吴恩达机器学习作业十一:异常检测
数据集在作业一
异常检测
异常检测就是发现与大部分对象不同的对象,其实就是发现离群点。异常检测有时也称偏差检测。异常对象是相对罕见的。用数据集建立概率模型p ( x ),如果新的测试数据在这个模型上小于某个阈值,则说它极大可能为异常点
算法流程:
1.求出均值与方差
2.计算正态分布密度函数
3.找出合适的阈值
代码实现
读取数据及可视化
import numpy as np
import matplotlib.pyplot as plt
import scipy.io as sio# 读取数据
data=sio.loadmat("ex8data1.mat")
X=data['X']
X_val=data['Xval']
y_val=data['yval']
# print(X.shape)(307, 2)# 可视化
# plt.scatter(X[:,0],X[:,1],marker='o',c='y',edgecolors='g')
# plt.show()
获取均值和方差
def estimate_gaussian(X,isCovariance):mu=np.mean(X,axis=0)if isCovariance:sigma = np.cov(X.T)else:sigma=np.var(X,axis=0)return mu,sigma这里的方差有一个不同之处,因为X有多个特征,不能判断特征之间是否没有线性关系,若没有,则按照每列来计算各列的方差,反之,我们就要用协方差。
协方差矩阵

计算概率密度
def gaussian_prob(X,mu,sigma):p=np.zeros((X.shape[0],1))n=len(mu)if np.ndim(sigma) == 1: # 返回sigma的维度是1sigma = np.diag(sigma) # 将一维数组转化为方阵,非对角线元素为0for i in range(X.shape[0]):# 计算公式中的指数部分:-0.5*(x-μ)⊤Σ⁻¹(x-μ)exponent = -0.5 * (X[i, :] - mu).T @ np.linalg.inv(sigma) @ (X[i, :] - mu)# 计算概率密度值并赋值给p[i]p[i] = (2 * np.pi) ** (-n / 2) # 公式中的(2π)^(-n/2)p[i] *= np.linalg.det(sigma) ** (-1 / 2) # 乘以|Σ|^(-1/2)p[i] *= np.exp(exponent) # 乘以指数部分return pp=gaussian_prob(X,mu,sigma)
绘制梯度密度等高线
def plot_gaussian(X,means,sigma):x=np.arange(0,30,0.5)y=np.arange(0,30,0.5)xx,yy=np.meshgrid(x,y)Z=gaussian_prob(np.c_[xx.ravel(),yy.ravel()],means,sigma)zz=Z.reshape(xx.shape)contour_levels = [10 ** h for h in range(-20, 0, 3)]plt.contour(xx, yy, zz, contour_levels)#生成了 [1e-20, 1e-17, 1e-14, 1e-11, 1e-8, 1e-5, 1e-2] 这 7 个值,# 表示只绘制密度等于这些值的等高线。plt.scatter(X[:, 0], X[:, 1], marker='x', c='b')plt.show()# plot_gaussian(X,mu,sigma)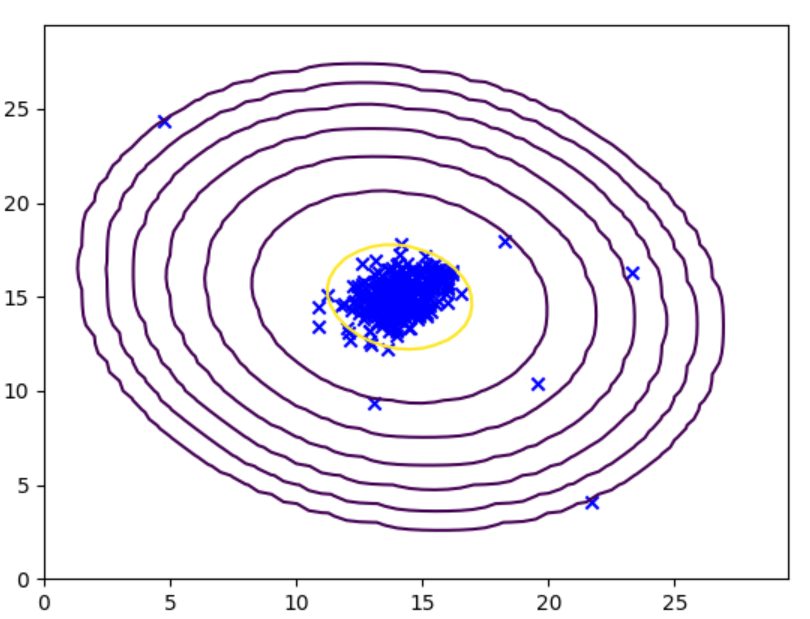
这里是通过取足够多的点并计算它们的概率密度,从而实现等高线。
找出最佳阈值
#4.阈值epsilonz自取
def selecteps(yval,p):bestEpsilon = 0 # 最佳阈值,初始化为0bestF1 = 0 # 最佳F1分数,初始化为0# 生成1000个候选阈值,均匀分布在p的最小值和最大值之间epsilons = np.linspace(min(p), max(p), 1000)for e in epsilons:# 基于当前阈值e判断:p < e → 异常(1),否则正常(0)p_ = p < e# 计算混淆矩阵的四个指标tp = np.sum((yval == 1) & (p_ == 1)) # 真正例:实际异常,预测也异常fp = np.sum((yval == 0) & (p_ == 1)) # 假正例:实际正常,预测异常tn = np.sum((yval == 0) & (p_ == 0)) # 真负例:实际正常,预测正常fn = np.sum((yval == 1) & (p_ == 0)) # 假负例:实际异常,预测正常# 计算精确率(Precision):预测为异常的样本中,实际异常的比例prec = tp / (tp + fp) if (tp + fp) else 0 # 避免分母为0# 计算召回率(Recall):实际异常的样本中,被正确预测的比例rec = tp / (tp + fn) if (tp + fn) else 0 # 避免分母为0# 计算F1分数:精确率和召回率的调和平均,综合评价模型性能F1 = (2 * prec * rec) / (prec + rec) if (prec + rec) else 0# 更新最佳阈值和F1分数if F1 > bestF1:bestF1 = F1bestEpsilon = ereturn bestF1,bestEpsilonp_val=gaussian_prob(X_val,mu,sigma)
bestF1,bestEpsilon=selecteps(y_val,p_val)这里利用了混淆矩阵来更新最佳阈值。
圈出异常点
# 圈出异常点
p=gaussian_prob(X,mu,sigma)
anoms = np.array([X[i] for i in range(X.shape[0]) if p[i] < bestEpsilon])
plt.scatter(anoms[:,0], anoms[:,1], s=100, marker='o', facecolors='none', edgecolors='r', linewidths=2)
plot_gaussian(X, mu, sigma)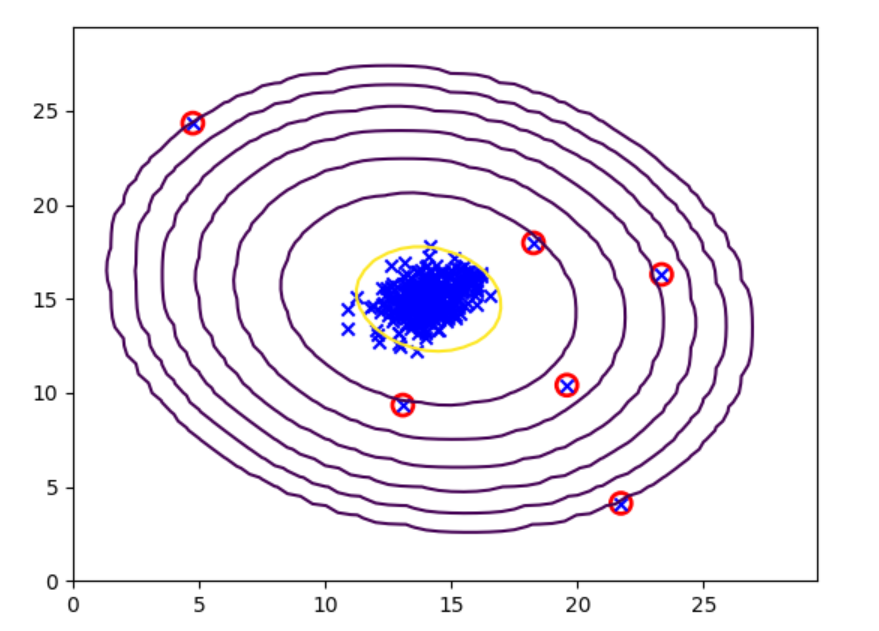
总结
读取数据——获取均值与方差——用概率密度函数构建模型——找出最佳阈值——找出异常点。