Batch Normalization 批归一化
为什么需要归一化?
在神经网络的训练中,参数不断变化,使得各层的输入分布也在不停调整。这样会使得模型收敛变慢,并对初始化和学习率敏感。
Batch Normalization的作用:
- 让每一层输入分布更稳定
- 加速训练,提高数值稳定性
- 允许更高的学习率
- 减少对初始化的敏感
BN计算整体流程
BN整体分为两个流程,先标准化,再尺度缩放和偏移。
假设某一层的输入x,[batch_size=B,channel=d,H,W]
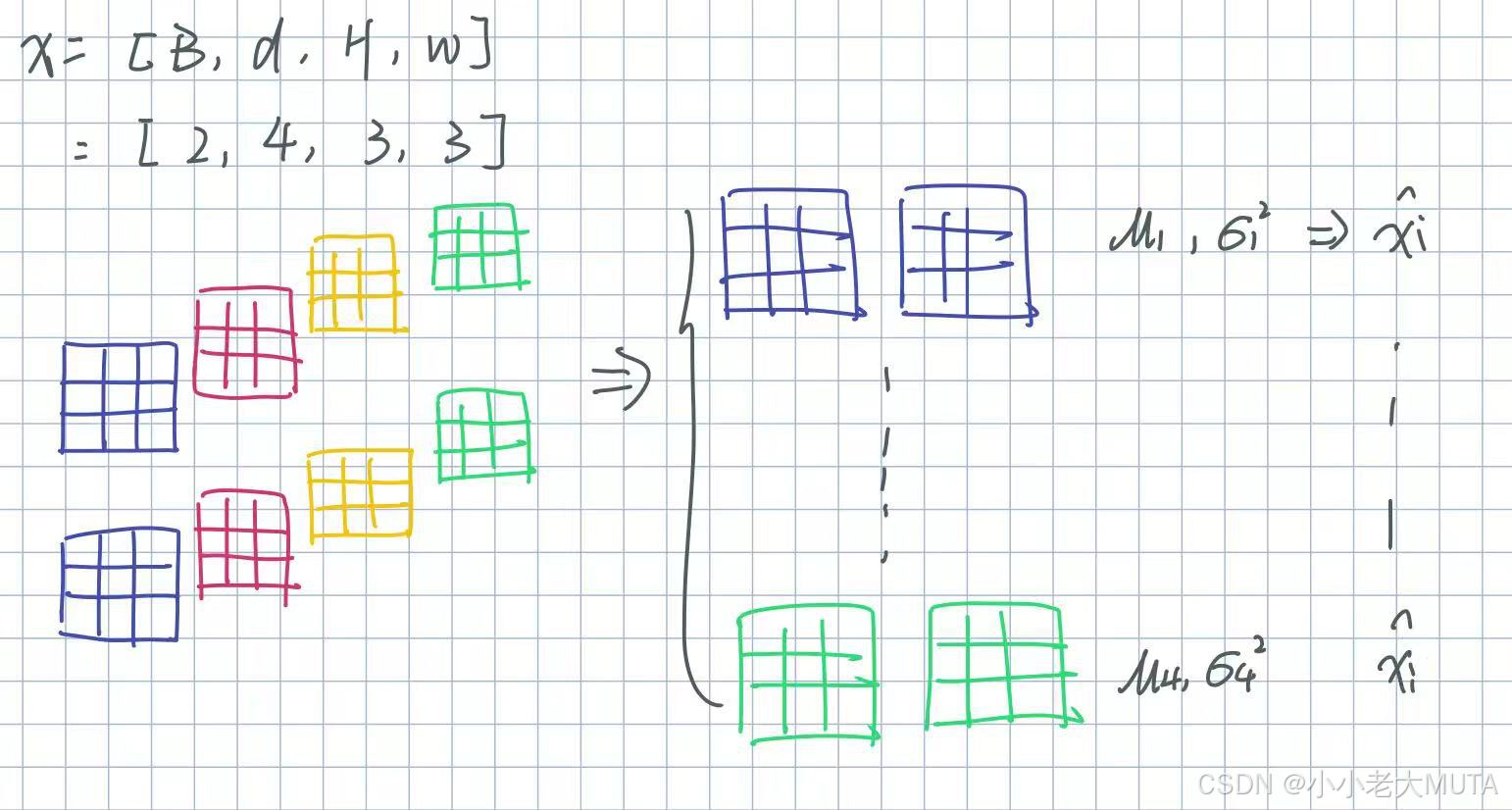
1. 对于每一维特征d,在minibatch内计算均值和方差:
2. 标准化:
其中 ϵ 是一个很小的正数,防止分母为零。
3. 引入两个可学习参数γ(缩放)和β(平移):
γ 和 β 让模型有能力恢复原始分布(如有需要),不会因为归一化限制了表达能力。
训练和验证阶段区别
训练
- 对每个 minibatch 计算均值
和方差
。
- 归一化用的是当前 batch 的均值和方差。
- 同时用这些 batch 统计量更新全局的滑动平均(moving average):
其中 ρ 是动量系数(如 0.9、0.99 等)。
验证
不再用 batch 的均值/方差(因为 batch size 可能很小,统计不稳定)。
用训练时累积得到的全局滑动平均
和
,进行归一化:
一般在神经网络中,都是先经过卷积--->BN----->ReLU
BN将卷积后的输出分布归一化后,使用ReLU激活,及那个分布中的负值清,达到更好的效果。
如果卷积层之后添加了BN层,卷积层中的bias设置为False,因为bias不起任何作用。
因为会抵消:
