【CVPR24-工业异常检测】InCTRL:少样本基于上下文残差学习的通才异常检测
摘要:
- 研究领域:广义异常检测(GAD) + 广义异常检测的研究目标:训练单一的检测模型到这个模型可以在没有对目标数据集进一步训练的情况下,泛化地检测来自不同应用领域的不同数据集的异常。
- 引入Clip:可以检测各种数据集中的工业异常,泛化能力强 + 模型不足:严重依赖关于缺陷的手工文本提示,难泛化到检测其他领域的异常(医学图像异常/自然图像中的语义异常)
- 训练图像:少样本正常图像 + GAD模型(给不同数据集提供样本提示)
- 提出模型:上下文残差学习模型(InCTRL) + 大致过程: 在辅助数据集上训练,通过计算查询图像和少量正常样本提示之间的残差的整体评估-》区分异常和正常(异常的残差比正常样本大) +效果:InCTRL可以在没有进一步训练的情况下,对其他领域的异常检测
- 实验结果: 数据集【9个:工业数据集,医疗数据集,语义数据集】+基准【GAD】+设置【一对一/多类别】+表现最佳,明显优于其他方法
代码:https://github.com/mala-lab/InCTRL
InCTRL方法概括
- 大致过程:把查询图像和一组少样本的正常图像之间的上下文残差=样本提示(利用Clip的泛化能力检测异常残差)
- + 分开讲解:
- + 1.Clip=由文本编码器f_t()和视觉编码器f_v()组成的模型,在网络规模的文本图像数据上预训练,经过编码器的图像和文本基本对齐
- + 2.创新点:上下文残差=用图像编码器的上下文残差学习+ 用辅助数据训练优化+文本编码器的文本提示引导先验知识增强学习
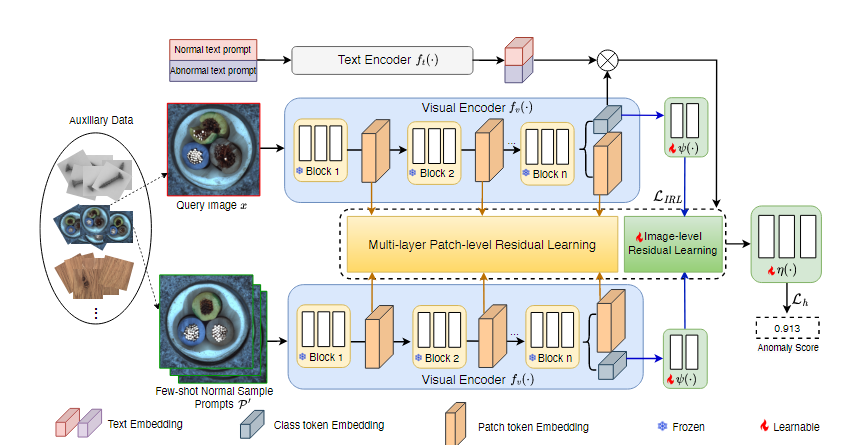
框架图
-
框架过程:
1.模拟上下文学习示例【从辅助数据列中随机采样的 一个查询图像x + 一组少量正常图像P’】
2.视觉编码器中加入多层补丁级残差学习【黄色砖块,用处:捕获查询图像和少量正常图像的局部差异】+ 图像级残差学习【蓝色砖块,用处:捕获查询图像和少量正常图像的全局差异】
-
3.正常提示和异常提示通过文本编码器 生成 正常提示嵌入和异常提示嵌入,计算正常/异常提示嵌入 和 查询图像之间的相似性,把相似性结果放入到视觉编码器中(目的:把正常和异常提示做引导)
InCTRL的训练目的:优化视觉编码器中的投影层和适配层-》让模型在训练数据集上 异常样本的异常分数>>正常样本的异常分数 + 保持视觉编码器和文本编码器的原始参数保持不变
测试过程
输入: 测试图像 +目标数据集的少量正常图像 +文本提示
模型:经过训练,加入适配器的基于CLIP的广义异常检测网络
输出:测试图像的异常分数(是不是没有像素级异常检测)
实验结果
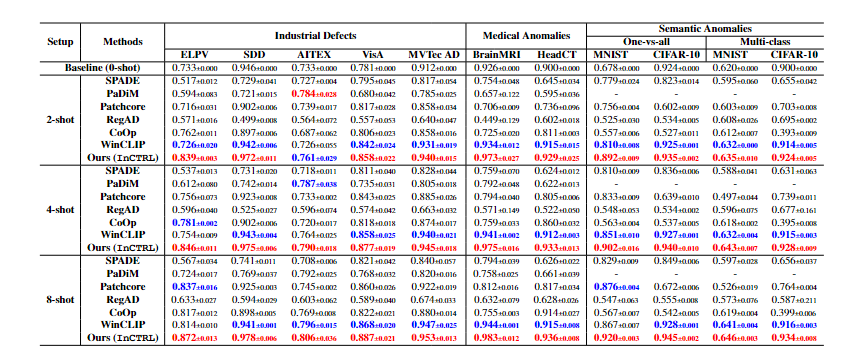
表1:InCTRL
跟6种方法相比(SPADE【2020】,PaDiM【2020】,PatchCore【2022】,RegAD【ECCV2022】,WinCLIP【CVPR2023】,CoOp【CVPR2022】 没有24,25年的比较)
指标:AUROC(平均结果)
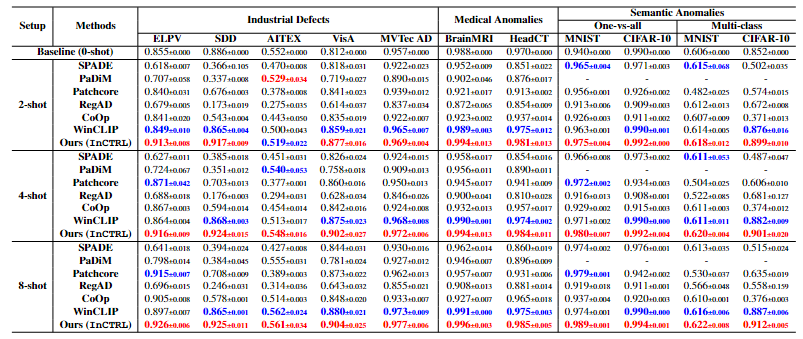 表2:InCTRL
表2:InCTRL
跟6种方法相比(SPADE【2020】,PaDiM【2020】,PatchCore【2022】,RegAD【ECCV2022】,WinCLIP【CVPR2023】,CoOp【CVPR2022】 没有24,25年的比较)
指标:AUPRC(平均结果)
- 工业异常检测:InCTRL在(2,4,8)少样本设置下,除了AITEX数据集的2-shot下比不过PaDiM外,其余都是第一【0样本的结果可以和其他方法比,看怎么样,能不能打过24年和25年的零样本,少样本的是否可以跟其他方法比】+ 样本越多,AUROC的值越高