 100% 24KB 6.9MB/s 00:00
[root@k8s-work1 ~]# scp snap.db 192.168.10.12:/root-
停止所有节点的etcd服务,并删除数据目录
[root@k8s-work1 ~]# rm -rf /var/lib/etcd/*
[root@k8s-work1 ~]# etcdctl snapshot restore test.db
[root@k8s-work1 ~]# cp -r default.etcd/member/ /var/lib/etcd/
[root@k8s-work1 ~]# docker ps -a | grep etcd
[root@k8s-work1 ~]# docker restart 550
[root@k8s-work1 ~]# etcdctl get s
s
1
# 其余两个节点相同操作恢复案例
所有 Kubernetes 对象都存储在 etcd 上。定期备份 etcd 集群数据对于在灾难场景(例如丢失所有控制平面节点)下恢复 Kubernetes 集群非常重要。 快照文件包含所有 Kubernetes 状态和关键信息。
在一个基线上为etcd做快照能够实现etcd数据的备份。通过定期地为etcd节点后端数据库做快照,etcd就能从一个已知的良好状态的时间点进行恢复。运行在虚拟机的k8s集群,如果偶遇突然断电,就可能会部分文件有问题,导致etcd和apiserver起不来,这样整个集群都无法运行,因此在k8s的集群进行etcd备份十分重要,下面主要演示单master集群和多master集群2个方面。
单master集群
环境准备:kubeadm安装的一主三从
[root@k8s-01 ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
k8s-01 Ready control-plane,master 22h v1.22.3
k8s-02 Ready <none> 22h v1.22.3
k8s-03 Ready <none> 22h v1.22.3
k8s-04 Ready <none> 22h v1.22.3
[root@k8s-01 ~]#-
先备份etcd数据
[root@k8s-01 kubernetes]# ETCDCTL_API=3 etcdctl snapshot save /opt/etcd-back/snap.db --endpoints=https://127.0.0.1:2379 --cacert=/etc/kubernetes/pki/etcd/ca.crt --cert=/etc/kubernetes/pki/etcd/peer.crt --key=/etc/kubernetes/pki/etcd/peer.key-
创建测试pod
[root@k8s-01 ~]# kubectl get pods
NAME READY STATUS RESTARTS AGE
nfs-client-provisioner-69b76b8dc6-6l8xs 1/1 Running 7 (3h55m ago) 4h43m
nginx-6799fc88d8-5rqg8 1/1 Running 0 48s
nginx-6799fc88d8-phvkx 1/1 Running 0 48s
nginx-6799fc88d8-rwjc6 1/1 Running 0 48s
[root@k8s-01 ~]#-
停止etcd和apiserver
control-plane阶段用于为API Server、Controller Manager和Scheduler生成静态Pod配置清单,而etcd阶段则为本地etcd存储生成静态Pod配置清单,它们都会保存于/etc/kubernetes/manifests目录中。当前主机上的kubelet服务会监视该目录中的配置清单的创建、变动和删除等状态变动,并根据变动完成Pod创建、更新或删除操作。因此,这两个阶段创建生成的各配置清单将会启动Master组件的相关Pod
[root@k8s-01 kubernetes]# mv /etc/kubernetes/manifests/ /etc/kubernetes/manifests-backup/
[root@k8s-01 kubernetes]# kubectl get pods -A
The connection to the server 192.168.1.128:6443 was refused - did you specify the right host or port?
[root@k8s-01 kubernetes]#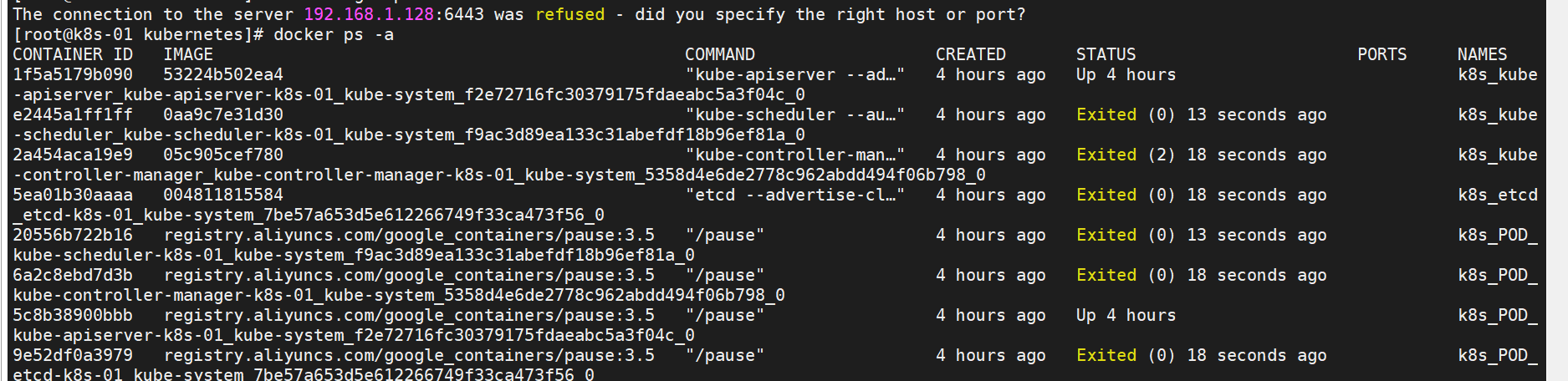
-
变更/var/lib/etcd
[root@k8s-01 kubernetes]# mv /var/lib/etcd /var/lib/etcd.bak
[root@k8s-01 kubernetes]#-
恢复etcd数据
[root@k8s-01 lib]# ETCDCTL_API=3 etcdctl --endpoints="https://127.0.0.1:2379" --cert="/etc/kubernetes/pki/etcd/server.crt" --key="/etc/kubernetes/pki/etcd/server.key" --cacert="/etc/kubernetes/pki/etcd/ca.crt" snapshot restore /opt/etcd-back/snap.db --data-dir=/var/lib/etcd/-
启动etcd和apiserver,查看pods
[root@k8s-01 lib]# cd /etc/kubernetes/
[root@k8s-01 kubernetes]# mv manifests-backup manifests
[root@k8s-01 kubernetes]# kubectl get pods
NAME READY STATUS RESTARTS AGE
nfs-client-provisioner-69b76b8dc6-6l8xs 1/1 Running 12 (2m25s ago) 4h48m
[root@k8s-01 ~]# kubectl get pods -n kube-system
NAME READY STATUS RESTARTS AGE
calico-kube-controllers-65898446b5-t2mqq 1/1 Running 11 (16h ago) 21h
calico-node-8md6b 1/1 Running 0 21h
calico-node-9457b 1/1 Running 0 21h
calico-node-nxs2w 1/1 Running 0 21h
calico-node-p7d52 1/1 Running 0 21h
coredns-7f6cbbb7b8-g84gl 1/1 Running 0 22h
coredns-7f6cbbb7b8-j9q4q 1/1 Running 0 22h
etcd-k8s-01 1/1 Running 0 22h
kube-apiserver-k8s-01 1/1 Running 0 22h
kube-controller-manager-k8s-01 1/1 Running 0 22h
kube-proxy-49b8g 1/1 Running 0 22h
kube-proxy-8wh5l 1/1 Running 0 22h
kube-proxy-b6lqq 1/1 Running 0 22h
kube-proxy-tldpv 1/1 Running 0 22h
kube-scheduler-k8s-01 1/1 Running 0 22h
[root@k8s-01 ~]#由于3个nginx是备份之后启动的,所以恢复后都不存在了。
多master集群
环境准备:kubeadm安装的二主二从
[root@k8s-01 ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
k8s-01 Ready control-plane,master 16h v1.22.3
k8s-02 Ready control-plane,master 16h v1.22.3
k8s-03 Ready <none> 16h v1.22.3
k8s-04 Ready <none> 16h v1.22.3
[root@k8s-01 etcd-v3.5.4-linux-amd64]# ETCDCTL_API=3 etcdctl --endpoints=https://192.168.1.123:2379,https://192.168.1.124:2379 --cacert=/etc/kubernetes/pki/etcd/ca.crt --cert=/etc/kubernetes/pki/etcd/peer.crt --key=/etc/kubernetes/pki/etcd/peer.key member list
58915ab47aed1957, started, k8s-02, https://192.168.1.124:2380, https://192.168.1.124:2379, false
c48307bcc0ac155e, started, k8s-01, https://192.168.1.123:2380, https://192.168.1.123:2379, false
[root@k8s-01 etcd-v3.5.4-linux-amd64]#-
2台master都需要备份:
[root@k8s-01 ~]# ETCDCTL_API=3 etcdctl --endpoints="https://127.0.0.1:2379" --cacert=/etc/kubernetes/pki/etcd/ca.crt --cert=/etc/kubernetes/pki/etcd/peer.crt --key=/etc/kubernetes/pki/etcd/peer.key snapshot save /snap-$(date +%Y%m%d%H%M).db
[root@k8s-02 ~]# ETCDCTL_API=3 etcdctl --endpoints="https://127.0.0.1:2379" --cacert=/etc/kubernetes/pki/etcd/ca.crt --cert=/etc/kubernetes/pki/etcd/peer.crt --key=/etc/kubernetes/pki/etcd/peer.key snapshot save /snap-$(date +%Y%m%d%H%M).db-
创建3个测试pod
[root@k8s-01 ~]# kubectl get pods
NAME READY STATUS RESTARTS AGE
nginx-6799fc88d8-2x6gw 1/1 Running 0 4m22s
nginx-6799fc88d8-82mjz 1/1 Running 0 4m22s
nginx-6799fc88d8-sbb6n 1/1 Running 0 4m22s
tomcat-7d987c7694-552v2 1/1 Running 0 2m8s
[root@k8s-01 ~]#-
停掉Master机器的kube-apiserver和etcd
[root@k8s-01 kubernetes]# mv /etc/kubernetes/manifests/ /etc/kubernetes/manifests-backup/
[root@k8s-02 kubernetes]# mv /etc/kubernetes/manifests/ /etc/kubernetes/manifests-backup/-
变更/var/lib/etcd
[root@k8s-01 kubernetes]# mv /var/lib/etcd /var/lib/etcd.bak
[root@k8s-02 kubernetes]# mv /var/lib/etcd /var/lib/etcd.bak-
恢复etcd数据,etcd集群用同一份snapshot恢复;
[root@k8s-01 /]# ETCDCTL_API=3 etcdctl snapshot restore /snap-202207182330.db --endpoints=192.168.1.123:2379 --name=k8s-01 --cacert=/etc/kubernetes/pki/etcd/ca.crt --cert=/etc/kubernetes/pki/etcd/peer.crt --key=/etc/kubernetes/pki/etcd/peer.key --initial-advertise-peer-urls=https://192.168.1.123:2380 --initial-cluster-token=etcd-cluster-0 --initial-cluster=k8s-01=https://192.168.1.123:2380,k8s-02=https://192.168.1.124:2380 --data-dir=/var/lib/etcd
[root@k8s-01 /]# scp snap-202207182330.db root@192.168.1.124:/
root@192.168.1.124's password:
snap-202207182330.db 100% 4780KB 45.8MB/s 00:00
[root@k8s-02 /]# ETCDCTL_API=3 etcdctl snapshot restore /snap-202207182330.db --endpoints=192.168.1.124:2379 --name=k8s-02 --cacert=/etc/kubernetes/pki/etcd/ca.crt --cert=/etc/kubernetes/pki/etcd/peer.crt --key=/etc/kubernetes/pki/etcd/peer.key --initial-advertise-peer-urls=https://192.168.1.124:2380 --initial-cluster-token=etcd-cluster-0 --initial-cluster=k8s-01=https://192.168.1.123:2380,k8s-02=https://192.168.1.124:2380 --data-dir=/var/lib/etcd6.master节点上启动etcd和apiserver,查看pods
[root@k8s-01 lib]# cd /etc/kubernetes/
[root@k8s-01 kubernetes]# mv manifests-backup manifests
[root@k8s-02 lib]# cd /etc/kubernetes/
[root@k8s-02 kubernetes]# mv manifests-backup manifests
[root@k8s-01 lib]# kubectl get pods
###发现无法看到后创建的pod信息
[root@k8s-01 ~]# kubectl get pods -n kube-system
NAME READY STATUS RESTARTS AGE
calico-kube-controllers-65898446b5-drjjj 1/1 Running 10 (16h ago) 16h
calico-node-9s7p2 1/1 Running 0 16h
calico-node-fnbj4 1/1 Running 0 16h
calico-node-nx6q6 1/1 Running 0 16h
calico-node-qcffj 1/1 Running 0 16h
coredns-7f6cbbb7b8-mn9hj 1/1 Running 0 16h
coredns-7f6cbbb7b8-nrwbf 1/1 Running 0 16h
etcd-k8s-01 1/1 Running 1 16h
etcd-k8s-02 1/1 Running 0 16h
kube-apiserver-k8s-01 1/1 Running 2 (16h ago) 16h
kube-apiserver-k8s-02 1/1 Running 0 16h
kube-controller-manager-k8s-01 1/1 Running 2 16h
kube-controller-manager-k8s-02 1/1 Running 0 16h
kube-proxy-d824j 1/1 Running 0 16h
kube-proxy-k5gw4 1/1 Running 0 16h
kube-proxy-mxmhp 1/1 Running 0 16h
kube-proxy-nvpf4 1/1 Running 0 16h
kube-scheduler-k8s-01 1/1 Running 1 16h
kube-scheduler-k8s-02 1/1 Running 0 16h
[root@k8s-01 ~]#Kubernetes集群升级指南
前言
本文演示kubernetes集群从v1.24.1升级到v1.29.15。
一、集群升级过程辅助命令
(1)查看节点上运行的pod。
kubectl get pod -o wide |grep <nodename>(2)查看集群配置文件。
kubectl -n kube-system get cm kubeadm-config -o yaml(3)查看当前集群节点。
kubectl get node二、升级master节点
2.1、升级kubeadm。
# 更新包管理器
yum update
# 查看可用版本
apt-cache madison kubeadm
yum list | grep kubeadm
# 更新
yum update -y kubeadm
# 验证版本
kubeadm version2.2、验证升级计划
(1)检查可升级到哪些版本,并验证你当前的集群是否可升级。
kubeadm upgrade plan
[upgrade/config] Making sure the configuration is correct:
[upgrade/config] Reading configuration from the cluster...
[upgrade/config] FYI: You can look at this config file with 'kubectl -n kube-system get cm kubeadm-config -o yaml'
[preflight] Running pre-flight checks.
[upgrade] Running cluster health checks
[upgrade] Fetching available versions to upgrade to
[upgrade/versions] Cluster version: v1.28.15
[upgrade/versions] kubeadm version: v1.29.15
I0327 11:28:43.151508 1125701 version.go:256] remote version is much newer: v1.32.3; falling back to: stable-1.29
[upgrade/versions] Target version: v1.29.15
[upgrade/versions] Latest version in the v1.28 series: v1.28.15
Components that must be upgraded manually after you have upgraded the control plane with 'kubeadm upgrade apply':
COMPONENT CURRENT TARGET
kubelet 3 x v1.28.15 v1.29.15
Upgrade to the latest stable version:
COMPONENT CURRENT TARGET
kube-apiserver v1.28.15 v1.29.15
kube-controller-manager v1.28.15 v1.29.15
kube-scheduler v1.28.15 v1.29.15
kube-proxy v1.28.15 v1.29.15
CoreDNS v1.10.1 v1.11.1
etcd 3.5.15-0 3.5.16-0
You can now apply the upgrade by executing the following command:
kubeadm upgrade apply v1.29.15
_____________________________________________________________________
The table below shows the current state of component configs as understood by this version of kubeadm.
Configs that have a "yes" mark in the "MANUAL UPGRADE REQUIRED" column require manual config upgrade or
resetting to kubeadm defaults before a successful upgrade can be performed. The version to manually
upgrade to is denoted in the "PREFERRED VERSION" column.
API GROUP CURRENT VERSION PREFERRED VERSION MANUAL UPGRADE REQUIRED
kubeproxy.config.k8s.io v1alpha1 v1alpha1 no
kubelet.config.k8s.io v1beta1 v1beta1 no
_____________________________________________________________________注意下面的MANUAL字段:
The table below shows the current state of component configs as understood by this version of kubeadm.
Configs that have a "yes" mark in the "MANUAL UPGRADE REQUIRED" column require manual config upgrade or
resetting to kubeadm defaults before a successful upgrade can be performed. The version to manually
upgrade to is denoted in the "PREFERRED VERSION" column.
API GROUP CURRENT VERSION PREFERRED VERSION MANUAL UPGRADE REQUIRED
kubeproxy.config.k8s.io v1alpha1 v1alpha1 no
kubelet.config.k8s.io v1beta1 v1beta1 no
_____________________________________________________________________指示哪些主键需要手动升级,如果是yes就要手动升级。
(2)显示哪些差异将被应用于现有的静态 pod 资源清单。
kubeadm upgrade diff 1.29.15
[upgrade/diff] Reading configuration from the cluster...
[upgrade/diff] FYI: You can look at this config file with 'kubectl -n kube-system get cm kubeadm-config -o yaml'
--- /etc/kubernetes/manifests/kube-apiserver.yaml
+++ new manifest
@@ -40,7 +40,7 @@- --service-cluster-ip-range=10.96.0.0/12- --tls-cert-file=/etc/kubernetes/pki/apiserver.crt- --tls-private-key-file=/etc/kubernetes/pki/apiserver.key
- image: registry.aliyuncs.com/google_containers/kube-apiserver:v1.28.15
+ image: registry.aliyuncs.com/google_containers/kube-apiserver:1.29.15imagePullPolicy: IfNotPresentlivenessProbe:failureThreshold: 8
--- /etc/kubernetes/manifests/kube-controller-manager.yaml
+++ new manifest
@@ -28,7 +28,7 @@- --service-account-private-key-file=/etc/kubernetes/pki/sa.key- --service-cluster-ip-range=10.96.0.0/12- --use-service-account-credentials=true
- image: registry.aliyuncs.com/google_containers/kube-controller-manager:v1.28.15
+ image: registry.aliyuncs.com/google_containers/kube-controller-manager:1.29.15imagePullPolicy: IfNotPresentlivenessProbe:failureThreshold: 8
--- /etc/kubernetes/manifests/kube-scheduler.yaml
+++ new manifest
@@ -16,7 +16,7 @@- --bind-address=127.0.0.1- --kubeconfig=/etc/kubernetes/scheduler.conf- --leader-elect=true
- image: registry.aliyuncs.com/google_containers/kube-scheduler:v1.28.15
+ image: registry.aliyuncs.com/google_containers/kube-scheduler:1.29.15imagePullPolicy: IfNotPresentlivenessProbe:failureThreshold: 82.3、master节点升级
(1)升级到 1.29.15版本,此命令仅升级master节点(control plane)。
kubeadm upgrade apply v1.29.15
[upgrade/config] Making sure the configuration is correct:
[upgrade/config] Reading configuration from the cluster...
[upgrade/config] FYI: You can look at this config file with 'kubectl -n kube-system get cm kubeadm-config -o yaml'
[preflight] Running pre-flight checks.
[upgrade] Running cluster health checks
[upgrade/version] You have chosen to change the cluster version to "v1.29.15"
[upgrade/versions] Cluster version: v1.28.15
[upgrade/versions] kubeadm version: v1.29.15
[upgrade] Are you sure you want to proceed? [y/N]: y
[upgrade/prepull] Pulling images required for setting up a Kubernetes cluster
[upgrade/prepull] This might take a minute or two, depending on the speed of your internet connection
[upgrade/prepull] You can also perform this action in beforehand using 'kubeadm config images pull'
[upgrade/apply] Upgrading your Static Pod-hosted control plane to version "v1.29.15" (timeout: 5m0s)...
[upgrade/etcd] Upgrading to TLS for etcd
[upgrade/staticpods] Preparing for "etcd" upgrade
[upgrade/staticpods] Renewing etcd-server certificate
[upgrade/staticpods] Renewing etcd-peer certificate
[upgrade/staticpods] Renewing etcd-healthcheck-client certificate
[upgrade/staticpods] Moved new manifest to "/etc/kubernetes/manifests/etcd.yaml" and backed up old manifest to "/etc/kubernetes/tmp/kubeadm-backup-manifests-2025-03-27-11-32-38/etcd.yaml"
[upgrade/staticpods] Waiting for the kubelet to restart the component
[upgrade/staticpods] This might take a minute or longer depending on the component/version gap (timeout 5m0s)
[apiclient] Found 1 Pods for label selector component=etcd
[upgrade/staticpods] Component "etcd" upgraded successfully!
[upgrade/etcd] Waiting for etcd to become available
[upgrade/staticpods] Writing new Static Pod manifests to "/etc/kubernetes/tmp/kubeadm-upgraded-manifests2230279311"
[upgrade/staticpods] Preparing for "kube-apiserver" upgrade
[upgrade/staticpods] Renewing apiserver certificate
[upgrade/staticpods] Renewing apiserver-kubelet-client certificate
[upgrade/staticpods] Renewing front-proxy-client certificate
[upgrade/staticpods] Renewing apiserver-etcd-client certificate
[upgrade/staticpods] Moved new manifest to "/etc/kubernetes/manifests/kube-apiserver.yaml" and backed up old manifest to "/etc/kubernetes/tmp/kubeadm-backup-manifests-2025-03-27-11-32-38/kube-apiserver.yaml"
[upgrade/staticpods] Waiting for the kubelet to restart the component
[upgrade/staticpods] This might take a minute or longer depending on the component/version gap (timeout 5m0s)
[apiclient] Found 1 Pods for label selector component=kube-apiserver
[upgrade/staticpods] Component "kube-apiserver" upgraded successfully!
[upgrade/staticpods] Preparing for "kube-controller-manager" upgrade
[upgrade/staticpods] Renewing controller-manager.conf certificate
[upgrade/staticpods] Moved new manifest to "/etc/kubernetes/manifests/kube-controller-manager.yaml" and backed up old manifest to "/etc/kubernetes/tmp/kubeadm-backup-manifests-2025-03-27-11-32-38/kube-controller-manager.yaml"
[upgrade/staticpods] Waiting for the kubelet to restart the component
[upgrade/staticpods] This might take a minute or longer depending on the component/version gap (timeout 5m0s)
[apiclient] Found 1 Pods for label selector component=kube-controller-manager
[upgrade/staticpods] Component "kube-controller-manager" upgraded successfully!
[upgrade/staticpods] Preparing for "kube-scheduler" upgrade
[upgrade/staticpods] Renewing scheduler.conf certificate
[upgrade/staticpods] Moved new manifest to "/etc/kubernetes/manifests/kube-scheduler.yaml" and backed up old manifest to "/etc/kubernetes/tmp/kubeadm-backup-manifests-2025-03-27-11-32-38/kube-scheduler.yaml"
[upgrade/staticpods] Waiting for the kubelet to restart the component
[upgrade/staticpods] This might take a minute or longer depending on the component/version gap (timeout 5m0s)
[apiclient] Found 1 Pods for label selector component=kube-scheduler
[upgrade/staticpods] Component "kube-scheduler" upgraded successfully!
[upload-config] Storing the configuration used in ConfigMap "kubeadm-config" in the "kube-system" Namespace
[kubelet] Creating a ConfigMap "kubelet-config" in namespace kube-system with the configuration for the kubelets in the cluster
[upgrade] Backing up kubelet config file to /etc/kubernetes/tmp/kubeadm-kubelet-config3777955110/config.yaml
[kubelet-start] Writing kubelet configuration to file "/var/lib/kubelet/config.yaml"
[kubeconfig] Writing "admin.conf" kubeconfig file
[kubeconfig] Writing "super-admin.conf" kubeconfig file
[bootstrap-token] Configured RBAC rules to allow Node Bootstrap tokens to get nodes
[bootstrap-token] Configured RBAC rules to allow Node Bootstrap tokens to post CSRs in order for nodes to get long term certificate credentials
[bootstrap-token] Configured RBAC rules to allow the csrapprover controller automatically approve CSRs from a Node Bootstrap Token
[bootstrap-token] Configured RBAC rules to allow certificate rotation for all node client certificates in the cluster
[addons] Applied essential addon: CoreDNS
[addons] Applied essential addon: kube-proxy
[upgrade/successful] SUCCESS! Your cluster was upgraded to "v1.29.15". Enjoy!
[upgrade/kubelet] Now that your control plane is upgraded, please proceed with upgrading your kubelets if you haven't already done so.(2) 腾空节点,即将节点上除守护进程之外的其他进程调度到其他节点,同时将开启调度保护。
kubectl drain <nodename> --ignore-daemonsets
$ kubectl drain k8s-master1 --ignore-daemonsets
node/k8s-master1 cordoned
WARNING: ignoring DaemonSet-managed Pods: kube-flannel/kube-flannel-ds-nxz4d, kube-system/kube-proxy-pbnk4
evicting pod kube-system/coredns-c676cc86f-twm96
evicting pod kube-system/coredns-c676cc86f-mdgbn
pod/coredns-c676cc86f-mdgbn evicted
pod/coredns-c676cc86f-twm96 evicted
node/k8s-master1 drained
$ kubectl get pod -A
NAMESPACE NAME READY STATUS RESTARTS AGE
kube-flannel kube-flannel-ds-nxz4d 1/1 Running 0 136m
kube-system coredns-c676cc86f-7stvs 0/1 Pending 0 60s
kube-system coredns-c676cc86f-vmkgv 0/1 Pending 0 60s
kube-system etcd-k8s-master1 1/1 Running 0 11m
kube-system kube-apiserver-k8s-master1 1/1 Running 0 10m
kube-system kube-controller-manager-k8s-master1 1/1 Running 0 10m
kube-system kube-proxy-pbnk4 1/1 Running 0 9m44s
kube-system kube-scheduler-k8s-master1 1/1 Running 0 9m58s
$ kubectl get node
NAME STATUS ROLES AGE VERSION
k8s-master1 Ready,SchedulingDisabled control-plane 162m v1.24.1(3)升级kubelet与kubectl组件。
yum update -y kubelet(4)重启 kubelet。
systemctl daemon-reload
systemctl restart kubelet(5)解除调度保护。
kubectl uncordon <nodename>三、升级node节点
(1)升级节点kubelet 配置。
kubeadm upgrade node(2)腾空节点,同时开启调度保护,此命令请在master节点操作
kubectl drain <nodename> --ignore-daemonsets(3)升级kubelet与kubectl组件。
yum update -y kubelet(4)重启 kubelet。
systemctl daemon-reload
systemctl restart kubelet(5)解除调度保护,master节点上执行该命令。
kubectl uncordon <nodename>总结
每个版本的升级都不一样,所以要根据版本进行适当调整,不作为万能指导。 升级过程:
-
升级master组件。
-
升级worker节点组件,调度保护、排空节点、worker节点组件升级、解除保护。
Kubernetes集群的升级可以分为以下几个步骤:
-
备份数据。在升级之前,需要备份Kubernetes集群的数据,包括访问控制、配置文件、数据卷等。
-
选择升级方式。Kubernetes集群的升级方式可以分为两种:滚动升级和强制替换。滚动升级是指逐个升级每个节点,直到所有节点都升级完成。强制替换是指一次性替换所有节点,将旧节点直接替换为新节点。
-
准备新版本。Kubernetes升级需要准备新版本的二进制文件和镜像文件。可以从Kubernetes官方网站下载最新版本的二进制文件和镜像文件,并上传到集群中的节点上。
-
升级Master节点。首先需要升级Master节点,使用新版本的二进制文件替换旧版本的二进制文件,并启动新版本的Kubernetes API Server、ControllerKubernetes是一个快速发展的开源项目,为了保持其功能和安全性,集群的升级是必须的。
-
查看升级文档:首先需要查看官方的升级文档,了解升级过程中需要注意的事项。
-
备份数据:在升级前需要备份当前的数据,以防升级过程中的意外情况导致数据丢失。
-
准备好备份:在升级前需要确保备份的可用性,以便在需要时能够 Manager和Scheduler。
-
-
升级Node节点。接下来需要升级Node节点。首先需要将节点上的Kubelet和kube-proxy服务停止,使用新版本的二进制文件替换旧版本的二进制文件,然后启动新版本的Kubelet和kube-proxy服务。
-
验证升级结果。升级完成后,需要验证恢复数据。
-
升级前的测试:可以在测试环境中进行升级测试,以确保升级过程和升级后的集群正常运行。
-
升级Node:首先需要升级每个Node节点中的Kubernetes组件,包括kubelet和kube-proxy等。
-
升级Control Plane:然后需要升级Control Plane中的Kubernetes组件,包括kube-apiserver、kube-controller-manager和kube-scheduler等。
-
升级Kubernetes对象:升级完Control Plane后,需要升级Kubernetes对象,如Deployment集群是否正常运行。可以使用kubectl命令查看集群的状态和资源对象的状态,确保所有的服务都能够正常访问。
-
-
回滚升级。如果升级失败或出现问题,可以回滚到之前的版本。回滚的过程与升级的过程相同,只需要使用旧版本的二进制文件和镜像文件即可。
Kubernetes集群的升级需要仔细规划和准备,并按照一定的步骤进行操作。只有在备份数据、选择适当的升级方式、准备新版本、升级Master节点、升级Node节点、验证升级结果等步骤都完成后,才能确保集群的升级成功。、StatefulSet等。
升级后的检查:
-
验证集群状态:升级后需要验证集群的状态,包括Node节点的状态、Pod的状态、Service的状态等。
-
验证应用程序:升级后需要验证应用程序的运行状态,确保应用程序正常运行。
-
观察日志:如果发现问题,可以通过查看日志来排查问题原因。
Kubernetes集群升级是一个需要谨慎处理的过程,需要充分准备和测试,以确保升级过程的顺利和集群的稳定。在升级过程中,需要注意备份数据和备份的可用性,升级顺序和升级后的检查等问题,以确保集群的正常运行和应用程序的稳定性。