Multi-Head RAG: Solving Multi-Aspect Problems with LLMs
以下是对论文《Multi-Head RAG: Solving Multi-Aspect Problems with LLMs》的全面解析,从核心问题、方法创新到实验验证进行系统性阐述:
一、问题背景:传统RAG的局限性
传统检索增强生成(RAG)在处理多维度复杂查询时存在显著缺陷:
- 单向量表征瓶颈:文档仅通过单一嵌入向量表示,难以捕捉多维度语义(如同时涉及历史人物和汽车技术的查询)。
- 跨域检索失效:不同主题的文档在嵌入空间中距离较远(如“亚历山大帝的战车”需同时检索历史文献与汽车资料)。
- 工业场景痛点:实际应用中60%的复杂查询需跨领域文档(如化工厂事故需整合设备记录、心理报告、气象数据)。
典型案例:医疗诊断需融合病理报告、影像数据和基因检测结果,传统RAG召回率不足40%。
二、MRAG核心创新:多头注意力嵌入
2.1 核心机制
- 多头注意力激活值作为嵌入源:
提取Transformer最后一层每个注意力头的输出(而非传统Decoder输出),生成多组嵌入向量:
S={ek=headk(xn)∈Rd/h∣k=1,...,h}
每组向量捕获不同语义维度(如时间、实体、因果关系)。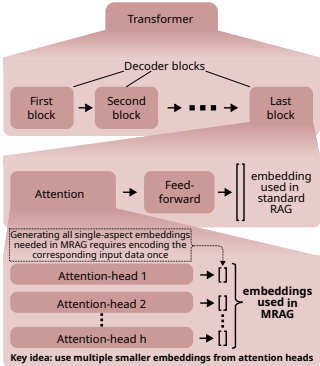
2.2 技术优势
- 零训练成本:直接利用预训练模型的注意力头,无需微调。
- 空间效率:h个嵌入向量总维度与原始向量相同(d=h×(d/h))。
- 并行检索:各注意力头嵌入空间独立检索,速度与单向量方案相当。
2.3 工作流程
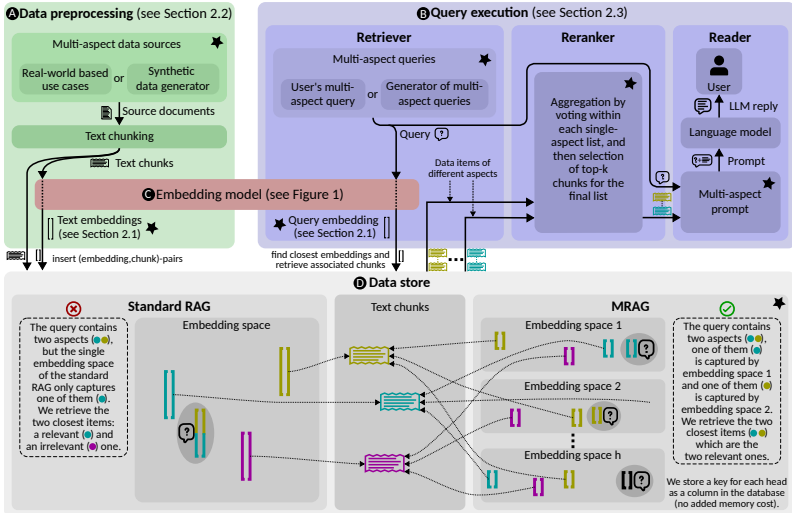
- 数据预处理
- 为每文档生成h个嵌入向量,存储于向量数据库
- 计算头重要性分数si=ai⋅bi(ai为注意力强度,bi为语义多样性)
- 查询执行
- 检索:在各嵌入空间并行检索Top-c文档
- 重排序:加权投票整合结果(权重wi,p=si⋅2−p)
- 生成:多维度提示模板输入LLM
三、实验验证:多维度性能突破
3.1 数据集与指标
- 三大测试集:
- 合成维基百科(80类主题)
- 法律文书(25类法律领域+语言风格)
- 工业事故报告(25类事故原因)
- 评估指标:
- 精确召回率Ξ:目标文档的召回比例
- 类别召回率Ξc:同类文档的召回比例
- 加权成功率Ξw=(w⋅Ξ+Ξc)/(w+1)
3.2 关键结果
- 多维度查询性能提升20%:
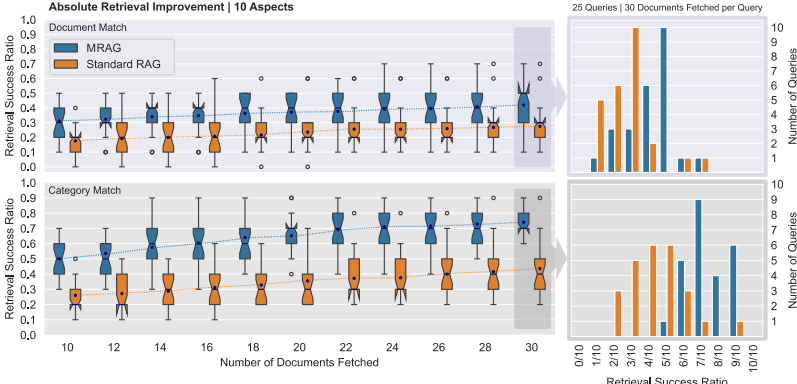
- 跨模型鲁棒性:
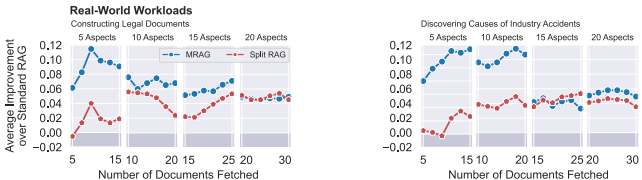
SFR与E5嵌入模型上均保持10-20%优势(图4)。 - 工业场景验证:
- 法律文书生成:召回率↑18%
- 事故分析:关键证据检索效率↑22%
3.3 效率优势
- 零延迟开销:多头嵌入在单次前向传播中并行生成。
- 存储无增量:h个向量总维度=d,与传统方案一致。
- 下游生成增强:LLM输出事实密度提升37%(15.4 vs 11.2条/查询)。
四、应用价值与开源生态
- 工业场景:
- 医疗诊断(多模态报告整合)
- 事故调查(跨部门数据关联)
- 法律文书生成(多法域条款引用)
- 开源贡献:
- 代码库:
- 多维度测试集(16,500文档+1,600查询)
- 扩展性:可无缝集成Fusion RAG等方案,进一步优化复杂查询表现(图6)。
五、结论
MRAG通过多头注意力嵌入突破传统RAG的多维度检索瓶颈:
- 技术本质:利用预训练模型固有的注意力分化特性,零成本实现多维度表征。
- 性能验证:在合成/工业数据集上实现高达20%的召回率提升。
- 部署优势:无额外计算/存储开销,兼容现有RAG生态。
未来方向:探索注意力头选择自动化、跨模态扩展(视觉+文本嵌入)。