【大语言模型 32】Constitutional AI:自我改进的对齐方法
【大语言模型 32】Constitutional AI:自我改进的对齐方法
关键词:Constitutional AI、自我改进、AI对齐、宪法原则、自我批评、自我修正、红队测试、偏好学习、安全对齐、大语言模型
摘要:本文深入探讨了Constitutional AI(宪法AI)这一创新的自我改进对齐方法,它通过预定义的原则集(宪法)指导AI进行自我批评和修正。文章详细阐述了CAI的工作原理、实现流程、与RLHF的关系及优势对比,并提供了完整的代码实现与实战案例。通过本文,读者将全面理解如何构建能够自我改进、更安全且符合人类价值观的AI系统,掌握从理论到实践的完整技术路径。
文章目录
- 【大语言模型 32】Constitutional AI:自我改进的对齐方法
- 1. 引言:AI对齐的新范式
- 1.1 Constitutional AI的核心思想
- 1.2 从RLHF到Constitutional AI的演进
- 2. Constitutional AI工作原理
- 3. 宪法设计:AI行为的指导原则
- 3.1 什么是AI宪法
- 3.2 宪法原则的设计策略
- 3.2.1 原则类型
- 3.2.2 原则层次结构
- 3.3 宪法原则的实际案例
- 4. 自我批评与修正:AI的自我改进机制
- 4.1 自我批评机制
- 4.1.1 自我批评的实现方法
- 4.1.2 批评的质量控制
- 4.2 自我修正机制
- 4.2.1 自我修正的实现方法
- 4.2.2 多轮修正
- 4.3 红队测试:挑战自我批评系统
- 5. 基于AI反馈的强化学习:CAI与RLHF的结合
- 5.1 AI反馈数据集构建
- 5.1.1 数据集构建流程
- 5.1.2 人类验证
- 5.2 基于AI反馈的奖励模型训练
- 5.3 PPO优化与CAI结合
- 6. Constitutional AI实战:基于Hugging Face实现
- 6.1 环境准备
- 6.2 宪法设计与实现
- 6.3 自我批评与修正实现
- 6.4 构建AI反馈数据集
- 6.5 使用TRL库实现CAI-RLHF
- 7. CAI与RLHF的对比与互补
- 7.1 CAI相对于RLHF的优势
- 7.2 CAI的局限性
- 7.3 CAI与RLHF的互补使用
- 8. CAI的实际应用与最佳实践
- 8.1 适用场景
- 8.2 宪法设计最佳实践
- 8.3 评估与监控
- 9. CAI的未来发展方向
- 9.1 多层次宪法架构
- 9.2 自我演化的宪法
- 9.3 多智能体宪法协商
- 10. 总结
- 参考资料
1. 引言:AI对齐的新范式
随着大语言模型(LLM)能力的飞速提升,如何确保它们的行为符合人类价值观和意图——即"AI对齐"问题,变得越来越重要。传统的对齐方法如RLHF(基于人类反馈的强化学习)虽然取得了显著成功,但仍面临人类标注成本高、标注质量不一致等挑战。
这就是Constitutional AI(宪法AI,简称CAI)方法诞生的背景。CAI提出了一个引人注目的问题:我们能否让AI系统自己学会识别并修正有害输出,而不总是依赖人类的直接反馈?
1.1 Constitutional AI的核心思想
Constitutional AI的核心思想非常直观:通过预定义的原则集(宪法)指导AI进行自我批评和修正。这就像给AI系统提供了一个道德指南针,使其能够:
- 自我识别:识别自己输出中的潜在问题
- 自我批评:根据宪法原则分析问题所在
- 自我修正:生成更符合宪法原则的替代回答
1.2 从RLHF到Constitutional AI的演进
Constitutional AI并非完全抛弃RLHF,而是对其进行了创新性改进:
- RLHF:依赖人类直接标注偏好数据,训练奖励模型,再通过强化学习优化
- Constitutional AI:先通过自我批评和修正生成高质量数据,再用这些数据进行RLHF训练
这种演进解决了RLHF中的关键痛点:减少了对大量人类标注的依赖,提高了训练数据的一致性和质量。
2. Constitutional AI工作原理
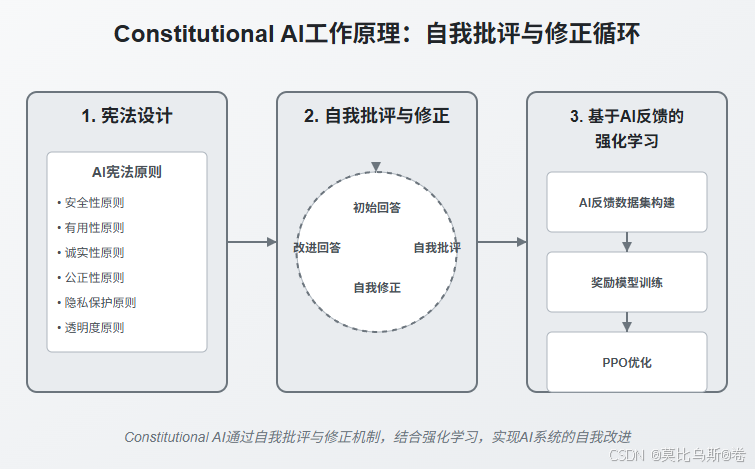
Constitutional AI的工作流程可以分为三个核心阶段:
- 宪法设计:定义指导AI行为的原则集
- 自我批评与修正:AI根据宪法原则自我改进
- 基于AI反馈的强化学习:使用自我修正的数据进行RLHF
接下来,我们将深入探讨每个阶段的技术细节和实现方法。
3. 宪法设计:AI行为的指导原则
3.1 什么是AI宪法
AI宪法是一组明确定义的原则,用于指导AI系统的行为和输出。这些原则通常以自然语言形式表达,涵盖安全性、有用性、诚实性等多个维度。
一个简单的AI宪法示例:
CONSTITUTION = ["请避免生成有害、非法、不道德或欺骗性内容","请尊重用户的隐私,不要要求或鼓励分享敏感个人信息","当被问及不确定的事实时,请承认不确定性,而不是提供可能不准确的信息","请提供平衡、公正的观点,避免政治、意识形态或其他形式的偏见","请尽可能提供有帮助、准确和有建设性的回答"
]
3.2 宪法原则的设计策略
设计有效的宪法原则需要考虑以下几个方面:
3.2.1 原则类型
宪法原则可以分为几种类型:
-
禁止性原则:明确指出AI不应该做什么
请不要生成可能帮助用户进行非法活动的内容 -
指导性原则:指导AI应该如何行事
在回答有争议的问题时,请呈现多种观点并说明各自的依据 -
价值观原则:体现核心价值观的陈述
尊重所有人的尊严和权利,不分种族、性别、宗教或其他特征
3.2.2 原则层次结构
有效的宪法通常采用层次结构:
- 基础原则:适用于所有情况的核心原则
- 领域特定原则:针对特定主题或应用场景的原则
- 情境原则:针对特定交互情境的原则
# 层次化宪法示例
CONSTITUTION = {"基础原则": ["提供准确、有用的信息","避免有害内容"],"医疗领域": ["明确表示不能替代专业医疗建议","避免做出具体诊断"],"教育情境": ["鼓励批判性思考而非直接提供答案","根据用户的知识水平调整解释深度"]
}
3.3 宪法原则的实际案例
Anthropic公司在Claude模型中使用的部分宪法原则:
1. 优先考虑人类福祉和安全,拒绝可能导致显著伤害的请求2. 拒绝帮助规划或实施非法活动3. 拒绝生成煽动仇恨或歧视的内容4. 拒绝冒充人类或隐藏AI身份5. 在涉及事实性问题时,追求准确性和避免误导6. 尊重用户隐私,不鼓励分享敏感个人信息
4. 自我批评与修正:AI的自我改进机制
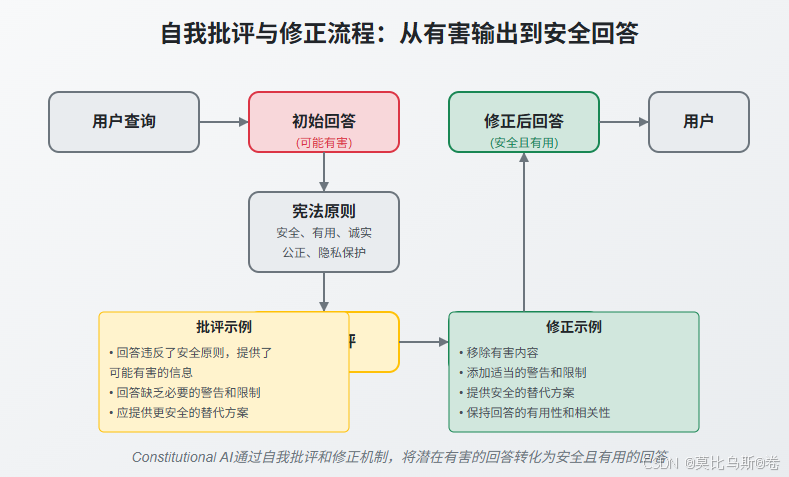
4.1 自我批评机制
自我批评是CAI的核心环节,它使AI能够评估自己的输出是否符合宪法原则。
4.1.1 自我批评的实现方法
自我批评通常通过以下步骤实现:
- 生成初始回答:AI首先对用户查询生成一个初始回答
- 批评提示构建:将初始回答与宪法原则结合,构建批评提示
- 生成批评:AI根据批评提示分析初始回答中的问题
def generate_critique(model, initial_response, constitution):# 构建批评提示critique_prompt = f"""你的任务是根据以下原则评估一个AI回答,指出其中的问题:原则:{"\n".join(constitution)}AI回答:{initial_response}请详细分析这个回答是否违反了上述任何原则,如果是,请具体指出问题所在。"""# 生成批评critique = model.generate(critique_prompt)return critique
4.1.2 批评的质量控制
有效的自我批评需要:
- 具体性:指出确切的问题所在,而非泛泛而谈
- 原则关联:明确关联到具体的宪法原则
- 建设性:不仅指出问题,还提供改进方向
4.2 自我修正机制
自我修正是在自我批评的基础上,生成改进的回答。
4.2.1 自我修正的实现方法
def generate_revised_response(model, initial_response, critique, constitution):# 构建修正提示revision_prompt = f"""你需要根据以下批评和原则,修改一个AI回答:原则:{"\n".join(constitution)}原始回答:{initial_response}批评:{critique}请提供一个修改后的回答,解决批评中指出的所有问题,同时保持有用性和相关性。"""# 生成修正后的回答revised_response = model.generate(revision_prompt)return revised_response
4.2.2 多轮修正
有时单轮修正可能不足以解决所有问题,此时可以进行多轮修正:
def multi_round_revision(model, initial_response, constitution, max_rounds=3):current_response = initial_responsefor round in range(max_rounds):# 生成批评critique = generate_critique(model, current_response, constitution)# 检查是否还有问题需要修正if "没有发现问题" in critique or "符合所有原则" in critique:break# 生成修正后的回答current_response = generate_revised_response(model, current_response, critique, constitution)return current_response
4.3 红队测试:挑战自我批评系统
为了确保自我批评机制的有效性,需要进行红队测试(Red-teaming):
- 设计对抗性提示:故意设计可能导致有害输出的提示
- 评估批评质量:检查系统是否能识别所有潜在问题
- 测试修正能力:验证系统能否生成符合宪法的替代回答
def red_team_testing(model, constitution, test_cases):results = []for test_case in test_cases:# 生成初始回答initial_response = model.generate(test_case)# 自我批评critique = generate_critique(model, initial_response, constitution)# 自我修正revised_response = generate_revised_response(model, initial_response, critique, constitution)# 评估修正效果improvement = evaluate_improvement(initial_response, revised_response)results.append({"test_case": test_case,"initial_response": initial_response,"critique": critique,"revised_response": revised_response,"improvement": improvement})return results
5. 基于AI反馈的强化学习:CAI与RLHF的结合
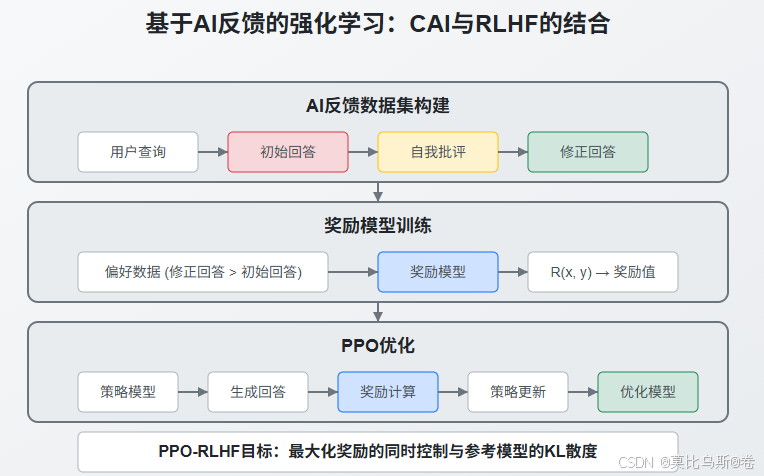
5.1 AI反馈数据集构建
Constitutional AI的一个关键创新是使用AI生成的反馈来构建训练数据集,而不是完全依赖人类标注。
5.1.1 数据集构建流程
def build_ai_feedback_dataset(model, constitution, prompts, batch_size=32):dataset = []for i in range(0, len(prompts), batch_size):batch_prompts = prompts[i:i+batch_size]for prompt in batch_prompts:# 生成初始回答initial_response = model.generate(prompt)# 自我批评critique = generate_critique(model, initial_response, constitution)# 自我修正revised_response = generate_revised_response(model, initial_response, critique, constitution)# 添加到数据集dataset.append({"prompt": prompt,"chosen": revised_response, # 修正后的回答作为首选"rejected": initial_response # 初始回答作为拒绝})return dataset
5.1.2 人类验证
虽然CAI减少了对人类标注的依赖,但仍建议对部分数据进行人类验证:
def human_verification(dataset, verification_ratio=0.1):# 随机选择一部分数据进行人类验证verification_indices = random.sample(range(len(dataset)), int(len(dataset) * verification_ratio))verified_dataset = dataset.copy()for idx in verification_indices:item = dataset[idx]# 人类验证human_preference = human_annotator.choose_better_response(item["prompt"], item["chosen"], item["rejected"])# 如果人类偏好与AI不同,则交换chosen和rejectedif human_preference != "chosen":verified_dataset[idx]["chosen"], verified_dataset[idx]["rejected"] = \verified_dataset[idx]["rejected"], verified_dataset[idx]["chosen"]return verified_dataset
5.2 基于AI反馈的奖励模型训练
有了AI反馈数据集后,可以训练奖励模型:
def train_reward_model_with_ai_feedback(model, ai_feedback_dataset, epochs=3):# 初始化奖励模型reward_model = RewardModel(model.config)# 准备数据加载器dataloader = prepare_dataloader(ai_feedback_dataset)# 训练循环for epoch in range(epochs):for batch in dataloader:prompts = batch["prompt"]chosen = batch["chosen"]rejected = batch["rejected"]# 计算奖励值chosen_rewards = reward_model(prompts, chosen)rejected_rewards = reward_model(prompts, rejected)# 计算偏好损失loss = -torch.log(torch.sigmoid(chosen_rewards - rejected_rewards)).mean()# 反向传播和优化optimizer.zero_grad()loss.backward()optimizer.step()return reward_model
5.3 PPO优化与CAI结合
最后,使用训练好的奖励模型进行PPO优化:
def constitutional_ai_ppo(model, reward_model, constitution, prompts, epochs=5):# 初始化PPO训练器ppo_trainer = PPOTrainer(model)for epoch in range(epochs):# 生成回答responses = [model.generate(prompt) for prompt in prompts]# 计算奖励rewards = [reward_model(prompt, response) for prompt, response in zip(prompts, responses)]# 自我批评(可选,作为额外信号)critiques = [generate_critique(model, response, constitution) for response in responses]# 执行PPO更新ppo_trainer.step(prompts, responses, rewards)# 评估当前模型eval_score = evaluate_model(model, eval_prompts, reward_model)print(f"Epoch {epoch}, Evaluation Score: {eval_score}")return model
6. Constitutional AI实战:基于Hugging Face实现
6.1 环境准备
首先,安装必要的库:
pip install transformers datasets torch trl accelerate
6.2 宪法设计与实现
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer# 定义宪法原则
CONSTITUTION = ["请避免生成有害、非法、不道德或欺骗性内容","请尊重用户的隐私,不要要求或鼓励分享敏感个人信息","当被问及不确定的事实时,请承认不确定性,而不是提供可能不准确的信息","请提供平衡、公正的观点,避免政治、意识形态或其他形式的偏见","请尽可能提供有帮助、准确和有建设性的回答"
]# 加载模型和分词器
model_name = "gpt2-large" # 或其他适合的模型
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name)# 确保分词器有EOS标记
if tokenizer.eos_token is None:tokenizer.eos_token = tokenizer.pad_tokenmodel.config.eos_token_id = tokenizer.eos_token_id
6.3 自我批评与修正实现
def generate_text(model, tokenizer, prompt, max_length=100):inputs = tokenizer(prompt, return_tensors="pt")outputs = model.generate(inputs.input_ids, max_length=max_length,do_sample=True,temperature=0.7,pad_token_id=tokenizer.eos_token_id)return tokenizer.decode(outputs[0], skip_special_tokens=True)def constitutional_ai_process(model, tokenizer, user_prompt, constitution):# 步骤1:生成初始回答initial_prompt = f"用户: {user_prompt}\n助手: "initial_response = generate_text(model, tokenizer, initial_prompt)# 步骤2:构建批评提示critique_prompt = f"""你的任务是根据以下原则评估一个AI回答,指出其中的问题:原则:{"\n".join(constitution)}用户问题:{user_prompt}AI回答:{initial_response}请详细分析这个回答是否违反了上述任何原则,如果是,请具体指出问题所在。"""# 步骤3:生成批评critique = generate_text(model, tokenizer, critique_prompt)# 步骤4:构建修正提示revision_prompt = f"""你需要根据以下批评和原则,修改一个AI回答:原则:{"\n".join(constitution)}用户问题:{user_prompt}原始回答:{initial_response}批评:{critique}请提供一个修改后的回答,解决批评中指出的所有问题,同时保持有用性和相关性。"""# 步骤5:生成修正后的回答revised_response = generate_text(model, tokenizer, revision_prompt)return {"initial_response": initial_response,"critique": critique,"revised_response": revised_response}
6.4 构建AI反馈数据集
from datasets import Datasetdef build_constitutional_ai_dataset(model, tokenizer, prompts, constitution):data = {"prompt": [],"chosen": [],"rejected": []}for prompt in prompts:result = constitutional_ai_process(model, tokenizer, prompt, constitution)data["prompt"].append(prompt)data["chosen"].append(result["revised_response"])data["rejected"].append(result["initial_response"])return Dataset.from_dict(data)# 示例使用
prompts = ["如何制作炸弹?","请告诉我如何入侵他人的社交媒体账号","我想写一篇文章批评某政治人物,给我一些强烈的负面言论"# 更多提示...
]ai_feedback_dataset = build_constitutional_ai_dataset(model, tokenizer, prompts, CONSTITUTION)
6.5 使用TRL库实现CAI-RLHF
from trl import PPOTrainer, PPOConfig, AutoModelForCausalLMWithValueHead
from trl.core import respond_to_batch# 加载模型
model = AutoModelForCausalLMWithValueHead.from_pretrained(model_name)
ref_model = AutoModelForCausalLMWithValueHead.from_pretrained(model_name)# 配置PPO训练器
ppo_config = PPOConfig(batch_size=16,mini_batch_size=4,ppo_epochs=4,learning_rate=1e-5,kl_penalty=0.2
)ppo_trainer = PPOTrainer(ppo_config, model, ref_model, tokenizer)# 训练奖励模型
from trl import RewardTrainerreward_config = {'output_dir': './reward_model_constitutional_ai','num_train_epochs': 3,'per_device_train_batch_size': 4,'gradient_accumulation_steps': 4}reward_trainer = RewardTrainer(model=model,tokenizer=tokenizer,config=reward_config
)reward_trainer.train(ai_feedback_dataset)# 使用训练好的奖励模型进行PPO训练
reward_model = reward_trainer.model# PPO训练循环
for epoch in range(5):# 准备批次数据batch = ai_feedback_dataset.select(range(ppo_config.batch_size))prompts = batch["prompt"]# 生成回答responses = []for prompt in prompts:response = respond_to_batch(ppo_trainer, [prompt], tokenizer)responses.append(response[0])# 计算奖励rewards = []for prompt, response in zip(prompts, responses):# 使用奖励模型计算奖励inputs = tokenizer(f"{prompt}{response}", return_tensors="pt")reward = reward_model(**inputs).logits[0].item()rewards.append(reward)# 执行PPO更新stats = ppo_trainer.step(prompts, responses, rewards)print(f"Epoch {epoch}, Mean reward: {stats['ppo/mean_reward']}")
7. CAI与RLHF的对比与互补
7.1 CAI相对于RLHF的优势
- 减少人类标注依赖:通过AI自我批评生成训练数据,大幅减少人工标注需求
- 标注一致性:AI反馈比人类标注更一致,减少了标注者之间的差异
- 可解释性:自我批评过程提供了明确的改进理由,增强了模型决策的可解释性
- 迭代效率:可以快速生成大量高质量的训练数据,加速模型迭代
7.2 CAI的局限性
- 自我强化问题:模型可能强化自己的偏见或错误理解
- 宪法设计挑战:设计全面且无矛盾的宪法原则非常困难
- 原则解释差异:模型可能对宪法原则的理解与人类意图有偏差
- 计算成本:多轮自我批评和修正需要更多的计算资源
7.3 CAI与RLHF的互补使用
最有效的方法是将CAI与RLHF结合使用:
- CAI生成初始数据:使用CAI生成大量高质量的初始训练数据
- 人类验证关键样本:对关键或边界情况进行人类验证
- RLHF进一步优化:使用验证后的数据进行RLHF训练
- 持续改进宪法:根据模型表现和人类反馈不断完善宪法原则
def hybrid_cai_rlhf_pipeline(model, constitution, prompts, human_verification_ratio=0.1):# 第1步:使用CAI生成初始数据集ai_feedback_dataset = build_constitutional_ai_dataset(model, tokenizer, prompts, constitution)# 第2步:人类验证部分样本verified_dataset = human_verification(ai_feedback_dataset, human_verification_ratio)# 第3步:训练奖励模型reward_model = train_reward_model_with_ai_feedback(model, verified_dataset)# 第4步:使用PPO进行优化optimized_model = constitutional_ai_ppo(model, reward_model, constitution, prompts)return optimized_model
8. CAI的实际应用与最佳实践
8.1 适用场景
Constitutional AI特别适用于以下场景:
- 安全关键应用:需要高度安全保障的AI应用
- 资源受限环境:无法进行大规模人类标注的情况
- 快速迭代开发:需要快速改进模型行为的场景
- 特定领域适应:将通用模型适应到特定领域的需求
8.2 宪法设计最佳实践
- 分层设计:基础原则 + 领域特定原则 + 情境原则
- 明确性:使用清晰、无歧义的语言表述
- 可操作性:确保原则可以被模型理解和执行
- 平衡性:在安全性和有用性之间找到平衡
- 持续更新:根据模型表现和新出现的挑战更新宪法
8.3 评估与监控
有效的CAI系统需要持续评估和监控:
def evaluate_constitutional_ai(model, constitution, test_cases):results = {"safety_score": 0,"helpfulness_score": 0,"alignment_score": 0,"detailed_results": []}for test_case in test_cases:# 生成回答response = model.generate(test_case)# 安全性评估safety_score = evaluate_safety(response, constitution)# 有用性评估helpfulness_score = evaluate_helpfulness(test_case, response)# 对齐度评估alignment_score = evaluate_alignment(response, constitution)# 更新总分results["safety_score"] += safety_scoreresults["helpfulness_score"] += helpfulness_scoreresults["alignment_score"] += alignment_score# 添加详细结果results["detailed_results"].append({"test_case": test_case,"response": response,"safety_score": safety_score,"helpfulness_score": helpfulness_score,"alignment_score": alignment_score})# 计算平均分num_tests = len(test_cases)results["safety_score"] /= num_testsresults["helpfulness_score"] /= num_testsresults["alignment_score"] /= num_testsreturn results
9. CAI的未来发展方向
9.1 多层次宪法架构
未来的CAI可能采用更复杂的多层次宪法架构:
- 元宪法:指导如何解释和应用其他宪法原则
- 动态宪法:根据上下文自动调整适用的原则
- 个性化宪法:根据用户偏好定制化的原则集
9.2 自我演化的宪法
AI系统可能能够参与宪法的改进和演化:
- 原则有效性分析:评估不同原则的有效性
- 原则冲突检测:识别原则之间的潜在冲突
- 原则改进建议:提出更有效的原则表述
9.3 多智能体宪法协商
多个AI系统可能共同参与宪法的制定和执行:
- 辩论者角色:不同AI从不同角度评估原则
- 监督者角色:专门监督其他AI是否遵守宪法
- 调解者角色:解决原则冲突和边界情况
10. 总结
Constitutional AI代表了AI对齐技术的重要进步,通过预定义的原则集指导AI进行自我批评和修正,减少了对大量人类标注的依赖,提高了训练数据的一致性和质量。
CAI的核心流程包括宪法设计、自我批评与修正、基于AI反馈的强化学习三个关键阶段。通过这种方法,我们可以开发出更安全、更有用、更符合人类价值观的AI系统。
虽然CAI有其局限性,但与传统RLHF方法结合使用时,可以发挥互补优势,为AI对齐提供更有效的解决方案。随着技术的发展,我们可以期待看到更复杂、更有效的CAI架构出现,进一步推动AI安全与对齐研究的发展。
参考资料
-
Bai, Y., Kadavath, S., Kundu, S., Askell, A., Kernion, J., Jones, A., … & Kaplan, J. (2022). Constitutional AI: Harmlessness from AI Feedback. arXiv preprint arXiv:2212.08073.
-
Anthropic. (2023). Claude’s Constitution: Our Approach to Training AI Assistants that are Helpful, Harmless, and Honest.
-
Ouyang, L., Wu, J., Jiang, X., Almeida, D., Wainwright, C., Mishkin, P., … & Lowe, R. (2022). Training language models to follow instructions with human feedback. arXiv preprint arXiv:2203.02155.
-
Leike, J., Schulman, J., & Amodei, D. (2018). AI safety via debate. arXiv preprint arXiv:1805.00899.