DAY17-新世纪DL(DeepLearning/深度学习)战士:Q(机器学习策略)2
本文参考文章0.0 目录-深度学习第一课《神经网络与深度学习》-Stanford吴恩达教授-CSDN博客
1.误差分析
学习算法还没有达到人类的表现,那么人工检查一下你的算法犯的错误也许可以让你了解接下来应该做什么。这个过程称为错误分析
如果你要搭建应用系统,那做个简单的人工统计步骤,错误分析,可以节省大量时间,可以迅速决定什么是最重要的,比如说10%错误率的猫分类器中,你的100个错误标记样本中只有5%是狗,就是说在100个错误标记的开发集样本中,有5个是狗和100个错误标记的开发集样本,你发现实际有50张图都是狗,所以有50%都是狗的照片,显然是后者更适合单独花时间去解决,前者解决了只会使错误率由10%到9.5%,而后者会变为5%
所以总结一下,进行错误分析,你应该找一组错误样本,可能在你的开发集里或者测试集里,观察错误标记的样本,看看假阳性(false positives)和假阴性(false negatives),统计属于不同错误类型的错误数量
2.清除标注错误的数据
你的监督学习问题的数据由输入 x xx 和输出标签 y yy 构成,如果你观察一下你的数据,并发现有些输出标签 是错的。你的数据有些标签是错的,是否值得花时间去修正这些标签呢?
首先,我们来考虑训练集,事实证明,深度学习算法对于训练集中的随机错误是相当健壮的(robust)。只要你的标记出错的样本,只要这些错误样本离随机错误不太远,有时可能做标记的人没有注意或者不小心,按错键了,如果错误足够随机/总数据集足够大,那么放着这些错误不管可能也没问题,而不要花太多时间修复它们。
深度学习算法对随机误差很健壮,但对系统性的错误就没那么健壮了。所以比如说,如果做标记的人一直把白色的狗标记成猫,那就成问题了。因为你的分类器学习之后,会把所有白色的狗都分类为猫。但随机错误或近似随机错误,对于大多数深度学习算法来说不成问题。
如果这些标记错误严重影响了你在开发集上评估算法的能力,那么就应该去花时间修正错误的标签。但是,如果它们没有严重影响到你用开发集评估成本偏差的能力,那么可能就不应该花宝贵的时间去处理。比如说,错误率为10%,6%的错误来自标记出错,所以10%的6%就是0.6%和错误率为2%,6%的错误来自标记出错,显然是后者更值得手动重新检查标签修正标记错误
总而言之,在构造实际系统时,通常需要更多的人工错误分析,更多的人类见解来架构这些系统
3.快速搭建你的第一个系统,并进行迭代
如果你正在开发全新的机器学习应用,教授会给你这样的建议,你应该尽快建立你的第一个系统原型,然后快速迭代。
一般来说,对于几乎所有的机器学习程序可能会有50个不同的方向可以前进,并且每个方向都是相对合理的可以改善你的系统。但挑战在于,你如何选择一个方向集中精力处理。我的意思是我建议你快速设立开发集和测试集还有指标,这样就决定了你的目标所在,如果你的目标定错了,之后改也是可以的。但一定要设立某个目标,然后我建议你马上搭好一个机器学习系统原型,然后找到训练集,训练一下,看看效果,开始理解你的算法表现如何,在开发集测试集,你的评估指标上表现如何。当你建立第一个系统后,你就可以马上用到之前说的偏差方差分析,还有之前讨论的错误分析,来确定下一步优先做什么
总而言之,搭建快速而粗糙的实现,然后用它做偏差/方差分析,用它做错误分析,然后用分析结果确定下一步优先要做的方向。
“踏上取经路,比取到真经更为重要”
4.在不同的划分上进行训练并测试
深度学习算法对训练数据的胃口很大,当你收集到足够多带标签的数据构成训练集时,算法效果最好,这导致很多团队用尽一切办法收集数据,然后把它们堆到训练集里,让训练的数据量更大,即使有些数据,甚至是大部分数据都来自和开发集、测试集不同的分布。在深度学习时代,越来越多的团队都用来自和开发集、测试集分布不同的数据来训练

假设你在开发一个手机应用,用户会上传他们用手机拍摄的照片,你想识别用户从应用中上传的图片是不是猫。现在你有两个数据来源,一个是你真正关心的数据分布,来自应用上传的数据,比如右边的应用,这些照片一般更业余,取景不太好,有些甚至很模糊。另一个数据来源就是你可以用爬虫程序挖掘网页直接下载,就这个样本而言,可以下载很多取景专业、高分辨率、拍摄专业的猫图片。如果你的应用用户数还不多,也许你只收集到10,000张用户上传的照片,但通过爬虫挖掘网页,你可以下载到海量猫图,也许你从互联网上下载了超过20万张猫图。而你真正关心的算法表现是你的最终系统处理来自应用程序的这个图片分布时效果好不好,因为最后你的用户会上传类似右边这些图片,你的分类器必须在这个任务中表现良好。现在你就陷入困境了,因为你有一个相对小的数据集,只有10,000个样本来自那个分布,而你还有一个大得多的数据集来自另一个分布,图片的外观和你真正想要处理的并不一样。但你又不想直接用这10,000张图片,因为这样你的训练集就太小了,使用这20万张图片似乎有帮助。但是,困境在于,这20万张图片并不完全来自你想要的分布,那么你可以怎么做呢?
这里有一种选择,你可以做的一件事是将两组数据合并在一起,这样你就有21万张照片,你可以把这21万张照片随机分配到训练、开发和测试集中。为了说明观点,我们假设你已经确定开发集和测试集各包含2500个样本,所以你的训练集有205000个样本。现在这么设立你的数据集有一些好处,也有坏处。好处在于,你的训练集、开发集和测试集都来自同一分布,这样更好管理。但坏处在于,这坏处还不小,就是如果你观察开发集,看看这2500个样本其中很多图片都来自网页下载的图片,那并不是你真正关心的数据分布,你真正要处理的是来自手机的图片。
所以结果你的数据总量,这200,000个样本,我就用 200k 缩写表示,我把那些是从网页下载的数据总量写成 210k ,所以对于这2500个样本,数学期望值是: ,有2381张图来自网页下载,这是期望值,确切数目会变化,取决于具体的随机分配操作。但平均而言,只有119张图来自手机上传。要记住,设立开发集的目的是告诉你的团队去瞄准的目标,而你瞄准目标的方式,你的大部分精力都用在优化来自网页下载的图片,这其实不是你想要的。所以我真的不建议使用第一个选项,因为这样设立开发集就是告诉你的团队,针对不同于你实际关心的数据分布去优化,所以不要这么做。
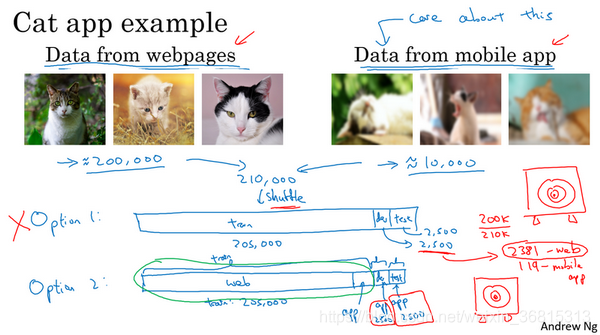
我建议你走另外一条路,就是这样,训练集,比如说还是205,000张图片,我们的训练集是来自网页下载的200,000张图片,然后如果需要的话,再加上5000张来自手机上传的图片。然后对于开发集和测试集,这数据集的大小是按比例画的,你的开发集和测试集都是手机图。而训练集包含了来自网页的20万张图片,还有5000张来自应用的图片,开发集就是2500张来自应用的图片,测试集也是2500张来自应用的图片。这样将数据分成训练集、开发集和测试集的好处在于,现在你瞄准的目标就是你想要处理的目标,你告诉你的团队,我的开发集包含的数据全部来自手机上传,这是你真正关心的图片分布。我们试试搭建一个学习系统,让系统在处理手机上传图片分布时效果良好。缺点在于,当然了,现在你的训练集分布和你的开发集、测试集分布并不一样。事实证明,这样把数据分成训练、开发和测试集,在长期能给你带来更好的系统性能。
5.不匹配数据划分的偏差和误差
估计学习算法的偏差和方差真的可以帮你确定接下来应该优先做的方向,但是,当你的训练集来自和开发集、测试集不同分布时,分析偏差和方差的方式可能不一样
我们继续用猫分类器为例,要进行错误率分析,你通常需要看训练误差,也要看看开发集的误差。比如说,在这个样本中,你的训练集误差是1%,你的开发集误差是10%,如果你的开发集来自和训练集一样的分布,你可能会说,这里存在很大的方差问题,你的算法不能很好的从训练集出发泛化,它处理训练集很好,但处理开发集就突然间效果很差了。
但如果你的训练数据和开发数据来自不同的分布,你就不能再放心下这个结论了。特别是,也许算法在开发集上做得不错,可能因为训练集很容易识别,因为训练集都是高分辨率图片,很清晰的图像,但开发集要难以识别得多。所以也许软件没有方差问题,这只不过反映了开发集包含更难准确分类的图片。所以这个分析的问题在于,当你看训练误差,再看开发误差,有两件事变了。首先算法只见过训练集数据,没见过开发集数据。第二,开发集数据来自不同的分布。而且因为你同时改变了两件事情,很难确认这增加的9%误差率有多少是因为算法没看到开发集中的数据导致的,这是问题方差的部分,有多少是因为开发集数据就是不一样。
我们要做的是随机打散训练集,然后分出一部分训练集作为训练-开发集(training-dev),就像开发集和测试集来自同一分布,训练集、训练-开发集也来自同一分布。
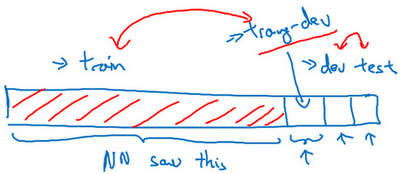
这个样本中,训练误差是1%,我们说训练-开发集上的误差是9%,然后开发集误差是10%,和以前一样。你就可以从这里得到结论,当你从训练数据变到训练-开发集数据时,错误率真的上升了很多。而训练数据和训练-开发数据的差异在于,你的神经网络能看到第一部分数据并直接在上面做了训练,但没有在训练-开发集上直接训练,这就告诉你,算法存在方差问题,因为训练-开发集的错误率是在和训练集来自同一分布的数据中测得的。所以你知道,尽管你的神经网络在训练集中表现良好,但无法泛化到来自相同分布的训练-开发集里,它无法很好地泛化推广到来自同一分布,但以前没见过的数据中,所以在这个样本中我们确实有一个方差问题。
我们来看一个不同的样本,假设训练误差为1%,训练-开发误差为1.5%,但当你开始处理开发集时,错误率上升到10%。现在你的方差问题就很小了,因为当你从见过的训练数据转到训练-开发集数据,神经网络还没有看到的数据,错误率只上升了一点点。但当你转到开发集时,错误率就大大上升了,所以这是数据不匹配的问题。因为你的学习算法没有直接在训练-开发集或者开发集训练过,但是这两个数据集来自不同的分布。但不管算法在学习什么,它在训练-开发集上做的很好,但开发集上做的不好,所以总之你的算法擅长处理和你关心的数据不同的分布,我们称之为数据不匹配的问题。
高偏差表现为模型在训练集和测试集上的性能差距较大,但通常训练集性能本身可能并不低。关键在于分布差异导致模型无法捕捉测试集的真实规律。
方差问题通常伴随训练集性能远高于测试集性能,且模型对微小数据变化敏感。
6.定位数据不匹配
如果您的训练集来自和开发测试集不同的分布,如果错误分析显示你有一个数据不匹配的问题该怎么办?这个问题没有完全系统的解决方案,但我们可以看看一些可以尝试的事情。如果我发现有严重的数据不匹配问题,我通常会亲自做错误分析,尝试了解训练集和开发测试集的具体差异。技术上,为了避免对测试集过拟合,要做错误分析,你应该人工去看开发集而不是测试集。
开发集有可能跟训练集不同或者更难识别,那么你可以尝试把训练数据变得更像开发集一点,或者,你也可以收集更多类似你的开发集和测试集的数据(人工合成数据)
总而言之,如果你认为存在数据不匹配问题,我建议你做错误分析,或者看看训练集,或者看看开发集,试图找出,试图了解这两个数据分布到底有什么不同,然后看看是否有办法收集更多看起来像开发集的数据作训练。
7.迁移学习
深度学习中,最强大的理念之一就是,有的时候神经网络可以从一个任务中习得知识,并将这些知识应用到另一个独立的任务中
迁移学习(Transfer Learning)是一种机器学习方法,通过将已训练模型的知识(如参数、特征表示)迁移到新的相关任务上,从而减少对新任务数据量和计算资源的需求。其核心思想是利用源领域的知识提升目标领域的性能。
应用于:
数据不足(主要):目标领域标注数据较少时,利用源领域的大规模数据预训练模型。
计算资源有限:直接训练复杂模型成本高,迁移预训练模型可降低计算开销。
跨领域任务:如将自然语言处理的BERT模型迁移到医疗文本分类任务。
具体来说,在第一阶段训练过程中,当你进行图像识别任务训练时,你可以训练神经网络的所有常用参数,所有的权重,所有的层,然后你就得到了一个能够做图像识别预测的网络。在训练了这个神经网络后,要实现迁移学习,你现在要做的是,把数据集换成新的 ( x , y ) (x,y)(x,y) 对,现在这些变成放射科图像,而 y yy 是你想要预测的诊断,你要做的是初始化最后一层的权重,让我们称之为 和
随机初始化。
现在,我们在这个新数据集上重新训练网络,在新的放射科数据集上训练网络。要用放射科数据集重新训练神经网络有几种做法。你可能,如果你的放射科数据集很小,你可能只需要重新训练最后一层的权重,就是和
并保持其他参数不变。如果你有足够多的数据,你可以重新训练神经网络中剩下的所有层。经验规则是,如果你有一个小数据集,就只训练输出层前的最后一层,或者也许是最后一两层。但是如果你有很多数据,那么也许你可以重新训练网络中的所有参数。如果你重新训练神经网络中的所有参数,那么这个在图像识别数据的初期训练阶段,有时称为预训练(pre-training),因为你在用图像识别数据去预先初始化,或者预训练神经网络的权重。然后,如果你以后更新所有权重,然后在放射科数据上训练,有时这个过程叫微调(fine tuning)。如果你在深度学习文献中看到预训练和微调,你就知道它们说的是这个意思,预训练和微调的权重来源于迁移学习。
特征提取,固定预训练模型的底层参数,仅训练顶层的分类器例如:
from tensorflow.keras.applications import VGG16base_model = VGG16(weights='imagenet', include_top=False, input_shape=(224, 224, 3))
for layer in base_model.layers:layer.trainable = False # 冻结预训练模型的权重
微调,解冻部分预训练模型的层,与新任务数据联合训练。例如:
base_model.trainable = True
for layer in base_model.layers[:-4]: # 仅微调最后4层layer.trainable = False
总结一下,从任务 A 学习并迁移一些知识到任务 B ,那么当任务 A 和任务 B 都有同样的输入 x 时,迁移学习是有意义的
8.多任务学习
在迁移学习中,你的步骤是串行的,你从任务 A 里学习只是然后迁移到任务 B 。在多任务学习中,你是同时开始学习的,试图让单个神经网络同时做几件事情,然后希望这里每个任务都能帮到其他所有任务。
多任务学习(Multi-Task Learning, MTL)是一种机器学习范式,通过同时学习多个相关任务来提升模型的泛化能力。核心思想是利用任务间的相关性共享表示,从而减少过拟合风险并提高数据效率。
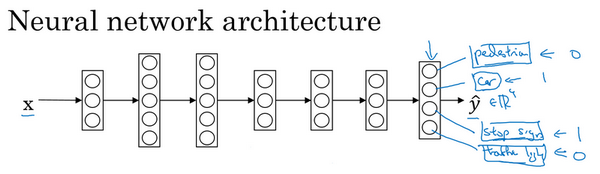
我们来看一个例子,假设你在研发无人驾驶车辆,那么你的无人驾驶车可能需要同时检测不同的物体,比如检测行人、车辆、停车标志,还有交通灯各种其他东西。比如在左边这个例子中,图像里有个停车标志,然后图像中有辆车,但没有行人,也没有交通灯。

那么你现在可以做的是训练一个神经网络,来预测这些 y 值,你就得到这样的神经网络,输入 x ,现在输出是一个四维向量 y 。请注意,这里输出我画了四个节点,所以第一个节点就是我们想预测图中有没有行人,然后第二个输出节点预测的是有没有车,这里预测有没有停车标志,这里预测有没有交通灯,所以这里 是四维的
要训练这个神经网络,你现在需要定义神经网络的损失函数,对于一个输出 是个4维向量,对于整个训练集的平均损失:
是这些单个预测的损失,所以这就是对四个分量的求和,行人、车、停车标志、交通灯,而这个标志 L 指的是logistic损失,我们就这么写:
整个训练集的平均损失和之前分类猫的例子主要区别在于,现在你要对 j = 1 j=1j=1 到 4 44 求和,这与softmax回归的主要区别在于,与softmax回归不同,softmax将单个标签分配给单个样本。
你不是只给图片一个标签,而是需要遍历不同类型,然后看看每个类型,那类物体有没有出现在图中,这里定了四个标签是为了方便理解
如果你训练了一个神经网络,试图最小化这个成本函数,你做的就是多任务学习。因为你现在做的是建立单个神经网络,观察每张图,然后解决四个问题,系统试图告诉你,每张图里面有没有这四个物体。另外你也可以训练四个不同的神经网络,而不是训练一个网络做四件事情。但神经网络一些早期特征,在识别不同物体时都会用到,然后你发现,训练一个神经网络做四件事情会比训练四个完全独立的神经网络分别做四件事性能要更好,这就是多任务学习的力量。
多任务学习也可以处理图像只有部分物体被标记的情况。所以第一个训练样本,我们说有人,给数据贴标签的人告诉你里面有一个行人,没有车,但他们没有标记是否有停车标志,或者是否有交通灯。即使是这样的数据集,你也可以在上面训练算法,同时做四个任务,即使一些图像只有一小部分标签,其他是问号或者不管是什么。然后你训练算法的方式,即使这里有些标签是问号,或者没有标记,这就是对 j 从1到4求和,你就只对带0和1标签的 j 值求和,所以当有问号的时候,你就在求和时忽略那个项,这样只对有标签的值求和,于是你就能利用这样的数据集。
以下情况多任务学习有意义:
第一,如果你训练的一组任务,可以共用低层次特征。对于无人驾驶的例子,同时识别交通灯、汽车和行人是有道理的,这些物体有相似的特征,也许能帮你识别停车标志,因为这些都是道路上的特征。
第二,这个准则没有那么绝对,所以不一定是对的。但我从很多成功的多任务学习案例中看到,如果你专注于单项任务,如果想要从多任务学习得到很大性能提升,那么其他任务加起来必须要有比单个任务大得多的数据量,比如,你有100个任务,每个任务中的数据量很相近
最后多任务学习往往在以下场合更有意义,当你可以训练一个足够大的神经网络,同时做好所有的工作,所以多任务学习的替代方法是为每个任务训练一个单独的神经网络。
所以这就是多任务学习,在实践中,多任务学习的使用频率要低于迁移学习。我看到很多迁移学习的应用,你需要解决一个问题,但你的训练数据很少,所以你需要找一个数据很多的相关问题来预先学习,并将知识迁移到这个新问题上。但多任务学习比较少见,就是你需要同时处理很多任务,都要做好,你可以同时训练所有这些任务,也许计算机视觉是一个例子。
总结一下,多任务学习能让你训练一个神经网络来执行许多任务,这可以给你更高的性能,比单独完成各个任务更高的性能。
9.什么是端到端的深度学习
端到端深度学习(End-to-End Deep Learning)是一种模型设计方法,通过单一神经网络直接从输入数据映射到最终输出,无需人工设计中间步骤或特征工程。传统机器学习流程通常包含多个模块(如特征提取、分类器设计等),而端到端方法将这些模块整合为一个统一的模型,由数据驱动自动学习最优表示。个人理解就是用单个神经网络代替多个阶段的处理
事实证明,端到端深度学习的挑战之一是,你可能需要大量数据才能让系统表现良好,比如,你只有3000小时数据去训练你的语音识别系统,那么传统的流水线效果真的很好。但当你拥有非常大的数据集时,比如10,000小时数据或者100,000小时数据,这样端到端方法突然开始很厉害了。所以当你的数据集较小的时候,传统流水线方法其实效果也不错,通常做得更好。你需要大数据集才能让端到端方法真正发出耀眼光芒。如果你的数据量适中,那么也可以用中间件方法,你可能输入还是音频,然后绕过特征提取,直接尝试从神经网络输出音位,然后也可以在其他阶段用,所以这是往端到端学习迈出的一小步,但还没有到那里。因为对于机器翻译来说的确有很多(英文,法文)的数据对,端到端深度学习在机器翻译领域非常好用。
10.是否要使用端到端的深度学习
假设你正在搭建一个机器学习系统,你要决定是否使用端对端方法,我们来看看端到端深度学习的一些优缺点,这样你就可以根据一些准则,判断你的应用程序是否有希望使用端到端方法。
应用端到端学习的一些好处,首先端到端学习真的只是让数据说话。所以如果你有足够多的(x,y) 数据,那么不管从 x 到 y 最适合的函数映射是什么,如果你训练一个足够大的神经网络,希望这个神经网络能自己搞清楚,而使用纯机器学习方法,直接从 x 到 y 输入去训练的神经网络,可能更能够捕获数据中的任何统计信息,而不是被迫引入人类的成见。
端到端深度学习的第二个好处就是所需手工设计的组件更少,所以这也许能够简化你的设计工作流程,你不需要花太多时间去手工设计功能,手工设计这些中间表示方式。
缺点是需要大量数据和排除了可能有用的手工设计组件。

如果你在构建一个新的机器学习系统,而你在尝试决定是否使用端到端深度学习,我认为关键的问题是,你有足够的数据能够直接学到从 x 映射到 y 足够复杂的函数吗?(个人理解,就是你有没有足够的数据去支撑这一学习方式)我还没有正式定义过这个词“必要复杂度(complexity needed)”。但直觉上,如果你想从 x 到 y 的数据学习出一个函数,就是看着这样的图像识别出图像中所有骨头的位置,那么也许这像是识别图中骨头这样相对简单的问题,也许系统不需要那么多数据来学会处理这个任务。或给出一张人物照片,也许在图中把人脸找出来不是什么难事,所以你也许不需要太多数据去找到人脸,或者至少你可以找到足够数据去解决这个问题。
11.总结与习题
2.11 总结-深度学习第三课《结构化机器学习项目》-Stanford吴恩达教授_在结构化学习中,教授机器-CSDN博客