TRELLIS:从多张图片生成3D模型
TRELLIS:从多张图片生成3D模型
- 一、背景介绍
- 二、TRELLIS是什么?
- 三、环境搭建与准备工作
- 四、准备多张不同角度的图片
- 五、生成3D模型
- 六、使用Blender进行高级渲染
- 七、总结与展望
一、背景介绍
在数字时代,3D模型广泛应用于游戏开发、影视特效、虚拟现实(VR)、增强现实(AR)乃至电子商务等领域。传统3D建模需要专业的技术和软件,过程繁琐且耗时。然而,随着人工智能(AI)技术的发展,现在我们只需通过拍摄物体的多张不同角度照片,就能自动生成高质量的3D模型。
本文旨在介绍如何利用微软开源的TRELLIS项目,将一组普通图片转换为逼真的3D模型,并进一步渲染成动态视频。
二、TRELLIS是什么?
为了让您更好地理解后续操作,我们先简单了解一下TRELLIS的工作原理。您不需要完全掌握这些技术细节,但了解其核心思想有助于理解整个过程。
核心目标:TRELLIS是一个多模态AI系统,它的核心任务是从有限的2D图片中推断出物体的3D结构、外观和材质。
它是如何做到的?(通俗版解释)
想象一下,您看到一个花瓶,只看正面一张照片很难想象它的背面和底部是什么样子。但如果您看了它的正面、侧面、俯视图等多张照片,您的大脑就能自动在脑海中构建出这个花瓶完整的3D形状。TRELLIS做的就是类似的事情,但它是一个经过海量3D数据和图片训练的“超级大脑”。
它的技术流程可以简化为:
- 理解图片内容:AI首先分析您提供的每张图片,识别出物体是什么、它的轮廓、颜色、纹理等。
- 推测3D结构:通过比较不同角度图片之间的差异,AI估算出物体的深度、形状以及相机拍摄的位置(类似于人眼的立体视觉)。
- 生成3D表示:TRELLIS强大之处在于它会同时生成多种流行的3D表示形式:
- 高斯溅射 (Gaussian Splatting):一种非常新颖且高效的表示方法,用许多微小的、带颜色的“粒子”来组成物体,渲染速度极快,效果非常逼真。
- 网格 (Mesh):传统的3D模型,由三角形面片构成,带有纹理贴图。这种格式通用性最强,能被几乎所有3D软件(如Blender)识别和编辑。
- 辐射场 (Radiance Field):类似于NeRF的技术,从任何角度看都能生成非常逼真的图像,但通常需要AI实时计算,不易直接编辑。
- 优化与输出:最后,系统会优化生成的3D模型,并输出为常见的3D文件格式(如
.glb、.ply)和渲染视频。
为什么选择TRELLIS?
- 多模型输出:一次运行,同时获得多种3D表示,满足不同需求。
- 高质量:得益于先进的AI算法,其生成的质量在业界处于领先水平。
- 开源免费:代码公开,可供研究和商业使用。
三、环境搭建与准备工作
在开始生成3D模型前,我们需要搭建一个能够运行TRELLIS的环境。由于项目依赖复杂的AI库和3D计算库,我们使用Docker来创建一个独立、统一的软件环境,避免与您系统上的其他软件发生冲突。
操作步骤说明:
-
创建项目目录:首先创建一个名为
TRELLIS_dev的文件夹,所有操作都将在这个目录内进行,方便管理。mkdir TRELLIS_dev cd TRELLIS_dev -
启动Docker容器:这行命令做了以下几件事:
--gpus all:让容器能使用您电脑的所有GPU(NVIDIA显卡),这是AI计算所必需的。--shm-size=32g:设置共享内存大小,处理大模型时需要更多内存。-v $PWD:/home:将当前目录($PWD)映射到容器内的/home目录。这样,容器里操作的文件在您电脑上也能看到。nvcr.io/nvidia/pytorch:24.03-py3:使用NVIDIA官方提供的、已经预装了PyTorch等基础AI框架的镜像,省去了手动安装的麻烦。
docker run --gpus all --shm-size=32g -it \-e NVIDIA_VISIBLE_DEVICES=all --privileged --net=host \-v $PWD:/home -w /home --name TRELLIS_dev nvcr.io/nvidia/pytorch:24.03-py3 /bin/bash -
获取TRELLIS代码:从GitHub上克隆(下载)TRELLIS项目的源代码。
cd /home git clone https://github.com/microsoft/TRELLIS.git cd /home/TRELLIS git submodule update --init --recursive # 初始化并下载项目依赖的子模块代码 -
安装系统依赖:安装一些图形和显示相关的底层库。
apt update apt install libgl1 -y apt install libx11-dev -y -
安装Python依赖:使用
pip安装项目运行所需的所有Python库。-i https://pypi.tuna.tsinghua.edu.cn/simple:指定使用清华大学的镜像源来下载软件包,速度会快很多。opencv-fixer是一个用于修复OpenCV库常见问题的工具。
pip3 install torch==2.4.0 -i https://pypi.tuna.tsinghua.edu.cn/simple pip3 install torchvision==0.19.0 -i https://pypi.tuna.tsinghua.edu.cn/simple pip3 install opencv-fixer==0.2.5 python3 -c "from opencv_fixer import AutoFix; AutoFix()" # 运行OpenCV修复脚本 ./setup.sh --basic --xformers --flash-attn --diffoctreerast --spconv --mipgaussian --kaolin --nvdiffrast # 运行项目自带的安装脚本,编译和安装核心组件 pip3 install numpy==1.26 # 安装Kaolin(一个3D深度学习库)的特定版本 pip3 install kaolin -f https://nvidia-kaolin.s3.us-east-2.amazonaws.com/torch-2.4.0_cu121.html pip3 install --upgrade flash-attn
环境搭建完成后,我们就可以开始准备数据了。
四、准备多张不同角度的图片
为什么需要多角度的图片?
正如前文原理所述,AI需要从不同视角了解物体的形状。图片的质量和覆盖角度直接决定了生成模型的好坏。
操作要点:
- 图片要求:在项目目录内创建一个名为
imgs的文件夹,将您的图片放入其中。- 角度:围绕物体均匀地拍摄一圈,最好还能有从上往下拍的顶视图和从下往上的底视图(如果可能)。覆盖的角度越多,生成的效果越好。
- 光照:光线均匀,避免过曝或过暗的区域,避免复杂的阴影。
- 背景:尽量简单、干净的背景有助于AI专注于物体本身。
- 一致性:物体在拍摄过程中不能移动或变形,相机焦点应对准物体。
- 示例:您提供的图片应该类似于下图,展示了物体的不同侧面。

五、生成3D模型
这是最核心的一步,我们将使用TRELLIS提供的管道(Pipeline)来生成3D模型。
操作步骤说明:
- 创建并运行Python脚本:我们将以下代码保存为
demo.py并运行。这段代码的主要功能是:- 加载预训练模型:
TrellisImageTo3DPipeline.from_pretrained("microsoft/TRELLIS-image-large")下载并加载微软发布的大型预训练模型。 - 读取图片:读取
imgs文件夹中的所有图片。 - 执行推理:
pipeline.run_multi_image()是核心函数,它接收图片和参数,开始计算并生成3D模型。 - 渲染视频:使用
render_utils将生成的3D模型从360度旋转一圈,渲染成视频,让我们能直观地查看效果。 - 导出模型文件:使用
postprocessing_utils.to_glb()将模型导出为.glb格式(一种常见的3D文件格式,包含网格和纹理),同时也可导出为.ply点云格式。
- 加载预训练模型:
cat > demo.py <<-'EOF'
import os
os.environ['SPCONV_ALGO'] = 'native'
import numpy as np
import imageio
from PIL import Image
from trellis.pipelines import TrellisImageTo3DPipeline
from trellis.utils import render_utils
import glob
import imageio
from PIL import Image
from trellis.pipelines import TrellisImageTo3DPipeline
from trellis.utils import render_utils, postprocessing_utils# 1. 加载预训练模型管道并将其移动到GPU上
pipeline = TrellisImageTo3DPipeline.from_pretrained("microsoft/TRELLIS-image-large")
pipeline.cuda()# 2. 读取所有输入图片
images = [Image.open(x) for x in glob.glob('imgs/*')]# 3. 运行管道,生成3D模型!
outputs = pipeline.run_multi_image(images,seed=1,# Optional parameterssparse_structure_sampler_params={"steps": 12,"cfg_strength": 7.5,},slat_sampler_params={"steps": 12,"cfg_strength": 3,},
)# 4. 渲染视频以预览结果
# 将高斯溅射和网格模型的渲染结果并列放在一个视频中
video_gs = render_utils.render_video(outputs['gaussian'][0])['color']
video_mesh = render_utils.render_video(outputs['mesh'][0])['normal']
video = [np.concatenate([frame_gs, frame_mesh], axis=1) for frame_gs, frame_mesh in zip(video_gs, video_mesh)]
imageio.mimsave("sample_multi.mp4", video, fps=30)# 也可以单独保存每种表示的渲染视频
video = render_utils.render_video(outputs['gaussian'][0])['color']
imageio.mimsave("sample_gs.mp4", video, fps=30)
video = render_utils.render_video(outputs['radiance_field'][0])['color']
imageio.mimsave("sample_rf.mp4", video, fps=30)
video = render_utils.render_video(outputs['mesh'][0])['normal']
imageio.mimsave("sample_mesh.mp4", video, fps=30)# 5. 导出为通用3D文件格式
# 生成GLB文件,可用于Blender、Unity等3D软件
glb = postprocessing_utils.to_glb(outputs['gaussian'][0],outputs['mesh'][0],# Optional parameterssimplify=0.95, # Ratio of triangles to remove in the simplification processtexture_size=1024, # Size of the texture used for the GLB
)
glb.export("sample.glb") # 导出GLB文件
outputs['gaussian'][0].save_ply("sample.ply") # 导出PLY文件
EOF
python3 demo.py
# 生成gif
ffmpeg -i sample_multi.mp4 -vf "fps=10,scale=640:-1:flags=lanczos,split[s0][s1];[s0]palettegen[p];[s1][p]paletteuse" output.gif
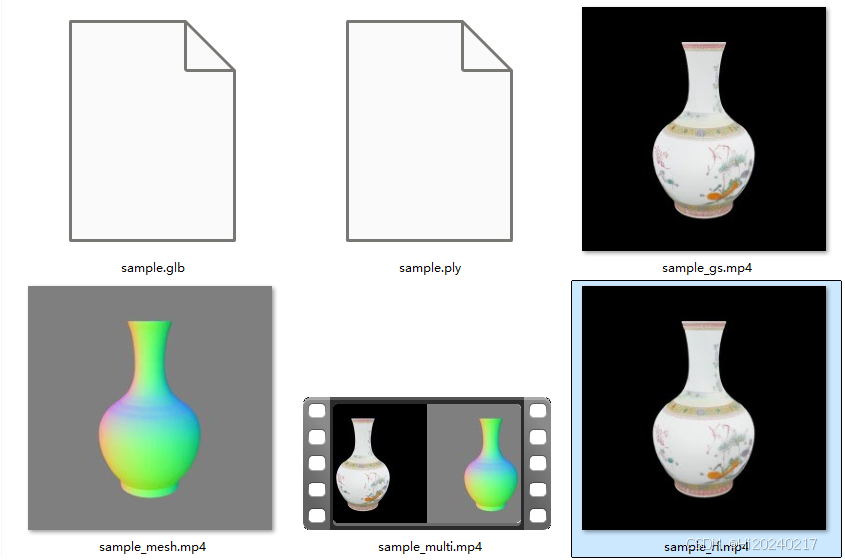
- 查看结果:脚本运行完成后,您会在目录下找到生成的视频文件(如
sample_multi.mp4)和3D模型文件(sample.glb)。生成的视频效果可能类似下图:

六、使用Blender进行高级渲染
TRELLIS自带的渲染主要用于快速预览。要获得更具电影感、光照更专业、分辨率更高的视频,我们需要使用专业的3D渲染软件——Blender。
操作步骤说明:
- 编写Blender脚本:我们将以下代码保存为
render_glb.py。这个脚本指示Blender在无界面的后台自动完成一系列操作:- 导入模型:自动打开我们生成的
sample.glb文件。 - 布置场景:清除默认场景,设置 Cycles 渲染引擎(以产生高质量光影)。
- 设置灯光:创建多个区域光(主光、补光、背光、顶光),并设置环境光,确保物体被均匀照亮且立体感强。
- 设置相机动画:让相机围绕模型进行球面运动,拍摄360度视频。
- 渲染输出:配置渲染分辨率、格式(MP4视频),并开始渲染。
- 导入模型:自动打开我们生成的
import bpy
import os
import math
import sys
import pathlib# 确保在 Blender 的 Python 环境中运行
if not hasattr(bpy, "context"):print("此脚本需要在 Blender 中运行")print("使用方法: blender --background --python script.py")sys.exit(1)def setup_scene():"""清除默认场景并设置基本参数"""# 清除默认对象bpy.ops.object.select_all(action='SELECT')bpy.ops.object.delete(use_global=False)# 设置渲染引擎为 Cyclesbpy.context.scene.render.engine = 'CYCLES'# 设置设备为 GPU(如果可用)try:bpy.context.preferences.addons['cycles'].preferences.compute_device_type = 'CUDA'bpy.context.scene.cycles.device = 'GPU'# 启用所有可用的计算设备for device in bpy.context.preferences.addons['cycles'].preferences.devices:device.use = Trueexcept:print("警告: 无法设置GPU设备,使用CPU渲染")bpy.context.scene.cycles.device = 'CPU'return Truedef import_glb(glb_path):"""导入 GLB 模型"""if not os.path.exists(glb_path):print(f"错误: 文件 {glb_path} 不存在")return False# 导入 GLB 文件bpy.ops.import_scene.gltf(filepath=glb_path)print("GLB 模型导入成功")return Truedef setup_camera_and_lights():"""设置相机和灯光 - 改进的光源设置,确保物体全身可见"""# 创建相机bpy.ops.object.camera_add(location=(0, -5, 0))camera = bpy.context.active_objectcamera.rotation_euler = (math.pi/2, 0, math.pi/2)bpy.context.scene.camera = camera# 创建主光源 - 使用面光源提供均匀照明bpy.ops.object.light_add(type='AREA', location=(5, 5, 5))main_light = bpy.context.active_objectmain_light.data.energy = 1000main_light.data.size = 5main_light.rotation_euler = (math.radians(-45), math.radians(-45), 0)# 创建填充光 - 从另一侧提供补充照明bpy.ops.object.light_add(type='AREA', location=(-5, -5, 5))fill_light = bpy.context.active_objectfill_light.data.energy = 1000fill_light.data.size = 5fill_light.rotation_euler = (math.radians(-45), math.radians(135), 0)# 创建背光 - 突出轮廓bpy.ops.object.light_add(type='AREA', location=(0, 0, -5))back_light = bpy.context.active_objectback_light.data.energy = 1000back_light.data.size = 5back_light.rotation_euler = (0, math.pi, 0)# 创建顶光 - 提供整体照明bpy.ops.object.light_add(type='AREA', location=(0, 0, 10))top_light = bpy.context.active_objecttop_light.data.energy = 1000top_light.data.size = 5top_light.rotation_euler = (0, 0, 0)# 创建环境光 - 使用世界节点提供均匀的环境光bpy.context.scene.world.use_nodes = Trueworld_nodes = bpy.context.scene.world.node_tree.nodesworld_links = bpy.context.scene.world.node_tree.links# 清除默认节点world_nodes.clear()# 添加环境光节点background_node = world_nodes.new(type='ShaderNodeBackground')background_node.inputs['Color'].default_value = (0.05, 0.05, 0.05, 1)background_node.inputs['Strength'].default_value = 0.2# 连接到世界输出world_output = world_nodes.new(type='ShaderNodeOutputWorld')world_links.new(background_node.outputs['Background'], world_output.inputs['Surface'])return cameradef setup_animation(camera, duration_seconds=5, fps=30):"""设置相机动画 - XY轴旋转"""# 设置帧率bpy.context.scene.render.fps = fps# 计算总帧数total_frames = fps * duration_seconds# 设置场景帧范围bpy.context.scene.frame_start = 1bpy.context.scene.frame_end = total_frames# 设置相机动画关键帧 - XY轴旋转for frame in range(1, total_frames + 1):# 计算旋转角度(XY轴旋转)angle_x = 2 * math.pi * (frame - 1) / total_frames # X轴旋转angle_y = math.pi * (frame - 1) / total_frames # Y轴旋转# 设置相机位置(球面坐标)radius = 5 # 相机距离原点的距离# 球面坐标转笛卡尔坐标x = radius * math.sin(angle_y) * math.cos(angle_x)y = radius * math.sin(angle_y) * math.sin(angle_x)z = radius * math.cos(angle_y)camera.location = (x, y, z)# 让相机始终看向原点direction = -camera.locationrot_quat = direction.to_track_quat('-Z', 'Y')camera.rotation_euler = rot_quat.to_euler()# 插入关键帧camera.keyframe_insert(data_path="location", frame=frame)camera.keyframe_insert(data_path="rotation_euler", frame=frame)print(f"动画设置完成: {total_frames} 帧")return total_framesdef setup_render_settings(output_path, resolution=(1280, 720)):"""设置渲染参数"""# 确保输出目录存在output_dir = os.path.dirname(output_path)if output_dir and not os.path.exists(output_dir):os.makedirs(output_dir)print(f"创建输出目录: {output_dir}")# 检查文件是否可写try:# 尝试创建文件以检查权限with open(output_path, 'wb') as f:passos.remove(output_path) # 删除测试文件except IOError as e:print(f"错误: 无法写入文件 {output_path}: {e}")# 尝试使用临时目录temp_dir = os.path.join(os.path.expanduser("~"), "Desktop")if os.path.exists(temp_dir) and os.access(temp_dir, os.W_OK):new_output_path = os.path.join(temp_dir, os.path.basename(output_path))print(f"使用备用路径: {new_output_path}")output_path = new_output_pathelse:print("错误: 没有可写的输出目录")return None# 设置输出路径和格式bpy.context.scene.render.filepath = output_pathbpy.context.scene.render.image_settings.file_format = 'FFMPEG'bpy.context.scene.render.ffmpeg.format = 'MPEG4'bpy.context.scene.render.ffmpeg.codec = 'H264'# 设置分辨率bpy.context.scene.render.resolution_x = resolution[0]bpy.context.scene.render.resolution_y = resolution[1]# 设置采样率bpy.context.scene.cycles.samples = 256# 启用透明背景(如果需要)bpy.context.scene.render.film_transparent = Trueprint(f"渲染设置完成,输出路径: {output_path}")return output_pathdef center_model():"""将模型居中并调整视图"""# 选择所有网格对象bpy.ops.object.select_all(action='DESELECT')for obj in bpy.context.scene.objects:if obj.type == 'MESH':obj.select_set(True)# 如果有选中的对象,将它们移动到世界中心if bpy.context.selected_objects:# 设置原点为几何中心bpy.ops.object.origin_set(type='ORIGIN_GEOMETRY', center='BOUNDS')# 将对象移动到世界中心for obj in bpy.context.selected_objects:obj.location = (0, 0, 0)print("模型已居中")def check_model_scale():"""检查模型缩放并调整"""for obj in bpy.context.scene.objects:if obj.type == 'MESH':# 获取边界框尺寸dimensions = obj.dimensions# 如果模型太大或太小,调整缩放max_dim = max(dimensions.x, dimensions.y, dimensions.z)if max_dim > 10 or max_dim < 0.1:scale_factor = 2.0 / max_dimobj.scale = (scale_factor, scale_factor, scale_factor)print(f"调整模型缩放: {scale_factor}")def main():"""主函数"""# 检查参数if len(sys.argv) < 5:print("用法: blender --background --python script.py -- <glb_path> <output_path> <duration> <resolution>")print("示例: blender --background --python render_glb.py -- model.glb output.mp4 5 1280x720")return# 获取参数 (Blender 会传递自己的参数,所以我们需要跳过它们)args = sys.argv[sys.argv.index("--") + 1:] if "--" in sys.argv else sys.argv[1:]if len(args) < 4:print("错误: 参数不足")returnglb_path = args[0]output_path = args[1]duration = int(args[2])resolution = tuple(map(int, args[3].split('x')))print(f"开始渲染: {glb_path} -> {output_path}")print(f"时长: {duration}秒, 分辨率: {resolution[0]}x{resolution[1]}")# 设置场景if not setup_scene():return# 导入模型if not import_glb(glb_path):return# 居中模型center_model()# 检查模型缩放check_model_scale()# 设置相机和灯光camera = setup_camera_and_lights()# 设置动画total_frames = setup_animation(camera, duration, 10)# 设置渲染参数final_output_path = setup_render_settings(output_path, resolution)if not final_output_path:return# 渲染动画print("开始渲染...")try:bpy.ops.render.render(animation=True)print(f"渲染完成! 视频已保存到: {final_output_path}")except Exception as e:print(f"渲染错误: {e}")# 尝试使用不同的编码器print("尝试使用不同的视频编码器...")bpy.context.scene.render.ffmpeg.codec = 'MPEG4'try:bpy.ops.render.render(animation=True)print(f"渲染完成! 视频已保存到: {final_output_path}")except Exception as e2:print(f"再次渲染错误: {e2}")if __name__ == "__main__":main()
- 执行Blender脚本:在您电脑的系统命令行(注意:不是在Docker容器内,而是需要您本地安装好Blender软件)中运行以下命令。
blender.exe --background --python render_glb.py -- sample.glb C:\Users\hello\Desktop\output1.mp4 2 1280x720
# 生成gif
ffmpeg -i output1.mp4 -vf "fps=10,scale=640:-1:flags=lanczos,split[s0][s1];[s0]palettegen[p];[s1][p]paletteuse" output1.gif
参数解释:
--background: 让Blender在后台运行,不打开图形界面。--python render_glb.py: 指定要执行的Python脚本。--: 用于分隔Blender自身的参数和我们脚本需要的参数。sample.glb: 输入模型文件(传递给脚本的第一个参数)。C:\Users\hello\Desktop\output1.mp4: 最终渲染视频的输出路径(第二个参数)。2: 视频时长,单位为秒(第三个参数)。1280x720: 视频分辨率(第四个参数)。
运行完毕后,您就可以在指定的桌面上找到最终生成的高质量渲染视频output1.mp4了。

七、总结与展望
通过以上步骤,我们成功地利用TRELLISAI模型和Blender渲染引擎,将一组2D图片转换为了一个可以360度观看的、高质量的3D模型视频。
- 技术总结:TRELLIS代表了生成式AI在3D内容创作领域的最前沿进展,极大地降低了3D内容的制作门槛。
- 应用前景:这项技术可以用于:
- 电商:快速为商品生成3D展示模型,提升购物体验。
- 文化遗产保护:数字化保存文物和古迹。
- 个人创作:为自己制作的手办、艺术品创建数字档案。
- 游戏和VR/AR开发:快速生成原型和资产。
注意事项与优化方向:
- 当前模型对计算资源要求较高,需要性能强大的NVIDIA GPU。
- 输入图片的质量至关重要,请务必提供清晰、多角度、光照良好的照片。
- 生成的网格模型(Mesh)可能包含一些瑕疵,可以在Blender等软件中进行进一步的修复和优化。