NM:微生物组数据分析的规划与描述

微生物生态学和微生物组科学的进展依赖于高质量的数据及其高质量的分析。为实现这一目标,研究发现必须既可重复(分析必须能在相同数据上重复进行)又可复现(发现必须在收集类似数据的未来研究中得到验证)。为确保可重复性,需要提供样本采集和实验室处理的信息,如样本储存温度、DNA提取试剂盒和方案、PCR引物和PCR循环数,以及后处理(生物信息学)细节,包括用于重叠群组装或序列变体构建的软件。不幸的是,当涉及统计分析时,方法部分经常缺少必要的细节和论证。
对于关注少量目标的研究,单个段落通常足以描述所进行的统计分析。然而,包括微生物组科学在内的现代基因组学领域,现在经常收集数千个生物单元的定量信息,包括菌株、基因和代谢通路,这些可以用无数种方式进行分析和总结。许多现代微生物组研究涵盖生态系统内的汇总统计如α多样性、跨生态系统的群落重叠或β多样性、差异丰度、系统发育分析等。与实验室和原始数据处理步骤一样,这些方法中的每一种都需要仔细描述方法、论证和质量控制保证。
以上述详细程度描述统计分析计划对作者要求更高,但有许多优势。确定结果变量和预测变量的过程(下文将详细讨论)可能有助于作者选择与研究目标一致的分析计划。因此,同行评审可能会更顺畅,因为审稿人和读者可以明确辨别进行了哪些分析。读者更可能正确解释结果,对发现的稳健性有信心,并相信显著结果可归因于生物学。最后,由于作者的假设被明确陈述,这将加速开发符合作者需求的统计方法。
为帮助作者规划、执行和描述他们的统计分析,我们为微生物组研究者提供一般指导和一个检查清单,以确认所描述分析的透明度和完整性。

创建统计分析计划
在获得数据之前起草统计分析可以提高研究质量。它可以使实验与目标科学问题保持一致,确保实验设计可以在分析中得到考虑,并突出显示用于质量控制或验证的相关数据。例如,尽管人们对纵向微生物组研究充满热情,但许多研究实际上对横断面比较感兴趣(例如,在环境暴露不同的人群之间),对于这些研究,纵向设计可能不是资源最优的。类似地,如果特定微生物群落成员的丰度是科学目标,则除了群落调查数据外,还可以收集绝对定量数据。下面我们提供了一个工作流程,用于起草和完善微生物组研究的统计分析部分,并附有示例。
列出计划的分析
首先,列出计划执行的所有分析。即使不同的生物单元将从相同的原始数据构建,也应该为每个生物单元进行此操作。例如,列表可能包括:分类学分析(α多样性包括丰富度、Shannon多样性,β多样性包括Bray-Curtis、UniFrac,差异丰度包括比例、倍数变化,差异存在/缺失包括被观察到的几率);基因分析(α多样性包括丰富度,差异丰度包括比例差异、倍数变化,差异存在/缺失包括被观察到的几率);序列分析(系统发育分析包括宏基因组组装基因组的物种树)。
上述列表中的每一项都是可以从相同原始数据(如鸟枪测序数据)构建的不同生物单元。您应该在列表中包含所有分析,而不仅仅是您计划在手稿中讨论的或产生统计显著假设检验的分析。
描述模型
对于您计划执行的每项分析,说明要拟合的模型。在许多情况下,模型的最小完整描述包括:结果变量,例如Chao1(丰富度)、样本Shannon多样性,或是否检测到超过五个reads(存在-缺失);预测变量集,例如年龄(连续测量)、BMI(连续测量)、二元性别(女性为基线)和他汀类药物使用指标的某种组合;用于连接结果和预测变量的模型。这可能是一个简单的模型(例如线性回归)或一个考虑实验设计的更复杂模型(例如,在同笼饲养的动物中具有可交换相关结构的广义估计方程)。
在其他情况下,如系统发育估计,没有预测变量集,描述用于估计结果变量的模型变得更加重要(例如,具有不等突变率和不等核苷酸频率的一般时间可逆模型)。
论证预测变量选择
接下来,论证每个模型中预测变量的选择。大多数研究人员直觉地知道,除了主要暴露或干预(例如治疗)外,在所有方面都相似的观察最适合进行比较。然而,对预测变量进行分类的正式框架有助于关于其省略或包含的含义的科学讨论,并可以阐明关于机制的假设。我们在下面提供了选择预测变量的一些指导原则。
感兴趣的预测变量
感兴趣的预测变量是主要预测变量。这个变量应该始终被包含,因为您想研究结果的分布(或结果分布的摘要,如均值、几率或风险)如何随预测变量的变化而变化。在微生物特征是结果变量、临床或环境特征是预测变量的分析中,常见的感兴趣预测变量包括疾病、治疗和修正。
精度变量
精度变量与结果相关但与感兴趣的预测变量不相关。精度变量之所以这样命名,是因为它们可以增加拒绝错误零假设的能力,通常通过减少与感兴趣的预测变量相关的参数的不确定性。在微生物丰度作为结果的研究中,常见的精度变量包括批次和测序变量(测序批次可能与观察到的计数相关,但与微生物丰度无关)。在任何分析中,通常都有大量未测量和已测量但被省略的精度变量。被省略的精度变量在线性回归中不会使参数估计产生偏差,但在其他回归模型中可能引起偏差并影响结果解释。
混杂因素
在任何旨在理解因果关系的研究中,应该调整充分的混杂因素集以防止混杂偏倚。在简单的情况下,混杂因素是这样的变量:(1)在因果上位于结果的上游,(2)在因果上位于预测变量的上游,(3)不在感兴趣的因果路径中。要确定一个变量是否是混杂因素,必须陈述一组因果假设。这通常通过构建因果图来完成(图1)。构建因果图后,可以查询它以获得控制混杂的调整集。从因果图确定调整集可确保调整混杂因素,并正确省略会在参数估计中引起偏差的变量,如碰撞因子(进一步阅读参见参考文献6)。重要的是,使用数据选择调整集带有重大风险,包括夸大统计显著性、低估不确定性和损害预测。因此,我们强烈主张通过因果推理选择调整集。
选择调整变量
特定测量的"类型"取决于研究。例如,与饮食相关的变量(例如纤维摄入)可能是感兴趣的预测变量、精度变量、混杂因素、碰撞因子或完全无关的变量,这取决于具体的研究问题。因此,在微生物丰度测量作为结果的研究中,不可能就应该调整哪些变量给出普遍适用的建议。这种建议需要因果假设,而因果假设是依赖于背景的。尽管如此,我们在图中为横断面研究提供了一组示例因果假设和由此产生的调整集。
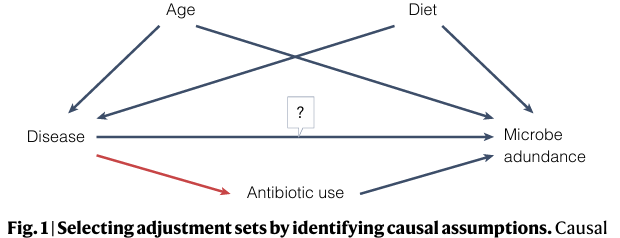
鼓励作者明确说明研究目标是因果性的还是相关性的。例如,回答"患有结直肠癌的成年人是否比没有患癌的成年人具有更高的具核梭杆菌丰度?"是一个相关性目标。相比之下,回答"患有结直肠癌是否会增加具核梭杆菌的丰度?“是一个因果目标。如果混杂是一个问题,那么研究的目标必须是因果性的。即使未测量的混杂的可能性意味着估计不能在没有做出不可检验的假设的情况下进行因果解释,这也是正确的。然而,由于因果和相关性问题需要不同的分析,研究的目标必须明确陈述。
在回归模型中调整变量意味着在关于调整变量相似的组之间进行比较。例如,如果您有兴趣比较使用药物不同的人群中人类肠道细菌物种多样性,比较在年龄、性别和肥胖程度相似的人群非正式地"匹配"了在药物使用上不同但在其他方面相似的受试者。如果研究的目标是回答因果问题"药物是否会降低人类肠道中的物种多样性”,调整这些特征可以降低将由于药物引起的多样性差异与由于其他变量引起的多样性差异混淆的风险。当然,即使进行了调整,由于可能混淆药物和多样性之间关系的未测量变量,估计可能仍有偏差。
统计推断
如果进行了统计推断,请明确说明所检验的零假设。例如,“我们检验了零假设,即在比较相同年龄、BMI和性别的个体时,使用他汀类药物不同的组之间观察到的平均Shannon多样性相等”。应明确说明所执行的检验(例如,使用正态似然的稳健得分检验或假设同方差性的Wald检验)。引用相关软件可以澄清所执行的检验统计量和推断程序,但它不能澄清所检验的零假设。请注意,零假设受分析中调整的变量选择的影响。我们在微生物组研究中看到的一个常见错误是将假设解释为调整或未调整,而实际情况相反,这造成了对所进行比较的混淆和对调整变量处理的模糊性。例如,零假设"观察到的平均Shannon多样性在使用他汀类药物不同的组之间相等"与前述零假设有根本不同。
假设
应陈述每种方法的关键假设以及用于验证它们的方法。例如,许多估计微生物丰度比例差异的方法假设所有微生物都能被同等良好地检测到,这可以使用测序对照进行验证。类似地,观察单位的独立性(以协变量为条件)是大多数统计检验的广泛而关键的假设。应在实验设计的背景下讨论独立性,特别是当研究设计是纵向的、涉及重复测量或批处理,或以其他方式涉及采样相关观察时。将假设表述为分析的"局限性"突出了调查的严谨性。
敏感性分析
应包括对所执行的任何敏感性分析的描述。例如,任何贝叶斯分析的结果都取决于先验参数的选择,要么在科学基础上论证先验的选择,要么说明结果对先验选择的稳健性,都能加强定量论证。类似地,用于分析微生物丰度的许多方法用小的非零丰度替换未观察到的分类群的经验丰度。研究对这种"伪计数"选择的敏感性可以保证差异丰度发现不是人为的。同样,从分析中删除稀有物种的选择可以大大改变多样性的估计,但可以很容易地用不同的流行率过滤阈值重新分析结果。将敏感性分析集中在手稿最重要的发现上比对所有结果进行浅层重新调查更可行和严格。
结论
我们主张在所有微生物组研究论文中包含详细且有组织的"统计分析"部分,包括对所有分析的描述和论证。我们建议将关键假设陈述为局限性,并对关键结果进行敏感性分析。尽管大多数作者通常对他们的选择有很好的论证,但对读者和审稿人的透明度将提高研究的可重复性和可复现性;澄清结果的解释;并增强我们领域的严谨性。
我们的指导方针比目前描述微生物组数据分析的期望更加复杂,我们承认科学家可能不知道我们提出的关于统计假设和参数解释问题的答案。在理想的世界中,每个处理定量数据的研究团队都能获得统计专业知识。在他们的团队中缺乏这种专业知识的情况下,我们鼓励科学家在设计、执行和描述统计分析时考虑与当地统计部门联系。
此外,我们鼓励统计软件的用户向工具开发者寻求澄清,并在科学背景下批判性地考虑方法的局限性。我们相信,跨学科对话和透明文化将通过支持更有效地利用实验资源并为知识积累提供更强大的定量框架而使微生物组科学家受益。
参考文献
Willis, A.D., Clausen, D.S. Planning and describing a microbiome data analysis. Nat Microbiol 10, 604–607 (2025). https://doi.org/10.1038/s41564-025-01944-6