【Doris入门】Doris数据表模型:明细模型(Duplicate Key Model)详解
目录
引言
1 明细模型概述
1.1 什么是明细模型
1.2 技术原理
2 建表实战与语法详解
2.1 显式创建明细模型表
2.2 默认创建明细模型表
3 数据操作详解
3.1 数据写入
3.2 数据删除
4 数据写入流程架构
4.1 写入流程图
4.2 存储架构图
5 性能优化建议
5.1 排序列选择优化
5.2 分桶策略优化
5.3 查询性能优化
6 总结
引言
Apache Doris 作为现代化的实时分析数据库,其数据模型设计直接决定了数据的组织方式和查询性能。本文将深入剖析 Doris 的明细模型(Duplicate Key Model),从技术原理、建表示例、数据操作到性能优化,全方位解读这一最常用也最基础的数据模型。
1 明细模型概述
1.1 什么是明细模型
明细模型(Duplicate Key Model)是 Apache Doris 中的默认数据模型,主要用于保存每一条原始数据记录。在该模型下,即使两行数据完全相同,也会全部保留,不会做任何去重或聚合处理。这种模型特别适合需要保留所有原始明细、仅追加写入(append-only)的分析场景,如日志分析、用户行为埋点、事件追踪等。
1.2 技术原理
在明细模型中,建表时指定的 DUPLICATE KEY 仅用于指明数据存储的排序列,并不代表唯一性约束。存储层会按照这些 Key 列对数据进行排序,以优化常用查询的性能。通常建议选择前 2-4 列作为 Duplicate Key,兼顾查询效率和存储结构。
核心特点:
- 允许 Key 列重复,保留所有写入数据
- 仅支持追加写入,不支持 UPDATE 或 UPSERT
- 支持按条件删除(DELETE),但高频删除会影响查询性能
- 默认模型,若不指定模型类型,自动创建为明细模型
2 建表实战与语法详解
2.1 显式创建明细模型表
- 在 ods_db 数据库中,我们以用户行为日志表为例,展示如何显式创建明细模型表:
CREATE TABLE IF NOT EXISTS ods_db.user_behavior_log(`event_time` DATETIME NOT NULL COMMENT "事件时间",`user_id` BIGINT NOT NULL COMMENT "用户ID",`event_type` VARCHAR(32) NOT NULL COMMENT "事件类型",`page_id` VARCHAR(64) COMMENT "页面ID",`device_type` VARCHAR(16) COMMENT "设备类型",`network` VARCHAR(16) COMMENT "网络环境",`stay_duration` INT COMMENT "停留时长(秒)"
) DUPLICATE KEY(`event_time`, `user_id`, `event_type`)
DISTRIBUTED BY HASH(`user_id`) BUCKETS 1
PROPERTIES ("replication_allocation" = "tag.location.default: 1"
);语法解析:
- DUPLICATE KEY(event_time, user_id, event_type):指定排序列,数据将按这三列排序存储
- DISTRIBUTED BY HASH(user_id):按用户ID哈希分桶,保证数据均匀分布
- BUCKETS 1:设置分桶数量,根据数据量调整
- PROPERTIES:设置副本数等属性
2.2 默认创建明细模型表
- 如果不指定模型类型,Doris 会自动创建明细模型表,并默认选择前3列作为排序列:
CREATE TABLE IF NOT EXISTS ods_db.app_start_log(`log_time` DATETIME NOT NULL COMMENT "日志时间",`device_id` VARCHAR(64) NOT NULL COMMENT "设备ID",`app_version` VARCHAR(16) NOT NULL COMMENT "应用版本",`os_type` VARCHAR(16) COMMENT "操作系统",`channel` VARCHAR(32) COMMENT "下载渠道",`ip` VARCHAR(32) COMMENT "IP地址"
) DISTRIBUTED BY HASH(`device_id`) BUCKETS 1
PROPERTIES ("replication_allocation" = "tag.location.default: 1"
);- 表结构查询:
mysql> desc ods_db.user_behavior_log;
+---------------+-------------+------+-------+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+---------------+-------------+------+-------+---------+-------+
| event_time | datetime | No | true | NULL | |
| user_id | bigint | No | true | NULL | |
| event_type | varchar(32) | No | true | NULL | |
| page_id | varchar(64) | Yes | false | NULL | NONE |
| device_type | varchar(16) | Yes | false | NULL | NONE |
| network | varchar(16) | Yes | false | NULL | NONE |
| stay_duration | int | Yes | false | NULL | NONE |
+---------------+-------------+------+-------+---------+-------+
7 rows in set (0.01 sec)mysql>
# 输出结果中,前三列 log_time、device_id、app_version 会自动标记为 Key 列(排序键)3 数据操作详解
3.1 数据写入
明细模型支持所有标准的数据导入方式,包括 INSERT、Stream Load、Broker Load、Routine Load 等。由于是追加写入模型,所有导入操作都是纯插入,不会更新已有数据。
- INSERT 示例:
INSERT INTO ods_db.user_behavior_log(event_time, user_id, event_type, page_id, device_type, network, stay_duration
) VALUES ('2025-01-01 10:00:00', 10001, 'page_view', '/home', 'mobile', '4G', 15
);- Stream Load 示例(批量导入):
curl --location-trusted -u user:password \-H "label:behavior_log_20250101" \-H "column_separator:," \-T behavior_log.csv \http://fe_host:8030/api/ods_db/user_behavior_log/_stream_load3.2 数据删除
明细模型支持标准的 DELETE 语句进行条件删除。其实现原理是记录删除谓词(Delete Predicate),在查询时作为运行时过滤器过滤掉被删除的数据。
- DELETE 示例:
-- 删除指定时间之前的数据
DELETE FROM ods_db.user_behavior_log
WHERE event_time < '2025-01-01 00:00:00';-- 删除特定用户的数据
DELETE FROM ods_db.user_behavior_log
WHERE user_id = 10001;性能警告:DELETE 操作本身非常快,几乎与删除的数据量无关。但频繁的 DELETE 操作会累积大量的运行时过滤器,严重影响后续查询性能。建议:
- 避免高频删除操作
- 尽量使用时间分区,通过 DROP PARTITION 清理旧数据
- 必要时重建表来彻底清理删除标记
4 数据写入流程架构
4.1 写入流程图

- 客户端写入请求:用户通过 MySQL 协议或 HTTP API 发送写入请求
- FE接收SQL:Frontend 节点接收并解析 SQL 语句
- 查询计划生成:FE 生成执行计划,确定数据分布和目标 BE 节点
- BE数据写入:Backend 节点接收数据并开始写入流程
- 数据按Duplicate Key排序:数据按照建表时指定的 DUPLICATE KEY 列进行排序
- 写入内存表:数据先写入内存中的 MemTable
- 生成数据版本:为这批数据生成版本号,用于后续读取和合并
- 数据副本同步:数据同步到其他副本节点,保证高可用
- 写入成功响应:返回成功结果给客户端
4.2 存储架构图
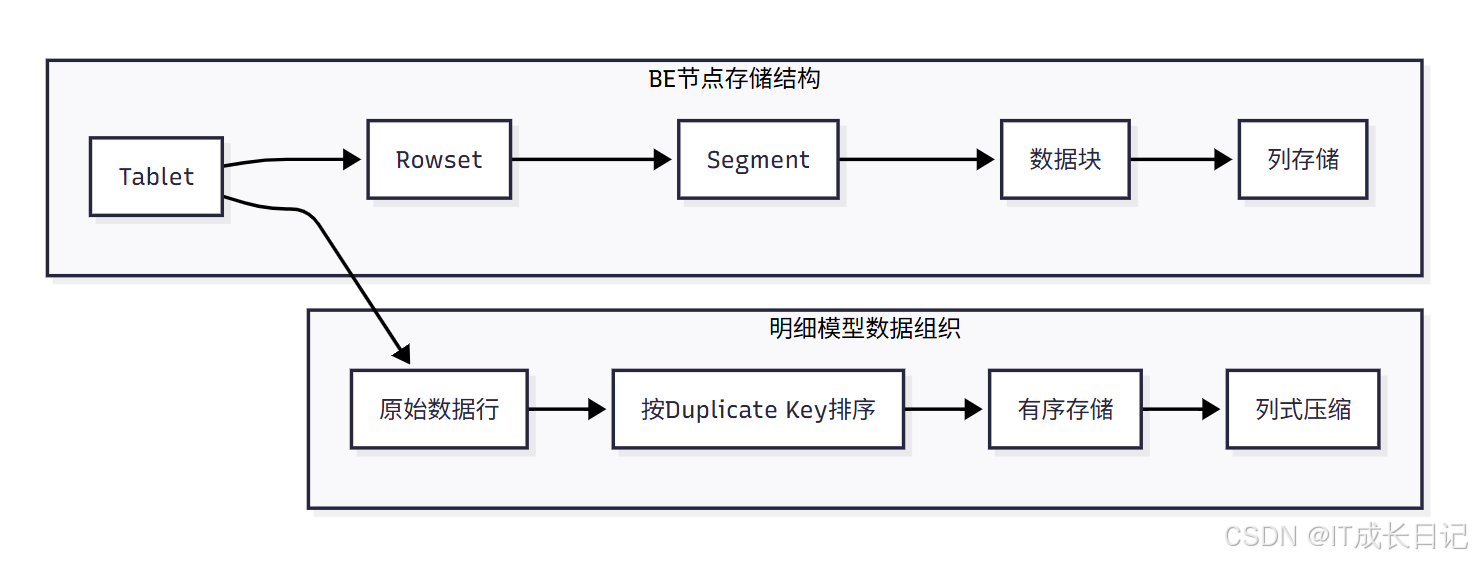
- Tablet:Doris 中数据分片的基本单元,每个表分桶对应一个 Tablet
- Rowset:每次导入生成的一个数据版本,包含多个 Segment
- Segment:数据文件的基本单位,按列存储
- 数据块:列存储中的数据块,支持高效压缩
- 按Duplicate Key排序:数据按照指定的 Key 列排序,提高查询效率
- 列式压缩:相同类型数据列式存储,压缩比高,查询性能好
5 性能优化建议
5.1 排序列选择优化
原则:
- 选择查询最频繁的 2-4 列作为 DUPLICATE KEY
- 优先选择高基数列(如 user_id、device_id)
- 避免选择低基数或经常变动的列
- 优化示例:
-- 不推荐:低基数列作为排序列
DUPLICATE KEY(event_type, device_type)-- 推荐:高基数且查询频繁的列
DUPLICATE KEY(event_time, user_id, event_type)5.2 分桶策略优化
原则:
- 分桶列应选择数据分布均匀的列
- 分桶数建议为磁盘数量的倍数
- 单个 Tablet 大小控制在 1-10GB
- 优化示例:
-- 不推荐:数据倾斜严重
DISTRIBUTED BY HASH(event_type) BUCKETS 10-- 推荐:数据分布均匀
DISTRIBUTED BY HASH(user_id) BUCKETS 325.3 查询性能优化
建议:
- 利用排序列加速查询:查询条件尽量包含 DUPLICATE KEY 的前缀列
- 避免全表扫描:合理使用分区和分桶,减少扫描数据量
- 列裁剪:只查询需要的列,减少 I/O 开销
- 避免高频删除:如需清理数据,优先使用分区管理
- 优化查询示例:
-- 不推荐:全表扫描
SELECT COUNT(*) FROM ods_db.user_behavior_log;-- 推荐:利用排序列和分区
SELECT COUNT(*)
FROM ods_db.user_behavior_log
WHERE event_time >= '2025-01-01' AND user_id = 10001;6 总结
Apache Doris 的明细模型(Duplicate Key Model)作为最基础也是最常用的数据模型,具有以下核心特性:
- 数据保留完整:保留所有原始数据,不做任何去重或聚合
- 写入性能优异:纯追加写入,写入性能高,适合高并发导入
- 查询灵活:支持任意维度的 Ad-hoc 查询,不受预聚合限制
- 存储高效:列式存储 + 高压缩比,存储成本低
- 操作限制:不支持 UPDATE,高频 DELETE 会影响查询性能
明细模型最适合以下业务场景:
- 日志分析:应用日志、系统日志、安全日志等
- 用户行为追踪:点击流、页面浏览、事件埋点等
- 时序数据:监控指标、IoT 传感器数据等
- 原始数据存储:需要保留所有明细的数据仓库 ODS 层