【Spring Cloud微服务】7.拆解分布式事务与CAP理论:从理论到实践,打造数据一致性堡垒
目录
一、引言:为什么我们需要分布式事务?
一个熟悉的场景引入
从单体到分布式的问题演变
二、基石:ACID、CAP与BASE理论
1. ACID:传统事务的四大护法
2. CAP定理:分布式系统的“三选二”困局
3. BASE理论:对ACID的柔性扩展
三、主流分布式事务解决方案深度解析
1. 强一致性方案
2PC(两阶段提交) - 协调者的主导
1.执行流程:
2.如何实现:
2.1 两种实现模式
2.2技术选型与组件
2.3代码实现示例(Spring Boot + Atomikos + MySQL)
1. 添加依赖 (pom.xml)
2. 配置多数据源 (application.yml)
3. 数据源配置类 (Java Config)
4. 业务服务层 (Service Layer)
2.4实现2PC的关键注意事项和最佳实践
2.5 优缺点
2. 最终一致性方案(主流)
TCC(尝试-确认-取消) - 补偿型事务
2.1 什么是TCC
2.2TCC模式的核心特点:
2.3 实现案例
2.3.1实现模式
2.3.2相关步骤(以Seata为例)
步骤 1: 环境准备与依赖引入
步骤 2: 设计数据库表
步骤 3: 编写TCC服务接口与实现(核心)
步骤 4: 编写全局事务入口(发起者)
2.3.3需要注意的核心要点
2.4最佳实践与总结
2.5 流程解析
成功提交流程
失败回滚流程
Saga模式 - 长事务的解决方案
基于消息队列的最终一致性
方案一:本地消息表
方案二:RocketMQ事务消息(推荐)
RocketMQ 事务消息的核心特点:
事务成功,发送Commit指令
事务失败,发送Rollback指令
事务未知,Broker发起事务回查
四、方案对比与选型指南
横向对比表格
选型核心考量因素
五、总结与展望
核心总结
最佳实践提醒
未来展望
六、互动与思考
在微服务与云原生时代,如何确保跨服务的数据操作要么全部成功,要么全部失败?本文将带你深入理解2PC、TCC、Saga、消息事务等主流方案。
想象一个再常见不过的电商下单流程:
- 订单服务:创建一个“待支付”状态的订单。
- 库存服务:扣减商品库存。
- 积分服务:为用户增加本次消费对应的积分。
在单体应用时代,这三个操作共享同一个数据库连接,一个简单的本地事务@Transactional就能保证它们“同生共死”。但在微服务架构下,每个服务都有自己独立的数据库,问题变得复杂了。
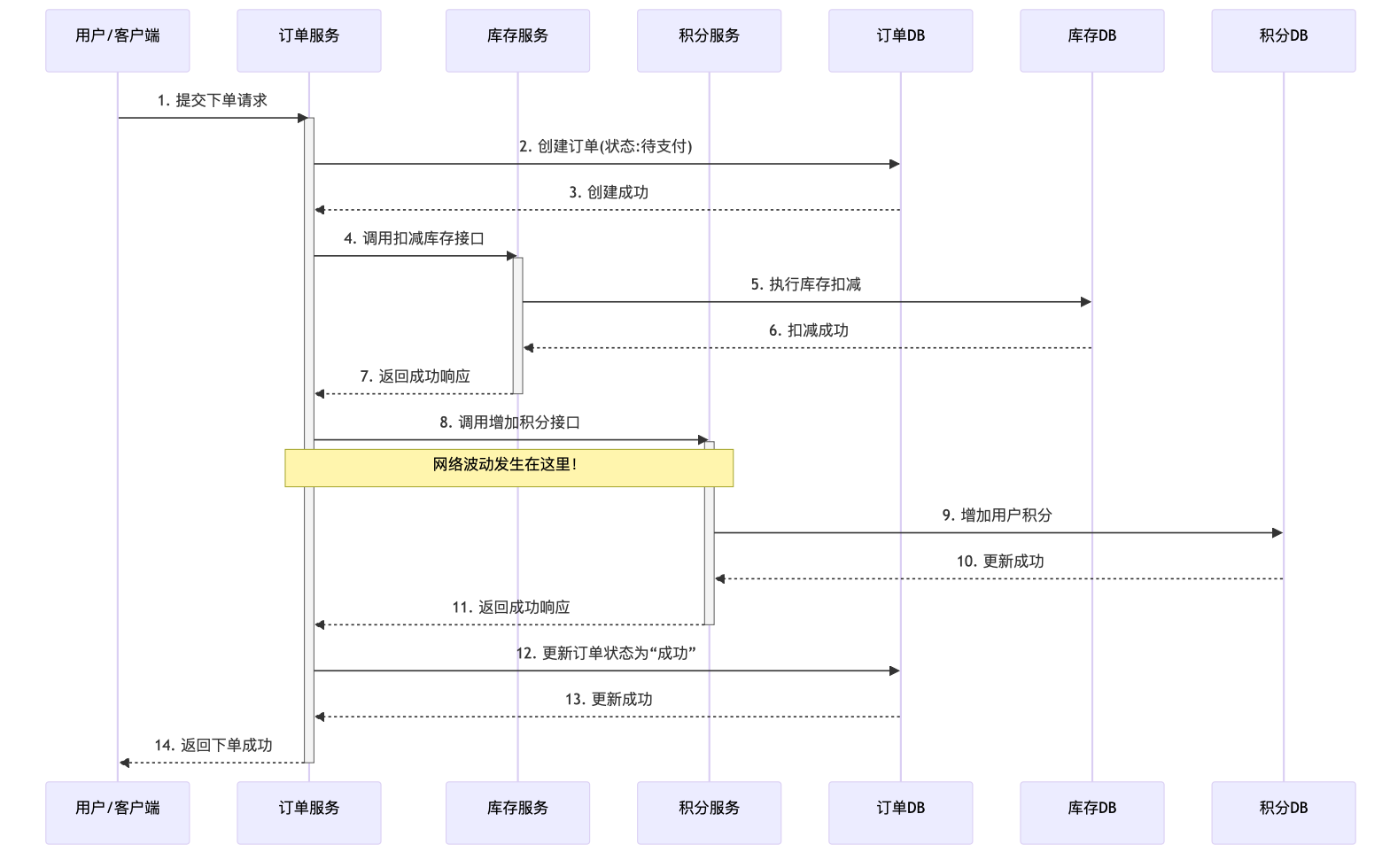
如果扣减库存成功,但调用积分服务时网络突然波动,请求超时了,会发生什么?
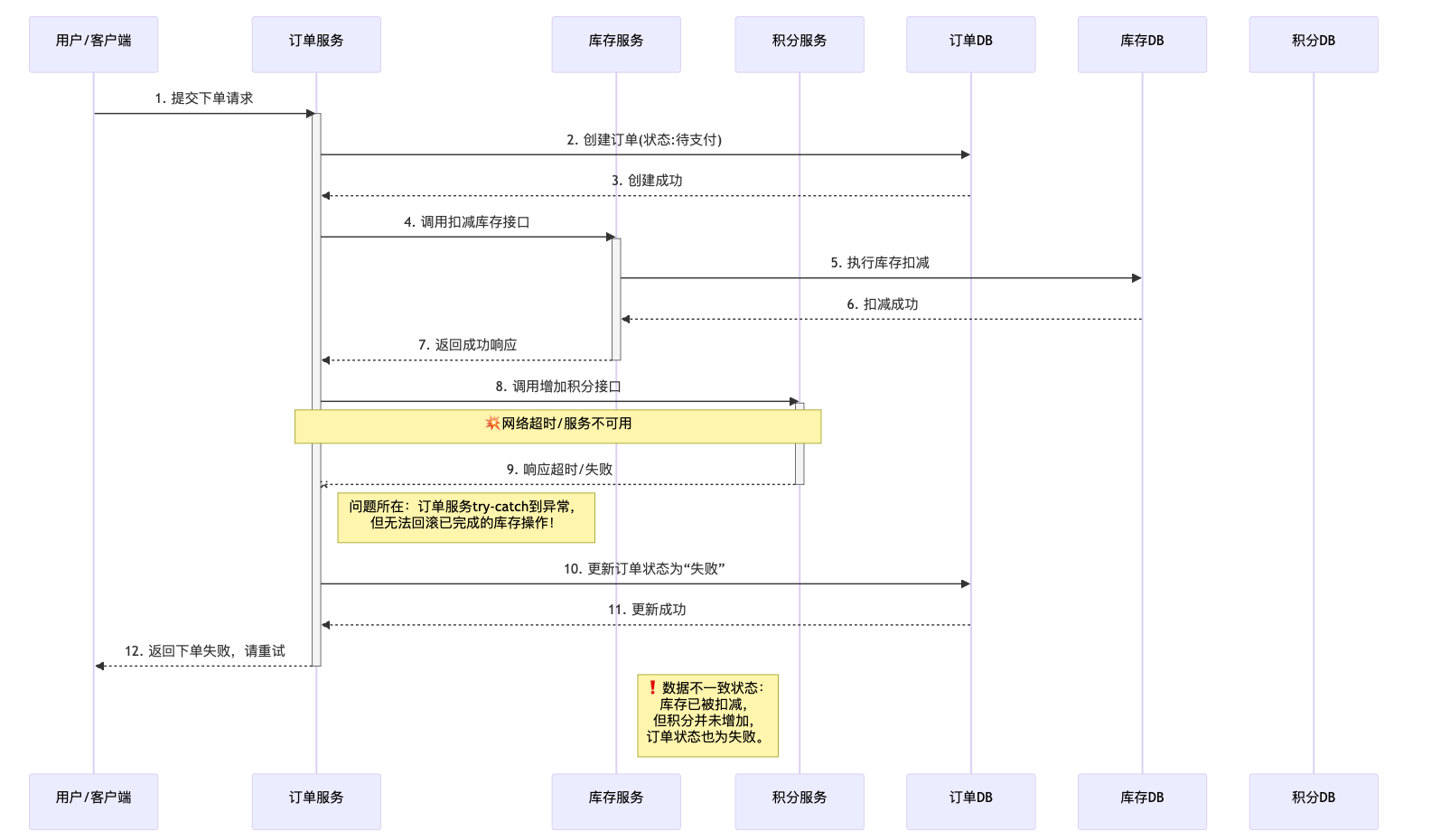
- 用户成功下单,库存也被扣了。
- 但用户的积分却没有到账。
- 结果:数据不一致了。用户体验受损,商家可能还需要人工介入处理。
这就是分布式事务要解决的核心问题:在分布式系统下,如何保证一系列跨服务、跨数据库的操作仍然满足事务的ACID特性,尤其是原子性(Atomicity)?
单体应用依靠数据库的本地事务,轻松实现了ACID。但微服务架构带来了新的挑战:
- 网络不可靠:网络延迟、超时、丢包会导致通信失败。
- 服务可用性:任何一个参与事务的服务都可能宕机。
- 性能瓶颈:传统的强一致性方案可能带来巨大的性能开销。
分布式事务就是在这样的背景下,为解决这些新复杂性而诞生的一套技术方案。
要理解各种解决方案,必须先掌握其背后的理论根基。
ACID是数据库事务正确执行的四个基本要素的缩写:
- 原子性(Atomicity):事务中的所有操作要么全部完成,要么全部不完成。
- 一致性(Consistency):事务执行前后,数据库必须从一个一致性状态变换到另一个一致性状态。
- 隔离性(Isolation):并发事务之间互不干扰。
- 持久性(Durability):事务完成后,对数据的修改是永久的。
在单数据源下,ACID由数据库完美保障。但在分布式环境下,我们无法奢求一个“分布式数据库”来为我们隐藏所有复杂性,必须做出权衡。
CAP定理指出,一个分布式系统最多只能同时满足一致性(Consistency)、可用性(Availability)和分区容错性(Partition tolerance)这三项中的两项。
- C(一致性):所有节点访问同一份最新的数据副本。
- A(可用性):每次请求都能获取非错的响应,但不保证数据是最新的。
- P(分区容错性):系统在遇到任何网络分区故障时,仍能对外提供一致性和可用性的服务。
核心结论:由于网络分区(P)在分布式系统中是必然存在的(你无法保证网络100%可靠),因此我们实际上只能在C(一致性) 和 A(可用性) 之间做选择。
- CP系统:如 ZooKeeper, etcd。当网络发生分区时,为了保证一致性,系统会拒绝写入或读取,牺牲可用性。
- AP系统:如 Eureka, Cassandra。当网络发生分区时,系统依然可用,但返回的数据可能不是最新的,牺牲一致性。
设计分布式事务方案时,首先就要问自己:我的业务场景更倾向于CP还是AP?
BASE理论是对CAP中AP方案的延伸,是互联网大规模分布式实践的总结,其核心思想是放弃强一致性,拥抱最终一致性。
- Basically Available(基本可用):系统在出现不可预知故障时,允许损失部分可用性(如响应时间变长、功能降级)。
- Soft state(软状态):允许系统中的数据存在中间状态,并且认为该中间状态的存在不会影响系统的整体可用性。
- Eventually consistent(最终一致性):经过一段时间后,所有数据副本最终能够达到一致的状态。
BASE理论是大部分最终一致性分布式事务方案(如TCC、Saga、消息事务)的理论基础。
两阶段提交引入了一个协调者(Coordinator) 来管理多个参与者(Participant) 的事务提交过程。
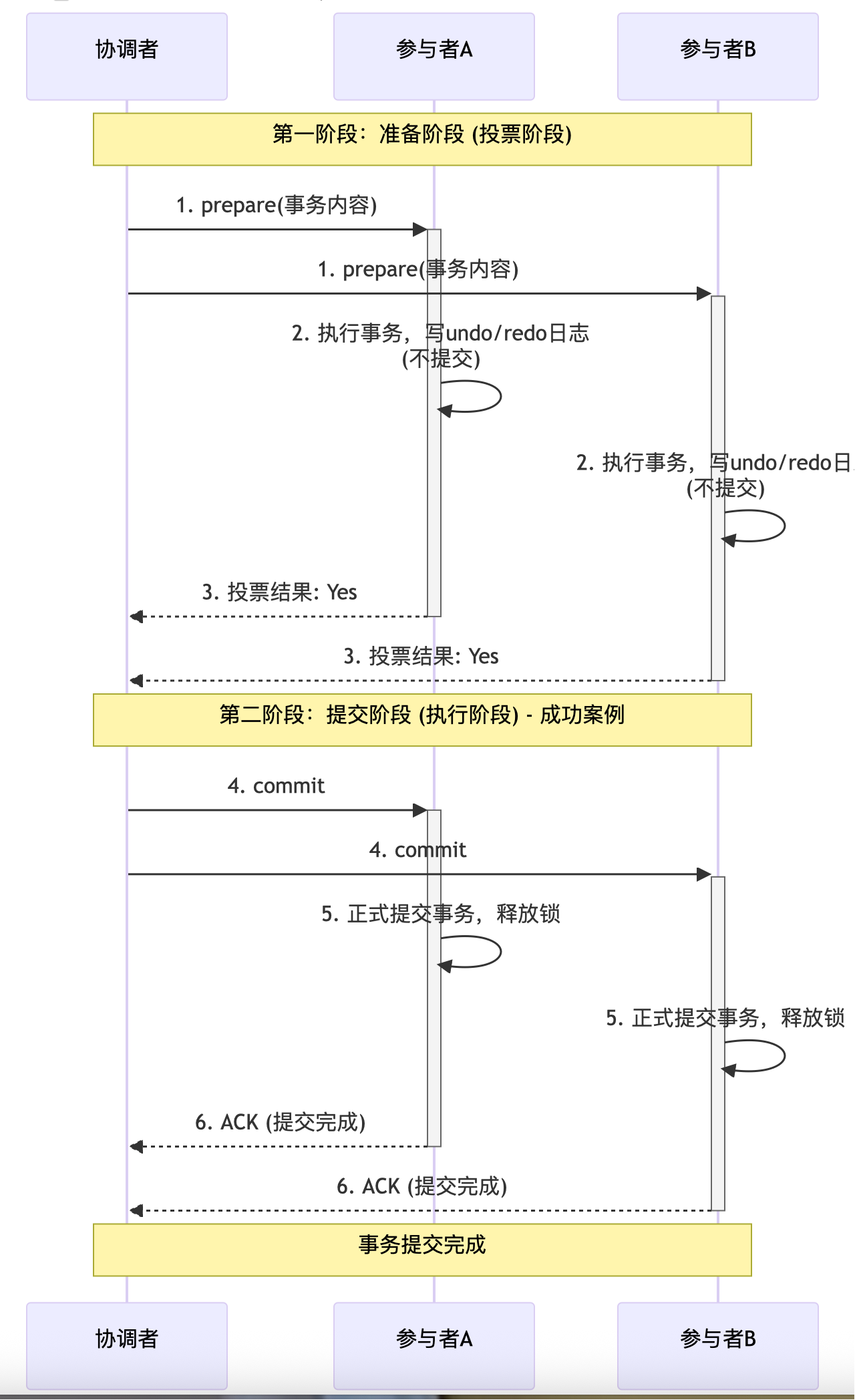
第一阶段:准备阶段
-
协调者向所有参与者发送
prepare请求,并携带事务内容。 -
参与者执行本地事务,写入undo/redo日志,但不提交。
-
参与者返回执行结果(成功/失败)给协调者。
第二阶段:提交/回滚阶段
-
如果所有参与者都返回“成功”,协调者发送
commit请求。 -
如果有任何一个参与者返回“失败”,协调者发送
rollback请求。 -
参与者根据协调者的指令执行最终操作(提交或回滚),并释放资源,最后向协调者发送ACK。
2PC通常有两种实现方式:
- 基于标准XA协议(数据库层面):
- 由数据库和资源管理器(RM)原生支持(如MySQL的InnoDB引擎)。
- 应用程序充当协调者(通过一个库或驱动),数据库充当参与者。
- 这是最“标准”的2PC实现。
- 基于自定义协调者(应用层面):
- 在应用层自己实现一个协调者(Transaction Coordinator)组件。
- 各个微服务作为参与者(Participant),暴露准备(prepare)、提交(commit)、回滚(rollback)接口。
- 这种方式更灵活,但需要自己处理所有复杂逻辑。
要实现基于XA的2PC,你需要:
- 支持XA的数据库:MySQL(InnoDB)、PostgreSQL、Oracle等。
- 支持XA的Java JDBC驱动:通常数据库驱动都支持。
- 一个XA事务管理器:
- 独立的TM:如Atomikos、Bitronix。这些是成熟的Java库,可以嵌入到你的应用中。
- 应用服务器提供的TM:如Java EE应用服务器(WebLogic, WebSphere, WildFly)都内置了XA事务管理器。
- Spring Boot集成:Spring Boot可以非常方便地集成Atomikos,通过s
pring-boot-starter-jta-atomikosstarter。
以下是一个在Spring Boot项目中实现XA分布式事务的详细步骤。
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-jta-atomikos</artifactId>
</dependency>
<dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId>
</dependency>
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>
spring:jta:enabled: truelog-dir: ./atomikos-logs # Atomikos日志目录datasource:orders-db:unique-resource-name: ordersDBxa-data-source-class-name: com.mysql.cj.jdbc.MysqlXADataSourcexa-properties:url: jdbc:mysql://localhost:3306/orders_dbuser: rootpassword: passwordpool-size: 5users-db:unique-resource-name: usersDBxa-data-source-class-name: com.mysql.cj.jdbc.MysqlXADataSourcexa-properties:url: jdbc:mysql://localhost:3306/users_dbuser: rootpassword: passwordpool-size: 5jpa:hibernate:ddl-auto: updateproperties:hibernate:dialect: org.hibernate.dialect.MySQL8Dialecttransaction:jta:platform: atomikos # 指定JTA平台为Atomikos
@Configuration
public class DataSourceConfig {@Primary@Bean("ordersDataSource")@ConfigurationProperties(prefix = "spring.datasource.orders-db")public DataSource ordersDataSource() {return new AtomikosDataSourceBean(); // 包装为XA数据源}@Bean("usersDataSource")@ConfigurationProperties(prefix = "spring.datasource.users-db")public DataSource usersDataSource() {return new AtomikosDataSourceBean();}@Primary@Bean("ordersEntityManagerFactory")public LocalContainerEntityManagerFactoryBean ordersEntityManagerFactory(EntityManagerFactoryBuilder builder,@Qualifier("ordersDataSource") DataSource dataSource) {return builder.dataSource(dataSource).packages("com.example.model.order") // 订单实体所在包.persistenceUnit("ordersPU").jta(true) // 启用JTA.build();}@Bean("usersEntityManagerFactory")public LocalContainerEntityManagerFactoryBean usersEntityManagerFactory(EntityManagerFactoryBuilder builder,@Qualifier("usersDataSource") DataSource dataSource) {return builder.dataSource(dataSource).packages("com.example.model.user") // 用户实体所在包.persistenceUnit("usersPU").jta(true).build();}
}
@Service
public class DistributedTransactionService {@Autowiredprivate OrderRepository orderRepository; // 使用 ordersDataSource@Autowiredprivate UserRepository userRepository; // 使用 usersDataSource@Transactional(transactionManager = "jtaTransactionManager") // 关键:使用JTA事务管理器public void placeOrder(Order order, User user) {// 第一阶段:准备阶段(Prepare Phase)// 以下所有操作都在同一个全局事务中// 1. 操作订单数据库orderRepository.save(order);// 2. 操作用户数据库(例如更新用户积分)user.setPoints(user.getPoints() - order.getPointsUsed());userRepository.save(user);// 如果任何一步抛出异常,全局事务管理器(Atomikos)会自动回滚两阶段的所有操作// 如果全部成功,事务管理器会提交两阶段// 第二阶段(提交/回滚)由Atomikos自动处理,对开发者透明}
}
- 性能瓶颈:
- 2PC是同步阻塞协议。在准备阶段,所有参与者都会锁定资源,直到收到协调者的指令。这意味着连接和资源会被长时间占用,在高并发场景下性能很差。
- 优化:尽量让事务范围变小,执行速度变快。
- 单点问题 (SPOF):
- 协调者(本例中是Atomikos)是单点。如果它所在的应用服务器宕机,会导致所有进行中的事务处于不确定状态。
- 解决:确保协调者本身的高可用。对于Atomikos,它是嵌入在应用中的,所以需要让你的应用本身成为集群,但这会很复杂。更高级的分布式事务框架(如Seata)提供了独立的TC(事务协调者)服务器,可以部署集群。
- 数据不一致风险:
- 在第二阶段,如果协调者只发送了部分Commit指令后就宕机,部分参与者提交了,另一部分没收到指令,就会导致数据不一致。
- 解决:人工干预是最后的兜底方案。你必须记录下全局事务ID和各个参与者的事务状态,并提供后台功能用于查询和手动修复(提交或回滚)那些状态不确定的事务。
- 超时机制:
- 必须为2PC的各个阶段设置超时。如果一个参与者长时间不响应准备请求,协调者应超时并发起全局回滚,防止资源一直被锁定。
- 日志持久化:
- 协调者必须在发送准备请求之前将全局事务状态持久化到日志中。这样即使协调者宕机重启,也能从日志中恢复事务状态并继续处理。Atomikos等成熟框架已经帮你做了这件事。
总结:何时使用2PC?
| 场景 | 推荐度 | 理由 |
|---|---|---|
| 传统金融核心系统 | ⭐⭐⭐⭐⭐ | 需要强一致性,可以接受性能损耗 |
| 内部管理系统 | ⭐⭐⭐⭐ | 并发不高,业务逻辑简单,需要强一致 |
| 高并发互联网业务 | ⭐ | 不推荐。性能瓶颈和同步阻塞问题会严重拖累系统 |
对于大多数互联网微服务场景,最终一致性方案(TCC、Saga、消息事务)通常是比2PC更好的选择,它们用更柔性的方式(最终一致)换取了更高的性能和可用性。
实现2PC的最佳方式是借助成熟的JTA事务管理器(如Atomikos) 和支持XA的数据库,而不是自己从头实现协调者的所有逻辑,因为这其中的复杂性(日志、恢复、超时)非常容易出错。
- 优点:概念简单,实现了强一致性。
- 缺点:
- 同步阻塞:所有参与者在等待协调者指令时都处于阻塞状态,占用的资源无法释放,性能差。
- 单点问题:协调者至关重要,一旦宕机,参与者将一直处于不确定状态。
- 数据不一致:在第二阶段,如果部分参与者收到了commit并成功提交,但协调者宕机,导致其他参与者未收到commit,就会发生数据不一致。
- 适用场景:数据库内部(如MySQL XA协议)、传统金融核心系统等对一致性要求极高且并发量不大的场景。
TCC要求每个业务操作都需要拆分为三个操作:
- Try:尝试执行。完成所有业务的检查,并预留必需的业务资源。
- 例如:检查库存是否充足,然后不是直接扣减,而是“冻结”相应数量的库存。
- Confirm:确认执行。真正执行业务,使用Try阶段预留的资源。此操作必须幂等。
- 例如:将Try阶段“冻结”的库存真正地“扣减”掉。
- Cancel:取消执行。释放Try阶段预留的资源。此操作必须幂等。
- 例如:将Try阶段“冻结”的库存“解冻”,恢复可用。
- 业务侵入性:需要业务系统自行实现Try、Confirm、Cancel三个接口,对业务代码改造较大。
- 最终一致性:通过两阶段操作(预留资源 -> 确认/取消)实现了分布式事务的最终一致性。
- 性能优势:相比2PC,资源锁定时间较短(只在Try阶段锁定),并发性能更好。
- 可靠性:通过Confirm/Cancel操作的幂等性设计,能够有效处理网络重试等问题。
TCC模式非常适合执行时间短、对一致性要求较高的业务场景,如金融、电商交易等。
- 适用场景:执行时间短、对一致性要求较高的业务,如资金、交易等核心系统。
实现TCC(Try-Confirm-Cancel)分布式事务是一个系统性的工程,涉及业务改造、状态控制和异常处理。
通常有两种模式来实现TCC:
- 基于TCC框架(推荐):
- 使用如 Seata(阿里开源)、ByteTCC、Hmily 等成熟框架。
- 好处:框架提供了全局事务管理器(协调者),自动管理事务上下文、重试、日志等,你只需要关注
ry/confirm/cancel的业务实现。 - 这是生产环境最常用的方式。
- 手动实现:
- 自己编写协调者逻辑,通过代码调用各个服务的TCC接口。
- 好处:完全可控,无框架依赖。
- 坏处:工作量巨大,需要处理所有网络异常、重试、幂等、悬挂等问题,极易出错。
本文将主要介绍基于 Seata Framework 的实现模式。
- 部署Seata Server (TC - Transaction Coordinator)
- 从Se官网下载Server,修改配置文件(注册中心、配置中心、存储模式,如db),然后启动。
- 在Spring Boot微服务中引入依赖
<!-- Seata Starter -->
<dependency><groupId>io.seata</groupId><artifactId>seata-spring-boot-starter</artifactId><version>最新版本</version>
</dependency>
<!-- 其他必要依赖,如Spring Cloud Alibaba -->
- 配置Application.yml
seata:application-id: your-service-nametx-service-group: my-tx-group # 事务组,需与seata-server配置匹配service:vgroup-mapping:my-tx-group: default # 映射到Seata Server的集群名registry:type: nacos # 与你的注册中心一致nacos:server-addr: localhost:8848config:type: nacos # 与你的配置中心一致
每个服务的数据库中,除了业务表,通常需要一张分支事务状态表(Seata框架会自动创建和管理此表),用于记录TCC各阶段的状态,实现幂等和防悬挂。
业务表需要增加相关字段来支持资源预留。
- 订单表
status字段(如:TRY_STATUS: 0-待处理, 1-已确认, 2-已取消) - 库存表 不仅要有
total_inventory,还要有frozen_inventory(冻结库存)字段。
每个参与TCC事务的服务都需要提供一个TCC接口。
示例:库存服务 InventoryService)
- 定义TCC接口(使用
@LocalTCC或@TwoPhaseBusinessAction)
// TCC接口定义
@LocalTCC
public interface InventoryService {/*** Try: 预留资源* @param businessActionContext 上下文,用于传递XID等* @param commodityCode 商品编码* @param count 要扣减的数量* @return*/@TwoPhaseBusinessAction(name = "inventoryAction", commitMethod = "confirm", rollbackMethod = "cancel")boolean prepare(BusinessActionContext businessActionContext,@BusinessActionContextParameter(paramName = "commodityCode") String commodityCode,@BusinessActionContextParameter(paramName = "count") int count);/*** Confirm: 真正扣减* @param actionContext 上下文* @return*/boolean confirm(BusinessActionContext actionContext);/*** Cancel: 释放预留资源* @param actionContext 上下文* @return*/boolean cancel(BusinessActionContext actionContext);
}
- 编写接口实现(核心逻辑)
@Service
public class InventoryServiceImpl implements InventoryService {@Autowiredprivate InventoryMapper inventoryMapper;@Overridepublic boolean prepare(BusinessActionContext context, String commodityCode, int count) {// 1. 检查库存是否充足Inventory inventory = inventoryMapper.findByCommodityCode(commodityCode);if (inventory.getTotal() < count) {throw new RuntimeException("库存不足");}// 2. 冻结库存 (资源预留)inventory.setFrozen(inventory.getFrozen() + count); // 增加冻结数量inventoryMapper.updateFrozen(inventory);// 记录尝试成功,Seata会记录分支事务状态return true;}@Overridepublic boolean confirm(BusinessActionContext context) {// 1. 获取Try阶段传入的参数String commodityCode = (String) context.getActionContext("commodityCode");int count = (int) context.getActionContext("count");// 2. 正式扣减: total = total - count, frozen = frozen - countinventoryMapper.confirmInventory(commodityCode, count);// 幂等性:通过seata_branch_table中的分支事务状态来判断是否已执行过return true;}@Overridepublic boolean cancel(BusinessActionContext context) {// 1. 获取Try阶段传入的参数String commodityCode = (String) context.getActionContext("commodityCode");int count = (int) context.getActionContext("count");// 2. 释放冻结库存: frozen = frozen - countinventoryMapper.cancelInventory(commodityCode, count);// 幂等性处理同上return true;}
}
对应的SQL Mapper示例:
<!-- InventoryMapper.xml -->
<update id="confirmInventory">UPDATE t_inventorySET total = total - #{count},frozen = frozen - #{count}WHERE commodity_code = #{commodityCode}
</update><update id="cancelInventory">UPDATE t_inventorySET frozen = frozen - #{count}WHERE commodity_code = #{commodityCode}
</update>
在全局事务的发起方(如订单服务),使用 @GlobalTransactional注解。
@Service
public class OrderServiceImpl implements OrderService {@Autowiredprivate OrderMapper orderMapper;@Autowiredprivate InventoryService inventoryService; // 通过RPC调用(Feign/Dubbo)@Override@GlobalTransactional(name = "createOrder", timeoutMills = 300000, rollbackFor = Exception.class) // 关键注解public Order createOrder(String userId, String commodityCode, int orderCount) {// 1. 创建订单 (状态为 TRY_STATUS)Order order = new Order();order.setUserId(userId);order.setCommodityCode(commodityCode);order.setCount(orderCount);order.setStatus(OrderStatus.TRY_STATUS);orderMapper.insert(order);// 2. 调用库存服务的TCC Try阶段// 注意:这里是通过RPC调用,Seata会将XID(全局事务ID)在调用链中传递boolean inventorySuccess = inventoryService.prepare(null, commodityCode, orderCount); // Feign调用if (!inventorySuccess) {throw new RuntimeException("库存预留失败");}// 3. 这里可以调用其他TCC服务,如积分服务...// 如果所有Try成功,@GlobalTransactional 注解会自动触发全局Commit// 如果任何一步抛出异常,会自动触发全局Rollbackreturn order;}
}
- 幂等性 (Idempotency)
- 问题:网络重试可能导致Confirm/Cancel被重复调用。
- 解决方案:
- 框架(如Seata)的
branch_table会记录每个分支事务的状态(PREPARED, COMMITTED, ROLLBACKED),在调用Confirm/Cancel前会检查状态,自动实现幂等。 - 你也可以在自己数据库的业务表中使用
状态字段(如<tcc_status)来实现业务幂等。
- 框架(如Seata)的
- 空回滚 (Empty Rollback)
- 问题:Try阶段因网络超时失败,协调者会触发回滚,调用Cancel。但此时Try根本没执行,Cancel操作不能执行实际业务。
- 解决方案:
- 在Cancel方法里,检查一下对应的Try是否执行过(例如,查询
branch_table或业务表是否有预留记录)。 - 如果没执行过(空回滚),直接返回成功并记录一条状态,防止悬挂。
- 在Cancel方法里,检查一下对应的Try是否执行过(例如,查询
- 悬挂 (Hanging)
- 问题:Cancel比Try先到达(网络延迟),发生了空回滚。之后迟到的Try请求才执行并预留了资源,这些资源永远被冻结了。
- 解决方案:
- 在Try方法中,检查是否已经存在一条对应XID的空回滚记录。
- 如果存在,则不再执行业务,直接返回失败,避免资源悬挂。
成熟的TCC框架(如Seata)已经帮你处理了以上大部分问题。
- 业务侵入性:TCC需要改造业务逻辑,设计
try/confirm/cancel接口,开发成本高。仅适用于核心、短流程业务(如支付、交易)。 - 技术选型:强烈推荐使用Seata等成熟框架,而不是手动实现。你自己很难正确处理所有边界情况。
- 数据库设计:数据库表需要增加状态字段和预留资源字段(如
frozen_inventory)来配合TCC操作。 - 可视化与监控:Seata Server提供了控制台,可以查看全局事务和分支事务的状态,便于排查问题。
- 回查机制:Seata的AT模式有自动回查机制,而TCC模式需要你通过上述的
状态字段自己实现状态检查。
总结:实现TCC就是:“业务模型改造 + 框架集成”。你负责将业务分解为三阶段,并保证其幂等性;框架(如Seata)负责可靠地协调这些阶段,确保最终一致性。它是一种非常强大但也很复杂的分布式事务解决方案。
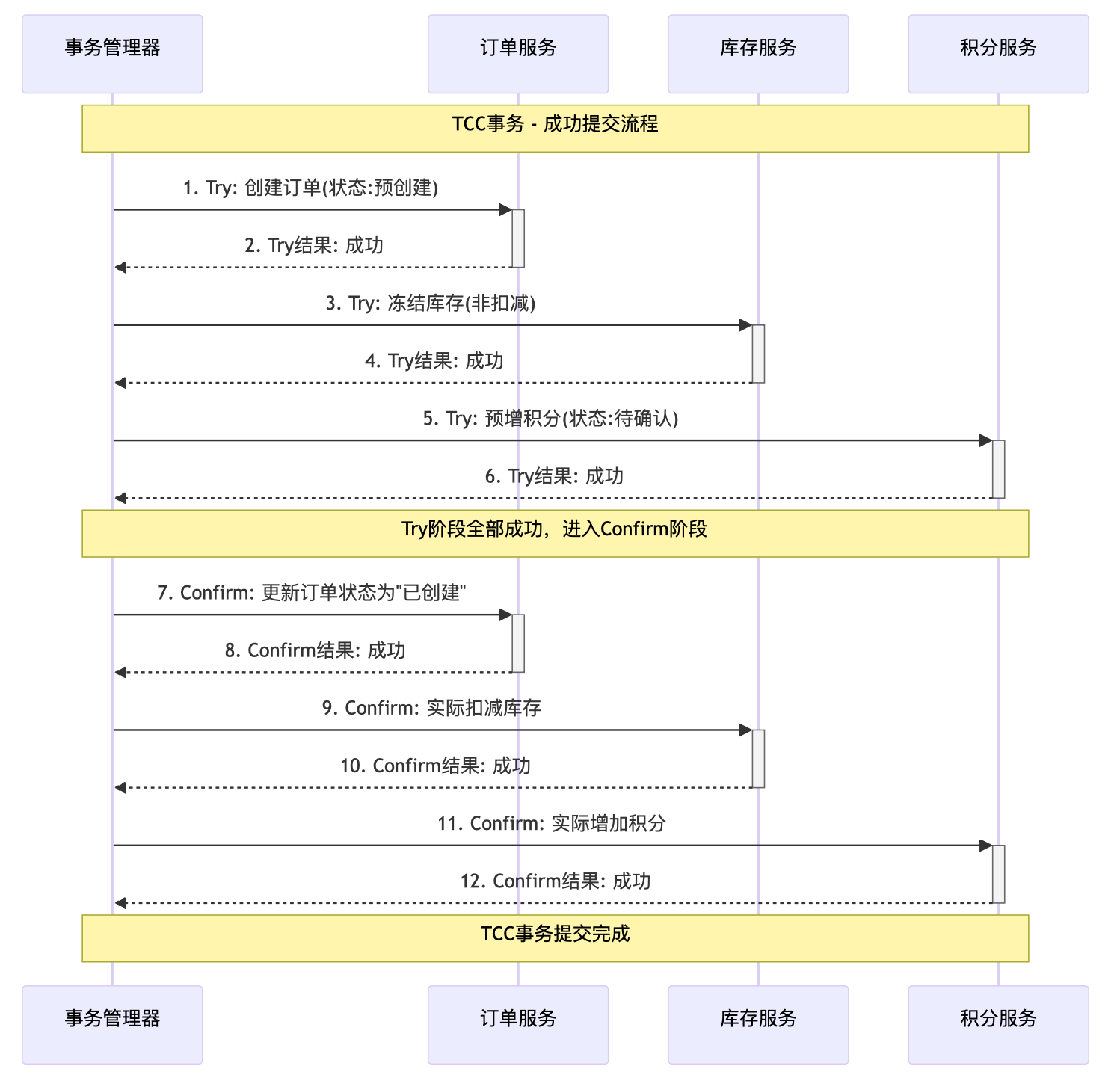
- Try阶段(资源预留):
- 事务管理器按顺序调用所有服务的Try接口。
- 订单服务:创建一个状态为"预创建"的订单,而不是最终状态。
- 库存服务:冻结相应数量的库存(而不是直接扣减),防止其他订单占用。
- 积分服务:预记录积分增加信息,状态为"待确认"(而不是实际增加积分)。
- 所有Try操作都成功,为Confirm阶段做好了准备。
- Confirm阶段(确认执行):
- 由于所有Try都成功,事务管理器开始调用Confirm接口。
- 各服务使用Try阶段预留的资源,执行实际业务操作:
- 订单服务将订单状态更新为"已创建"。
- 库存服务将冻结的库存实际扣减。
- 积分服务将预增的积分实际添加到用户账户。
- Confirm操作必须是幂等的,即重复调用不会产生额外影响。
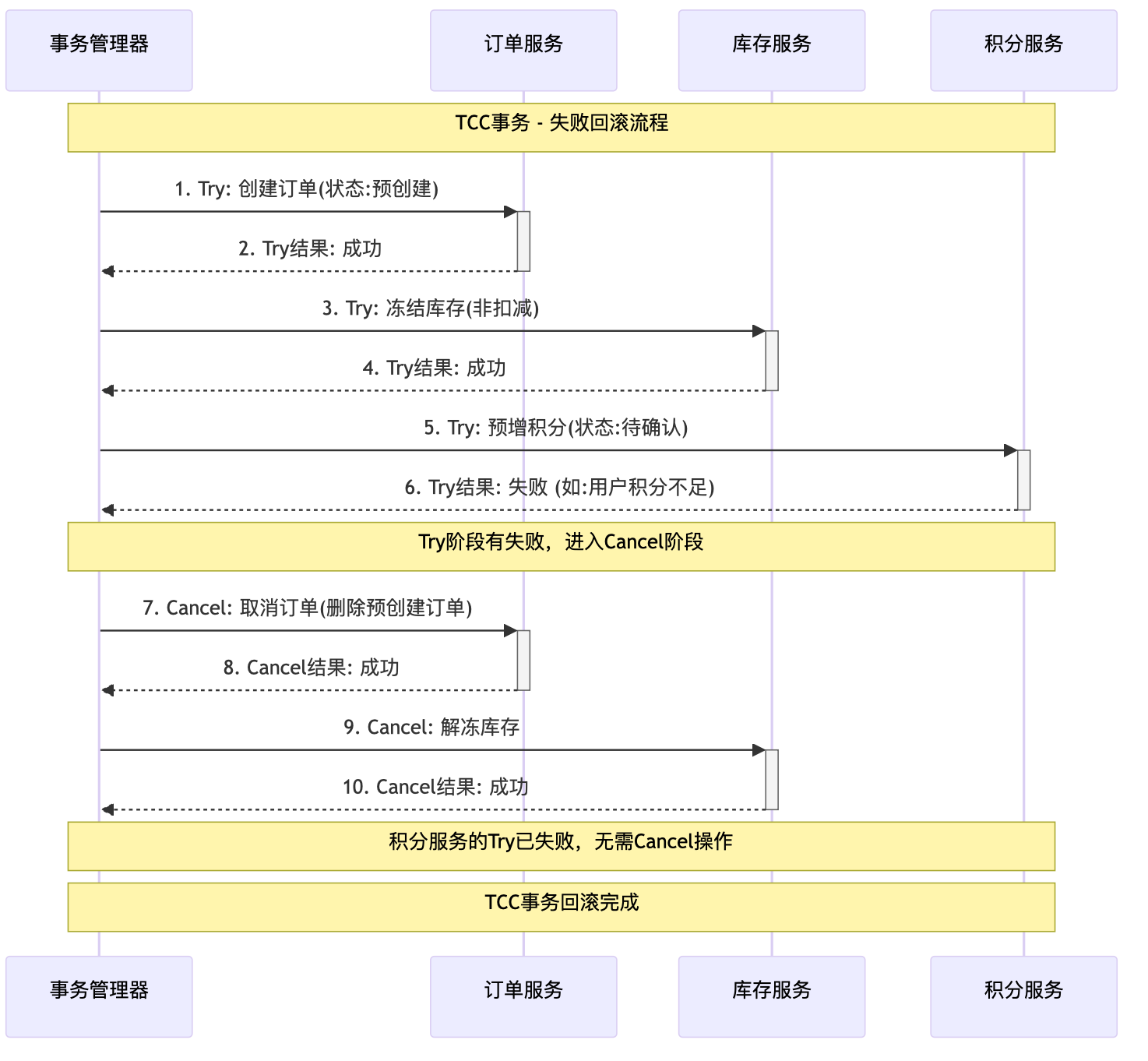
- Try阶段(资源预留):
- 事务管理器按顺序调用Try接口。
- 订单服务和库存服务的Try操作成功,预留了资源。
- 当调用积分服务的Try接口时,由于某种原因(如用户积分不足)失败。
- Cancel阶段(取消释放):
- 由于有Try操作失败,事务管理器开始调用已成功服务的Cancel接口。
- 订单服务:取消订单,删除或作废在Try阶段创建的"预创建"订单。
- 库存服务:解冻在Try阶段冻结的库存,使其可被其他订单使用。
- 积分服务:因为其Try操作已经失败,没有预留资源,所以不需要执行Cancel操作。
- Cancel操作也必须是幂等的。
Saga的理念是“长事务拆分为多个本地短事务”,由本地事务和对应的补偿机制组成。它特别适合业务流程长、参与者多的场景。
- 两种实现模式:
- 协同式(Choreography):没有中心协调点,每个服务监听其他服务的事件,并触发后续操作或补偿。就像一场没有指挥的交响乐,靠乐谱(事件契约)协同。优点是简单、松耦合;缺点是流程复杂后难以理解和调试。
- 编排式(Orchestration):引入一个协调器(Orchestrator) 来集中管理整个事务的流程。协调器按顺序调用参与者,并在出现故障时调用补偿操作。优点是逻辑集中、易于管理和监控;缺点是引入了单点负担。
- 执行流程(以编排式为例):
- 协调器调用订单服务,创建订单(提交)。
- 协调器调用库存服务,扣减库存(提交)。
- 如果调用积分服务失败,协调器会先调用库存服务的补偿操作(恢复库存),再调用订单服务的补偿操作(取消订单)。
- 优点:
- 业务侵入性低:参与者只需要提供正常的业务接口和对应的补偿接口即可。
- 非常适合长流程业务。
- 缺点:
- 补偿操作设计困难:补偿不一定是简单的“反向操作”,可能涉及外部调用,必须保证幂等。
- 调试复杂:尤其是在协同式下,事务链路追踪困难。
- 适用场景:旅行预订流程(订票、订酒店、租车)、电商下单长流程等。
这是互联网公司最常用的一种方案,其核心是利用消息队列的高可靠性来保证数据最终一致。
这是一种“土但有效”的方案,无需依赖特定MQ特性。
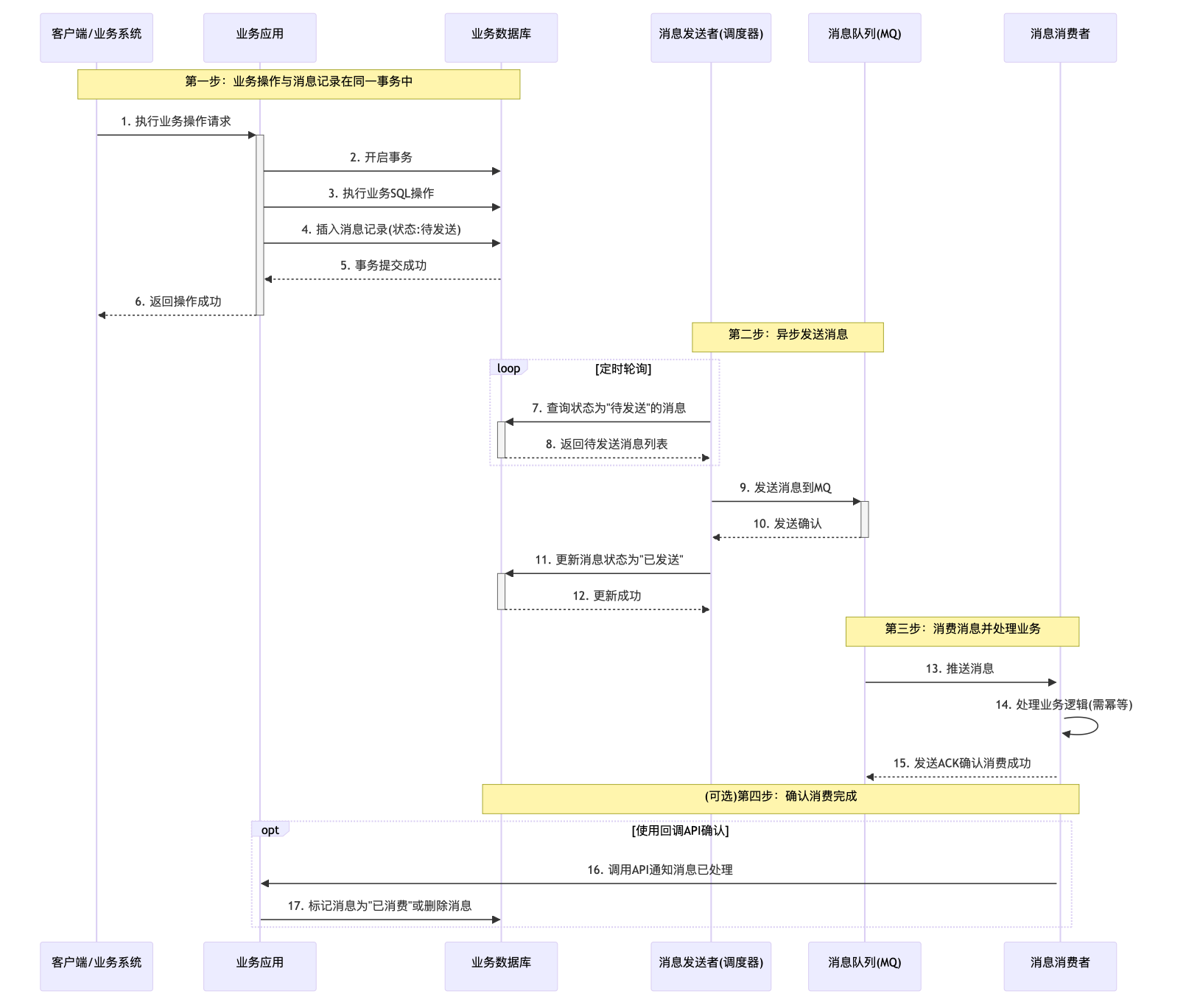
执行流程:
1.在业务数据库中,同一事务内插入业务数据并插入一条消息记录(状态为“待发送”)。
2.有一个独立的消息发送者定时轮询消息表,将状态为“待发送”的记录取出。
3. 消息发送者将消息发送给MQ,并将本地消息状态更新为“已发送”。
4. 消息消费者消费消息,处理业务。处理成功后,可以调用一个API通知发送方删除消息,或采用ACK机制。
- 半消息机制:确保在生产者本地事务执行成功前,消息对消费者不可见。
- 事务状态回查:解决了生产者宕机后消息状态不确定的问题,是相比本地消息表方案的一大优势。
- 最终一致性:保证了分布式系统的最终一致性,而不是强一致性。
- 减少侵入性:相比 TCC 模式,对业务代码的侵入性更低。
- 高性能:异步化机制,性能较高。
RocketMQ提供了原生的事务消息模型,简化了上述流程。
- 执行流程:
- 生产者向Broker发送一条半消息(Half Message),该消息对消费者不可见。
- Broker回复半消息发送成功。
- 生产者执行本地事务。
- 生产者根据本地事务执行结果(成功/失败),向Broker发送Commit或Rollback指令。
- Commit:半消息变为正常消息,消费者可见并进行消费。
- Rollback:Broker丢弃该半消息。
- 如果生产者迟迟没有返回Commit/Rollback(例如宕机),Broker会定时回查生产者的本地事务状态,并根据回查结果决定消息状态。
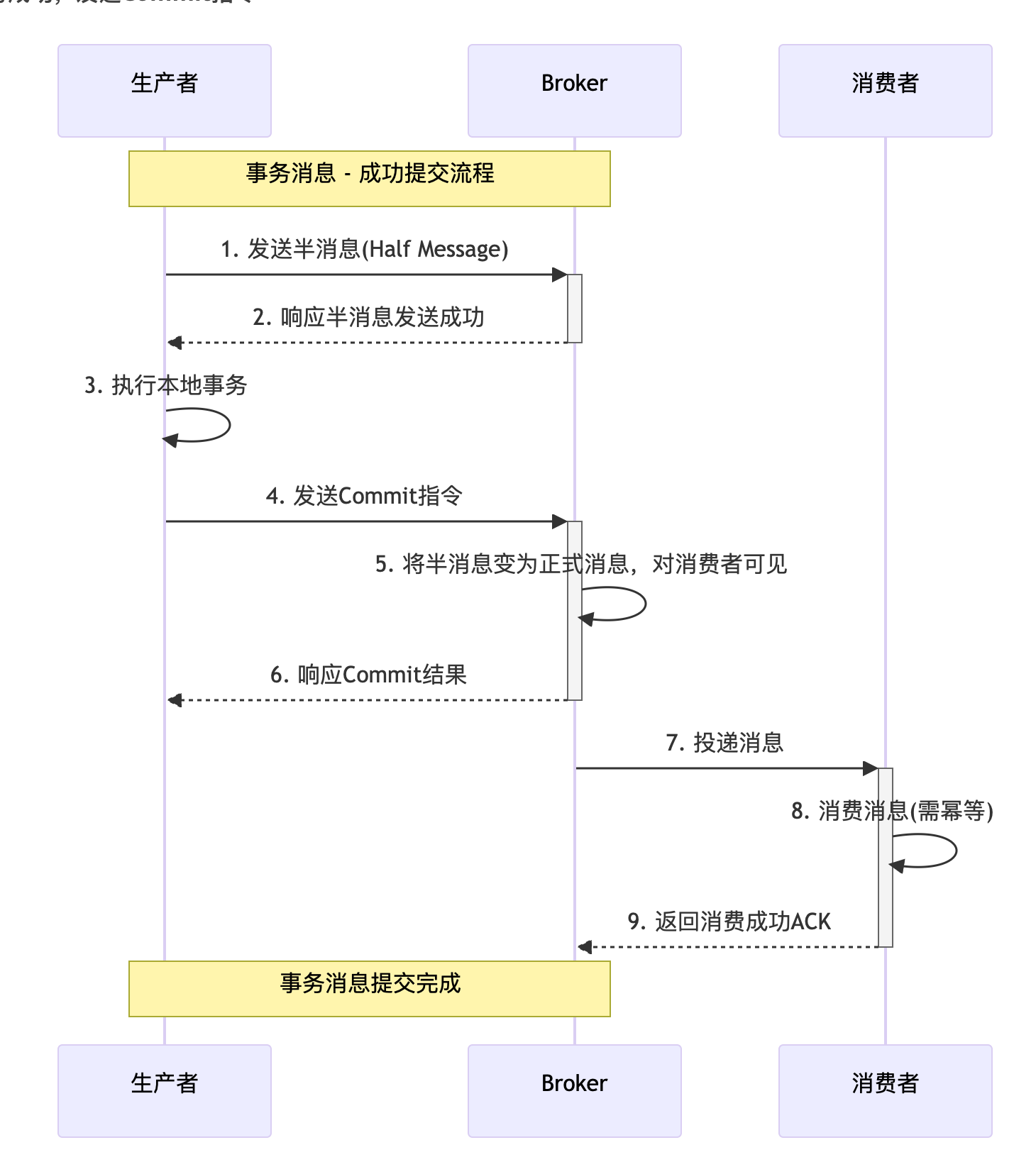
解析:
- 生产者向 Broker 发送一条半消息(Half Message),这种消息对消费者不可见。
- Broker 确认收到半消息并响应成功。
- 生产者执行本地事务(如订单创建、库存扣减等)。
- 如果本地事务执行成功,生产者向 Broker 发送 Commit 指令。
- Broker 将半消息变为正式消息,对消费者可见。
- Broker 响应 Commit 操作结果。
- Broker 将消息投递给消费者。
- 消费者处理消息(必须实现幂等性)。
- 消费者返回消费成功确认(ACK)。
:::
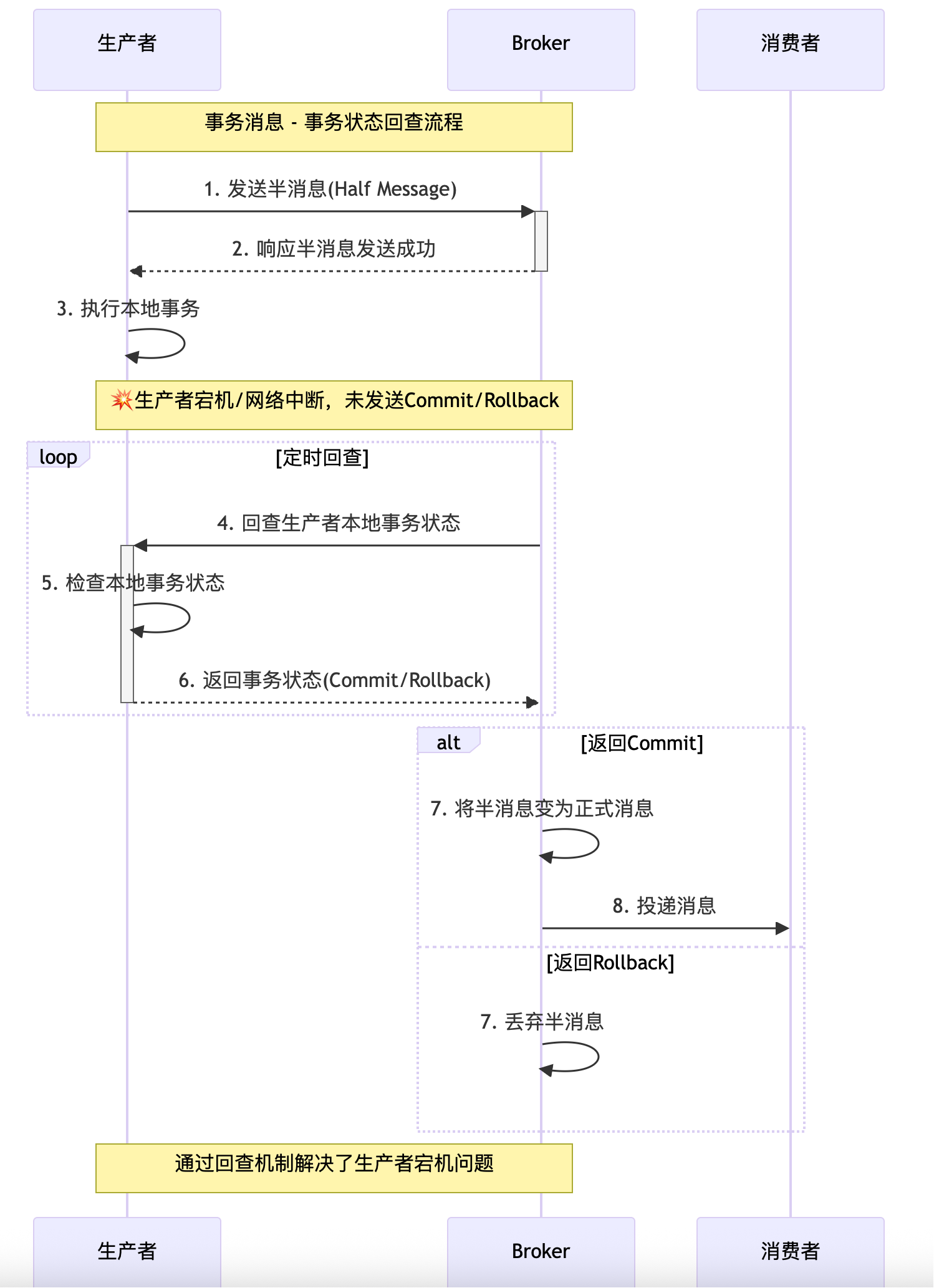
失败回滚流程
1-2. 与前一个流程相同,生产者发送半消息,Broker 响应成功。
3. 生产者执行本地事务,但执行失败。
4. 生产者向 Broker 发送 Rollback 指令。
5. Broker 丢弃半消息,消费者永远不会看到这条消息。
6. Broker 响应 Rollback 操作结果
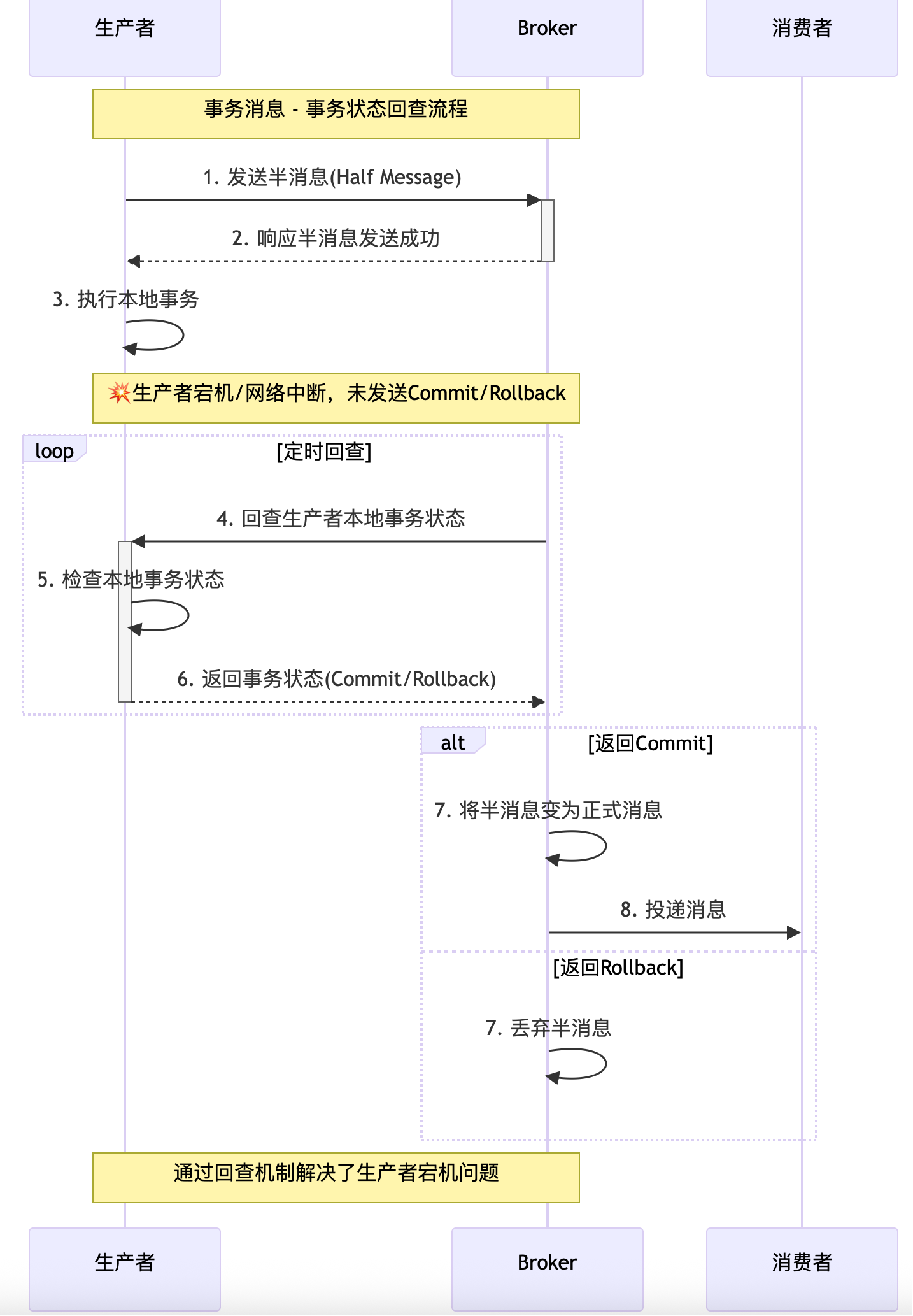
1-2. 与前两个流程相同,生产者发送半消息,Broker 响应成功。
3. 生产者执行本地事务。
4. 由于生产者宕机或网络中断,未能发送 Commit 或 Rollback 指令。
5. Broker 定时回查生产者的本地事务状态。
6. 生产者检查本地事务的执行结果,并返回状态(Commit 或 Rollback)。
7. 根据生产者返回的状态,Broker 决定是将半消息变为正式消息还是丢弃。
- 优点:
- 吞吐量高:异步化机制。
- 业务侵入性低:与业务逻辑解耦清晰。
- 通用性强:适用于大多数最终一致性场景。
- 缺点:
- 只保证最终一致性:消费者可能延迟收到消息。
- 必须保证消费端幂等:因为网络重传等原因,消息可能被重复消费。
- 适用场景:几乎所有异步场景,如积分增加、短信/邮件通知、统计信息更新、日志处理等。
| 方案 | 一致性 | 性能 | 复杂度 | 业务侵入性 | 适用场景 |
|---|---|---|---|---|---|
| 2PC | 强一致 | 低 | 低 | 低 | 数据库层面,内部强一致系统 |
| TCC | 最终一致 | 中 | 高 | 高 | 短流程,金融、交易核心 |
| Saga | 最终一致 | 中 | 中 | 中 | 长流程,业务旅行、订单 |
| 消息事务 | 最终一致 | 高 | 中 | 低 | 异步场景,数据最终一致 |
- 业务需求是第一位的:
- 业务是否允许最终一致性?如果必须是强一致(如银行转账),考虑2PC或TCC。
- 业务流程的长短?短流程可用TCC,长流程用Saga。
- 延迟是否敏感?敏感则慎用基于消息的方案。
- 性能要求:高并发、高吞吐场景,优先考虑基于消息的最终一致性方案。
- 开发与维护成本:
- 团队是否有能力设计和实现侵入性强的TCC?
- 是否有现成的协调器框架(如Seata)来降低复杂度?
- 技术栈:公司现有的中间件是否支持?例如,是否有RocketMQ来支持事务消息?
简单决策路径:
- 强一致 -> 2PC (简单但性能差) 或 TCC (复杂但性能好)。
- 最终一致 + 长流程 -> Saga。
- 最终一致 + 异步场景 -> 基于消息队列 (首选)。
分布式事务没有完美的银弹,它始终是一致性、性能、复杂度三者之间的权衡艺术。
- 2PC 提供了强一致性,但代价是性能和可用性。
- TCC、Saga、消息事务 等最终一致性方案是互联网分布式架构的主流选择,它们通过不同的方式在业务可接受的时间窗口内实现了数据一致,从而换取了更高的可用性和性能。
无论选择哪种方案,以下几点都至关重要:
- 幂等性:这是分布式系统的护身符。所有重复的请求都必须不会产生副作用。
- 可观测性:必须配备完善的日志、链路追踪(Tracing)和监控(Metrics),让你能清晰地看到每一个分布式事务的执行轨迹和状态,以便快速定位和修复问题。
- 人工干预通道:再完美的系统也可能有未能处理的异常。必须提供一个管理后台,允许运维或开发人员查询、暂停、重试或手动回滚那些“悬而不决”的事务。
分布式事务的探索仍在继续:
- Service Mesh:像Istio这样的服务网格技术,能否在基础设施层提供更通用的分布式事务支持,从而让业务开发者完全无感?
- Serverless:在无服务器架构下,函数的无状态和短生命周期特性对分布式事务提出了新的挑战。
- 标准化:随着微服务的普及,类似OpenTracing的标准是否会出现在分布式事务领域,实现不同框架和语言的互联互通?
- 你在工作中遇到过哪些分布式事务的难题?又是如何解决的? 是选择了文中的某种方案,还是有自己的独门秘籍?欢迎在评论区分享你的经历和思考。
- 对于文中的几种方案,你更倾向于哪一种?为什么? 是基于技术考量,还是基于团队和业务的现实情况?
- 代码示例:以下是一个基于RocketMQ事务消息的伪代码逻辑,帮助大家理解:
// 订单服务(生产者)
public class OrderService {@Autowiredprivate TransactionMQProducer producer;public void createOrder(Order order) {// 1. 构建消息Message msg = new Message("ORDER_TOPIC", JSON.toJSONBytes(order));// 2. 发送半消息TransactionSendResult sendResult = producer.sendMessageInTransaction(msg, null);// ... 后续处理}// 3. 实现LocalTransactionExecute(执行本地事务)@Overridepublic LocalTransactionState executeLocalTransaction(Message msg, Object arg) {try {// 在本地数据库创建订单orderMapper.insert(order);return LocalTransactionState.COMMIT_MESSAGE; // 本地事务成功,提交消息} catch (Exception e) {return LocalTransactionState.ROLLBACK_MESSAGE; // 本地事务失败,回滚消息}}// 4. 实现本地事务状态回查(可选)@Overridepublic LocalTransactionState checkLocalTransaction(MessageExt msg) {// 根据消息中的订单ID,查询数据库中的订单状态Order order = orderMapper.selectById(orderId);if (order != null) {return LocalTransactionState.COMMIT_MESSAGE;} else {return LocalTransactionState.ROLLBACK_MESSAGE;}}
}// 积分服务(消费者)
public class PointsServiceConsumer {@RocketMQMessageListener(topic = "ORDER_TOPIC", consumerGroup = "points-group")public void consumeMessage(Message message) {// 1. 解析消息,获取订单信息Order order = JSON.parseObject(message.getBody(), Order.class);// 2. 查询订单是否已经处理过(幂等性校验)if (hasProcessed(order.getId())) {return; // 已经处理过,直接返回}// 3. 进行积分增加操作pointsService.addPoints(order.getUserId(), order.getAmount());// 4. 记录处理状态,用于幂等性校验markAsProcessed(order.getId());}
}
希望这篇文章能为你解开分布式事务的迷雾,助你在分布式系统的世界里构建出更加健壮、可靠的应用。