目标检测算法YOLOv4详解
前言
由于项目组的安排需要在小目标方向做研究,yolo属于是这里面的经典之作,2025 年的今天仍有大量工作基于 YOLOv5 进行改进与创新,而YOLOv4 作为 YOLO 系列发展承上启下的关键里程碑,集成了当时最优秀的 Bag of Freebies (BoF) 和 Bag of Specials (BoS) 策略,其在网络架构、数据增强、训练策略等方面的系统性优化,为后续所有版本的设计奠定了坚实框架。
yolov4主要的改进
Bag-of-Specials (BoS)
对于主干Backbone,作者尝试了多种用于骨干网络的架构,如ResNeXt50、EfficientNet-B3和Darknet-53。表现最好的架构是对Darknet-53进行修改,加入了跨阶段部分连接(CSPNet)和Mish激活函数作为骨干网络,有助于减少模型的计算量,同时保持相同的准确率。
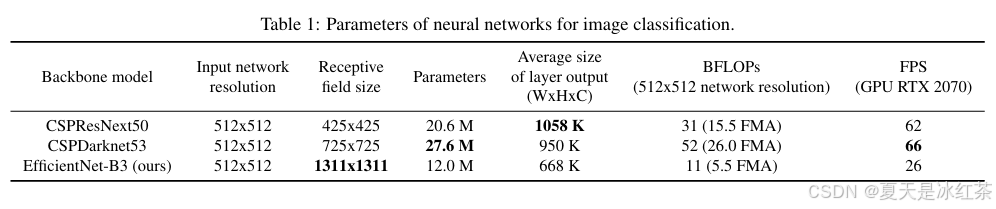
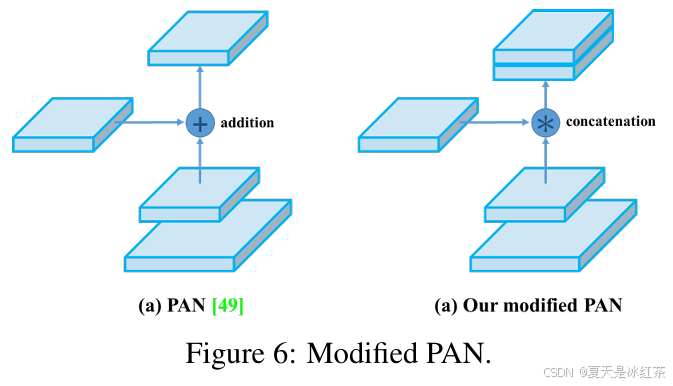
对于颈部Neck,使用了YOLOv3-spp中修改过的空间金字塔池化(SPP)增加了感受野而不影响推理速度,以及与YOLOv3相同的多尺度预测,但用PANet代替了FPN,将特征进行拼接,而不是像原始PANet论文中那样相加。,加强了对底层位置、细节特征的传播,并且使用了修改过的空间注意力模块(SAM)。
最后,Head头部分输出层的锚框机制和Yolov3相同,该模型被称为CSPDarknet53-PANet-SPP。
Bag of Freebies (BoF)
除了随机亮度、对比度、缩放、裁剪、翻转和旋转等常规增强外,作者还采用了马赛克增强Mosaic,将4张图片拼接训练,丰富了背景,从而能够检测超出其常规上下文的对象,并且减少了批量归一化所需的大型小批量大小。

为了正则化,使用了DropBlock作为Dropout的替代品,以及类别标签平滑Label Smoothing,解决过拟合的问题。对于检测器,添加了CIoU损失和跨小批量归一化(CmBN),从整个批次而不是像常规批量归一化那样从小批量中收集统计信息。
自对抗训练(SAT)
为了使模型对扰动更具鲁棒性,对输入图像进行对抗攻击,创建一种欺骗,使地面真实物体看起来不在图像中,但保留原始标签以检测正确的物体。
使用遗传算法进行超参数优化
为了找到用于训练的最佳超参数,他们在前10%的周期中使用遗传算法,并使用余弦退火调度器在训练过程中调整学习率。它首先缓慢降低学习率,然后在训练过程的一半时快速降低,最后稍微降低。
yolov4网络结构
整个网络结构如下图所示:
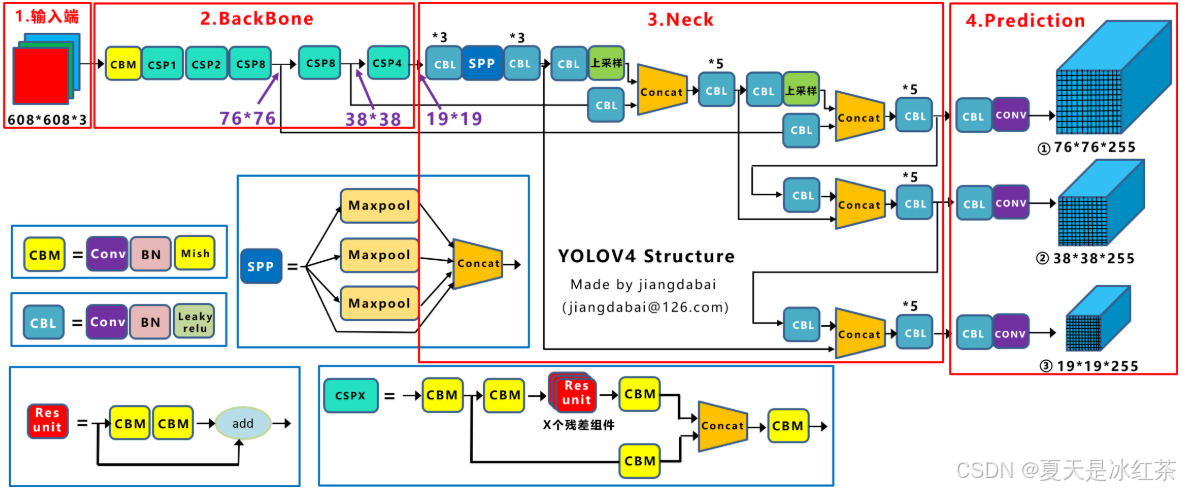
CBM是Yolov4网络结构中的最小组件,由Conv+Bn+Mish激活函数三者组成,CBL由Conv + Bn + Leaky_relu激活函数三者组成。Res unit借鉴Resnet网络中的残差结构,让网络可以构建的更深。CSPX借鉴CSPNet网络结构,由三个卷积层和X个Res unint模块Concate组成。SPP采用1×1,5×5,9×9,13×13的最大池化的方式,进行多尺度融合。
输入端
Mosaic数据增强
这里我仅仅是对图像做了处理,官方实现的都是集成好的,这里我们仅仅是做一下了解,并尝试自己实现。
import cv2
import numpy as np
import randomdef random_resize(img, scale_range=(0.5, 1.5)):"""随机缩放图像"""h, w = img.shape[:2]scale = random.uniform(*scale_range)new_w, new_h = int(w * scale), int(h * scale)return cv2.resize(img, (new_w, new_h))def mosaic(image_paths, out_size=(640, 640)):assert len(image_paths) == 4, "Mosaic需要4张图像"h, w = out_sizexc, yc = [int(random.uniform(0.3, 0.7) * s) for s in (w, h)] # 中心点随机result = np.full((h, w, 3), 114, dtype=np.uint8)for i, path in enumerate(image_paths):img = cv2.imread(path)img = random_resize(img)ih, iw = img.shape[:2]if i == 0: # top-leftx1a, y1a, x2a, y2a = 0, 0, xc, ycx1b, y1b, x2b, y2b = max(iw - xc, 0), max(ih - yc, 0), iw, ihelif i == 1: # top-rightx1a, y1a, x2a, y2a = xc, 0, w, ycx1b, y1b, x2b, y2b = 0, max(ih - yc, 0), min(w - xc, iw), ihelif i == 2: # bottom-leftx1a, y1a, x2a, y2a = 0, yc, xc, hx1b, y1b, x2b, y2b = max(iw - xc, 0), 0, iw, min(h - yc, ih)else: # bottom-rightx1a, y1a, x2a, y2a = xc, yc, w, hx1b, y1b, x2b, y2b = 0, 0, min(w - xc, iw), min(h - yc, ih)crop = img[y1b:y2b, x1b:x2b]target_h = y2a - y1atarget_w = x2a - x1a# 如果裁剪区域大小和目标区域不同,调整if crop.shape[0] != target_h or crop.shape[1] != target_w:crop = cv2.resize(crop, (target_w, target_h))# 贴到大图上result[y1a:y2a, x1a:x2a] = cropreturn resultif __name__=="__main__":image_paths = [r"E:\PythonProject\YoloProject\data\coco8\images\train\000000000009.jpg",r"E:\PythonProject\YoloProject\data\coco8\images\train\000000000025.jpg",r"E:\PythonProject\YoloProject\data\coco8\images\train\000000000030.jpg",r"E:\PythonProject\YoloProject\data\coco8\images\train\000000000034.jpg"]mosaic_img = mosaic(image_paths, out_size=(640, 640))cv2.imwrite("1.png", mosaic_img)cv2.imshow("mosaic augment image", mosaic_img)cv2.waitKey(0)
以coco8数据集为例:

-
提升小目标检测效果:通过拼接缩放,使小目标更容易被网络学习。
-
增加样本多样性:一张图像中包含多个不同场景和目标,提升数据分布的丰富性。
-
隐式扩大 batch size:单张图像中就能学习到多个样本的信息,提高训练稳定性。
-
增强模型鲁棒性:随机拼接带来更多位置、尺度、背景变化,提高泛化能力。
SAT的基本原理
在目标检测和图像识别的训练中,我们常常会使用数据增强方法(如随机裁剪、旋转、翻转、颜色扰动等)来提升模型的鲁棒性。但这些方法大多是外部增强,也就是说它们不依赖模型自身,而是人为地对输入图像进行变化。自对抗训练(SAT, Self-Adversarial Training) 则是一种基于模型自身的增强方法,由 YOLOv4 中被提出,效果非常独特。
SAT 包含两个阶段:
扰动阶段:在前向传播前,模型会用当前参数对输入图像做一次前向推理,计算得到的梯度信息。这些梯度信息会被用来反向修改输入图像本身,让它看起来更“欺骗”模型。效果是图像在短时间内被“攻击”,产生难以识别的特征。
训练阶段:模型再用修改过的图像作为输入,进行正常的前向传播和反向传播。这样,模型会学会 抵抗这种自我制造的“攻击”图像,从而提升鲁棒性。
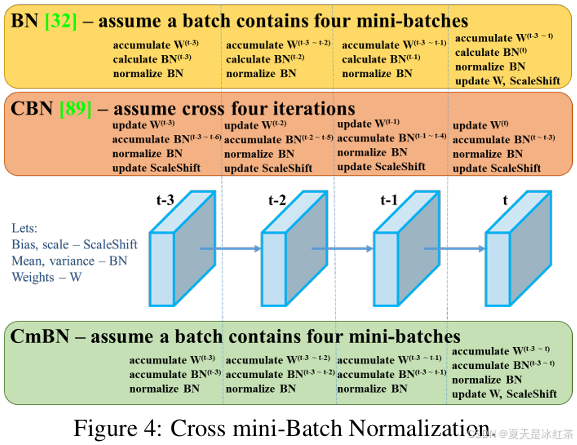
CmBN
BN,是在一个mini-batch内计算均值和方差,并用其来规范化该batch内的数据,但其严重依赖于batch size,当batch size很小时(例如为1或2),计算的均值和方差变得极不准确,无法代表整个训练集的分布,导致模型性能急剧下降。
CBN,利用过去几次迭代(iterations)中计算出的均值和方差,通过线性插值的方式,为当前iteration提供一个更稳定、更接近全局的统计量估计。简单来说,CBN不再只看当前batch,而是“偷看”前面几个batch的数据统计信息,将它们融合起来使用。
CmBN,是YOLOv4对CBN思想的一种改进和简化,使其更高效地应用于YOLO这样的目标检测器。CmBN的全称是Cross mini-Batch Normalization。它的核心思想与CBN类似,但其“Cross”的范围不是一个迭代,而是在一个大的“Batch”内部。
Label Smoothing的作用
在训练深度学习模型,特别是分类模型时,我们通常使用one-hot编码和交叉熵损失函数。我们通常将标签表示为one-hot向量,交叉熵损失函数会鼓励模型为正确类别输出无限接近1的概率,为错误类别输出无限接近0的概率。这使得模型会不断追求极致的“正确自信”。Label Smoothing的核心思想非常简单:将“硬标签”软化,让网络不再盲目地追求极致的概率输出。
Label Smoothing通过一个简单的线性插值来生成新的标签分布:
平滑后的软标签,
是原始的one-hot编码标签,
平滑因子,是一个很小的值,通常设置在 0.1 左右。它控制了平滑的程度,K是类别总数。
这样有助于减轻过拟合,提升泛化能力,防止模型对硬标签的过度追求,并且模型的预测概率会变得更加“温和”,更能反映其真实的确信度。例如,预测为0.9的样本,其实际正确的概率也更接近90%,而错误类别也并非完全没有概率,这为模型训练提供了一个小的“噪声”信号,可以看作是一种正则化,有助于提升模型的鲁棒性。
主干网络
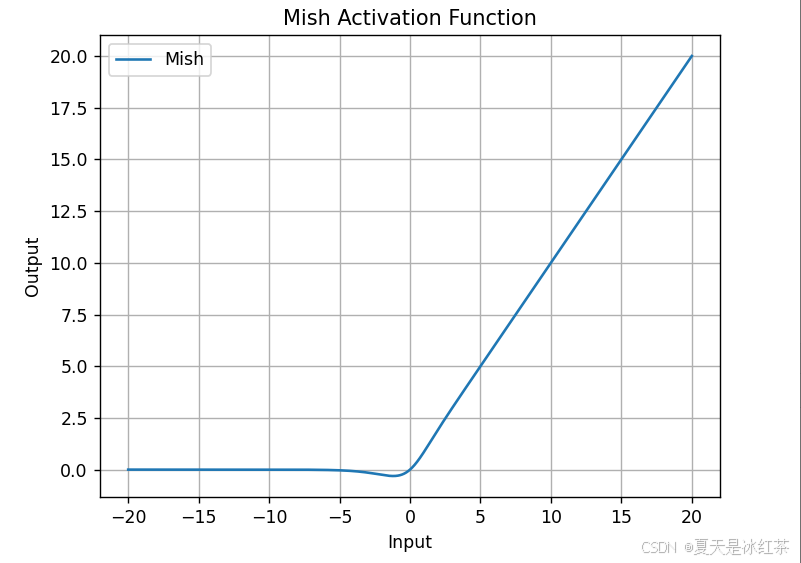
Mish激活函数
yolov4只在Backbone中都使用了Mish激活函数,而后面的网络则还是使用的是leaky_relu。
class Mish(nn.Module):def __init__(self, inplace=False):super().__init__()self.inplace = inplacedef _mish(self, x):if self.inplace:return x.mul_(torch.tanh(F.softplus(x)))else:return x * torch.tanh(F.softplus(x))def forward(self, x):return self._mish(x)DropBlock
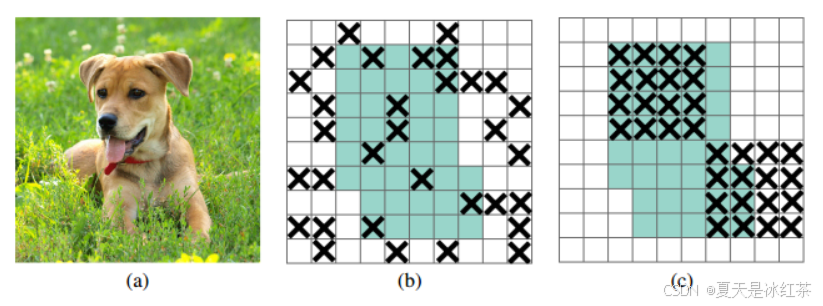
(a)原始输入图像;(b)绿色部分表示激活的特征单元,b图表示了随机dropout激活单元,但是这样dropout后,网络还会从drouout掉的激活单元附近学习到同样的信息;(c)绿色部分表示激活的特征单元,c图表示本文的DropBlock,通过dropout掉一部分相邻的整片的区域(比如头和脚),网络就会去注重学习狗的别的部位的特征,来实现正确分类,从而表现出更好的泛化。
import torch
import torch.nn as nn
import torch.nn.functional as Fclass DropBlock(nn.Module):"""Randomly drop some regions of feature maps.Please refer to the method proposed in `DropBlock<https://arxiv.org/abs/1810.12890>` for details. Copyright (c) OpenMMLab. All rights reserved.total_iters = ceil(The total number of samples in the dataset / batch_size) * total_epochswarmup_iters = int(total_iters * 0.05) # 5%~10%"""def __init__(self, drop_prob, block_size, warmup_iters=2000, eps=1e-6):super(DropBlock, self).__init__()assert block_size % 2 == 1assert 0 < drop_prob <= 1assert warmup_iters >= 0self.drop_prob = drop_probself.block_size = block_sizeself.warmup_iters = warmup_itersself.esp = epsself.iter_cnt = 0def forward(self, x):if not self.training or self.drop_prob == 0:return xself.iter_cnt += 1N, C, H, W = list(x.shape)gamma = self._compute_gamma((H, W))mask_shape = (N, C, H - self.block_size + 1, W - self.block_size + 1)mask = torch.bernoulli(torch.full(mask_shape, gamma, device=x.device))mask = F.pad(mask, [self.block_size // 2] * 4, value=0)mask = F.max_pool2d(input=mask,stride=(1, 1),kernel_size=(self.block_size, self.block_size),padding=self.block_size // 2)mask = 1 - maskx = x * mask * mask.numel() / (self.esp + mask.sum())return xdef _compute_gamma(self, feat_size):"""Compute the value of gamma according to paper. gamma is theparameter of bernoulli distribution, which controls the number offeatures to drop.gamma = (drop_prob * fm_area) / (drop_area * keep_area)Args:feat_size (tuple[int, int]): The height and width of feature map.Returns:float: The value of gamma."""gamma = (self.drop_prob * feat_size[0] * feat_size[1])gamma /= ((feat_size[0] - self.block_size + 1) *(feat_size[1] - self.block_size + 1))gamma /= (self.block_size ** 2)factor = (1.0 if self.iter_cnt > self.warmup_iters else self.iter_cnt /self.warmup_iters)return gamma * factorif __name__=="__main__":feat = torch.rand(1, 1, 8, 8)drop_prob = 0.5dropblock = DropBlock(drop_prob, block_size=3, warmup_iters=1)out_feat = dropblock(feat)print(feat)print(out_feat)下面是运行的数据,warmup_iters表示文中提到的线性减小keep_prob的迭代次数,即这里线性增大drop_prob的迭代次数。
tensor([[[[0.2918, 0.1338, 0.0256, 0.1683, 0.1543, 0.3968, 0.1123, 0.3021],[0.9277, 0.8150, 0.3299, 0.0435, 0.8693, 0.4234, 0.0535, 0.0751],[0.6832, 0.6207, 0.3766, 0.3782, 0.8423, 0.4333, 0.3997, 0.0330],[0.3511, 0.8286, 0.7066, 0.9704, 0.3213, 0.8970, 0.0215, 0.1854],[0.8134, 0.6661, 0.0937, 0.8077, 0.0578, 0.7240, 0.9163, 0.2477],[0.8118, 0.3664, 0.5025, 0.5898, 0.4648, 0.8046, 0.3196, 0.9896],[0.0026, 0.4029, 0.4864, 0.8737, 0.1804, 0.8855, 0.7628, 0.8371],[0.2014, 0.0188, 0.1605, 0.8519, 0.8853, 0.5643, 0.2013, 0.9251]]]])
tensor([[[[0.5188, 0.2379, 0.0455, 0.2992, 0.0000, 0.0000, 0.0000, 0.5370],[1.6493, 1.4488, 0.5865, 0.0000, 0.0000, 0.0000, 0.0000, 0.1335],[1.2145, 1.1034, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0587],[0.6242, 1.4730, 0.0000, 0.0000, 0.0000, 0.0000, 0.0383, 0.3297],[1.4460, 1.1842, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000],[1.4432, 0.6513, 0.8933, 1.0485, 0.8262, 0.0000, 0.0000, 0.0000],[0.0047, 0.7163, 0.8647, 1.5532, 0.3208, 0.0000, 0.0000, 0.0000],[0.3580, 0.0334, 0.2853, 1.5146, 1.5739, 1.0032, 0.3579, 1.6446]]]])CSPDarknet53
CSPDarknet53的核心是在Darknet-53的基础上(可以看以前我对DarkNet的实现),将其中的残差块(Residual Block)替换为CSP模块。现在我们试着实现一下:
import torch
import torch.nn as nn
import torch.nn.functional as Fclass Mish(nn.Module):def __init__(self, inplace=False):super().__init__()self.inplace = inplacedef _mish(self, x):if self.inplace:return x.mul_(torch.tanh(F.softplus(x)))else:return x * torch.tanh(F.softplus(x))def forward(self, x):return self._mish(x)class DropBlock(nn.Module):"""Randomly drop some regions of feature maps.Please refer to the method proposed in `DropBlock<https://arxiv.org/abs/1810.12890>` for details. Copyright (c) OpenMMLab. All rights reserved."""def __init__(self, drop_prob, block_size, warmup_iters=0, eps=1e-6):super(DropBlock, self).__init__()assert block_size % 2 == 1assert 0 < drop_prob <= 1assert warmup_iters >= 0self.drop_prob = drop_probself.block_size = block_sizeself.warmup_iters = warmup_itersself.esp = epsself.iter_cnt = 0def forward(self, x):if not self.training or self.drop_prob == 0:return xself.iter_cnt += 1N, C, H, W = list(x.shape)gamma = self._compute_gamma((H, W))mask_shape = (N, C, H - self.block_size + 1, W - self.block_size + 1)mask = torch.bernoulli(torch.full(mask_shape, gamma, device=x.device))mask = F.pad(mask, [self.block_size // 2] * 4, value=0)mask = F.max_pool2d(input=mask,stride=(1, 1),kernel_size=(self.block_size, self.block_size),padding=self.block_size // 2)mask = 1 - maskx = x * mask * mask.numel() / (self.esp + mask.sum())return xdef _compute_gamma(self, feat_size):"""Compute the value of gamma according to paper. gamma is theparameter of bernoulli distribution, which controls the number offeatures to drop.gamma = (drop_prob * fm_area) / (drop_area * keep_area)Args:feat_size (tuple[int, int]): The height and width of feature map.Returns:float: The value of gamma."""gamma = (self.drop_prob * feat_size[0] * feat_size[1])gamma /= ((feat_size[0] - self.block_size + 1) *(feat_size[1] - self.block_size + 1))gamma /= (self.block_size ** 2)factor = (1.0 if self.iter_cnt > self.warmup_iters else self.iter_cnt /self.warmup_iters)return gamma * factorclass CBM(nn.Module):def __init__(self, in_channels, out_channels, kernel_size, stride, padding, dilation=1, groups=1, bias=False):super(CBM, self).__init__()self.conv = nn.Conv2d(in_channels, out_channels, kernel_size, stride, padding, dilation=dilation,groups=groups, bias=bias)self.bn = nn.BatchNorm2d(out_channels)self.activation = Mish()def forward(self, x):return self.activation(self.bn(self.conv(x)))class ResUnit(nn.Module):"""Basic residual block with Mish activation"""def __init__(self, channels, hidden_channels=None):super(ResUnit, self).__init__()if hidden_channels is None:hidden_channels = channelsself.block = nn.Sequential(CBM(in_channels=channels, out_channels=hidden_channels, kernel_size=1, stride=1, padding=0),CBM(in_channels=hidden_channels, out_channels=channels, kernel_size=3, stride=1, padding=1),)def forward(self, x):return x + self.block(x)class CSPBlock(nn.Module):"""CSP (Cross Stage Partial) Block - the core of CSPDarknet53input -> CBM -> CBM1 -> X * ResUnit -> CBM2 -> || Concat -> CBM -> output| --------------------> CBM3 -> |"""def __init__(self, in_channels, out_channels, num_blocks):super(CSPBlock, self).__init__()self.downsample_conv = CBM(in_channels, out_channels, 3, 2, 1)self.cbm1 = CBM(out_channels, out_channels//2, 1, 1, 0)self.cbm2 = CBM(out_channels // 2, out_channels // 2, 1, 1, 0)self.cbm3 = CBM(out_channels, out_channels//2, 1, 1, 0)# X times ResUnitself.res_blocks = nn.Sequential(*[ResUnit(out_channels//2) for _ in range(num_blocks)])self.transition_conv = CBM(out_channels, out_channels, 1, 1, 0)def forward(self, x):# Split the inputx = self.downsample_conv(x)# main path: →CBM →CBM →Redunit →CBM →x_main = self.cbm1(x)x_main = self.res_blocks(x_main)x_main = self.cbm2(x_main)# Shortcut path: →CBM →x_shortcut = self.cbm3(x)# Concatenate and transitionx_out = torch.cat([x_main, x_shortcut], dim=1)return self.transition_conv(x_out)class CSPDarknet53(nn.Module):def __init__(self, num_classes=1000, num_blocks=(1, 2, 8, 8, 4), drop_prob=0.1):super(CSPDarknet53, self).__init__()self.conv0 = CBM(3, 32, 3, 1, 1)# if num_blocks = 1:self.csp1_downsample_conv = CBM(32, 64, 3, 2, 1)self.csp1_main_path = nn.Sequential(CBM(64, 64, 1, 1, 0),ResUnit(64, 64 // 2),CBM(64, 64, 1, 1, 0))self.csp1_shortcut_path = CBM(64, 64, 1, 1, 0)self.csp1_transition_conv = CBM(2 * 64, 64, 1, 1, 0)self.csp2 = CSPBlock(64, 128, num_blocks=num_blocks[1])self.csp3 = CSPBlock(128, 256, num_blocks=num_blocks[2])self.csp4 = CSPBlock(256, 512, num_blocks=num_blocks[3])self.csp5 = CSPBlock(512, 1024, num_blocks=num_blocks[4])# DropBlock (optional)self.dropblock = DropBlock(drop_prob, block_size=7)self.global_pool = nn.AdaptiveAvgPool2d(1)self.dropout = nn.Dropout(0.5)self.fc = nn.Linear(1024, num_classes)def forward(self, x):out = self.conv0(x)out = self.csp1_downsample_conv(out)csp1_main = self.csp1_main_path(out)csp1_shortcut = self.csp1_shortcut_path(out)out1 = self.csp1_transition_conv(torch.cat([csp1_main, csp1_shortcut], 1))out2 = self.csp2(out1)out3 = self.csp3(out2)out4 = self.csp4(out3)out5 = self.csp5(out4)# typically output out3, out4, out5out = self.global_pool(out5)out = out.view(out.size(0), -1)x = self.dropout(x)out = self.fc(out)return outif __name__=="__main__":model = CSPDarknet53(num_classes=1000)input_tensor = torch.randn(2, 3, 224, 224)output = model(input_tensor)print(f"Input shape: {input_tensor.shape}")print(f"Output shape: {output.shape}")这里主要是参考的网上的模型图实现的,命名符合上面yolov4的结构图,方便对照着理解,一般检测部分是输出out3,out4,out5,yolov4使用时删去了最后的池化层和全连接层。
颈部网络
Yolov4的Neck主要采用了SPP模块、FPN+PAN的方式。
SPP模块
SPP的核心思想非常简单却极其有效,就是将空间池化操作推迟到卷积层的最后,使用多尺度的池化策略来生成固定长度的输出。
import torch
import torch.nn as nnclass SPP(nn.Module):"""Implements Spatial Pyramid Pooling (SPP) for feature extraction, ref: https://arxiv.org/abs/1406.4729."""def __init__(self, c1, c2, k=(5, 9, 13)):"""Initializes SPP layer with Spatial Pyramid Pooling, ref: https://arxiv.org/abs/1406.4729, args: c1 (input channels), c2 (output channels), k (kernel sizes)."""super().__init__()c_ = c1 // 2 # hidden channelsself.cv1 = nn.Sequential(nn.Conv2d(c1, c_, kernel_size=1),nn.BatchNorm2d(c_),nn.SiLU())self.cv2 = nn.Sequential(nn.Conv2d(c_ * (len(k) + 1), c2, kernel_size=1),)self.m = nn.ModuleList([nn.MaxPool2d(kernel_size=x, stride=1, padding=x // 2) for x in k])def forward(self, x):x = self.cv1(x)return self.cv2(torch.cat([x] + [m(x) for m in self.m], 1))if __name__=="__main__":spp = SPP(c1=64, c2=128, k=(5, 9, 13))batch_size, channels, height, width = 4, 64, 32, 32input_tensor = torch.randn(batch_size, channels, height, width)print(f"输入形状: {input_tensor.shape}")output = spp(input_tensor)print(f"输出形状: {output.shape}")原文出自这里:Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition | SpringerLink
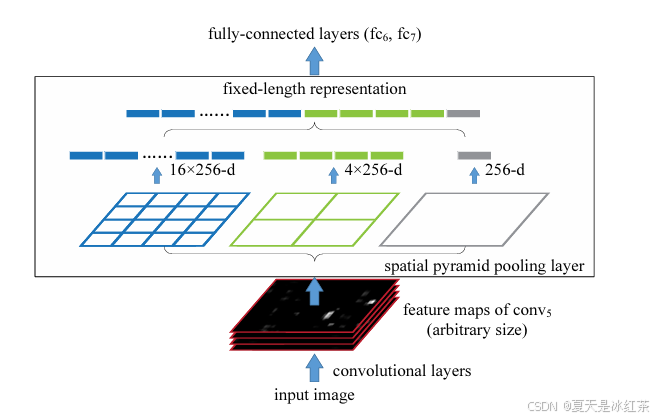
这里要从下往上看,input image可以是任意大小,然后进行卷积运算,到最后一个卷积层,就是图中的conv5,输出得到该层的feature maps,其大小也是任意的,进入SPP层后,会将特征分别映射成16,4,1份,也就是特征映射被转化成了 16X256+4X256+1X256 = 21X256 的矩阵。在送入全连接时可以扩展成一维矩阵,即 1X10752 ,所以第一个全连接层的参数就可以设置成10752了,这样也就解决了输入数据大小任意的问题了。当然划分为多少份可以自己定,但我们一般还是按照它论文中这样设置。
FPN+PAN
Yolov4中Neck这部分除了使用FPN外,还在此基础上使用了PAN结构。FPN的核心思想是将深层的强语义特征传递到浅层,增强浅层特征的语义信息,但FPN是单向的信息流动(自顶向下),浅层的定位信息无法传递给深层。PAN在FPN的基础上增加了自底向上的路径,实现了双向特征融合。
-
FPN(自上而下):语义信息向下传播,增强浅层特征的语义能力
-
PAN(自下而上):定位信息向上传播,增强深层特征的定位精度
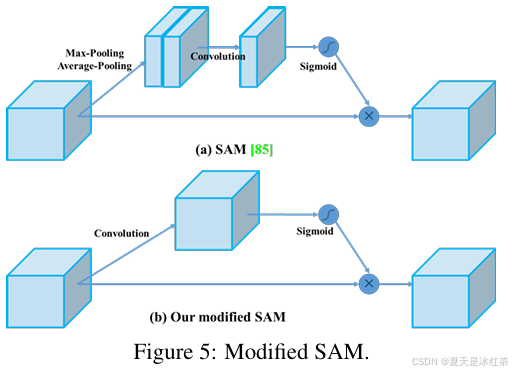
SAM注意力
作者在论文里面说虽然SE模块可以在ImageNet图像分类任务中提升ResNet50的top-1准确率1%,但代价只是增加了2%的计算量,但在GPU上通常会增加约10%的推理时间,因此更适合用于移动设备。而对于和空间注意力模块SAM,只需额外付出0.1%的计算量,就能在ImageNet图像分类任务中提升ResNet50-SE的top-1准确率0.5%,并且完全不影响GPU上的推理速度。
class SAM(nn.Module):"""Spatial Attention Module"""def __init__(self, kernel_size=7):super(SAM, self).__init__()self.conv = nn.Conv2d(2, 1, kernel_size, padding=kernel_size//2, bias=False)self.sigmoid = nn.Sigmoid()def forward(self, x):# x: [B, C, H, W]max_out, _ = torch.max(x, dim=1, keepdim=True) # [B,1,H,W]avg_out = torch.mean(x, dim=1, keepdim=True) # [B,1,H,W]x_out = torch.cat([max_out, avg_out], dim=1) # [B,2,H,W]attention = self.sigmoid(self.conv(x_out)) # [B,1,H,W]return x * attention预测头
CIOU_Loss
CIoU在DIoU的基础上,增加了长宽比一致性的考虑,完整地包含了:重叠面积,中心点距离,长宽比。
import torch
import mathdef CIoU(box1, box2, xywh=True, eps=1e-7):# Get the coordinates of bounding boxesif xywh: # transform from xywh to xyxy(x1, y1, w1, h1), (x2, y2, w2, h2) = box1.chunk(4, -1), box2.chunk(4, -1)w1_, h1_, w2_, h2_ = w1 / 2, h1 / 2, w2 / 2, h2 / 2b1_x1, b1_x2, b1_y1, b1_y2 = x1 - w1_, x1 + w1_, y1 - h1_, y1 + h1_b2_x1, b2_x2, b2_y1, b2_y2 = x2 - w2_, x2 + w2_, y2 - h2_, y2 + h2_else: # x1, y1, x2, y2 = box1b1_x1, b1_y1, b1_x2, b1_y2 = box1.chunk(4, -1)b2_x1, b2_y1, b2_x2, b2_y2 = box2.chunk(4, -1)w1, h1 = b1_x2 - b1_x1, (b1_y2 - b1_y1).clamp(eps)w2, h2 = b2_x2 - b2_x1, (b2_y2 - b2_y1).clamp(eps)# Intersection areainter = (b1_x2.minimum(b2_x2) - b1_x1.maximum(b2_x1)).clamp(0) * (b1_y2.minimum(b2_y2) - b1_y1.maximum(b2_y1)).clamp(0)# Union Areaunion = w1 * h1 + w2 * h2 - inter + eps# IoUiou = inter / unioncw = b1_x2.maximum(b2_x2) - b1_x1.minimum(b2_x1) # convex (smallest enclosing box) widthch = b1_y2.maximum(b2_y2) - b1_y1.minimum(b2_y1) # convex heightc2 = cw**2 + ch**2 + eps # convex diagonal squaredrho2 = ((b2_x1 + b2_x2 - b1_x1 - b1_x2) ** 2 + (b2_y1 + b2_y2 - b1_y1 - b1_y2) ** 2) / 4 # center dist ** 2v = (4 / math.pi**2) * (torch.atan(w2 / h2) - torch.atan(w1 / h1)).pow(2)with torch.no_grad():alpha = v / (v - iou + (1 + eps))return iou - (rho2 / c2 + v * alpha) DIOU_NMS
在目标检测的后处理环节,非极大值抑制(NMS) 是确保最终检测结果准确性的关键步骤。传统的NMS基于IoU来抑制重叠框,但在一些复杂场景下表现不佳。DIOU_NMS 的提出,通过引入中心点距离信息,让NMS过程更加智能和准确,特别是在处理遮挡、密集目标等挑战性场景时表现卓越。
也就是如果两个框中心点距离很远,即使IoU较高,也不应该相互抑制;如果两个框中心点距离很近,即使IoU不高,也可能需要抑制。
参考论文
YOLO 图文入门 04 v4 PAN,SAM(含代码+原文)_yolo pan-CSDN博客
【YOLO系列】--YOLOv4超详细解读/总结(网络结构)-CSDN博客
YOLO那些事儿【YOLOv4详解】_yolov4的sat-CSDN博客
YOLOV4-综述_yolov4的 panet-CSDN博客
YOLOv4论文翻译(已校正)-CSDN博客
正则化方法之DropBlock-CSDN博客
DropBlock(NeurIPS 2018)论文与代码解析_neurips模板中伪代码怎么写-CSDN博客
(97 封私信) YOLOv4特征提取网络——CSPDarkNet结构解析及PyTorch实现 - 知乎