基于muduo库的图床云共享存储项目(三)
基于muduo库的图床云共享存储项目(三)
- 数据库的引入
- 涉及的数据库表单
- 引入MySQL线程池,Redis线程池
- mysql
- redis
- 配置文件的引入
- 实现完整注册功能
- 头文件以及通用函数统一设置
- 注册功能完善
- 登录功能完善
- 阶段性功能验证
- 文件上传功能实现
- /api/upload上传文件
- 流程解析
- 代码实现
- /api/md5文件秒传
- 流程解析
- 代码实现
- 功能验证
在图床云共享存储项目(二)中我们已经实现了用户注册以及登录功能,但是并没有引入数据库,本文主要是针对于注册以及登录功能进行完善,以及对文件上传功能的实现。
数据库的引入
涉及的数据库表单
我们注册的信息是存储在数据库当中的,那当前就需要一个数据库表单来进行存储,所以我们就需要创建一个数据库,专门用来存储我们图床项目的一些表单信息。
创建数据库
#创建数据库
DROP DATABASE IF EXISTS `0voice_tuchuang`;
CREATE DATABASE `0voice_tuchuang`;
#使用数据库
use `0voice_tuchuang`;
user表创建
# 清除表单
DROP TABLE IF EXISTS `user_info`;
# 重新创建表单 id自增,nick_name user_name创建唯一索引
CREATE TABLE `user_info` (
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '用户序号,自动递增,主键',
`user_name` varchar(32) NOT NULL DEFAULT '' COMMENT '用户名称',
`nick_name` varchar(32) CHARACTER SET utf8mb4 NOT NULL DEFAULT '' COMMENT '用户昵
称',
`password` varchar(32) NOT NULL DEFAULT '' COMMENT '密码',
`phone` varchar(16) NOT NULL DEFAULT '' COMMENT '手机号码',
`email` varchar(64) DEFAULT '' COMMENT '邮箱',
`create_time` timestamp NULL DEFAULT CURRENT_TIMESTAMP COMMENT '时间',
PRIMARY KEY (`id`),
UNIQUE KEY `uq_nick_name` (`nick_name`),
UNIQUE KEY `uq_user_name` (`user_name`)
) ENGINE=InnoDB AUTO_INCREMENT=14 DEFAULT CHARSET=utf8 COMMENT='用户信息表';
引入MySQL线程池,Redis线程池
redis mysql目录为MySQL redis操作接口。
下面是 mysql 以及 redis 连接池的封装代码实现,后续会专门更新一片关于连接池的文章
mysql
db_poo.h
#ifndef DBPOOL_H_
#define DBPOOL_H_#include <condition_variable>
#include <iostream>
#include <list>
#include <map>
#include <mutex>
#include <stdint.h>
#include <string>#include <mysql.h>#define MAX_ESCAPE_STRING_LEN 10240using namespace std;// https://www.mysqlzh.com/api/66.html 学习mysql c接口使用// 返回结果 select的时候用
class CResultSet {public:CResultSet(MYSQL_RES *res);virtual ~CResultSet();bool Next();int GetInt(const char *key);char *GetString(const char *key);private:int _GetIndex(const char *key);// 该结构代表返回行的查询结果(SELECT, SHOW, DESCRIBE, EXPLAIN)MYSQL_RES *res_;// 这是1行数据的“类型安全”表示。它目前是按照计数字节字符串的数组实施的。MYSQL_ROW row_;map<string, int> key_map_;
};// 插入数据用
class CPrepareStatement {public:CPrepareStatement();virtual ~CPrepareStatement();bool Init(MYSQL *mysql, string &sql);void SetParam(uint32_t index, int &value);void SetParam(uint32_t index, uint32_t &value);void SetParam(uint32_t index, string &value);void SetParam(uint32_t index, const string &value);bool ExecuteUpdate();uint32_t GetInsertId();private:MYSQL_STMT *stmt_;MYSQL_BIND *param_bind_;uint32_t param_cnt_;
};class CDBPool;class CDBConn {public:CDBConn(CDBPool *pDBPool);virtual ~CDBConn();int Init();// 创建表bool ExecuteCreate(const char *sql_query);// 删除表bool ExecuteDrop(const char *sql_query);// 查询CResultSet *ExecuteQuery(const char *sql_query);bool ExecutePassQuery(const char *sql_query);/*** 执行DB更新,修改** @param sql_query sql* @param care_affected_rows 是否在意影响的行数,false:不在意;true:在意** @return 成功返回true 失败返回false*/bool ExecuteUpdate(const char *sql_query, bool care_affected_rows = true);uint32_t GetInsertId();// 开启事务bool StartTransaction();// 提交事务bool Commit();// 回滚事务bool Rollback();// 获取连接池名const char *GetPoolName();MYSQL *GetMysql() { return mysql_; }int GetRowNum() { return row_num; }private:int row_num = 0;CDBPool *db_pool_; // to get MySQL server informationMYSQL *mysql_; // 对应一个连接char escape_string_[MAX_ESCAPE_STRING_LEN + 1];
};class CDBPool { // 只是负责管理连接CDBConn,真正干活的是CDBConnpublic:CDBPool() {} // 如果在构造函数做一些可能失败的操作,需要抛出异常,外部要捕获异常CDBPool(const char *pool_name, const char *db_server_ip,uint16_t db_server_port, const char *username, const char *password,const char *db_name, int max_conn_cnt);virtual ~CDBPool();int Init(); // 连接数据库,创建连接CDBConn *GetDBConn(const int timeout_ms = 0); // 获取连接资源void RelDBConn(CDBConn *pConn); // 归还连接资源const char *GetPoolName() { return pool_name_.c_str(); }const char *GetDBServerIP() { return db_server_ip_.c_str(); }uint16_t GetDBServerPort() { return db_server_port_; }const char *GetUsername() { return username_.c_str(); }const char *GetPasswrod() { return password_.c_str(); }const char *GetDBName() { return db_name_.c_str(); }private:string pool_name_; // 连接池名称string db_server_ip_; // 数据库ipuint16_t db_server_port_; // 数据库端口string username_; // 用户名string password_; // 用户密码string db_name_; // db名称int db_cur_conn_cnt_; // 当前启用的连接数量int db_max_conn_cnt_; // 最大连接数量list<CDBConn *> free_list_; // 空闲的连接list<CDBConn *> used_list_; // 记录已经被请求的连接std::mutex mutex_;std::condition_variable cond_var_;bool abort_request_ = false;
};// manage db pool (master for write and slave for read)
class CDBManager {public:virtual ~CDBManager();static void SetConfPath(const char *conf_path);static CDBManager *getInstance();int Init();CDBConn *GetDBConn(const char *dbpool_name);void RelDBConn(CDBConn *pConn);private:CDBManager();private:static CDBManager *s_db_manager;map<string, CDBPool *> dbpool_map_;static std::string conf_path_;
};
// 目的是在函数退出后自动将连接归还连接池
class AutoRelDBCon {public:AutoRelDBCon(CDBManager *manger, CDBConn *conn): manger_(manger), conn_(conn) {}~AutoRelDBCon() {if (manger_) {printf("%s RelDBConn:%p\n", __FUNCTION__, conn_);manger_->RelDBConn(conn_);}} //在析构函数规划private:CDBManager *manger_ = NULL;CDBConn *conn_ = NULL;
};
// 构建栈上的对象
#define AUTO_REL_DBCONN(m, c) AutoRelDBCon autoreldbconn(m, c)#endif /* DBPOOL_H_ */
db_pool.cc
#include "db_pool.h"
#include <string.h>
#include "muduo/base/Logging.h"
#include "config_file_reader.h"#define MIN_DB_CONN_CNT 1
#define MAX_DB_CONN_FAIL_NUM 10CDBManager *CDBManager::s_db_manager = NULL;
std::string CDBManager::conf_path_ = "tc_http_server.conf";
CResultSet::CResultSet(MYSQL_RES *res) {res_ = res;// map table field key to index in the result arrayint num_fields = mysql_num_fields(res_); // 返回结果集中的行数。MYSQL_FIELD *fields = mysql_fetch_fields(res_); // 关于结果集所有列的MYSQL_FIELD结构的数组for (int i = 0; i < num_fields; i++) {// 多行key_map_.insert(make_pair(fields[i].name, i)); // 每个结构提供了结果集中1列的字段定义LOG_DEBUG << " num_fields fields["<< i << "].name: " << fields[i].name;}
}CResultSet::~CResultSet() {if (res_) {mysql_free_result(res_);res_ = NULL;}
}bool CResultSet::Next() {row_ = mysql_fetch_row(res_); // 检索结果集的下一行,行内值的数目由mysql_num_fields(result)给出if (row_) {return true;} else {return false;}
}int CResultSet::_GetIndex(const char *key) {map<string, int>::iterator it = key_map_.find(key);if (it == key_map_.end()) {return -1;} else {return it->second;}
}int CResultSet::GetInt(const char *key) {int idx = _GetIndex(key); // 查找列的索引if (idx == -1) {return 0;} else {return atoi(row_[idx]); // 有索引}
}char *CResultSet::GetString(const char *key) {int idx = _GetIndex(key);if (idx == -1) {return NULL;} else {return row_[idx]; // 列}
}/////////////////////////////////////////
CPrepareStatement::CPrepareStatement() {stmt_ = NULL;param_bind_ = NULL;param_cnt_ = 0;
}CPrepareStatement::~CPrepareStatement() {if (stmt_) {mysql_stmt_close(stmt_);stmt_ = NULL;}if (param_bind_) {delete[] param_bind_;param_bind_ = NULL;}
}bool CPrepareStatement::Init(MYSQL *mysql, string &sql) {mysql_ping(mysql); // 当mysql连接丢失的时候,使用mysql_ping能够自动重连数据库// g_master_conn_fail_num ++;stmt_ = mysql_stmt_init(mysql);if (!stmt_) {LOG_ERROR << "mysql_stmt_init failed";return false;}if (mysql_stmt_prepare(stmt_, sql.c_str(), sql.size())) {LOG_ERROR << "mysql_stmt_prepare failed: " << mysql_stmt_error(stmt_);return false;}param_cnt_ = mysql_stmt_param_count(stmt_);if (param_cnt_ > 0) {param_bind_ = new MYSQL_BIND[param_cnt_];if (!param_bind_) {LOG_ERROR << "new failed";return false;}memset(param_bind_, 0, sizeof(MYSQL_BIND) * param_cnt_);}return true;
}void CPrepareStatement::SetParam(uint32_t index, int &value) {if (index >= param_cnt_) {LOG_ERROR << "index too large: " << index;return;}param_bind_[index].buffer_type = MYSQL_TYPE_LONG;param_bind_[index].buffer = &value;
}void CPrepareStatement::SetParam(uint32_t index, uint32_t &value) {if (index >= param_cnt_) {LOG_ERROR << "index too large: " << index;return;}param_bind_[index].buffer_type = MYSQL_TYPE_LONG;param_bind_[index].buffer = &value;
}void CPrepareStatement::SetParam(uint32_t index, string &value) {if (index >= param_cnt_) {LOG_ERROR << "index too large: " << index;return;}param_bind_[index].buffer_type = MYSQL_TYPE_STRING;param_bind_[index].buffer = (char *)value.c_str();param_bind_[index].buffer_length = value.size();
}void CPrepareStatement::SetParam(uint32_t index, const string &value) {if (index >= param_cnt_) {LOG_ERROR << "index too large: " << index;return;}param_bind_[index].buffer_type = MYSQL_TYPE_STRING;param_bind_[index].buffer = (char *)value.c_str();param_bind_[index].buffer_length = value.size();
}bool CPrepareStatement::ExecuteUpdate() {if (!stmt_) {LOG_ERROR << "no m_stmt"; return false;}if (mysql_stmt_bind_param(stmt_, param_bind_)) {LOG_ERROR << "mysql_stmt_bind_param failed: " << mysql_stmt_error(stmt_);return false;}if (mysql_stmt_execute(stmt_)) {LOG_ERROR << "mysql_stmt_execute failed: " << mysql_stmt_error(stmt_);return false;}if (mysql_stmt_affected_rows(stmt_) == 0) {LOG_ERROR << "ExecuteUpdate have no effect"; return false;}return true;
}uint32_t CPrepareStatement::GetInsertId() {return mysql_stmt_insert_id(stmt_);
}/////////////////////
CDBConn::CDBConn(CDBPool *pPool) {db_pool_ = pPool;mysql_ = NULL;
}CDBConn::~CDBConn() {if (mysql_) {mysql_close(mysql_);}
}int CDBConn::Init() {mysql_ = mysql_init(NULL); // mysql_标准的mysql c client对应的apiif (!mysql_) {LOG_ERROR << "mysql_init failed"; return 1;}int reconnect = 1;// mysql_options(mysql_, MYSQL_OPT_RECONNECT, &reconnect); // 配合mysql_ping实现自动重连mysql_options(mysql_, MYSQL_SET_CHARSET_NAME, "utf8mb4"); // utf8mb4和utf8区别// ip 端口 用户名 密码 数据库名if (!mysql_real_connect(mysql_, db_pool_->GetDBServerIP(),db_pool_->GetUsername(), db_pool_->GetPasswrod(),db_pool_->GetDBName(), db_pool_->GetDBServerPort(),NULL, 0)) {LOG_ERROR << "mysql_real_connect failed: " << mysql_error(mysql_);return 2;}return 0;
}const char *CDBConn::GetPoolName() { return db_pool_->GetPoolName(); }bool CDBConn::ExecuteCreate(const char *sql_query) {mysql_ping(mysql_);// mysql_real_query 实际就是执行了SQLif (mysql_real_query(mysql_, sql_query, strlen(sql_query))) {LOG_ERROR << "mysql_real_query failed: " << mysql_error(mysql_); return false;}return true;
}bool CDBConn::ExecutePassQuery(const char *sql_query) {mysql_ping(mysql_);// mysql_real_query 实际就是执行了SQLif (mysql_real_query(mysql_, sql_query, strlen(sql_query))) {LOG_ERROR << "mysql_real_query failed: " << mysql_error(mysql_); return false;}return true;
}bool CDBConn::ExecuteDrop(const char *sql_query) {mysql_ping(mysql_); // 如果断开了,能够自动重连if (mysql_real_query(mysql_, sql_query, strlen(sql_query))) {LOG_ERROR << "mysql_real_query failed: " << mysql_error(mysql_); return false;}return true;
}CResultSet *CDBConn::ExecuteQuery(const char *sql_query) {mysql_ping(mysql_);row_num = 0;if (mysql_real_query(mysql_, sql_query, strlen(sql_query))) {LOG_ERROR << "mysql_real_query failed: " << mysql_error(mysql_) << ", sql:" << sql_query;return NULL;}// 返回结果MYSQL_RES *res = mysql_store_result(mysql_); // 返回结果 https://www.mysqlzh.com/api/66.htmlif (!res) // 如果查询未返回结果集和读取结果集失败都会返回NULL{LOG_ERROR << "mysql_store_result failed: " << mysql_error(mysql_);return NULL;}row_num = mysql_num_rows(res);// LOG_INFO << "row_num: " << row_num;CResultSet *result_set = new CResultSet(res); // 存储到CResultSetreturn result_set;
}/*
1.执行成功,则返回受影响的行的数目,如果最近一次查询失败的话,函数返回 -12.对于delete,将返回实际删除的行数.3.对于update,如果更新的列值原值和新值一样,如update tables set col1=10 where
id=1; id=1该条记录原值就是10的话,则返回0。mysql_affected_rows返回的是实际更新的行数,而不是匹配到的行数。
*/
bool CDBConn::ExecuteUpdate(const char *sql_query, bool care_affected_rows) {mysql_ping(mysql_);if (mysql_real_query(mysql_, sql_query, strlen(sql_query))) {LOG_ERROR << "mysql_real_query failed: " << mysql_error(mysql_) << ", sql:" << sql_query;return false;}if (mysql_affected_rows(mysql_) > 0) {return true;} else { // 影响的行数为0时if (care_affected_rows) { // 如果在意影响的行数时, 返回false,否则返回true LOG_ERROR << "mysql_real_query failed: " << mysql_error(mysql_) << ", sql:" << sql_query;return false;} else {LOG_WARN << "affected_rows=0, sql: " << sql_query;return true;}}
}bool CDBConn::StartTransaction() {mysql_ping(mysql_);if (mysql_real_query(mysql_, "start transaction\n", 17)) {LOG_ERROR << "mysql_real_query failed: " << mysql_error(mysql_) << " start transaction failed";return false;}return true;
}bool CDBConn::Rollback() {mysql_ping(mysql_);if (mysql_real_query(mysql_, "rollback\n", 8)) {LOG_ERROR << "mysql_real_query failed: " << mysql_error(mysql_) << ", sql: rollback";return false;}return true;
}bool CDBConn::Commit() {mysql_ping(mysql_);if (mysql_real_query(mysql_, "commit\n", 6)) {LOG_ERROR << "mysql_real_query failed: " << mysql_error(mysql_) << ", sql: commit";return false;}return true;
}
uint32_t CDBConn::GetInsertId() { return (uint32_t)mysql_insert_id(mysql_); }////////////////
CDBPool::CDBPool(const char *pool_name, const char *db_server_ip,uint16_t db_server_port, const char *username,const char *password, const char *db_name, int max_conn_cnt) {pool_name_ = pool_name;db_server_ip_ = db_server_ip;db_server_port_ = db_server_port;username_ = username;password_ = password;db_name_ = db_name;db_max_conn_cnt_ = max_conn_cnt; //db_cur_conn_cnt_ = MIN_DB_CONN_CNT; // 最小连接数量
}// 释放连接池
CDBPool::~CDBPool() {std::lock_guard<std::mutex> lock(mutex_);abort_request_ = true;cond_var_.notify_all(); // 通知所有在等待的for (list<CDBConn *>::iterator it = free_list_.begin();it != free_list_.end(); it++) {CDBConn *pConn = *it;delete pConn;}free_list_.clear();
}int CDBPool::Init() {// 创建固定最小的连接数量for (int i = 0; i < db_cur_conn_cnt_; i++) {CDBConn *db_conn = new CDBConn(this);int ret = db_conn->Init();if (ret) {delete db_conn;return ret;}free_list_.push_back(db_conn);}// log_info("db pool: %s, size: %d\n", m_pool_name.c_str(),// (int)free_list_.size());return 0;
}/**TODO:*增加保护机制,把分配的连接加入另一个队列,这样获取连接时,如果没有空闲连接,*TODO:*检查已经分配的连接多久没有返回,如果超过一定时间,则自动收回连接,放在用户忘了调用释放连接的接口* timeout_ms默认为 0死等* timeout_ms >0 则为等待的时间*/
CDBConn *CDBPool::GetDBConn(const int timeout_ms) {std::unique_lock<std::mutex> lock(mutex_);if (abort_request_) {LOG_WARN << "have aboort"; return NULL;}if (free_list_.empty()) // 2 当没有连接可以用时{// 第一步先检测 当前连接数量是否达到最大的连接数量if (db_cur_conn_cnt_ >= db_max_conn_cnt_) // 等待的逻辑{// 如果已经到达了,看看是否需要超时等待if (timeout_ms <= 0) // 死等,直到有连接可以用 或者 连接池要退出{cond_var_.wait(lock, [this] {// 当前连接数量小于最大连接数量 或者请求释放连接池时退出return (!free_list_.empty()) | abort_request_;});} else {// return如果返回 false,继续wait(或者超时),// 如果返回true退出wait 1.m_free_list不为空 2.超时退出// 3. m_abort_request被置为true,要释放整个连接池cond_var_.wait_for(lock, std::chrono::milliseconds(timeout_ms),[this] { return (!free_list_.empty()) | abort_request_; });// 带超时功能时还要判断是否为空if (free_list_.empty()) // 如果连接池还是没有空闲则退出{return NULL;}}if (abort_request_) {LOG_WARN << "have abort"; return NULL;}} else // 还没有到最大连接则创建连接{CDBConn *db_conn = new CDBConn(this); //新建连接int ret = db_conn->Init();if (ret) {LOG_ERROR << "Init DBConnecton failed"; delete db_conn;return NULL;} else {free_list_.push_back(db_conn);db_cur_conn_cnt_++;// log_info("new db connection: %s, conn_cnt: %d\n",// m_pool_name.c_str(), m_db_cur_conn_cnt);}}}CDBConn *pConn = free_list_.front(); // 获取连接free_list_.pop_front(); // STL 吐出连接,从空闲队列删除return pConn;
}void CDBPool::RelDBConn(CDBConn *pConn) {std::lock_guard<std::mutex> lock(mutex_);list<CDBConn *>::iterator it = free_list_.begin();for (; it != free_list_.end(); it++) // 避免重复归还{if (*it == pConn) {break;}}if (it == free_list_.end()) {// used_list_.remove(pConn);free_list_.push_back(pConn);cond_var_.notify_one(); // 通知取队列} else {LOG_WARN << "RelDBConn failed"; // 不再次回收连接}
}
// 遍历检测是否超时未归还
// pConn->isTimeout(); // 当前时间 - 被请求的时间
// 强制回收 从m_used_list 放回 free_list_/////////////////
CDBManager::CDBManager() {}CDBManager::~CDBManager() {}CDBManager *CDBManager::getInstance() {if (!s_db_manager) {s_db_manager = new CDBManager();if (s_db_manager->Init()) {delete s_db_manager;s_db_manager = NULL;}}return s_db_manager;
}void CDBManager::SetConfPath(const char *conf_path)
{conf_path_ = conf_path;
}int CDBManager::Init() {LOG_INFO << "Init";CConfigFileReader config_file(conf_path_.c_str());char *db_instances = config_file.GetConfigName("DBInstances");if (!db_instances) {LOG_ERROR << "not configure DBInstances"; return 1;}char host[64];char port[64];char dbname[64];char username[64];char password[64];char maxconncnt[64];CStrExplode instances_name(db_instances, ',');for (uint32_t i = 0; i < instances_name.GetItemCnt(); i++) {char *pool_name = instances_name.GetItem(i);snprintf(host, 64, "%s_host", pool_name);snprintf(port, 64, "%s_port", pool_name);snprintf(dbname, 64, "%s_dbname", pool_name);snprintf(username, 64, "%s_username", pool_name);snprintf(password, 64, "%s_password", pool_name);snprintf(maxconncnt, 64, "%s_maxconncnt", pool_name);char *db_host = config_file.GetConfigName(host);char *str_db_port = config_file.GetConfigName(port);char *db_dbname = config_file.GetConfigName(dbname);char *db_username = config_file.GetConfigName(username);char *db_password = config_file.GetConfigName(password);char *str_maxconncnt = config_file.GetConfigName(maxconncnt);LOG_INFO << "db_host: " << db_host << ", db_port:" << str_db_port << ", db_dbname:" << db_dbname << ", db_username:" << db_username << ", db_password: " << db_password;if (!db_host || !str_db_port || !db_dbname || !db_username ||!db_password || !str_maxconncnt) {LOG_ERROR << "not configure db instance: " << pool_name;return 2;}int db_port = atoi(str_db_port);int db_maxconncnt = atoi(str_maxconncnt);CDBPool *pDBPool = new CDBPool(pool_name, db_host, db_port, db_username,db_password, db_dbname, db_maxconncnt);if (pDBPool->Init()) {LOG_ERROR << "init db instance failed: " << pool_name;return 3;}dbpool_map_.insert(make_pair(pool_name, pDBPool));}return 0;
}
//1. 先找连接池 2.从连接池获取连接
CDBConn *CDBManager::GetDBConn(const char *dbpool_name) {map<string, CDBPool *>::iterator it = dbpool_map_.find(dbpool_name); // 主从if (it == dbpool_map_.end()) {return NULL;} else {return it->second->GetDBConn();}
}void CDBManager::RelDBConn(CDBConn *pConn) {if (!pConn) {return;}map<string, CDBPool *>::iterator it = dbpool_map_.find(pConn->GetPoolName());if (it != dbpool_map_.end()) {it->second->RelDBConn(pConn);}
}
redis
cache_pool.h
/** @Author: your name* @Date: 2019-12-07 10:54:57* @LastEditTime : 2020-01-10 16:35:13* @LastEditors : Please set LastEditors* @Description: In User Settings Edit* @FilePath: \src\cache_pool\cache_pool.h*/
#ifndef CACHEPOOL_H_
#define CACHEPOOL_H_#include <condition_variable>
#include <iostream>
#include <list>
#include <map>
#include <mutex>
#include <vector>#include "hiredis.h"using std::list;
using std::map;
using std::string;
using std::vector;#define REDIS_COMMAND_SIZE 300 /* redis Command 指令最大长度 */
#define FIELD_ID_SIZE 100 /* redis hash表field域字段长度 */
#define VALUES_ID_SIZE 1024 /* redis value域字段长度 */
typedef char (*RFIELDS)[FIELD_ID_SIZE]; /* redis hash表存放批量field字符串数组类型 *///数组指针类型,其变量指向 char[1024]
typedef char (*RVALUES)[VALUES_ID_SIZE]; /* redis 表存放批量value字符串数组类型 */class CachePool;class CacheConn {public:CacheConn(const char *server_ip, int server_port, int db_index,const char *password, const char *pool_name = "");CacheConn(CachePool *pCachePool);virtual ~CacheConn();int Init();void DeInit();const char *GetPoolName();// 通用操作// 判断一个key是否存在bool IsExists(string &key);// 删除某个keylong Del(string key);// ------------------- 字符串相关 -------------------string Get(string key);string Set(string key, string value);string SetEx(string key, int timeout, string value);// string mset(string key, map);//批量获取bool MGet(const vector<string> &keys, map<string, string> &ret_value);//原子加减1int Incr(string key, int64_t &value);int Decr(string key, int64_t &value);// ---------------- 哈希相关 ------------------------long Hdel(string key, string field);string Hget(string key, string field);int Hget(string key, char *field, char *value);bool HgetAll(string key, map<string, string> &ret_value);long Hset(string key, string field, string value);long HincrBy(string key, string field, long value);long IncrBy(string key, long value);string Hmset(string key, map<string, string> &hash);bool Hmget(string key, list<string> &fields, list<string> &ret_value);// ------------ 链表相关 ------------long Lpush(string key, string value);long Rpush(string key, string value);long Llen(string key);bool Lrange(string key, long start, long end, list<string> &ret_value);// zset 相关int ZsetExit(string key, string member);int ZsetAdd(string key, long score, string member);int ZsetZrem(string key, string member);int ZsetIncr(string key, string member);int ZsetZcard(string key);int ZsetZrevrange(string key, int from_pos, int end_pos, RVALUES values,int &get_num);int ZsetGetScore(string key, string member);bool FlushDb();private:CachePool *cache_pool_;redisContext *context_; // 每个redis连接 redisContext redis客户端编程的对象uint64_t last_connect_time_;uint16_t server_port_;string server_ip_;string password_;uint16_t db_index_;string pool_name_;
};class CachePool {public:// db_index和mysql不同的地方CachePool(const char *pool_name, const char *server_ip, int server_port,int db_index, const char *password, int max_conn_cnt);virtual ~CachePool();int Init();// 获取空闲的连接资源CacheConn *GetCacheConn(const int timeout_ms = 0);// Pool回收连接资源void RelCacheConn(CacheConn *cache_conn);const char *GetPoolName() { return pool_name_.c_str(); }const char *GetServerIP() { return server_ip_.c_str(); }const char *GetPassword() { return password_.c_str(); }int GetServerPort() { return m_server_port; }int GetDBIndex() { return db_index_; }private:string pool_name_;string server_ip_;string password_;int m_server_port;int db_index_; // mysql 数据库名字, redis db indexint cur_conn_cnt_;int max_conn_cnt_;list<CacheConn *> free_list_;std::mutex m_mutex;std::condition_variable cond_var_;bool abort_request_ = false;
};class CacheManager {public:virtual ~CacheManager();/// @brief /// @param conf_path static void SetConfPath(const char *conf_path);static CacheManager *getInstance();int Init();CacheConn *GetCacheConn(const char *pool_name);void RelCacheConn(CacheConn *cache_conn);private:CacheManager();private:static CacheManager *s_cache_manager;map<string, CachePool *> m_cache_pool_map;static std::string conf_path_;
};class AutoRelCacheCon {public:AutoRelCacheCon(CacheManager *manger, CacheConn *conn): manger_(manger), conn_(conn) {}~AutoRelCacheCon() {if (manger_) {manger_->RelCacheConn(conn_);}} //在析构函数规划private:CacheManager *manger_ = NULL;CacheConn *conn_ = NULL;
};#define AUTO_REL_CACHECONN(m, c) AutoRelCacheCon autorelcacheconn(m, c)#endif /* CACHEPOOL_H_ */
cache_pool.cc
#include "cache_pool.h"#include "util.h"
#include <stdlib.h>
#include <string.h>
#define log_error printf
#define log_info printf
#define log_warn printf
// #define log printf
#define MIN_CACHE_CONN_CNT 2
#define MAX_CACHE_CONN_FAIL_NUM 10#include "muduo/base/Logging.h"#include "config_file_reader.h"CacheManager *CacheManager::s_cache_manager = NULL;
std::string CacheManager::conf_path_ = "tc_http_server.conf"; // 默认
CacheConn::CacheConn(const char *server_ip, int server_port, int db_index,const char *password, const char *pool_name) {server_ip_ = server_ip;server_port_ = server_port;db_index_ = db_index;password_ = password;pool_name_ = pool_name;context_ = NULL;last_connect_time_ = 0;
}CacheConn::CacheConn(CachePool *pCachePool) {cache_pool_ = pCachePool;if (pCachePool) {server_ip_ = pCachePool->GetServerIP();server_port_ = pCachePool->GetServerPort();db_index_ = pCachePool->GetDBIndex();password_ = pCachePool->GetPassword();pool_name_ = pCachePool->GetPoolName();} else {log_error("pCachePool is NULL\n");}context_ = NULL;last_connect_time_ = 0;
}CacheConn::~CacheConn() {if (context_) {redisFree(context_);context_ = NULL;}
}/** redis初始化连接和重连操作,类似mysql_ping()*/
int CacheConn::Init() {if (context_) // 非空,连接是正常的{return 0;}// 1s 尝试重连一次uint64_t cur_time = (uint64_t)time(NULL);if (cur_time < last_connect_time_ + 1) // 重连尝试 间隔1秒{printf("cur_time:%lu, m_last_connect_time:%lu\n", cur_time,last_connect_time_);return 1;}// printf("m_last_connect_time = cur_time\n");last_connect_time_ = cur_time;// 1000ms超时struct timeval timeout = {0, 1000000};// 建立连接后使用 redisContext 来保存连接状态。// redisContext 在每次操作后会修改其中的 err 和 errstr// 字段来表示发生的错误码(大于0)和对应的描述。context_ =redisConnectWithTimeout(server_ip_.c_str(), server_port_, timeout);if (!context_ || context_->err) {if (context_) {log_error("redisConnect failed: %s\n", context_->errstr);redisFree(context_);context_ = NULL;} else {log_error("redisConnect failed\n");}return 1;}redisReply *reply;// 验证if (!password_.empty()) {reply =(redisReply *)redisCommand(context_, "AUTH %s", password_.c_str());if (!reply || reply->type == REDIS_REPLY_ERROR) {log_error("Authentication failure:%p\n", reply);if (reply)freeReplyObject(reply);return -1;} else {// log_info("Authentication success\n");}freeReplyObject(reply);}reply = (redisReply *)redisCommand(context_, "SELECT %d", 0);if (reply && (reply->type == REDIS_REPLY_STATUS) &&(strncmp(reply->str, "OK", 2) == 0)) {freeReplyObject(reply);return 0;} else {if (reply)log_error("select cache db failed:%s\n", reply->str);return 2;}
}void CacheConn::DeInit() {if (context_) {redisFree(context_);context_ = NULL;}
}const char *CacheConn::GetPoolName() { return pool_name_.c_str(); }string CacheConn::Get(string key) {string value;if (Init()) {return value;}redisReply *reply =(redisReply *)redisCommand(context_, "GET %s", key.c_str());if (!reply) {log_error("redisCommand failed:%s\n", context_->errstr);redisFree(context_);context_ = NULL;return value;}if (reply->type == REDIS_REPLY_STRING) {value.append(reply->str, reply->len);}freeReplyObject(reply);return value;
}string CacheConn::Set(string key, string value) {string ret_value;if (Init()) {return ret_value;}// 返回的结果存放在redisReplyredisReply *reply = (redisReply *)redisCommand(context_, "SET %s %s",key.c_str(), value.c_str());if (!reply) {log_error("redisCommand failed:%s\n", context_->errstr);redisFree(context_);context_ = NULL;return ret_value;}ret_value.append(reply->str, reply->len);freeReplyObject(reply); // 释放资源return ret_value;
}string CacheConn::SetEx(string key, int timeout, string value) {string ret_value;if (Init()) {return ret_value;}redisReply *reply = (redisReply *)redisCommand(context_, "SETEX %s %d %s", key.c_str(), timeout, value.c_str());if (!reply) {log_error("redisCommand failed:%s\n", context_->errstr);redisFree(context_);context_ = NULL;return ret_value;}ret_value.append(reply->str, reply->len);freeReplyObject(reply);return ret_value;
}bool CacheConn::MGet(const vector<string> &keys,map<string, string> &ret_value) {if (Init()) {return false;}if (keys.empty()) {return false;}string strKey;bool bFirst = true;for (vector<string>::const_iterator it = keys.begin(); it != keys.end();++it) {if (bFirst) {bFirst = false;strKey = *it;} else {strKey += " " + *it;}}if (strKey.empty()) {return false;}strKey = "MGET " + strKey;redisReply *reply = (redisReply *)redisCommand(context_, strKey.c_str());if (!reply) {log_info("redisCommand failed:%s\n", context_->errstr);redisFree(context_);context_ = NULL;return false;}if (reply->type == REDIS_REPLY_ARRAY) {for (size_t i = 0; i < reply->elements; ++i) {redisReply *child_reply = reply->element[i];if (child_reply->type == REDIS_REPLY_STRING) {ret_value[keys[i]] = child_reply->str;}}}freeReplyObject(reply);return true;
}bool CacheConn::IsExists(string &key) {if (Init()) {return false;}redisReply *reply =(redisReply *)redisCommand(context_, "EXISTS %s", key.c_str());if (!reply) {log_error("redisCommand failed:%s\n", context_->errstr);redisFree(context_);context_ = NULL;return false;}long ret_value = reply->integer;freeReplyObject(reply);if (0 == ret_value) {return false;} else {return true;}
}long CacheConn::Del(string key) {if (Init()) {return 0;}redisReply *reply =(redisReply *)redisCommand(context_, "DEL %s", key.c_str());if (!reply) {log_error("redisCommand failed:%s\n", context_->errstr);redisFree(context_);context_ = NULL;return 0;}long ret_value = reply->integer;freeReplyObject(reply);return ret_value;
}long CacheConn::Hdel(string key, string field) {if (Init()) {return -1;}redisReply *reply = (redisReply *)redisCommand(context_, "HDEL %s %s",key.c_str(), field.c_str());if (!reply) {log_error("redisCommand failed:%s\n", context_->errstr);redisFree(context_);context_ = NULL;return -1;}long ret_value = reply->integer;freeReplyObject(reply);return ret_value;
}string CacheConn::Hget(string key, string field) {string ret_value;if (Init()) {return ret_value;}redisReply *reply = (redisReply *)redisCommand(context_, "HGET %s %s",key.c_str(), field.c_str());if (!reply) {log_error("redisCommand failed:%s\n", context_->errstr);redisFree(context_);context_ = NULL;return ret_value;}if (reply->type == REDIS_REPLY_STRING) {ret_value.append(reply->str, reply->len);}freeReplyObject(reply);return ret_value;
}
int CacheConn::Hget(string key, char *field, char *value) {int retn = 0;int len = 0;if (Init()) {return -1;}redisReply *reply =(redisReply *)redisCommand(context_, "hget %s %s", key.c_str(), field);if (reply == NULL || reply->type != REDIS_REPLY_STRING) {printf("hget %s %s error %s\n", key.c_str(), field, context_->errstr);retn = -1;goto END;}len = reply->len > VALUES_ID_SIZE ? VALUES_ID_SIZE : reply->len;strncpy(value, reply->str, len);value[len] = '\0';END:freeReplyObject(reply);return retn;
}
bool CacheConn::HgetAll(string key, map<string, string> &ret_value) {if (Init()) {return false;}redisReply *reply =(redisReply *)redisCommand(context_, "HGETALL %s", key.c_str());if (!reply) {log_error("redisCommand failed:%s\n", context_->errstr);redisFree(context_);context_ = NULL;return false;}if ((reply->type == REDIS_REPLY_ARRAY) && (reply->elements % 2 == 0)) {for (size_t i = 0; i < reply->elements; i += 2) {redisReply *field_reply = reply->element[i];redisReply *value_reply = reply->element[i + 1];string field(field_reply->str, field_reply->len);string value(value_reply->str, value_reply->len);ret_value.insert(make_pair(field, value));}}freeReplyObject(reply);return true;
}long CacheConn::Hset(string key, string field, string value) {if (Init()) {return -1;}redisReply *reply = (redisReply *)redisCommand(context_, "HSET %s %s %s", key.c_str(), field.c_str(), value.c_str());if (!reply) {log_error("redisCommand failed:%s\n", context_->errstr);redisFree(context_);context_ = NULL;return -1;}long ret_value = reply->integer;freeReplyObject(reply);return ret_value;
}long CacheConn::HincrBy(string key, string field, long value) {if (Init()) {return -1;}redisReply *reply = (redisReply *)redisCommand(context_, "HINCRBY %s %s %ld", key.c_str(), field.c_str(), value);if (!reply) {log_error("redisCommand failed:%s\n", context_->errstr);redisFree(context_);context_ = NULL;return -1;}long ret_value = reply->integer;freeReplyObject(reply);return ret_value;
}long CacheConn::IncrBy(string key, long value) {if (Init()) {return -1;}redisReply *reply = (redisReply *)redisCommand(context_, "INCRBY %s %ld",key.c_str(), value);if (!reply) {log_error("redis Command failed:%s\n", context_->errstr);redisFree(context_);context_ = NULL;return -1;}long ret_value = reply->integer;freeReplyObject(reply);return ret_value;
}string CacheConn::Hmset(string key, map<string, string> &hash) {string ret_value;if (Init()) {return ret_value;}int argc = hash.size() * 2 + 2;const char **argv = new const char *[argc];if (!argv) {return ret_value;}argv[0] = "HMSET";argv[1] = key.c_str();int i = 2;for (map<string, string>::iterator it = hash.begin(); it != hash.end();it++) {argv[i++] = it->first.c_str();argv[i++] = it->second.c_str();}redisReply *reply =(redisReply *)redisCommandArgv(context_, argc, argv, NULL);if (!reply) {log_error("redisCommand failed:%s\n", context_->errstr);delete[] argv;redisFree(context_);context_ = NULL;return ret_value;}ret_value.append(reply->str, reply->len);delete[] argv;freeReplyObject(reply);return ret_value;
}bool CacheConn::Hmget(string key, list<string> &fields,list<string> &ret_value) {if (Init()) {return false;}int argc = fields.size() + 2;const char **argv = new const char *[argc];if (!argv) {return false;}argv[0] = "HMGET";argv[1] = key.c_str();int i = 2;for (list<string>::iterator it = fields.begin(); it != fields.end(); it++) {argv[i++] = it->c_str();}redisReply *reply = (redisReply *)redisCommandArgv(context_, argc, (const char **)argv, NULL);if (!reply) {log_error("redisCommand failed:%s\n", context_->errstr);delete[] argv;redisFree(context_);context_ = NULL;return false;}if (reply->type == REDIS_REPLY_ARRAY) {for (size_t i = 0; i < reply->elements; i++) {redisReply *value_reply = reply->element[i];string value(value_reply->str, value_reply->len);ret_value.push_back(value);}}delete[] argv;freeReplyObject(reply);return true;
}int CacheConn::Incr(string key, int64_t &value) {value = 0;if (Init()) {return -1;}redisReply *reply =(redisReply *)redisCommand(context_, "INCR %s", key.c_str());if (!reply) {log_error("redis Command failed:%s\n", context_->errstr);redisFree(context_);context_ = NULL;return -1;}value = reply->integer;freeReplyObject(reply);return 0;
}int CacheConn::Decr(string key, int64_t &value) {if (Init()) {return -1;}redisReply *reply =(redisReply *)redisCommand(context_, "DECR %s", key.c_str());if (!reply) {log_error("redis Command failed:%s\n", context_->errstr);redisFree(context_);context_ = NULL;return -1;}value = reply->integer;freeReplyObject(reply);return 0;
}long CacheConn::Lpush(string key, string value) {if (Init()) {return -1;}redisReply *reply = (redisReply *)redisCommand(context_, "LPUSH %s %s",key.c_str(), value.c_str());if (!reply) {log_error("redisCommand failed:%s\n", context_->errstr);redisFree(context_);context_ = NULL;return -1;}long ret_value = reply->integer;freeReplyObject(reply);return ret_value;
}long CacheConn::Rpush(string key, string value) {if (Init()) {return -1;}redisReply *reply = (redisReply *)redisCommand(context_, "RPUSH %s %s",key.c_str(), value.c_str());if (!reply) {log_error("redisCommand failed:%s\n", context_->errstr);redisFree(context_);context_ = NULL;return -1;}long ret_value = reply->integer;freeReplyObject(reply);return ret_value;
}long CacheConn::Llen(string key) {if (Init()) {return -1;}redisReply *reply =(redisReply *)redisCommand(context_, "LLEN %s", key.c_str());if (!reply) {log_error("redisCommand failed:%s\n", context_->errstr);redisFree(context_);context_ = NULL;return -1;}long ret_value = reply->integer;freeReplyObject(reply);return ret_value;
}bool CacheConn::Lrange(string key, long start, long end,list<string> &ret_value) {if (Init()) {return false;}redisReply *reply = (redisReply *)redisCommand(context_, "LRANGE %s %d %d",key.c_str(), start, end);if (!reply) {log_error("redisCommand failed:%s\n", context_->errstr);redisFree(context_);context_ = NULL;return false;}if (reply->type == REDIS_REPLY_ARRAY) {for (size_t i = 0; i < reply->elements; i++) {redisReply *value_reply = reply->element[i];string value(value_reply->str, value_reply->len);ret_value.push_back(value);}}freeReplyObject(reply);return true;
}int CacheConn::ZsetExit(string key, string member) {int retn = 0;redisReply *reply = NULL;if (Init()) {return -1;}//执行命令reply =(redisReply *)redisCommand(context_, "zlexcount %s [%s [%s",key.c_str(), member.c_str(), member.c_str());if (reply->type != REDIS_REPLY_INTEGER) {log_error("zlexcount: %s,member: %s Error:%s,%s\n", key.c_str(),member.c_str(), reply->str, context_->errstr);retn = -1;goto END;}retn = reply->integer;END:freeReplyObject(reply);return retn;
}int CacheConn::ZsetAdd(string key, long score, string member) {int retn = 0;redisReply *reply = NULL;if (Init()) {LOG_ERROR << "Init() -> failed";return -1;}//执行命令, reply->integer成功返回1,reply->integer失败返回0reply = (redisReply *)redisCommand(context_, "ZADD %s %ld %s", key.c_str(),score, member.c_str());// rop_test_reply_type(reply);if (reply->type != REDIS_REPLY_INTEGER) {printf("ZADD: %s,member: %s Error:%s,%s, reply->integer:%lld, %d\n",key.c_str(), member.c_str(), reply->str, context_->errstr,reply->integer, reply->type);retn = -1;goto END;}END:freeReplyObject(reply);return retn;
}int CacheConn::ZsetZrem(string key, string member) {int retn = 0;redisReply *reply = NULL;if (Init()) {LOG_ERROR << "Init() -> failed";return -1;}//执行命令, reply->integer成功返回1,reply->integer失败返回0reply = (redisReply *)redisCommand(context_, "ZREM %s %s", key.c_str(),member.c_str());if (reply->type != REDIS_REPLY_INTEGER) {printf("ZREM: %s,member: %s Error:%s,%s\n", key.c_str(), member.c_str(),reply->str, context_->errstr);retn = -1;goto END;}
END:freeReplyObject(reply);return retn;
}
int CacheConn::ZsetIncr(string key, string member) {int retn = 0;redisReply *reply = NULL;if (Init()) {return false;}reply = (redisReply *)redisCommand(context_, "ZINCRBY %s 1 %s", key.c_str(),member.c_str());// rop_test_reply_type(reply);if (strcmp(reply->str, "OK") != 0) {printf("Add or increment table: %s,member: %s Error:%s,%s\n",key.c_str(), member.c_str(), reply->str, context_->errstr);retn = -1;goto END;}END:freeReplyObject(reply);return retn;
}int CacheConn::ZsetZcard(string key) {redisReply *reply = NULL;if (Init()) {return -1;}int cnt = 0;reply = (redisReply *)redisCommand(context_, "ZCARD %s", key.c_str());if (reply->type != REDIS_REPLY_INTEGER) {printf("ZCARD %s error %s\n", key.c_str(), context_->errstr);cnt = -1;goto END;}cnt = reply->integer;END:freeReplyObject(reply);return cnt;
}
int CacheConn::ZsetZrevrange(string key, int from_pos, int end_pos,RVALUES values, int &get_num) {int retn = 0;redisReply *reply = NULL;if (Init()) {return -1;}int i = 0;int max_count = 0;int count = end_pos - from_pos + 1; //请求元素个数//降序获取有序集合的元素reply = (redisReply *)redisCommand(context_, "ZREVRANGE %s %d %d",key.c_str(), from_pos, end_pos);if (reply->type != REDIS_REPLY_ARRAY) //如果返回不是数组{printf("ZREVRANGE %s error!%s\n", key.c_str(), context_->errstr);retn = -1;goto END;}//返回一个数组,查看elements的值(数组个数)//通过element[index] 的方式访问数组元素//每个数组元素是一个redisReply对象的指针max_count = (reply->elements > count) ? count : reply->elements;get_num = max_count; //得到结果value的个数for (i = 0; i < max_count; ++i) {strncpy(values[i], reply->element[i]->str, VALUES_ID_SIZE - 1);values[i][VALUES_ID_SIZE - 1] = 0; //结束符}END:if (reply != NULL) {freeReplyObject(reply);}return retn;
}int CacheConn::ZsetGetScore(string key, string member) {if (Init()) {return -1;}int score = 0;redisReply *reply = NULL;reply = (redisReply *)redisCommand(context_, "ZSCORE %s %s", key.c_str(),member.c_str());if (reply->type != REDIS_REPLY_STRING) {printf("[-][GMS_REDIS]ZSCORE %s %s error %s\n", key.c_str(),member.c_str(), context_->errstr);score = -1;goto END;}score = atoi(reply->str);END:freeReplyObject(reply);return score;
}bool CacheConn::FlushDb() {bool ret = false;if (Init()) {return false;}redisReply *reply = (redisReply *)redisCommand(context_, "FLUSHDB");if (!reply) {log_error("redisCommand failed:%s\n", context_->errstr);redisFree(context_);context_ = NULL;return false;}if (reply->type == REDIS_REPLY_STRING &&strncmp(reply->str, "OK", 2) == 0) {ret = true;}freeReplyObject(reply);return ret;
}
///////////////
CachePool::CachePool(const char *pool_name, const char *server_ip,int server_port, int db_index, const char *password,int max_conn_cnt) {pool_name_ = pool_name;server_ip_ = server_ip;m_server_port = server_port;db_index_ = db_index;password_ = password;max_conn_cnt_ = max_conn_cnt;cur_conn_cnt_ = MIN_CACHE_CONN_CNT;
}CachePool::~CachePool() {{std::lock_guard<std::mutex> lock(m_mutex);abort_request_ = true;cond_var_.notify_all(); // 通知所有在等待的}{std::lock_guard<std::mutex> lock(m_mutex);for (list<CacheConn *>::iterator it = free_list_.begin();it != free_list_.end(); it++) {CacheConn *pConn = *it;delete pConn;}}free_list_.clear();cur_conn_cnt_ = 0;
}int CachePool::Init() {for (int i = 0; i < cur_conn_cnt_; i++) {CacheConn *pConn =new CacheConn(server_ip_.c_str(), m_server_port, db_index_,password_.c_str(), pool_name_.c_str());if (pConn->Init()) {delete pConn;return 1;}free_list_.push_back(pConn);}log_info("cache pool: %s, list size: %lu\n", pool_name_.c_str(),free_list_.size());return 0;
}CacheConn *CachePool::GetCacheConn(const int timeout_ms) {std::unique_lock<std::mutex> lock(m_mutex);if (abort_request_) {log_info("have aboort\n");return NULL;}if (free_list_.empty()) // 2 当没有连接可以用时{// 第一步先检测 当前连接数量是否达到最大的连接数量if (cur_conn_cnt_ >= max_conn_cnt_) // 等待的逻辑{// 如果已经到达了,看看是否需要超时等待if (timeout_ms <= 0) // 死等,直到有连接可以用 或者 连接池要退出{log_info("wait ms:%d\n", timeout_ms);cond_var_.wait(lock, [this] {// 当前连接数量小于最大连接数量 或者请求释放连接池时退出return (!free_list_.empty()) | abort_request_;});} else {// return如果返回 false,继续wait(或者超时),// 如果返回true退出wait 1.m_free_list不为空 2.超时退出// 3. m_abort_request被置为true,要释放整个连接池cond_var_.wait_for(lock, std::chrono::milliseconds(timeout_ms),[this] { return (!free_list_.empty()) | abort_request_; });// 带超时功能时还要判断是否为空if (free_list_.empty()) // 如果连接池还是没有空闲则退出{return NULL;}}if (abort_request_) {log_warn("have aboort\n");return NULL;}} else // 还没有到最大连接则创建连接{CacheConn *db_conn =new CacheConn(server_ip_.c_str(), m_server_port, db_index_,password_.c_str(), pool_name_.c_str()); //新建连接int ret = db_conn->Init();if (ret) {log_error("Init DBConnecton failed\n\n");delete db_conn;return NULL;} else {free_list_.push_back(db_conn);cur_conn_cnt_++;// log_info("new db connection: %s, conn_cnt: %d\n",// m_pool_name.c_str(), m_cur_conn_cnt);}}}CacheConn *pConn = free_list_.front();free_list_.pop_front();return pConn;
}void CachePool::RelCacheConn(CacheConn *p_cache_conn) {std::lock_guard<std::mutex> lock(m_mutex);list<CacheConn *>::iterator it = free_list_.begin();for (; it != free_list_.end(); it++) {if (*it == p_cache_conn) {break;}}if (it == free_list_.end()) {// m_used_list.remove(pConn);free_list_.push_back(p_cache_conn);cond_var_.notify_one(); // 通知取队列} else {log_error("RelDBConn failed\n"); // 不再次回收连接}
}///////////
CacheManager::CacheManager() {}CacheManager::~CacheManager() {}void CacheManager::SetConfPath(const char *conf_path) {conf_path_ = conf_path;
}CacheManager *CacheManager::getInstance() {if (!s_cache_manager) {s_cache_manager = new CacheManager();if (s_cache_manager->Init()) {delete s_cache_manager;s_cache_manager = NULL;}}return s_cache_manager;
}int CacheManager::Init() {LOG_INFO << "Init";CConfigFileReader config_file(conf_path_.c_str());char *cache_instances = config_file.GetConfigName("CacheInstances");if (!cache_instances) {LOG_ERROR << "not configure CacheIntance";return 1;}char host[64];char port[64];char db[64];char maxconncnt[64];CStrExplode instances_name(cache_instances, ',');for (uint32_t i = 0; i < instances_name.GetItemCnt(); i++) {char *pool_name = instances_name.GetItem(i);// printf("%s", pool_name);snprintf(host, 64, "%s_host", pool_name);snprintf(port, 64, "%s_port", pool_name);snprintf(db, 64, "%s_db", pool_name);snprintf(maxconncnt, 64, "%s_maxconncnt", pool_name);char *cache_host = config_file.GetConfigName(host);char *str_cache_port = config_file.GetConfigName(port);char *str_cache_db = config_file.GetConfigName(db);char *str_max_conn_cnt = config_file.GetConfigName(maxconncnt);if (!cache_host || !str_cache_port || !str_cache_db ||!str_max_conn_cnt) {if(!cache_host)LOG_ERROR << "not configure cache instance: " << pool_name << ", cache_host is null";if(!str_cache_port)LOG_ERROR << "not configure cache instance: " << pool_name << ", str_cache_port is null";if(!str_cache_db)LOG_ERROR << "not configure cache instance: " << pool_name << ", str_cache_db is null";if(!str_max_conn_cnt)LOG_ERROR << "not configure cache instance: " << pool_name << ", str_max_conn_cnt is null";return 2;}CachePool *pCachePool =new CachePool(pool_name, cache_host, atoi(str_cache_port),atoi(str_cache_db), "", atoi(str_max_conn_cnt));if (pCachePool->Init()) {LOG_ERROR << "Init cache pool failed";return 3;}m_cache_pool_map.insert(make_pair(pool_name, pCachePool));}return 0;
}CacheConn *CacheManager::GetCacheConn(const char *pool_name) {map<string, CachePool *>::iterator it = m_cache_pool_map.find(pool_name);if (it != m_cache_pool_map.end()) {return it->second->GetCacheConn();} else {return NULL;}
}void CacheManager::RelCacheConn(CacheConn *cache_conn) {if (!cache_conn) {return;}map<string, CachePool *>::iterator it =m_cache_pool_map.find(cache_conn->GetPoolName());if (it != m_cache_pool_map.end()) {return it->second->RelCacheConn(cache_conn);}
}
MySQL连接池,目前设置了 master,slave 两个连接池,master 用于有写的操作,slave 用于读的操作。Redis 连接池,目前设置了 token,ranking_list 两个连接池,token 用于 token 的读写,ranking_list 用于下载排行榜的操作。
配置文件的引入
tc_http_server.conf
# config format spec
# 绑定的ip和端口
http_bind_ip=0.0.0.0
http_bind_port=8081# io线程数量 默认先用单个epoll
num_event_loops=1
# 业务线程数量
num_threads=8# nodelay参数 目前不影响性能
nodelay=1# 测试性能的时候改为WARN级别,默认INFO
# TRACE = 0, // 0
# DEBUG, //1
# INFO, //2
# WARN, //3
# ERROR, //4
# FATAL, //5
log_level=2# 是否开启短链, 主要是图片分享地址,如果开启需要设置shorturl-server grpc服务地址
# 课程前期先禁用短链,避免一上来就把课程搞复杂
enable_shorturl=0
# 因为当前部署是同一台机器所以使用127.0.0.1,注意端口和shorturl-server保持一致
shorturl_server_address=127.0.0.1:50051
shorturl_server_access_token=e8n05nr9jey84prEhw5u43th0yi294780yjr3h7sksSdkFdDngKidfs_path_client=/etc/fdfs/client.conf
storage_web_server_ip=192.168.1.6
storage_web_server_port=80#configure for mysql
DBInstances=tuchuang_master,tuchuang_slave
#tuchuang_master
tuchuang_master_host=localhost
tuchuang_master_port=3306
tuchuang_master_dbname=0voice_tuchuang
tuchuang_master_username=root
tuchuang_master_password=123456
tuchuang_master_maxconncnt=8#tuchuang_slave
tuchuang_slave_host=localhost
tuchuang_slave_port=3306
tuchuang_slave_dbname=0voice_tuchuang
tuchuang_slave_username=root
tuchuang_slave_password=123456
tuchuang_slave_maxconncnt=64#configure for token
CacheInstances=token,ranking_list
#token相关
token_host=127.0.0.1
token_port=6379
token_db=0
token_maxconncnt=64# 排行榜相关,但目前排行也是直接用了token的连接池
ranking_list_host=127.0.0.1
ranking_list_port=6379
ranking_list_db=1
ranking_list_maxconncnt=64
tc_http_server.conf 是在 nginx 运行过程中需要进行读取的文件,我们需要将对应的 mysql 和 redis 添加进去。
同时,我们也引入了对于配置文件的解析代码:
config_file_reader.h
/** config_file_reader.h** Created on: 2013-7-2* Author: ziteng@mogujie.com*/#ifndef CONFIGFILEREADER_H_
#define CONFIGFILEREADER_H_#include "util.h"class CConfigFileReader {public:CConfigFileReader(const char *filename);~CConfigFileReader();char *GetConfigName(const char *name);int SetConfigValue(const char *name, const char *value);uint16_t get_http_bind_port() {return http_bind_port;}private:void _LoadFile(const char *filename);int _WriteFIle(const char *filename = NULL);void _ParseLine(char *line);char *_TrimSpace(char *name);bool load_ok_;map<string, string> config_map_; // key -valuestring config_file_;int16_t http_bind_port = 8081;string http_bind_ip;
};#endif /* CONFIGFILEREADER_H_ */
让config_file_reader.cc
/** ConfigFileReader.cpp** Created on: 2013-7-2* Author: ziteng@mogujie.com*/#include "config_file_reader.h"
using namespace std;
CConfigFileReader::CConfigFileReader(const char *filename) {_LoadFile(filename);
}CConfigFileReader::~CConfigFileReader() {}char *CConfigFileReader::GetConfigName(const char *name) {if (!load_ok_)return NULL;char *value = NULL;map<string, string>::iterator it = config_map_.find(name);if (it != config_map_.end()) {value = (char *)it->second.c_str();}return value;
}int CConfigFileReader::SetConfigValue(const char *name, const char *value) {if (!load_ok_)return -1;map<string, string>::iterator it = config_map_.find(name);if (it != config_map_.end()) {it->second = value;} else {config_map_.insert(make_pair(name, value));}return _WriteFIle();
}
void CConfigFileReader::_LoadFile(const char *filename) {config_file_.clear();config_file_.append(filename);FILE *fp = fopen(filename, "r");if (!fp) {printf("can not open %s,errno = %d", filename, errno);return;}char buf[256];for (;;) {char *p = fgets(buf, 256, fp);if (!p)break;size_t len = strlen(buf);if (buf[len - 1] == '\n')buf[len - 1] = 0; // remove \n at the endchar *ch = strchr(buf, '#'); // remove string start with #if (ch)*ch = 0;if (strlen(buf) == 0)continue;_ParseLine(buf);}fclose(fp);load_ok_ = true;
}int CConfigFileReader::_WriteFIle(const char *filename) {FILE *fp = NULL;if (filename == NULL) {fp = fopen(config_file_.c_str(), "w");} else {fp = fopen(filename, "w");}if (fp == NULL) {return -1;}char szPaire[128];map<string, string>::iterator it = config_map_.begin();for (; it != config_map_.end(); it++) {memset(szPaire, 0, sizeof(szPaire));snprintf(szPaire, sizeof(szPaire), "%s=%s\n", it->first.c_str(),it->second.c_str());uint32_t ret = fwrite(szPaire, strlen(szPaire), 1, fp);if (ret != 1) {fclose(fp);return -1;}}fclose(fp);return 0;
}
void CConfigFileReader::_ParseLine(char *line) {char *p = strchr(line, '=');if (p == NULL)return;*p = 0;char *key = _TrimSpace(line);char *value = _TrimSpace(p + 1);if (key && value) {config_map_.insert(make_pair(key, value));}
}char *CConfigFileReader::_TrimSpace(char *name) {// remove starting space or tabchar *start_pos = name;while ((*start_pos == ' ') || (*start_pos == '\t')) {start_pos++;}if (strlen(start_pos) == 0)return NULL;// remove ending space or tabchar *end_pos = name + strlen(name) - 1;while ((*end_pos == ' ') || (*end_pos == '\t')) {*end_pos = 0;end_pos--;}int len = (int)(end_pos - start_pos) + 1;if (len <= 0)return NULL;return start_pos;
}
这里的目的是为了让 config_file_reader.cc 代码更为通用,不管新增还是减少字段,只需要解析出来key-value就行,具体key-value意思是什么由业务代码去处理。如果使用json配置文件的方式,我们需要将config_file_reader.cc和业务进行强绑定,当要添加配置字段的时候,我们需要修改config_file_reader.cc。
此时我们的主函数入口就需要将对应的配置文件信息,上传相关的配置信息,redis 以及 mysql 相关的信息都进行一个初始化。
main.cc
int main(int argc, char *argv[])
{std::cout << argv[0] << "[conf ] "<< std::endl;// 默认情况下,往一个读端关闭的管道或socket连接中写数据将引发SIGPIPE信号。我们需要在代码中捕获并处理该信号,// 或者至少忽略它,因为程序接收到SIGPIPE信号的默认行为是结束进程,而我们绝对不希望因为错误的写操作而导致程序退出。// SIG_IGN 忽略信号的处理程序signal(SIGPIPE, SIG_IGN); //忽略SIGPIPE信号int ret = 0;char *str_tc_http_server_conf = NULL;if(argc > 1) {str_tc_http_server_conf = argv[1]; // 指向配置文件路径} else {str_tc_http_server_conf = (char *)"tc_http_server.conf";}std::cout << "conf file path: " << str_tc_http_server_conf << std::endl;// 读取配置文件CConfigFileReader config_file(str_tc_http_server_conf); //读取配置文件char *dfs_path_client = config_file.GetConfigName("dfs_path_client"); // /etc/fdfs/client.confchar *storage_web_server_ip = config_file.GetConfigName("storage_web_server_ip"); //后续可以配置域名char *storage_web_server_port = config_file.GetConfigName("storage_web_server_port");// 初始化mysql、redis连接池,内部也会读取读取配置文件tc_http_server.confCacheManager::SetConfPath(str_tc_http_server_conf); //设置配置文件路径CacheManager *cache_manager = CacheManager::getInstance();if (!cache_manager) {LOG_ERROR <<"CacheManager init failed";return -1;}// 将配置文件的参数传递给对应模块// ApiUploadInit(dfs_path_client, storage_web_server_ip, storage_web_server_port, "", "");CDBManager::SetConfPath(str_tc_http_server_conf); //设置配置文件路径CDBManager *db_manager = CDBManager::getInstance();if (!db_manager) {LOG_ERROR <<"DBManager init failed";return -1;}std::cout << "hello tucuang!!! tc_http_src2\n";uint16_t http_bind_port = 8081; // 端口号const char *http_bind_ip = "0.0.0.0"; // ip地址int32_t num_event_loops = 4; // subRecator的数量EventLoop loop; // 主循环的loopInetAddress addr(http_bind_ip, http_bind_port);LOG_INFO << "port: " << http_bind_port;HttpServer server(&loop, addr, "HttpServer", num_event_loops);server.start();loop.loop();return 0;
}
实现完整注册功能
头文件以及通用函数统一设置
当前为了使代码更加的清晰易懂,我们统一将对应的一些头文件以及接口创建一个文件进行实现,方便后期进行调用:
api_common.h
#ifndef _API_COMMON_H_
#define _API_COMMON_H_
#include "cache_pool.h" // redis操作头文件
#include "db_pool.h" //MySQL操作头文件
#include <json/json.h> // jsoncpp头文件
#include "muduo/base/Logging.h" // Logger日志头文件
#include <string>using std::string;#define SQL_MAX_LEN (512) // sql语句长度#define FILE_NAME_LEN (256) //文件名字长度
#define TEMP_BUF_MAX_LEN (512) //临时缓冲区大小
#define FILE_URL_LEN (512) //文件所存放storage的host_name长度
#define HOST_NAME_LEN (30) //主机ip地址长度
#define USER_NAME_LEN (128) //用户名字长度
#define TOKEN_LEN (128) //登陆token长度
#define MD5_LEN (256) //文件md5长度
#define PWD_LEN (256) //密码长度
#define TIME_STRING_LEN (25) //时间戳长度
#define SUFFIX_LEN (8) //后缀名长度
#define PIC_NAME_LEN (10) //图片资源名字长度
#define PIC_URL_LEN (256) //图片资源url名字长度#define HTTP_RESP_OK 0
#define HTTP_RESP_FAIL 1 //
#define HTTP_RESP_USER_EXIST 2 // 用户存在
#define HTTP_RESP_DEALFILE_EXIST 3 // 别人已经分享此文件
#define HTTP_RESP_TOKEN_ERR 4 // token验证失败
#define HTTP_RESP_FILE_EXIST 5 //个人已经存储了该文件//redis key相关定义
#define REDIS_SERVER_IP "127.0.0.1"
#define REDIS_SERVER_PORT "6379"extern string s_dfs_path_client;
extern string s_storage_web_server_ip;
extern string s_storage_web_server_port;
extern string s_shorturl_server_address;
extern string s_shorturl_server_access_token;/*--------------------------------------------------------
| 共享用户文件有序集合 (ZSET)
| Key: FILE_PUBLIC_LIST
| value: md5文件名
| redis 语句
| ZADD key score member 添加成员
| ZREM key member 删除成员
| ZREVRANGE key start stop [WITHSCORES] 降序查看
| ZINCRBY key increment member 权重累加increment
| ZCARD key 返回key的有序集元素个数
| ZSCORE key member 获取某个成员的分数
| ZREMRANGEBYRANK key start stop 删除指定范围的成员
| zlexcount zset [member [member 判断某个成员是否存在,存在返回1,不存在返回0
`---------------------------------------------------------*/
#define FILE_PUBLIC_ZSET "FILE_PUBLIC_ZSET"/*-------------------------------------------------------
| 文件标示和文件名对应表 (HASH)
| Key: FILE_NAME_HASH
| field: file_id(md5文件名)
| value: file_name
| redis 语句
| hset key field value
| hget key field
`--------------------------------------------------------*/
#define FILE_NAME_HASH "FILE_NAME_HASH"#define FILE_PUBLIC_COUNT "FILE_PUBLIC_COUNT" // 共享文件数量
#define FILE_USER_COUNT "FILE_USER_COUNT" // 用户文件数量 FILE_USER_COUNT+username
#define SHARE_PIC_COUNT "SHARE_PIC_COUNT" // 用户分享图片数量 SHARE_PIC_COUNT+username// 某些参数没有使用时用该宏定义避免报警告
#define UNUSED(expr) \do { \(void)(expr); \} while (0)
//验证登陆token,成功返回0,失败-1
int VerifyToken(string &user_name, string &token);//获取用户文件个数
int CacheSetCount(CacheConn *cache_conn, string key, int64_t count);
int CacheGetCount(CacheConn *cache_conn, string key, int64_t &count);
int CacheIncrCount(CacheConn *cache_conn, string key);
int CacheDecrCount(CacheConn *cache_conn, string key);//处理数据库查询结果,结果集保存在buf,只处理一条记录,一个字段,
//如果buf为NULL,无需保存结果集,只做判断有没有此记录 返回值:
// 0成功并保存记录集,1没有记录集,2有记录集但是没有保存,-1失败
int GetResultOneCount(CDBConn *db_conn, char *sql_cmd, int &count);
int GetResultOneStatus(CDBConn *db_conn, char *sql_cmd, int &shared_status);// 检测是否存在记录,-1 操作失败,0:没有记录, 1:有记录
int CheckwhetherHaveRecord(CDBConn *db_conn, char *sql_cmd);int DBGetUserFilesCountByUsername(CDBConn *db_conn, string user_name, int &count);// 解析http url中的参数
int QueryParseKeyValue(const char *query, const char *key, char *value, int *value_len_p);
//获取文件名后缀
int GetFileSuffix(const char *file_name, char *suffix);
//去掉两边空白字符
int TrimSpace(char *inbuf);
string RandomString(const int len);// 它是一个模板函数,实现也需要放在头文件里,否则报错
template <typename... Args>
std::string FormatString(const std::string &format, Args... args) {auto size = std::snprintf(nullptr, 0, format.c_str(), args...) +1; // Extra space for '\0'std::unique_ptr<char[]> buf(new char[size]);std::snprintf(buf.get(), size, format.c_str(), args...);return std::string(buf.get(), buf.get() + size - 1); // We don't want the '\0' inside
}
#endif
api_common.cc
#include "api_common.h"string s_dfs_path_client;
// string s_web_server_ip;
// string s_web_server_port;
string s_storage_web_server_ip;
string s_storage_web_server_port;
string s_shorturl_server_address;
string s_shorturl_server_access_token;//验证登陆token,成功返回0,失败-1
int VerifyToken(string &user_name, string &token) {int ret = 0;CacheManager *cache_manager = CacheManager::getInstance();CacheConn *cache_conn = cache_manager->GetCacheConn("token");AUTO_REL_CACHECONN(cache_manager, cache_conn);if (cache_conn) {string temp_user_name = cache_conn->Get(token); //校验token和用户名的关系if (temp_user_name == user_name) {ret = 0;} else {ret = -1;}} else {ret = -1;}return ret;
}int CacheSetCount(CacheConn *cache_conn, string key, int64_t count) {string ret = cache_conn->Set(key, std::to_string(count));if (!ret.empty()) {return 0;} else {return -1;}
}
int CacheGetCount(CacheConn *cache_conn, string key, int64_t &count) {count = 0;string str_count = cache_conn->Get(key);if (!str_count.empty()) {count = atoll(str_count.c_str());return 0;} else {return -1;}
}int CacheIncrCount(CacheConn *cache_conn, string key) {int64_t count = 0;int ret = cache_conn->Incr(key, count);if (ret < 0) {return -1;}LOG_INFO << key << "-" << count;return 0;
}
// 这里最小我们只允许为0
int CacheDecrCount(CacheConn *cache_conn, string key) {int64_t count = 0;int ret = cache_conn->Decr(key, count);if (ret < 0) {return -1;}LOG_INFO << key << "-" << count;if (count < 0) {LOG_ERROR << key << "请检测你的逻辑 decr count < 0 -> " << count;ret = CacheSetCount(cache_conn, key, 0); // 文件数量最小为0值if (ret < 0) {return -1;}}return 0;
}//处理数据库查询结果,结果集保存在count,如果要读取count值则设置为0,如果设置为-1则不读取
//返回值: 0成功并保存记录集,1没有记录集,2有记录集但是没有保存,-1失败
int GetResultOneCount(CDBConn *db_conn, char *sql_cmd, int &count) {int ret = -1;CResultSet *result_set = db_conn->ExecuteQuery(sql_cmd);if (!result_set) {ret = -1;}if (count == 0) {// 读取if (result_set->Next()) {ret = 0;// 存在在返回count = result_set->GetInt("count");LOG_INFO << "count: " << count;} else {ret = 1; // 没有记录}} else {if (result_set->Next()) {ret = 2;} else {ret = 1; // 没有记录}}delete result_set;return ret;
}int CheckwhetherHaveRecord(CDBConn *db_conn, char *sql_cmd) {int ret = -1;CResultSet *result_set = db_conn->ExecuteQuery(sql_cmd);if (!result_set) {ret = -1;} else if (result_set && result_set->Next()) {ret = 1;} else {ret = 0;}delete result_set;return ret;
}int GetResultOneStatus(CDBConn *db_conn, char *sql_cmd, int &shared_status) {int ret = 0;CResultSet *result_set = db_conn->ExecuteQuery(sql_cmd);if (!result_set) {LOG_ERROR << "result_set is NULL";ret = -1;}if (result_set->Next()) {ret = 0;// 存在在返回shared_status = result_set->GetInt("shared_status");LOG_INFO << "shared_status: " << shared_status;} else {LOG_ERROR<< "result_set->Next() is NULL";ret = -1;}delete result_set;return ret;
}
//获取用户文件个数
int DBGetUserFilesCountByUsername(CDBConn *db_conn, string user_name, int &count) {count = 0;int ret = 0;// 先查看用户是否存在string str_sql;str_sql = FormatString("select count(*) from user_file_list where user='%s'",user_name.c_str());LOG_INFO << "执行: " << str_sql;CResultSet *result_set = db_conn->ExecuteQuery(str_sql.c_str());if (result_set && result_set->Next()) {// 存在在返回count = result_set->GetInt("count(*)");LOG_INFO << "count: " << count;ret = 0;delete result_set;} else if (!result_set) { // 操作失败LOG_ERROR << "操作失败" << str_sql;LOG_ERROR << "操作失败" << str_sql;ret = -1;} else {// 没有记录则初始化记录数量为0ret = 0;LOG_INFO << "没有记录: count: " << count;}return ret;
}/*** @brief 解析url query 类似 abc=123&bbb=456 字符串* 传入一个key,得到相应的value* @returns* 0 成功, -1 失败*/
int QueryParseKeyValue(const char *query, const char *key, char *value,int *value_len_p) {char *temp = NULL;char *end = NULL;int value_len = 0;//找到是否有keytemp = (char *)strstr(query, key);if (temp == NULL) {return -1;}temp += strlen(key); //=temp++; // value// get valueend = temp;while ('\0' != *end && '#' != *end && '&' != *end) {end++;}value_len = end - temp;strncpy(value, temp, value_len);value[value_len] = '\0';if (value_len_p != NULL) {*value_len_p = value_len;}return 0;
}//通过文件名file_name, 得到文件后缀字符串, 保存在suffix
//如果非法文件后缀,返回"null"
int GetFileSuffix(const char *file_name, char *suffix) {const char *p = file_name;int len = 0;const char *q = NULL;const char *k = NULL;if (p == NULL) {return -1;}q = p;// mike.doc.png// ↑while (*q != '\0') {q++;}k = q;while (*k != '.' && k != p) {k--;}if (*k == '.') {k++;len = q - k;if (len != 0) {strncpy(suffix, k, len);suffix[len] = '\0';} else {strncpy(suffix, "null", 5);}} else {strncpy(suffix, "null", 5);}return 0;
}/*** @brief 去掉一个字符串两边的空白字符** @param inbuf确保inbuf可修改** @returns* 0 成功* -1 失败*/
int TrimSpace(char *inbuf) {int i = 0;int j = strlen(inbuf) - 1;char *str = inbuf;int count = 0;if (str == NULL) {return -1;}while (isspace(str[i]) && str[i] != '\0') {i++;}while (isspace(str[j]) && j > i) {j--;}count = j - i + 1;strncpy(inbuf, str + i, count);inbuf[count] = '\0';return 0;
}// 这个随机字符串是有问题的
string RandomString(const int len) /*参数为字符串的长度*/
{/*初始化*/string str; /*声明用来保存随机字符串的str*/char c; /*声明字符c,用来保存随机生成的字符*/int idx; /*用来循环的变量*//*循环向字符串中添加随机生成的字符*/for (idx = 0; idx < len; idx++) {/*rand()%26是取余,余数为0~25加上'a',就是字母a~z,详见asc码表*/c = 'a' + rand() % 26;str.push_back(c); /*push_back()是string类尾插函数。这里插入随机字符c*/}return str; /*返回生成的随机字符串*/
}
注册功能完善
对于注册功能,上一阶段我们已经实现了部分,接下来我们就需引入 mysql 了,主要就是针对于 registerUser 接口:
int registerUser(std::string &user_name, std::string &nick_name, std::string &pwd,std::string &phone, std::string &email) {// ret = 2; 用户已经存在; = 1 注册异常; = 0 注册成功int ret = 0;// 创建一个mysql连接对象uint32_t user_id = 0;CDBManager *db_manager = CDBManager::getInstance();// 主数据库进行写数据操作CDBConn *db_conn = db_manager->GetDBConn("tuchuang_master");// 析构自动释放对应的对象AUTO_REL_DBCONN(db_manager, db_conn);if(!db_conn) {LOG_ERROR << "GetDBConn(tuchuang_slave) failed" ;return 1;}//查询数据库是否存在string str_sql = FormatString("select id from user_info where user_name='%s'", user_name.c_str());// 处理对应的查询sql语句CResultSet *result_set = db_conn->ExecuteQuery(str_sql.c_str());// 如果对应的用户已经存在,就返回if(result_set && result_set->Next()) {LOG_WARN << "id: " << result_set->GetInt("id") << ", user_name: " << user_name << " 已经存在";delete result_set;ret = 2; //已经存在对应的用户名} else {// 只有不存在是才会创建用户time_t now;char create_time[TIME_STRING_LEN];//获取当前时间now = time(NULL);strftime(create_time, TIME_STRING_LEN - 1, "%Y-%m-%d %H:%M:%S", localtime(&now)); // unix格式化后的时间str_sql = "insert into user_info ""(`user_name`,`nick_name`,`password`,`phone`,`email`,`create_""time`) values(?,?,?,?,?,?)";LOG_INFO << "执行: " << str_sql;// 预处理方式写入数据CPrepareStatement *stmt = new CPrepareStatement();if (stmt->Init(db_conn->GetMysql(), str_sql)) {uint32_t index = 0;string c_time = create_time;stmt->SetParam(index++, user_name);stmt->SetParam(index++, nick_name);stmt->SetParam(index++, pwd);stmt->SetParam(index++, phone);stmt->SetParam(index++, email);stmt->SetParam(index++, c_time);bool bRet = stmt->ExecuteUpdate(); //真正提交要写入的数据if (bRet) { //提交正常返回 trueret = 0;user_id = db_conn->GetInsertId(); LOG_INFO << "insert user_id: " << user_id << ", user_name: " << user_name ;} else {LOG_ERROR << "insert user_info failed. " << str_sql;ret = 1;}}delete stmt;}return ret;
}
- 这一块儿我们需要制定相应的规则,客户端发起注册账户的请求,那么就会就会存在两种结果,成功或者是失败,失败也会存在两种不同的原因,注册异常或者是账户已经存在,所以当前我们就约定返回值 = 0 注册成功,= 1 注册异常,= 2 账户已经存在;
- 进入函数以后我们就需要先获取到 mysql 对象,与数据库建立连接以后,判断当前注册是用户是不是已经存在,如果不存在,我们在进行注册操作,其实这中间的代码逻辑也比较简单,就是对对应的 mysql 语句进行操作就可以了。
登录功能完善
登录功能主要是完善 verifyUserPassword 和 setToken 这两个接口, verifyUserPassword 接口通过用户名查询数据库对应的密码,对比请求登录的密码是否一致,一致我们才可以登陆成功。setToken 接口如果一致则 生成一个新 token,并以 token 为 key ,用户名作为 value ,把 token 存储到 redis 里。
这儿需要注意的就是,当前是以 token 为 key ,是为了为了提高系统性能和安全性,因为用户名这种东西很容易就被获取到,获取到以后就容易破解对应的密码,但是 token 随机生成,一般情况下是不会被获取到的,增加了对应的安全性。
// 设置对应的 uuid
std::string generateUUID() {uuid_t uuid;uuid_generate_time_safe(uuid); //调用uuid的接口char uuidStr[40] = {0};uuid_unparse(uuid, uuidStr); //调用uuid的接口return std::string(uuidStr);
}// 验证账号密码是否匹配
int verifyUserPassword(std::string &user_name, std::string &pwd) {int ret = 0;// 创建一个mysql对象CDBManager *db_manager = CDBManager::getInstance();CDBConn *db_conn = db_manager->GetDBConn("tuchuang_slave");AUTO_REL_DBCONN(db_manager, db_conn); //析构时自动归还连接// 根据用户名查询密码string strSql = FormatString("select password from user_info where user_name='%s'", user_name.c_str());CResultSet *result_set = db_conn->ExecuteQuery(strSql.c_str());if (result_set && result_set->Next()) { //如果存在则读取密码// 存在在返回string password = result_set->GetString("password");LOG_INFO << "mysql-pwd: " << password << ", user-pwd: " << pwd;if (password == pwd) //对比密码是否一致ret = 0; //对比成功elseret = -1; //对比失败} else { // 说明用户不存在ret = -1;}delete result_set;return ret;
}// 生成token信息
int setToken(std::string &user_name, std::string &token) {int ret = 0;// 创建一个 Redis 对象CacheManager *cache_manager = CacheManager::getInstance();CacheConn *cache_conn = cache_manager->GetCacheConn("token");AUTO_REL_CACHECONN(cache_manager, cache_conn);token = generateUUID(); // 生成唯一的tokenif (cache_conn) {//token - 用户名, 86400有效时间为24小时 有效期可以自己修改cache_conn->SetEx(token, 86400, user_name); // redis做超时} else {ret = -1;}return ret;
}
- 使用redis实现token验证机制的好处就在于,Redis是一个开源的内存数据存储系统,可以用作数据库、缓存和消息中间件。它支持多种数据结构,例如字符串、哈希、列表、集合和有序集合。Redis通过将数据存储在内存中,提供了非常高效的读写速度。
- 在Web应用程序中,使用Redis存储Token有以下几个优点:
快速:Redis的数据存储在内存中,读写速度非常快,适用于高并发的场景。
可扩展性:Redis支持分布式部署,可以轻松实现横向扩展。
多种数据结构:Redis支持多种数据结构,可以根据需求选择适合的数据结构存储Token。
过期时间管理:Redis提供了设置过期时间的功能,可以轻松实现Token的自动过期和续期。 - 我们使用 token 作为 key ,所以需要做到唯一,所以也就需要通过算法生成唯一的 key,我们使用 libuuid 这个库,通过调用 generateUUID 接口获取到唯一的 token。
阶段性功能验证
对于注册已经登录功能当前我们已经进行了完善,接下来我们就进行功能的测试:

我们可以看见,正常情况下我们是可以注册成功的,但是如果用户名和昵称一旦有一个重复,就会返回异常码 1。
文件上传功能实现
当前用户注册与登录功能已经完全实现,我们接下来就实现文件上传的功能,首先我们依然需要创建两张表结构,对应的文件上传也依赖于这之前创建的和这两张表结构:
DROP TABLE IF EXISTS `file_info`;
CREATE TABLE `file_info` (`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '文件序号,自动递增,主键',`md5` varchar(256) NOT NULL COMMENT '文件md5',`file_id` varchar(256) NOT NULL COMMENT '文件id:/group1/M00/00/00/xxx.png',`url` varchar(512) NOT NULL COMMENT '文件url 192.168.52.139:80/group1/M00/00/00/xxx.png',`size` bigint(20) DEFAULT '0' COMMENT '文件大小, 以字节为单位',`type` varchar(32) DEFAULT '' COMMENT '文件类型: png, zip, mp4……',`count` int(11) DEFAULT '0' COMMENT '文件引用计数,默认为1。每增加一个用户拥有此文件,此计数器+1',PRIMARY KEY (`id`),-- UNIQUE KEY `uq_md5` (`md5) KEY `uq_md5` (`md5`(8)) -- 前缀索引
) ENGINE=InnoDB AUTO_INCREMENT=70 DEFAULT CHARSET=utf8 COMMENT='文件信息表';DROP TABLE IF EXISTS `user_file_list`;
CREATE TABLE `user_file_list` (`id` int(11) NOT NULL AUTO_INCREMENT COMMENT '编号',`user` varchar(32) NOT NULL COMMENT '文件所属用户',`md5` varchar(256) NOT NULL COMMENT '文件md5',`create_time` timestamp NULL DEFAULT CURRENT_TIMESTAMP COMMENT '文件创建时间',`file_name` varchar(128) DEFAULT NULL COMMENT '文件名字',`shared_status` int(11) DEFAULT NULL COMMENT '共享状态, 0为没有共享, 1为共享',`pv` int(11) DEFAULT NULL COMMENT '文件下载量,默认值为0,下载一次加1',PRIMARY KEY (`id`),KEY `idx_user_md5_file_name` (`user`,`md5`, `file_name`)
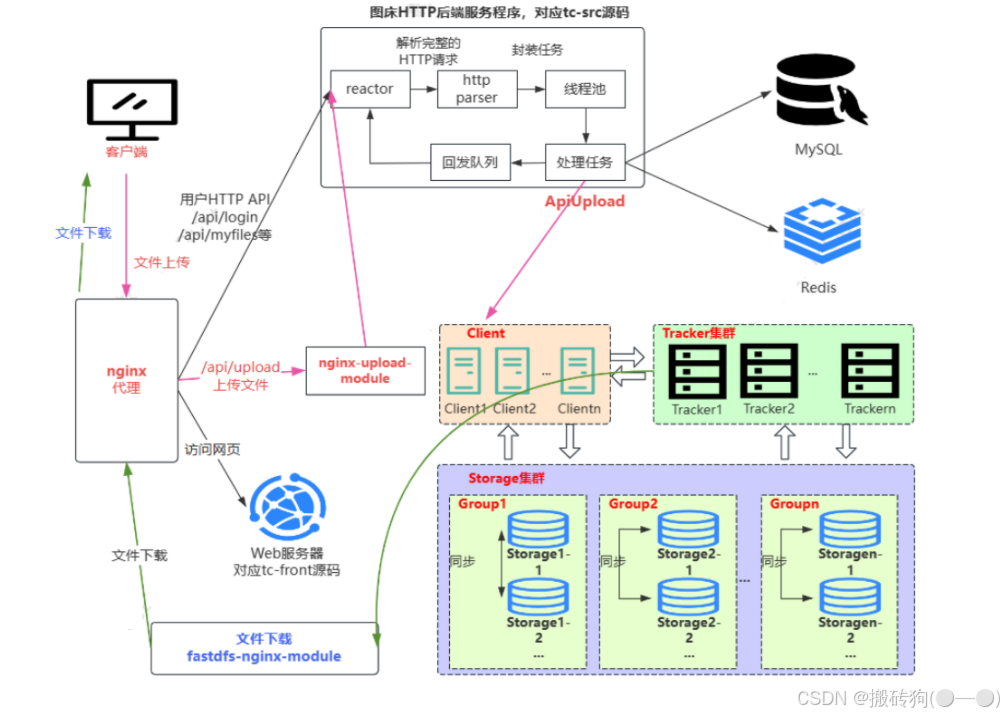
) ENGINE=InnoDB AUTO_INCREMENT=30 DEFAULT CHARSET=utf8 COMMENT='用户文件列表';首先我们先对上传文件模块的整体框架进行一个解析,上传文件的总体逻辑:
- 先通过 nginx-upload-module 模块上传文件到临时目录;
- nginx-upload-module 模块上传完文件后通知 /api/upload 后端处理程序;
- 后端处理程序 ApiUpload 函数解析文件信息,然后将临时文件上传到 fastdfs;
- 更新数据库记录:file_info,user_file_list。
但是其中是存在许多的细节实现的:
- 客户端在上传文件之前将文件的MD5码上传到服务器;
- 服务器端判断是否已存在此MD5码,如果存在,说明该文件已存在,则此文件无需再上传,在此文件的计数器加 1,说明此文件多了一个用户共用;
- 如果服务器没有此MD5码,说明上传的文件是新文件,则真正上传此文件。
流程图如下所示:
下面是对于 nginx.conf 文件的配置,对于 nginx 不太了解的可以去看一下我之前的一篇关于 nginx 的文章:探秘 Nginx 的工作原理,里面对于 nginx.conf 文件解析都有详细的介绍:
user root;
worker_processes 4;#error_log logs/error.log;
#error_log logs/error.log notice;
#error_log logs/error.log info;#pid logs/nginx.pid;events {worker_connections 1024;
}http {include mime.types;default_type application/octet-stream;#log_format main '$remote_addr - $remote_user [$time_local] "$request" '# '$status $body_bytes_sent "$http_referer" '# '"$http_user_agent" "$http_x_forwarded_for"';#access_log logs/access.log main;sendfile on;#tcp_nopush on;#keepalive_timeout 0;keepalive_timeout 65;# file 30Mclient_max_body_size 30m;#gzip on;server {listen 80;server_name 0.0.0.0;#charset koi8-r;#access_log logs/host.access.log main;index index.html index.htm default.htm default.html;root /home/lqf/my-study/tuchuang/tuchuang-master/tc-front;autoindex off;#access_log logs/host.access.log main;# 指定允许跨域的方法,*代表所有add_header Access-Control-Allow-Methods *;# 预检命令的缓存,如果不缓存每次会发送两次请求add_header Access-Control-Max-Age 3600;# 带cookie请求需要加上这个字段,并设置为trueadd_header Access-Control-Allow-Credentials true;# 表示允许这个域跨域调用(客户端发送请求的域名和端口)# $http_origin动态获取请求客户端请求的域 不用*的原因是带cookie的请求不支持*号add_header Access-Control-Allow-Origin $http_origin;# 表示请求头的字段 动态获取add_header Access-Control-Allow-Headers$http_access_control_request_headers;#charset koi8-r;#access_log logs/host.access.log main;location / {root /home/lqf/my-study/tuchuang/tuchuang-master/tc-front;index index.html index.htm;try_files $uri $uri/ /index.html;}location ~/group([0-9])/M([0-9])([0-9]) { ngx_fastdfs_module;} location /api/upload {# Pass altered request body to this locationupload_pass @api_upload;# Store files to this directory# The directory is hashed, subdirectories 0 1 2 3 4 5 6 7 8 9 should existupload_store /root/tmp 1;# Allow uploaded files to be read only by userupload_store_access user:r;# Set specified fields in request bodyupload_set_form_field "${upload_field_name}_name" $upload_file_name;upload_set_form_field "${upload_field_name}_content_type" $upload_content_type;upload_set_form_field "${upload_field_name}_path" $upload_tmp_path;# Inform backend about hash and size of a fileupload_aggregate_form_field "${upload_field_name}_md5" $upload_file_md5;upload_aggregate_form_field "${upload_field_name}_size" $upload_file_size;#upload_pass_form_field "^.*"; upload_pass_form_field "^user"; # 把user字段也传递给后端解析处理#upload_pass_form_field "^submit$|^description$";}# Pass altered request body to a backendlocation @api_upload {proxy_pass http://127.0.0.1:8081;}# 短链代理,对应tuchuang/shorturl/shorturl-proxy服务location /p/{proxy_pass http://127.0.0.1:8082;}# /api/子目录的都透传到http://127.0.0.1:8081location /api/{ proxy_pass http://127.0.0.1:8081;}#error_page 404 /404.html;# redirect server error pages to the static page /50x.html#error_page 500 502 503 504 /50x.html;location = /50x.html {root html;}}include /usr/local/nginx/conf/conf.d/*.conf;
}
/api/upload上传文件
流程解析
请求URL
| URL | http://192.168.1.6/api/uploa |
|---|---|
| 请求方式 | POST |
| HTTP版本 | 1.1 |
| Content-Type | application/octet-stream |
返回结果参数说明
| 名称 | 含义 | 规则说明 |
|---|---|---|
| code | 结果值 | 0: 上传成功 1: 上传失败 |
对于上传文件模块,是需要一个解析流程的,我们需要对上传文件的文件名,文件类型,MD5值,文件大小,上传用户等重要的信息进行解析,解析完毕以后获取到对应的文件,放在一个临时目录当中,然后将其上传至 fastdfs 中,然后更新至数据库:

代码实现
api_upload.h
#ifndef _APIUPLOAD_H_
#define _APIUPLOAD_H_
#include "api_common.h"// 文件上传功能实现
int ApiUpload(string &post_data, string &str_json);// 将配置文件的参数传递给对应模块
int ApiUploadInit(const char *dfs_path_client, const char *storage_web_server_ip, const char *storage_web_server_port, const char *shorturl_server_address, const char *access_token);#endif // !__UPLOAD_H_api_upload.cc
#include "api_upload.h"
#include <unistd.h>
#include <sys/wait.h>// fileid 返回
int uploadFileToFastDfs(char *file_path, char *fileid) {int ret = 0;if(s_dfs_path_client.empty()) {LOG_ERROR << "s_dfs_path_client is empty";return -1;}pid_t pid;int fd[2];//无名管道的创建if (pipe(fd) < 0) // fd[0] → r; fd[1] → w 获取上传后返回的信息 fileid{LOG_ERROR << "pipe error";ret = -1;goto END;}//创建进程pid = fork(); // if (pid < 0) //进程创建失败{LOG_ERROR << "fork error";ret = -1;goto END;}if (pid == 0) //子进程{//关闭读端close(fd[0]);//将标准输出 重定向 写管道dup2(fd[1], STDOUT_FILENO); // 往标准输出写的东西都会重定向到fd所指向的文件,// 当fileid产生时输出到管道fd[1]// fdfs_upload_file /etc/fdfs/client.conf 123.txt// printf("fdfs_upload_file %s %s %s\n", fdfs_cli_conf_path, filename,// file_path);//通过execlp执行fdfs_upload_file//如果函数调用成功,进程自己的执行代码就会变成加载程序的代码,execlp()后边的代码也就不会执行了.execlp("fdfs_upload_file", "fdfs_upload_file",s_dfs_path_client.c_str(), file_path, NULL); //// 执行正常不会跑下面的代码// 执行失败LOG_ERROR << "execlp fdfs_upload_file error";close(fd[1]);} else {//父进程关闭写端close(fd[1]);//从管道中去读数据read(fd[0], fileid, TEMP_BUF_MAX_LEN); // 等待管道写入然后读取LOG_INFO << "fileid1: " << fileid;//去掉一个字符串两边的空白字符TrimSpace(fileid);if (strlen(fileid) == 0) {LOG_ERROR << "upload failed";ret = -1;goto END;}LOG_INFO << "fileid2: " << fileid;wait(NULL); //等待子进程结束,回收其资源close(fd[0]);}END:return ret;
}int getFullUrlByFileid(char *fileid, char *fdfs_file_url) {if(s_storage_web_server_ip.empty()) {LOG_ERROR << "s_storage_web_server_ip is empty";return -1;} int ret = 0;char *p = NULL;char *q = NULL;char *k = NULL;char fdfs_file_stat_buf[TEMP_BUF_MAX_LEN] = {0};char fdfs_file_host_name[HOST_NAME_LEN] = {0}; // storage所在服务器ip地址pid_t pid;int fd[2];//无名管道的创建if (pipe(fd) < 0) {LOG_ERROR << "pipe error";ret = -1;goto END;}//创建进程pid = fork();if (pid < 0) //进程创建失败{LOG_ERROR << "fork error";ret = -1;goto END;}if (pid == 0) //子进程{//关闭读端close(fd[0]);//将标准输出 重定向 写管道dup2(fd[1], STDOUT_FILENO); // dup2(fd[1], 1);execlp("fdfs_file_info", "fdfs_file_info", s_dfs_path_client.c_str(),fileid, NULL);//执行失败LOG_ERROR << "execlp fdfs_file_info error";close(fd[1]);} else {// 父进程关闭写端close(fd[1]);//从管道中去读数据read(fd[0], fdfs_file_stat_buf, TEMP_BUF_MAX_LEN);wait(NULL); //等待子进程结束,回收其资源close(fd[0]);// LOG_INFO << "fdfs_file_stat_buf: " << fdfs_file_stat_buf;//拼接上传文件的完整url地址--->http://host_name/group1/M00/00/00/D12313123232312.pngp = strstr(fdfs_file_stat_buf, "source ip address: ");q = p + strlen("source ip address: ");k = strstr(q, "\n");strncpy(fdfs_file_host_name, q, k - q);fdfs_file_host_name[k - q] = '\0'; // 这里这个获取回来只是局域网的ip地址,在讲fastdfs原理的时候再继续讲这个问题LOG_INFO << "host_name: " << s_storage_web_server_ip << ", fdfs_file_host_name: " << fdfs_file_host_name;// storage_web_server服务器的端口strcat(fdfs_file_url, "http://");strcat(fdfs_file_url, s_storage_web_server_ip.c_str());// strcat(fdfs_file_url, ":");// strcat(fdfs_file_url, s_storage_web_server_port.c_str());strcat(fdfs_file_url, "/");strcat(fdfs_file_url, fileid);LOG_INFO << "fdfs_file_url:" << fdfs_file_url;}END:return ret;
}int storeFileinfo(CDBConn *db_conn, CacheConn *cache_conn, char *user,char *filename, char *md5, long size, char *fileid,const char *fdfs_file_url) {int ret = 0;time_t now;char create_time[TIME_STRING_LEN];char suffix[SUFFIX_LEN];char sql_cmd[SQL_MAX_LEN] = {0};//得到文件后缀字符串 如果非法文件后缀,返回"null"GetFileSuffix(filename, suffix); // mp4, jpg, png// sql 语句/*-- =============================================== 文件信息表-- md5 文件md5-- file_id 文件id-- url 文件url-- size 文件大小, 以字节为单位-- type 文件类型: png, zip, mp4……-- count 文件引用计数, 默认为1, 每增加一个用户拥有此文件,此计数器+1*/sprintf(sql_cmd,"insert into file_info (md5, file_id, url, size, type, count) ""values ('%s', '%s', '%s', '%ld', '%s', %d)",md5, fileid, fdfs_file_url, size, suffix, 1);// LOG_INFO << "执行: " << sql_cmd;if (!db_conn->ExecuteCreate(sql_cmd)) //执行sql语句{LOG_ERROR << sql_cmd << " 操作失败";ret = -1;goto END;}//获取当前时间now = time(NULL);strftime(create_time, TIME_STRING_LEN - 1, "%Y-%m-%d %H:%M:%S", localtime(&now));/*-- =============================================== 用户文件列表-- user 文件所属用户-- md5 文件md5-- create_time 文件创建时间-- file_name 文件名字-- shared_status 共享状态, 0为没有共享, 1为共享-- pv 文件下载量,默认值为0,下载一次加1*/// sql语句sprintf(sql_cmd,"insert into user_file_list(user, md5, create_time, file_name, ""shared_status, pv) values ('%s', '%s', '%s', '%s', %d, %d)",user, md5, create_time, filename, 0, 0);// LOG_INFO << "执行: " << sql_cmd;if (!db_conn->ExecuteCreate(sql_cmd)) {LOG_ERROR << sql_cmd << " 操作失败";ret = -1;goto END;}END:return ret;
}// 文件上传主接口实现
int ApiUpload(string &post_data, string &str_json){LOG_INFO << "post_data:\n" << post_data;char suffix[SUFFIX_LEN] = {0}; //后缀 .png .mp4char fileid[TEMP_BUF_MAX_LEN] = {0}; //文件上传到fastDFS后的文件idchar fdfs_file_url[FILE_URL_LEN] = {0}; //文件所存放storage的host_nameint ret = 0;char boundary[TEMP_BUF_MAX_LEN] = {0}; //分界线信息 分隔符char file_name[128] = {0}; //文件名char file_content_type[128] = {0}; //文件类型char file_path[128] = {0}; //文件路径char new_file_path[128] = {0}; //新文件路径char file_md5[128] = {0}; // 文件的md5char file_size[32] = {0}; //文件的大小long long_file_size = 0; //转成long类型的文件大小char user[32] = {0}; //用户名// 从传入文件信息的开始位置进行解析char *begin = (char *)post_data.c_str();char *p1, *p2; //临时的界限位置Json::Value value;// 获取数据库连接CDBManager *db_manager = CDBManager::getInstance();CDBConn *db_conn = db_manager->GetDBConn("tuchuang_master"); // 连接池可以配置多个分库AUTO_REL_DBCONN(db_manager, db_conn);//分隔符// 1. 解析boundary// Content-Type: multipart/form-data;// boundary=----WebKitFormBoundaryjWE3qXXORSg2hZiB 找到起始位置p1 = strstr(begin, "\r\n"); // 作用是返回字符串中首次出现子串的地址if (p1 == NULL) {LOG_ERROR << "wrong no boundary!";ret = -1;goto END;}//拷贝分界线strncpy(boundary, begin, p1 - begin); // 缓存分界线, 比如:WebKitFormBoundary88asdgewtgewxboundary[p1 - begin] = '\0'; //字符串结束符LOG_INFO << "boundary: " << boundary; //打印出来// 查找文件名file_name 匹配字符串的算法begin = p1 + 2; // 2->\r\np2 = strstr(begin, "name=\"file_name\""); //找到file_name字段if (!p2) {LOG_ERROR << "wrong no file_name!";ret = -1;goto END;}p2 = strstr(begin, "\r\n"); // 找到file_name下一行p2 += 4; //下一行起始begin = p2; // p2 = strstr(begin, "\r\n");strncpy(file_name, begin, p2 - begin);LOG_INFO << "file_name: " << file_name;// 查找文件类型file_content_typebegin = p2 + 2;p2 = strstr(begin, "name=\"file_content_type\""); //if (!p2) {LOG_ERROR << "wrong no file_content_type!";ret = -1;goto END;}p2 = strstr(p2, "\r\n");p2 += 4;begin = p2;p2 = strstr(begin, "\r\n");strncpy(file_content_type, begin, p2 - begin);LOG_INFO << "file_content_type: " << file_content_type;// 查找文件file_pathbegin = p2 + 2;p2 = strstr(begin, "name=\"file_path\""); //if (!p2) {LOG_ERROR << "wrong no file_path!";ret = -1;goto END;}p2 = strstr(p2, "\r\n");p2 += 4;begin = p2;p2 = strstr(begin, "\r\n");strncpy(file_path, begin, p2 - begin);LOG_INFO << "file_path: " << file_path;// 查找文件file_md5begin = p2 + 2;p2 = strstr(begin, "name=\"file_md5\""); //if (!p2) {LOG_ERROR << "wrong no file_md5!";ret = -1;goto END;}p2 = strstr(p2, "\r\n");p2 += 4;begin = p2;p2 = strstr(begin, "\r\n");strncpy(file_md5, begin, p2 - begin);LOG_INFO << "file_md5: " << file_md5;// 查找文件file_sizebegin = p2 + 2;p2 = strstr(begin, "name=\"file_size\""); //if (!p2) {LOG_ERROR << "wrong no file_size!";ret = -1;goto END;}p2 = strstr(p2, "\r\n");p2 += 4;begin = p2;p2 = strstr(begin, "\r\n");strncpy(file_size, begin, p2 - begin);LOG_INFO << "file_size: " << file_size;long_file_size = strtol(file_size, NULL, 10); //字符串转long// 查找userbegin = p2 + 2;p2 = strstr(begin, "name=\"user\""); //if (!p2) {LOG_ERROR << "wrong no user!";ret = -1;goto END;}p2 = strstr(p2, "\r\n");p2 += 4;begin = p2;p2 = strstr(begin, "\r\n");strncpy(user, begin, p2 - begin);LOG_INFO << "user: " << user;//把临时文件拷贝到fastdfs /root/tmp/9/0035297749, 后缀呢?//从文件名获取文件后缀//把临时文件 改成带后缀名文件// 获取文件名后缀GetFileSuffix(file_name, suffix); // 20230720-2.txt -> txt mp4, jpg, pngstrcat(new_file_path, file_path); // /root/tmp/1/0045118901strcat(new_file_path, "."); // /root/tmp/1/0045118901.strcat(new_file_path, suffix); // /root/tmp/1/0045118901.txt// 重命名 修改文件名 fastdfs 他需要带后缀的文件ret = rename(file_path, new_file_path); /// /root/tmp/1/0045118901 -> /root/tmp/1/0045118901.txt sudo if (ret < 0) {LOG_ERROR << "rename " << file_path << " to " << new_file_path << " failed" ;ret = -1;goto END;} //===============> 将该文件存入fastDFS中,并得到文件的file_id <============LOG_INFO << "uploadFileToFastDfs, file_name:" << file_name << ", new_file_path:" << new_file_path;if (uploadFileToFastDfs(new_file_path, fileid) < 0) {LOG_ERROR << "uploadFileToFastDfs failed, unlink: " << new_file_path;ret = unlink(new_file_path);if (ret != 0) {LOG_ERROR << "unlink: " << new_file_path << " failed"; // 删除失败则需要有个监控重新清除过期的临时文件,比如过期两天的都删除}ret = -1;goto END;}//================> 删除本地临时存放的上传文件 <===============LOG_INFO << "unlink: " << new_file_path;ret = unlink(new_file_path);if (ret != 0) {LOG_WARN << "unlink: " << new_file_path << " failed"; // 删除失败则需要有个监控重新清除过期的临时文件,比如过期两天的都删除}//================> 得到文件所存放storage的host_name <=================// 拼接出完整的http地址LOG_INFO << "getFullurlByFileid, fileid: " << fileid;if (getFullUrlByFileid(fileid, fdfs_file_url) < 0) {LOG_ERROR << "getFullurlByFileid failed ";ret = -1;goto END;}//===============> 将该文件的FastDFS相关信息存入mysql中 <======LOG_INFO << "storeFileinfo, origin url: " << fdfs_file_url ;// << " -> short url: " << short_url;// 把文件写入file_infoif (storeFileinfo(db_conn, NULL, user, file_name, file_md5,long_file_size, fileid, fdfs_file_url) < 0) {LOG_ERROR << "storeFileinfo failed ";ret = -1;// 严谨而言,这里需要删除 已经上传的文件goto END;}ret = 0;value["code"] = 0;str_json = value.toStyledString(); // json序列化, 直接用writer是紧凑方式,这里toStyledString是格式化更可读方式return 0;
END:value["code"] = 1;str_json = value.toStyledString(); // json序列化return -1;
}int ApiUploadInit(const char *dfs_path_client, const char *storage_web_server_ip, const char *storage_web_server_port, const char *shorturl_server_address, const char *access_token) {s_dfs_path_client = dfs_path_client;s_storage_web_server_ip = storage_web_server_ip;s_storage_web_server_port = storage_web_server_port;s_shorturl_server_address = shorturl_server_address;s_shorturl_server_access_token = access_token;return 0;
}-
ApiUpload() 接口为文件上传位置的入口函数,对于当前文件我们需要上传至 fastdfs 和 数据库,那么就需要设置一系列的变量将对应的文件信息保存下来,然后分段进行解析,解析完毕以后,将其存入到一个临时文件当中,然后上传至 fsatdfs 当中,删除掉对应的临时文件,然后根据对应的从 fsatdfs 中获取到的 url ,将文件保存到 mysql 数据库中。
-
uploadFileToFastDfs() 接口就是将文件上传至 fastdfs 中,这块采用的逻辑就是 fork 子进程的方式去解决的,fork 创建子进程后执行的是和父进程相同的程序(但有可能执行不同的代码分支),子进程往往要调用一种exec函数以执行另一个程序,当进程调用一种exec函数时,该进程的用户空间代码和数据完全被新程序替换。
-
当前使用的是 execlp 函数,他的第一个参数就代表当前子进程执行的操作就是
fdfs_upload_file这个指令,也就是上传文件的操作,接下来的操作就是代表怎么去执行,当前就是需要上传临时库中的文件至 fastdfs 当中,整体执行的语句就是fdfs_upload_file /etc/fdfs/client.conf /root/tmp/1/xxx.txt,这也是我们子进程去完成的任务,完成以后就通知父进程已经完成。
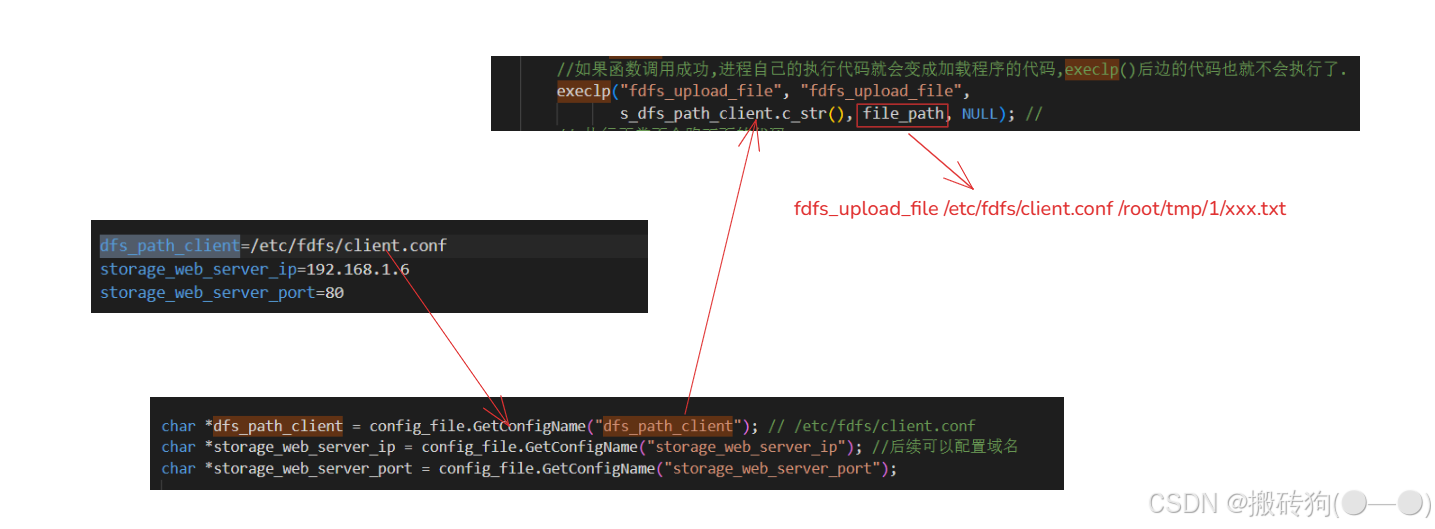
-
当前还是用的匿名管道通信,数据本身时父进程发送过来的,子进程需要进行处理,父进程所做的就是读取的操作,管道数据半双工通信,所以就需要创建两个匿名管道,父进程关闭写端,只需要读取数据,而子进程所做的就是写入的操作,关闭读端。
-
我们当前就会做一个约定,从标准输入流读取数据就相当于从匿名管道读取数据,向标准输出流写入数据就相当于向管道文件中写入数据,这儿就是用来 dup2 的重定向函数,实现了父子进程之间的通信,此时,管道文件就不需要知道对应的文件描述符了,只需要向标准输出流写入数据,标准输入流读取数据即可。
-
getFullUrlByFileid() 也是同样的道理,我们 fork 子进程,子进程获取到对应的 url 以后返回结果给父进程,父进程读取到这个结果,然后最终调用 storeFileinfo() 函数对数据库进行操作,将对应的数据写入数据库。
/api/md5文件秒传
流程解析
秒传文件的作用就在于:上传文件的时候会先调用/api/md5接口判断服务器是否有该文件,如果/api/md5返回成功,则说明服务器已经存在该文件,客户端不需要再去调用 /api/upload 接口上传文件,如果不成功则客户端继续调用/api/upload接口上传文件。
这样的操作就在于我们并不需要每次都上传一个相同的文件,当前用户已经上传过一次了,后期再上传相同的这个文件,就可以通过秒传功能来操作。
请求URL
| URL | http://192.168.1.6/api/md5 |
|---|---|
| 请求方式 | POST |
| HTTP版本 | 1.1 |
| Content-Type | application/json |
请求参数
| 参数名 | 含义 | 规则说明 | 是否必须 | 缺省值 |
|---|---|---|---|---|
| token | 令牌 | 同 | 上 必填 | 无 |
| md5 | md5值 | 不能超过32个字符 | 必填 | 无 |
| filename | 文件名称 | 不能超过128个字符 | 必填 | 无 |
| user | 用户名称 | 不能超过32个字符 | 必填 | 无 |
返回结果参数说明
| 名称 | 含义 | 规则说明 |
|---|---|---|
| code | 结果值 | 0: 秒传成功 1: 秒传失败 4: token校验失败 5:文件已存在 |
每个文件都有一个唯一的MD5值(比如2bf8170b42cc7124b04a8886c83a9c6f),就好比每个人的指纹都是唯一的一样,效验MD5就是用来确保文件在传输过程中未被修改过。
客户端在上传文件之前将文件的MD5码上传到服务器,服务器端判断是否已存在此MD5码,如果存在,说明该文件已存在,则此文件无需再上传,在此文件的计数器加1,说明此文件多了一个用户共用,如果服务器没有此MD5码,说明上传的文件是新文件,则真正上传此文件。
处理逻辑

代码实现
api_md5.h
#include "api_upload.h"
#include <unistd.h>
#include <sys/wait.h>// fileid 返回
int uploadFileToFastDfs(char *file_path, char *fileid) {int ret = 0;if(s_dfs_path_client.empty()) {LOG_ERROR << "s_dfs_path_client is empty";return -1;}pid_t pid;int fd[2];//无名管道的创建if (pipe(fd) < 0) // fd[0] → r; fd[1] → w 获取上传后返回的信息 fileid{LOG_ERROR << "pipe error";ret = -1;goto END;}//创建进程pid = fork(); // if (pid < 0) //进程创建失败{LOG_ERROR << "fork error";ret = -1;goto END;}if (pid == 0) //子进程{//关闭读端close(fd[0]);//将标准输出 重定向 写管道dup2(fd[1], STDOUT_FILENO); // 往标准输出写的东西都会重定向到fd所指向的文件,// 当fileid产生时输出到管道fd[1]// fdfs_upload_file /etc/fdfs/client.conf 123.txt// printf("fdfs_upload_file %s %s %s\n", fdfs_cli_conf_path, filename,// file_path);//通过execlp执行fdfs_upload_file//如果函数调用成功,进程自己的执行代码就会变成加载程序的代码,execlp()后边的代码也就不会执行了.execlp("fdfs_upload_file", "fdfs_upload_file",s_dfs_path_client.c_str(), file_path, NULL); //// 执行正常不会跑下面的代码// 执行失败LOG_ERROR << "execlp fdfs_upload_file error";close(fd[1]);} else {//父进程关闭写端close(fd[1]);//从管道中去读数据read(fd[0], fileid, TEMP_BUF_MAX_LEN); // 等待管道写入然后读取LOG_INFO << "fileid1: " << fileid;//去掉一个字符串两边的空白字符TrimSpace(fileid);if (strlen(fileid) == 0) {LOG_ERROR << "upload failed";ret = -1;goto END;}LOG_INFO << "fileid2: " << fileid;wait(NULL); //等待子进程结束,回收其资源close(fd[0]);}END:return ret;
}int getFullUrlByFileid(char *fileid, char *fdfs_file_url) {if(s_storage_web_server_ip.empty()) {LOG_ERROR << "s_storage_web_server_ip is empty";return -1;} int ret = 0;char *p = NULL;char *q = NULL;char *k = NULL;char fdfs_file_stat_buf[TEMP_BUF_MAX_LEN] = {0};char fdfs_file_host_name[HOST_NAME_LEN] = {0}; // storage所在服务器ip地址pid_t pid;int fd[2];//无名管道的创建if (pipe(fd) < 0) {LOG_ERROR << "pipe error";ret = -1;goto END;}//创建进程pid = fork();if (pid < 0) //进程创建失败{LOG_ERROR << "fork error";ret = -1;goto END;}if (pid == 0) //子进程{//关闭读端close(fd[0]);//将标准输出 重定向 写管道dup2(fd[1], STDOUT_FILENO); // dup2(fd[1], 1);execlp("fdfs_file_info", "fdfs_file_info", s_dfs_path_client.c_str(),fileid, NULL);//执行失败LOG_ERROR << "execlp fdfs_file_info error";close(fd[1]);} else {// 父进程关闭写端close(fd[1]);//从管道中去读数据read(fd[0], fdfs_file_stat_buf, TEMP_BUF_MAX_LEN);wait(NULL); //等待子进程结束,回收其资源close(fd[0]);// LOG_INFO << "fdfs_file_stat_buf: " << fdfs_file_stat_buf;//拼接上传文件的完整url地址--->http://host_name/group1/M00/00/00/D12313123232312.pngp = strstr(fdfs_file_stat_buf, "source ip address: ");q = p + strlen("source ip address: ");k = strstr(q, "\n");strncpy(fdfs_file_host_name, q, k - q);fdfs_file_host_name[k - q] = '\0'; // 这里这个获取回来只是局域网的ip地址,在讲fastdfs原理的时候再继续讲这个问题LOG_INFO << "host_name: " << s_storage_web_server_ip << ", fdfs_file_host_name: " << fdfs_file_host_name;// storage_web_server服务器的端口strcat(fdfs_file_url, "http://");strcat(fdfs_file_url, s_storage_web_server_ip.c_str());// strcat(fdfs_file_url, ":");// strcat(fdfs_file_url, s_storage_web_server_port.c_str());strcat(fdfs_file_url, "/");strcat(fdfs_file_url, fileid);LOG_INFO << "fdfs_file_url:" << fdfs_file_url;}END:return ret;
}int storeFileinfo(CDBConn *db_conn, CacheConn *cache_conn, char *user,char *filename, char *md5, long size, char *fileid,const char *fdfs_file_url) {int ret = 0;time_t now;char create_time[TIME_STRING_LEN];char suffix[SUFFIX_LEN];char sql_cmd[SQL_MAX_LEN] = {0};//得到文件后缀字符串 如果非法文件后缀,返回"null"GetFileSuffix(filename, suffix); // mp4, jpg, png// sql 语句/*-- =============================================== 文件信息表-- md5 文件md5-- file_id 文件id-- url 文件url-- size 文件大小, 以字节为单位-- type 文件类型: png, zip, mp4……-- count 文件引用计数, 默认为1, 每增加一个用户拥有此文件,此计数器+1*/sprintf(sql_cmd,"insert into file_info (md5, file_id, url, size, type, count) ""values ('%s', '%s', '%s', '%ld', '%s', %d)",md5, fileid, fdfs_file_url, size, suffix, 1);// LOG_INFO << "执行: " << sql_cmd;if (!db_conn->ExecuteCreate(sql_cmd)) //执行sql语句{LOG_ERROR << sql_cmd << " 操作失败";ret = -1;goto END;}//获取当前时间now = time(NULL);strftime(create_time, TIME_STRING_LEN - 1, "%Y-%m-%d %H:%M:%S", localtime(&now));/*-- =============================================== 用户文件列表-- user 文件所属用户-- md5 文件md5-- create_time 文件创建时间-- file_name 文件名字-- shared_status 共享状态, 0为没有共享, 1为共享-- pv 文件下载量,默认值为0,下载一次加1*/// sql语句sprintf(sql_cmd,"insert into user_file_list(user, md5, create_time, file_name, ""shared_status, pv) values ('%s', '%s', '%s', '%s', %d, %d)",user, md5, create_time, filename, 0, 0);// LOG_INFO << "执行: " << sql_cmd;if (!db_conn->ExecuteCreate(sql_cmd)) {LOG_ERROR << sql_cmd << " 操作失败";ret = -1;goto END;}END:return ret;
}// 文件上传主接口实现
int ApiUpload(std::string &post_data, std::string &str_json){LOG_INFO << "post_data:\n" << post_data;char suffix[SUFFIX_LEN] = {0}; //后缀 .png .mp4char fileid[TEMP_BUF_MAX_LEN] = {0}; //文件上传到fastDFS后的文件idchar fdfs_file_url[FILE_URL_LEN] = {0}; //文件所存放storage的host_nameint ret = 0;char boundary[TEMP_BUF_MAX_LEN] = {0}; //分界线信息 分隔符char file_name[128] = {0}; //文件名char file_content_type[128] = {0}; //文件类型char file_path[128] = {0}; //文件路径char new_file_path[128] = {0}; //新文件路径char file_md5[128] = {0}; // 文件的md5char file_size[32] = {0}; //文件的大小long long_file_size = 0; //转成long类型的文件大小char user[32] = {0}; //用户名// 从传入文件信息的开始位置进行解析char *begin = (char *)post_data.c_str();char *p1, *p2; //临时的界限位置Json::Value value;// 获取数据库连接CDBManager *db_manager = CDBManager::getInstance();CDBConn *db_conn = db_manager->GetDBConn("tuchuang_master"); // 连接池可以配置多个分库AUTO_REL_DBCONN(db_manager, db_conn);//分隔符// 1. 解析boundary// Content-Type: multipart/form-data;// boundary=----WebKitFormBoundaryjWE3qXXORSg2hZiB 找到起始位置p1 = strstr(begin, "\r\n"); // 作用是返回字符串中首次出现子串的地址if (p1 == NULL) {LOG_ERROR << "wrong no boundary!";ret = -1;goto END;}//拷贝分界线strncpy(boundary, begin, p1 - begin); // 缓存分界线, 比如:WebKitFormBoundary88asdgewtgewxboundary[p1 - begin] = '\0'; //字符串结束符LOG_INFO << "boundary: " << boundary; //打印出来// 查找文件名file_name 匹配字符串的算法begin = p1 + 2; // 2->\r\np2 = strstr(begin, "name=\"file_name\""); //找到file_name字段if (!p2) {LOG_ERROR << "wrong no file_name!";ret = -1;goto END;}p2 = strstr(begin, "\r\n"); // 找到file_name下一行p2 += 4; //下一行起始begin = p2; // p2 = strstr(begin, "\r\n");strncpy(file_name, begin, p2 - begin);LOG_INFO << "file_name: " << file_name;// 查找文件类型file_content_typebegin = p2 + 2;p2 = strstr(begin, "name=\"file_content_type\""); //if (!p2) {LOG_ERROR << "wrong no file_content_type!";ret = -1;goto END;}p2 = strstr(p2, "\r\n");p2 += 4;begin = p2;p2 = strstr(begin, "\r\n");strncpy(file_content_type, begin, p2 - begin);LOG_INFO << "file_content_type: " << file_content_type;// 查找文件file_pathbegin = p2 + 2;p2 = strstr(begin, "name=\"file_path\""); //if (!p2) {LOG_ERROR << "wrong no file_path!";ret = -1;goto END;}p2 = strstr(p2, "\r\n");p2 += 4;begin = p2;p2 = strstr(begin, "\r\n");strncpy(file_path, begin, p2 - begin);LOG_INFO << "file_path: " << file_path;// 查找文件file_md5begin = p2 + 2;p2 = strstr(begin, "name=\"file_md5\""); //if (!p2) {LOG_ERROR << "wrong no file_md5!";ret = -1;goto END;}p2 = strstr(p2, "\r\n");p2 += 4;begin = p2;p2 = strstr(begin, "\r\n");strncpy(file_md5, begin, p2 - begin);LOG_INFO << "file_md5: " << file_md5;// 查找文件file_sizebegin = p2 + 2;p2 = strstr(begin, "name=\"file_size\""); //if (!p2) {LOG_ERROR << "wrong no file_size!";ret = -1;goto END;}p2 = strstr(p2, "\r\n");p2 += 4;begin = p2;p2 = strstr(begin, "\r\n");strncpy(file_size, begin, p2 - begin);LOG_INFO << "file_size: " << file_size;long_file_size = strtol(file_size, NULL, 10); //字符串转long// 查找userbegin = p2 + 2;p2 = strstr(begin, "name=\"user\""); //if (!p2) {LOG_ERROR << "wrong no user!";ret = -1;goto END;}p2 = strstr(p2, "\r\n");p2 += 4;begin = p2;p2 = strstr(begin, "\r\n");strncpy(user, begin, p2 - begin);LOG_INFO << "user: " << user;//把临时文件拷贝到fastdfs /root/tmp/9/0035297749, 后缀呢?//从文件名获取文件后缀//把临时文件 改成带后缀名文件// 获取文件名后缀GetFileSuffix(file_name, suffix); // 20230720-2.txt -> txt mp4, jpg, pngstrcat(new_file_path, file_path); // /root/tmp/1/0045118901strcat(new_file_path, "."); // /root/tmp/1/0045118901.strcat(new_file_path, suffix); // /root/tmp/1/0045118901.txt// 重命名 修改文件名 fastdfs 他需要带后缀的文件ret = rename(file_path, new_file_path); /// /root/tmp/1/0045118901 -> /root/tmp/1/0045118901.txt sudo if (ret < 0) {LOG_ERROR << "rename " << file_path << " to " << new_file_path << " failed" ;ret = -1;goto END;} //===============> 将该文件存入fastDFS中,并得到文件的file_id <============LOG_INFO << "uploadFileToFastDfs, file_name:" << file_name << ", new_file_path:" << new_file_path;if (uploadFileToFastDfs(new_file_path, fileid) < 0) {LOG_ERROR << "uploadFileToFastDfs failed, unlink: " << new_file_path;ret = unlink(new_file_path);if (ret != 0) {LOG_ERROR << "unlink: " << new_file_path << " failed"; // 删除失败则需要有个监控重新清除过期的临时文件,比如过期两天的都删除}ret = -1;goto END;}//================> 删除本地临时存放的上传文件 <===============LOG_INFO << "unlink: " << new_file_path;ret = unlink(new_file_path);if (ret != 0) {LOG_WARN << "unlink: " << new_file_path << " failed"; // 删除失败则需要有个监控重新清除过期的临时文件,比如过期两天的都删除}//================> 得到文件所存放storage的host_name <=================// 拼接出完整的http地址LOG_INFO << "getFullurlByFileid, fileid: " << fileid;if (getFullUrlByFileid(fileid, fdfs_file_url) < 0) {LOG_ERROR << "getFullurlByFileid failed ";ret = -1;goto END;}//===============> 将该文件的FastDFS相关信息存入mysql中 <======LOG_INFO << "storeFileinfo, origin url: " << fdfs_file_url;// 把文件写入file_infoif (storeFileinfo(db_conn, NULL, user, file_name, file_md5,long_file_size, fileid, fdfs_file_url) < 0) {LOG_ERROR << "storeFileinfo failed ";ret = -1;// 严谨而言,这里需要删除 已经上传的文件goto END;}ret = 0;value["code"] = 0;str_json = value.toStyledString(); // json序列化, 直接用writer是紧凑方式,这里toStyledString是格式化更可读方式return 0;
END:value["code"] = 1;str_json = value.toStyledString(); // json序列化return -1;
}int ApiUploadInit(const char *dfs_path_client, const char *storage_web_server_ip, const char *storage_web_server_port, const char *shorturl_server_address, const char *access_token) {s_dfs_path_client = dfs_path_client;s_storage_web_server_ip = storage_web_server_ip;s_storage_web_server_port = storage_web_server_port;s_shorturl_server_address = shorturl_server_address;s_shorturl_server_access_token = access_token;return 0;
}- ApiMd5() 依然为 MD5 模块的主函数入口,我们所做的工作就是解析解析对应的数据信息,然后进行MD5处理,返回对应的状态码;
- handleDealMd5() 作为秒传处理的接口,也是最为重要的一个接口,他的逻辑就在于获取到一个数据库对象,然后去根据MD5值去查询当前文件的拥有用户的数量,如果已经有用户上传了,就证明当前文件已经存在,不需要再重复进行上传,它本身所依赖的就是
user_file_list和file_info这两张表结构,file_info是一个文件信息表,存储各种上传文件的信息,user_file_list用户文件列表,所代表的是用户上传的文件信息,但是这两张是有联系的两张表,对于相同文件,他们的 MD5 值是一样的。
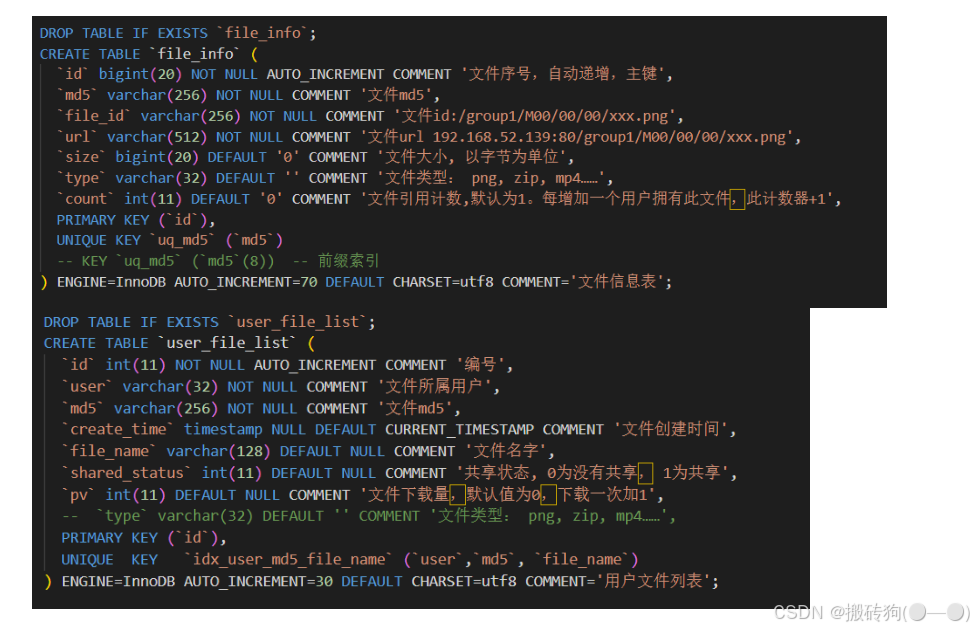
- 我们首先会检查
file_info是否存在这个文件,来看当前文件是否已经被上传,没有记录是不会进行秒传操作的,再检查user_file_list是否有这个文件,来看当前用户是否已经上传,当前用户没有上传的时候我们才会去进行上传操作。
文件上传于秒传功能实现以后,当前就需要将对应的,模块添加进去:
http_conn.cc
#include "http_conn.h"
#include "muduo/base/Logging.h"
#include "api_login.h"
#include "api_register.h"
#include "api_md5.h"
#include "api_upload.h"#define HTTP_RESPONSE_JSON_MAX 4096
#define HTTP_RESPONSE_JSON \"HTTP/1.1 200 OK\r\n" \"Connection:close\r\n" \"Content-Length:%d\r\n" \"Content-Type:application/json;charset=utf-8\r\n\r\n%s"#define HTTP_RESPONSE_HTML \"HTTP/1.1 200 OK\r\n" \"Connection:close\r\n" \"Content-Length:%d\r\n" \"Content-Type:text/html;charset=utf-8\r\n\r\n%s"#define HTTP_RESPONSE_BAD_REQ \"HTTP/1.1 400 Bad\r\n" \"Connection:close\r\n" \"Content-Length:%d\r\n" \"Content-Type:application/json;charset=utf-8\r\n\r\n%s"#define HTTP_RESPONSE_REQ \"HTTP/1.1 404 OK\r\n" \"Connection:close\r\n" \"Content-Length:%d\r\n" \"Content-Type:application/json;charset=utf-8\r\n\r\n%s"CHttpConn::CHttpConn(TcpConnectionPtr tcp_conn): tcp_conn_(tcp_conn)
{// 构造对应的uuiduuid_ = std::any_cast<uint32_t>(tcp_conn_->getContext());LOG_INFO << "构造CHttpConn uuid: "<< uuid_ ;
}void CHttpConn::OnRead(Buffer *buf) {// 获取buf的数据const char* in_buf = buf->peek();// LOG_INFO << "get msg: " << in_buf;// 获取对应的数据长度int32_t length = buf->readableBytes();// 对url进行解析http_parser.ParseHttpContent(in_buf, length);if (http_parser.IsReadAll()) {string url = http_parser.GetUrlString();string content = http_parser.GetBodyContentString();LOG_INFO << "url: " << url << ", content: " << content;if (strncmp(url.c_str(), "/api/reg", 8) == 0) {_HandleRegisterRequest(content);} else if (strncmp(url.c_str(), "/api/login", 10) == 0) {_HandleLoginRequest(content);} else if (strncmp(url.c_str(), "/api/md5", 8) == 0) { _HandleMd5Request(content); // 处理} else if (strncmp(url.c_str(), "/api/upload", 11) == 0) { // 上传_HandleUploadRequest(content);} else {char *resp_content = new char[256];string str_json = "{\"code\": 0}"; uint32_t len_json = str_json.size();snprintf(resp_content, 256, HTTP_RESPONSE_REQ, len_json, str_json.c_str()); tcp_conn_->send(resp_content);}}
}// 账号注册处理
int CHttpConn::_HandleRegisterRequest(std::string &post_data) {std::string resp_json;// 调用注册的进行处理int ret = ApiRegisterUser(post_data, resp_json);// 封装http_bodychar *http_body = new char[HTTP_RESPONSE_JSON_MAX];uint32_t ulen = resp_json.length();snprintf(http_body, HTTP_RESPONSE_JSON_MAX, HTTP_RESPONSE_JSON, ulen,resp_json.c_str()); tcp_conn_->send(http_body);delete[] http_body;LOG_INFO << " uuid: "<< uuid_;return 0;
}int CHttpConn::_HandleLoginRequest(std::string &post_data)
{std::string str_json;// 调用登录的接口进行处理int ret = ApiUserLogin(post_data, str_json);// 封装返回内容char *szContent = new char[HTTP_RESPONSE_JSON_MAX];uint32_t ulen = str_json.length();snprintf(szContent, HTTP_RESPONSE_JSON_MAX, HTTP_RESPONSE_JSON, ulen, str_json.c_str()); tcp_conn_->send(szContent);delete [] szContent;LOG_INFO << " uuid: "<< uuid_; return 0;
}// 文件秒传功能
int CHttpConn::_HandleMd5Request(std::string &post_data)
{std::string str_json;int ret = ApiMd5(post_data, str_json);char *szContent = new char[HTTP_RESPONSE_JSON_MAX];uint32_t ulen = str_json.length();snprintf(szContent, HTTP_RESPONSE_JSON_MAX, HTTP_RESPONSE_JSON, ulen, str_json.c_str()); tcp_conn_->send(szContent);delete [] szContent;LOG_INFO << " uuid: "<< uuid_; return 0;
}// 文件上传功能int CHttpConn::_HandleUploadRequest(std::string &post_data)
{std::string str_json;int ret = ApiUpload(post_data, str_json);char *szContent = new char[HTTP_RESPONSE_JSON_MAX];uint32_t ulen = str_json.length();snprintf(szContent, HTTP_RESPONSE_JSON_MAX, HTTP_RESPONSE_JSON, ulen, str_json.c_str()); tcp_conn_->send(szContent);delete [] szContent;LOG_INFO << " uuid: "<< uuid_; return 0;
}CHttpConn::~CHttpConn() {LOG_INFO << "析构CHttpConn uuid: "<< uuid_ ;
}
功能验证
接下来我们来进行功能验证,我们可以看见,文件是可以正常进行上传的,上传完毕以后,我们根据对应的链接,也是可以正常去查看文件的:
