【模型训练篇】VeRL分布式基础 - 框架Ray
前两篇文章简单复习了训练框架 ①英伟达的Megatron 和 ②Hugging face的TRL,接着学习一下字节家的VeRL,很牛的一个框架,所以准备分五篇文章介绍:
- 底层分布式能力基础
Ray VeRL的原理,也就是那篇论文VeRL的使用,普通RL(单轮RL)VeRL的使用,Agentic RL(多轮RL)VeRL的魔改
下面先介绍一下VeRL等众多RL框架的分布式基础,Ray 
架构
以下内容会结合Ray17年的论文 【Ray: A Distributed Framework for Emerging AI Applications】,虽然年头久了点,但核心思想依然可以借鉴,只不过架构、细节等内容会以今天2025年8月31日(版本 Ray-2.49.0)为准。
首先Ray最令人熟知(最出圈儿)的东西就是 通过@ray.remote这个装饰器 decorator,让普通方法/类具备分布式远程计算能力,但经过这7/8年的发展Ray已经进化成了一个庞然大物;
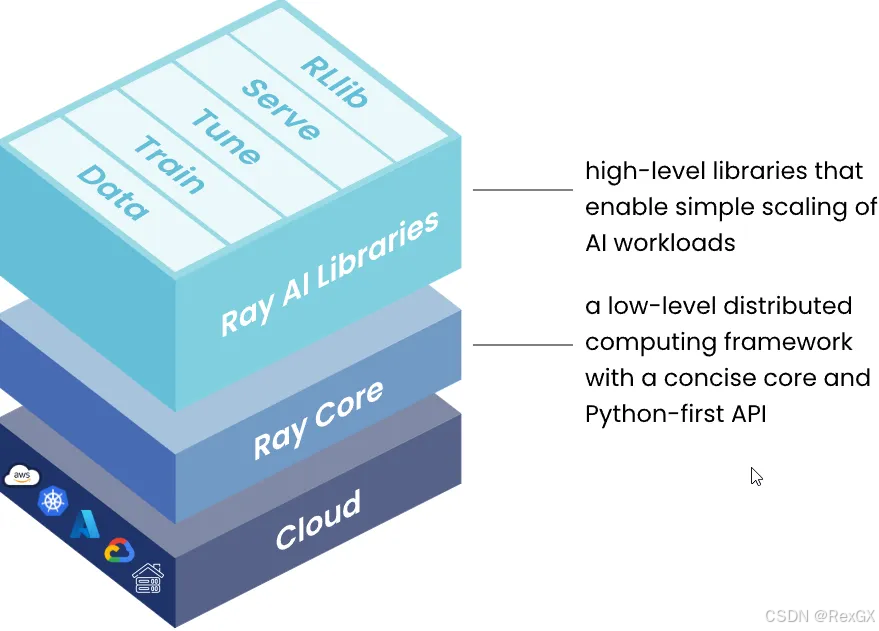
- 架构上分为三层,可以从下往上看:
- 首先是
Ray Cluster,也就是分布式集群,集群中的角色分为:主理人ray head和 打工人ray worker,可以部署在公有云/私有云上 - 然后是
Ray Core,和很多其他框架一样(例如Megatron Core)把一些核心能力抽象出API,对外暴露 - 最上层
Ray AI Lib,专为机器学习设计的tookit
- 其中
Ray AI Lib又可以分为五大类:处理数据的Data,分布式训练的Train、超参调优的Tune、inference部署的Serve、强化学习RLLib
安装
pip install -U "ray[data,train,tune,serve,rllib]"括号内想用啥就安装啥- 或是直接用docker
docker run -t -i rayproject/ray
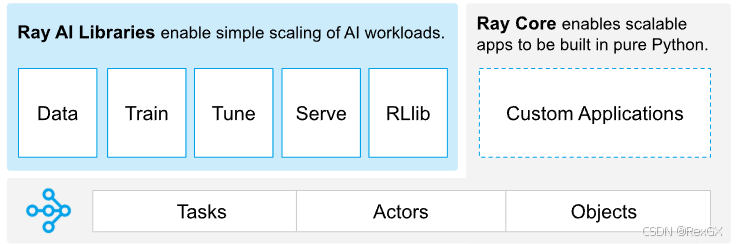
核心思想 - Ray Core
先看Ray Core,需要首先理解几个Ray中的核心概念:
Task:只需要以下3步,就可以把 普通函数 变成 分布式远程执行的函数,看注释:
@ray.remote # 1. 用 @ray.remote装饰器 包上你的方法
def square(x):return x * x
futures = [square.remote(i) for i in range(4)] # 2. 使用 .remote() 执行远程调用,此时是异步的,返回的是future对象
print(ray.get(futures)) # 3. 同步执行 ray.get(future) 获取最终结果 -> [0, 1, 4, 9]
Actor:与 无状态的Task 不同,Actor是 有状态的 ,只需要以下4步(因为是类所以多一步创建对象)就可以把 普通类class 变成 分布式远程执行的类class,看注释:
@ray.remote # 1. 用 @ray.remote装饰器 包装上你的类
class Counter:def __init__(self):self.i = 0def get(self):return self.idef incr(self, value):self.i += valuec = Counter.remote() # 2. 创建了一个远程的actor对象for _ in range(10):c.incr.remote(1) # 3. 异步调用,但是在remote那是串行执行的print(ray.get(c.get.remote())) # 4. 通用使用 ray.get 获取异步结果, -> 10
Objects:Ray使用 分布式存储 管理集群中的数据:
- task和actor返回的数据,都会自动存储在分布式存储中,拿到的都是对象的引用,而这个引用又可以在task或actor中高效传递
- 自己管理的一些对象,则可以使用
ray.put()把数据存入分布式存储
Ray worker指的是一个Python进程,虽然都是给task和actor干活,但处理方式却不同:
- 1个
Ray worker可以执行 多个task ,默认的每个Ray的节点在启动的时候都会自动创建一些worker,reuse这些worker去执行task - 1个
Ray worker只能处理 1个actor ,只有在执行你的actor.remote()的时候才会创建worker(lazy),所有这个对象的方法都在这个worker进程上执行,不同于执行task的worker会reuse,执行actor的worker执行完毕就被删掉
scheduling,执行task或actor的时候可以指定执行的资源resource,每个工作节点node的状态分成:
-
完全不行:如果指定跑在GPU上,但这个节点只有CPU,那就是完全不行,直接“达卖”
-
不可用:指定的资源有,但现在被其他任务占着,所以只是暂时不可用
-
可用:指定的资源有,并且可用
同时
scheduling策略又分成两种: -
默认的default:会给每个节点的资源利用率打分,每次选的时候会从利用最低的节点里选阶段执行,但会综合考虑资源利用率和load-balance(比如加random逻辑),但如果直接指定
@ray.remote(num_gpus=0)就纯随机了 -
spread,从名字上就可以看出来,会把task或actor铺开了运行在可用节点上,
通过resource来指定你的task或actor需要的资源:
例如:
@ray.remote(num_cpus=0, gputs=0.25),此外可以加很多节点亲和性的策略(了解k8s的人应该很熟悉)例如通过label指定任务跑在H100上;
bundle和placement group都是 资源集合:
-
但bundle最终是要部署在一个单独的节点node上的,例如
{"cpu":1,"gpu":2}可以部署在{"cpu":4,"gpu":2}的节点上,但如果指定bundle为{"cpu":1,"gpu":5}就不行了 -
而placement group是在集群cluster上的
bundle和placement groupfit到node或cluser之后,那部分资源就相当于 **被预留(占用) **了,使用方式: -
首先创建placement_group:
pg = placement_group([{"CPU": 1, "GPU": 1}]) -
然后指定你的task或actor使用这个pg:
actor_class.options(placement_group=pg)
fault tolerance既然是分布式计算就必需考虑容错问题,Ray把异常分成两类:
- 用户自己写的bug触发异常,这种user异常最常见的做法就是catch、retry或者cancel task/actor
- 节点异常、ray本身的异常等等都会触发特定的异常兜底机制
Ray Graph可以自定义DAG,但截止今天20250831还是beta版本,就不说了
数据处理 - Ray Data
Ray Data 主要就是 分布式数据Dataset ,和PyTorch中的使用方式没啥区别,处理数据加载和处理;
- 但它的API都是 lazy 的,也就是只有在 真正 触发使用的时候才执行
- 同时既然是分布式就一定会 分片,partition之后之后的颗粒度是
Block,并行处理Dataset的时候其实处理的是Block
分布式训练 - Ray Train
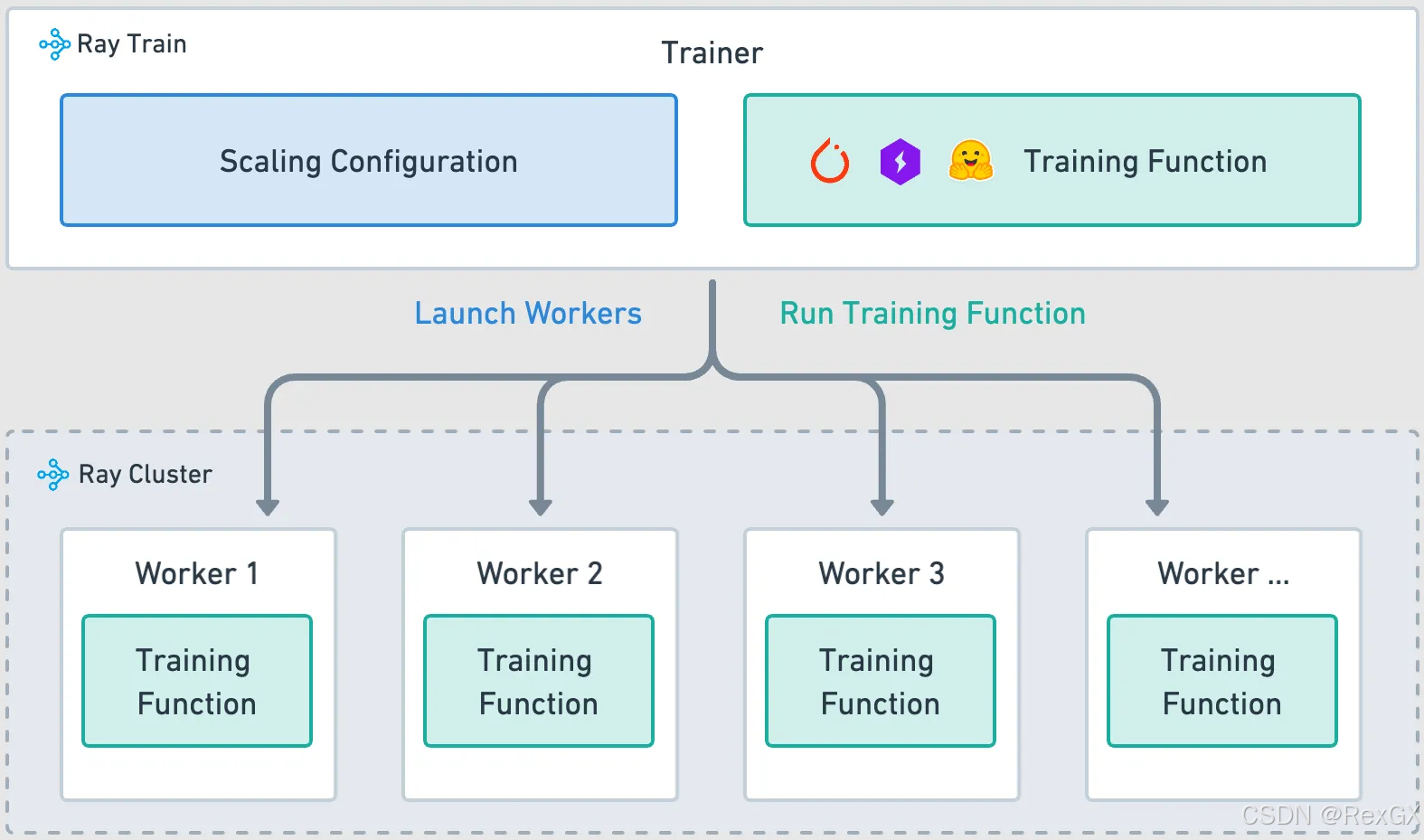
Ray Train用于分布式训练和微调,自称 simplest solution 哦,架构如上图所示:
training function:就是训练逻辑的Python函数(模型加载、数据集加载、模型训练、checkpoints保存、metrics logging等等),分布式环境下,每个worker执行这个function的逻辑worker:每个worker都是一个独立进程,执行上面的 training functionscaling configuration:指定worker的数量和计算资源(cpu/gpu),scaling_config = ScalingConfig(num_workers=4, use_gpu=True)Trainer:整合上面三个东西,Ray本身提供了一些开箱即用的Trainer,直接调fit()方法即可,trainer = xxTrainer(train_func, scaling_config=scaling_config); trainer.fit()
其中train_func中的数据可以使用Ray Data处理,例如切分数据时 ray.get_dataset_shard() 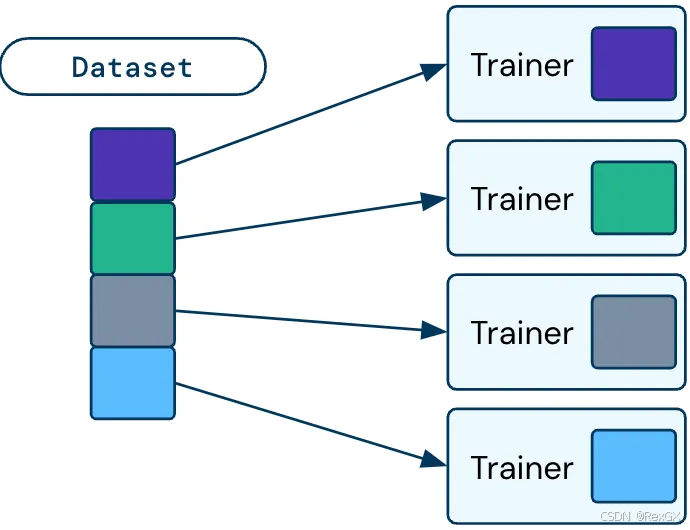
超参调优 - Ray Tune
Ray Tune用于超参调优,支持很多种算法和工具,个人理解这些工具底层逻辑就是在做 末位淘汰;
以PBT/Population Based Training为例:将并行训练的多个模型称作"种群",每个模型模型独立进行梯度下降,定期与其他模型交互调整超参,对于性能靠后的百分之xx的模型的超参,直接替换成高性能的(末位淘汰既视感),同时加上 扰动 以探索更优配置。
下面展示一个最基础的Ray Tune示例,细节看注释:
# 基础信息准备
class Model(nn.Module)... # 省略模型定义
def train_func()... # Ray Train 中worker执行的逻辑,也就是目标函数
def trainable().. # 入口函数
trainable_with_gpu = tune.with_resources(trainable, {"cpu":2, "gpu":2}) # 指定资源
search_space = {"lr": tune.choice([1,2,3]), "momentum": tune.unfiform(0.1, 0.9)} # 定义超参可以sample的搜索空间,有很多开箱即用的API
algo = BayesOptSearch() # 定义搜索算法
scheduler = ASHAScheduler() # 定义调度器,用于控制何时停止tune,并指定了每轮淘汰比例
tuner = tune.Tuner(trainable_with_gpu, param_space=search_space, tune_config=tune.TuneConfig(search_alg=algo, scheduler=scheduler)) # 定义Tuner封装整个流程
results = tuner.fit() # 启动
best_result = results.get_best_result(metric="loss", mode="min") # 获取最佳结果
Inference部署 - Ray Serve
Ray Serve除了像其他框架可以serve模型外,它还是个 end-to-end 的分布式应用框架,因为大部分模型serveing框架都是 tensor-in、tensor-out的,但还需要额外搭配处理业务逻辑、http请求、扩容缩容… 而Ray Serve对它们进行了 整合,可以构建LLM应用。
下面时一个最基础的翻译模型:
from transformers import pipeline # File name: model.py
class Translator:def __init__(self):self.model = pipeline("translation_en_to_fr", model="t5-small") # Load modeldef translate(self, text: str) -> str:model_output = self.model(text) # inferencetranslation = model_output[0]["translation_text"] # returnreturn translation
translator = Translator()
translation = translator.translate("Hello world!")
print(translation)
只需要两步,就可以把它变成Ray Server APP
from transformers import pipeline
@serve.deployment(num_replicas=2, ray_actor_options={"num_cpus": 0.2, "num_gpus": 0}) # 1. 定义depolyment
class Translator:def __init__(self):self.model = pipeline("translation_en_to_fr", model="t5-small")def translate(self, text: str) -> str:model_output = self.model(text)translation = model_output[0]["translation_text"]return translationasync def __call__(self, http_request: Request) -> str: # 2. 定义 __call__ 用于处理http请求english_text: str = await http_request.json()return self.translate(english_text)
其中 @serve.deployment 的装饰器decorator 通过它指定:①部署app instance个数num_replicas通过它实现扩缩容 ②每个instance的配置,需要多少资源
然后的运行部署,可以把配置都放到 .yaml 文件里,然后通过 CLI serve run xx.yaml 启动即可。
强化学习 - Ray RL lib
RayLib 专用于RL的开源库,内置了些经典算法(例如PPO),也支持自定义算法扩展,但其实不会有人直接用的,像VeRL等框架都自己实现的,所以知道有就行;
下面是PPO的基础示例,细节看注释:
from ray.rllib.algorithms.ppo import PPOConfig
config = (PPOConfig().environment("xx") # 自定义环境,需实现例如 step(action)方法,输入action,输出reward、next_state等信息.framework("torch") # 选框架torch.resources(num_gpus=1) # 指定资源.rollouts(num_rollout_workers=4) # 并行rollout数量.training(lr=0.001, gamma=0.99) # 设置超参
)
algo = config.build() # 构建算法实例
for i in range(10):result = algo.train() # 执行一次训练迭代print(f"Iter {i}: Mean reward = {result['episode_reward_mean']}")
algo.save("checkpoint_dir") # 保存
集群架构
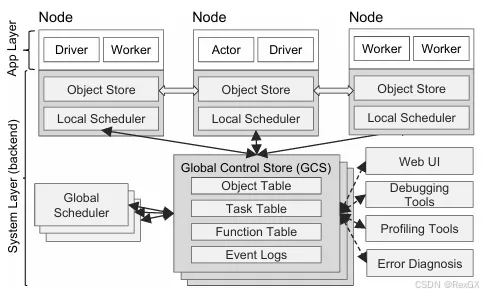
整个Ray Cluster包含1个主理人head节点和多个打工人worker节点:
- head节点负责:GCS(global control service 集群管理)、自动扩缩容(k8s的side-car)、执行job
- worker节点:执行 Ray Task 或 Ray Actor 的代码(其中执行job的worker叫做
driver)
以上内容稍微流水账了点,毕竟是基础内容,下篇文章开始介绍VeRL,先看下它的那片论文。